序言:保存資料的方式各種各樣,最簡單的方式是直接保存為文本檔案,如TXT、JSON、CSV等,除此之外Excel也是現在比較流行的存盤格式,通過這篇文章你也將掌握通過一些第三方庫(xlrd/xlwt/pandas/openpyxl)去操作Excel進行資料存盤與讀取,此一文足以!
一、TXT文本存盤
1.1 使用方式
TXT文本幾乎兼容任何平臺,但是不利于檢索,如果對檢索和資料結構要求不高,尋求方便的話,可以采用TXT文本存盤格式
1.2 基本寫法
1 file = open('demo.txt','a',encoding='utf-8') 2 file.write(data) 3 file.close()
open()方法第一個引數表示要保存的目標檔案名稱,也可指定絕對路徑,第二個引數a表示以追加的方式寫入到文本,這樣前面寫入的內容就不會被覆寫,在爬蟲中一般使用的都是這種追加的方式,第三個引數指定檔案的編碼為utf-8,接著寫入資料,最后用close()方法來關閉檔案
1.3 打開方式
上面的引數a表示每次寫入文本時不會清空之前寫入的資料,而是在文本末尾寫入新的資料,這是一種打開方式,還有其他打開檔案的方式:
| r | 以只讀方式打開檔案 |
| rb | 以二進制只讀方式打開一個檔案 |
| r+ | 以讀寫方式打開一個檔案 |
| rb+ | 以二進制讀寫方式打開一個檔案 |
| w | 以寫入方式打開檔案 |
| wb | 以二進制寫入方式打開一個檔案 |
| w+ | 以讀寫方式打開一個檔案 |
| wb+ | 以二進制讀寫方式打開一個檔案 |
| a | 以追加方式打開一個檔案 |
| ab | 以二進制追加方式打開一個檔案 |
| a+ | 以讀寫方式打開一個檔案 |
| ab+ | 以二進制追加方式打開一個檔案 |
上面的b表示二進制,+表示以讀寫方式,r表示讀,w表示寫
1.4 簡化寫法
用with as 語法來寫入資料,檔案會自動關閉,就不需要呼叫close()方法了,簡寫如下:
1 with open('demo.txt','a',encoding='utf-8') as f: 2 f.write(data)
二、JSON檔案存盤
2.1 適用方式
JSON,全稱為JavaScript Object Notation,也就是JavaScript物件標記,構造簡潔但是結構化程度非常高,采用物件和陣列的組合來表示資料,是一種輕量級的資料交換格式,和XML有點類似,如果對資料結構有要求的話,可根據需求考慮此種方式
2.2 基本寫法
Python提供了json庫來實作對json檔案的讀寫操作,通過呼叫json庫的loads()方法可以將json文本字串轉換為json物件,而呼叫dumps()方法可以將json物件轉換為文本字串,如下:
1 import json 2 3 with open('demo.json','w',encoding='utf-8') as f: 4 f.write(json.dumps(data,indent=2,ensure_ascii=False))
1 import json 2 3 with open('demo.json','r',encoding='utf-8') as f: 4 data =https://www.cnblogs.com/makerchen/archive/2021/11/04/ f.read() 5 data =https://www.cnblogs.com/makerchen/archive/2021/11/04/ json.loads(data) 6 price = data.get('price') 7 location = data.get('location') 8 size = data.get('size')
