一、題目要求

二、題目分析
1、對爬蟲的概述
2、爬取資訊的基本流程
不管是通用的網路爬蟲還是聚焦性爬蟲,其實爬取網頁并且獲取資訊大概按順序分為以下一些步驟:
(1)選擇你想要爬取的網站的網址,和想要的資訊(例如圖片或者文字或者音頻等)
(2)獲取User-Agent,它的作用是將爬蟲偽裝成瀏覽器發送資訊,讓被爬取的網站認為我們是用戶的主觀點擊,而不是一個程式運行的結果,
(3)通過request獲取url,從而得到網頁原始碼,然后在原始碼中查找資料,
(4)獲取網頁回應,這里很重要,也要注意反爬,
(5)通過url獲取網頁源代碼,然后通過正則運算式獲取所需要的資訊
(6)保存獲取的資訊
3、爬蟲的準備流程
在爬蟲中我們常用的庫有BeautifulSoup庫(靚湯),它的作用是決議網頁并且獲取資料;還有re庫,它的作用是對正則運算式的內容進行文字匹配;還有urlib下的request和error,可以定制url獲取網頁原始碼;最后是xlwt或者matplotlib等庫,用于對保存的資料進行可視化處理,
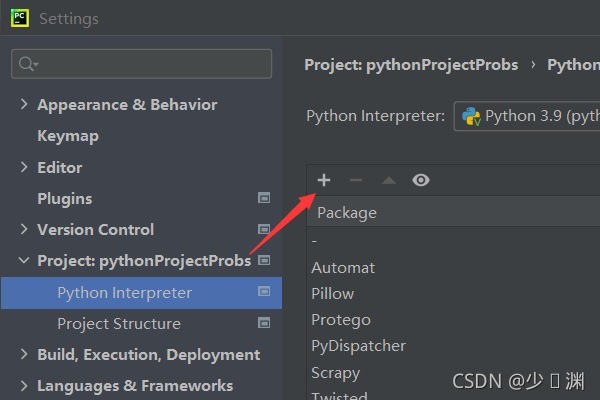
如果您使用的是Pycharm,那么下載這些庫可以通過以下步驟:在pycharm下依次點擊File-->Settings-->Project Interpreter然后可以見到以下界面
