您好,我是碼農飛哥,感謝您閱讀本文,歡迎一鍵三連哦,
本文是爬蟲專欄的第四篇,重點介紹lxml庫與XPath搭配使用決議網頁提取網頁內容,
干貨滿滿,建議收藏,系列文章持續更新, 小伙伴們如有問題及需要,歡迎踴躍留言告訴我哦~ ~ ~,
前言(為什么寫這篇文章)
上一篇文章我們簡單的介紹了Html與xml的基本概念,并且重點介紹了XPath的語法,這篇文章就讓我們來實戰一下: 通過本文你將學會如何 如何利用lxml庫來加載和決議網頁,然后搭配XPath的語法定位特定元素及節點資訊的知識點,
文章目錄
- 前言(為什么寫這篇文章)
- lxml庫的介紹
- 利用pip安裝lxm庫
- 利用lxml庫決議HTML片段
- 利用lxml庫加載html檔案
- 實戰開始
- 第一步: 獲得文章的分組
- 第二步: 獲取文章的鏈接
- 第三步:獲取標題內容
- 完整的參考代碼
- 總結
- 粉絲專屬福利
lxml庫的介紹
lxml庫是一個HTML/XML的決議器,主要功能是如何決議和提取HTML/XML的資料,
lxml和正則一樣,也是用C語言實作的,是一款高性能的Python HTML/XML決議器,利用前面學習的XPath的語法來快速定位網頁上的特定元素以及節點資訊,
利用pip安裝lxm庫
pip install lxml
利用lxml庫決議HTML片段
lxml庫可以決議傳入的任何一段XML或者HTML片段,當然前提是你的XML或者HTML片段沒有語法錯誤,
#lxml_test.py
from lxml import etree
text = """
<div id="content_views" class="htmledit_views">
<p style="text-align:center;"><strong>全網ID名:<b>碼農飛哥</b></strong></p>
<p style="text-align:right;"><strong>掃碼加入技術交流群!</strong></span></p>
<p style="text-align:right;"><img src="https://img-blog.csdnimg.cn/5df64755954146a69087352b41640653.png"/></p>
<div style="text-align:left;">個人微信號<img src="https://img-blog.csdnimg.cn/09bddad423ad4bbb89200078c1892b1e.png"/></div>
</div>
"""
# 利用etree.HTML將字串決議成HTML檔案
html = etree.HTML(text)
print("呼叫etree.HTML=", html)
# 將Element物件序列化成字串
result = etree.tostring(html)
print("將Element物件序列化成字串=", result)
result2 = etree.tostring(html, encoding='utf-8').decode()
print(result2)