indent代表縮進字符個數,ensure_ascii=False規定檔案輸出的編碼,這樣就可以輸出中文
注意:JSON的資料需要用雙引號來包圍,不能使用單引號,代碼如下:
1 [ 2 { 3 "name":"makerchen', 4 "gender":"male", 5 "hobby":"running" 6 } 7 ]
2.3 以TXT格式存盤JSON資料
如果我們想要把資料存盤為TXT格式,又想要把資料變為json這樣的結構,可以這樣實作:
1 import json 2 3 with open('demo.txt','a',encoding='utf-8') as f: 4 f.write(json.dumps(data,indent=4,ensure_ascii=False) + '\n')
三、CSV檔案存盤
3.1 適用方式
CSV,全稱為Comma-Separated Values,中文名可以叫做字符分隔值或逗號分隔值,以純文本形式存盤表格資料,文本默認以逗號分隔,CSV相當于一個結構化表的純文本形式,比Excel檔案更加簡潔,保存資料非常方便
3.2 單行寫入
1 import csv 2 3 with open('demo.csv','w',encoding='utf-8') as csvf: 4 writer = csv.writer(csvf) 5 writer.writerow(['id','name','gender']) 6 writer.writerow(['100','makerchen','male']) 7 writer.writerow(['101','makerliu','female']) 8 writer.writerow(['102','makerqin','male'])
首先呼叫csv庫的writer()方法初始化寫入物件,然后再呼叫writerow()方法傳入每行的資料即可完成寫入
Excel效果如下:
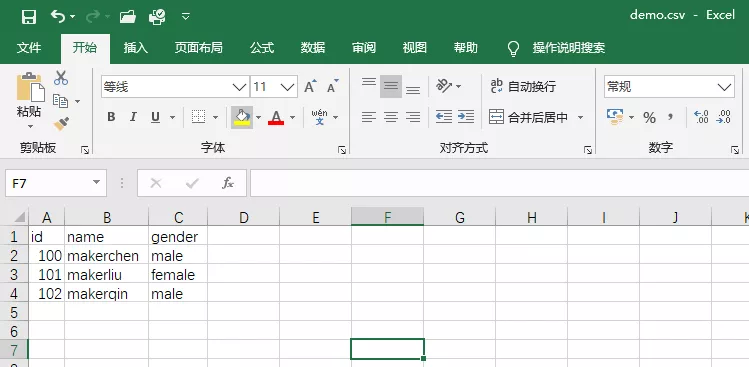
如果想修改列與列之間的分隔符,可以傳入引數delimiter,代碼如下:
1 import csv 2 3 with open('demo.csv','w',encoding='utf-8') as csvf: 4 writer = csv.writer(csvf,delimiter=' ') 5 writer.writerow(['id','name','gender']) 6 writer.writerow(['100','makerchen','male']) 7 writer.writerow(['101','makerliu','female']) 8 writer.writerow(['102','makerqin','male'])
這里表示每一列資料以空格分隔
3.3 多行寫入
呼叫writerows()方法就可以同時寫入多行,此時引數需要為二維串列,代碼如下:
