前言
本文主要涉及到的面試問題點比較多各種各樣的,本文主要涉及到的是Java的基礎、集合類、并發編程、框架、面試題我就把我常遇到的和一些出現頻率比較多的問題整理出來了,
如果想要更多的學習資料的小伙伴可以點擊下面的鏈接交個朋友我們一起交流點擊一起學習
?Java學習路線個人總結-博客
?備戰2022年春季面試Java面試題庫-資料庫篇《收藏》
?備戰2022年春季面試Java面試題庫-快取篇Redis《收藏》
?歡迎點贊👍收藏?留言 📝分享給需要的小伙伴
文章目錄
- 前言
- 1、Java基礎
- JDK 和 JRE 有什么區別?
- == 和 equals 的區別是什么?
- hashCode()與 equals()
- 基本資料型別
- Java 中的幾種基本資料型別是什么?對應的包裝型別是什么?各自占用多少位元組呢?
- 自動裝箱與拆箱
- 8 種基本型別的包裝類和常量池
- 多載和重寫的區別
- 多載
- 重寫
- 深拷貝 vs 淺拷貝
- 面向物件三大特征
- 封裝
- 繼承
- 多型
- String StringBuffer 和 StringBuilder 的區別是什么? String 為什么是不可變的?
- Object 類的常見方法總結
- 例外
- Throwable 類常用方法
- try-catch-finally
- 使用 `try-with-resources` 來代替`try-catch-finally`
- Java常見關鍵字總結
- final,static,this,super 關鍵字總結
- final 關鍵字
- static 關鍵字
- this 關鍵字
- super 關鍵字
- 2、Java集合類
- Collection 子介面之 List
- Arraylist 和 Vector 的區別?
- Arraylist 與 LinkedList 區別?
- Collection 子介面之 Set
- comparable 和 Comparator 的區別
- Comparator 定制排序
- 重寫 compareTo 方法實作按年齡來排序
- 無序性和不可重復性的含義是什么
- 比較 HashSet、LinkedHashSet 和 TreeSet 三者的異同
- Map 介面
- HashMap 和 Hashtable 的區別
- HashMap 和 HashSet 區別
- HashMap 和 TreeMap 區別
- HashSet 如何檢查重復
- HashMap 的底層實作
- JDK1.8 之前
- JDK1.8 之后
- HashMap 的長度為什么是 2 的冪次方
- HashMap 多執行緒操作導致死回圈問題
- HashMap 有哪幾種常見的遍歷方式?
- ConcurrentHashMap 和 Hashtable 的區別
- ConcurrentHashMap 執行緒安全的具體實作方式/底層具體實作
- JDK1.7(上面有示意圖)
- 10.2. JDK1.8 (上面有示意圖)
- Collections 工具類
- 排序操作
- 查找,替換操作
- 同步控制
- 3、Java并發
- 說說并發與并行的區別?
- 為什么要使用多執行緒呢?
- 使用多執行緒可能帶來什么問題?
- 說說執行緒的生命周期和狀態?
- 什么是執行緒死鎖?如何避免死鎖?
- 認識執行緒死鎖
- 如何預防和避免執行緒死鎖?
- 說說 sleep() 方法和 wait() 方法區別和共同點?
- 為什么我們呼叫 start() 方法時會執行 run() 方法,為什么我們不能直接呼叫 run() 方法?
- synchronized 關鍵字
- 說一說自己對于 synchronized 關鍵字的了解
- 說說自己是怎么使用 synchronized 關鍵字
- 構造方法可以使用 synchronized 關鍵字修飾么?
- 講一下 synchronized 關鍵字的底層原理
- synchronized 同步陳述句塊的情況
- synchronized 修飾方法的的情況
- 總結
- volatile 關鍵字
- CPU 快取模型
- 講一下 JMM(Java 記憶體模型)
- 并發編程的三個重要特性
- 說說 synchronized 關鍵字和 volatile 關鍵字的區別
- ThreadLocal
- ThreadLocal 簡介
- ThreadLocal 示例
- ThreadLocal 原理
- ThreadLocal 記憶體泄露問題
- 執行緒池
- 為什么要用執行緒池?
- 實作 Runnable 介面和 Callable 介面的區別
- 執行 execute()方法和 submit()方法的區別是什么呢?
- 如何創建執行緒池
- ThreadPoolExecutor 類分析
- ?`ThreadPoolExecutor`建構式重要引數分析
- ?`ThreadPoolExecutor` 飽和策略
- 一個簡單的執行緒池 Demo
- 執行緒池原理分析
- AQS
- AQS 介紹
- 6.2. AQS 原理分析
- 6.2.1. AQS 原理概覽
- 6.2.2. AQS 對資源的共享方式
- 6.2.3. AQS 底層使用了模板方法模式
- 6.3. AQS 組件總結
- 6.4. 用過 CountDownLatch 么?什么場景下用的?
- 4、Spring
- 什么是 Spring 框架?
- 列舉一些重要的 Spring 模塊?
- Spring IOC & AOP
- 談談自己對于 Spring IoC 的了解
- 談談自己對于 AOP 的了解
- Spring AOP 和 AspectJ AOP 有什么區別?
- Spring bean
- 什么是 bean?
- bean 的作用域有哪些?
- 單例 bean 的執行緒安全問題了解嗎?
- [@Component ](/Component ) 和 [@Bean ](/Bean ) 的區別是什么?
- 將一個類宣告為 bean 的注解有哪些?
- bean 的生命周期?
- Spring MVC
- 說說自己對于 Spring MVC 了解?
- SpringMVC 作業原理了解嗎?
- Spring 框架中用到了哪些設計模式?
- Spring 事務
- Spring 管理事務的方式有幾種?
- Spring 事務中哪幾種事務傳播行為?
- Spring 事務中的隔離級別有哪幾種?
- [@Transactional(rollbackFor ](/Transactional(rollbackFor ) = Exception.class)注解了解嗎?
- JPA
- 如何使用 JPA 在資料庫中非持久化一個欄位?
1、Java基礎
JDK 和 JRE 有什么區別?
JDK:Java Development Kit 的簡稱,java 開發工具包,提供了 java 的開發環境和運行環境,
?
JRE:Java Runtime Environment 的簡稱,java 運行環境,為 java 的運行提供了所需環境,
?
具體來說 JDK 其實包含了 JRE,同時還包含了編譯 java 原始碼的編譯器 javac,還包含了很多 java 程式除錯和分析的工具,簡單來說:如果你需要運行 java 程式,只需安裝 JRE 就可以了,如果你需要撰寫 java 程式,需要安裝 JDK,
== 和 equals 的區別是什么?
對于基本資料型別來說,==比較的是值,對于參考資料型別來說,==比較的是物件的記憶體地址,
因為 Java 只有值傳遞,所以,對于 == 來說,不管是比較基本資料型別,還是參考資料型別的變數,其本質比較的都是值,只是參考型別變數存的值是物件的地址,
**equals()** 作用不能用于判斷基本資料型別的變數,只能用來判斷兩個物件是否相等,equals()方法存在于Object類中,而Object類是所有類的直接或間接父類,
Object 類 equals() 方法:
public boolean equals(Object obj) {
return (this == obj);
}
equals() 方法存在兩種使用情況:
- **類沒有覆寫 **
**equals()**方法 :通過equals()比較該類的兩個物件時,等價于通過“==”比較這兩個物件,使用的默認是Object類equals()方法, - **類覆寫了 **
**equals()**方法 :一般我們都覆寫equals()方法來比較兩個物件中的屬性是否相等;若它們的屬性相等,則回傳 true(即,認為這兩個物件相等),
舉個例子:
public class test1 {
public static void main(String[] args) {
String a = new String("ab"); // a 為一個參考
String b = new String("ab"); // b為另一個參考,物件的內容一樣
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 從常量池中查找
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一物件
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
if (42 == 42.0) { // true
System.out.println("true");
}
}
}
hashCode()與 equals()
面試官可能會問你:“你重寫過 hashcode 和 equals么,為什么重寫 equals 時必須重寫 hashCode 方法?”
1)hashCode()介紹:
hashCode() 的作用是獲取哈希碼,也稱為散列碼;它實際上是回傳一個 int 整數,這個哈希碼的作用是確定該物件在哈希表中的索引位置,hashCode()定義在 JDK 的 Object 類中,這就意味著 Java 中的任何類都包含有 hashCode() 函式,另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 語言或 c++ 實作的,該方法通常用來將物件的 記憶體地址 轉換為整數之后回傳,
public native int hashCode();
散串列存盤的是鍵值對(key-value),它的特點是:能根據“鍵”快速的檢索出對應的“值”,這其中就利用到了散列碼!(可以快速找到所需要的物件)
2)為什么要有 hashCode?
我們以“HashSet 如何檢查重復”為例子來說明為什么要有 hashCode?
當你把物件加入 HashSet 時,HashSet 會先計算物件的 hashcode 值來判斷物件加入的位置,同時也會與其他已經加入的物件的 hashcode 值作比較,如果沒有相符的 hashcode,HashSet 會假設物件沒有重復出現,但是如果發現有相同 hashcode 值的物件,這時會呼叫 equals() 方法來檢查 hashcode 相等的物件是否真的相同,如果兩者相同,HashSet 就不會讓其加入操作成功,如果不同的話,就會重新散列到其他位置,(摘自我的 Java 啟蒙書《Head First Java》第二版),這樣我們就大大減少了 equals 的次數,相應就大大提高了執行速度,
3)為什么重寫 **equals** 時必須重寫 **hashCode** 方法?
如果兩個物件相等,則 hashcode 一定也是相同的,兩個物件相等,對兩個物件分別呼叫 equals 方法都回傳 true,但是,兩個物件有相同的 hashcode 值,它們也不一定是相等的 ,因此,equals 方法被覆寫過,則 **hashCode** 方法也必須被覆寫,
hashCode()的默認行為是對堆上的物件產生獨特值,如果沒有重寫hashCode(),則該 class 的兩個物件無論如何都不會相等(即使這兩個物件指向相同的資料)
4)為什么兩個物件有相同的 hashcode 值,它們也不一定是相等的?
在這里解釋一位小伙伴的問題,以下內容摘自《Head Fisrt Java》,
因為 hashCode() 所使用的哈希演算法也許剛好會讓多個物件傳回相同的哈希值,越糟糕的哈希演算法越容易碰撞,但這也與資料值域分布的特性有關(所謂碰撞也就是指的是不同的物件得到相同的 hashCode ),
我們剛剛也提到了 HashSet,如果 HashSet 在對比的時候,同樣的 hashcode 有多個物件,它會使用 equals() 來判斷是否真的相同,也就是說 hashcode 只是用來縮小查找成本,
基本資料型別
Java 中的幾種基本資料型別是什么?對應的包裝型別是什么?各自占用多少位元組呢?
Java 中有 8 種基本資料型別,分別為:
- 6 種數字型別 :
byte、short、int、long、float、double - 1 種字符型別:
char - 1 種布爾型:
boolean,
這 8 種基本資料型別的默認值以及所占空間的大小如下:
| 基本型別 | 位數 | 位元組 | 默認值 |
|---|---|---|---|
int | 32 | 4 | 0 |
short | 16 | 2 | 0 |
long | 64 | 8 | 0L |
byte | 8 | 1 | 0 |
char | 16 | 2 | ‘u0000’ |
float | 32 | 4 | 0f |
double | 64 | 8 | 0d |
boolean | 1 | false |
另外,對于 boolean,官方檔案未明確定義,它依賴于 JVM 廠商的具體實作,邏輯上理解是占用 1 位,但是實際中會考慮計算機高效存盤因素,
注意:
- Java 里使用
long型別的資料一定要在數值后面加上 L,否則將作為整型決議, char a = 'h'char :單引號,String a = "hello":雙引號,
這八種基本型別都有對應的包裝類分別為:Byte、Short、Integer、Long、Float、Double、Character、Boolean ,
包裝型別不賦值就是 Null ,而基本型別有默認值且不是 Null,
另外,這個問題建議還可以先從 JVM 層面來分析,
基本資料型別直接存放在 Java 虛擬機堆疊中的區域變數表中,而包裝型別屬于物件型別,我們知道物件實體都存在于堆中,相比于物件型別, 基本資料型別占用的空間非常小,
《深入理解 Java 虛擬機》 :區域變數表主要存放了編譯期可知的基本資料型別 (boolean、byte、char、short、int、float、long、double)、物件參考(reference 型別,它不同于物件本身,可能是一個指向物件起始地址的參考指標,也可能是指向一個代表物件的句柄或其他與此物件相關的位置),
自動裝箱與拆箱
- 裝箱:將基本型別用它們對應的參考型別包裝起來;
- 拆箱:將包裝型別轉換為基本資料型別;
舉例:
Integer i = 10; //裝箱
int n = i; //拆箱
上面這兩行代碼對應的位元組碼為:
L1
LINENUMBER 8 L1
ALOAD 0
BIPUSH 10
INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
PUTFIELD AutoBoxTest.i : Ljava/lang/Integer;
L2
LINENUMBER 9 L2
ALOAD 0
ALOAD 0
GETFIELD AutoBoxTest.i : Ljava/lang/Integer;
INVOKEVIRTUAL java/lang/Integer.intValue ()I
PUTFIELD AutoBoxTest.n : I
RETURN
從位元組碼中,我們發現裝箱其實就是呼叫了 包裝類的valueOf()方法,拆箱其實就是呼叫了 xxxValue()方法,
因此,
Integer i = 10等價于Integer i = Integer.valueOf(10)int n = i等價于int n = i.intValue();
8 種基本型別的包裝類和常量池
Java 基本型別的包裝類的大部分都實作了常量池技術,Byte,Short,Integer,Long 這 4 種包裝類默認創建了數值 [-128,127] 的相應型別的快取資料,Character 創建了數值在[0,127]范圍的快取資料,Boolean 直接回傳 True Or False,
Integer 快取原始碼:
/**
*此方法將始終快取-128 到 127(包括端點)范圍內的值,并可以快取此范圍之外的其他值,
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
}
**Character**** 快取原始碼:**
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}
**Boolean**** 快取原始碼:**
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
如果超出對應范圍仍然會去創建新的物件,快取的范圍區間的大小只是在性能和資源之間的權衡,
兩種浮點數型別的包裝類 Float,Double 并沒有實作常量池技術,
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// 輸出 true
Float i11 = 333f;
Float i22 = 333f;
System.out.println(i11 == i22);// 輸出 false
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// 輸出 false
下面我們來看一下問題,下面的代碼的輸出結果是 true 還是 flase 呢?
