💖作者簡介:大家好,我是車神哥,府學路18號的車神🥇
📝個人主頁:應無所住而生其心的博客_府學路18號車神_CSDN博客
🎉點贊?評論?收藏 == 養成習慣(一鍵三連)😋?希望大家多多支持🤗~一起加油 😁
- 專欄《Fault Diagnosis》
其他專欄:
- 《LeetCode天梯》
- 《Neural Network》
- 《Python》
- 《Algorithm》
資料降維方法及Python實作
- 前言
- 大綱
- 線性資料降維
- 主元分析(PCA)
- 偏最小二乘法(PLS)
- 獨立成分分析(ICA)
- 線性判別分析(LDA)
- 典型相關分析(CCA)
- 慢特征分析(SFA)
- 非線性資料降維
- 神經網路非線性方法
- 核(Kernel)方法
- 線性核函式
- 高斯核函式
- 流行學習方法
- LLE(Locally Linear Embedding) 區域線性嵌入
- LE (Laplacian Eigenmaps) 拉普拉斯特征映射
- LPP(Locality Preserving Projection) 區域保留投影
前言
11月份了,目前再準備開題, 依舊搞故障診斷,在工業程序中的程序監控現狀大多是從資料驅動的角度進行監控和診斷,然鵝,我們遇到的很多工況資料確實非線性的,在實際生產中,大部分都是非線性的資料,但也有一些線性的,由此我們可以從全域和區域出發,來對資料進行挖掘和分析,對此,近期我做了很多關于資料降維的一些作業用于畢業論文,現在在下面講講我的一些見解和Python代碼的復現,
Python代碼在文末喲!~
大綱
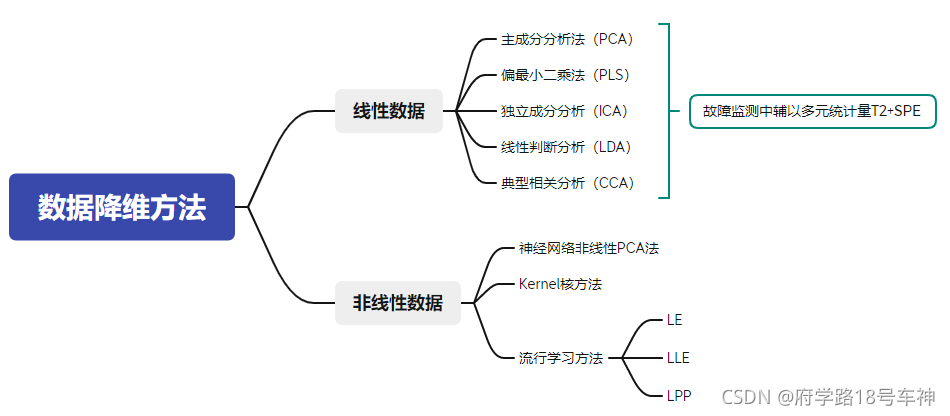
線性資料降維
線性降維方法,如主元分析(PCA)"、部分最小二乘化(PLS)及獨立元分析(ICA),線性辨別分析(LDA)等,
主元分析(PCA)
之前有過一篇blog介紹過這一部分,-> 看這里
程序監控中的應用可看 -> 這里
還是在介紹一遍吧~
PCA是一種統計方法,廣泛應用于工程和科學應用中,與傅里葉分析相比,尤其適用于質量監測,
設 x ∈ R m \boldsymbol{x} \in \mathfrak{R}^{m} x∈Rm表示 m m m個傳感器矢量的樣本測量值,
假設每個傳感器有 N N N個樣本,資料矩陣 X = [ x 1 x 2 ? x N ] T ∈ R N × m \mathbf{X}=\left[\begin{array}{llll} \boldsymbol{x}_{1} & \boldsymbol{x}_{2} & \cdots & \boldsymbol{x}_{N} \end{array}\right]^{T} \in \mathfrak{R}^{N \times m} X=[x1??x2????xN??]T∈RN×m,由代表樣本 x i T x^T_i xiT?的每一行組成,
正常資料矩陣
X
X
X的一個重要要求是,它應具有豐富的正常變化,以代表程序的共同原因變化,矩陣
X
X
X被縮放為零均值,通常為PCA建模的單位方差,矩陣
X
X
X通過奇異值分解(SVD)分解為得分矩陣
T
T
T和加載矩陣
P
P
P,
X
=
T
P
T
+
X
~
(1)
\mathbf{X}=\mathbf{T P}^{T}+\tilde{\mathbf{X}}\tag{1}
X=TPT+X~(1)
其中
T
=
X
P
T=XP
T=XP包含
l
l
l 個左前導奇異向量和奇異值,P 包含
l
l
l個右前導奇異向量,
X
~
\tilde{\mathbf{X}}
X~ 是殘差矩陣,因此,T 的列是正交的,P 的列是正交的,將樣本協方差矩陣表示為
S
=
1
N
?
1
X
T
X
(2)
\mathbf{S}=\frac{1}{N-1} \mathbf{X}^{T} \mathbf{X}\tag{2}
S=N?11?XTX(2)
作為SVD的替代方法,可以對 S 進行特征分解,以獲得 P 作為 S 的 l l l 個前導特征向量,特征值表示為
Λ
=
diag
?
{
λ
1
,
λ
2
,
…
,
λ
l
}
(3)
\mathbf{\Lambda}=\operatorname{diag}\left\{\lambda_{1}, \lambda_{2}, \ldots, \lambda_{l}\right\}\tag{3}
Λ=diag{λ1?,λ2?,…,λl?}(3)
第
i
i
i 個特征值可與得分矩陣 T 的第
i
i
i 列相關,如下所示:
λ
i
=
1
N
?
1
t
i
T
t
i
≈
var
?
{
t
i
}
(4)
\lambda_{i}=\frac{1}{N-1} \mathbf{t}_{i}^{T} \mathbf{t}_{i} \approx \operatorname{var}\left\{\mathbf{t}_{i}\right\}\tag{4}
λi?=N?11?tiT?ti?≈var{ti?}(4)
這是第 i i i個得分向量 t i ∈ R N \mathbf{t}_{i} \in \mathfrak{R}^{N} ti?∈RN的樣本方差,主成分子空間(PCS)是 S p = span ? { P } \mathcal{S}_{p}=\operatorname{span}\{\mathbf{P}\} Sp?=span{P},剩余子空間(RS) S r S_r Sr?是 S p S_p Sp?的正交補,將測量空間劃分為PCS和RS,使得RS僅包含微小的奇異值,這些奇異值對應于通常具有較小變化的子空間,或者主要是噪聲的子空間,因此,殘差類似于根據質量平衡和能量平衡建立的數學模型中的方程誤差,
樣本向量 x ∈ R m \mathbf{x} \in \mathfrak{R}^{m} x∈Rm可以分別投影到PCS和RS上,
x ^ = P t = P P T x ∈ S p (5) \hat{\boldsymbol{x}}=\mathbf{P} \boldsymbol{t}=\mathbf{P P}^{T} \boldsymbol{x} \in \mathcal{S}_{p}\tag{5} x^=Pt=PPTx∈Sp?(5)
其中,
t = P T x ∈ R l (6) \boldsymbol{t}=\mathbf{P}^{T} \boldsymbol{x} \in \mathfrak{R}^{l}\tag{6} t=PTx∈Rl(6)
為 l l l 個潛在變數得分的向量,
殘差向量:
x ~ = x ? x ^ = ( I ? P P T ) x ∈ S r (7) \tilde{\boldsymbol{x}}=\boldsymbol{x}-\hat{\boldsymbol{x}}=\left(\mathbf{I}-\mathbf{P P}^{T}\right) \boldsymbol{x} \in \mathcal{S}_{r}\tag{7} x~=x?x^=(I?PPT)x∈Sr?(7)
因為 S p S_p Sp? 和 S r S_r Sr? 是正交的,
x ^ T x ~ = 0 (8) \hat{\boldsymbol{x}}^{T} \tilde{\boldsymbol{x}}=0\tag{8} x^Tx~=0(8)
且
x = x ^ + x ~ (9) \boldsymbol{x}=\hat{\boldsymbol{x}}+\tilde{\boldsymbol{x}}\tag{9} x=x^+x~(9)
其中,一個重要的概念是,資料的PCA模型, x ^ \hat{\boldsymbol{x}} x^由潛變數 t ∈ R m \mathbf{t} \in \mathfrak{R}^{m} t∈Rm 引數化,
偏最小二乘法(PLS)
PLS具體演算法程序如下:
- 將X和Y經過標準化(包括減均值、除標準差等)(此操作可參考 這里 的CCA演算法),
- 設X的第一個主成分為 p 1 p_1 p1?,Y的第一個主成分為 q 1 q_1 q1?,兩者都經過單位化,(注意:這里的主成分并不是通過PCA得到的主成分)(~~菜雞解釋:~~這里主成分可簡單的看成CCA系數矩陣中的第一系數成分,如 a 1 a_1 a1?),