1 import csv 2 3 with open('demo.csv','w',encoding='utf-8') as csvf: 4 writer = csv.writer(csvf) 5 writer.writerow(['id','name','gender']) 6 writer.writerows(['100','makerchen','male'], 7 ['101','makerliu','female'],['102','makerqin','male'])
3.4 字典寫入
一般情況下,爬蟲提取的資料都是結構化資料,我們一般會用字典來表示,代碼如下:
1 import csv 2 3 with open('demo.csv','w',encoding='utf-8') as csvf: 4 fieldnames = ['id','name','gender'] 5 writer = csv.DictWriter(csvf,fieldnames=fieldnames) 6 writer.writeheader() 7 writer.writerow({'id':'100','name':'makerchen','gender':'male'}) 8 writer.writerow({'id':'101','name':'makerliu','gender':'female'}) 9 writer.writerow({'id':'102','name':'makerqin','gender':'male'})
首先用fieldnames定義頭資訊,然后將其傳給DictWriter來初始化一個字典寫入物件,接著用writeheader()方法寫入頭資訊,最后呼叫writerow()方法傳入字典即可
如果想追加寫入的話,可將open()方法的第二個引數改為a,代碼如下:
1 with open('demo.csv','a',encoding='utf-8') as csvf
3.5 讀取CSV檔案
我們可以將剛才寫入的檔案內容讀取出來,代碼如下:
1 import csv 2 3 with open('demo.csv','r',encoding='utf-8') as csvf: 4 datas = csv.reader(csvf) 5 for data in datas: 6 print(data)
輸出結果如下:
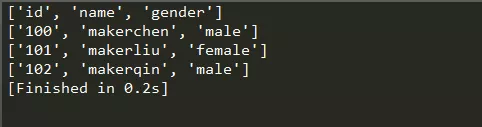
通過遍歷輸出每行內容,每一行都是一個串列形式
注意:如果CSV檔案中包含中文的話,還需要指定檔案編碼
當然也可以用pandas庫中的read_csv()方法將資料從CSV中讀取出來:
1 import pandas as pd 2 3 data = https://www.cnblogs.com/makerchen/archive/2021/11/04/pd.read_csv('demo.csv') 4 print(data)
此種方式在做資料分析的時候用的比較多,也是一種比較方便讀取CVS檔案的方法
四、Excel檔案存盤
4.1 xlwt資料寫入
Excel檔案中包含了文本、數值、公式和格式等內容,而CSV不包含這些,默認打開編碼為Unicode,是現在比較流行的資料存盤格式
基本寫入方式
這里我們呼叫xlwt庫進行Excel的資料寫入,代碼如下:
1 import xlwt 2 3 file = xlwt.Workbook(encoding='utf-8') 4 table = file.add_sheet('data') 5 datas = [ 6 ['python實習生','貴陽','本科'], 7 ['java實習生','杭州','本科'], 8 ['爬蟲工程師','成都市','碩士'] 9 ] 10 for i,p in enumerate(datas): 11 for j,q in enumerate(p): 12 table.write(i,j,q) 13 file.save('demo.xls')
我們首先匯入xlwt庫,然后呼叫Workbook()方法初始化一個可以操縱Excel表格的物件,并指定編碼格式為utf-8,接著再創建一個我們要寫入資料的指定表,用串列的形式創建二維陣列,再用兩個for回圈指定我們要添加資料的位置,這里的i表示外層串列元素所在位置的序號,j表示里層串列元素所在位置的序號,p和q分別表示外層串列和里層串列的元素值,table.write(i,j,q)表示在第i行和第j列插入資料q,最后保存Excel檔案,
運行效果如下:
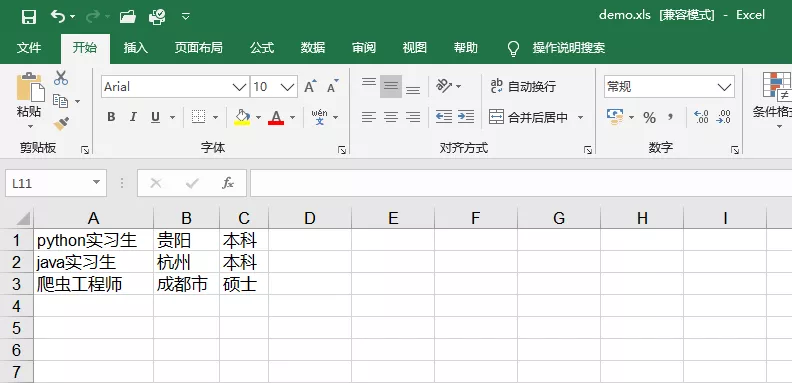
帶序號的寫入方式
代碼如下:
1 import xlwt 2 3 file = xlwt.Workbook(encoding = 'utf-8') 4 table = file.add_sheet('data') 5 data =https://www.cnblogs.com/makerchen/archive/2021/11/04/ { 6 "1":['python實習生','貴陽','本科'], 7 "2":['java實習生','杭州','本科'], 8 "3":['爬蟲工程師','成都市','碩士'] 9 } 10 ldata =https://www.cnblogs.com/makerchen/archive/2021/11/04/ [] 11 num = [a for a in data] 12 #for回圈指定取出key值存入num中,也就是序號 13 num.sort() 14 print(num) 15 #字典資料取出后需要先排序,避免序號混亂 16 for x in num: 17 #for回圈將data字典中的鍵和值分批的保存在ldata中 18 t = [int(x)] 19 for a in data[x]: 20 print(t) 21 t.append(a) 22 print(t) 23 ldata.append(t) 24 print(ldata) 25 26 for i,p in enumerate(ldata): 27 #將資料寫入檔案,i,j是enumerate()函式回傳的序號數 28 for j,q in enumerate(p): 29 # print i,j,q 30 table.write(i,j,q) 31 file.save('demo.xls')
控制臺輸出如下:
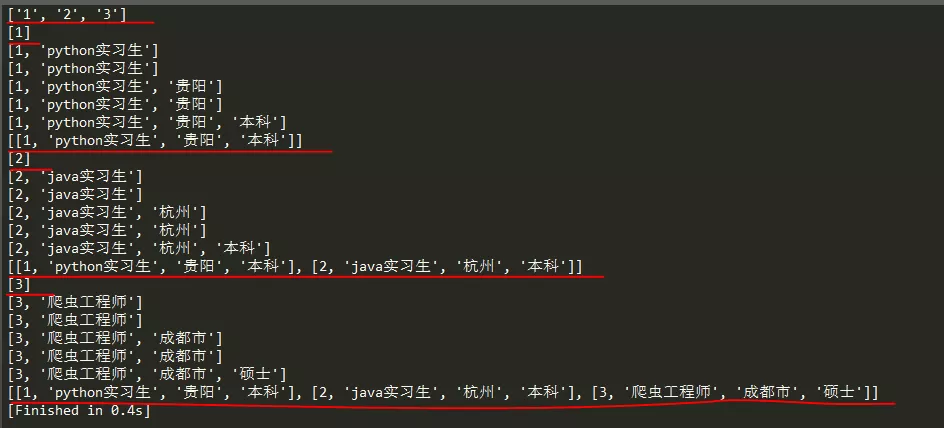
從上圖看,num就是一個帶有序號的串列,其值是data中的key,t是一個串列,并且它的第一個值也就是序號我們把它強制轉換成了整型,然后利用for回圈遍歷data中value的每個欄位值,并把這些欄位值依次添加到串列t中;因為后面我們要以二維陣列的形式把資料插入到Excel中,才能定位插入的位置,所以需要再構建一個串列ldata,最后再把串列t添加到串列ldata中,這樣就構成了二維陣列,后面的寫法和上面的第一種寫法一樣
