文章目錄
- 前言
- 一.需求分析
- 二.代碼實作
- 1.百度文字識別
- 2.查看檔案獲取access_token
- 3.圖片代碼
- 4.代碼部分解讀
- 三.效果展示
前言
就在前幾天一個大一學妹打破了我繁忙的生活,我納悶了,直接問她啥事啊(老直男了)
原來是找我幫個忙,作為好學長那肯定得助人為樂啊…
話不多說,進入正題
一.需求分析
根據學妹的描述來看,就只是想要一個能識別圖片文字的程式,那就不管啥排版了,直接依次識別算了,主要是忙…那我直接用百度的ocr就行了,半小時搞定它!
二.代碼實作
1.百度文字識別
文字識別官方入口
https://ai.baidu.com/tech/ocr/general

點擊立即使用,我們就白嫖吧,反正一個月也用不到1000次
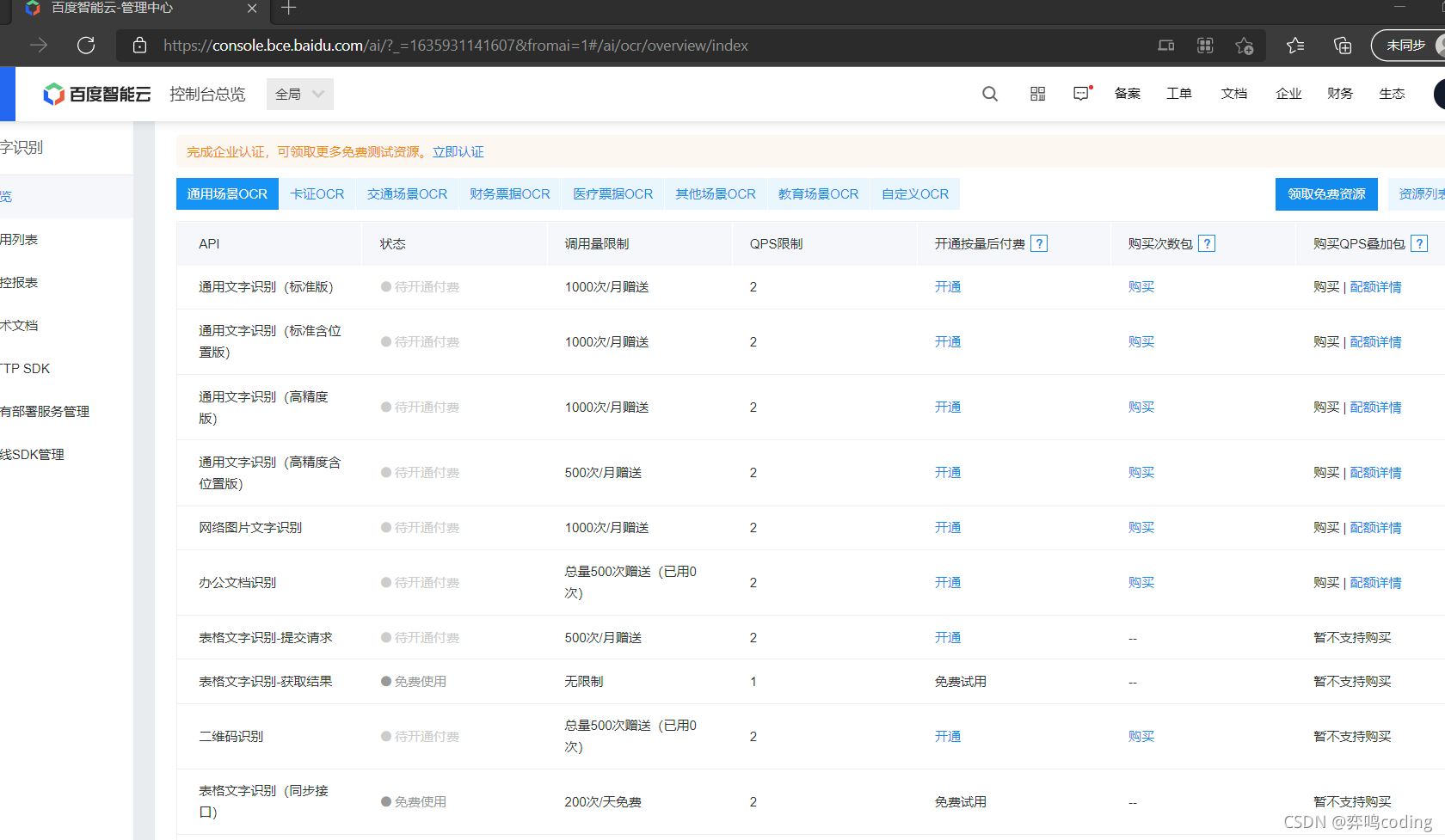
創建應用,輸入應用名稱,這個隨意哈,然后選一個文字識別-免費的,有錢的話當我沒說,
下圖創建成功,
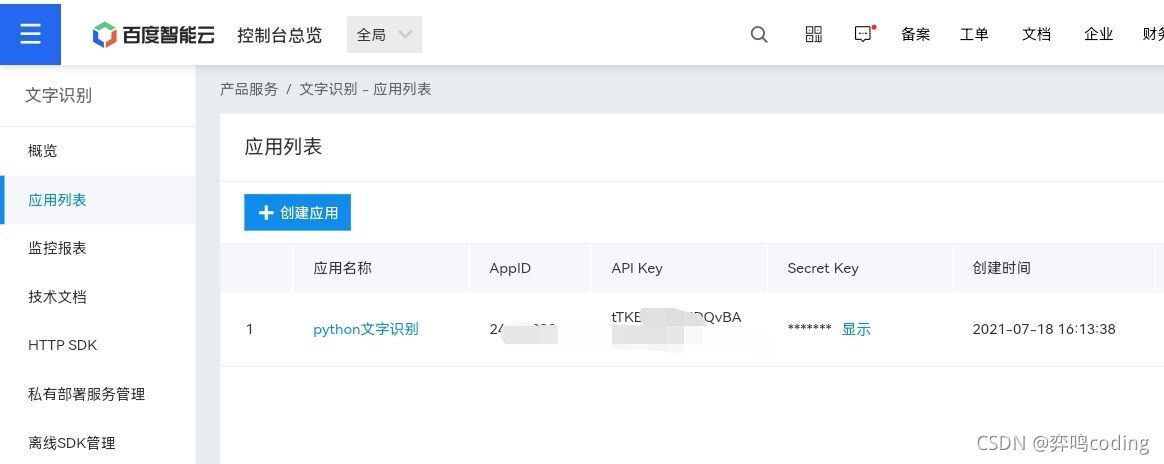
一會API Key和Secret Key是要使用的,
2.查看檔案獲取access_token
接下來就要去看看檔案了,看是怎么使用的
https://ai.baidu.com/ai-doc/OCR/1k3h7y3db
不會看檔案的小伙伴,我直接就講我需要的東西了,其余的大家自己學著看吧,
從檔案來看,我們首先要獲取一個東西——access_token
官網代碼
# encoding:utf-8
import requests