- u 1 = X p 1 , v 1 = Y q 1 u_1=Xp_1,v_1=Yq_1 u1?=Xp1?,v1?=Yq1?,這和CCA幾乎一樣,可得下面的期望的約束條件,
-
V
a
r
(
u
1
)
→
M
a
x
,
V
a
r
(
v
1
)
→
M
a
x
Var(u_1)\rightarrow Max,Var(v_1)\rightarrow Max
Var(u1?)→Max,Var(v1?)→Max,代表在主成分分量上的投影,得到了期望的方差最大化值(
貌似這樣解釋有點奇怪), - R ( u 1 , v 1 ) → M a x R_(u_1,v_1)\rightarrow Max R(?u1?,v1?)→Max,和CCA一樣,
- 綜合以上條件,可得 C o v ( u 1 , v 1 ) = V a r ( u 1 ) V a r ( v 1 ) R ( u 1 , v 1 ) → M a x Cov(u_1,v_1)=\sqrt{Var(u_1)Var(v_1)}R_(u_1,v_1) \rightarrow Max Cov(u1?,v1?)=Var(u1?)Var(v1?) ?R(?u1?,v1?)→Max,
簡而言之,為了實作偏最小二乘回歸的基本思想,要求p1和q1的協方差最大,即求解下面優化后的目標函式:
M a x : < X p 1 , Y q 1 > S . t . : ∣ ∣ p 1 ∣ ∣ = 1 , ∣ ∣ q 1 ∣ ∣ = 1 Max:<Xp_1,Yq_1> \\ S.t.:||p_1||=1,||q_1||=1 Max:<Xp1?,Yq1?>S.t.:∣∣p1?∣∣=1,∣∣q1?∣∣=1
看似比CCA的簡單,這里附上CCA的目標函式:
M a x : R ( U , V ) = Cov ? ( U , V ) Var ? [ U ] Var ? [ V ] = C o v ( U , V ) = t k T C o v ( A , B ) h k = t k T Σ 12 h k S . t . : V a r ( U k ) = V a r ( t k T A ) = t k T Σ 11 t k = 1 , V a r ( V k ) = V a r ( h k T A ) = h k T Σ 22 h k = 1 Max:R_{(U,V)}=\frac{\operatorname{Cov}(U, V)}{\sqrt{\operatorname{Var}[U] \operatorname{Var}[V]}}=Cov(U,V)={t_k}^TCov(A,B)h_k={t_k}^T\Sigma_{12} h_k\\ S.t.:Var(U_k)=Var({t_k^T}{A})={t_k^T}\Sigma_{11}t_k=1, Var(V_k)=Var({h_k^T}{A})={h_k^T}\Sigma_{22}h_k=1 Max:R(U,V)?=Var[U]Var[V] ?Cov(U,V)?=Cov(U,V)=tk?TCov(A,B)hk?=tk?TΣ12?hk?S.t.:Var(Uk?)=Var(tkT?A)=tkT?Σ11?tk?=1,Var(Vk?)=Var(hkT?A)=hkT?Σ22?hk?=1
上面CCA是一次求解的程序,而我們的PLS回歸只是對目前的第一主成分做了優化計算,剩下的主成分還得再計算,
關于優化的目標求解的辦法,和CCA一樣,也是參考了拉格朗日乘數法來求解,(下面給出詳細計算步驟)
首先,引入拉格朗日乘子:
L
=
p
1
T
X
T
Y
q
1
?
λ
2
(
p
1
T
p
1
?
1
)
?
θ
2
(
q
1
T
q
1
?
1
)
\mathcal{L}=p_{1}^{T} X^{T} Y q_{1}-\frac{\lambda}{2}\left(p_{1}^{T} p_{1}-1\right)-\frac{\theta}{2}\left(q_{1}^{T} q_{1}-1\right)
L=p1T?XTYq1??2λ?(p1T?p1??1)?2θ?(q1T?q1??1)
分別對
p
1
p_1
p1?和
q
1
q_1
q1?求偏導,
?
L
?
p
1
=
X
τ
Y
q
1
?
λ
p
1
=
0
?
L
?
q
1
=
Y
τ
X
p
1
?
θ
q
1
=
0
\begin{array}{l} \frac{\partial \mathcal{L}}{\partial p_{1}}=X^{\tau} Y q_{1}-\lambda p_{1}=0 \\\\ \frac{\partial \mathcal{L}}{\partial q_{1}}=Y^{\tau} X p_{1}-\theta q_{1}=0 \end{array}
?p1??L?=XτYq1??λp1?=0?q1??L?=YτXp1??θq1?=0?
和CCA一樣,可求得
λ
\lambda
λ和
θ
\theta
θ相等,
將
λ
?
1
X
τ
Y
q
1
=
p
1
\lambda^{-1}X^{\tau} Y q_{1}= p_{1}
λ?1XτYq1?=p1?代入上面第二式子,可得
Y
τ
X
X
τ
Y
q
1
=
λ
2
q
1
Y^{\tau}XX^{\tau} Y q_{1}= \lambda^{2} q_{1}
YτXXτYq1?=λ2q1?
兩邊均乘以
p
1
p_1
p1?或
q
1
q_1
q1?,再利用約束條件
∣
∣
p
1
∣
∣
=
1
,
∣
∣
q
1
∣
∣
=
1
||p_1||=1,||q_1||=1
∣∣p1?∣∣=1,∣∣q1?∣∣=1,可得:
X
τ
Y
Y
τ
X
p
1
=
λ
2
p
1
X^{\tau}YY^{\tau} X p_{1}= \lambda^{2} p_{1}
XτYYτXp1?=λ2p1?
故上式
λ
2
\lambda^{2}
λ2則為
X
τ
Y
Y
τ
X
p
1
X^{\tau}YY^{\tau} X p_{1}
XτYYτXp1?的特征值,
p
1
p_1
p1?為相應的單位特征向量,
q
1
q_1
q1?一樣,
求得 p 1 p_1 p1?、 q 1 q_1 q1?這樣 ? X p 1 , Y q 1 ? → p 1 τ X τ Y q 1 → p 1 τ ( λ p 1 ) → λ \left\langle X p_{1}, Y q_{1}\right\rangle \rightarrow p_{1}^{\tau} X^{\tau} Y q_{1} \rightarrow p_{1}^{\tau}\left(\lambda p_{1}\right) \rightarrow \lambda ?Xp1?,Yq1??→p1τ?XτYq1?→p1τ?(λp1?)→λ可得到最優解,
可見 p 1 p_1 p1?和 q 1 q_1 q1?是投影方差最大和兩者相關性最大上的權衡,而CCA只是相關性上最大化,
到此,我們可以得到 u 1 、 v 1 u_1、v_1 u1?、v1?值,這里的 u 1 、 v 1 u_1、v_1 u1?、v1?在圖上面只是表示為綠色點,如果這樣就完成求解,那和CCA的程序一樣,得不到X到Y的映射,
具體整個演算法的詳細原理(模型+回歸)可看 -> 這里
獨立成分分析(ICA)
獨立成分分析 ICA(Independent Component Correlation Algorithm)是一種函式,X為n維觀測信號矢量,S為獨立的m(m<=n)維未知源信號矢量,矩陣A被稱為混合矩陣,ICA的目的就是尋找解混矩陣W(A的逆矩陣),然后對X進行線性變換,得到輸出向量U,
這里使用最大似然估計來解釋演算法,我們假定每個
s
i
s_i
si?有概率密度
p
s
p_s
ps?,那么給定時刻原信號的聯合分布就是
p
(
s
)
=
∏
i
=
1
n
p
s
(
s
i
)
\mathrm{p}(\mathrm{s})=\prod_{i=1}^{n} p_{s}\left(s_{i}\right)
p(s)=i=1∏n?ps?(si?)
