本案例進行一下中場休息,給大家帶來一篇如何通過開發者工具定位介面的案例,
目標站點分析
在正式學習之前,首先要明確一點:目前各大視頻站點,例如 愛奇藝,優酷,芒果 TV,騰訊視頻,它們的視頻和評論內容都是存在著作權的,所以針對以上站點的任何采集,都屬于侵權行為哦~
本次爬蟲采集涉及的網站,全部進行了脫敏處理,原版文章建議從 【78 技術人社群~Python 分部】 尋找,
本次案例要采集的目標站點,你可以選擇任意平臺進行測驗,它們邏輯一致,本次目標資料為電視劇相關評論內容,
首先通過下拉發現評論的加載為異步加載,即通過服務器呼叫介面進行回傳,顧查找到對應介面是核心突破點,
但是當啟用開發者工具之后,發現頁面存在太多的請求,視頻加載,廣告加載,圖片加載非常多,導致評論的介面很難被檢測出,
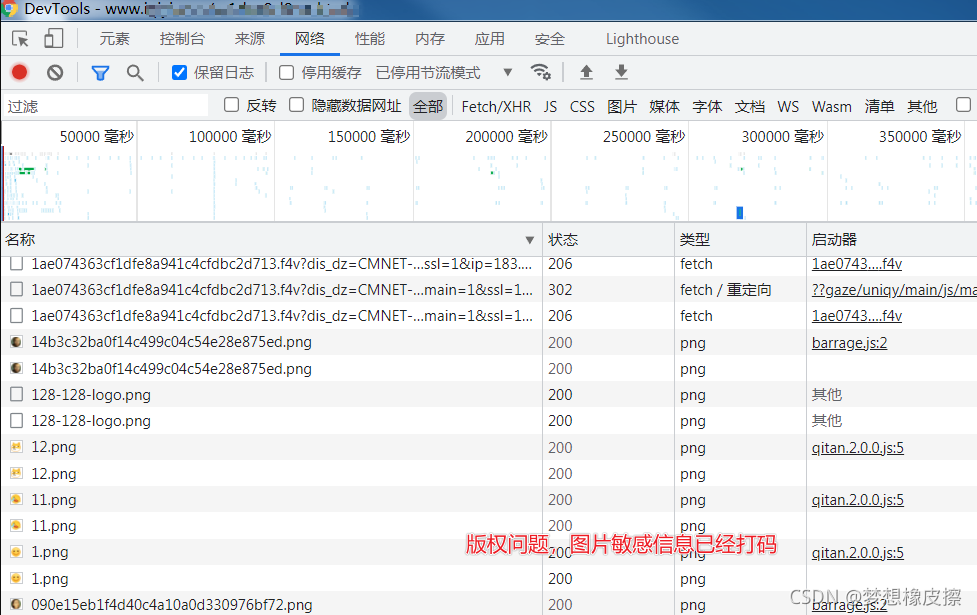
這里首先用到的第一個技巧是,通過某一評論內容,檢索介面可能出現的位置,
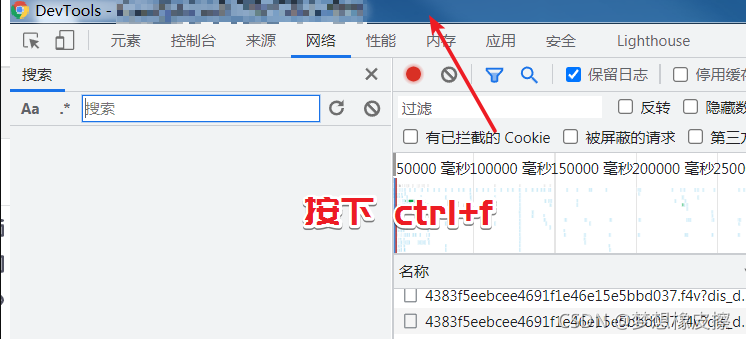
在開發者工具標題欄按下 Ctrl+F 鍵,喚醒搜索視窗,如下圖所示:
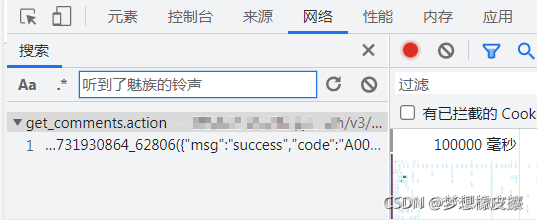
然后輸入任意評論內容,按下回車鍵,即可查找該資料存在的介面,如下圖所示:
雙擊目標介面,得到請求相關資料,然后切換到標頭,即 headers 部分,此時就得到了資料回傳介面,
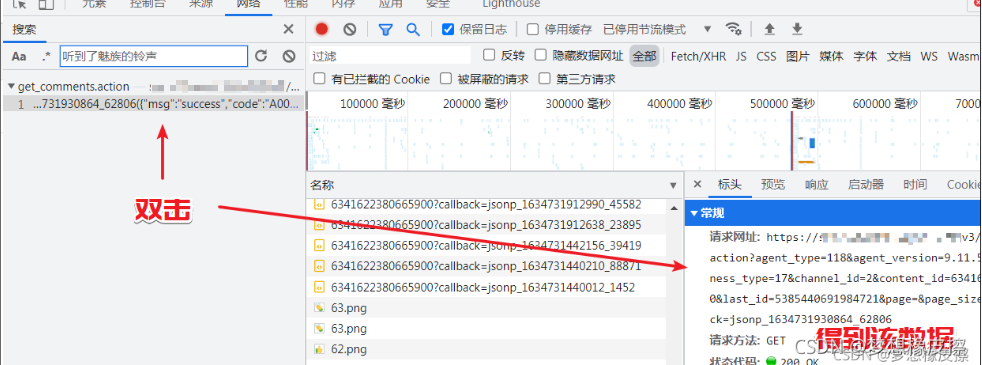
將得到的請求網址相關資訊,放置到請求過濾輸入框,然后頁面就可以對評論介面進行過濾了,
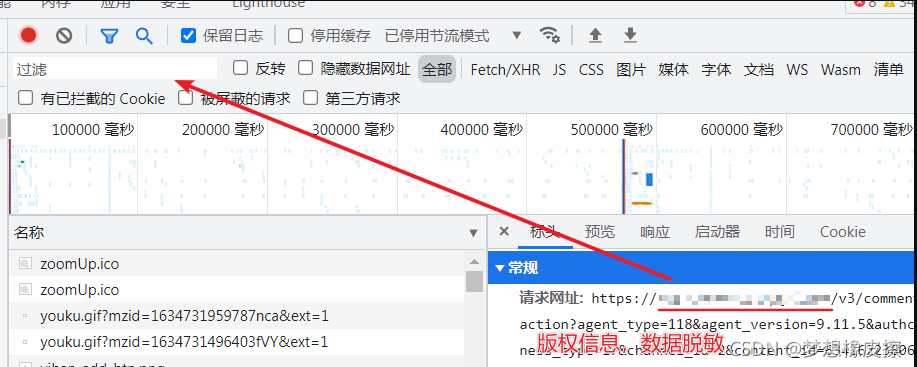
在接下來的動作是拆解介面引數,此處用到的基本技巧是猜+試(有一部分是經常撰寫爬蟲的經驗)
https://通過開發者工具,獲取到的網站域名/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=2&content_id=6341622380665900&hot_size=0&last_id=8268424748618621&page=&page_size=20&types=time&callback=jsonp_1634731681416_32977
https://通過開發者工具,獲取到的網站域名/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=2&content_id=6341622380665900&hot_size=0&last_id=5385440691984721&page=&page_size=20&types=time&callback=jsonp_1634731930864_62806