# client_id 為官網獲取的AK, client_secret 為官網獲取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官網獲取的AK】&client_secret=【官網獲取的SK】'
response = requests.get(host)
if response:
print(response.json())
我的代碼
import requests
def access_token():
url = 'https://aip.baidubce.com/oauth/2.0/token'
token_ = {
'grant_type': 'client_credentials',
# API Key
'client_id': '官網獲取的AK',
# ecret Key
'client_secret': '官網獲取的SK'
}
res = requests.post(url, data=token_)
res = res.json()
print(res)
access_token = res['access_token']
print(access_token)
return access_token
if __name__ == '__main__':
access_token()
官網說推薦使用post,那我們就用post,但是官方代碼是用的get這種方法,其實結果都一樣,都能得到需要的資料,只不過官方的代碼還需要一步提取出access_token,
access_token = response.json()['access_token']

然后就能得到access_token了,

如果在這個程序中遇到錯誤,檔案也有,而且會比我講的詳細,所以遇到問題的話可以先看檔案,實在不行可以問我,
獲取access_token的函式
def access_token():
url = 'https://aip.baidubce.com/oauth/2.0/token'
token_ = {
'grant_type': 'client_credentials',
# API Key
'client_id': '自己獲取',
# ecret Key
'client_secret': '自己獲取'
}
res = requests.post(url, data=token_)
res = res.json()
print(res)
access_token = res['access_token']
print(access_token)
return access_token
當我們需要用時直接呼叫就行了,

根據檔案的說明,我們就開始寫讀取圖片的代碼了
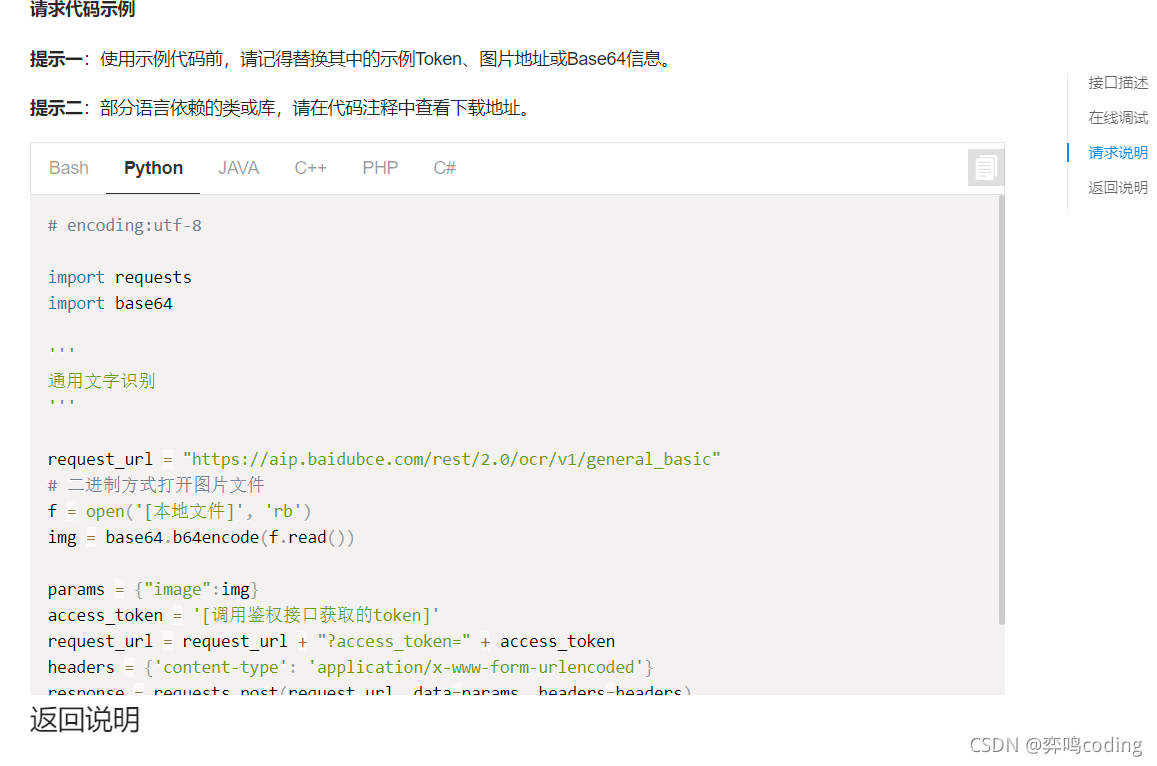
3.圖片代碼
def raed_pic():
url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate"
request_url = url + "?access_token=" + access_token()
f = open('6.jpg', 'rb')
img = base64.b64encode(f.read())
# 引數看檔案
params = {"image": img,
"language_type": "CHN_ENG",
"recognize_granularity": "small",
}