此公式代表一個假設前提:每個人發出的聲音信號各自獨立,
有了
p
(
s
)
p(s)
p(s),我們可以求得
p
(
x
)
p(x)
p(x)
p
(
x
)
=
p
s
(
H
x
)
∣
H
∣
=
∣
H
∣
∏
i
=
1
n
p
s
(
h
i
T
x
)
\mathrm{p}(\mathrm{x})=\mathrm{p}_{s}(H x)|\mathrm{H}|=|\mathrm{H}| \prod_{i=1}^{n} p_{s}\left(h_{i}{ }^{T} x\right)
p(x)=ps?(Hx)∣H∣=∣H∣i=1∏n?ps?(hi?Tx)
左邊是每個采樣信號
x
x
x的概率,右邊是每個原信號概率的乘積的
∣
H
∣
|H|
∣H∣倍,
若沒有先驗知識,我們無法求得 H H H和 s s s,
因此我們需要知道
p
s
(
s
i
)
p_s(s_i)
ps?(si?),我們打算選取一個概率密度函式賦給
s
s
s,但是我們不能選取高斯分布的密度函式,在概率論里我們知道密度函式p(x)由累計分布函式(cdf)F(x)求導得到,F(x)要滿足兩個性質是:單調遞增和在[0,1],我們發現sigmoid函式很適合,定義域負無窮到正無窮,值域0到1,緩慢遞增,我們假定
s
s
s的累積分布函式符合sigmoid函式
g
(
s
)
=
1
1
+
e
?
s
g(s)=\frac{1}{1+e^{-s}}
g(s)=1+e?s1?
求導可得,
p
s
(
s
)
=
g
′
(
s
)
=
e
s
(
1
+
e
s
)
2
p_{s}(s)=g^{\prime}(s)=\frac{e^{s}}{\left(1+e^{s}\right)^{2}}
ps?(s)=g′(s)=(1+es)2es?
這就是
s
s
s的密度函式,此時的
s
s
s是實數,
要是我們預先知道 s s s的分布函式,那就不用假設了,但在未知的情況下,sigmoid函式能夠在大多數問題上取得不錯的效果,
由于上式中 p s ( s ) p_s(s) ps?(s)是個對稱函式,因此E[s]=0(s的均值為0),那么E[x]=E[As]=0,x的均值也是0,
現在我們知道了 p s ( s ) p_s(s) ps?(s),下面開始求 H H H,
采樣后的訓練樣本為
X
(
i
)
=
(
x
1
(
i
)
,
x
2
(
i
)
,
…
,
x
n
(
i
)
)
;
(
i
=
1
,
…
,
m
)
\mathrm{X}^{(i)}=\left(x_{1}^{(i)}, x_{2}^{(i)}, \ldots, x_{n}^{(i)}\right) ;( i=1, \ldots, m)
X(i)=(x1(i)?,x2(i)?,…,xn(i)?);(i=1,…,m),使用前面得到的
x
x
x的概率密度函式,得其樣本對數似然估計:
?
(
H
)
=
∑
i
=
1
m
(
∑
j
=
1
n
log
?
g
′
(
h
j
T
x
(
i
)
)
+
log
?
∣
H
∣
)
\ell(H)=\sum_{i=1}^{m}\left(\sum_{j=1}^{n} \log g^{\prime}\left(h_{j}^{T} x^{(i)}\right)+\log |H|\right)
?(H)=i=1∑m?(j=1∑n?logg′(hjT?x(i))+log∣H∣)
其中,括號里的一大堆為
p
(
x
(
i
)
)
p(x^{(i)})
p(x(i)),然后再對
H
H
H進行求導操作,在上式中包含有行列式,對行列式|W|進行求導的方法可參考這里,
最終得到的求導結果公式(很復雜很繁瑣–心情):
H
:
=
H
+
α
(
[
1
?
2
g
(
h
1
T
x
(
i
)
)
1
?
2
g
(
h
2
T
x
(
i
)
)
?
1
?
2
g
(
h
n
T
x
(
i
)
)
]
x
(
i
)
T
+
(
H
T
)
?
1
)
H:=H+\alpha\left(\left[\begin{array}{c} 1-2 g\left(h_{1}^{T} x^{(i)}\right) \\ 1-2 g\left(h_{2}^{T} x^{(i)}\right) \\ \vdots \\ 1-2 g\left(h_{n}^{T} x^{(i)}\right) \end{array}\right] x^{(i)^{T}}+\left(H^{T}\right)^{-1}\right)
H:=H+α????????????1?2g(h1T?x(i))1?2g(h2T?x(i))?1?2g(hnT?x(i))???????x(i)T+(HT)?1??????
其中
α
\alpha
α表示的是梯度上升速率,可自定義,
當通過多次迭代后,可求出 H H H,便可得到 s ( i ) = H x ( i ) s^{(i)}=Hx^{(i)} s(i)=Hx(i)來還原出原始信號,
具體獨立成分分析ICA原理及應用可看 —> 這里
線性判別分析(LDA)
LDA的思想:由所給定的資料集,設法將樣例資料投影在一條直線上,使得同類資料的投影點盡可能的接近、而異類資料的投影點之間將可能間隔更遠,在我們做新樣本資料的分類時,將其投影到同樣的直線上,再根據投影點的位置來確定新樣本的類別,如下圖(源自周志華《機器學習》)所示:
這里的投影直線也用到了最小二乘的思想,所有資料樣本垂直投影在直線上,只是我們的約束條件表為了不同資料樣本之間的投影在直線上的距離度量,
我們需要尋找到在投影方向 w w w上,使得資料樣本滿足兩個條件:1) 相同資料之間投影距離最小;2)不同資料之間投影點位置最大(可通過求其不同資料的投影中心點來判別)
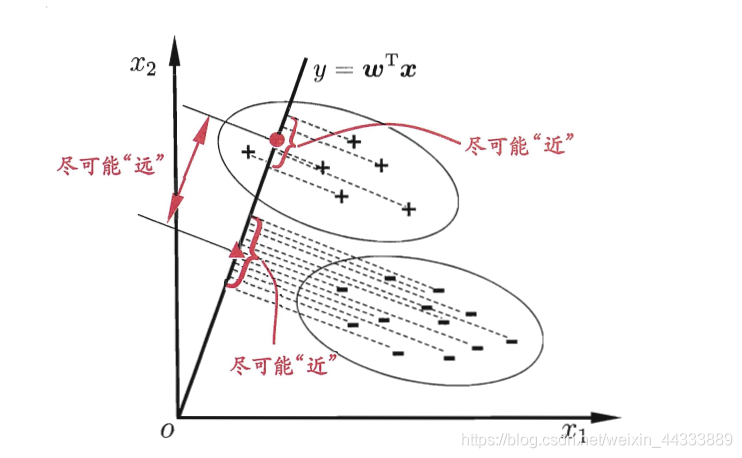
圖中,“+”和“-”代表的是兩種不同的資料簇,而橢圓表示資料簇的外輪廓線,虛線表示其投影,紅色實心圓●和紅色實心三角形△分別代表的兩類資料簇投影到 w w w方向上的中心點,
對于上面投影方向 y = w T x y=\mathbf{w^Tx} y=wTx,有博主認為描述的不夠準確,書中并未提及關于 y y y的解釋,但是對于 y y y其實是有所提及的,
但我認為,這里的
y
y
y,僅僅是為了體現投影的一個方向,將資料
x
x
x投影在方向為
w
w
w的直線上,而不是代表的這根投影直線為
y
=
w
T
x
y=\mathbf{w^Tx}
y=wTx,或許會被人誤認為是投影后的值0,
—菜雞理解(如有不對,請批評指正)
已知給定的資料集為
D
=
{
(
x
i
,
y
i
)
}
i
=
1
m
,
y
i
∈
{
0
,
1
}
D=\{(x_i,y_i)\}_{i=1}^{m},y_i\in \{0,1\}
D={(xi?,yi?)}i=1m?,yi?∈{0,1}
假設
X
i
、
μ
i
、
Σ
i
X_i、\mu_i、\Sigma_i
Xi?、μi?、Σi?分別表示第
i
∈
{
0
,
1
}
i\in\{0,1\}
i∈{0,1}類(注意:這里的
i
i
i 指代有多少個不同的類別資料集,圖中只有兩類,故為0和1)示例的集合、均值向量、協方差矩陣,
假如將所有的樣本資料點都投影到直線 w w w上來,那么兩類不同的樣本資料的中心點在直線上的投影可表示為 w T μ 0 、 w T μ 1 w^{T}\mu_0、w^{T}\mu_1 wTμ0?、wTμ1?;同樣,所有樣本投影到直線上后,我們得到的兩類樣本的協方差分別為 w T Σ 0 w w^{T}\Sigma_0w wTΣ0?w和 w T Σ 1 w w^{T}\Sigma_1w wTΣ1?w.