復制 2 個進行比對就可以,對比完成,在將得到的結論應用到第 3 個地址,
介面地址:https://通過開發者工具,獲取到的網站域名/v3/comment/get_comments.action
agent_type:未知,保持默認 118 ;agent_version:未知,保持默認 9.11.5 ;authcookie:未知,保持 null;business_type:未知,保持 17;channel_id:未知,保持 2;content_id:未知,保持 6341622380665900;hot_size:未知,保持 0;last_id:有變化,猜測與評論的 ID 有關;page:頁碼,沒有變化;page_size:每頁資料量,默認 20;types:未知,保持默認;callback:回到函式,用于 JS,(基于經驗的結論)
然后復制第 3 個請求地址,驗證結論,
https://通過開發者工具,獲取到的網站域名/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=2&content_id=6341622380665900&hot_size=0&last_id=5385440691984721&page=&page_size=20&types=time&callback=jsonp_1634731705450_53631
接下來的一步是嘗試去除部分引數,查看回傳資料是否有變化,
最后得到的精簡介面地址為:
https://通過開發者工具,獲取到的網站域名/v3/comment/get_comments.action?agent_type=118&business_type=17&content_id=6341622380665900&last_id=5385440691984721
這里如果你有撰寫爬蟲的經驗,可以知道
last_id引數是上一介面回傳的最后一條資料 ID
如果沒有相關經驗,依然使用開發者工具的檢索功能,查詢last_id值即可,
當 last_id 為空時資料回傳第一頁資料,
scrapy 采集電視劇相關評論
找到介面之后,使用 scrapy 采集就變得非常簡單了,代碼如下:
import json
import scrapy
class IqySpider(scrapy.Spider):
name = 'iqy'
allowed_domains = ['配置域名']
