正則運算式是Java、Php等編程語言中相當重要的一環,在實際應用程式代碼中相當廣泛,更是網路安全領域中不可或缺的一點,下面總講一下正則運算式的基礎知識以及相關應用
什么是正則運算式:正則運算式(regular expression,簡寫為regex)是一個字串,用來描述匹配一個字串集合的模式, 對于字串處理來說,正則運算式是一個強大的工具,可以使用正則運算式來匹配、替換和拆分字串,
目錄
HINT 1 匹配字串
HINT 2 正則運算式語法
HINT 3 替換和拆分字串
HINT 1 匹配字串
從String類中的matches方法(相較于equals方法雖然類似,但是它的功能強大很多)開始看,它不僅可以匹配一個固定的字串,還可以匹配符合一個模式的字串集,如以下陳述句的結果都為true:
"Java is fun".matches("Java.*")
"Java is cool".matches("Java.*")
"Java is powerful".matches("Java.*")看到以上代碼,后面的 "Java.*"是一個正則運算式,它描述了一個字串模式,以Java開始,后面跟0個或者多個字串,這里,子字串 .* 匹配0或者多個任意字符 簡單點來說就是你前面只要有Java,不論后面是什么都對
這里我們舉幾個例子來看下matches方法的一些基礎用法:String.matches("正則運算式")
System.out.print("e".matches("[ae|cd]"));
//true
System.out.print("w".matches("[xyw]"));
//true
System.out.print("xy".matches("[xyw]{2}"));
//true
/*前面的[xyz]表示字串中字符的范圍,{2}代表匹配范圍為前兩位*/
System.out.print("xyqqqqqq".matches("[xyw]{2}"));
//false
/*因為“xyqqqqqqq”只有前兩位匹配了但后面的多位都不匹配*/
System.out.print("xyqqqqqq".matches("[xyw]{2}.*"));
//true
/*加上“.*”后只判斷{n}中前n位匹配即可*/ 其實我們寫Java用關鍵字引入類別,比如import java.util.Scanner、import java.util.Arrays等等都可以按這樣的方式理解,理解為什么都是寫成這個形式,編譯器中是如何判斷我們輸入的代碼是正確的,歸于什么類別的,包括正則運算式應用于郵箱的創建、判別等等,都是有極大的用處的,這里放一個正則運算式應用于郵箱的鏈接,值得學習!
java郵箱的運算式_Java郵箱正則運算式_weixin_39955423的博客-CSDN博客
HINT 2 正則運算式語法
正則運算式由字面值字符和特殊符號組成,下面的表格列出了正則運算式常用的語法
注意:反斜杠是一個特殊的字符,在字串中開始轉義序列,因此Java中需要使用\\來表示\ 回顧一下,空白字符是 ' '、'\t'、'\n'、'\r' 或者 '\f' ,因此,\s 和 [\t\n\r\f] 等同, \s 和 [^ \t\n\r\f] 等同 
