背景介紹
Cobar簡介
Cobar 是阿里開源的一款資料庫中間件產品,
在業務高速增長的情況下,資料庫往往成為整個業務系統的瓶頸,資料庫中間件的出現就是為了解決資料庫瓶頸而產生的一種中間層產品,
在軟體工程中,沒有什么問題是加一層中間層解決不了的,如果有,再加一層,
一款proxy型別(本文不討論client SDK型別的資料庫中間件)的資料庫中間件具備以下能力:
- 支持資料庫的透明代理,做到用戶無感知
- 能夠水平、垂直拆分資料庫和表,橫向擴展資料庫的容量和性能
- 讀和寫的分離,降低主庫壓力
- 復用資料庫連接,降低資料庫的連接消耗
- 能夠檢測資料庫集群的各種故障,做到快速failover
- 足夠穩定可靠,性能足夠好
而本文的主角Cobar除了讀寫分離外其他特性都支持的很好,而且基于Cobar開發讀寫分離的特性并不是一件很難的事,
SQL審計
筆者有幸也曾在公司內的Cobar上做過定制開發,開發的功能是SQL審計,
從資料庫產品的運營角度看,統計分析執行過的SQL是一個必要的功能;從安全角度看,資訊泄露、例外SQL也需要被審計,
SQl審計需要審計哪些資訊?通過調研,大致確定要采集執行的SQL、執行時間、來源host、回傳行數等幾個維度,
SQL審計的需求很簡單,但就算是一個很簡單的需求放在資料庫中間件的高并發、低延遲,單機QPS可達幾萬到十幾萬的場景下都需要謹慎考慮,嚴格測驗,
舉個例子,獲取作業系統時間,在Java中直接呼叫 System.currentTimeMillis(); 就可以,但在Cobar中如果這么獲取時間,就會導致性能損耗非常嚴重(怎么解決?去Cobar的github倉庫上看看代碼吧),
技術方案
大方向
經調研,SQL審計實作的方向大致有兩種
- 一種是比較容易想到的直接修改Cobar代碼,在需要收集資訊的地方埋點
- 另一種是阿里云資料庫提供的方案,通過抓取資料庫的通信流量進行分析,
考慮到技術的復雜度,我們選擇了較為簡單的第一種實作方式,
SQL審計在Cobar中屬于“錦上添花”的需求,不能因為這個功能導致Cobar性能下降,更不能導致Cobar不可用,所以必須遵循以下兩點:
- 性能盡可能接近無SQL審計版本
- 無論如何不能造成Cobar不可用
對于性能的損耗,沒有度量就沒法優化,于是使用sysbench(一種資料庫基準測驗工具)來對現在版本的Cobar進行壓測,
Cobar部署在4C8G的機器上,mysql部署在性能足夠好的物理機上,壓出了5.5w/s的基準,后續的版本都和這個數值進行比對,
由于采取了侵入Cobar代碼的方式,想對Cobar造成影響最小,就需要保持代碼最小的修改,于是采取了agent的方案,
這樣可以保持代碼的最小修改,只需要打點采集并傳輸給agent,向遠端傳輸審計資訊的邏輯就只需要在agent中處理即可,向遠端傳輸資訊幾乎在一開始就確定了用kafka,這樣也能保持Cobar不引入新的第三方依賴,保持代碼的干凈(要知道Cobar的第三方依賴只有log4j),讓kafka和Cobar保持在兩個JVM中,更是一種隔離,于是有了下圖的架構初稿
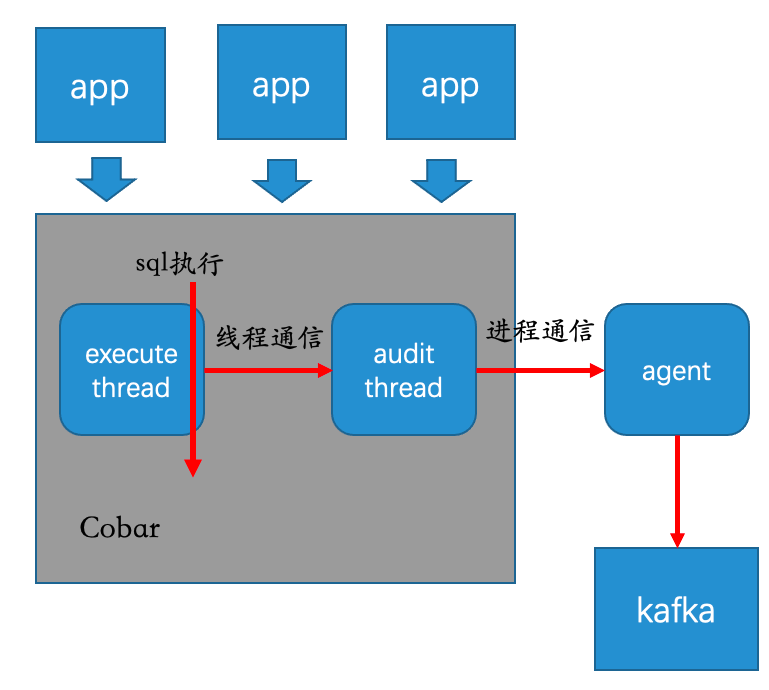
通過上圖梳理出了兩個關鍵技術點:執行緒通信和行程通信,
行程通信容易理解,為什么這里還涉及執行緒通信?