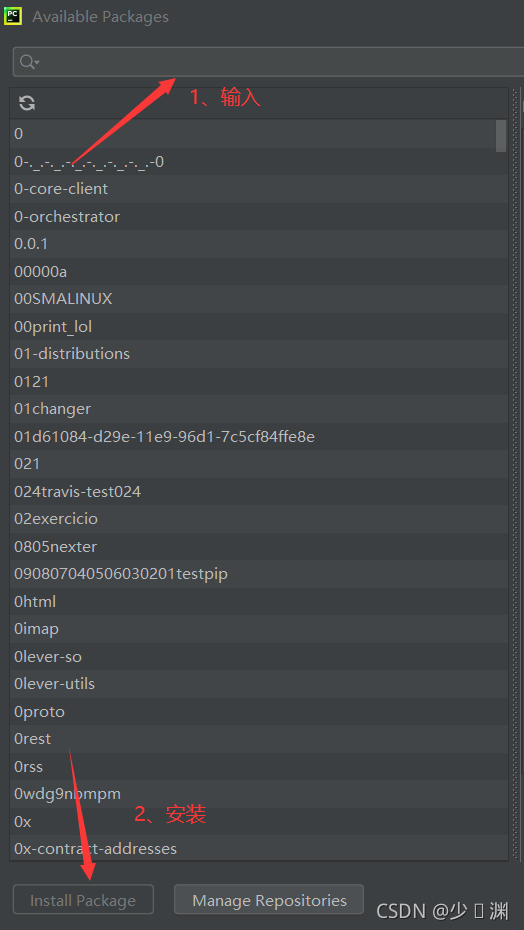
如果您沒有安裝Pycharm,那么可以按下win+R鍵,輸入cmd,在打開的視窗中輸入“pip install 庫名”即可等待它安裝成功,
from bs4 import BeautifulSoup # 網頁決議,獲取資料
import re # 正則運算式,進行文字匹配`
import urllib.request, urllib.error # 制定URL,獲取網頁資料
import xlwt # 進行excel操作
import matplotlib.pyplot as plt4、具體實作程序
為了方便理解,我將代碼分成了幾個部分:主函式部分、撰寫正則運算式部分、獲取URL部分、獲取所需資訊部分和保存資訊或者實作可視化部分,
(1)在主函式中,我們首先需要給定想要爬取的網址,具體方法略,直接搜即可,在這里因為題目要求,我們按照爬取微博為例(主要爬取熱搜排名、熱搜標題、熱搜鏈接、熱搜熱度值),然后通過getData方法獲取儲存著資訊的二維串列;其實在getData里也呼叫了獲取網頁源代碼的askURL的方法,最后指定儲存路徑并通過saveData儲存到Excel中或者通過其他可視化方法呈現,
def main():