由于我們只是在一維平面上的直線,故為一維空間,由此 w T μ 0 、 w T μ 1 、 w T Σ 0 w 、 w T Σ 1 w w^{T}\mu_0、w^{T}\mu_1、w^{T}\Sigma_0w、w^{T}\Sigma_1w wTμ0?、wTμ1?、wTΣ0?w、wTΣ1?w都是實數,
為什么說這里是一維空間呢?可以看上圖,假設每個樣本都是d維向量(上圖為二維 x 1 、 x 2 x_1、x_2 x1?、x2?坐標系),現在就簡單一點,想用一條直線 w w w表示這些樣本,稱之為樣本集合的一維表達,所以這里說的一維講的是投影到一條直線上以后的資料,在直線上是屬于一維空間表達的,
下面思考另一個問題,如何讓同類的資料樣本投影點盡可能的靠近,而使得不同樣本投影點離得更遠呢?
這里需要引入協方差的概念,小小復習一下協方差及樣本方差的知識(因為本菜雞數學基礎差)
協方差(Covariance)在概率論和統計學中用于衡量兩個變數的總體誤差,而方差是協方差的一種特殊情況,即當兩個變數是相同的情況,
上面的 Σ 0 、 Σ 1 \Sigma_0、\Sigma_1 Σ0?、Σ1?因為是自協方差也就是代表方差(也即為樣本方差),方差:當資料分布比較分散(即資料在平均數附近波動較大)時,各個資料與平均數的差的平方和較大,方差就較大;當資料分布比較集中時,各個資料與平均數的差的平方和較小,
總的說來:方差越大,資料的波動越大;方差越小,資料的波動就越小,
協方差表示的是兩個變數的總體的誤差,這與只表示一個變數誤差的方差不同, 如果兩個變數的變化趨勢一致,也就是說如果其中一個大于自身的期望值,另外一個也大于自身的期望值,那么兩個變數之間的協方差就是正值, 如果兩個變數的變化趨勢相反,即其中一個大于自身的期望值,另外一個卻小于自身的期望值,那么兩個變數之間的協方差就是負值,
簡而言之:兩個變數之間差距越大,協方差就越小;相反,兩個變數越相似變化趨勢一致,則協方差越大,
復習完協方差、樣本方差的知識后,解決上面的問題應該不難,
按照我們的需求,讓同類的樣本投影點盡可能的靠近,換句話說就是讓同類樣本投影的協方差盡可能的小(注意:這里由于是自協方差==樣本方差,也就滿足上面大字第一條),即 w T Σ 0 w + w T Σ 1 w w^{T}\Sigma_0 w+w^{T}\Sigma_1 w wTΣ0?w+wTΣ1?w盡可能的小,這樣資料的波動就小,之間的距離就更小更靠近,
關于不同資料樣本投影點之間的操作,使其更加的遠離,我們可以通過不同資料集投影的中心點來判別,不同中心點之間的距離越大,那么表示他們之間離得更遠,則 ∣ ∣ w T μ 0 + w T μ 1 ∣ ∣ 2 2 ||w^{T}\mu_0+w^{T}\mu_1||_2^2 ∣∣wTμ0?+wTμ1?∣∣22?(歐式距離)更大,
好!現在我們同時考慮兩者的情況,則可以使得得到最大化的目標,建立我們的模型:
J
=
∥
w
T
μ
0
?
w
T
μ
1
∥
2
2
w
T
Σ
0
w
+
w
T
Σ
1
w
=
w
T
(
μ
0
?
μ
1
)
(
μ
0
?
μ
1
)
T
w
w
T
(
Σ
0
+
Σ
1
)
w
\begin{aligned} J &=\frac{\left\|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\mu}_{0}-\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\mu}_{1}\right\|_{2}^{2}}{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\Sigma}_{0} \boldsymbol{w}+\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\Sigma}_{1} \boldsymbol{w}} \\ &=\frac{\boldsymbol{w}^{\mathrm{T}}\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}}\left(\boldsymbol{\Sigma}_{0}+\boldsymbol{\Sigma}_{1}\right) \boldsymbol{w}} \end{aligned}
J?=wTΣ0?w+wTΣ1?w∥∥?wTμ0??wTμ1?∥∥?22??=wT(Σ0?+Σ1?)wwT(μ0??μ1?)(μ0??μ1?)Tw??
觀察上式目標函式,當我們的
J
→
M
a
x
J\rightarrow Max
J→Max則是我們想要的結果,式子太復雜,那我們再優化一下吧,
引入一下類內和間散度矩陣的知識:
- 類間散度矩陣用于表示各樣本點圍繞均值的散布情況,
- 類內散度矩陣用于表示樣本點圍繞均值的散步情況,關于特征選擇和提取的結果,類內散布矩陣的積越小越好,
具體可參考這里,還有這里,
首先,我們來定義“類內散度矩陣”(within-class scatter matrix)
S
w
=
Σ
0
+
Σ
1
=
∑
x
∈
X
0
(
x
?
μ
0
)
(
x
?
μ
0
)
T
+
∑
x
∈
X
1
(
x
?
μ
1
)
(
x
?
μ
1
)
T
\begin{aligned} \mathbf{S}_{w} &=\boldsymbol{\Sigma}_{0}+\boldsymbol{\Sigma}_{1} \\ &=\sum_{\boldsymbol{x} \in X_{0}}\left(\boldsymbol{x}-\boldsymbol{\mu}_{0}\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_{0}\right)^{\mathrm{T}}+\sum_{\boldsymbol{x} \in X_{1}}\left(\boldsymbol{x}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}} \end{aligned}
Sw??=Σ0?+Σ1?=x∈X0?∑?(x?μ0?)(x?μ0?)T+x∈X1?∑?(x?μ1?)(x?μ1?)T?
“類間散度矩陣”(between-class scatter matrix):
S
b
=
(
μ
0
?
μ
1
)
(
μ
0
?
μ
1
)
T
\mathbf{S}_{b}=\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}}
Sb?=(μ0??μ1?)(μ0??μ1?)T
然后我們的
J
J
J可以表示為
J
=
w
T
S
b
w
w
T
S
w
w
J=\frac{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}}
J=wTSw?wwTSb?w?
這樣看起來簡單多了,這就是我們的LDA想要最大化的目標函式,比較專業的說法為,
S
b
S_b
Sb?和
S
w
S_w
Sw?的“廣義瑞利商”(generalizad Rayleigh quotient),
關于“廣義瑞利商”(generalizad Rayleigh quotient)的解釋,可以參考這里和這里,
瑞利商經常出現在降維和聚類任務中,因為降維聚類任務往往能匯出最大化最小化瑞利熵的式子,進而通過特征值分解的方式找到降維空間,
大體內容如下:
下面開始構建我們的函式及約束條件,

首先得確定我們的
w
w
w,由于
J
J
J的分母分子都是關于
w
w
w的二項式子,則與
w
w
w的長度無關,且只與方向有關,故我們令
w
T
S
w
w
=
1
\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}=1
wTSw?w=1,則:
min
?
w
?
w
T
S
b
w
s.t.
w
T
S
w
w
=
1
\begin{array}{ll} \min _{\boldsymbol{w}} & -\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w} \\ \text { s.t. } & \boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}=1 \end{array}
minw? s.t. ??wTSb?wwTSw?w=1?
