?
目錄
目標
代碼實作效果
環境準備
手動安裝pytesseract庫
安裝Tesseract-OCR.exe
下載地址
配置環境變數
校驗安裝成功
安裝Pillow包
代碼正文
初始化瀏覽器和元素定位方式
獲取圖片
識別圖片上的文本
問題:
Python腳本運行報錯:
解決方案:
目標
解決UI自動化程序中的圖文驗證碼問題,程序大致分為兩個步驟:
- 1. 自動下載網頁上指定的圖片
- 2. 識別圖片上的文本內容
本文以“識別頁面上指定圖片的文本“為例,
很多人學習python,不知道從何學起, 很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手, 很多已經做案例的人,卻不知道如何去學習更加高深的知識, 那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼! QQ群:861355058 歡迎加入,一起討論 一起學習!
代碼實作效果
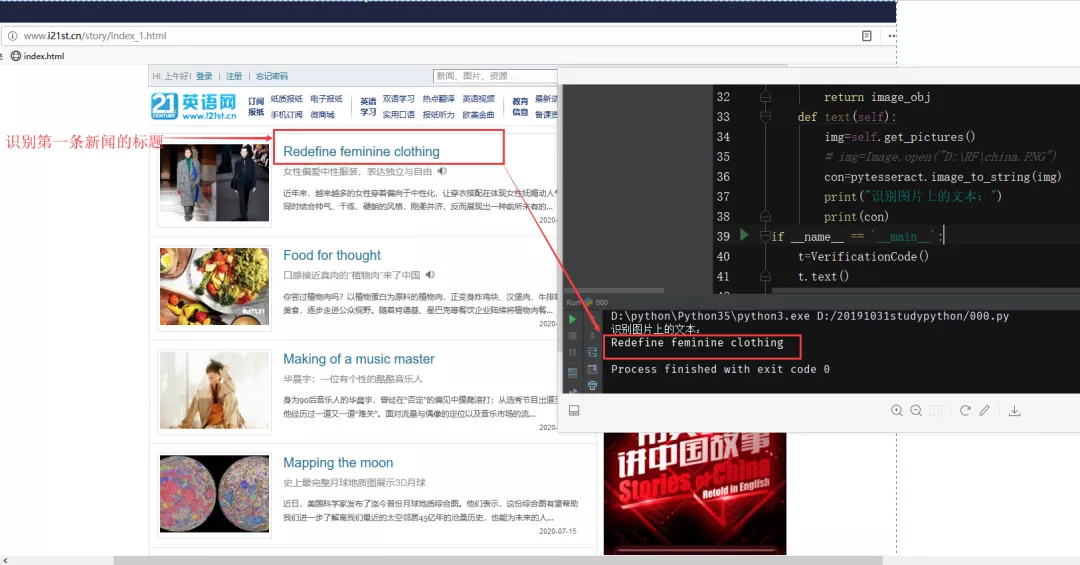 ?
?
環境準備
- Pytesseract
- Tesseract-OCR
- Pillow
手動安裝pytesseract庫
命令:
pip install pytesseract ?
?
安裝Tesseract-OCR.exe
下載地址
http://8rr.co/Krrw
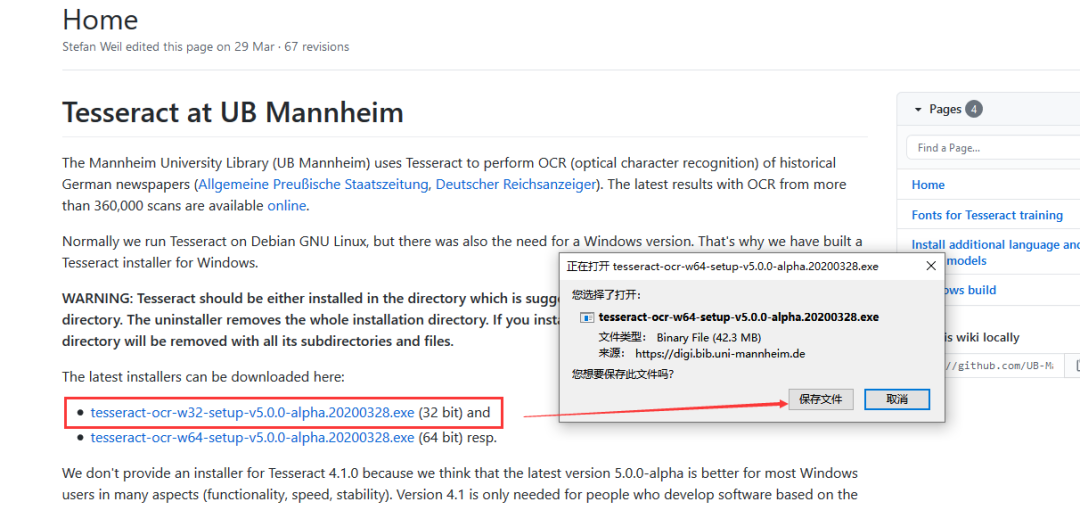 ?