baseurl = "https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
datalist = getData(baseurl)
savepath = "D:\PyCharm Community Edition 2020.2.3\微博熱搜50.xls"
saveData(datalist,savepath)
(2)然后所需要做的是撰寫正則運算式:
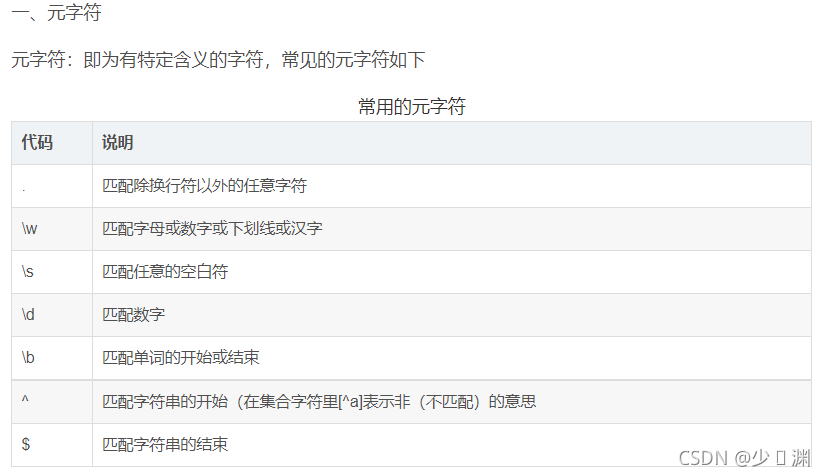
為什么要寫正則運算式呢?是因為在我們通過url獲取到的網頁源代碼里有著幾千行代碼,但是我們所需要的僅僅是一部分,所以正則運算式其實是一種篩選標準,篩選我們所需要的部分,那么什么又是正則運算式呢?這里我不細講,給出幾張圖片和一個鏈接,各位看官自行查閱:正則運算式
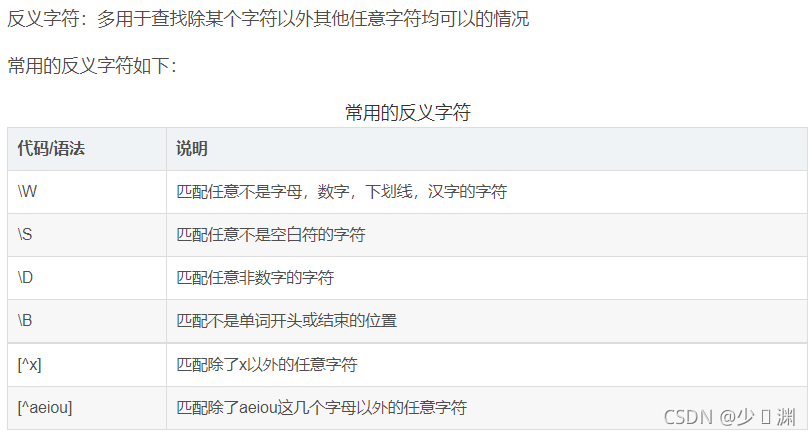
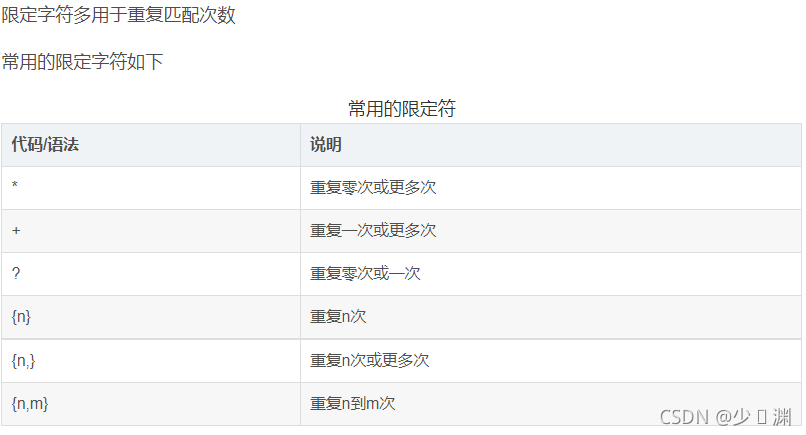
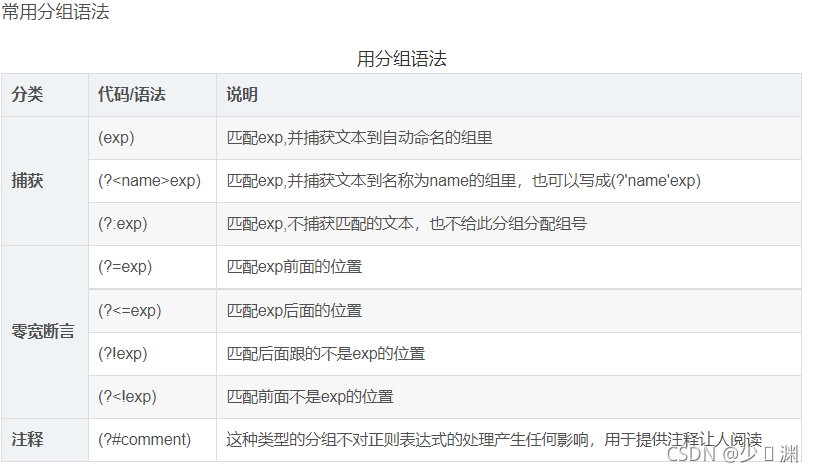
對于本題而言,所需要獲取的是熱搜排名(其實可有可無,因為是按排名讀取,只要在最后寫入的時候加上去就行)、鏈接、標題、熱度值,
那么既然上面說了,正則運算式是一種篩選標準,篩選滿足條件的資料,那么我們起碼要先觀察一下有哪些資料吧?