由拉格朗日乘數法(具體可參考CCA中Lagrange的應用)可得,
S
b
w
=
λ
S
w
w
(*)
\boldsymbol{S_bw=\lambda S_w w}\tag{*}
Sb?w=λSw?w(*)
其中, λ \lambda λ為拉格朗日乘子,
由上“類間散度矩陣”可知,
S
b
w
\boldsymbol{S_bw}
Sb?w為
μ
0
?
μ
1
\mu_0-\mu_1
μ0??μ1?的平方,故
S
b
w
\boldsymbol{S_bw}
Sb?w的方向則恒為
μ
0
?
μ
1
\mu_0-\mu_1
μ0??μ1?,向量的方向可以確定了,我們再令
S
b
w
=
λ
(
μ
0
?
μ
1
)
\boldsymbol{S_bw=\lambda (\mu_0-\mu_1)}
Sb?w=λ(μ0??μ1?)
向量方向確定, λ \lambda λ只是代表方向向量的長度,所以 S b w \boldsymbol{S_bw} Sb?w可由上式表達,可能會有人疑惑了,這里的 λ \lambda λ和(*)式的 λ \lambda λ是一個 λ \lambda λ嗎?
答案是肯定的,
將上式代入(*)式,可得關于
S
w
\boldsymbol{S_w}
Sw?的式子:
w
=
S
w
?
1
(
μ
0
?
μ
1
)
\boldsymbol{w=S_w^{-1}(\mu_0-\mu_1)}
w=Sw?1?(μ0??μ1?)
這里需要對
S
w
\boldsymbol{S_w}
Sw?求逆,考慮到數值解的穩定性,常規實踐操作中,需要對
S
w
\boldsymbol{S_w}
Sw?進行奇異值分解(也就是我們在矩陣理論中學到的SVD方法),原理很簡單,此處,即為
S
w
=
U
Σ
V
T
\boldsymbol{S_w=U\Sigma V^{T}}
Sw?=UΣVT,其中
Σ
\Sigma
Σ是一個實對角矩陣,對角線上的元素也就是所謂的“跡”是
S
w
\boldsymbol{S_w}
Sw?的奇異值,我們需要求解的是
S
w
\boldsymbol{S_w}
Sw?的逆,故式子變為了這樣,
S
w
?
1
=
V
Σ
?
1
U
T
\boldsymbol{S_w^{-1}=V\Sigma^{-1} U^{T}}
Sw?1?=VΣ?1UT
至此,我們得到了
S
w
?
1
\boldsymbol{S_w^{-1}}
Sw?1?,從而可求得直線向量
w
w
w,找到使得
J
J
J 最大的
w
w
w.
LDA還可從貝葉斯決策理論的角度來描述(關于貝葉斯可參考這里),可證明,當兩類資料同先驗、滿足高斯分布(正態分布)且協方差相等時,LDA可以達到最優的分類效果,
上述講了這么多都是二分類問題,那么關于多分類任務,
具體線性判別分析LDA和Fisher判別分析原理及推廣可看 —> 這里
典型相關分析(CCA)
從字面意義上理解CCA,我們可以知道,簡單說來就是對不同變數之間做相關分析,較為專業的說就是,一種度量兩組變數之間相關程度的多元統計方法,
關于相似性度量距離問題,在這里有一篇Blog可以參考參考,
首先,從基本的入手,
當我們需要對兩個變數 X , Y X,Y X,Y進行相關關系分析時,則常常會用到相關系數來反映,學過概率統計的小伙伴應該都知道的吧,還是解釋一下,
相關系數:是一種用以反映變數之間相關關系密切程度的統計指標,相關系數是按積差方法計算,同樣以兩變數與各自平均值的離差為基礎,通過兩個離差相乘來反映兩變數之間相關程度;著重研究線性的單相關系數,
R ( X , Y ) = Cov ? ( X , Y ) Var ? [ X ] Var ? [ Y ] R(X, Y)=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}[X] \operatorname{Var}[Y]}} R(X,Y)=Var[X]Var[Y] ?Cov(X,Y)?
其中, C o v ( X , Y ) Cov(X,Y) Cov(X,Y)表示 X , Y X,Y X,Y的協方差矩陣, V a r [ X ] Var[X] Var[X]為 X X X的方差, V a r [ Y ] Var[Y] Var[Y]為 Y Y Y的方差.
復習了一下大學本科概率統計知識,那么,如果我們需要分析的物件是兩組或者多組向量,又該怎么做呢?
CCA的數學表達:
這里舉例兩組變數
A
(
a
1
,
a
2
,
.
.
.
,
a
n
)
,
B
(
b
1
,
b
2
,
.
.
.
,
b
m
)
A(a_1,a_2,...,a_n),B(b_1,b_2,...,b_m)
A(a1?,a2?,...,an?),B(b1?,b2?,...,bm?),那么我們的公式會是這樣:
R
(
X
i
,
Y
j
)
=
∑
i
=
1
,
j
=
1
n
,
m
C
o
v
(
X
i
,
Y
j
)
V
a
r
[
X
i
]
V
a
r
[
Y
j
]
R(X_i,Y_j)=\sum_{i=1,j=1}^{n,m} \frac{Cov(X_i,Y_j)}{\sqrt{Var[X_i]Var[Y_j]}}
R(Xi?,Yj?)=i=1,j=1∑n,m?Var[Xi?]Var[Yj?]
?Cov(Xi?,Yj?)?
我們會得到一個這樣的矩陣:
[
R
(
X
1
,
Y
1
)
.
.
.
R
(
X
1
,
Y
m
?
1
)
R
(
X
1
,
Y
m
)
R
(
X
2
,
Y
1
)
.
.
.
R
(
X
2
,
Y
m
?
1
)
R
(
X
2
,
Y
m
)
.
.
.
.
.
.
.
.
.
.
.
.
R
(
X
n
,
Y
1
)
.
.
.
.
.
.
R
(
X
n
,
Y
m
)
]
\begin{bmatrix} R(X_1,Y_1) &... & R(X_1,Y_{m-1}) & R(X_1,Y_m)\\R(X_2,Y_1) & ...& R(X_2,Y_{m-1})& R(X_2,Y_m)\\ ...& ...& ...&... \\ R(X_n,Y_1) & ...& ...&R(X_n,Y_m) \end{bmatrix}
?????R(X1?,Y1?)R(X2?,Y1?)...R(Xn?,Y1?)?............?R(X1?,Ym?1?)R(X2?,Ym?1?)......?R(X1?,Ym?)R(X2?,Ym?)...R(Xn?,Ym?)??????
這樣的話,我們把每個變數的相關系數都求了出來,不知道會不會和我一樣覺得這樣很繁瑣呢,如果我們能找到兩組變數之間的各自的線性組合,那么我們就只分析討論線性組合之間的相關分析,
典型相關系數:是先對原來各組變數進行主成分分析,得到新的線性關系的綜合指標,再通過綜合指標之間的線性相關系數來研究原各組變數間相關關系,
現在我們利用主成分分析(PCA)的思想,可以把多個變數與多個變數之間的相關轉化成兩個變數之間的相關,
先得到兩組變數
(
A
T
,
B
T
)
(A^T,B^T)
(AT,BT)的協方差矩陣
Σ
=
[
Σ
11
Σ
12
Σ
21
Σ
22
]
\Sigma=\left[\begin{array}{l} \Sigma_{11} \ \Sigma_{12} \\ \Sigma_{21} \ \Sigma_{22} \end{array}\right]
Σ=[Σ11? Σ12?Σ21? Σ22??]
其中,
Σ
11
=
C
o
v
(
A
)
,
Σ
22
=
C
o
v
(
B
)
,
Σ
12
=
Σ
12
T
=
C
o
v
(
A
,
B
)
\Sigma_{11} = Cov(A),\Sigma_{22} = Cov(B),\Sigma_{12}=\Sigma_{12}^T = Cov(A,B)
Σ11?=Cov(A),Σ22?=Cov(B),Σ12?=Σ12T?=Cov(A,B).
把上面兩組變數
A
(
a
1
,
a
2
,
.
.
.
,
a
n
)
,
B
(
b
1
,
b
2
,
.
.
.
,
b
m
)
A(a_1,a_2,...,a_n),B(b_1,b_2,...,b_m)
A(a1?,a2?,...,an?),B(b1?,b2?,...,bm?)分別組合成兩個變數U、V,則用線性表示
U
=
t
1
a
1
+
t
2
a
2
+
.