?
雙擊exe程式直接安裝即可
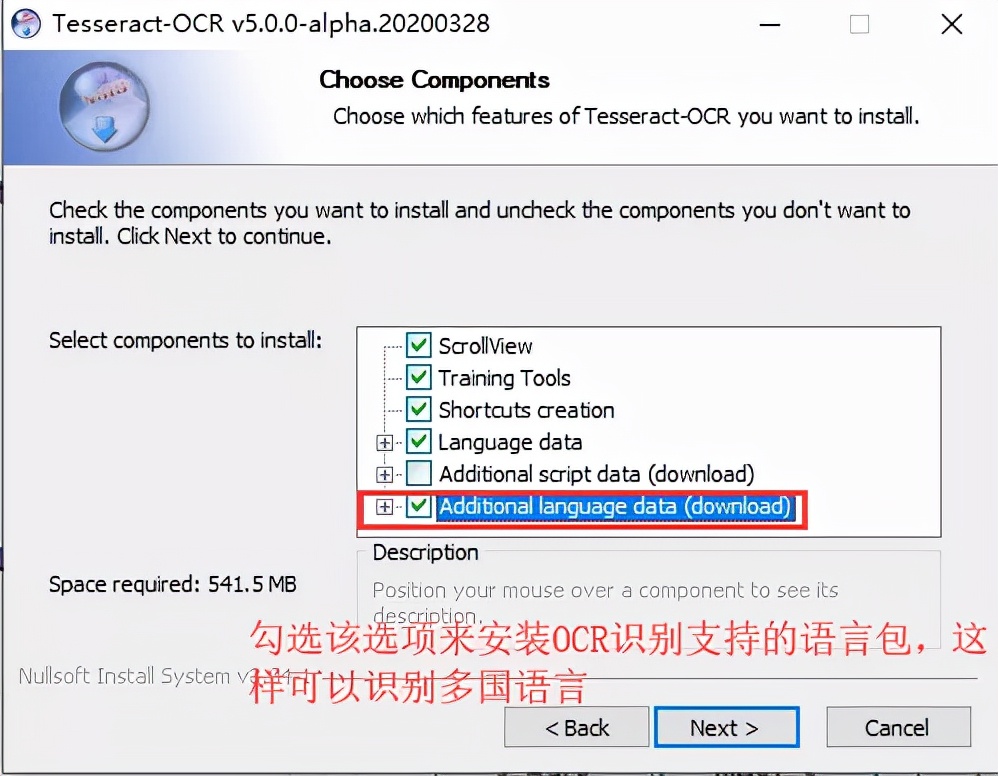 ?
?