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);
Integer i1=40 這一行代碼會發生裝箱,也就是說這行代碼等價于 Integer i1=Integer.valueOf(40) ,因此,i1 直接使用的是常量池中的物件,而Integer i1 = new Integer(40) 會直接創建新的物件,
因此,答案是 false ,你答對了嗎?
記住:所有整型包裝類物件之間值的比較,全部使用 equals 方法比較,

多載和重寫的區別
多載就是同樣的一個方法能夠根據輸入資料的不同,做出不同的處理
重寫就是當子類繼承自父類的相同方法,輸入資料一樣,但要做出有別于父類的回應時,你就要覆寫父類方法
多載
發生在同一個類中(或者父類和子類之間),方法名必須相同,引數型別不同、個數不同、順序不同,方法回傳值和訪問修飾符可以不同,
下面是《Java 核心技術》對多載這個概念的介紹:

綜上:多載就是同一個類中多個同名方法根據不同的傳參來執行不同的邏輯處理,
重寫
重寫發生在運行期,是子類對父類的允許訪問的方法的實作程序進行重新撰寫,
- 回傳值型別、方法名、引數串列必須相同,拋出的例外范圍小于等于父類,訪問修飾符范圍大于等于父類,
- 如果父類方法訪問修飾符為
private/final/static則子類就不能重寫該方法,但是被 static 修飾的方法能夠被再次宣告, - 構造方法無法被重寫
綜上:重寫就是子類對父類方法的重新改造,外部樣子不能改變,內部邏輯可以改變
暖心的 Guide 哥最后再來個圖表總結一下!
| 區別點 | 多載方法 | 重寫方法 |
|---|---|---|
| 發生范圍 | 同一個類 | 子類 |
| 引數串列 | 必須修改 | 一定不能修改 |
| 回傳型別 | 可修改 | 子類方法回傳值型別應比父類方法回傳值型別更小或相等 |
| 例外 | 可修改 | 子類方法宣告拋出的例外類應比父類方法宣告拋出的例外類更小或相等; |
| 訪問修飾符 | 可修改 | 一定不能做更嚴格的限制(可以降低限制) |
| 發生階段 | 編譯期 | 運行期 |
方法的重寫要遵循“兩同兩小一大”(以下內容摘錄自《瘋狂 Java 講義》,issue#892 ):
- “兩同”即方法名相同、形參串列相同;
- “兩小”指的是子類方法回傳值型別應比父類方法回傳值型別更小或相等,子類方法宣告拋出的例外類應比父類方法宣告拋出的例外類更小或相等;
- “一大”指的是子類方法的訪問權限應比父類方法的訪問權限更大或相等,
?? 關于 重寫的回傳值型別 這里需要額外多說明一下,上面的表述不太清晰準確:如果方法的回傳型別是 void 和基本資料型別,則回傳值重寫時不可修改,但是如果方法的回傳值是參考型別,重寫時是可以回傳該參考型別的子類的,
public class Hero {
public String name() {
return "超級英雄";
}
}
public class SuperMan extends Hero{
@Override
public String name() {
return "超人";
}
public Hero hero() {
return new Hero();
}
}
public class SuperSuperMan extends SuperMan {
public String name() {
return "超級超級英雄";
}
@Override
public SuperMan hero() {
return new SuperMan();
}
}
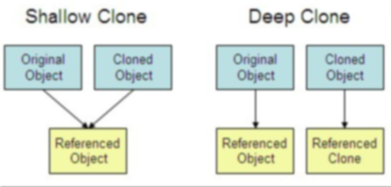
深拷貝 vs 淺拷貝
- 淺拷貝:對基本資料型別進行值傳遞,對參考資料型別進行參考傳遞般的拷貝,此為淺拷貝,
- 深拷貝:對基本資料型別進行值傳遞,對參考資料型別,創建一個新的物件,并復制其內容,此為深拷貝,
面向物件三大特征
封裝
封裝是指把一個物件的狀態資訊(也就是屬性)隱藏在物件內部,不允許外部物件直接訪問物件的內部資訊,但是可以提供一些可以被外界訪問的方法來操作屬性,就好像我們看不到掛在墻上的空調的內部的零件資訊(也就是屬性),但是可以通過遙控器(方法)來控制空調,如果屬性不想被外界訪問,我們大可不必提供方法給外界訪問,但是如果一個類沒有提供給外界訪問的方法,那么這個類也沒有什么意義了,就好像如果沒有空調遙控器,那么我們就無法操控空凋制冷,空調本身就沒有意義了(當然現在還有很多其他方法 ,這里只是為了舉例子),
public class Student {
private int id;//id屬性私有化
private String name;//name屬性私有化
//獲取id的方法
public int getId() {
return id;
}
//設定id的方法
public void setId(int id) {
this.id = id;
}
//獲取name的方法
public String getName() {
return name;
}
//設定name的方法
public void setName(String name) {
this.name = name;
}
}
繼承
不同型別的物件,相互之間經常有一定數量的共同點,例如,小明同學、小紅同學、小李同學,都共享學生的特性(班級、學號等),同時,每一個物件還定義了額外的特性使得他們與眾不同,例如小明的數學比較好,小紅的性格惹人喜愛;小李的力氣比較大,繼承是使用已存在的類的定義作為基礎建立新類的技術,新類的定義可以增加新的資料或新的功能,也可以用父類的功能,但不能選擇性地繼承父類,通過使用繼承,可以快速地創建新的類,可以提高代碼的重用,程式的可維護性,節省大量創建新類的時間 ,提高我們的開發效率,
關于繼承如下 3 點請記住:
- 子類擁有父類物件所有的屬性和方法(包括私有屬性和私有方法),但是父類中的私有屬性和方法子類是無法訪問,只是擁有,
- 子類可以擁有自己屬性和方法,即子類可以對父類進行擴展,
- 子類可以用自己的方式實作父類的方法,(以后介紹),
多型
多型,顧名思義,表示一個物件具有多種的狀態,具體表現為父類的參考指向子類的實體,
多型的特點:
- 物件型別和參考型別之間具有繼承(類)/實作(介面)的關系;
- 參考型別變數發出的方法呼叫的到底是哪個類中的方法,必須在程式運行期間才能確定;
- 多型不能呼叫“只在子類存在但在父類不存在”的方法;
- 如果子類重寫了父類的方法,真正執行的是子類覆寫的方法,如果子類沒有覆寫父類的方法,執行的是父類的方法,
String StringBuffer 和 StringBuilder 的區別是什么? String 為什么是不可變的?
可變性
簡單的來說:String 類中使用 final 關鍵字修飾字符陣列來保存字串,private final char value[],所以String 物件是不可變的,
補充(來自issue 675):在 Java 9 之后,String 、
StringBuilder與StringBuffer的實作改用 byte 陣列存盤字串private final byte[] value
而 StringBuilder 與 StringBuffer 都繼承自 AbstractStringBuilder 類,在 AbstractStringBuilder 中也是使用字符陣列保存字串char[]value 但是沒有用 final 關鍵字修飾,所以這兩種物件都是可變的,
StringBuilder 與 StringBuffer 的構造方法都是呼叫父類構造方法也就是AbstractStringBuilder 實作的,大家可以自行查閱原始碼,
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}}
執行緒安全性
String 中的物件是不可變的,也就可以理解為常量,執行緒安全,AbstractStringBuilder 是 StringBuilder 與 StringBuffer 的公共父類,定義了一些字串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法,StringBuffer 對方法加了同步鎖或者對呼叫的方法加了同步鎖,所以是執行緒安全的,StringBuilder 并沒有對方法進行加同步鎖,所以是非執行緒安全的,
性能
每次對 String 類型進行改變的時候,都會生成一個新的 String 物件,然后將指標指向新的 String 物件,StringBuffer 每次都會對 StringBuffer 物件本身進行操作,而不是生成新的物件并改變物件參考,相同情況下使用 StringBuilder 相比使用 StringBuffer 僅能獲得 10%~15% 左右的性能提升,但卻要冒多執行緒不安全的風險,
對于三者使用的總結:
- 操作少量的資料: 適用
String - 單執行緒操作字串緩沖區下操作大量資料: 適用
StringBuilder - 多執行緒操作字串緩沖區下操作大量資料: 適用
StringBuffer
Object 類的常見方法總結
Object 類是一個特殊的類,是所有類的父類,它主要提供了以下 11 個方法:
public final native Class<?> getClass()//native方法,用于回傳當前運行時物件的Class物件,使用了final關鍵字修飾,故不允許子類重寫,
public native int hashCode() //native方法,用于回傳物件的哈希碼,主要使用在哈希表中,比如JDK中的HashMap,
public boolean equals(Object obj)//用于比較2個物件的記憶體地址是否相等,String類對該方法進行了重寫用戶比較字串的值是否相等,
protected native Object clone() throws CloneNotSupportedException//naitive方法,用于創建并回傳當前物件的一份拷貝,一般情況下,對于任何物件 x,運算式 x.clone() != x 為true,x.clone().getClass() == x.getClass() 為true,Object本身沒有實作Cloneable介面,所以不重寫clone方法并且進行呼叫的話會發生CloneNotSupportedException例外,
public String toString()//回傳類的名字@實體的哈希碼的16進制的字串,建議Object所有的子類都重寫這個方法,
public final native void notify()//native方法,并且不能重寫,喚醒一個在此物件監視器上等待的執行緒(監視器相當于就是鎖的概念),如果有多個執行緒在等待只會任意喚醒一個,
public final native void notifyAll()//native方法,并且不能重寫,跟notify一樣,唯一的區別就是會喚醒在此物件監視器上等待的所有執行緒,而不是一個執行緒,
public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重寫,暫停執行緒的執行,注意:sleep方法沒有釋放鎖,而wait方法釋放了鎖 ,timeout是等待時間,
public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos引數,這個引數表示額外時間(以毫微秒為單位,范圍是 0-999999), 所以超時的時間還需要加上nanos毫秒,
public final void wait() throws InterruptedException//跟之前的2個wait方法一樣,只不過該方法一直等待,沒有超時時間這個概念
protected void finalize() throws Throwable { }//實體被垃圾回收器回收的時候觸發的操作
?