start_urls = [
'https://配置域名/v3/comment/get_comments.action?agent_type=118&business_type=17&content_id=6341622380665900&last_id=']
def parse(self, response):
html = response.body
json_data = json.loads(html)
yield json_data
if json_data is not None:
ret = json_data['data']
comments = ret['comments']
_id = comments[-1]['id']
next = self.start_urls[0] + str(_id)
# 下一介面
yield scrapy.Request(url=next)
else:
return None
請重點查看 parse 方法,首先回傳的是 json_data,即介面回傳資料的 JSON 物件,然后直接獲取最后一條資料的 ID,拼接成下一頁請求地址,從而實作回圈采集,
使用下述命令運行爬蟲程式:
scrapy crawl iqy -o comments.json -s CLOSESPIDER_ITEMCOUNT=10
-o comments.json:保存為 JSON 格式檔案;-s CLOSESPIDER_ITEMCOUNT=10:設定爬取多少個item之后關閉,
本次案例直接將介面請求回傳的原資料進行了保存,
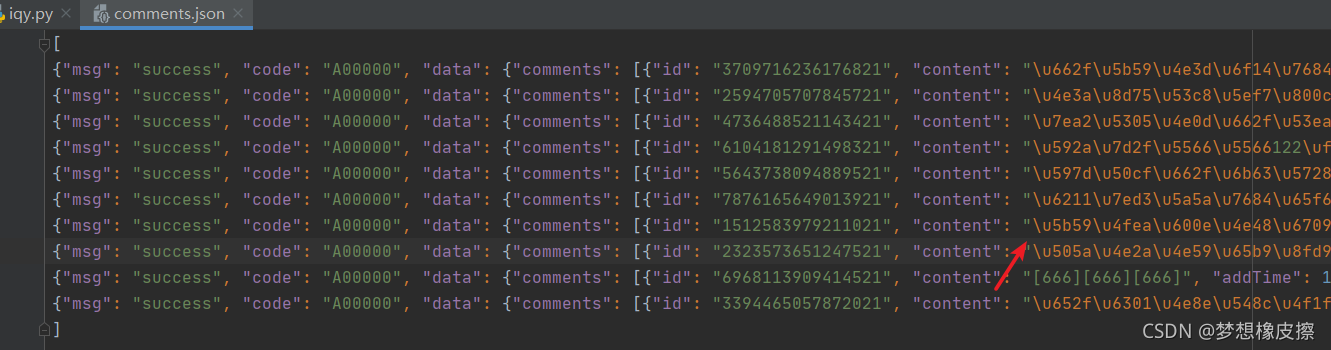
如果希望保存為 UTF-8 編碼,使用如下命令即可,
scrapy crawl iqy -o comments.json -s CLOSESPIDER_ITEMCOUNT=10 -s FEED_EXPORT_ENCODING=UTF-8
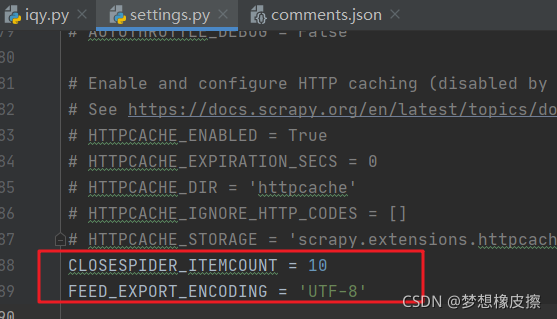
 如果不想在命令列撰寫,可以直接在
如果不想在命令列撰寫,可以直接在 settings.py 檔案中進行設定,
以上代碼就是本篇博客的全部內容啦,
寫在后面
今天是持續寫作的第 250 / 365 天,
期待 關注,點贊、評論、收藏,
更多精彩
《爬蟲 100 例,專欄銷售中,買完就能學會系列專欄》

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/344641.html
標籤:python
上一篇:maven編譯后復制到目標位置