打開微博熱搜:https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6
右鍵查看源代碼:
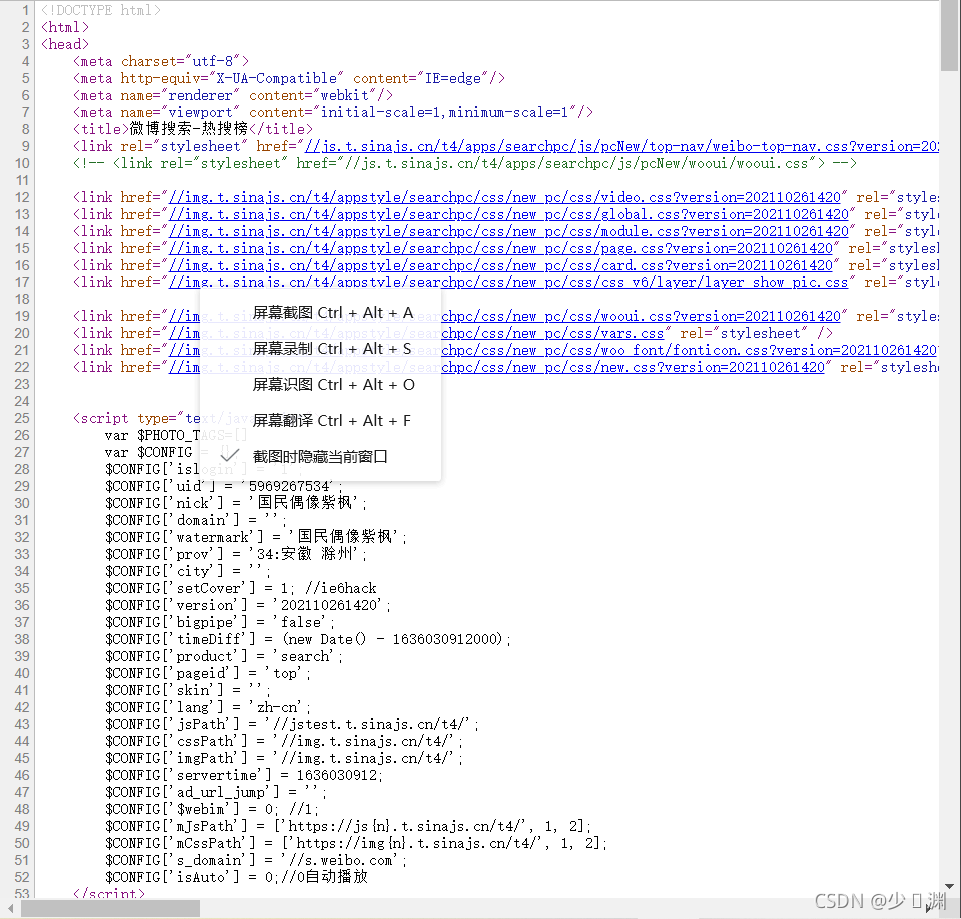
得到這么一串花里胡哨的東西,我們忍著性子找找看有沒有我們需要的內容:

哎,發現了,這些不就是我要的資料嗎?為啥就是這些呢?你跟熱搜榜比對一下不就行了...
那么我們一個個來,觀察一下所有熱搜鏈接的共同點:
對,就是都在<a href=" " target="_blank">這半個標簽里面,唯一的不同就是href中的內容,畢竟是不同的鏈接嘛,所以我們獲取鏈接的正則運算式就是
findLink = re.compile(r'<a href="(.*?)" target="_blank">')其中的.*?指獲取任意字符0次或者多次盡可能少,也就是不管里面鏈接多長,都可以獲取,
觀察上面的標題所在位置<a>標題</a>,在兩個a標簽之前,但是我們發現不僅僅標題不同,這里面還包含著熱搜嘞,所以我們完全可以通過
findTitleAndLink = re.compile(r'<a href="(.*?)" target="_blank">(.*?)</a>')同時獲取鏈接和標題,豈不美哉!獲取的資料第一個是鏈接,第二個是標題,
獲取熱度的就更簡單了,熱度值在<span></span>標簽中,直接重復.*?就可以了嗎?如果這樣就錯誤了,因為細看熱搜,就會發現,有的熱搜熱度除了數值外,還有:
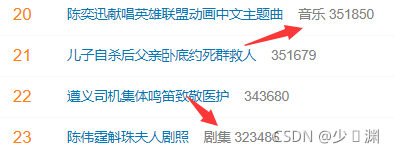
音樂、劇集等漢字,并且漢字和數字之間還有一個空格,你可以選擇直接舍棄漢字和空格部分,也可以像我一樣包含他們:
findHot = re.compile(r'<span>(\w*\s\d*)</span>')
(3)得到一個指定網頁的內容
在這個方法里,我們一定要做的一件事就是設定head,因為我們訪問網頁并點擊進去就是一個完整的瀏覽程序,當我們想要通程序式獲取的時候,必須要模擬這種程序,不然瀏覽器會拒絕我們接入,而head就是幫助我們模擬這種程序的工具,
我們通過模擬瀏覽器頭部資訊,向微博服務器發送訊息,一般模擬谷歌瀏覽器:
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73'但其實直接就這樣就設定完成的話,最終爬取到的是Sina Visitor System ,嗯,應該是被反爬了,咋辦呢?還可以通過添加cookie:打開熱搜網頁,F12進入開發者工具
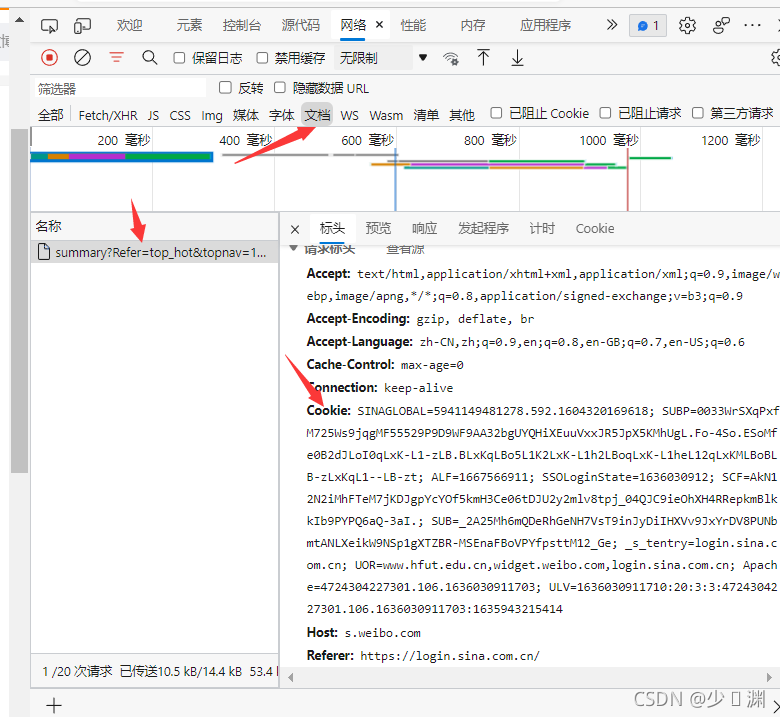
選擇 檔案,就可以查看到cookie內容,賦值粘貼到head里即可,為啥加上cookie就可以爬取了?因為cookies就是某些網站為了識別用戶身份、進行會話跟蹤而儲存在用戶本地終端上的資料,設定好cookies可以模擬用戶操作,讓瀏覽器“放下戒心”,具體解釋如下:

設定好head之后,通過urllib的request傳入爬取的網頁和head值,獲取到request,
然后通過urllib.request.urlopen回傳一個型別是http.client.HTTPResponse的response物件,最后用一個字串html儲存response解碼后的內容,注意解碼形式為utf-8.最后回傳html就可以獲取到網頁源代碼的字串形式了,
def askURL(url):
head = { # 模擬瀏覽器頭部資訊,向服務器發送訊息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73',