首先Cobar的execute執行緒是執行SQL的主執行緒,如果在這個執行緒中去進行行程通信,那性能肯定被消耗的體無完膚,于是只能丟給審計執行緒去做,這樣對Cobar的性能影響最小,
行程間通信
先說行程間的通信,這塊稍微簡單點,我們只需要羅列出可用的行程間通信方式,然后對比優缺點,選擇一個合適的使用即可
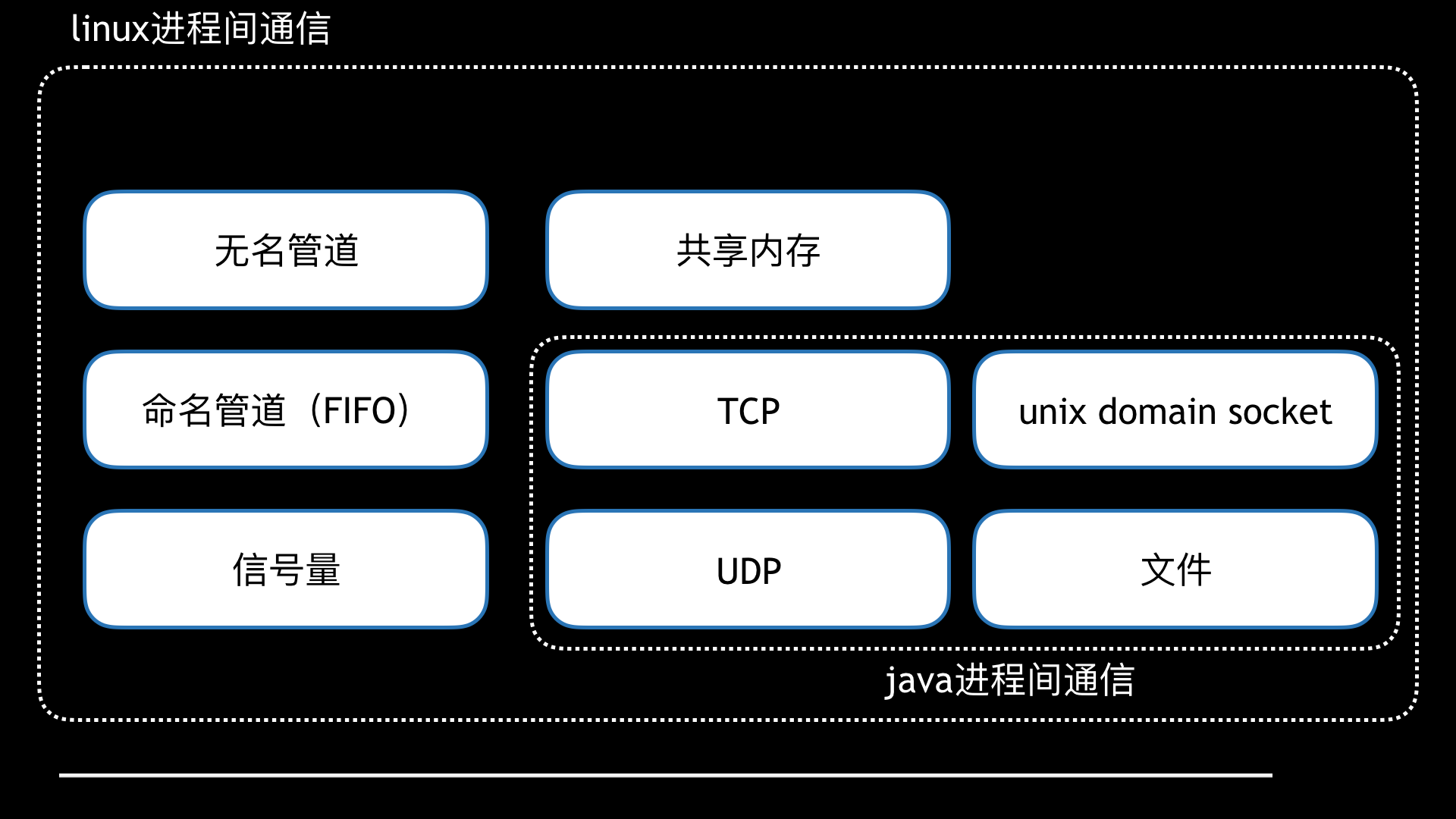
首先Cobar是Java撰寫,于是我們框定了范圍:TCP、UDP、UnixDomainSocket、檔案,
經過調研,UnixDomainSocket與平臺相關性太強,且沒有官方的實作,只有第三方的實作(如junixsocket),測驗下來,不同linux的版本支持都不一致,所以這里直接排除,
寫檔案會導致高IO,甚至有寫滿磁盤的風險,畢竟在如此高的并發之下,遂排除,
最終在TCP和UDP中選擇,考慮性能UDP比TCP好,且TCP還得自己解決粘包問題,于是我們選擇了UDP,其實想想,SQL審計需求類似日志收集、metric上報,許多日志收集、metric上報都是采取UDP的方式,
執行緒間通信