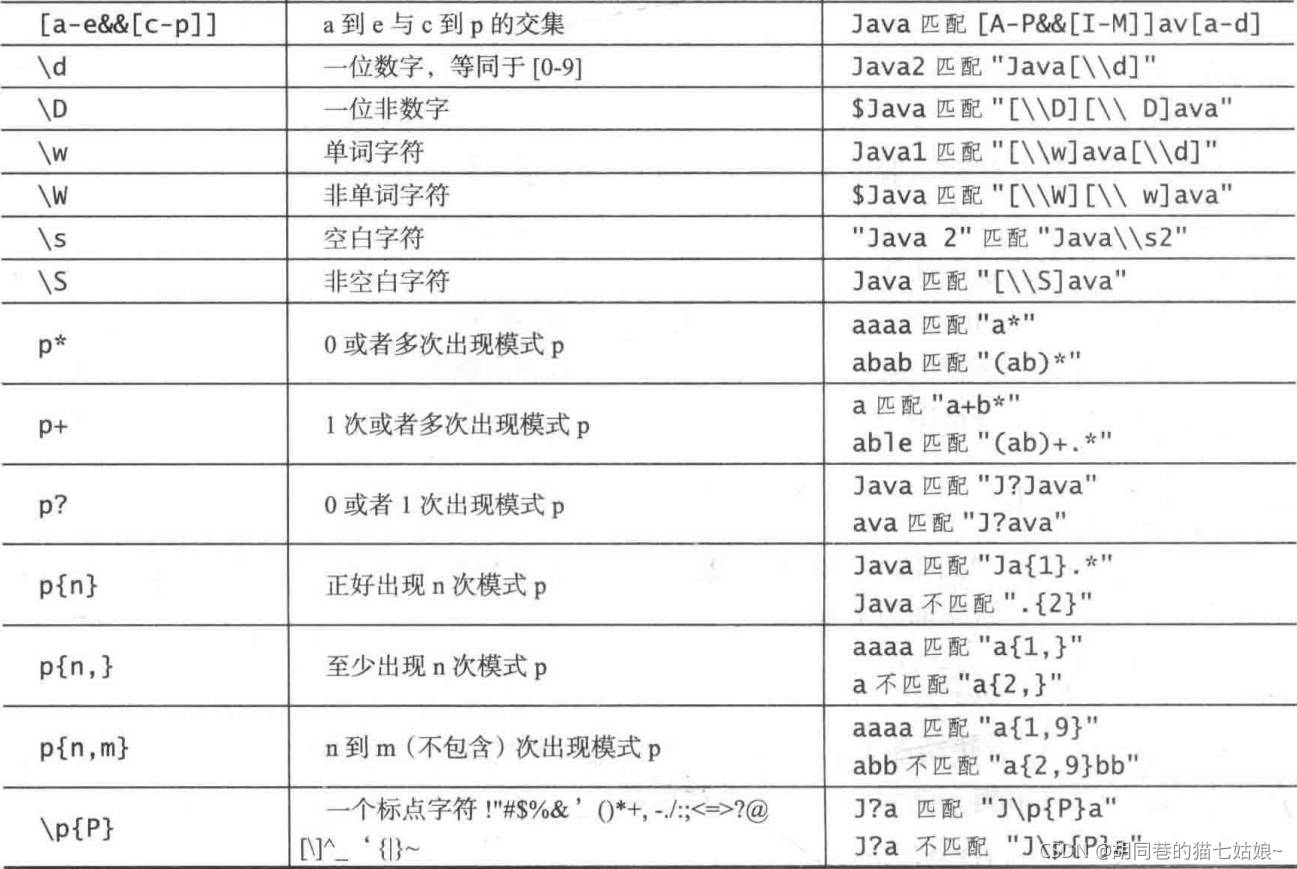
注意!表格中倒數第二行p{n,m}表示n到m次出現模式p,是包含m次的 !下面的例4中用到
有了這個表格的相關表達解釋后上面我們舉例的matches相關應用也能更容易理解了 ,當然了表格中還有一些需要注意與加以詳解的地方,下面總結一下:
1.表中提及的單詞字符是任何的字母,數字或者下劃線字符,因此 \w 等同于 [a-z[A-Z][0-9]_] 或者簡化為 [a-Za-z0-9_],\W 等同于 [^a-Za-z0-9] 2.表中后面六個條目 *、 +、 ?、 {n}、 {n, m} 稱為量詞符,用于確定量詞符前面的模式會重復多少次,例如,A* 匹配0或者多個A,A+ 匹配1或者多個A,A?匹配0或者1個A,而 A{3} 精確匹配AAA,A{3, }匹配至少3個A,A{3,6}匹配3到6之間個A,包括前面提到的 *A 等同于 {0,}, + 等同于 {1,}, ? 等同于{0.1} 任意字串都匹配正則運算式 ".*" 警告:不要再重復量詞中使用空白,例如,A{3,6} 不能寫成逗號后面有一個空白符的 A{3, 6} 3.可以使用括號來將模式進行分組,例如, (ab){3} 匹配 ababab,但是 ab{3} 匹配 abbb
重點理解這個表格,真正去理解正則運算式的語法,它是按照一個怎樣的邏輯去寫然后實作這個功能的,當然了網上還有許多更加深入的正則運算式的具體應用,下面鏈接中的博客也總結到了,想更加深入學習了解的也可以自己去搜去實踐
Java基礎學習總結(21)——常用正則運算式串列 - 一杯甜酒 - 博客園
下面我們也用一些示例來演示如何構建正則運算式:
1.社會安全號的模式是 xxx-xx-xxxx,其中x是一位數字,根據題意得知我們規定的模式就是這樣,那么它的正則運算式可以描述為 [\\d]{3}-[\\d]{2}-[\\d]{4} (需要轉義序列,d表示整數)
System.out.print("111-22-3333".matches("[\\d]{3}-[\\d]{2}-[\\d]{4}"));
//True
System.out.print("11-22-3333".matches("[\\d]{3}-[\\d]{2}-[\\d]{4}"));
//False2.偶數以數字 0、 2、 4、 6 或者 8 結尾,那么偶數的模式可以描述為 [\\d]*[02468] 理解
System.out.print("122".matches("[\\d]*[02468]"));
//true
System.out.print("123".matches("[\\d]*[02468]"));
//false3.電話號碼的模式是 (xxx)xxx-xxxx,這里x是一位數字,并且第一位數字不能為0,那么電話號碼的正則運算式可以描述為 \\([1-9][\\d]{2}\\) [\\d]{3}-[\\d]{4} 注意: 括符在正則運算式中是特殊字符,用于對模式進行分組,為了在正則運算式中表示字面值(或者),必須用轉義符\\
System.out.print("(912) 921-2343".matches("\\([1-9][\\d]{2}\\) [\\d]{3}-[\\d]{4}"));
//true