例外
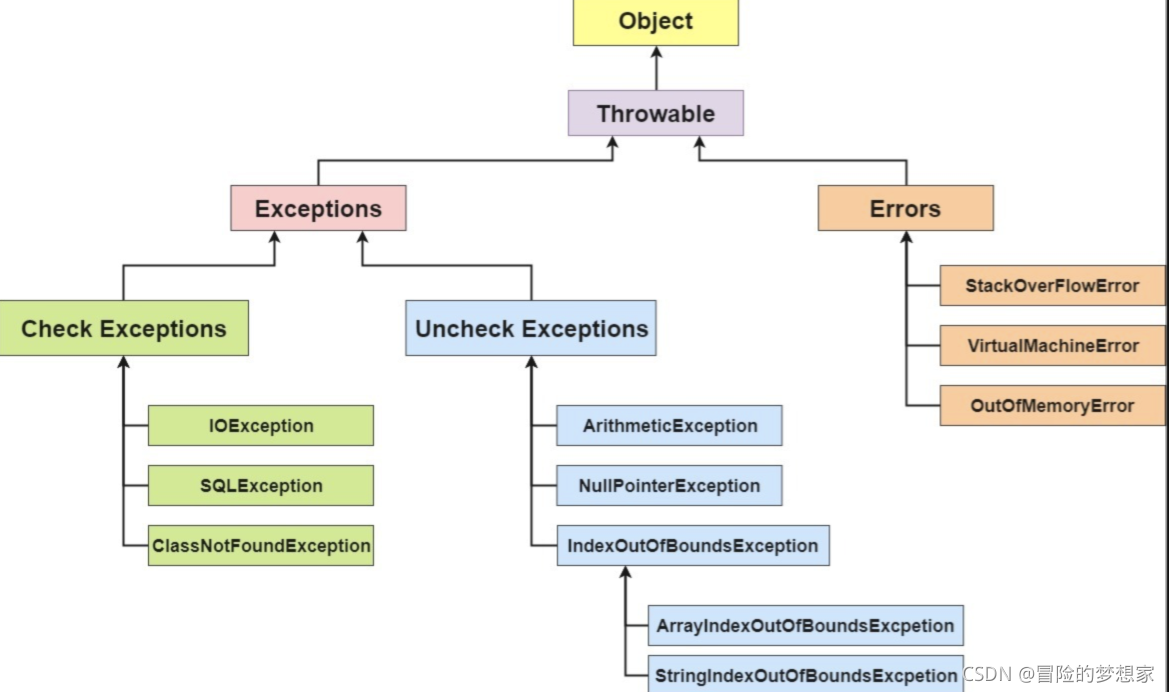
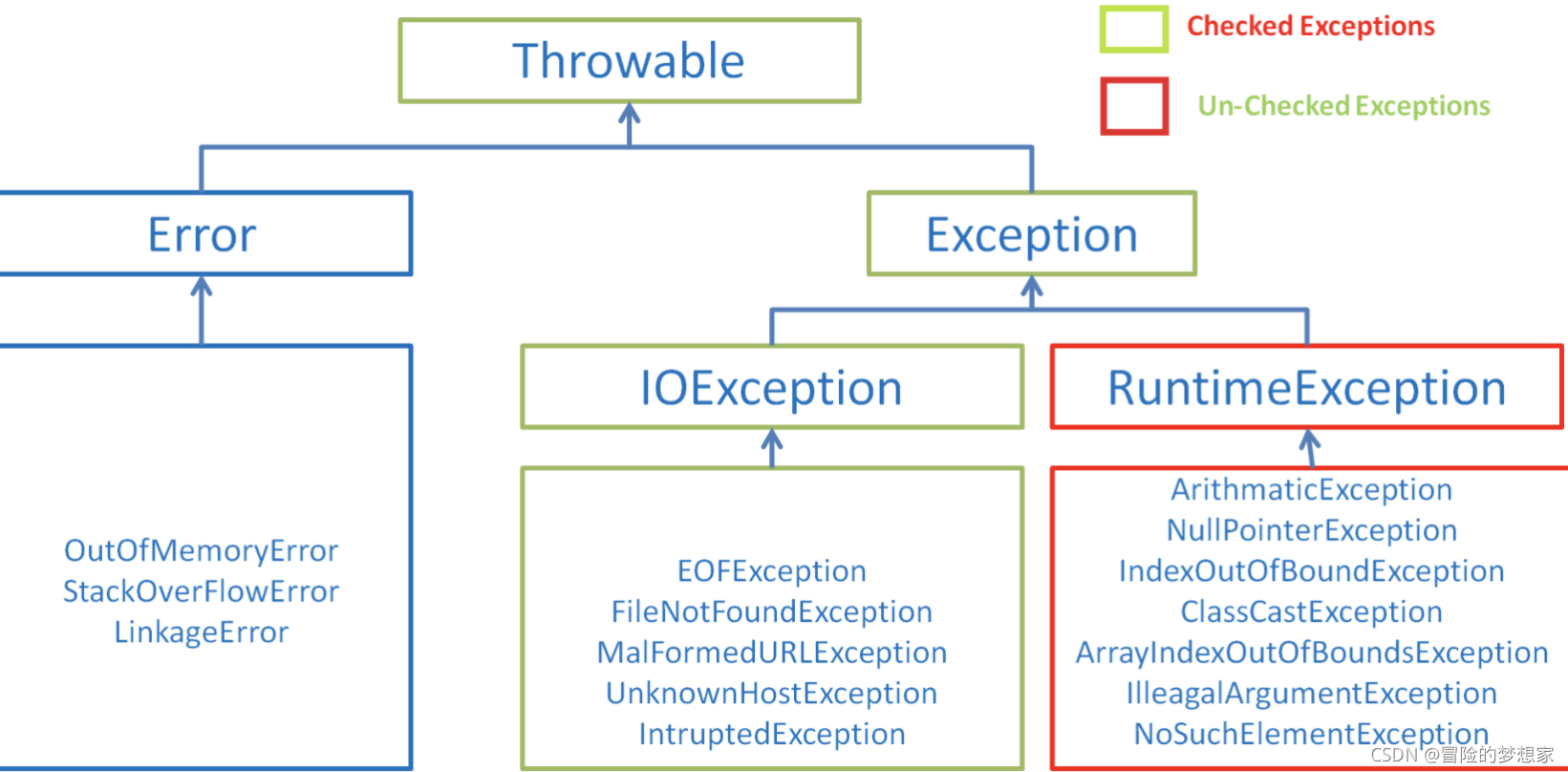
在 Java 中,所有的例外都有一個共同的祖先 java.lang 包中的 Throwable 類,Throwable 類有兩個重要的子類 Exception(例外)和 Error(錯誤),Exception 能被程式本身處理(try-catch), Error 是無法處理的(只能盡量避免),
Exception 和 Error 二者都是 Java 例外處理的重要子類,各自都包含大量子類,
**Exception**:程式本身可以處理的例外,可以通過catch來進行捕獲,Exception又可以分為 受檢查例外(必須處理) 和 不受檢查例外(可以不處理),**Error**:Error屬于程式無法處理的錯誤 ,我們沒辦法通過catch來進行捕獲 ,例如,Java 虛擬機運行錯誤(Virtual MachineError)、虛擬機記憶體不夠錯誤(OutOfMemoryError)、類定義錯誤(NoClassDefFoundError)等 ,這些例外發生時,Java 虛擬機(JVM)一般會選擇執行緒終止,
受檢查例外
Java 代碼在編譯程序中,如果受檢查例外沒有被 catch/throw 處理的話,就沒辦法通過編譯 ,比如下面這段 IO 操作的代碼,
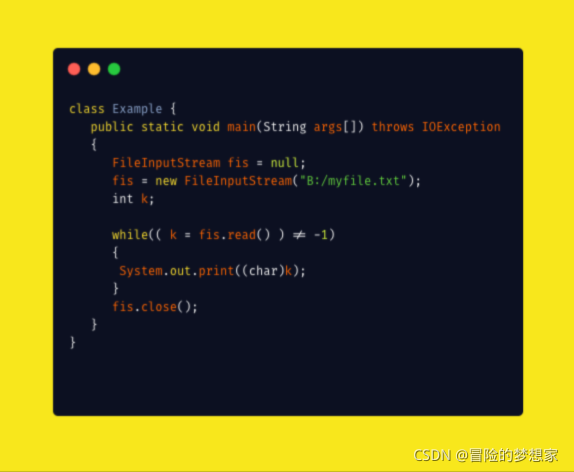
除了RuntimeException及其子類以外,其他的Exception類及其子類都屬于受檢查例外 ,常見的受檢查例外有: IO 相關的例外、ClassNotFoundException 、SQLException…,
不受檢查例外
Java 代碼在編譯程序中 ,我們即使不處理不受檢查例外也可以正常通過編譯,
RuntimeException 及其子類都統稱為非受檢查例外,例如:NullPointerException、NumberFormatException(字串轉換為數字)、ArrayIndexOutOfBoundsException(陣列越界)、ClassCastException(型別轉換錯誤)、ArithmeticException(算術錯誤)等,
Throwable 類常用方法
**public String getMessage()**:回傳例外發生時的簡要描述**public String toString()**:回傳例外發生時的詳細資訊**public String getLocalizedMessage()**:回傳例外物件的本地化資訊,使用Throwable的子類覆寫這個方法,可以生成本地化資訊,如果子類沒有覆寫該方法,則該方法回傳的資訊與getMessage()回傳的結果相同**public void printStackTrace()**:在控制臺上列印Throwable物件封裝的例外資訊
try-catch-finally
**try**塊: 用于捕獲例外,其后可接零個或多個catch塊,如果沒有catch塊,則必須跟一個finally塊,**catch**塊: 用于處理 try 捕獲到的例外,**finally**** 塊:** 無論是否捕獲或處理例外,finally塊里的陳述句都會被執行,當在try塊或catch塊中遇到return陳述句時,finally陳述句塊將在方法回傳之前被執行,
在以下 3 種特殊情況下,**finally**** 塊不會被執行:**
- 在
try或finally塊中用了System.exit(int)退出程式,但是,如果System.exit(int)在例外陳述句之后,finally還是會被執行 - 程式所在的執行緒死亡,
- 關閉 CPU,
下面這部分內容來自 issue:https://github.com/Snailclimb/JavaGuide/issues/190,
注意: 當 try 陳述句和 finally 陳述句中都有 return 陳述句時,在方法回傳之前,finally 陳述句的內容將被執行,并且 finally 陳述句的回傳值將會覆寫原始的回傳值,如下:
public class Test {
public static int f(int value) {
try {
return value * value;
} finally {
if (value == 2) {
return 0;
}
}
}
}
如果呼叫 f(2),回傳值將是 0,因為 finally 陳述句的回傳值覆寫了 try 陳述句塊的回傳值,
使用 try-with-resources 來代替try-catch-finally
- 適用范圍(資源的定義): 任何實作
java.lang.AutoCloseable或者java.io.Closeable的物件 - 關閉資源和 finally 塊的執行順序: 在
try-with-resources陳述句中,任何 catch 或 finally 塊在宣告的資源關閉后運行
《Effecitve Java》中明確指出:
面對必須要關閉的資源,我們總是應該優先使用
try-with-resources而不是try-finally,隨之產生的代碼更簡短,更清晰,產生的例外對我們也更有用,try-with-resources陳述句讓我們更容易撰寫必須要關閉的資源的代碼,若采用try-finally則幾乎做不到這點,
Java 中類似于InputStream、OutputStream 、Scanner 、PrintWriter等的資源都需要我們呼叫close()方法來手動關閉,一般情況下我們都是通過try-catch-finally陳述句來實作這個需求,如下:
//讀取文本檔案的內容
Scanner scanner = null;
try {
scanner = new Scanner(new File("D://read.txt"));
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}
使用 Java 7 之后的 try-with-resources 陳述句改造上面的代碼:
try (Scanner scanner = new Scanner(new File("test.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace();
}
當然多個資源需要關閉的時候,使用 try-with-resources 實作起來也非常簡單,如果你還是用try-catch-finally可能會帶來很多問題,
通過使用分號分隔,可以在try-with-resources塊中宣告多個資源,
try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
int b;
while ((b = bin.read()) != -1) {
bout.write(b);
}
}
catch (IOException e) {
e.printStackTrace();
}
Java常見關鍵字總結
final,static,this,super 關鍵字總結
final 關鍵字
final 關鍵字,意思是最終的、不可修改的,最見不得變化 ,用來修飾類、方法和變數,具有以下特點:
- final 修飾的類不能被繼承,final 類中的所有成員方法都會被隱式的指定為 final 方法;
- final 修飾的方法不能被重寫;
- final 修飾的變數是常量,如果是基本資料型別的變數,則其數值一旦在初始化之后便不能更改;如果是參考型別的變數,則在對其初始化之后便不能讓其指向另一個物件,
說明:使用 final 方法的原因有兩個,第一個原因是把方法鎖定,以防任何繼承類修改它的含義;第二個原因是效率,在早期的 Java 實作版本中,會將 final 方法轉為內嵌呼叫,但是如果方法過于龐大,可能看不到內嵌呼叫帶來的任何性能提升(現在的 Java 版本已經不需要使用 final 方法進行這些優化了),類中所有的 private 方法都隱式地指定為 final,
static 關鍵字
static 關鍵字主要有以下四種使用場景:
- 修飾成員變數和成員方法: 被 static 修飾的成員屬于類,不屬于單個這個類的某個物件,被類中所有物件共享,可以并且建議通過類名呼叫,被 static 宣告的成員變數屬于靜態成員變數,靜態變數 存放在 Java 記憶體區域的方法區,呼叫格式:
類名.靜態變數名類名.靜態方法名() - 靜態代碼塊: 靜態代碼塊定義在類中方法外, 靜態代碼塊在非靜態代碼塊之前執行(靜態代碼塊—>非靜態代碼塊—>構造方法), 該類不管創建多少物件,靜態代碼塊只執行一次.