從上面的輸出結果可以看出etree.HTML(text) 方法可以將字串決議成HTML檔案,也就是一個Element物件,etree.tostring(html) 可以將HTML檔案序列化成字串,序列化之后的結果是一個 bytes 物件,中文是不能正常顯示的,需要通過指定編碼方式為utf-8,并且呼叫decode()方法中文才能正常輸出,并且輸出的HTML是有格式的,即不是列印成一行,
利用lxml庫加載html檔案
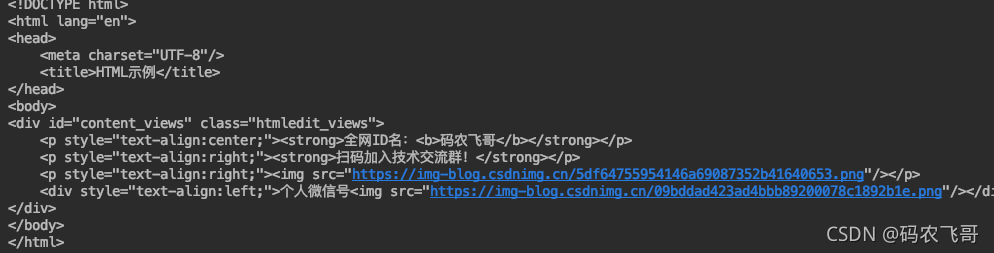
lxml庫不僅僅可以決議XML/HTML片段,還可以決議完整的HTML/XML檔案 ,下面創建了一個名為test.html檔案,然后通過 etree.parse方法進行決議,
<div id="content_views" class="htmledit_views">
<p style="text-align:center;"><strong>全網ID名:<b>碼農飛哥</b></strong></p>
<p style="text-align:right;"><strong>掃碼加入技術交流群!</strong></p>
<p style="text-align:right;"><img src="https://img-blog.csdnimg.cn/5df64755954146a69087352b41640653.png"/></p>
<div style="text-align:left;">個人微信號<img src="https://img-blog.csdnimg.cn/09bddad423ad4bbb89200078c1892b1e.png"/></div>
</div>
然后創建一個html_parse.py的檔案進行決議,需要注意的是該檔案跟test.html檔案在同一個目錄下,
# html_parse.py
from lxml import etree
#讀取外部檔案 test.html
html = etree.parse('./test.html')
result = etree.tostring(html, encoding='utf-8').decode()
print(result)
決議結果是:

可以看出如果被決議的HTML檔案是一個標準的HTML代碼片段的話則可以正常加載,因為這里parse方法默認使用的是XML的決議器,
但是當HTML檔案是一個標準的完整的HTML檔案則XML決議器是不能決議,現在將test.html 改下圖2的代碼,如果直接使用XML決議器決議就會報下面的錯誤,
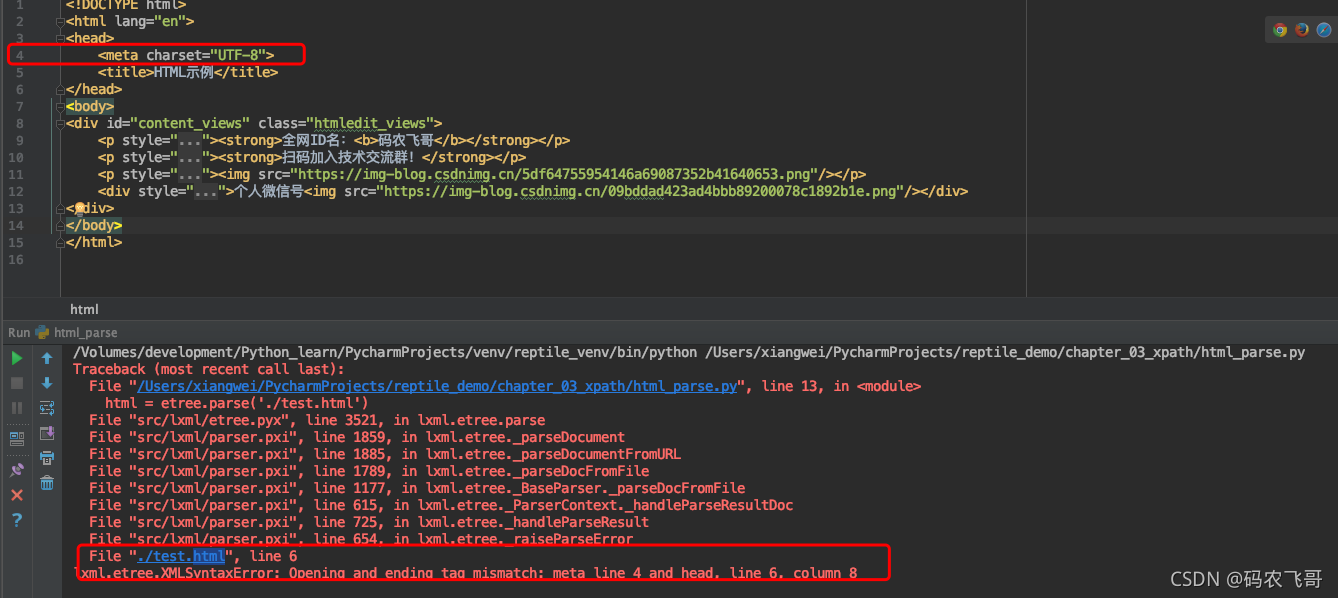
針對HTML檔案需要通過HTMLParser方法設定HTML決議器,然后在parse方法指定該決議器,就像下面代碼所示的一樣,
from lxml import etree
# 定義決議器
html_parser = etree.HTMLParser(encoding='utf-8')
# 讀取外部檔案 test.html
html = etree.parse('./test.html', parser=html_parser)
result = etree.tostring(html, encoding='utf-8').decode()