System.out.print("(012) 921-2343".matches("\\([1-9][\\d]{2}\\) [\\d]{3}-[\\d]{4}"));
//false4.假定姓由最多25個字母組成,并且第一個字母為大寫形式,符合這兩個要求的正則運算式(姓的模式)可以寫成 [A-Z][a-zA-Z]{1,24} 這里解釋一下這個正則運算式,我們應該按照順序來匹配,正則都是這樣的,所以[A-Z]是匹配第一個字母是否是大寫字母,接下來匹配24個大小寫都可以的字母,這樣很容易理解 注意:同上面講到的要求一樣,不能隨便放空白符到正則運算式中,否則報錯
System.out.print("Smith".matches("[A-Z][a-zA-Z]{1,24}"));
//ture
System.out.print("Jone123".matches("[A-Z][a-zA-Z]{1,24}"));
//false
System.out.print("yellin".matches("[A-Z][a-zA-Z]{1,24}"));
//false5.根據Java識別符號的定義(1.識別符號必須以字母、下劃線(_)或者美元符號開始,不能以數字開頭 2.識別符號是一個由字母、數字、下劃線和美元符號組成的字符序列),那么識別符號的模式(正則運算式)可以描述為[a-zA-Z_$][\\w$]* 這個也按照正則運算式順序來理解
HINT 3 替換和拆分字串
前面所提及的正則運算式的用途還有替換和拆分字串沒講,這里簡單了解一下,如果字串匹配正則運算式,String類的matches方法回傳true,當然了String類也包含repalceAll、replaceFirst和split方法(這個在基礎語言中應該應用地相當廣泛),用于替換和拆分字串,用法可在下圖中了解,如果想更詳盡地知道可以自行去檢索
這里舉幾個例子說明一下 replaceAll 方法表示替換所有匹配的子字串 replaceFirst方法表示替換第一個匹配的子字串
System.out.print("Lyq Lyq Lyq".replaceAll("y\\w", "sf"));
//程式運行結果為 Lsf Lsf Lsf
//該方法是替換匹配到的所有子字串,也就是查別到后面的所有都要替換,這里我們從"y"開始
System.out.print("Lyq Lyq Lyq".replaceFirst("L\\w", "X"));
//程式運行結果為 Xyq Lyq Lyq
//一個字母當然也是一個子字串,這里只更改匹配到的第一個,后面再出現也不再更改
//自己也可以多去嘗試一下,比如一個替換多個,這些都是可以的,實踐出真知而split方法有兩個多載方式: 1.split(regex)方法使用匹配的分隔符將一個字串拆分為子字串,例如以下陳述句:
String[] love = "Lsf13Xyq14Forever".split("\\d\\d");
for (int i = 0;i < 3;i++)
{
System.out.print(love[i] +' ');
}
//程式運行結果為 Lsf Xyq Forever
