對于初學者來說,摸索清楚一個領域的知識體系往往比單純學習某個技術要重要得多,因為技術總會跟隨時代發生快速變化,而知識體系往往變化較小,今天我們以自學的角度來了解一下Python爬蟲的知識體系吧,
一、python爬蟲提取資訊的基本步驟:
1,獲取資料
2,決議資料
3,提取資料
4,保存資料
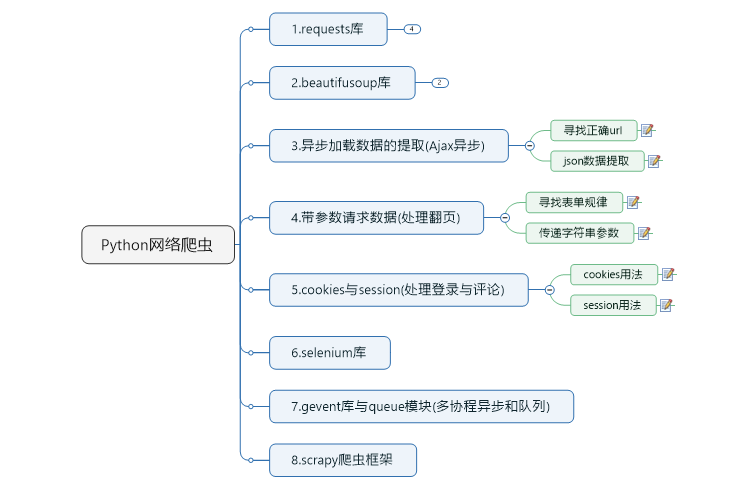
二、python爬蟲學習框架
1,requests庫
requests庫主要功能是模擬瀏覽器發送請求,獲取網頁資料,最重要的方法就是requests.get()方法,其次還有3個重要屬性:response.text(獲取網頁文本)、response.content(獲取二進制內容)、response.encoding(更改網頁編碼方式),
2,beautifulsoup庫
beautifulsoup庫主要功能是決議網頁與資訊提取,其實我們平時日常作業還是用得比較少,因為不夠便捷!你沒聽錯,雖然beautifulsoup庫也可以實作大部分網頁的資訊提取,但是我還是推薦Xpath(需配合谷歌瀏覽器xpath插件使用),另外還有大名鼎鼎的正則運算式(re),不過使用頻率較少,

附上xpath語法及簡單案例

import requests,time #載入庫from lxml import etree #載入xpath需要的決議器for page in range(1,2): #爬取頁數url = f"https://www.fabiaoqing.com/biaoqing/lists/page/{page}.html"headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"} #網址及請求頭#f"https://www.fabiaoqing.com/biaoqing/lists/page/{page}.html"與"https://www.fabiaoqing.com/biaoqing/lists/page/{}.html".format(page)用法一致,r = requests.get(url,headers=headers) #發送網路請求time.sleep(1) #time庫,用來等待1秒,減少網站服務器壓力print(r.status_code) #列印狀態碼html = etree.HTML(r.text) #將網頁文本放入決議器results = html.xpath("//div[@class='tagbqppdiv']/a/img") #提取目標網址for result in results: #遍歷序列tpurl = result.xpath("./@data-original")[0] #提取網址文本print(tpurl) #列印網址tp = requests.get(tpurl,headers) #獲取圖片with open(tpurl[-10:],"wb") as f: #保存f.write(tp.content) #保存為二進制內容f.close() #關閉檔案
學會前面兩個庫和xpath選擇器,那么恭喜你,你已經掌握了至少60%的網頁爬取方法,
3,異步加載資料的提取(Ajax異步)
比如網易云音樂、QQ音樂等,這里要分兩種情況,一種是異步加載,一種是演算法加密,異步加載只需要通過瀏覽器的XHR選項,找到發送請求真正的網址,采用json資料提取方式即可(方法同字典格式);演算法加密的資料直接使用selenium庫獲取,以免掉頭發,
4,帶引數請求提取翻頁資料(處理翻頁)
在處理異步加載時,一般都需要處理網址翻頁,這個時候就需要多查看幾個后面的網址,總結網址翻頁的規律,再通過網址引數發送請求即可,
學會前面4步,那么恭喜你,你已經掌握了至少80%的網頁爬取方法,
5,cookies與session(處理登錄與評論)
有些網站的資料是非公開的,比如淘寶,攜程等,需要登錄,這時候就需要使用python去模擬登錄,當然也可以模擬發送評論資訊,
6,selenium庫
selenium庫是通過指揮瀏覽器作業,間接獲取網頁資訊,可以無視網頁加密和快速處理登錄,優勢相當明顯,大力推薦使用,但需要配置瀏覽器驅動,
學會前面6步,那么恭喜你,你已經掌握了至少90%的網頁爬取方法,
7,gevent庫與queue模塊(多協程異步和佇列)
如果你有大規模的資料需要獲取,可以學習使用這兩個模塊,非專業作業者可以直接跳過,
8,scrapy庫
scrapy是一個非常優秀的網路爬蟲框架,應該有所耳聞吧!適合于大規模資料的提取,自學者可以嘗試一下,
學會前面8步,那么恭喜你,你已經掌握了大規模資料的爬取方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/342218.html
標籤:python
上一篇:解決安裝Python后IDA中找不到Python模塊的問題
下一篇:Python---分支與回圈