print(result)
運行結果是:
實戰開始
了解了lxml方法的基本使用之后,接下來我們就以碼農飛哥的博客 為例,這里我們的需求是爬取他博客下所有文章(暫不包括文章內容),然后將爬取的資料保存到本地txt檔案中,首先讓我們來看看他的博客長啥樣,涉及前面幾篇博客知識點這里不再詳細介紹了,這里重點介紹如何通過XPath來快速定位特定的元素和資料,
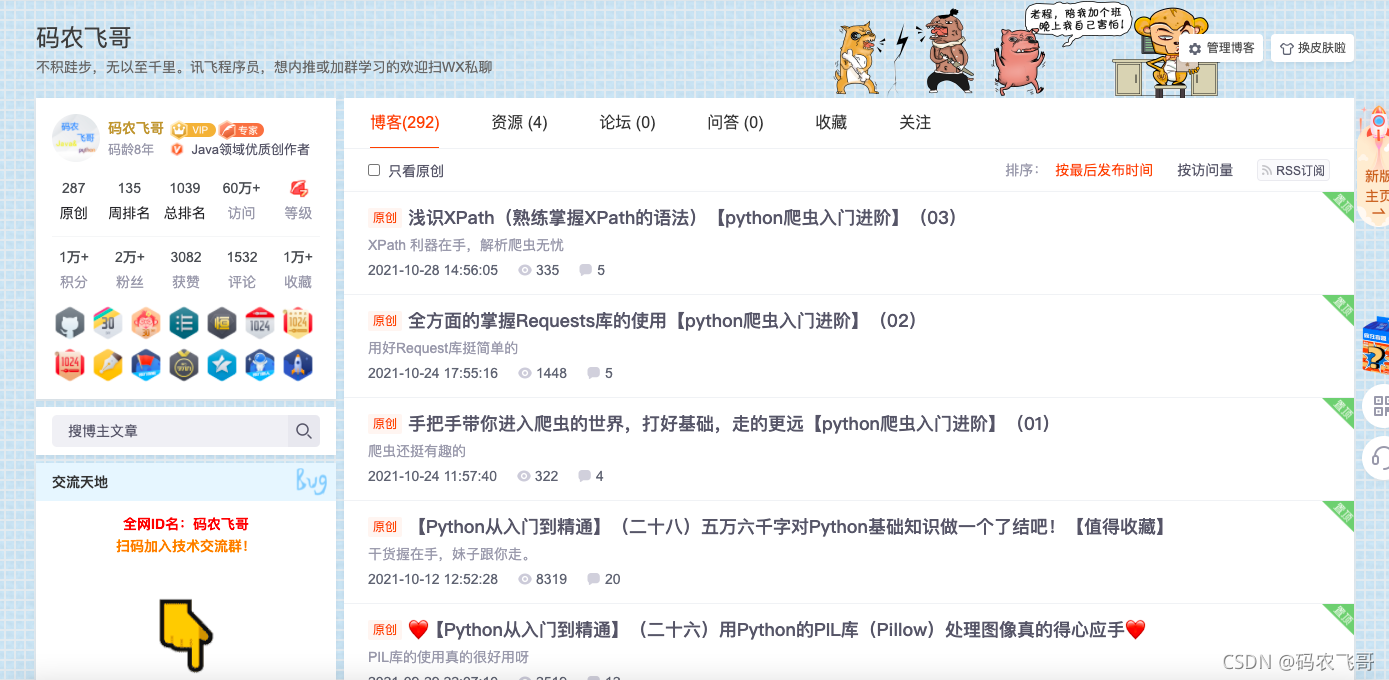
第一步: 獲得文章的分組
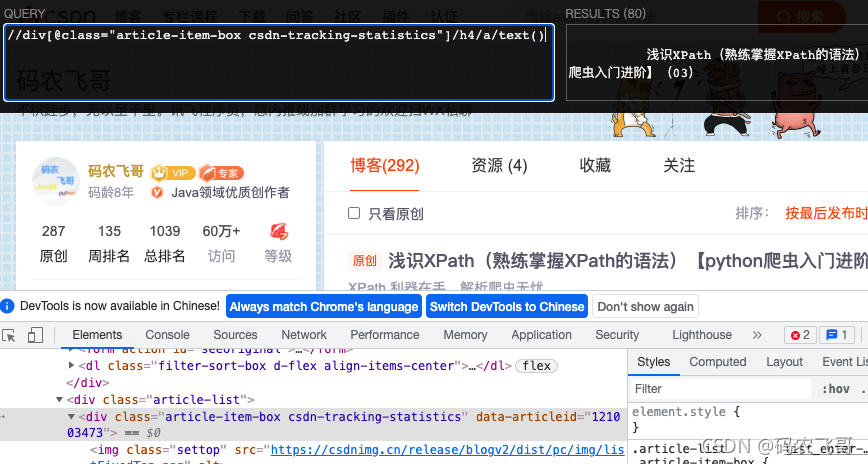
首先獲取文章的分組,還是使用萬能的XPath Helper, 通過F12調出除錯視窗,可以看出每個文章分組都是放在<div class="article-item-box csdn-tracking-statistics xh-highlight"></div> ,所以,通過 //div[@class="article-item-box csdn-tracking-statistics"] 運算式就可以獲取所有的文章分組,

代碼示例如下:
from lxml import etree
import requests
response = requests.get("https://feige.blog.csdn.net/", timeout=10) # 發送請求
html = response.content.decode()
html = etree.HTML(html) # 獲取文章分組
li_temp_list = html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
print(li_temp_list)
運行結果是:

這里通過html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]') 方法得到40個Element物件,這40個Element物件就是我們需要爬取的當前頁面的所有文章, 每個Element物件就是下面這樣的內容,

接下來通過result = etree.tostring(li_temp_list[0], encoding='utf-8').decode() 方法序列化Element物件,得到的結果是:
<div class="article-item-box csdn-tracking-statistics" data-articleid="121003473">
<img class="settop" src="https://csdnimg.cn/release/blogv2/dist/pc/img/listFixedTop.png" alt=""/>
<h4 class="">
<a href="https://feige.blog.csdn.net/article/details/121003473" data-report-click="{"spm":"1001.2014.3001.5190"}" target="_blank">