如果說行程間通信拍拍腦袋就能決定,是因為他并不直接影響Cobar,他是審計執行緒與agent行程間的通信,然而執行緒間的通信則直接決定了對Cobar的性能影響,必須謹慎,
執行緒間通信必須通過一個中間的緩沖buffer來中轉,我們對這個buffer有如下要求
- 有界,無界就可能會導致記憶體溢位
- 投遞不能阻塞,阻塞會導致夯住主執行緒,極大影響Cobar性能
- 可以無序,為了保證Cobar可用性,甚至可以在極端情況下丟失一些資料
- 執行緒安全,高并發下如果執行緒不安全,資料就會錯亂
- 高性能
Java內置佇列
Java中內置的佇列可以充當這個buffer
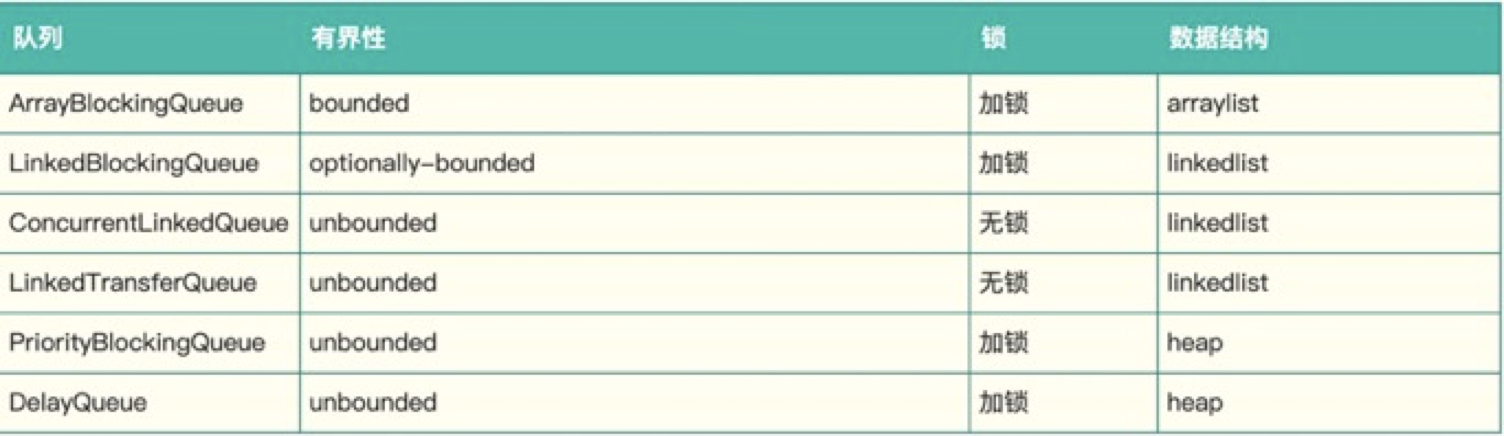
有界的只有ArrayBlockingQueue和LinkedBlockingQueue,然而他們都是加鎖的,直覺告訴我,他的性能不會太好,
想到Java中CurrentHashMap和LongAdder都是通過分段來解決鎖沖突的,于是打算使用多個ArrayBlockingQueue來構造這個buffer
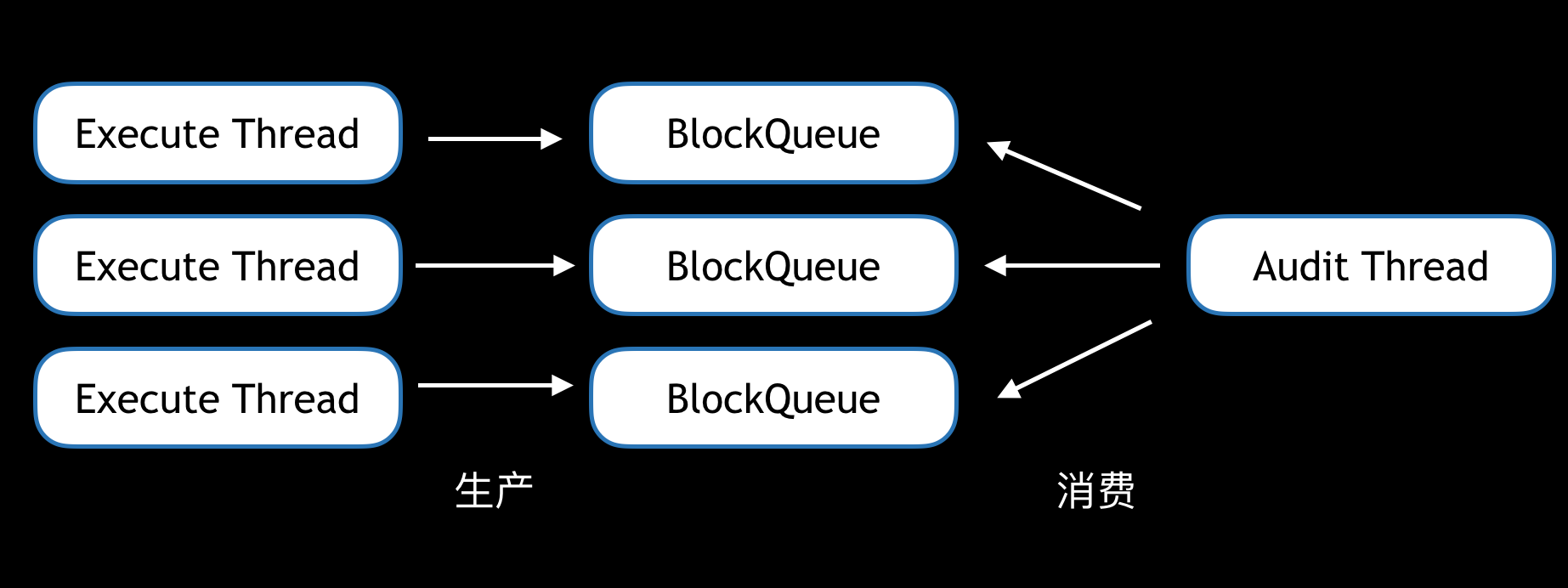