'referer': 'https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',
'cookie':'SINAGLOBAL=5941149481278.592.1604320169618; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF9AA32bgUYQHiXEuuVxxJR5JpX5KMhUgL.Fo-4So.ESoMfe0B2dJLoI0qLxK-L1-zLB.BLxKqLBo5L1K2LxK-L1h2LBoqLxK-L1heL12qLxKMLBoBLB-zLxKqL1--LB-zt; ALF=1667371481; SSOLoginState=1635835482; SCF=AkN12N2iMhFTeM7jKDJgpYcYOf5kmH3Ce06tDJU2y2mljYlKd05KkJok_NVeQQlKS5DVQ3MLyNAD0Dq6QEWbaWs.; SUB=_2A25MhK4KDeRhGeNH7VsT9inJyDiIHXVv85jCrDV8PUNbmtANLWLukW9NSp1gXY7kU378-JL7Yek2RvC4p8_BqxCH; _s_tentry=weibo.com; Apache=683258631837.9574.1635836312586; ULV=1635836312593:18:1:1:683258631837.9574.1635836312586:1633605575935; UOR=www.hfut.edu.cn,widget.weibo.com,www.cnblogs.com',
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
(4)獲取資料并儲存
定義一個空二維串列儲存資訊,然后通過BeautifulSoup傳入獲取的字串型別源代碼html和決議器型別html.parser,然后通過soup的find_all方法找到所有符合條件的資料,進行遍歷,
這次還要再回顧這個圖:
細看知道,不管是熱搜標題還是鏈接還是熱度,都包含在td標簽里,那么我們可以在find_all中指定搜索型別'td',并且為了縮小范圍,我們可以加上td的class屬性,可以看到源代碼中class的屬性值td-02,之后就可以開始遍歷了,
在每次遍歷中都定義一個一維空串列,將資訊依次放入,對了,因為剛剛將html轉成了其他型別,所以回圈時記得轉回字串,然后通過正則運算式獲取資訊依次append進行就行了,這里需要注意的一個坑是:微博可能有置頂的,那個是不在50條熱搜之內的,但是它也是新聞,我們可以也將它放入,最后輸出的時候告訴用戶這個是置頂的就行;還有一個坑是,現在雙十一快到了,經常有廣告摻雜在熱搜里面,很煩,因為廣告的代碼和熱搜不太一樣,正則運算式識別到td但是識別不出需要的內容就會卡死在那,
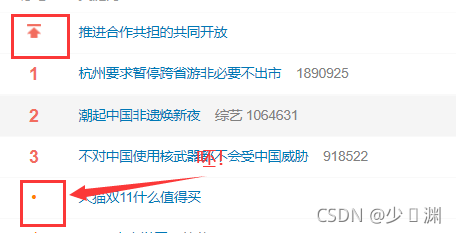
我們可以每次讀取到它的時候,都直接跳過,畢竟誰想看廣告呢你說是吧,然后在每次回圈結束的時候將一維串列放入二維串列即可,那么一來二去,咱不就保存了所有需要的資訊了嗎?
ps:可以通過APScheduler庫定時爬取資訊并且更新熱搜內容,時間問題先不詳述,寒假或者其他時候有時間再具體寫,
(5)可視化保存資料
我們已將資料全部保存到二維串列中了,那么下一步很顯然就是保存,最大眾的方法就是寫一個txt檔案,然后一行一行將資訊存進去;稍微升級一點就是將資訊儲存到Excel里;再高階一點就是通過matplotlib和numpy庫將二維串列轉化成二維numpy陣列并且以直方圖的形式呈現出來;再高階一點就是實時更新熱搜排名并且以直方圖的形式顯示出來,結果看起來像是影片一般有動態效果,