<span class="article-type type-1 float-none">原創</span>
淺識XPath(熟練掌握XPath的語法)【python爬蟲入門進階】(03)
</a>
</h4>
<p class="content">
XPath 利器在手,決議爬蟲無憂
</p>
<div class="info-box d-flex align-content-center">
<p>
<span class="date">2021-10-28 14:56:05</span>
<span class="read-num"><img src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png" alt=""/>335</span>
<span class="read-num"><img src="https://csdnimg.cn/release/blogv2/dist/pc/img/commentCountWhite.png" alt=""/>5</span>
</p>
</div>
</div>
第二步: 獲取文章的鏈接
從上面的代碼我們可以看出文章的鏈接在<a href="https://feige.blog.csdn.net/article/details/121003473"> 中,而a元素的父元素是h4元素,h4元素的父元素是 <div class="article-item-box csdn-tracking-statistics">元素,
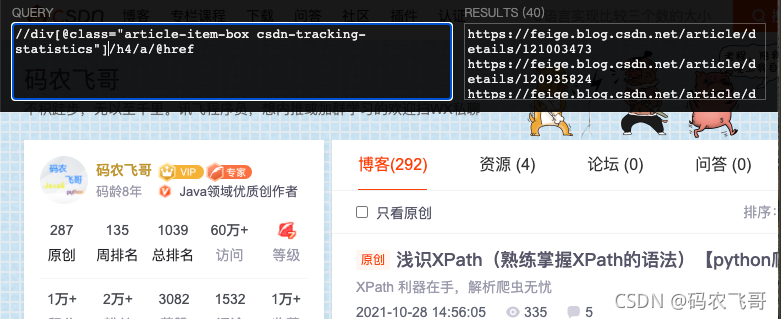
換成XPath的運算式就是//div[@class="article-item-box csdn-tracking-statistics"]/h4/a/@href ,即首先通過//div[@class="article-item-box csdn-tracking-statistics"] 選取所有的<div class="article-item-box csdn-tracking-statistics"> 然后通過/h4找到他的子元素h4,在通過/a找到h4的子元素a,最后就是通過/@href 找到鏈接內容,
不過第一步我們已經獲取到了<div class="article-item-box csdn-tracking-statistics"> 元素的Element物件,所以,這里就不需要在重復寫//div[@class="article-item-box csdn-tracking-statistics"]了,只需要通過. 代替,表示在當前目錄下找,參考代碼如下:
#省略第一步的代碼
href = li_temp_list[0].xpath('./h4/a/@href')[0]
print(href)
得到的結果是:https://feige.blog.csdn.net/article/details/121003473 ,需要注意的是.xpath方法回傳的是一個串列,所以需要提取其第一個元素
第三步:獲取標題內容
