我用Python爬蟲爬取并分析了C站前100用戶最高訪問的2000篇文章
- 寫在前面
- 專案總述
- 資料爬取
- 獲得服務器API
- 程式總體設計
- 用戶名爬取
- 文章爬取
- 資料分析
- 資料存盤
- 總體資料可視化
- 資料分組
- 完整代碼
寫在前面
最近系統地學習了正則運算式,發現正則運算式最大的應用之一——網路爬蟲之前一直沒有涉獵,遂借此貧訓順帶寫一個爬蟲的demo備用,選擇物件是CSDN排行榜前100用戶,各自按訪問量從高到低排序的前20篇文章,使用一些簡單的資料分析手段看看技術熱點,方便今后拓寬技術堆疊,
專案總述
主要爬取的資料是文章標題和訪問量,先總體可視化總體文章的技術關鍵詞;然后按訪問量分組,可視化每個訪問段的技術熱點,
資料爬取
獲得服務器API
首先我們要知道通過什么介面可以獲得網站資料:首先進入博客總榜,按F12進入控制臺,選中Network選項卡監視網路請求,然后重繪網頁,從下圖可以看到在API"https://blog.csdn.net/phoenix/web/blog/all-rank?page=1&pageSize=20"中我們可以拿到我們想要的用戶資訊——主要是用戶名
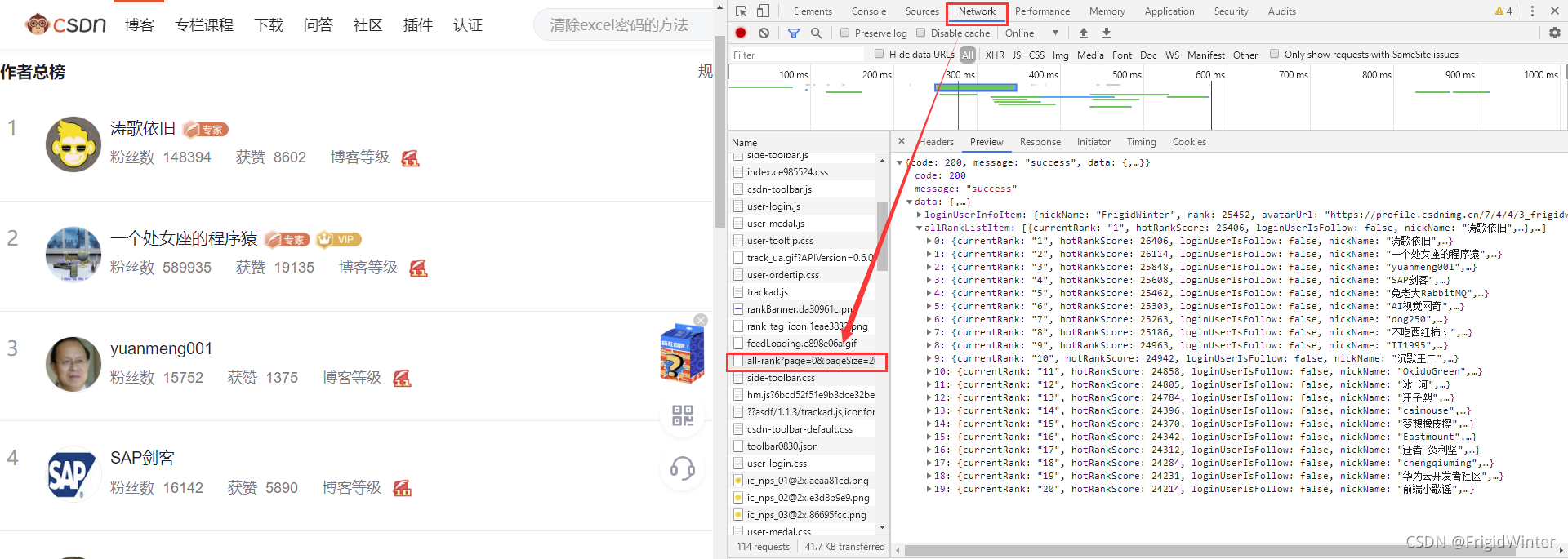
現在到用戶博客首頁,同樣地,按F12進入控制臺,選中Network選項卡監視網路請求,然后點擊按訪問量排序,則可以發現另一個關鍵APIhttps://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={},如下圖所示,
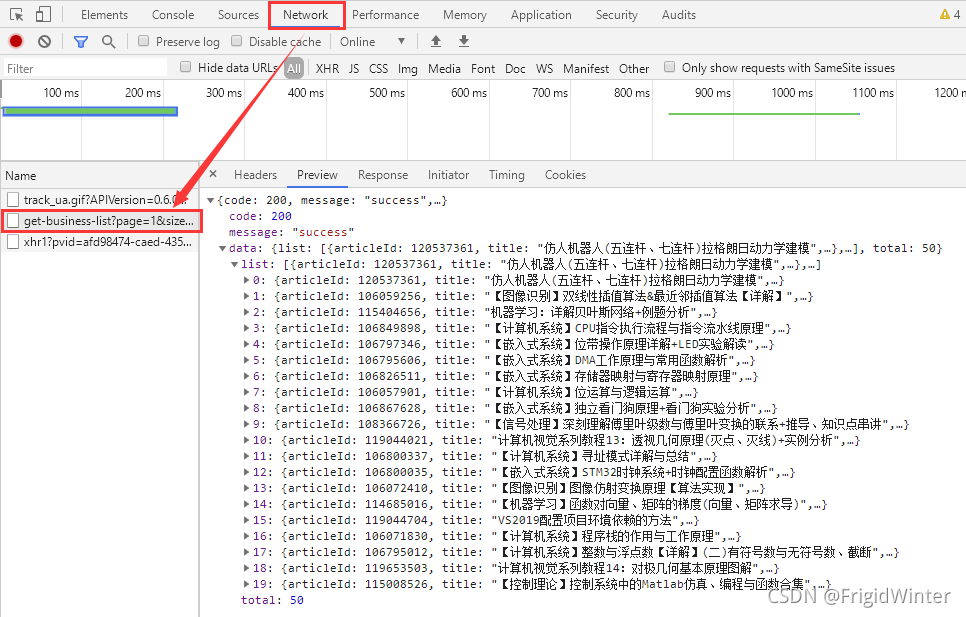
我們與服務器的互動就依靠這兩個API進行,
程式總體設計
思考一下,我們總共有如下的公共變數:
# 請求頭
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按訪問量排行的文章串列
mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
userNames =[] # 用戶名串列
titleList = [] # 文章標題串列
viewCntList = [] # 訪問量串列
為便于管理,引入一個類進行爬蟲,專門負責與服務器進行資料互動
class GetInfo:
def __init__(self) -> None:
# 請求頭
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
self.rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按訪問量排行的文章串列
self.mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
self.userNames = []
self.titleList, self.viewCntList = [], []
互動完成后,再使用別的庫進行資料分析,將兩個程序分離開
用戶名爬取
定義一個私有的初始化函式
def __initRankUsrName(self):
usrNameList = []
for i in range(5):
response = requests.get(url=self.rankUrl.format(i),
headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
information = json.loads(str(soup))
for item in information['data']['allRankListItem']:
usrNameList.append(item['userName'])
return usrNameList
這里獲取用戶名主要是為了動態生成第二個API
文章爬取