- 靜態內部類(static 修飾類的話只能修飾內部類): 靜態內部類與非靜態內部類之間存在一個最大的區別: 非靜態內部類在編譯完成之后會隱含地保存著一個參考,該參考是指向創建它的外圍類,但是靜態內部類卻沒有,沒有這個參考就意味著:1. 它的創建是不需要依賴外圍類的創建,2. 它不能使用任何外圍類的非 static 成員變數和方法,
- 靜態導包(用來匯入類中的靜態資源,1.5 之后的新特性): 格式為:
import static這兩個關鍵字連用可以指定匯入某個類中的指定靜態資源,并且不需要使用類名呼叫類中靜態成員,可以直接使用類中靜態成員變數和成員方法,
this 關鍵字
this 關鍵字用于參考類的當前實體, 例如:
class Manager {
Employees[] employees;
void manageEmployees() {
int totalEmp = this.employees.length;
System.out.println("Total employees: " + totalEmp);
this.report();
}
void report() { }
}
在上面的示例中,this 關鍵字用于兩個地方:
- this.employees.length:訪問類 Manager 的當前實體的變數,
- this.report():呼叫類 Manager 的當前實體的方法,
此關鍵字是可選的,這意味著如果上面的示例在不使用此關鍵字的情況下表現相同, 但是,使用此關鍵字可能會使代碼更易讀或易懂,
super 關鍵字
super 關鍵字用于從子類訪問父類的變數和方法, 例如:
public class Super {
protected int number;
protected showNumber() {
System.out.println("number = " + number);
}
}
public class Sub extends Super {
void bar() {
super.number = 10;
super.showNumber();
}
}
在上面的例子中,Sub 類訪問父類成員變數 number 并呼叫其父類 Super 的 showNumber() 方法,
使用 this 和 super 要注意的問題:
- 在構造器中使用
super()呼叫父類中的其他構造方法時,該陳述句必須處于構造器的首行,否則編譯器會報錯,另外,this 呼叫本類中的其他構造方法時,也要放在首行, - this、super 不能用在 static 方法中,
簡單解釋一下:
被 static 修飾的成員屬于類,不屬于單個這個類的某個物件,被類中所有物件共享,而 this 代表對本類物件的參考,指向本類物件;而 super 代表對父類物件的參考,指向父類物件;所以, this 和 super 是屬于物件范疇的東西,而靜態方法是屬于類范疇的東西,
?
2、Java集合類
Collection 子介面之 List
Arraylist 和 Vector 的區別?
ArrayList是List的主要實作類,底層使用Object[ ]存盤,適用于頻繁的查找作業,執行緒不安全 ;Vector是List的古老實作類,底層使用Object[ ]存盤,執行緒安全的,
Arraylist 與 LinkedList 區別?
- 是否保證執行緒安全:
ArrayList和LinkedList都是不同步的,也就是不保證執行緒安全; - 底層資料結構:
Arraylist底層使用的是**Object**** 陣列**;LinkedList底層使用的是 雙向鏈表 資料結構(JDK1.6 之前為回圈鏈表,JDK1.7 取消了回圈,注意雙向鏈表和雙向回圈鏈表的區別,下面有介紹到!) - 插入和洗掉是否受元素位置的影響:
ArrayList采用陣列存盤,所以插入和洗掉元素的時間復雜度受元素位置的影響, 比如:執行add(E e)方法的時候,ArrayList會默認在將指定的元素追加到此串列的末尾,這種情況時間復雜度就是 O(1),但是如果要在指定位置 i 插入和洗掉元素的話(add(int index, E element))時間復雜度就為 O(n-i),因為在進行上述操作的時候集合中第 i 和第 i 個元素之后的(n-i)個元素都要執行向后位/向前移一位的操作,LinkedList采用鏈表存盤,所以,如果是在頭尾插入或者洗掉元素不受元素位置的影響(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),近似 O(1),如果是要在指定位置i插入和洗掉元素的話(add(int index, E element),remove(Object o)) 時間復雜度近似為 O(n) ,因為需要先移動到指定位置再插入,
- 是否支持快速隨機訪問:
LinkedList不支持高效的隨機元素訪問,而ArrayList支持,快速隨機訪問就是通過元素的序號快速獲取元素物件(對應于get(int index)方法), - 記憶體空間占用: ArrayList 的空 間浪費主要體現在在 list 串列的結尾會預留一定的容量空間,而 LinkedList 的空間花費則體現在它的每一個元素都需要消耗比 ArrayList 更多的空間(因為要存放直接后繼和直接前驅以及資料),
Collection 子介面之 Set
comparable 和 Comparator 的區別
comparable介面實際上是出自java.lang包 它有一個compareTo(Object obj)方法用來排序comparator介面實際上是出自 java.util 包它有一個compare(Object obj1, Object obj2)方法用來排序
一般我們需要對一個集合使用自定義排序時,我們就要重寫compareTo()方法或compare()方法,當我們需要對某一個集合實作兩種排序方式,比如一個 song 物件中的歌名和歌手名分別采用一種排序方法的話,我們可以重寫compareTo()方法和使用自制的Comparator方法或者以兩個 Comparator 來實作歌名排序和歌星名排序,第二種代表我們只能使用兩個引數版的 Collections.sort().
Comparator 定制排序
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
System.out.println("原始陣列:");
System.out.println(arrayList);
// void reverse(List list):反轉
Collections.reverse(arrayList);
System.out.println("Collections.reverse(arrayList):");
System.out.println(arrayList);
// void sort(List list),按自然排序的升序排序
Collections.sort(arrayList);
System.out.println("Collections.sort(arrayList):");
System.out.println(arrayList);
// 定制排序的用法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
System.out.println("定制排序后:");
System.out.println(arrayList);
Output:
原始陣列:
[-1, 3, 3, -5, 7, 4, -9, -7]
Collections.reverse(arrayList):
[-7, -9, 4, 7, -5, 3, 3, -1]
Collections.sort(arrayList):
[-9, -7, -5, -1, 3, 3, 4, 7]
定制排序后:
[7, 4, 3, 3, -1, -5, -7, -9]
重寫 compareTo 方法實作按年齡來排序
// person物件沒有實作Comparable介面,所以必須實作,這樣才不會出錯,才可以使treemap中的資料按順序排列
// 前面一個例子的String類已經默認實作了Comparable介面,詳細可以查看String類的API檔案,另外其他
// 像Integer類等都已經實作了Comparable介面,所以不需要另外實作了
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* T重寫compareTo方法實作按年齡來排序
*/
@Override
public int compareTo(Person o) {
if (this.age > o.getAge()) {
return 1;
}
if (this.age < o.getAge()) {
return -1;
}
return 0;
}
}
public static void main(String[] args) {
TreeMap<Person, String> pdata = new TreeMap<Person, String>();
pdata.put(new Person("張三", 30), "zhangsan");
pdata.put(new Person("李四", 20), "lisi");
pdata.put(new Person("王五", 10), "wangwu");
pdata.put(new Person("小紅", 5), "xiaohong");
// 得到key的值的同時得到key所對應的值
Set<Person> keys = pdata.keySet();
for (Person key : keys) {
System.out.println(key.getAge() + "-" + key.getName());
}
}
Output:
5-小紅
10-王五
20-李四
30-張三
無序性和不可重復性的含義是什么
1、什么是無序性?無序性不等于隨機性 ,無序性是指存盤的資料在底層陣列中并非按照陣列索引的順序添加 ,而是根據資料的哈希值決定的,
2、什么是不可重復性?不可重復性是指添加的元素按照 equals()判斷時 ,回傳 false,需要同時重寫 equals()方法和 HashCode()方法,
比較 HashSet、LinkedHashSet 和 TreeSet 三者的異同
HashSet 是 Set 介面的主要實作類 ,HashSet 的底層是 HashMap,執行緒不安全的,可以存盤 null 值;
LinkedHashSet 是 HashSet 的子類,能夠按照添加的順序遍歷;
TreeSet 底層使用紅黑樹,元素是有序的,排序的方式有自然排序和定制排序,
Map 介面
HashMap 和 Hashtable 的區別
- 執行緒是否安全:
HashMap是非執行緒安全的,Hashtable是執行緒安全的,因為Hashtable內部的方法基本都經過synchronized修飾,(如果你要保證執行緒安全的話就使用ConcurrentHashMap吧!); - 效率: 因為執行緒安全的問題,
HashMap要比Hashtable效率高一點,另外,Hashtable基本被淘汰,不要在代碼中使用它; - 對 Null key 和 Null value 的支持:
HashMap可以存盤 null 的 key 和 value,但 null 作為鍵只能有一個,null 作為值可以有多個;Hashtable 不允許有 null 鍵和 null 值,否則會拋出NullPointerException, - 初始容量大小和每次擴充容量大小的不同 : ① 創建時如果不指定容量初始值,
Hashtable默認的初始大小為 11,之后每次擴充,容量變為原來的 2n+1,HashMap默認的初始化大小為 16,之后每次擴充,容量變為原來的 2 倍,② 創建時如果給定了容量初始值,那么 Hashtable 會直接使用你給定的大小,而HashMap會將其擴充為 2 的冪次方大小(HashMap中的tableSizeFor()方法保證,下面給出了源代碼),也就是說HashMap總是使用 2 的冪作為哈希表的大小,后面會介紹到為什么是 2 的冪次方, - 底層資料結構: JDK1.8 以后的
HashMap在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為 8)(將鏈表轉換成紅黑樹前會判斷,如果當前陣列的長度小于 64,那么會選擇先進行陣列擴容,而不是轉換為紅黑樹)時,將鏈表轉化為紅黑樹,以減少搜索時間,Hashtable 沒有這樣的機制,
**HashMap**** 中帶有初始容量的建構式:**
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
下面這個方法保證了 HashMap 總是使用 2 的冪作為哈希表的大小,
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap 和 HashSet 區別
如果你看過 HashSet 原始碼的話就應該知道:HashSet 底層就是基于 HashMap 實作的,(HashSet 的原始碼非常非常少,因為除了 clone()、writeObject()、readObject()是 HashSet 自己不得不實作之外,其他方法都是直接呼叫 HashMap 中的方法,
HashMap | HashSet |
|---|---|
實作了 Map | |
| 介面 | 實作 Set |
| 介面 | |
| 存盤鍵值對 | 僅存盤物件 |
呼叫 put() | |
| 向 map 中添加元素 | 呼叫 add() |
方法向 Set
中添加元素 |
| HashMap
使用鍵(Key)計算 hashcode | HashSet
使用成員物件來計算 hashcode
值,對于兩個物件來說 hashcode
可能相同,所以equals()
方法用來判斷物件的相等性 |
HashMap 和 TreeMap 區別
TreeMap 和HashMap 都繼承自AbstractMap ,但是需要注意的是TreeMap它還實作了NavigableMap介面和SortedMap 介面,
實作 NavigableMap 介面讓 TreeMap 有了對集合內元素的搜索的能力,
實作SortedMap介面讓 TreeMap 有了對集合中的元素根據鍵排序的能力,默認是按 key 的升序排序,不過我們也可以指定排序的比較器,示例代碼如下:
/**
* @author shuang.kou
* @createTime 2020年06月15日 17:02:00
*/
public class Person {
private Integer age;
public Person(Integer age) {
this.age = age;
}
public Integer getAge() {
return age;
}
public static void main(String[] args) {
TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person person1, Person person2) {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
}
});
treeMap.put(new Person(3), "person1");
treeMap.put(new Person(18), "person2");
treeMap.put(new Person(35), "person3");
treeMap.put(new Person(16), "person4");
treeMap.entrySet().stream().forEach(personStringEntry -> {
System.out.println(personStringEntry.getValue());
});
}
}
輸出:
person1
person4
person2
person3
可以看出,TreeMap 中的元素已經是按照 Person 的 age 欄位的升序來排列了,
上面,我們是通過傳入匿名內部類的方式實作的,你可以將代碼替換成 Lambda 運算式實作的方式:
TreeMap<Person, String> treeMap = new TreeMap<>((person1, person2) -> {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
});
綜上,相比于**HashMap**來說 **TreeMap** 主要多了對集合中的元素根據鍵排序的能力以及對集合內元素的搜索的能力,
HashSet 如何檢查重復
以下內容摘自我的 Java 啟蒙書《Head first java》第二版:
當你把物件加入HashSet時,HashSet 會先計算物件的hashcode值來判斷物件加入的位置,同時也會與其他加入的物件的 hashcode 值作比較,如果沒有相符的 hashcode,HashSet 會假設物件沒有重復出現,但是如果發現有相同 hashcode 值的物件,這時會呼叫equals()方法來檢查 hashcode 相等的物件是否真的相同,如果兩者相同,HashSet 就不會讓加入操作成功,
在openjdk8中,HashSet的add()方法只是簡單的呼叫了HashMap的put()方法,并且判斷了一下回傳值以確保是否有重復元素,直接看一下HashSet中的原始碼:
// Returns: true if this set did not already contain the specified element
// 回傳值:當set中沒有包含add的元素時回傳真
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
而在HashMap的putVal()方法中也能看到如下說明:
// Returns : previous value, or null if none
// 回傳值:如果插入位置沒有元素回傳null,否則回傳上一個元素
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
}
也就是說,在openjdk8中,實際上無論HashSet中是否已經存在了某元素,HashSet都會直接插入,只是會在add()方法的回傳值處告訴我們插入前是否存在相同元素,
**hashCode()**與 **equals()** 的相關規定:
- 如果兩個物件相等,則
hashcode一定也是相同的 - 兩個物件相等,對兩個
equals()方法回傳 true - 兩個物件有相同的
hashcode值,它們也不一定是相等的 - 綜上,
equals()方法被覆寫過,則hashCode()方法也必須被覆寫 hashCode()的默認行為是對堆上的物件產生獨特值,如果沒有重寫hashCode(),則該 class 的兩個物件無論如何都不會相等(即使這兩個物件指向相同的資料),
==與 equals 的區別
對于基本型別來說,== 比較的是值是否相等;
對于參考型別來說,== 比較的是兩個參考是否指向同一個物件地址(兩者在記憶體中存放的地址(堆記憶體地址)是否指向同一個地方);
對于參考型別(包括包裝型別)來說,equals 如果沒有被重寫,對比它們的地址是否相等;如果 equals()方法被重寫(例如 String),則比較的是地址里的內容,
HashMap 的底層實作
JDK1.8 之前
JDK1.8 之前 HashMap 底層是 陣列和鏈表 結合在一起使用也就是 鏈表散列,HashMap 通過 key 的 hashCode 經過擾動函式處理過后得到 hash 值,然后通過 (n - 1) & hash 判斷當前元素存放的位置(這里的 n 指的是陣列的長度),如果當前位置存在元素的話,就判斷該元素與要存入的元素的 hash 值以及 key 是否相同,如果相同的話,直接覆寫,不相同就通過拉鏈法解決沖突,
所謂擾動函式指的就是 HashMap 的 hash 方法,使用 hash 方法也就是擾動函式是為了防止一些實作比較差的 hashCode() 方法 換句話說使用擾動函式之后可以減少碰撞,
JDK 1.8 HashMap 的 hash 方法原始碼:
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加簡化,但是原理不變,
static final int hash(Object key) {
int h;
// key.hashCode():回傳散列值也就是hashcode
// ^ :按位異或
// >>>:無符號右移,忽略符號位,空位都以0補齊
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
對比一下 JDK1.7 的 HashMap 的 hash 方法原始碼.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能會稍差一點點,因為畢竟擾動了 4 次,
所謂 “拉鏈法” 就是:將鏈表和陣列相結合,也就是說創建一個鏈表陣列,陣列中每一格就是一個鏈表,若遇到哈希沖突,則將沖突的值加到鏈表中即可,
JDK1.8 之后
相比于之前的版本, JDK1.8 之后在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為 8)(將鏈表轉換成紅黑樹前會判斷,如果當前陣列的長度小于 64,那么會選擇先進行陣列擴容,而不是轉換為紅黑樹)時,將鏈表轉化為紅黑樹,以減少搜索時間,
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底層都用到了紅黑樹,紅黑樹就是為了解決二叉查找樹的缺陷,因為二叉查找樹在某些情況下會退化成一個線性結構,
HashMap 的長度為什么是 2 的冪次方
為了能讓 HashMap 存取高效,盡量較少碰撞,也就是要盡量把資料分配均勻,我們上面也講到了過了,Hash 值的范圍值-2147483648 到 2147483647,前后加起來大概 40 億的映射空間,只要哈希函式映射得比較均勻松散,一般應用是很難出現碰撞的,但問題是一個 40 億長度的陣列,記憶體是放不下的,所以這個散列值是不能直接拿來用的,用之前還要先做對陣列的長度取模運算,得到的余數才能用來要存放的位置也就是對應的陣列下標,這個陣列下標的計算方法是“ (n - 1) & hash”,(n 代表陣列長度),這也就解釋了 HashMap 的長度為什么是 2 的冪次方,
這個演算法應該如何設計呢?