配置環境變數
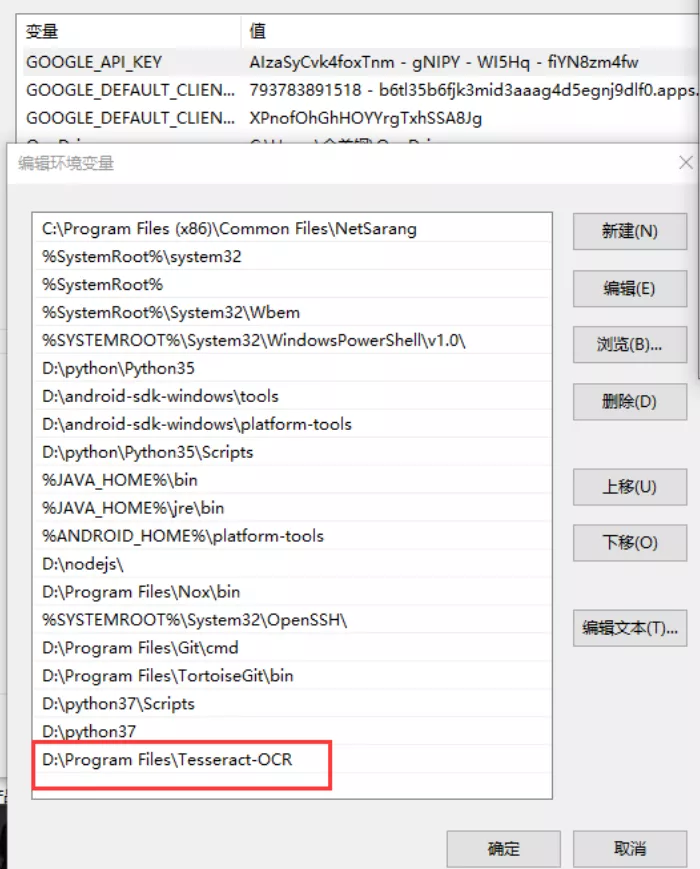 ?
?
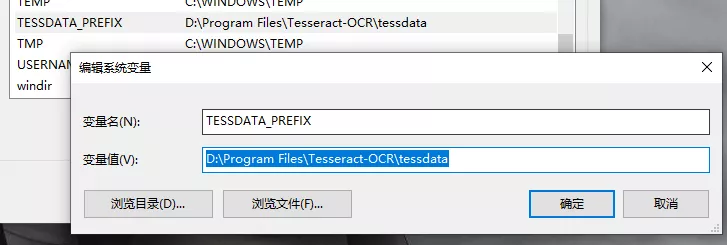 ?
?
校驗安裝成功
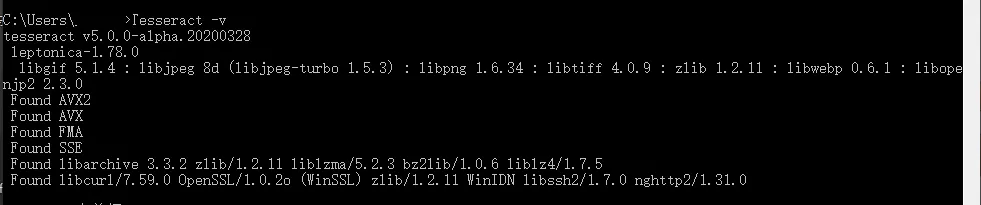 ?
?
安裝Pillow包
Python自帶的圖文簡單處理模塊,正常安裝Python的時候會自動安裝,故無需另外手動安裝,(若沒自動安裝則可手動安裝:pip install Pillow)
代碼正文
初始化瀏覽器和元素定位方式
初始化并放大瀏覽器初始化元素定位方式:本文使用CSS選擇器方式定位
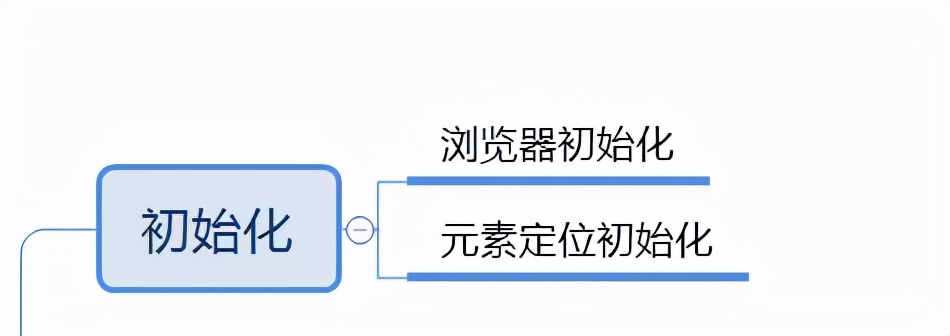 ?