//這里陳述句 String[] love = "Lsf13Xyq14Forever".split("\\d\\d") 將字串"Lsf13Xyq14Forever"
//拆分為 Lsf、Xyq以及Forever并且保存在love[0],love[1]和love[2]中,注意我們后面拆分的條件是識別
//到兩個數字,這里必須是一一對應的關系,不能只寫一個//d,大家可以用多種情況去跑一下,自己檢驗2.split(regex,limit)方法中,limit 引數確定模式匹配多少次,如果 limit <= 0,split(regex,limit) 等同于 split(regex),如果 limit > 0,模式最多匹配 limit - 1次,下面是一些示例:
String[] love = "Lsf13Xyq14Forever".split("\\d\\d",0);
//拆分為 Lsf, Xyq, Forever 相當于split("\\d\\d") 無限匹配
String[] love = "Lsf13Xyq14Forever".split("\\d\\d",1);
//拆分為 LsfXyqForever 拆分limit - 1次,所以此時拆分0次,即不拆分
String[] love = "Lsf13Xyq14Forever".split("\\d\\d",2);
//拆分為 Lsf, XyqForever 此時拆分2 - 1次
String[] love = "Lsf13Xyq14Forever".split("\\d\\d",3);
//拆分為 Lsf, Xyq, Forever 此時拆分3 - 1次,拆分完畢
String[] love = "Lsf13Xyq14Forever".split("\\d\\d",4);
//拆分為 Lsf, Xyq, Forever 大于最大拆分數,也只拆分這么多次注意:默認情況下,所有量詞符都是“貪婪”的,這意味著它們會盡可能匹配多次,比如下面陳述句會顯示 JRvaa,因為第一個匹配成功的是aaa
System.out.println("Jaaavaa".replaceFirst("a+","R"));
這里不要理解錯題目的意思,并不是說在整個字串中找a最多的子字串進行替換,而是匹配到第一個含a子字串盡可能多地將a全部替換掉,比如這里會替換aaa,而非aaa中的一個或者兩個a,Jaavaaaa也會被替換成JRvaaaa
解決方法:可以通過在后面添加問號(?)來改變數詞符的默認行為,量詞符變為“不情愿”或者“惰性”的,這意味著它將匹配盡可能少的次數,例如,下面的陳述句顯示JRaavaa,因為第一個匹配成功的是a
System.out.println("Jaaavaa".replaceFirst("a+?","R"));
以上就是Java中正則運算式的基礎知識與相關應用,實際上正則在各類編程語言中應用得相當廣泛,我們生活中的很多功能也是通過正則實作的,大家也可以去搜索相關網課或者博客繼續深入學習~ (#^.^#)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/342200.html
標籤:java
上一篇:【JAVA SE】 JAVA基礎強襲之路 資料型別及其轉換和提升全面講解(猛男細節+保底一個收藏)
下一篇:CGBTN2109匯總復習