實測下來,只達到了4.7w/s,性能損失約10%
Disruptor
Java內置的佇列屬于有鎖佇列,那么有沒有不加鎖且有界的佇列呢?搜索后發現了一款開源的無鎖佇列實作Disruptor,大量的產品如Log4j2等都使用了Disruptor,它是一種環形的資料結構,使用了Java中的CAS代替了鎖,且有許多細節上的性能優化,導致他的性能非常強悍,
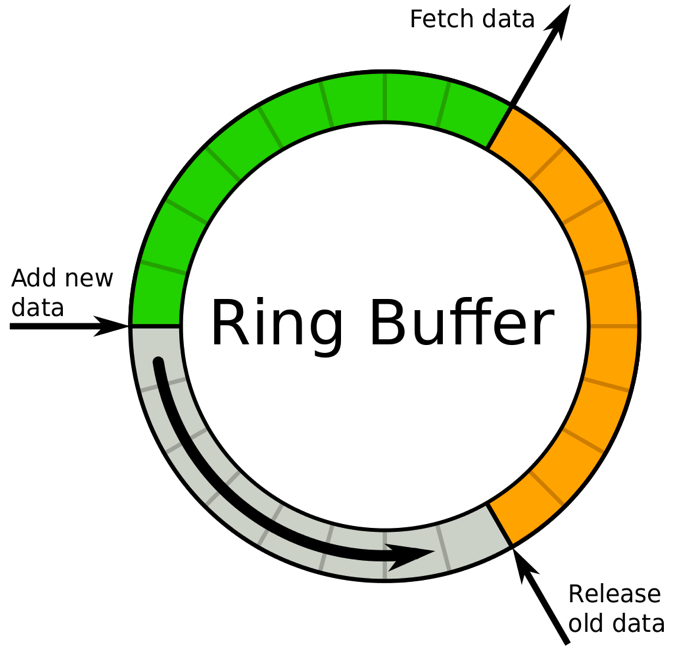
但很可惜的是,在測驗時發現當Disruptor的buffer寫滿之后,再寫就會阻塞,這和我們的需求不符合,如果主執行緒發生阻塞將是災難性的,于是放棄,
SkyWalking的RingBuffer
剛好當時組內同學在研究SkyWalking,SkyWalking是一款開源的應用性能監控系統,包括指標監控,分布式追蹤,分布式系統性能診斷,
他的原理是利用Java的位元組碼修改技術在呼叫處插入埋點,采集資訊上報,和Cobar的采集上報程序類似,
那么他的RingBuffer是如何實作的呢?其實非常簡單,緩沖區就是一個陣列,每次投遞時獲取一個沒有寫入資料的陣列下標即可,在多執行緒下只要保證獲取的下標不會被兩個執行緒同時獲取即可,資料的寫入速度快慢就看這個下標獲取是否高效即可,如下圖:
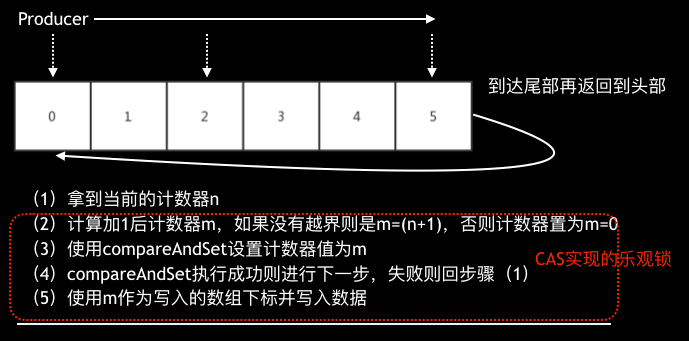
獲取陣列下標和Disruptor類似也是使用了CAS,但他實作非常簡單,甚至有點粗糙,但他可以在寫滿時選擇是阻塞、覆寫或是忽略,我們選擇覆寫這個策略,在極端情況下丟掉老資料來換取Cobar的可用性,我們測驗了一下使用多個SkyWalking的RingBuffer的場景,結果只有3w/s,損失45%性能,
于是我們對這個Ringbuffer進行了一些優化
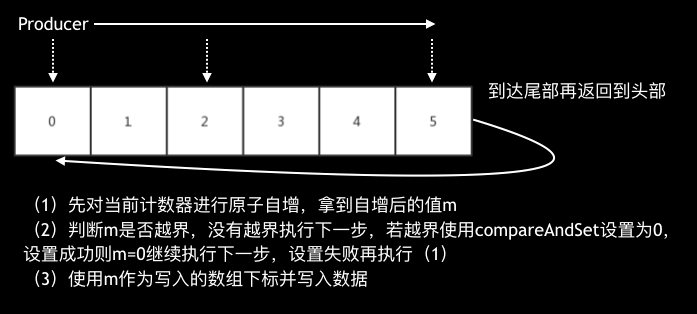
這個優化主要是將CAS換成incrementAndGet,這樣就能利用到JDK8對incrementAndGet的優化,在JDK8之前,incrementAndGet底層也是CAS,但在JDK8之后,incrementAndGet使用了fetch-and-add(CPU指令),性能要強勁很多,這塊具體的介紹和代碼可以參考《一種極致性能的緩沖佇列》,