?
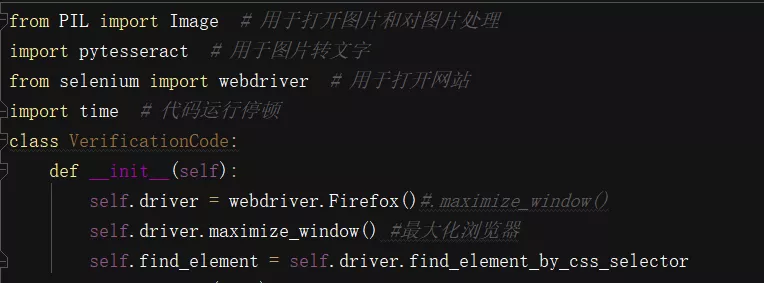 ?
?
獲取圖片
頁面全屏截圖截圖轉為Image物件獲取指定圖片的大小和位置裁剪圖片
 ?
?
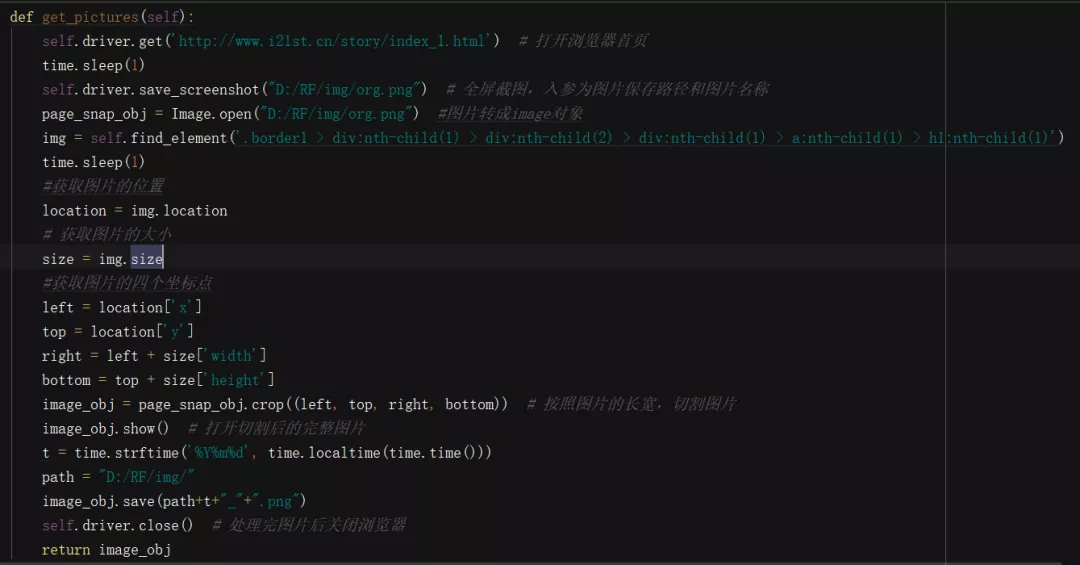 ?
?
識別圖片上的文本
識別裁剪后的圖片上的文本內容
 ?
?