再定義一個私有函式,輸入引數是用戶名串列:
def __initArticalInfo(self, usrList):
titleList = []
viewCntList = []
for name in usrList:
url = self.mostViewArtical.format(name)
# print(url)
response = requests.get(url=url, headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
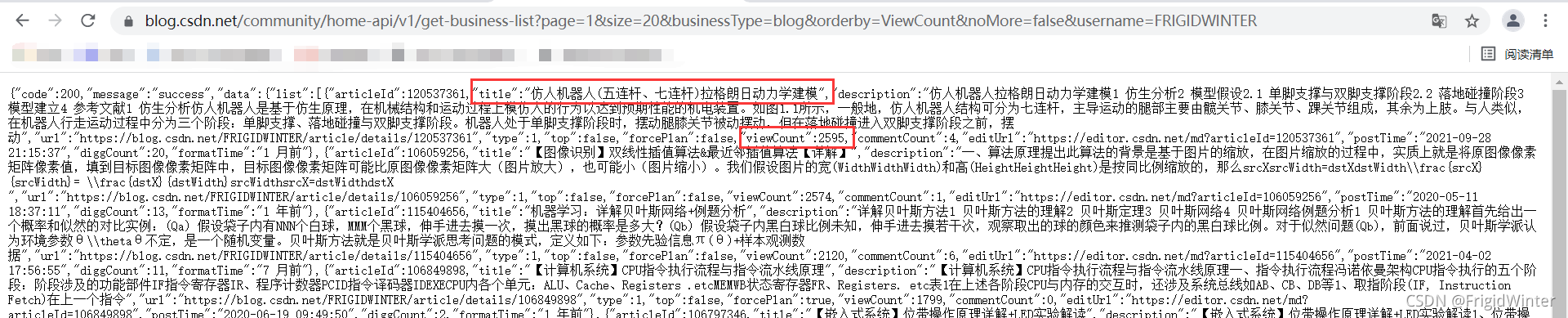
titleList.extend(re.findall(r"\"title\":\"(.*?)\"", response.text))
viewCntList.extend(re.findall(r"\"viewCount\":(.*?),", response.text))
return titleList, viewCntList
這里我使用正則運算式直接處理字串,并回傳文章標題串列、訪問量串列,可以隨便訪問一個API做實驗,這里以我的用戶名為例,可以看到要獲取文章標題就是以\"title\":\"(.*?)\"去匹配,其中\用于轉義;要獲取訪問量就是以\"viewCount\":(.*?),去匹配,訪問數字沒有加引號,
事實上,用正則匹配不需要將回傳的字串加載為Json字典,可能有更快的處理效率(但不如json靈活)
這個爬蟲類就設計好了,完整代碼如下:
class GetInfo:
def __init__(self) -> None:
# 請求頭
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
self.rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按訪問量排行的文章串列
self.mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
self.userNames = self.__initRankUsrName()
self.titleList, self.viewCntList = self.__initArticalInfo(
self.userNames)
def __initArticalInfo(self, usrList):
titleList = []
viewCntList = []
for name in usrList:
url = self.mostViewArtical.format(name)
# print(url)
response = requests.get(url=url, headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
titleList.extend(re.findall(r"\"title\":\"(.*?)\"", response.text))
viewCntList.extend(
re.findall(r"\"viewCount\":(.*?),", response.text))
return titleList, viewCntList
def __initRankUsrName(self):
usrNameList = []
for i in range(5):
response = requests.get(url=self.rankUrl.format(i),
headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
information = json.loads(str(soup))
for item in information['data']['allRankListItem']:
usrNameList.append(item['userName'])
return usrNameList
info = GetInfo()
使用也很方便,只需要實體化呼叫其中的串列屬性即可,
資料分析
資料存盤
將文本資料存成csv格式,先設計表頭:
if not os.path.exists("articalInfo.csv"):
#創建存盤csv檔案存盤資料
with open('articalInfo.csv', "w", encoding="utf-8-sig", newline='') as f:
csv_head = csv.writer(f)
csv_head.writerow(['title', 'viewCnt'])
注意編碼格式為utf-8-sig,否則會亂碼
接下來存資料:
length = len(info.titleList)
for i in range(length):
if info.titleList[i]:
with open('articalInfo.csv', 'a+', encoding='utf-8-sig') as f:
f.write(info.titleList[i] + ',' + info.viewCntList[i] + '\n')
總體資料可視化
新建一個模塊專門用于可視化資料,與爬蟲分離開,因為爬蟲是慢IO程序,會影響除錯效率,后面可以試試用協程來處理爬蟲,
首先,把爬蟲的資訊讀取到txt檔案去
df = pd.read_csv('articalInfoNor.csv', encoding='utf-8-sig',usecols=['title', 'viewCnt'])
titleList = ','.join(df['title'].values)
with open('text.txt','a+', encoding='utf-8-sig') as f:
f.writelines(titleList)
如何回傳分詞結果:
def getKeyWordText():
# 讀取檔案資訊
file = open(path.join(path.dirname(__file__), 'text.txt'), encoding='utf-8-sig').read()
return ' '.join(jieba.cut(file))
借助詞云庫可視化一下:
bg_pic = imread('2.jpg')
#生成詞云
wordcloud = WordCloud(font_path=r'C:\Windows\Fonts\simsun.ttc',mask=bg_pic,background_color='white',scale=1.5).generate(text)
image_colors = ImageColorGenerator(bg_pic)
#顯示詞云圖片
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
#保存圖片
wordcloud.to_file('test.jpg')

這個大大的“的”是什么鬼?顯然高頻關鍵詞里有太多語氣助詞、連接詞,我們最好設定一個停用詞串列把這些明顯不需要的詞屏蔽掉,我這里采用修飾器的方法讓代碼更簡潔,關于修飾器的內容可以參考Python修飾器
def splitText(mode):
stopWords = ["的","與","和","建議","收藏","使用","了","實作","我","中","你","在","之","年","月","日"]
def warpper(func):
def warp():
textSplit = func()
if mode:
temp = [word for word in textSplit if word not in stopWords]
return ' '.join(temp)
else:
return ' '.join(textSplit)