.
.
+
t
n
a
n
,
V
=
h
1
b
1
+
h
2
b
2
+
.
.
.
+
h
m
b
m
\begin{matrix} U=t_1a_1+t_2a_2+...+t_na_n,\\ \\V=h_1b_1+h_2b_2+...+h_mb_m \end{matrix}
U=t1?a1?+t2?a2?+...+tn?an?,V=h1?b1?+h2?b2?+...+hm?bm??
然后,找出最大可能的相關系數 t k = ( t 1 , t 2 , . . . , t n ) T , h k = ( h 1 , h 2 , . . . , h m ) T {t_k}=(t_1,t_2,...,t_n)^T,{h_k}=(h_1,h_2,...,h_m)^T tk?=(t1?,t2?,...,tn?)T,hk?=(h1?,h2?,...,hm?)T,
使得, R ( U , V ) ? M a x R(U,V)\longrightarrow Max R(U,V)?Max,這樣,就得到了典型相關系數;而其中的 U , V U,V U,V 為典型相關變數,
典型相關分析最樸素的思想:首先分別在每組變數中找出第一對典型變數,使其具有最大相關性,然后在每組變數中找出第二對典型變數,使其分別與本組內的第一對典型變數不相關,第二對本身具有次大的相關性,如此下去,直到進行到K步,兩組變數的相關系被提取完為止,可以得到K組變數,
So,
注意:此時的 ( U , V ) (U,V) (U,V)若不能反映兩組變數之間的相關關系,我們需要繼續構造下一組關系變數來表示,具體可構造 K K K對這樣的關系
直到
R
(
U
,
V
)
?
M
a
x
R(U,V)\longrightarrow Max
R(U,V)?Max為止
U
k
=
t
k
T
A
=
t
1
k
a
1
+
t
2
k
a
2
+
.
.
.
+
t
n
k
a
n
V
k
=
h
k
T
B
=
h
1
k
b
1
+
h
2
k
b
2
+
.
.
.
+
h
m
k
b
m
\begin{matrix} U_k={t_k^T}{A}=t_{1k}a_1+t_{2k}a_2+...+t_{nk}a_n\\ \\ V_k={h_k^T}{B}=h_{1k}b_1+h_{2k}b_2+...+h_{mk}b_m \end{matrix}
Uk?=tkT?A=t1k?a1?+t2k?a2?+...+tnk?an?Vk?=hkT?B=h1k?b1?+h2k?b2?+...+hmk?bm??
其中,我們需要一個約束條件滿足,使得 R ( U , V ) ? M a x R(U,V)\longrightarrow Max R(U,V)?Max
V
a
r
(
U
k
)
=
V
a
r
(
t
k
T
A
)
=
t
k
T
Σ
11
t
k
=
1
V
a
r
(
V
k
)
=
V
a
r
(
h
k
T
A
)
=
h
k
T
Σ
22
h
k
=
1
C
o
v
(
U
k
,
U
i
)
=
C
o
v
(
U
k
,
V
i
)
=
C
o
v
(
V
i
,
U
k
)
=
C
o
v
(
V
k
,
V
i
)
=
0
(
1
<
=
i
<
k
)
\begin{matrix} Var(U_k)=Var({t_k^T}{A})={t_k^T}\Sigma_{11}t_k=1\\ \\ Var(V_k)=Var({h_k^T}{A})={h_k^T}\Sigma_{22}h_k=1\\ \\ Cov(U_k,U_i)=Cov(U_k,V_i)=Cov(V_i,U_k)=Cov(V_k,V_i)=0(1<=i<k) \end{matrix}
Var(Uk?)=Var(tkT?A)=tkT?Σ11?tk?=1Var(Vk?)=Var(hkT?A)=hkT?Σ22?hk?=1Cov(Uk?,Ui?)=Cov(Uk?,Vi?)=Cov(Vi?,Uk?)=Cov(Vk?,Vi?)=0(1<=i<k)?
典型相關系數公式
R
(
U
,
V
)
R_{(U,V)}
R(U,V)?
R
(
U
,
V
)
=
Cov
?
(
U
,
V
)
Var
?
[
U
]
Var
?
[
V
]
=
C
o
v
(
U
,
V
)
=
t
k
T
C
o
v
(
A
,
B
)
h
k
=
t
k
T
Σ
12
h
k
R_{(U,V)}=\frac{\operatorname{Cov}(U, V)}{\sqrt{\operatorname{Var}[U] \operatorname{Var}[V]}}=Cov(U,V)={t_k}^TCov(A,B)h_k={t_k}^T\Sigma_{12} h_k
R(U,V)?=Var[U]Var[V]
?Cov(U,V)?=Cov(U,V)=tk?TCov(A,B)hk?=tk?TΣ12?hk?
在此約束條件下, t k , h k t_k,h_k tk?,hk?系數得到最大,則使得 R ( U , V ) R_{(U,V)} R(U,V)?最大,
具體典型相關分析CCA演算法及故障診斷應用可看 —> 這里
慢特征分析(SFA)
給定一個 i 維輸入信號 x ( t ) = [ x 1 ( t ) , … , x I ( t ) ] T \mathbf{x}(t)=\left[x_{1}(t), \ldots, x_{I}(t)\right]^{T} x(t)=[x1?(t),…,xI?(t)]T,考慮一個輸入-輸出函式 g ( x ) = [ g 1 ( x ) , … , g J ( x ) ] T \mathbf{g}(\mathbf{x})=\left[g_{1}(\mathbf{x}), \ldots, g_{J}(\mathbf{x})\right]^{T} g(x)=[g1?(x),…,gJ?(x)]T,每個分量都是一組K個非線性函式的加權和 h k ( x ) : g j ( x ) : = ∑ k = 1 K w j k h k ( x ) h_{k}(\mathbf{x}): g_{j}(\mathbf{x}):=\sum_{k=1}^{K}w_{j k} h_{k}(\mathbf{x}) hk?(x):gj?(x):=∑k=1K?wjk?hk?(x),通常K > max(I, J),應用 h = [ h 1 , … , h K ] T \mathbf{h}=\left[h_{1}, \ldots, h_{K}\right]^{T} h=[h1?,…,hK?]T對輸入信號產生非線性擴展信號 z ( t ) : = h ( x ( t ) ) \mathbf{z}(t):=\mathbf{h}(\mathbf{x}(t)) z(t):=h(x(t)),經過這種非線性展開后,可以將該問題在擴展的信號分量 z k ( t ) z_k(t) zk?(t)中視為線性問題,這是將非線性問題轉化為線性問題的常用方法,一個眾所周知的例子是支持向量機(Vapnik, 1995),權向量 w j = [ w j 1 , … , w j K ] T \mathbf{w}_{j}=\left[w_{j 1}, \ldots, w_{j K}\right]^{T} wj?=[wj1?,…,wjK?]T進行學習,第j個輸出信號分量由 y j ( t ) = g j ( x ( t ) ) = w j T h ( x ( t ) ) = w j T z ( t ) y_{j}(t)=g_{j}(\mathbf{x}(t))=\mathbf{w}_{j}^{T} \mathbf{h}(\mathbf{x}(t))=\mathbf{w}_{j}^{T} \mathbf{z}(t) yj?(t)=gj?(x(t))=wjT?h(x(t))=wjT?z(t)給出,
目標(見方程1)是優化輸入-輸出函式,從而使權值達到
Δ
(
y
j
)
=
?
y
˙
j
2
?