我們首先可能會想到采用%取余的操作來實作,但是,重點來了:“取余(%)操作中如果除數是 2 的冪次則等價于與其除數減一的與(&)操作(也就是說 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;),” 并且 采用二進制位操作 &,相對于%能夠提高運算效率,這就解釋了 HashMap 的長度為什么是 2 的冪次方,
HashMap 多執行緒操作導致死回圈問題
主要原因在于并發下的 Rehash 會造成元素之間會形成一個回圈鏈表,不過,jdk 1.8 后解決了這個問題,但是還是不建議在多執行緒下使用 HashMap,因為多執行緒下使用 HashMap 還是會存在其他問題比如資料丟失,并發環境下推薦使用 ConcurrentHashMap ,
詳情請查看:https://coolshell.cn/articles/9606.html
HashMap 有哪幾種常見的遍歷方式?
HashMap 的 7 種遍歷方式與性能分析!
ConcurrentHashMap 和 Hashtable 的區別
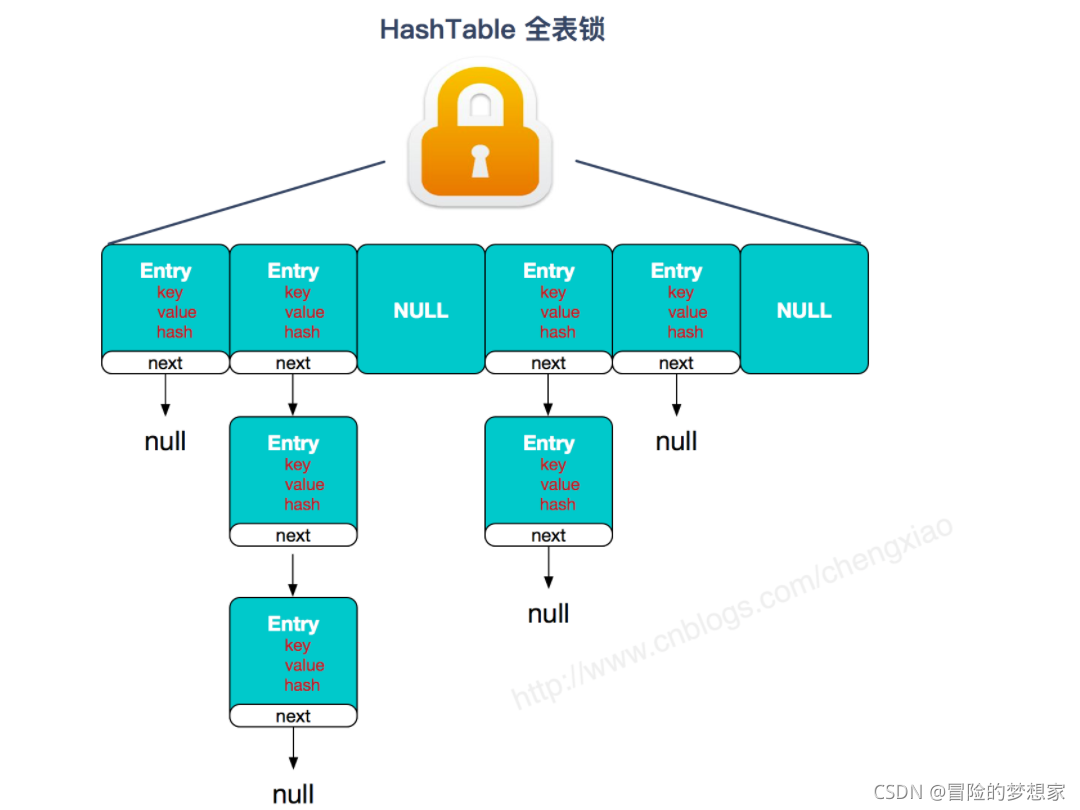
ConcurrentHashMap 和 Hashtable 的區別主要體現在實作執行緒安全的方式上不同,
- 底層資料結構: JDK1.7 的
ConcurrentHashMap底層采用 分段的陣列+鏈表 實作,JDK1.8 采用的資料結構跟HashMap1.8的結構一樣,陣列+鏈表/紅黑二叉樹,Hashtable和 JDK1.8 之前的HashMap的底層資料結構類似都是采用 陣列+鏈表 的形式,陣列是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的; - 實作執行緒安全的方式(重要): ① 在 JDK1.7 的時候,
**ConcurrentHashMap**(分段鎖) 對整個桶陣列進行了分割分段(Segment),每一把鎖只鎖容器其中一部分資料,多執行緒訪問容器里不同資料段的資料,就不會存在鎖競爭,提高并發訪問率, 到了 JDK1.8 的時候已經摒棄了**Segment**的概念,而是直接用**Node**陣列+鏈表+紅黑樹的資料結構來實作,并發控制使用**synchronized**和 CAS 來操作,(JDK1.6 以后 對**synchronized**鎖做了很多優化) 整個看起來就像是優化過且執行緒安全的HashMap,雖然在 JDK1.8 中還能看到Segment的資料結構,但是已經簡化了屬性,只是為了兼容舊版本;②**Hashtable**(同一把鎖) :使用synchronized來保證執行緒安全,效率非常低下,當一個執行緒訪問同步方法時,其他執行緒也訪問同步方法,可能會進入阻塞或輪詢狀態,如使用 put 添加元素,另一個執行緒不能使用 put 添加元素,也不能使用 get,競爭會越來越激烈效率越低,
兩者的對比圖:
Hashtable:
https://www.cnblogs.com/chengxiao/p/6842045.html>
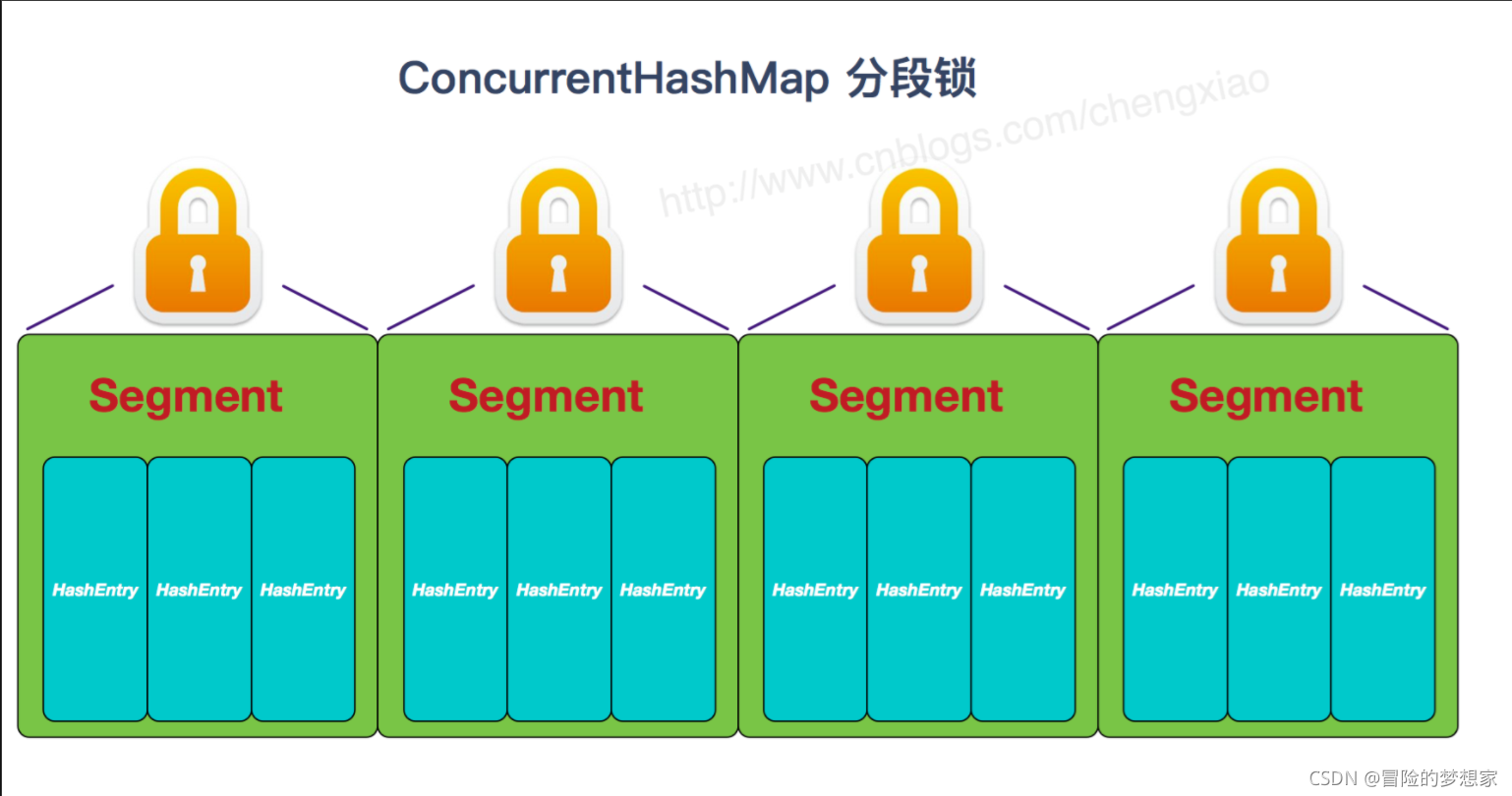
JDK1.7 的 ConcurrentHashMap:
https://www.cnblogs.com/chengxiao/p/6842045.html>
JDK1.8 的 ConcurrentHashMap:
JDK1.8 的 ConcurrentHashMap 不再是 Segment 陣列 + HashEntry 陣列 + 鏈表,而是 Node 陣列 + 鏈表 / 紅黑樹,不過,Node 只能用于鏈表的情況,紅黑樹的情況需要使用 **TreeNode**,當沖突鏈表達到一定長度時,鏈表會轉換成紅黑樹,
ConcurrentHashMap 執行緒安全的具體實作方式/底層具體實作
JDK1.7(上面有示意圖)
首先將資料分為一段一段的存盤,然后給每一段資料配一把鎖,當一個線程占用鎖訪問其中一個段資料時,其他段的資料也能被其他執行緒訪問,
**ConcurrentHashMap**** 是由 **Segment** 陣列結構和 **HashEntry** 陣列結構組成**,
Segment 實作了 ReentrantLock,所以 Segment 是一種可重入鎖,扮演鎖的角色,HashEntry 用于存盤鍵值對資料,
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
一個 ConcurrentHashMap 里包含一個 Segment 陣列,Segment 的結構和 HashMap 類似,是一種陣列和鏈表結構,一個 Segment 包含一個 HashEntry 陣列,每個 HashEntry 是一個鏈表結構的元素,每個 Segment 守護著一個 HashEntry 陣列里的元素,當對 HashEntry 陣列的資料進行修改時,必須首先獲得對應的 Segment 的鎖,
10.2. JDK1.8 (上面有示意圖)
ConcurrentHashMap 取消了 Segment 分段鎖,采用 CAS 和 synchronized 來保證并發安全,資料結構跟 HashMap1.8 的結構類似,陣列+鏈表/紅黑二叉樹,Java 8 在鏈表長度超過一定閾值(8)時將鏈表(尋址時間復雜度為 O(N))轉換為紅黑樹(尋址時間復雜度為 O(log(N)))
synchronized 只鎖定當前鏈表或紅黑二叉樹的首節點,這樣只要 hash 不沖突,就不會產生并發,效率又提升 N 倍,
Collections 工具類
Collections 工具類常用方法:
- 排序
- 查找,替換操作
- 同步控制(不推薦,需要執行緒安全的集合型別時請考慮使用 JUC 包下的并發集合)
排序操作
void reverse(List list)//反轉
void shuffle(List list)//隨機排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序邏輯
void swap(List list, int i , int j)//交換兩個索引位置的元素
void rotate(List list, int distance)//旋轉,當distance為正數時,將list后distance個元素整體移到前面,當distance為負數時,將 list的前distance個元素整體移到后面
查找,替換操作
int binarySearch(List list, Object key)//對List進行二分查找,回傳索引,注意List必須是有序的
int max(Collection coll)//根據元素的自然順序,回傳最大的元素, 類比int min(Collection coll)
int max(Collection coll, Comparator c)//根據定制排序,回傳最大元素,排序規則由Comparatator類控制,類比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素
int frequency(Collection c, Object o)//統計元素出現次數
int indexOfSubList(List list, List target)//統計target在list中第一次出現的索引,找不到則回傳-1,類比int lastIndexOfSubList(List source, list target)
boolean replaceAll(List list, Object oldVal, Object newVal)//用新元素替換舊元素
同步控制
Collections 提供了多個synchronizedXxx()方法·,該方法可以將指定集合包裝成執行緒同步的集合,從而解決多執行緒并發訪問集合時的執行緒安全問題,
我們知道 HashSet,TreeSet,ArrayList,LinkedList,HashMap,TreeMap 都是執行緒不安全的,Collections 提供了多個靜態方法可以把他們包裝成執行緒同步的集合,
最好不要用下面這些方法,效率非常低,需要執行緒安全的集合型別時請考慮使用 JUC 包下的并發集合,
方法如下:
synchronizedCollection(Collection<T> c) //回傳指定 collection 支持的同步(執行緒安全的)collection,
synchronizedList(List<T> list)//回傳指定串列支持的同步(執行緒安全的)List,
synchronizedMap(Map<K,V> m) //回傳由指定映射支持的同步(執行緒安全的)Map,
synchronizedSet(Set<T> s) //回傳指定 set 支持的同步(執行緒安全的)set,
3、Java并發
說說并發與并行的區別?