還是那句話,快要考試了,實在沒時間,只寫了保存到Excel,其余可視化方案(直方圖、餅圖)以后再說,具體保存操作沒有難度,就是新建或打開一個Excel,逐行寫入即可,
(6)運行結果
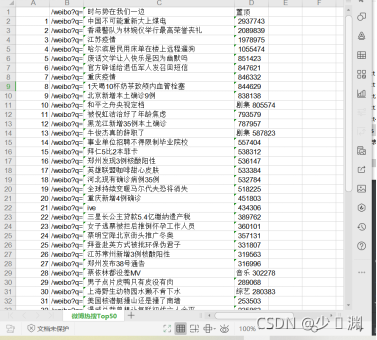
5、代碼
# _*_ coding:utf8 _*_
# -*- codeing = utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
import urllib.request, urllib.error
import xlwt
import matplotlib.pyplot as plt
findLink = re.compile(r'<a href="(.*?)" target="_blank">')
# 獲取標題
findTitle = re.compile(r'<a href="(.*?)" target="_blank">(.*?)</a>')
# 獲取熱度值
findHot = re.compile(r'<span>(\w*\s\d*)</span>')
def main():
baseurl = "https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
# baseurl="view-source:file:///C:/Users/%E5%AD%99%E5%BB%BA%E6%9E%97/Desktop/%E5%89%8D%E7%AB%AF/new%201.html"
datalist = getData(baseurl)
savepath = "D:\PyCharm Community Edition 2020.2.3\微博熱搜50.xls" #當前目錄新建XLS,存盤進去
saveData(datalist,savepath)
def getData(baseurl):
datalist = []
url=baseurl
html=askURL(url)
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('td',class_="td-02"):
data=[]
item=str(item)
if len(re.findall(findLink,item))==0:
continue
link=re.findall(findLink,item)[0]
data.append(link)
# print(re.findall(findTitle,item))
title=str(re.findall(findTitle,item)[0])
title=title.strip('(')
title=title.strip(')')
title=title.replace("\'","")
title=title.split(",")
data.append(title[1])
if len(re.findall(findHot,item))==0:
data.append("置頂")
datalist.append(data)
continue
hot=re.findall(findHot,item)[0]
data.append(hot)
datalist.append(data)
return datalist
# 得到指定一個URL的網頁內容
def askURL(url):
head = { # 模擬瀏覽器頭部資訊,向服務器發送訊息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73',