return warp
return warpper
當mode=True時啟用屏蔽,否則關閉屏蔽,那么之前的函式應該修改為:
# 回傳關鍵詞文本
@splitText(False)
def getKeyWordText():
# 讀取檔案資訊
file = open(path.join(path.dirname(__file__), 'text.txt'), encoding='utf-8-sig').read()
return jieba.cut(file)
再來一次:

現在就正常多了,可以看到Python和Java是絕對的領先,之后是各位總結的方法論等等,演算法的詞頻反而不高?
資料分組
我把資料進一步分層為
1、訪問量>10W
2、訪問量5W~10W
3、訪問量1W~5W
4、訪問量5K~1W
5、訪問量5K以下
先來看看資料分布情況:
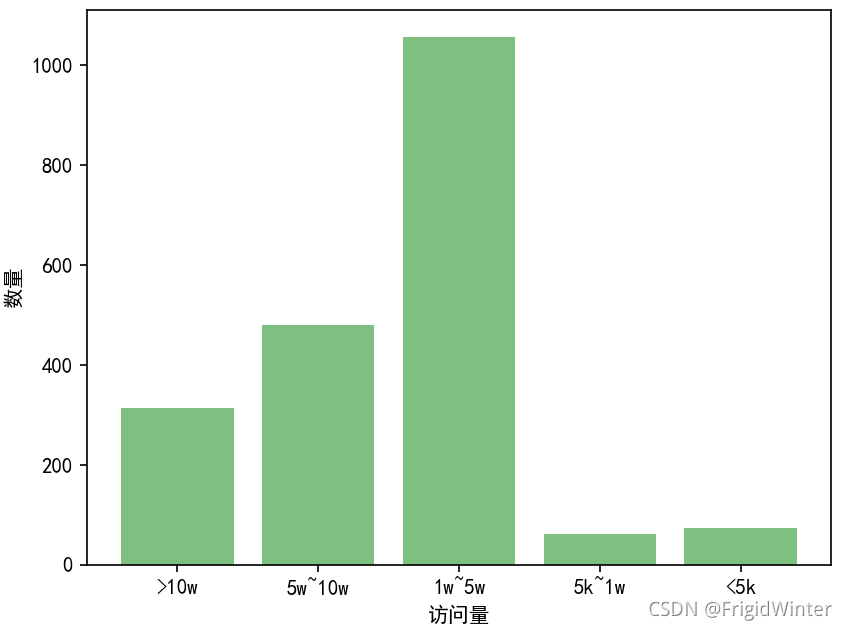
我猜如果分段分得再細一點可能趨于正態分布~
分組可視化看看:




感覺從這里開始更百花齊放一些,似乎也更關注具體問題的解決

不得不感嘆python在每個階段都是牌面
完整代碼
import requests
from bs4 import BeautifulSoup
import os, json, re, csv
class GetInfo:
def __init__(self) -> None:
# 請求頭
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
self.rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按訪問量排行的文章串列
self.mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
self.userNames = self.__initRankUsrName()
self.titleList, self.viewCntList = self.__initArticalInfo(
self.userNames)
def __initArticalInfo(self, usrList):
titleList = []
viewCntList = []
for name in usrList:
url = self.mostViewArtical.format(name)
# print(url)
response = requests.get(url=url, headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
titleList.extend(re.findall(r"\"title\":\"(.*?)\"", response.text))
viewCntList.extend(
re.findall(r"\"viewCount\":(.*?),", response.text))
return titleList, viewCntList
def __initRankUsrName(self):
usrNameList = []
for i in range(5):
response = requests.get(url=self.rankUrl.format(i),
headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
information = json.loads(str(soup))
for item in information['data']['allRankListItem']:
usrNameList.append(item['userName'])
return usrNameList
info = GetInfo()
if not os.path.exists("articalInfo.csv"):