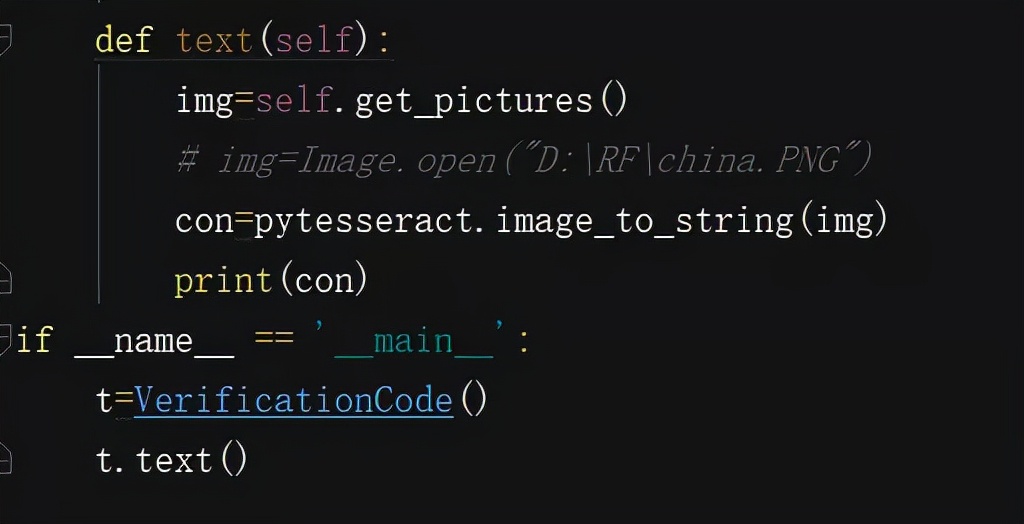 ?
?
問題:
Python腳本運行報錯:
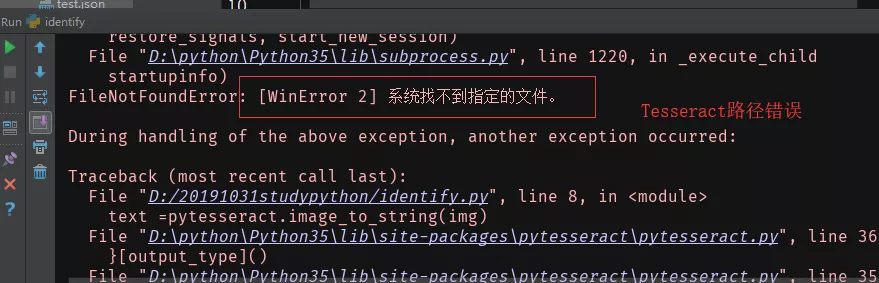 ?
?
解決方案:
修改tesseract檔案的默認路徑
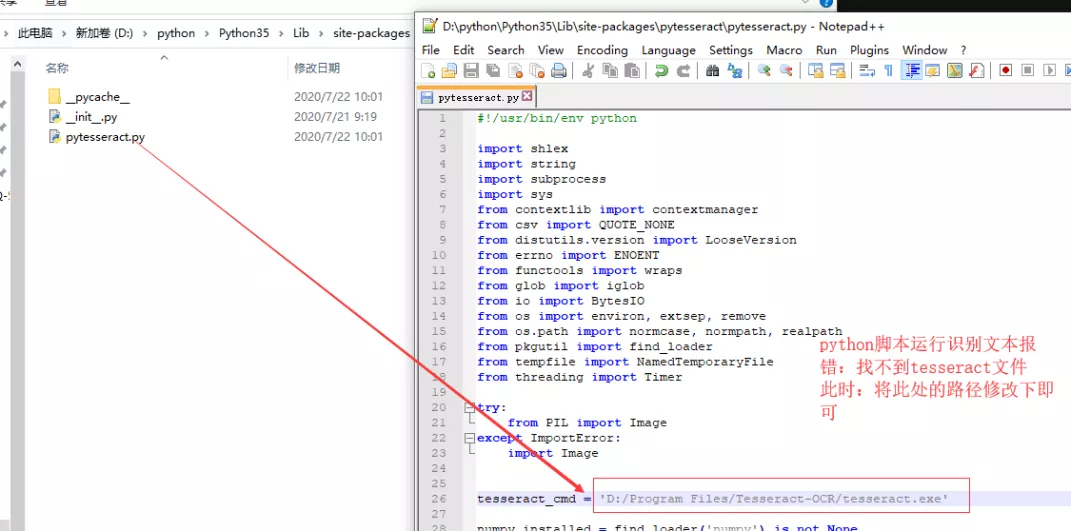 ?
?
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/350689.html
標籤:Python