scrapy 中的 settings.py 檔案在專案中是非常重要的,因其包含非常多的配置,
這篇博客基于官方手冊為你說明 settings.py 檔案相關配置,并補充一些擴展說明,
settings 的 4 個級別
- 優先級最高 - 命令列,例如
scrapy crawl my_spider -s LOG_LEVEL=WARNINI; - 優先級第二 - 爬蟲檔案自己的設定,例如在
xxx.py檔案中設定custom_settings; - 優先級第三 - 專案模塊,這里指的是
settings.py檔案中的配置; - 優先級第四 -
default_settings屬性配置; - 優先級第五 -
default_settings.py檔案中的配置,
settings配置的讀取,一般使用spider中的from_crawler方法,在中間件,管道,擴展中都可以進行呼叫,
settings 配置讀取操作非常簡單,上一篇博客已經有所涉及,命令格式如下所示:
scrapy settings --get 配置變數名稱
settings 常用配置
基本配置
BOT_NAME:爬蟲名稱;SPIDER_MODULES:爬蟲模塊串列;NEWSPIDER_MODULE:模塊在哪里使用genspider命令創建新的爬蟲;
日志
scrapy 日志與 logging 模塊一致,使用 5 個級別:
配置名為 LOG_LEVEL,最低的是 DEBUG(默認),INFO,WARNING,ERROR,CRITICAL(最高),
其余日志相關配置如下,
LOGSTATS_INTERVAL:設定日志頻率,默認是 60 秒,可以修改為 5 秒,LOG_FILE:日志檔案;LOG_ENABLED:是否啟用日志,關閉了運行爬蟲,就啥都不輸出了;LOG_ENCODING:編碼;LOG_FORMAT:日志格式,這個可以參考logging模塊學習;LOG_DATEFORMAT:同上,負責格式化日期/時間;
統計
STATS_DUMP:默認開啟,爬蟲采集完畢,將爬蟲運行資訊統計并輸出到日志;DOWNLOADER_STATS:啟用下載中間件統計;DEPTH_STATS和DEPTH_STATS_VERBOSE:統計深度相關設定;STATSMAILER_RCPTS:爬蟲采集完畢,發送郵箱串列,
性能
CONCURRENT_REQUESTS:最大并發請求數,抓取不同網站時使用,該值默認是 16,如果一次請求耗時 0.2 秒,則并發極限是 16/0.2 = 80 次請求CONCURRENT_REQUESTS_PER_DOMAIN和CONCURRENT_REQUESTS_PER_IP:單個域或者單個 IP 的最大并發請求數;CONCURRENT_ITEMS:每次請求并發處理的最大檔案數,如果CONCURRENT_REQUESTS=16,CONCURRENT_ITEMS=100,則表示每秒有 1600 個檔案會被寫入資料庫;DOWNLOAD_TIMEOUT:下載器在超時前等待的時間量;DOWNLOAD_DELAY:下載延遲,限制爬取速度,配合RANDOMIZE_DOWNLOAD_DELAY使用,會使用一個隨機值 *DOWNLOAD_DELAY;CLOSESPIDER_TIMEOUT,CLOSESPIDER_ITEMCOUNT,CLOSESPIDER_PAGECOUNT,CLOSESPIDER_ERRORCOUNT:四個配置比較類似,都是為了提前關閉爬蟲,分別為時間,抓取 item 的數量,發出一定的請求數,發生一定的錯誤量,
抓取相關
USER_AGENT:用戶代理;DEPTH_LIMIT:抓取的最大深度,在深度抓取時有用;ROBOTSTXT_OBEY:是否遵守robots.txt約定;COOKIES_ENABLED:是否禁用 cookie,禁用之后有時能提高采集速度;DEFAULT_REQUEST_HEADERS:請求頭;IMAGES_STORE:使用ImagePipeline時圖片的存盤路徑;IMAGES_MIN_WIDTH和IMAGES_MIN_HEIGHT:篩選圖片;IMAGES_THUMBS:設定縮略圖;FILES_STORE:檔案存盤路徑;FILES_URLS_FIELD與FILES_RESULT_FIELD:使用Files Pipeline時的一些變數名配置;URLLENGTH_LIMIT:允許抓取網站地址的最大長度,
擴展功能
ITEM_PIPELINES:管道配置;COMMANDS_MODULE:自定義命令;DOWNLOADER_MIDDLEWARES:下載中間件;SCHEDULER:調度器;EXTENSIONS:擴展;SPIDER_MIDDLEWARES:爬蟲中間件;RETRY_*:設定了 Retry 相關中間件配置;REDIRECT_*:設定了 Redirect 相關中間件配置;METAREFRESH_*:設定了 Meta-Refresh 中間件相關配置;MEMUSAGE_*:設定了內存相關配置,