=
w
j
T
?
z
˙
z
˙
T
?
w
j
\Delta\left(y_{j}\right)=\left\langle\dot{y}_{j}^{2}\right\rangle=\mathbf{w}_{j}^{T}\left\langle\dot{\mathbf{z}} \dot{\mathbf{z}}^{T}\right\rangle \mathbf{w}_{j}
Δ(yj?)=?y˙?j2??=wjT??z˙z˙T?wj? (3.1)
是最小的,
假設所選擇的非線性函式hkare使擴展信號z(t)具有零均值和單位協方差矩陣,這樣一組非線性函式 h k h_k hk?可以很容易地通過一個球階從任意集合 h k ′ h_{k}^{\prime} hk′?中匯出,如下所述,然后我們發現約束條件(見公式2-4)
? y j ? = w j T ? z ? ? = 0 = 0 , ( 3.2 ) ? y j 2 ? = w j T ? z z T ? ? = I w j = w j T w j = 1 ( 3.3 ) , ? j ′ < j : ? y j ′ y j ? = w j ′ T ? z z T ? ? = I w j = w j ′ T w j = 0 , ( 3.4 ) \begin{array}{r} \left\langle y_{j}\right\rangle = \mathbf{w}_{j}^{T} \underbrace{\langle\mathbf{z}\rangle}_{ = 0} = 0, (3.2)\\ \left\langle y_{j}^{2}\right\rangle = \mathbf{w}_{j}^{T} \underbrace{\left\langle\mathbf{z z}^{T}\right\rangle}_{ = \mathbf{I}} \mathbf{w}_{j} = \mathbf{w}_{j}^{T} \mathbf{w}_{j} = 1 (3.3), \\ \forall j^{\prime}<j: \quad\left\langle y_{j^{\prime}} y_{j}\right\rangle = \mathbf{w}_{j^{\prime}}^{T} \underbrace{\left\langle\mathbf{z z}^{T}\right\rangle}_{ = \mathbf{I}} \mathbf{w}_{j} = \mathbf{w}_{j^{\prime}}^{T} \mathbf{w}_{j} = 0, (3.4) \end{array} ?yj??=wjT?=0 ?z???=0,(3.2)?yj2??=wjT?=I ?zzT???wj?=wjT?wj?=1(3.3),?j′<j:?yj′?yj??=wj′T?=I ?zzT???wj?=wj′T?wj?=0,(3.4)?
當且僅當我們約束權重向量為向量的標準正交集時,自動滿足,
因此,對于輸入輸出函式的第一個分量,優化問題簡化為尋找使方程(3.1)中的 Δ ( y 1 ) \Delta\left(y_{1}\right) Δ(y1?)最小的賦范權向量,解是矩陣 ? z ˙ z ˙ T ? \left\langle\dot{\mathbf{z}} \dot{\mathbf{z}}^{T}\right\rangle ?z˙z˙T?的賦范特征向量,它對應于最小的特征值(cf. Mitchison, 1991),下一個更高的特征值的特征向量產生輸入-輸出函式的下一個分量與下一個更高的1個值,這就引出了解決上述優化問題的演算法,
明確區分原始信號、來自訓練資料的精確歸一化信號和來自測驗資料的近似歸一化信號是有用的,設 x ~ ( t ) \tilde{\mathbf{x}}(t) x~(t)是一個可以有任意均值和方差的原始輸入信號,為了計算方便和顯示的目的,信號被歸一化為零的平均值和單位方差,這種歸一化對訓練資料x(t)是精確的,用相同的偏移量和因子來校正測驗資料,通常會得到一個近似歸一化的輸入信號 x ′ ( t ) \mathbf{x}^{\prime}(t) x′(t),因為每個資料樣本的均值和方差略有不同,而歸一化總是使用從訓練資料中確定的偏移量和因子來完成,在下面,原始信號有一個波浪線,測驗資料有一個破折號;沒有波浪線或破折號的符號通常(但不總是)指的是規范化訓練資料,
該演算法現在有如下形式(參見下圖):
- 輸入信號,用于訓練,i維輸入信號為 x ~ ( t ) \tilde{\mathbf{x}}(t) x~(t),
- 輸入信號歸一化,對輸入信號進行歸一化得到
x ( t ) : = [ x 1 ( t ) , … , x I ( t ) ] T ( 3.5 ) with x i ( t ) : = x ~ i ( t ) ? ? x ~ i ? ? ( x ~ i ? ? x ~ i ? ) 2 ? , ( 3.6 ) so that ? x i ? = 0 ( 3.7 ) and ? x i 2 ? = 1 ( 3.8 ) \begin{aligned} \mathbf{x}(t) &:=\left[x_{1}(t), \ldots, x_{I}(t)\right]^{T} (3.5)\\ \text { with } \quad x_{i}(t) &:=\frac{\tilde{x}_{i}(t)-\left\langle\tilde{x}_{i}\right\rangle}{\sqrt{\left\langle\left(\tilde{x}_{i}-\left\langle\tilde{x}_{i}\right\rangle\right)^{2}\right\rangle}}, (3.6) \\ \text { so that } \quad\left\langle x_{i}\right\rangle &=0 (3.7)\\ \text { and } \quad\left\langle x_{i}^{2}\right\rangle &=1 (3.8) \end{aligned} x(t) with xi?(t) so that ?xi?? and ?xi2???:=[x1?(t),…,xI?(t)]T(3.5):=?(x~i???x~i??)2? ?x~i?(t)??x~i???,(3.6)=0(3.7)=1(3.8)?
- 非線性擴張,應用一組非線性函式 h ~ ( x ) \tilde{\mathbf{h}}(\mathbf{x}) h~(x),生成擴展信號 z ~ ( t ) \tilde{\mathbf{z}}(t) z~(t),這里使用了一次的所有單項式(導致線性 S F A SFA SFA有時用 S F A 1 SFA_1 SFA1?表示)或一次和兩次的單項式,包括混合項,如 x 1 x 2 x_1x_2 x1?x2?(導致二次SFA有時用 S F A 2 SFA_2 SFA2?表示),但也可以使用任何其他的函式集,因此對于二次 S F A SFA SFA,
h ~ ( x ) : = [ x 1 , … , x I , x 1 x 1 , x 1 x 2 , … , x I x I ] T ( 3.9 ) z ~ ( t ) : = h ~ ( x ( t ) ) = [ x 1 ( t ) , … , x I ( t ) , x 1 ( t ) x 1 ( t ) , x 1 ( t ) x 2 ( t ) , … , x I ( t ) x I ( t ) ] T ( 3.10 ) \begin{aligned} \tilde{\mathbf{h}}(\mathbf{x}):=&\left[x_{1}, \ldots, x_{I}, x_{1} x_{1}, x_{1} x_{2}, \ldots, x_{I} x_{I}\right]^{T} (3.9) \\ \tilde{\mathbf{z}}(t):=\tilde{\mathbf{h}}(\mathbf{x}(t))=&\left[x_{1}(t), \ldots, x_{I}(t), x_{1}(t) x_{1}(t),\right.\\ &\left.x_{1}(t) x_{2}(t), \ldots, x_{I}(t) x_{I}(t)\right]^{T} (3.10) \end{aligned} h~(x):=z~(t):=h~(x(t))=?[x1?,…,xI?,x1?x1?,x1?x2?,…,xI?xI?]T(3.9)[x1?(t),…,xI?(t),x1?(t)x1?(t),x1?(t)x2?(t),…,xI?(t)xI?(t)]T(3.10)?
屬于
h
~
(
x
)
\tilde{\mathbf{h}}(\mathbf{x})
h~(x)和屬于
z
~
(
t
)
\tilde{\mathbf{z}}(\mathbf{t})
z~(t)的一、二度分量詞的維數為
K
=
I
+
I
(
I
+
1
)
/
2
K = I + I(I + 1)/2
K=I
標籤:python
- 標籤雲
-
其他(157675) Python(38076) JavaScript(25376) Java(17977) C(15215) 區塊鏈(8255) C#(7972) AI(7469) 爪哇(7425) MySQL(7132) html(6777) 基礎類(6313) sql(6102) 熊猫(6058) PHP(5869) 数组(5741) R(5409) Linux(5327) 反应(5209) 腳本語言(PerlPython)(5129) 非技術區(4971) Android(4554) 数据框(4311) css(4259) 节点.js(4032) C語言(3288) json(3245) 列表(3129) 扑(3119) C++語言(3117) 安卓(2998) 打字稿(2995) VBA(2789) Java相關(2746) 疑難問題(2699) 细绳(2522) 單片機工控(2479) iOS(2429) ASP.NET(2402) MongoDB(2323) 麻木的(2285) 正则表达式(2254) 字典(2211) 循环(2198) 迅速(2185) 擅长(2169) 镖(2155) 功能(1967) .NET技术(1958) Web開發(1951) python-3.x(1918) HtmlCss(1915) 弹簧靴(1913) C++(1909) xml(1889) PostgreSQL(1872) .NETCore(1853) 谷歌表格(1846) Unity3D(1843) for循环(1842)
- 熱門瀏覽
-
-
Codeforces 1400E Clear the Multiset(貪心 + 分治)
鏈接:https://codeforces.com/problemset/problem/1400/E 來源:Codeforces 思路:給你一個陣列,現在你可以進行兩種操作,操作1:將一段沒有 0 的區間進行減一的操作,操作2:將 i 位置上的元素歸零。最終問:將這個陣列的全部元素歸零后操作的最少 ......