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
# print(response)
# res = response.json()
# print(res)
# 判斷是否回應成功
if response:
# 保存讀出文字的檔案,自動創建
file_name = "yiming6.txt"
# 這個沒說的了,就是寫入操作
with open(file_name, 'w', encoding='utf-8') as f:
for j in res:
f.write(j["words"] + "\n")
4.代碼部分解讀
從json分析來看我們只要提取當中的words_result里面的words

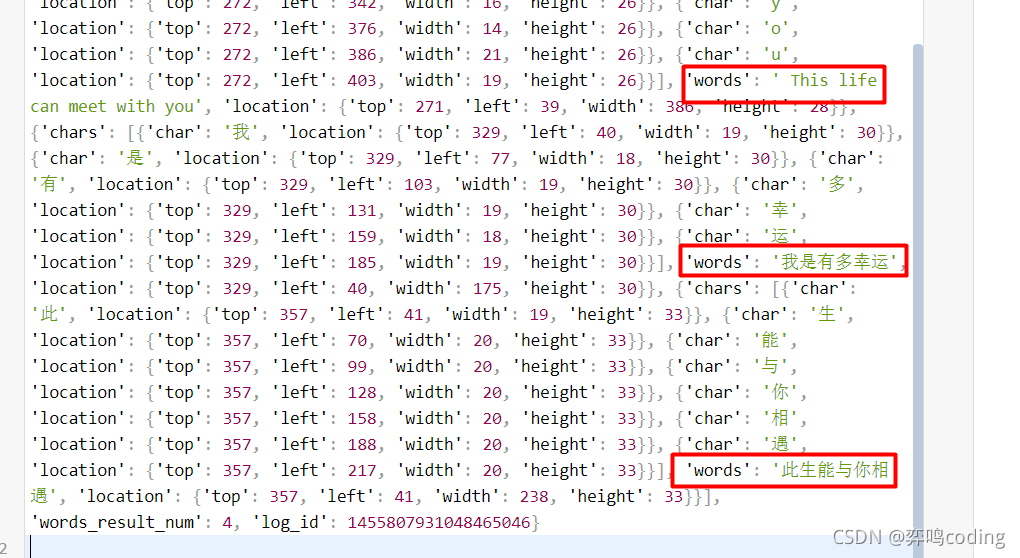
關于base64,大家可以看這篇文章
https://www.cnblogs.com/longwhite/p/10397707.html
三.效果展示
效果如下:
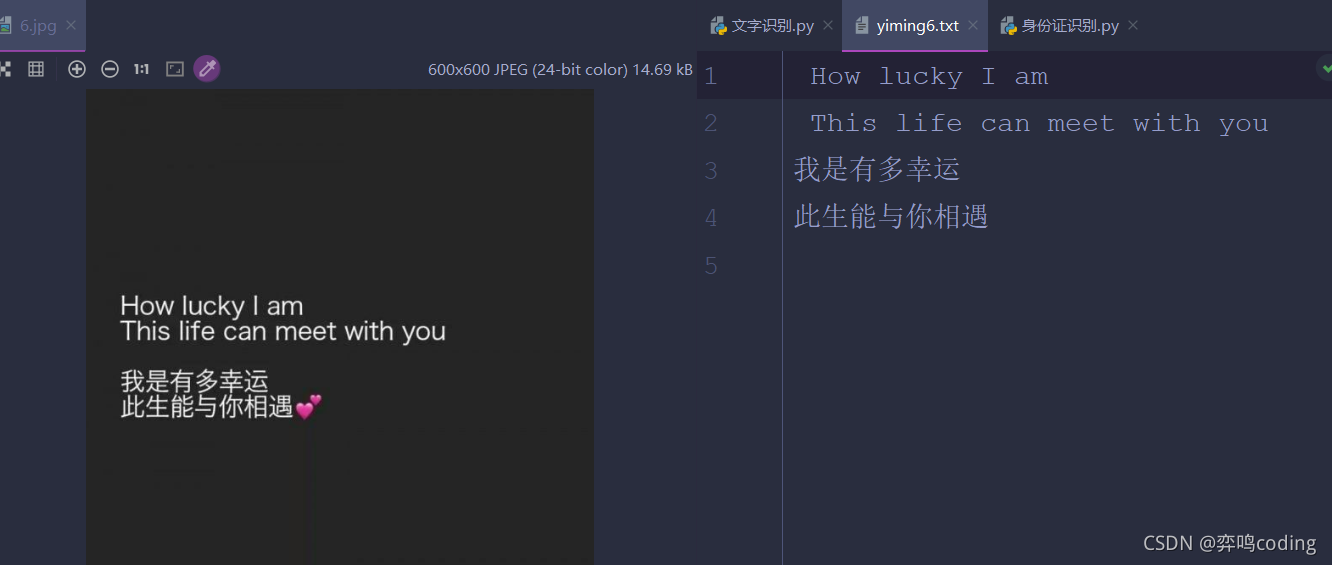
nice!當然可以寫個回圈然后直接遍歷一個檔案夾里面的所有圖片,就可以得到每張圖的文字了,再讀取里面的文字放在同一個txt檔案里面,有閑工夫的小伙伴可以試一試,我就不寫了,最后也成功得到學妹的奶茶,就不上圖片了,嘻嘻嘻~
喜歡的小伙伴記得點贊!需要原始碼可以加我qq:2024810652
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/348401.html
標籤:python
下一篇:前端知識之JavaScript