settings 配置的一些技巧
- 通用配置寫在專案的
settings.py檔案中; - 爬蟲個性化設定寫在
custom_settings變數內; - 不同進行的爬蟲,配置要初始化在命令列內,
本篇博客的爬蟲案例
這一次的爬蟲就采集藍橋訓練營的課程吧,頁面經過測驗得到的請求地址如下:
https://www.lanqiao.cn/api/v2/courses/?page_size=20&page=2&include=html_url,name,description,students_count,fee_type,picture_url,id,label,online_type,purchase_seconds_info,level
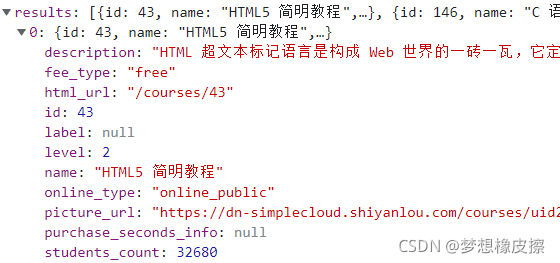
其中引數除了 page_size 和 page 以外,還存在一個 include 引數,這也是介面中常用的一個引數,其值代表介面回傳哪些欄位(包含哪些屬性),如下圖所示,
接下來就使用 scrapy 將其實作,并把結果保存到 json 檔案中,
lanqiao.py 檔案代碼
import json
import scrapy
from lq.items import LqItem
class LanqiaoSpider(scrapy.Spider):
name = 'lanqiao'
allowed_domains = ['lanqiao.cn']
def start_requests(self):
url_format = 'https://www.lanqiao.cn/api/v2/courses/?page_size=20&page={}&include=html_url,name,description,students_count,fee_type,picture_url,id,label,online_type,purchase_seconds_info,level'
for page in range(1, 34):
url = url_format.format(page)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
json_data = json.loads(response.text)
for ret_item in json_data["results"]:
item = LqItem(**ret_item)
yield item
代碼中直接將 ret_item 賦值到了 LqItem 的建構式中,實作對欄位的賦值,
items.py 檔案代碼
該類主要對資料欄位進行限制,
import scrapy
class LqItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
html_url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
students_count = scrapy.Field()
fee_type = scrapy.Field()
picture_url = scrapy.Field()
id = scrapy.Field()
label = scrapy.Field()
online_type = scrapy.Field()
purchase_seconds_info = scrapy.Field()
level = scrapy.Field()
settings.py 開啟部分配置
BOT_NAME = 'lq'
SPIDER_MODULES = ['lq.spiders']
NEWSPIDER_MODULE = 'lq.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 16
DOWNLOAD_DELAY = 3
爬蟲運行結果:
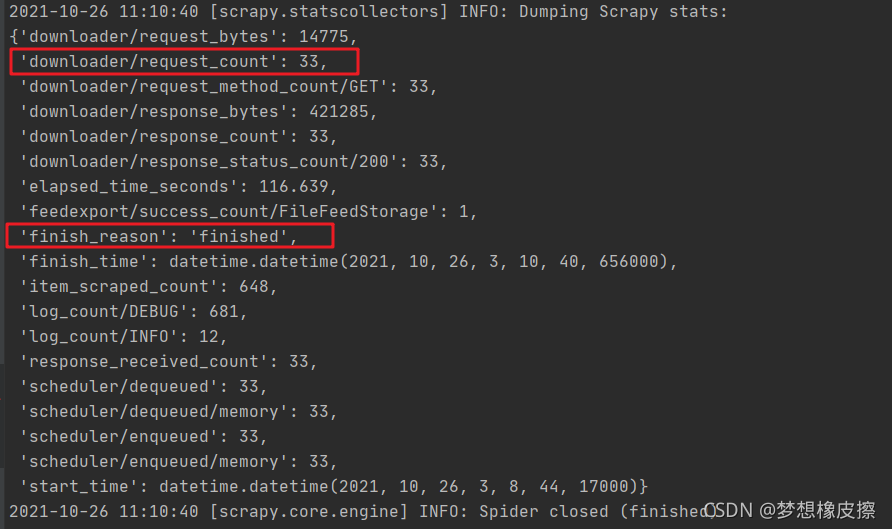
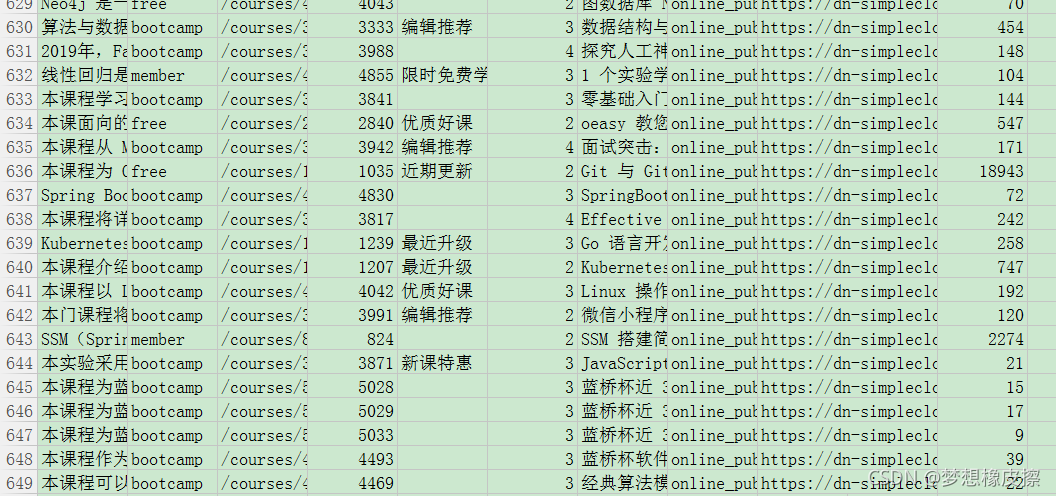
累計爬取到 **600+**課程資訊,
寫在后面
今天是持續寫作的第 254 / 365 天,
期待 關注,點贊、評論、收藏,
更多精彩
《爬蟲 100 例,專欄銷售中,買完就能學會系列專欄》

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/349624.html
標籤:python