Excel效果如下:
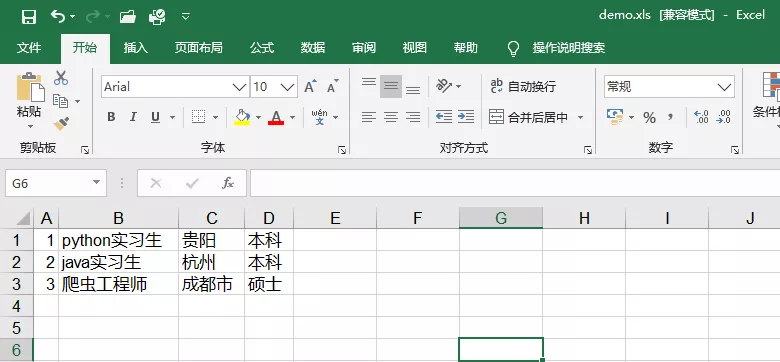
注意:由于xlwt支持的Excel版本兼容問題,只支持Excel 97-2003(*.xls),不支持Excel 2010(*.xlsx)和Excel 2016(*.xlsx)的,所以在保存時后綴需為.xls,否則可能會有如下錯誤提示:

4.2 xlrd資料讀取
這里我們用剛剛寫入的資料demo.xls進行讀取,代碼如下:
1 import xlrd 2 3 def read(xlsfile): 4 file = xlrd.open_workbook(xlsfile) # 得到Excel檔案的book物件,實體化物件 5 sheet0 = file.sheet_by_index(0) # 通過sheet索引獲得sheet物件 6 # sheet1 = book.sheet_by_name(sheet_name) # 通過sheet名字來獲取,當然如果知道sheet名字就可以直接指定 7 nrows = sheet0.nrows # 獲取行總數 8 ncols = sheet0.ncols # 獲取列總數 9 list = [] 10 for i in range(nrows): 11 list.append([]) 12 for j in range(ncols): 13 # print(sheet0.cell_value(i, j)) 14 list[i].append(str(sheet0.cell_value(i, j))) 15 print(list) 16 return list 17 18 19 def excel_to_data(): 20 list = read('demo.xls') 21 for lis in list: 22 print(lis) 23 24 if __name__ == '__main__': 25 excel_to_data()
首先呼叫xlrd的open_workbook()方法創建操縱Excel檔案的物件,然后通過sheet_by_index(index)方法或者sheet_by_name(sheet_name)方法根據索引、sheet名獲取sheet物件,然后獲取資料的總行數以及總列數,通過兩個for回圈,呼叫sheet物件的cell_value(i, j)獲取單元格的值,強制轉換成字串型別之后再根據索引添加到串列list中,以此構成二維陣列,輸出并回傳,最后再遍歷二維陣列的每個元素(每個串列)進行輸出即可
控制臺輸出如下:
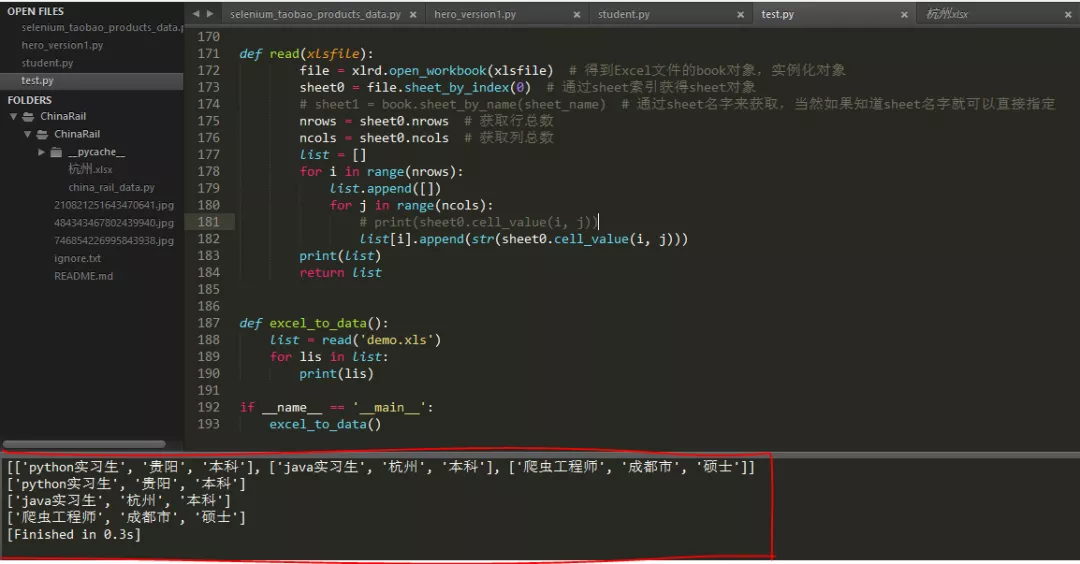
注意:xlrd支持對后綴為.xls以及.xlsx的Excel檔案的讀取;并且不論是xlwt還是xlrd,資料的起始索引位置都為0
4.3 pandas寫入或讀取Excel
pandas讀取
我們還是用上面的demo.xls進行操作:
1 import pandas as pd 2 3 data = https://www.cnblogs.com/makerchen/archive/2021/11/04/pd.read_excel('demo.xls') 4 print(data) 5 print(type(data))
我們看一下控制臺輸出結果:
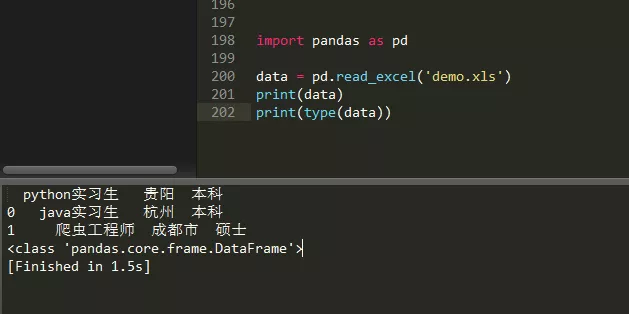