uj5u.com 2020-09-10 00:57:30 more -
UVA11610 【Reverse Prime】
本人看到此題沒有翻譯,就附帶了一個自己的翻譯版本 思考 這一題,它的第一個要求是找出所有 $7$ 位反向質數及其質因數的個數。 我們應該需要質數篩篩選1~$10^{7}$的所有數,這里就不慢慢介紹了。但是,重讀題,我們突然發現反向質數都是 $7$ 位,而將它反過來后的數字卻是 $6$ 位數,這就說明 ......
uj5u.com 2020-09-10 00:57:36 more -
C/C++編程筆記:C++中的 const 變數詳解,教你正確認識const用法
1、C中的const 1、區域const變數存放在堆疊區中,會分配記憶體(也就是說可以通過地址間接修改變數的值)。測驗代碼如下: 運行結果: 2、全域const變數存放在只讀資料段(不能通過地址修改,會發生寫入錯誤), 默認為外部聯編,可以給其他源檔案使用(需要用extern關鍵字修飾) 運行結果: ......
uj5u.com 2020-09-10 00:58:04 more -
【C++犯錯記錄】VS2019 MFC添加資源不懂如何修改資源宏ID
1. 首先在資源視圖中,添加資源 2. 點擊新添加的資源,復制自動生成的ID 3. 在解決方案資源管理器中找到Resource.h檔案,編輯,使用整個專案搜索和替換的方式快速替換 宏宣告 4. Ctrl+Shift+F 全域搜索,點擊查找全部,然后逐個替換 5. 為什么使用搜索替換而不使用屬性視窗直 ......
uj5u.com 2020-09-10 00:59:11 more -
【C++犯錯記錄】VS2019 MFC不懂的批量添加資源
1. 打開資源頭檔案Resource.h,在其中預先定義好宏 ID(不清楚其實ID值應該設定多少,可以先新建一個相同的資源項,再在這個資源的ID值的基礎上遞增即可) 2. 在資源視圖中選中專案資源,按F7編輯資源檔案,按 ID 型別 相對路徑的形式添加 資源。(別忘了先把檔案拷貝到專案中的res檔案 ......
uj5u.com 2020-09-10 01:00:19 more -
C/C++編程筆記:關于C++的參考型別,專供新手入門使用
今天要講的是C++中我最喜歡的一個用法——參考,也叫別名。 參考就是給一個變數名取一個變數名,方便我們間接地使用這個變數。我們可以給一個變數創建N個參考,這N + 1個變數共享了同一塊記憶體區域。(參考型別的變數會占用記憶體空間,占用的記憶體空間的大小和指標型別的大小是相同的。雖然參考是一個物件的別名,但 ......
uj5u.com 2020-09-10 01:00:22 more -
【C/C++編程筆記】從頭開始學習C ++:初學者完整指南
眾所周知,C ++的學習曲線陡峭,但是花時間學習這種語言將為您的職業帶來奇跡,并使您與其他開發人員區分開。您會更輕松地學習新語言,形成真正的解決問題的技能,并在編程的基礎上打下堅實的基礎。 C ++將幫助您養成良好的編程習慣(即清晰一致的編碼風格,在撰寫代碼時注釋代碼,并限制類內部的可見性),并且由 ......
uj5u.com 2020-09-10 01:00:41 more
- 最新发布
-
-
Rust中的智能指標:Box<T> Rc<T> Arc<T> Cell<T> RefCell<T> Weak
Rust中的智能指標是什么 智能指標(smart pointers)是一類資料結構,是擁有資料所有權和額外功能的指標。是指標的進一步發展 指標(pointer)是一個包含記憶體地址的變數的通用概念。這個地址參考,或 ” 指向”(points at)一些其 他資料 。參考以 & 符號為標志并借用了他們所 ......
uj5u.com 2023-04-20 07:24:10 more -
Java的值傳遞和參考傳遞
值傳遞不會改變本身,參考傳遞(如果傳遞的值需要實體化到堆里)如果發生修改了會改變本身。 1.基本資料型別都是值傳遞 package com.example.basic; public class Test { public static void main(String[] args) { int ......
uj5u.com 2023-04-20 07:24:04 more -
[2]SpinalHDL教程——Scala簡單入門
第一個 Scala 程式 shell里面輸入 $ scala scala> 1 + 1 res0: Int = 2 scala> println("Hello World!") Hello World! 檔案形式 object HelloWorld { /* 這是我的第一個 Scala 程式 * 以 ......
uj5u.com 2023-04-20 07:23:58 more -
理解函式指標和回呼函式
理解 函式指標 指向函式的指標。比如: 理解函式指標的偽代碼 void (*p)(int type, char *data); // 定義一個函式指標p void func(int type, char *data); // 宣告一個函式func p = func; // 將指標p指向函式func ......
uj5u.com 2023-04-20 07:23:52 more -
Django筆記二十五之資料庫函式之日期函式
本文首發于公眾號:Hunter后端 原文鏈接:Django筆記二十五之資料庫函式之日期函式 日期函式主要介紹兩個大類,Extract() 和 Trunc() Extract() 函式作用是提取日期,比如我們可以提取一個日期欄位的年份,月份,日等資料 Trunc() 的作用則是截取,比如 2022-0 ......
uj5u.com 2023-04-20 07:23:45 more -
一天吃透JVM面試八股文
什么是JVM? JVM,全稱Java Virtual Machine(Java虛擬機),是通過在實際的計算機上仿真模擬各種計算機功能來實作的。由一套位元組碼指令集、一組暫存器、一個堆疊、一個垃圾回收堆和一個存盤方法域等組成。JVM屏蔽了與作業系統平臺相關的資訊,使得Java程式只需要生成在Java虛擬機 ......
uj5u.com 2023-04-20 07:23:31 more -
使用Java接入小程式訂閱訊息!
更新完微信服務號的模板訊息之后,我又趕緊把微信小程式的訂閱訊息給實作了!之前我一直以為微信小程式也是要企業才能申請,沒想到小程式個人就能申請。 訊息推送平臺🔥推送下發【郵件】【短信】【微信服務號】【微信小程式】【企業微信】【釘釘】等訊息型別。 https://gitee.com/zhongfuch ......
uj5u.com 2023-04-20 07:22:59 more -
java -- 緩沖流、轉換流、序列化流
緩沖流 緩沖流, 也叫高效流, 按照資料型別分類: 位元組緩沖流:BufferedInputStream,BufferedOutputStream 字符緩沖流:BufferedReader,BufferedWriter 緩沖流的基本原理,是在創建流物件時,會創建一個內置的默認大小的緩沖區陣列,通過緩沖 ......
uj5u.com 2023-04-20 07:22:49 more -
Java-SpringBoot-Range請求頭設定實作視頻分段傳輸
老實說,人太懶了,現在基本都不喜歡寫筆記了,但是網上有關Range請求頭的文章都太水了 下面是抄的一段StackOverflow的代碼...自己大修改過的,寫的注釋挺全的,應該直接看得懂,就不解釋了 寫的不好...只是希望能給視頻網站開發的新手一點點幫助吧. 業務場景:視頻分段傳輸、視頻多段傳輸(理 ......
uj5u.com 2023-04-20 07:22:42 more -
Windows 10開發教程_編程入門自學教程_菜鳥教程-免費教程分享
教程簡介 Windows 10開發入門教程 - 從簡單的步驟了解Windows 10開發,從基本到高級概念,包括簡介,UWP,第一個應用程式,商店,XAML控制元件,資料系結,XAML性能,自適應設計,自適應UI,自適應代碼,檔案管理,SQLite資料庫,應用程式到應用程式通信,應用程式本地化,應用程式 ......
uj5u.com 2023-04-20 07:22:35 more
-
- 友情鏈接