除了這個主要的優化外,還參考Disruptor進行對SkyWalking進行了快取行填充優化,最后達到了5.4w/s,性能損失僅僅1.8%,非常給力,于是使用了這個版本的Ringbuffer作為Cobar SQL審計的快取區,
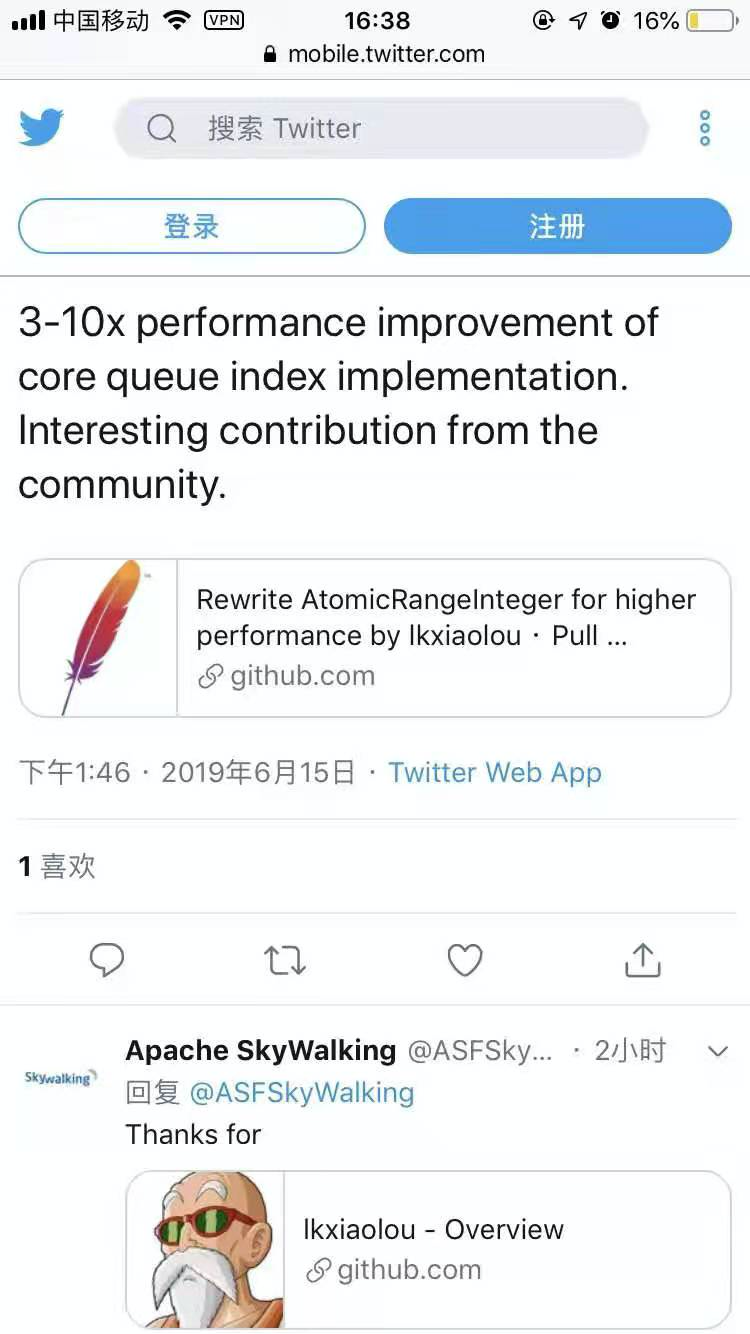
優化后的Ringbuffer也回饋給了SkyWalking社區,SkyWalking作者贊賞這是一個“intersting contribution”,
總結
Cobar的SQL審計在上線后穩定支撐了公司所有Cobar集群,是承載最高QPS的系統之一,
回頭來看對性能的極致追求可能或許過于"偏執",創造的收益在旁人眼里看來并沒有那么大,加一臺機器就能搞定的事情非要搞這么復雜,但這份“偏執”卻是我們對技術最初的追求,生活不止眼前的茍且,還有詩和遠方,
關于作者:專注后端的中間件開發,公眾號"捉蟲大師"作者,關注我,給你最純粹的技術干貨

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/348155.html
標籤:Java
上一篇:多賬號統一登陸,怎么實作?