我們可以觀察看,通過pandas庫的read_excel()方法,看起來好像更簡單,但它更偏向于資料分析,注意資料型別為DataFrame,輸出的資料中帶有序號
pandas寫入
1 import pandas as pd 2 3 data = https://www.cnblogs.com/makerchen/archive/2021/11/04/pd.DataFrame([['python實習生','貴陽','本科'],['java實習生','杭州','本科'],['爬蟲工程師','成都市','碩士']]) 4 data.to_excel('demo.xlsx')
Excel效果如下:
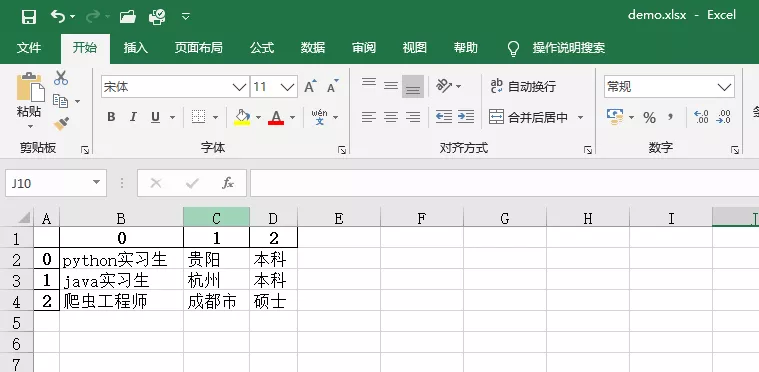
以pandas庫的DataFrame()方法存盤的資料都是帶有索引序號的,方便進行資料分析、建模等
注意:pandas庫支持后綴為.xlsx的Excel表格
4.4 openpyxl寫入或讀取Excel
openpyxl寫入
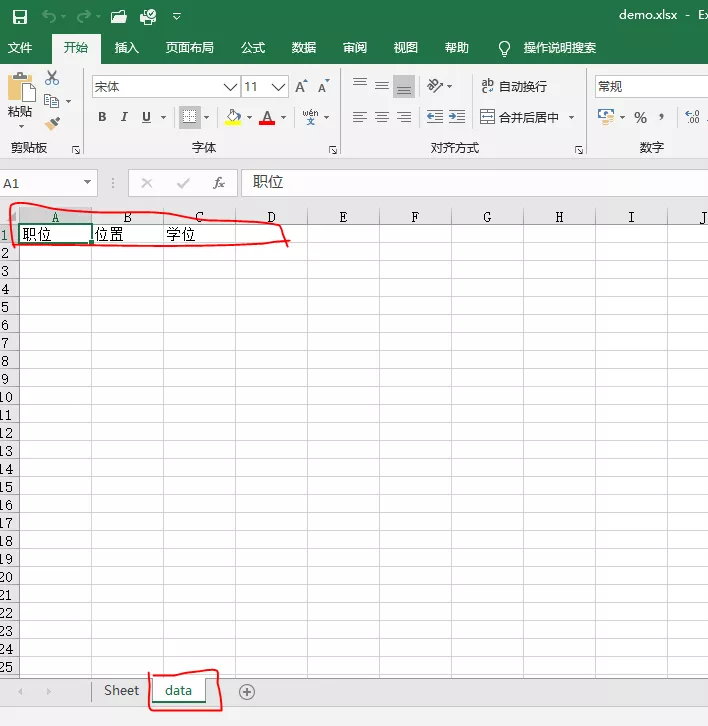
1 import openpyxl 2 3 wb = openpyxl.Workbook() 4 ws = wb.create_sheet('data') 5 ws.cell(row=1,column=1).value=https://www.cnblogs.com/makerchen/archive/2021/11/04/"職位" 6 ws.cell(row=1,column=2).value=https://www.cnblogs.com/makerchen/archive/2021/11/04/"位置" 7 ws.cell(row=1,column=3).value=https://www.cnblogs.com/makerchen/archive/2021/11/04/"學位" 8 wb.save('demo.xlsx')
Excel效果如下:
openpyxl讀取
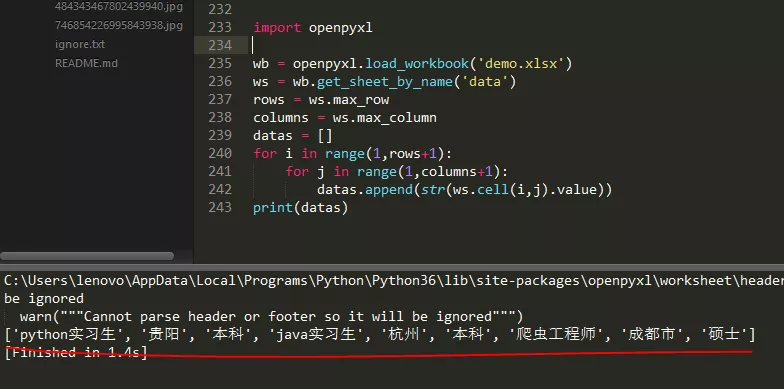
1 import openpyxl 2 3 wb = openpyxl.load_workbook('demo.xlsx') 4 ws = wb.get_sheet_by_name('data') 5 rows = ws.max_row 6 columns = ws.max_column 7 datas = [] 8 for i in range(1,rows+1): 9 for j in range(1,columns+1): 10 datas.append(str(ws.cell(i,j).value)) 11 print(datas)
控制臺輸出如下:
注意:openpyxl只支持后綴為.xlsx的Excel檔案,并且讀取或寫入資料的索引位置均為1
個人推薦使用xlrd和xlwt以及pandas,這些庫操作Excel檔案時資料的起始索引位置都為0,比較方便,不過也可以根據個人使用習慣以及需求來決定
更多獨家精彩內容 請掃碼關注個人公眾號,一起Coding吧!
—— —— —— —— — END —— —— —— —— ————
歡迎掃碼關注我的公眾號
小鴻星空科技

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/348181.html
標籤:其他