#創建存盤csv檔案存盤資料
with open('articalInfo.csv', "w", encoding="utf-8-sig", newline='') as f:
csv_head = csv.writer(f)
csv_head.writerow(['title', 'viewCnt'])
length = len(info.titleList)
for i in range(length):
if info.titleList[i]:
with open('articalInfo.csv', 'a+', encoding='utf-8-sig') as f:
f.write(info.titleList[i] + ',' + info.viewCntList[i] + '\n')
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
from imageio import imread
import jieba
import pandas as pd
from os import path
df = pd.read_csv('articalInfoCom.csv', encoding='utf-8-sig',usecols=['title', 'viewCnt'])
titleList = ','.join(df['title'].values)
with open('text.txt','a+', encoding='utf-8-sig') as f:
f.writelines(titleList)
def splitText(mode):
stopWords = ["的","與","和","建議","收藏","使用","了","實作","我","中","你","在","之","年","月","日"]
def warpper(func):
def warp():
textSplit = func()
if mode:
temp = [word for word in textSplit if word not in stopWords]
return ' '.join(temp)
else:
return ' '.join(textSplit)
return warp
return warpper
# 回傳關鍵詞文本
@splitText(True)
def getKeyWordText():
# 讀取檔案資訊
file = open(path.join(path.dirname(__file__), 'text.txt'), encoding='utf-8-sig').read()
return jieba.cut(file)
text = getKeyWordText()
#讀取txt檔案、背景圖片
bg_pic = imread('2.jpg')
#生成詞云
wordcloud = WordCloud(font_path=r'C:\Windows\Fonts\simsun.ttc',mask=bg_pic,background_color='white',scale=1.5).generate(text)
image_colors = ImageColorGenerator(bg_pic)
#顯示詞云圖片
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
#保存圖片
wordcloud.to_file('test.jpg')
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/345752.html
標籤:python
上一篇:【Unity使用UGUI實作王者榮耀UI界面(二)】加載頁面-靜音按鈕和頁面完善
下一篇:Python解決TypeError, ValueError, KeyError, Unicode Encode Error報錯