- 并發: 同一時間段,多個任務都在執行 (單位時間內不一定同時執行);
- 并行: 單位時間內,多個任務同時執行,
為什么要使用多執行緒呢?
先從總體上來說:
- 從計算機底層來說: 執行緒可以比作是輕量級的行程,是程式執行的最小單位,執行緒間的切換和調度的成本遠遠小于行程,另外,多核 CPU 時代意味著多個執行緒可以同時運行,這減少了執行緒背景關系切換的開銷,
- 從當代互聯網發展趨勢來說: 現在的系統動不動就要求百萬級甚至千萬級的并發量,而多執行緒并發編程正是開發高并發系統的基礎,利用好多執行緒機制可以大大提高系統整體的并發能力以及性能,
再深入到計算機底層來探討:
- 單核時代: 在單核時代多執行緒主要是為了提高單行程利用 CPU 和 IO 系統的效率, 假設只運行了一個 Java 行程的情況,當我們請求 IO 的時候,如果 Java 行程中只有一個執行緒,此執行緒被 IO 阻塞則整個行程被阻塞,CPU 和 IO 設備只有一個在運行,那么可以簡單地說系統整體效率只有 50%,當使用多執行緒的時候,一個執行緒被 IO 阻塞,其他執行緒還可以繼續使用 CPU,從而提高了 Java 行程利用系統資源的整體效率,
- 多核時代: 多核時代多執行緒主要是為了提高行程利用多核 CPU 的能力,舉個例子:假如我們要計算一個復雜的任務,我們只用一個執行緒的話,不論系統有幾個 CPU 核心,都只會有一個 CPU 核心被利用到,而創建多個執行緒,這些執行緒可以被映射到底層多個 CPU 上執行,在任務中的多個執行緒沒有資源競爭的情況下,任務執行的效率會有顯著性的提高,約等于(單核時執行時間/CPU 核心數),
使用多執行緒可能帶來什么問題?
并發編程的目的就是為了能提高程式的執行效率提高程式運行速度,但是并發編程并不總是能提高程式運行速度的,而且并發編程可能會遇到很多問題,比如:記憶體泄漏、死鎖、執行緒不安全等等,
說說執行緒的生命周期和狀態?
Java 執行緒在運行的生命周期中的指定時刻只可能處于下面 6 種不同狀態的其中一個狀態(圖源《Java 并發編程藝術》4.1.4 節),

執行緒在生命周期中并不是固定處于某一個狀態而是隨著代碼的執行在不同狀態之間切換,Java 執行緒狀態變遷如下圖所示(圖源《Java 并發編程藝術》4.1.4 節):
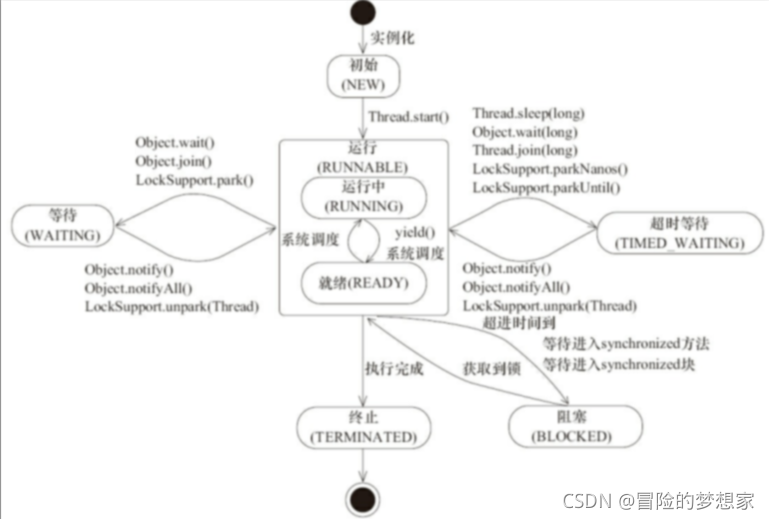
訂正(來自issue736):原圖中 wait 到 runnable 狀態的轉換中,
join實際上是Thread類的方法,但這里寫成了Object,
由上圖可以看出:執行緒創建之后它將處于 NEW(新建) 狀態,呼叫 start() 方法后開始運行,執行緒這時候處于 READY(可運行) 狀態,可運行狀態的執行緒獲得了 CPU 時間片(timeslice)后就處于 RUNNING(運行) 狀態,
在作業系統中層面執行緒有 READY 和 RUNNING 狀態,而在 JVM 層面只能看到 RUNNABLE 狀態(圖源:HowToDoInJava:Java Thread Life Cycle and Thread States),所以 Java 系統一般將這兩個狀態統稱為 RUNNABLE(運行中) 狀態 ,
為什么 JVM 沒有區分這兩種狀態呢? (摘自:java執行緒運行怎么有第六種狀態? - Dawell的回答 ) 現在的時分(time-sharing)多任務(multi-task)作業系統架構通常都是用所謂的“時間分片(time quantum or time slice)”方式進行搶占式(preemptive)輪轉調度(round-robin式),這個時間分片通常是很小的,一個執行緒一次最多只能在 CPU 上運行比如 10-20ms 的時間(此時處于 running 狀態),也即大概只有 0.01 秒這一量級,時間片用后就要被切換下來放入調度佇列的末尾等待再次調度,(也即回到 ready 狀態),執行緒切換的如此之快,區分這兩種狀態就沒什么意義了,

當執行緒執行 wait()方法之后,執行緒進入 WAITING(等待) 狀態,進入等待狀態的執行緒需要依靠其他執行緒的通知才能夠回傳到運行狀態,而 TIMED_WAITING(超時等待) 狀態相當于在等待狀態的基礎上增加了超時限制,比如通過 sleep(long millis)方法或 wait(long millis)方法可以將 Java 執行緒置于 TIMED_WAITING 狀態,當超時時間到達后 Java 執行緒將會回傳到 RUNNABLE 狀態,當執行緒呼叫同步方法時,在沒有獲取到鎖的情況下,執行緒將會進入到 BLOCKED(阻塞) 狀態,執行緒在執行 Runnable 的run()方法之后將會進入到 TERMINATED(終止) 狀態,
相關閱讀:挑錯 |《Java 并發編程的藝術》中關于執行緒狀態的三處錯誤 ,
什么是執行緒死鎖?如何避免死鎖?
認識執行緒死鎖
執行緒死鎖描述的是這樣一種情況:多個執行緒同時被阻塞,它們中的一個或者全部都在等待某個資源被釋放,由于執行緒被無限期地阻塞,因此程式不可能正常終止,
如下圖所示,執行緒 A 持有資源 2,執行緒 B 持有資源 1,他們同時都想申請對方的資源,所以這兩個執行緒就會互相等待而進入死鎖狀態,
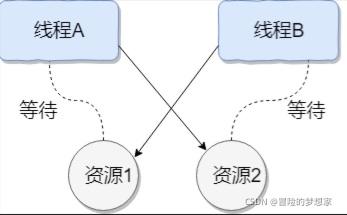
下面通過一個例子來說明執行緒死鎖,代碼模擬了上圖的死鎖的情況 (代碼來源于《并發編程之美》):
public class DeadLockDemo {
private static Object resource1 = new Object();//資源 1
private static Object resource2 = new Object();//資源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "執行緒 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "執行緒 2").start();
}
}
Output
Thread[執行緒 1,5,main]get resource1
Thread[執行緒 2,5,main]get resource2
Thread[執行緒 1,5,main]waiting get resource2
Thread[執行緒 2,5,main]waiting get resource1
執行緒 A 通過 synchronized (resource1) 獲得 resource1 的監視器鎖,然后通過Thread.sleep(1000);讓執行緒 A 休眠 1s 為的是讓執行緒 B 得到執行然后獲取到 resource2 的監視器鎖,執行緒 A 和執行緒 B 休眠結束了都開始企圖請求獲取對方的資源,然后這兩個執行緒就會陷入互相等待的狀態,這也就產生了死鎖,上面的例子符合產生死鎖的四個必要條件,
學過作業系統的朋友都知道產生死鎖必須具備以下四個條件:
- 互斥條件:該資源任意一個時刻只由一個執行緒占用,
- 請求與保持條件:一個行程因請求資源而阻塞時,對已獲得的資源保持不放,
- 不剝奪條件:執行緒已獲得的資源在未使用完之前不能被其他執行緒強行剝奪,只有自己使用完畢后才釋放資源,
- 回圈等待條件:若干行程之間形成一種頭尾相接的回圈等待資源關系,
如何預防和避免執行緒死鎖?
如何預防死鎖? 破壞死鎖的產生的必要條件即可:
- 破壞請求與保持條件 :一次性申請所有的資源,
- 破壞不剝奪條件 :占用部分資源的執行緒進一步申請其他資源時,如果申請不到,可以主動釋放它占有的資源,
- 破壞回圈等待條件 :靠按序申請資源來預防,按某一順序申請資源,釋放資源則反序釋放,破壞回圈等待條件,
如何避免死鎖?
避免死鎖就是在資源分配時,借助于演算法(比如銀行家演算法)對資源分配進行計算評估,使其進入安全狀態,
安全狀態 指的是系統能夠按照某種行程推進順序(P1、P2、P3…Pn)來為每個行程分配所需資源,直到滿足每個行程對資源的最大需求,使每個行程都可順利完成,稱<P1、P2、P3…Pn>序列為安全序列,
我們對執行緒 2 的代碼修改成下面這樣就不會產生死鎖了,
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "執行緒 2").start();
Output
Thread[執行緒 1,5,main]get resource1
Thread[執行緒 1,5,main]waiting get resource2
Thread[執行緒 1,5,main]get resource2
Thread[執行緒 2,5,main]get resource1
Thread[執行緒 2,5,main]waiting get resource2
Thread[執行緒 2,5,main]get resource2
Process finished with exit code 0
我們分析一下上面的代碼為什么避免了死鎖的發生?