按斬訓取鏈接的思想,我們同樣可以獲取標題內容,標題的內容就直接在a標簽里,這里只需要多一步就是通過text()方法提取a標簽的內容,運算式就是//div[@class="article-item-box csdn-tracking-statistics"]/h4/a/text(),
參考代碼是:
title_list = li_temp_list[0].xpath('./h4/a/text()')
print(title_list)
print(title_list[1])
運行結果是:
['\n ', '\n 淺識XPath(熟練掌握XPath的語法)【python爬蟲入門進階】(03)\n ']
淺識XPath(熟練掌握XPath的語法)【python爬蟲入門進階】(03)
因為串列中的第一個元素是\n,所以需要獲取第二個元素,
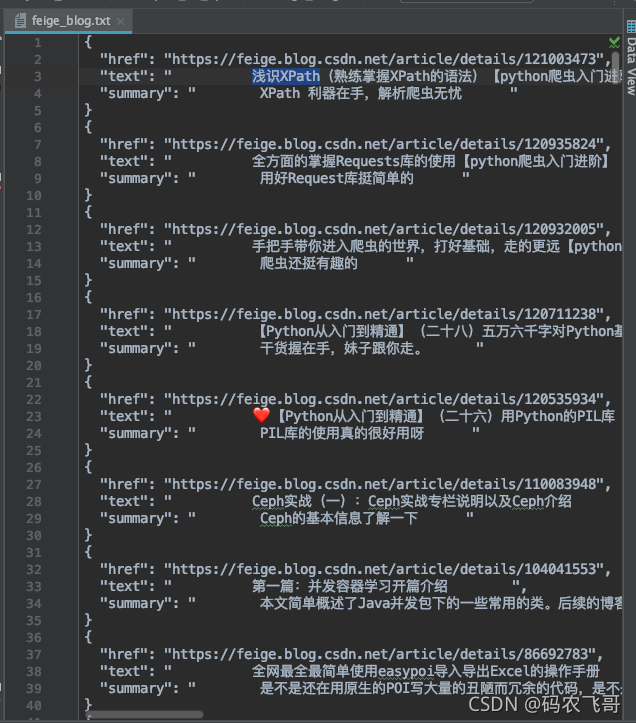
完整的參考代碼
import requests
from lxml import etree
import json
import os
class FeiGe:
# 初始化
def __init__(self, url, pages):
self.url = url
self.pages = pages
self.headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}
def get_total_url_list(self):
"""
獲取所有的urllist
:return:
"""
url_list = []
for i in range(self.pages):
url_list.append(self.url + "/article/list/" + str(i + 1) + "?t=1")
return url_list
def parse_url(self, url):
"""
一個發送請求,獲取回應,同時etree處理html
:param url:
:return:
"""
print('parsing url:', url)
response = requests.get(url, headers=self.headers, timeout=10) # 發送請求
html = response.content.decode()
html = etree.HTML(html)
return html
def get_title_href(self, url):
"""
獲取一個頁面的title和href
:param url:
:return:
"""
html = self.parse_url(url)
# 獲取文章分組
li_temp_list = html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
total_items = []
# 遍歷分組
for i in li_temp_list:
href = i.xpath('./h4/a/@href')[0] if len(i.xpath('./h4/a/@href')) > 0 else None
title = i.xpath('./h4/a/text()')[1] if len(i.xpath('./h4/a/text()')) > 0 else None