'referer': 'https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',
'cookie':'SINAGLOBAL=5941149481278.592.1604320169618; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF9AA32bgUYQHiXEuuVxxJR5JpX5KMhUgL.Fo-4So.ESoMfe0B2dJLoI0qLxK-L1-zLB.BLxKqLBo5L1K2LxK-L1h2LBoqLxK-L1heL12qLxKMLBoBLB-zLxKqL1--LB-zt; ALF=1667371481; SSOLoginState=1635835482; SCF=AkN12N2iMhFTeM7jKDJgpYcYOf5kmH3Ce06tDJU2y2mljYlKd05KkJok_NVeQQlKS5DVQ3MLyNAD0Dq6QEWbaWs.; SUB=_2A25MhK4KDeRhGeNH7VsT9inJyDiIHXVv85jCrDV8PUNbmtANLWLukW9NSp1gXY7kU378-JL7Yek2RvC4p8_BqxCH; _s_tentry=weibo.com; Apache=683258631837.9574.1635836312586; ULV=1635836312593:18:1:1:683258631837.9574.1635836312586:1633605575935; UOR=www.hfut.edu.cn,widget.weibo.com,www.cnblogs.com',
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #創建workbook物件
sheet = book.add_sheet('微博熱搜Top50', cell_overwrite_ok=True) #創建作業表
col = ["熱搜排名","熱搜鏈接","熱搜標題","熱搜熱度"]
for i in range(0, 4):
sheet.write(1, i, col[i]) # 列名
for i in range(2,53):
print("第%d條" %(i-1)) #輸出陳述句,用來測驗
data = datalist[i-2]
print(data)
if i==2:
sheet.write(i-1,0,"置頂")
sheet.write(i-1,1,data[0])
sheet.write(i-1, 2, data[1])
sheet.write(i-1, 3, data[2])
else:
sheet.write(i-2,0,i-2)
for j in range(1,4):
sheet.write(i-2, j, data[j-1]) # 資料
book.save(savepath) # 保存
if __name__ == "__main__": # 當程式執行時
# 呼叫函式
main()
print("爬取完畢!")
三、尾言
好幾天沒有更新演算法題真的是因為事情太多了,期中考試之后一定補回來!完整的python大作頁澩正在上傳,可以持續關注哦,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/349630.html
標籤:python
下一篇:pandas使用append函式在dataframe上縱向合并資料實戰:多個dataframe合并、合并series左右dataframe的一樣、合并字典資料作為dataframe的行