執行緒 1 首先獲得到 resource1 的監視器鎖,這時候執行緒 2 就獲取不到了,然后執行緒 1 再去獲取 resource2 的監視器鎖,可以獲取到,然后執行緒 1 釋放了對 resource1、resource2 的監視器鎖的占用,執行緒 2 獲取到就可以執行了,這樣就破壞了破壞回圈等待條件,因此避免了死鎖,
說說 sleep() 方法和 wait() 方法區別和共同點?
- 兩者最主要的區別在于:
**sleep()**** 方法沒有釋放鎖,而**wait()**方法釋放了鎖** , - 兩者都可以暫停執行緒的執行,
wait()通常被用于執行緒間互動/通信,sleep()通常被用于暫停執行,wait()方法被呼叫后,執行緒不會自動蘇醒,需要別的執行緒呼叫同一個物件上的notify()或者notifyAll()方法,sleep()方法執行完成后,執行緒會自動蘇醒,或者可以使用wait(long timeout)超時后執行緒會自動蘇醒,
為什么我們呼叫 start() 方法時會執行 run() 方法,為什么我們不能直接呼叫 run() 方法?
這是另一個非常經典的 Java 多執行緒面試問題,而且在面試中會經常被問到,很簡單,但是很多人都會答不上來!
new 一個 Thread,執行緒進入了新建狀態,呼叫 start()方法,會啟動一個執行緒并使執行緒進入了就緒狀態,當分配到時間片后就可以開始運行了, start() 會執行執行緒的相應準備作業,然后自動執行 run() 方法的內容,這是真正的多執行緒作業, 但是,直接執行 run() 方法,會把 run() 方法當成一個 main 執行緒下的普通方法去執行,并不會在某個執行緒中執行它,所以這并不是多執行緒作業,
總結: 呼叫 **start()** 方法方可啟動執行緒并使執行緒進入就緒狀態,直接執行 **run()** 方法的話不會以多執行緒的方式執行,
synchronized 關鍵字
說一說自己對于 synchronized 關鍵字的了解
**synchronized**** 關鍵字解決的是多個執行緒之間訪問資源的同步性,****synchronized**關鍵字可以保證被它修飾的方法或者代碼塊在任意時刻只能有一個執行緒執行,
另外,在 Java 早期版本中,synchronized 屬于 重量級鎖,效率低下,
為什么呢?
因為監視器鎖(monitor)是依賴于底層的作業系統的 Mutex Lock 來實作的,Java 的執行緒是映射到作業系統的原生執行緒之上的,如果要掛起或者喚醒一個執行緒,都需要作業系統幫忙完成,而作業系統實作執行緒之間的切換時需要從用戶態轉換到內核態,這個狀態之間的轉換需要相對比較長的時間,時間成本相對較高,
慶幸的是在 Java 6 之后 Java 官方對從 JVM 層面對 synchronized 較大優化,所以現在的 synchronized 鎖效率也優化得很不錯了,JDK1.6 對鎖的實作引入了大量的優化,如自旋鎖、適應性自旋鎖、鎖消除、鎖粗化、偏向鎖、輕量級鎖等技術來減少鎖操作的開銷,
所以,你會發現目前的話,不論是各種開源框架還是 JDK 原始碼都大量使用了 synchronized 關鍵字,
說說自己是怎么使用 synchronized 關鍵字
synchronized 關鍵字最主要的三種使用方式:
1.修飾實體方法: 作用于當前物件實體加鎖,進入同步代碼前要獲得 當前物件實體的鎖
synchronized void method() {
//業務代碼
}
2.修飾靜態方法: 也就是給當前類加鎖,會作用于類的所有物件實體 ,進入同步代碼前要獲得 當前 class 的鎖,因為靜態成員不屬于任何一個實體物件,是類成員( static 表明這是該類的一個靜態資源,不管 new 了多少個物件,只有一份),所以,如果一個執行緒 A 呼叫一個實體物件的非靜態 synchronized 方法,而執行緒 B 需要呼叫這個實體物件所屬類的靜態 synchronized 方法,是允許的,不會發生互斥現象,因為訪問靜態 **synchronized** 方法占用的鎖是當前類的鎖,而訪問非靜態 **synchronized** 方法占用的鎖是當前實體物件鎖,
synchronized static void method() {
//業務代碼
}
3.修飾代碼塊 :指定加鎖物件,對給定物件/類加鎖,synchronized(this|object) 表示進入同步代碼庫前要獲得給定物件的鎖,synchronized(類.class) 表示進入同步代碼前要獲得 當前 class 的鎖
synchronized(this) {
//業務代碼
}
總結:
synchronized關鍵字加到static靜態方法和synchronized(class)代碼塊上都是是給 Class 類上鎖,synchronized關鍵字加到實體方法上是給物件實體上鎖,- 盡量不要使用
synchronized(String a)因為 JVM 中,字串常量池具有快取功能!
下面我以一個常見的面試題為例講解一下 synchronized 關鍵字的具體使用,
面試中面試官經常會說:“單例模式了解嗎?來給我手寫一下!給我解釋一下雙重檢驗鎖方式實作單例模式的原理唄!”
雙重校驗鎖實作物件單例(執行緒安全)
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判斷物件是否已經實體過,沒有實體化過才進入加鎖代碼
if (uniqueInstance == null) {
//類物件加鎖
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
另外,需要注意 uniqueInstance 采用 volatile 關鍵字修飾也是很有必要,
uniqueInstance 采用 volatile 關鍵字修飾也是很有必要的, uniqueInstance = new Singleton(); 這段代碼其實是分為三步執行:
- 為
uniqueInstance分配記憶體空間 - 初始化
uniqueInstance - 將
uniqueInstance指向分配的記憶體地址
但是由于 JVM 具有指令重排的特性,執行順序有可能變成 1->3->2,指令重排在單執行緒環境下不會出現問題,但是在多執行緒環境下會導致一個執行緒獲得還沒有初始化的實體,例如,執行緒 T1 執行了 1 和 3,此時 T2 呼叫 getUniqueInstance() 后發現 uniqueInstance 不為空,因此回傳 uniqueInstance,但此時 uniqueInstance 還未被初始化,
使用 volatile 可以禁止 JVM 的指令重排,保證在多執行緒環境下也能正常運行,
構造方法可以使用 synchronized 關鍵字修飾么?
先說結論:構造方法不能使用 synchronized 關鍵字修飾,
構造方法本身就屬于執行緒安全的,不存在同步的構造方法一說,
講一下 synchronized 關鍵字的底層原理
synchronized 關鍵字底層原理屬于 JVM 層面,
synchronized 同步陳述句塊的情況
public class SynchronizedDemo {
public void method() {
synchronized (this) {
System.out.println("synchronized 代碼塊");
}
}
}
通過 JDK 自帶的 javap 命令查看 SynchronizedDemo 類的相關位元組碼資訊:首先切換到類的對應目錄執行 javac SynchronizedDemo.java 命令生成編譯后的 .class 檔案,然后執行javap -c -s -v -l SynchronizedDemo.class,
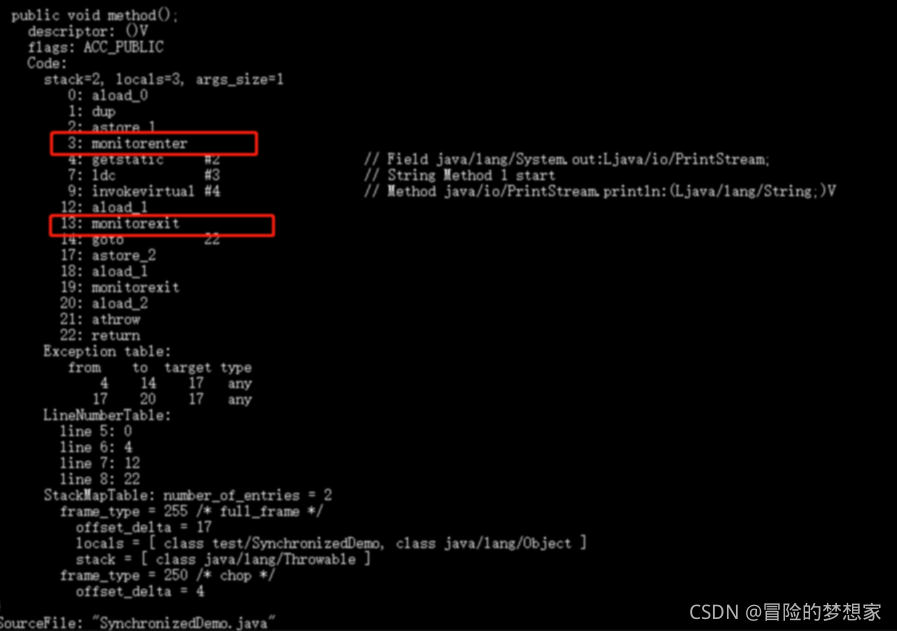
從上面我們可以看出:
**synchronized**** 同步陳述句塊的實作使用的是 **monitorenter** 和 **monitorexit** 指令,其中 **monitorenter** 指令指向同步代碼塊的開始位置,**monitorexit** 指令則指明同步代碼塊的結束位置,**
當執行 monitorenter 指令時,執行緒試圖獲取鎖也就是獲取 **物件監視器 ****monitor** 的持有權,
在 Java 虛擬機(HotSpot)中,Monitor 是基于 C++實作的,由ObjectMonitor實作的,每個物件中都內置了一個
ObjectMonitor物件,另外,
wait/notify等方法也依賴于monitor物件,這就是為什么只有在同步的塊或者方法中才能呼叫wait/notify等方法,否則會拋出java.lang.IllegalMonitorStateException的例外的原因,
在執行monitorenter時,會嘗試獲取物件的鎖,如果鎖的計數器為 0 則表示鎖可以被獲取,獲取后將鎖計數器設為 1 也就是加 1,
在執行 monitorexit 指令后,將鎖計數器設為 0,表明鎖被釋放,如果獲取物件鎖失敗,那當前執行緒就要阻塞等待,直到鎖被另外一個執行緒釋放為止,
synchronized 修飾方法的的情況
public class SynchronizedDemo2 {
public synchronized void method() {
System.out.println("synchronized 方法");
}
}
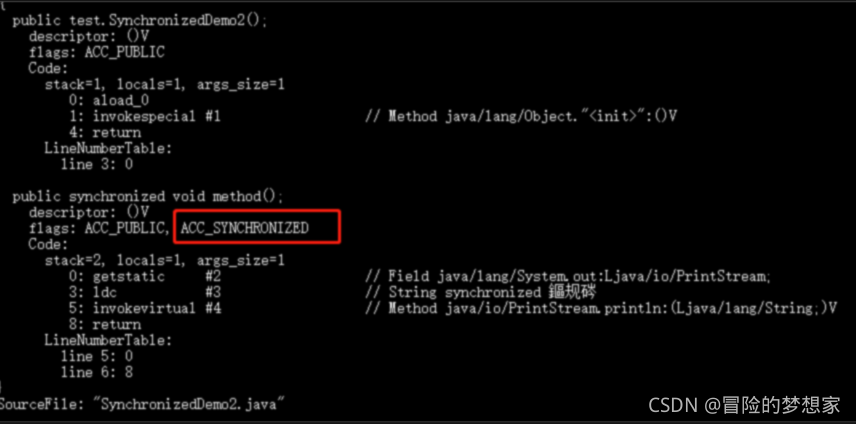
synchronized 修飾的方法并沒有 monitorenter 指令和 monitorexit 指令,取得代之的確實是 ACC_SYNCHRONIZED 標識,該標識指明了該方法是一個同步方法,JVM 通過該 ACC_SYNCHRONIZED 訪問標志來辨別一個方法是否宣告為同步方法,從而執行相應的同步呼叫,
總結
synchronized 同步陳述句塊的實作使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代碼塊的開始位置,monitorexit 指令則指明同步代碼塊的結束位置,
synchronized 修飾的方法并沒有 monitorenter 指令和 monitorexit 指令,取得代之的確實是 ACC_SYNCHRONIZED 標識,該標識指明了該方法是一個同步方法,
不過兩者的本質都是對物件監視器 monitor 的獲取,
?
volatile 關鍵字
我們先要從 CPU 快取模型 說起!
CPU 快取模型
為什么要弄一個 CPU 高速快取呢?