summary = i.xpath('./p')[0] if len(i.xpath('./p')) > 0 else None
# 放入字典
item = dict(href=href, text=title.replace('\n', ''), summary=summary.text.replace('\n', ''))
total_items.append(item)
return total_items
def save_item(self, item):
"""
保存一個item
:param item:
:return:
"""
with open('feige_blog.txt', 'a') as f:
f.write(json.dumps(item, ensure_ascii=False, indent=2))
f.write("\n")
def run(self):
# 找到url規律,url_list
url_list = self.get_total_url_list()
os.remove('feige_blog.txt')
for url in url_list:
# 遍歷url_list發送請求,獲得回應
total_item = self.get_title_href(url)
for item in total_item:
print(item)
self.save_item(item)
if __name__ == '__main__':
fei_ge = FeiGe("https://feige.blog.csdn.net/", 8)
fei_ge.run()
運行結果是:
該類主要分為幾大塊,
- 初始化方法
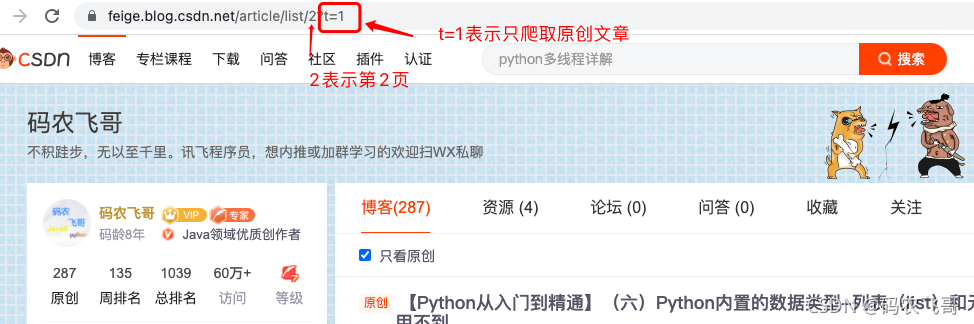
__init__(self, url, pages)主要設定需要爬取的博客的域名,以及博客的頁數,以及初始化請求頭, - 獲取所有頁數的鏈接的方法
get_total_url_list(self),這里需要注意的鏈接的規律,
parse_url(self, url)方法主要就是根據傳入的url獲得該url的html頁面,get_title_href(self, url)方法主要分為兩塊,第一塊就是呼叫parse_url(self, url) 方法得到鏈接對應的html頁面,第二塊就是決議HTML頁面以定位到我們需要的資料的元素,并將元素放在串列total_items中回傳,save_item(self, item)方法就是將第四步回傳的total_items中的資料保存到feige_blog.txt檔案中,run(self)方法是主入口,統籌呼叫各個方法,
總結
本文通過碼農飛哥演示了如何在實戰中使用XPath來爬取我們想要的資料,
粉絲專屬福利
軟考資料:實用軟考資料
面試題:5G 的Java高頻面試題
學習資料:50G的各類學習資料
脫單秘籍:回復【脫單】
并發編程:回復【并發編程】
👇🏻 驗證碼 可通過搜索下方 公眾號 獲取👇🏻
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/342224.html
標籤:python