類比我們開發網站后臺系統使用的快取(比如 Redis)是為了解決程式處理速度和訪問常規關系型資料庫速度不對等的問題, CPU 快取則是為了解決 CPU 處理速度和記憶體處理速度不對等的問題,
我們甚至可以把 記憶體可以看作外存的高速快取,程式運行的時候我們把外存的資料復制到記憶體,由于記憶體的處理速度遠遠高于外存,這樣提高了處理速度,
總結:CPU Cache 快取的是記憶體資料用于解決 CPU 處理速度和記憶體不匹配的問題,記憶體快取的是硬碟資料用于解決硬碟訪問速度過慢的問題,
為了更好地理解,我畫了一個簡單的 CPU Cache 示意圖如下(實際上,現代的 CPU Cache 通常分為三層,分別叫 L1,L2,L3 Cache):
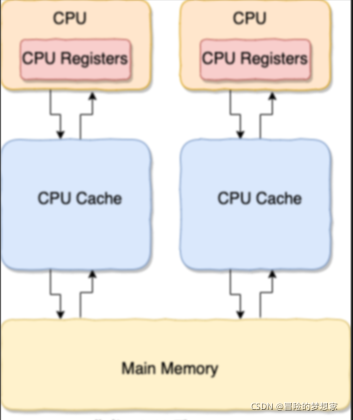
CPU Cache 的作業方式:
先復制一份資料到 CPU Cache 中,當 CPU 需要用到的時候就可以直接從 CPU Cache 中讀取資料,當運算完成后,再將運算得到的資料寫回 Main Memory 中,但是,這樣存在 記憶體快取不一致性的問題 !比如我執行一個 i操作的話,如果兩個執行緒同時執行的話,假設兩個執行緒從 CPU Cache 中讀取的 i=1,兩個執行緒做了 1運算完之后再寫回 Main Memory 之后 i=2,而正確結果應該是 i=3,
CPU 為了解決記憶體快取不一致性問題可以通過制定快取一致協議或者其他手段來解決,
講一下 JMM(Java 記憶體模型)
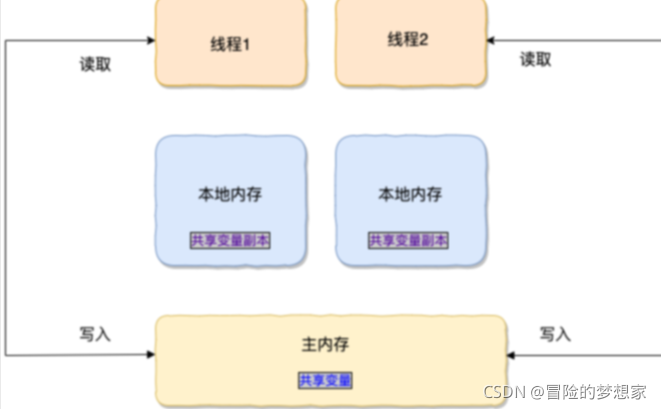
在 JDK1.2 之前,Java 的記憶體模型實作總是從主存(即共享記憶體)讀取變數,是不需要進行特別的注意的,而在當前的 Java 記憶體模型下,執行緒可以把變數保存本地記憶體(比如機器的暫存器)中,而不是直接在主存中進行讀寫,這就可能造成一個執行緒在主存中修改了一個變數的值,而另外一個執行緒還繼續使用它在暫存器中的變數值的拷貝,造成資料的不一致,
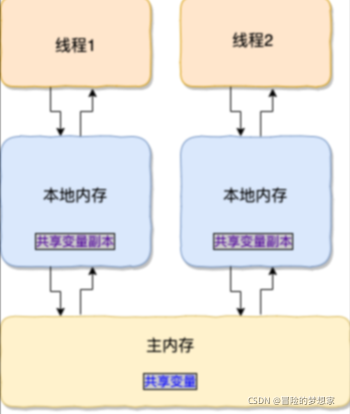
要解決這個問題,就需要把變數宣告為 **volatile** ,這就指示 JVM,這個變數是共享且不穩定的,每次使用它都到主存中進行讀取,
所以,**volatile**** 關鍵字 除了防止 JVM 的指令重排 ,還有一個重要的作用就是保證變數的可見性,**
并發編程的三個重要特性
- 原子性 : 一個的操作或者多次操作,要么所有的操作全部都得到執行并且不會收到任何因素的干擾而中斷,要么所有的操作都執行,要么都不執行,
synchronized可以保證代碼片段的原子性, - 可見性 :當一個執行緒對共享變數進行了修改,那么另外的執行緒都是立即可以看到修改后的最新值,
volatile關鍵字可以保證共享變數的可見性, - 有序性 :代碼在執行的程序中的先后順序,Java 在編譯器以及運行期間的優化,代碼的執行順序未必就是撰寫代碼時候的順序,
volatile關鍵字可以禁止指令進行重排序優化,
說說 synchronized 關鍵字和 volatile 關鍵字的區別
synchronized 關鍵字和 volatile 關鍵字是兩個互補的存在,而不是對立的存在!
**volatile**** 關鍵字是執行緒同步的輕量級實作**,所以**volatile**性能肯定比**synchronized**關鍵字要好 ,但是**volatile**** 關鍵字只能用于變數而**synchronized**關鍵字可以修飾方法以及代碼塊** ,**volatile**** 關鍵字能保證資料的可見性,但不能保證資料的原子性,**synchronized**關鍵字兩者都能保證,****volatile**關鍵字主要用于解決變數在多個執行緒之間的可見性,而**synchronized**關鍵字解決的是多個執行緒之間訪問資源的同步性,
ThreadLocal
ThreadLocal 簡介
通常情況下,我們創建的變數是可以被任何一個執行緒訪問并修改的,如果想實作每一個執行緒都有自己的專屬本地變數該如何解決呢? JDK 中提供的ThreadLocal類正是為了解決這樣的問題, **ThreadLocal**類主要解決的就是讓每個執行緒系結自己的值,可以將**ThreadLocal**類形象的比喻成存放資料的盒子,盒子中可以存盤每個執行緒的私有資料,
如果你創建了一個**ThreadLocal**變數,那么訪問這個變數的每個執行緒都會有這個變數的本地副本,這也是**ThreadLocal**變數名的由來,他們可以使用 **get()** 和 **set()** 方法來獲取默認值或將其值更改為當前執行緒所存的副本的值,從而避免了執行緒安全問題,
再舉個簡單的例子:
比如有兩個人去寶屋收集寶物,這兩個共用一個袋子的話肯定會產生爭執,但是給他們兩個人每個人分配一個袋子的話就不會出現這樣的問題,如果把這兩個人比作執行緒的話,那么 ThreadLocal 就是用來避免這兩個執行緒競爭的,
ThreadLocal 示例
相信看了上面的解釋,大家已經搞懂 ThreadLocal 類是個什么東西了,
import java.text.SimpleDateFormat;
import java.util.Random;
public class ThreadLocalExample implements Runnable{
// SimpleDateFormat 不是執行緒安全的,所以每個執行緒都要有自己獨立的副本
private static final ThreadLocal<SimpleDateFormat> formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample obj = new ThreadLocalExample();
for(int i=0 ; i<10; i++){
Thread t = new Thread(obj, ""+i);
Thread.sleep(new Random().nextInt(1000));
t.start();
}
}
@Override
public void run() {
System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
//formatter pattern is changed here by thread, but it won't reflect to other threads
formatter.set(new SimpleDateFormat());
System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
}
}
Output:
Thread Name= 0 default Formatter = yyyyMMdd HHmm
Thread Name= 0 formatter = yy-M-d ah:mm
Thread Name= 1 default Formatter = yyyyMMdd HHmm
Thread Name= 2 default Formatter = yyyyMMdd HHmm
Thread Name= 1 formatter = yy-M-d ah:mm
Thread Name= 3 default Formatter = yyyyMMdd HHmm
Thread Name= 2 formatter = yy-M-d ah:mm
Thread Name= 4 default Formatter = yyyyMMdd HHmm
Thread Name= 3 formatter = yy-M-d ah:mm
Thread Name= 4 formatter = yy-M-d ah:mm
Thread Name= 5 default Formatter = yyyyMMdd HHmm
Thread Name= 5 formatter = yy-M-d ah:mm
Thread Name= 6 default Formatter = yyyyMMdd HHmm
Thread Name= 6 formatter = yy-M-d ah:mm
Thread Name= 7 default Formatter = yyyyMMdd HHmm
Thread Name= 7 formatter = yy-M-d ah:mm
Thread Name= 8 default Formatter = yyyyMMdd HHmm
Thread Name= 9 default Formatter = yyyyMMdd HHmm
Thread Name= 8 formatter = yy-M-d ah:mm
Thread Name= 9 formatter = yy-M-d ah:mm
從輸出中可以看出,Thread-0 已經改變了 formatter 的值,但仍然是 thread-2 默認格式化程式與初始化值相同,其他執行緒也一樣,
上面有一段代碼用到了創建 ThreadLocal 變數的那段代碼用到了 Java8 的知識,它等于下面這段代碼,如果你寫了下面這段代碼的話,IDEA 會提示你轉換為 Java8 的格式(IDEA 真的不錯!),因為 ThreadLocal 類在 Java 8 中擴展,使用一個新的方法withInitial(),將 Supplier 功能介面作為引數,
private static final ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){
@Override
protected SimpleDateFormat initialValue(){
return new SimpleDateFormat("yyyyMMdd HHmm");
}
};
ThreadLocal 原理
從 Thread類源代碼入手,
public class Thread implements Runnable {
//......
//與此執行緒有關的ThreadLocal值,由ThreadLocal類維護
ThreadLocal.ThreadLocalMap threadLocals = null;
//與此執行緒有關的InheritableThreadLocal值,由InheritableThreadLocal類維護
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
//......
}
從上面Thread類 源代碼可以看出Thread 類中有一個 threadLocals 和 一個 inheritableThreadLocals 變數,它們都是 ThreadLocalMap 型別的變數,我們可以把 ThreadLocalMap 理解為ThreadLocal 類實作的定制化的 HashMap,默認情況下這兩個變數都是 null,只有當前執行緒呼叫 ThreadLocal 類的 set或get方法時才創建它們,實際上呼叫這兩個方法的時候,我們呼叫的是ThreadLocalMap類對應的 get()、set()方法,
ThreadLocal類的set()方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
通過上面這些內容,我們足以通過猜測得出結論:最終的變數是放在了當前執行緒的 **ThreadLocalMap** 中,并不是存在 **ThreadLocal** 上,**ThreadLocal**** 可以理解為只是****ThreadLocalMap**的封裝,傳遞了變數值, ThrealLocal 類中可以通過Thread.currentThread()獲取到當前執行緒物件后,直接通過getMap(Thread t)可以訪問到該執行緒的ThreadLocalMap物件,
每個**Thread**中都具備一個**ThreadLocalMap**,而**ThreadLocalMap**可以存盤以**ThreadLocal**為 key ,Object 物件為 value 的鍵值對,
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//......
}
比如我們在同一個執行緒中宣告了兩個 ThreadLocal 物件的話,會使用 Thread內部都是使用僅有那個ThreadLocalMap 存放資料的,ThreadLocalMap的 key 就是 ThreadLocal物件,value 就是 ThreadLocal 物件呼叫set方法設定的值,
ThreadLocalMap是ThreadLocal的靜態內部類,
ThreadLocal 記憶體泄露問題
ThreadLocalMap 中使用的 key 為 ThreadLocal 的弱參考,而 value 是強參考,所以,如果 ThreadLocal 沒有被外部強參考的情況下,在垃圾回收的時候,key 會被清理掉,而 value 不會被清理掉,這樣一來,ThreadLocalMap 中就會出現 key 為 null 的 Entry,假如我們不做任何措施的話,value 永遠無法被 GC 回收,這個時候就可能會產生記憶體泄露,ThreadLocalMap 實作中已經考慮了這種情況,在呼叫 set()、get()、remove() 方法的時候,會清理掉 key 為 null 的記錄,使用完 ThreadLocal方法后 最好手動呼叫remove()方法
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
弱參考介紹:
如果一個物件只具有弱參考,那就類似于可有可無的生活用品,弱參考與軟參考的區別在于:只具有弱參考的物件擁有更短暫的生命周期,在垃圾回收器執行緒掃描它 所管轄的記憶體區域的程序中,一旦發現了只具有弱參考的物件,不管當前記憶體空間足夠與否,都會回收它的記憶體,不過,由于垃圾回收器是一個優先級很低的執行緒, 因此不一定會很快發現那些只具有弱參考的物件,
弱參考可以和一個參考佇列(ReferenceQueue)聯合使用,如果弱參考所參考的物件被垃圾回收,Java 虛擬機就會把這個弱參考加入到與之關聯的參考佇列中,
?
執行緒池
為什么要用執行緒池?
池化技術想必大家已經屢見不鮮了,執行緒池、資料庫連接池、Http 連接池等等都是對這個思想的應用,池化技術的思想主要是為了減少每次獲取資源的消耗,提高對資源的利用率,
執行緒池提供了一種限制和管理資源(包括執行一個任務), 每個執行緒池還維護一些基本統計資訊,例如已完成任務的數量,
這里借用《Java 并發編程的藝術》提到的來說一下使用執行緒池的好處:
- 降低資源消耗,通過重復利用已創建的執行緒降低執行緒創建和銷毀造成的消耗,
- 提高回應速度,當任務到達時,任務可以不需要等到執行緒創建就能立即執行,
- 提高執行緒的可管理性,執行緒是稀缺資源,如果無限制的創建,不僅會消耗系統資源,還會降低系統的穩定性,使用執行緒池可以進行統一的分配,調優和監控,
實作 Runnable 介面和 Callable 介面的區別
Runnable自 Java 1.0 以來一直存在,但Callable僅在 Java 1.5 中引入,目的就是為了來處理Runnable不支持的用例,**Runnable**** 介面** 不會回傳結果或拋出檢查例外,但是 **Callable**** 介面** 可以,所以,如果任務不需要回傳結果或拋出例外推薦使用 **Runnable**** 介面** ,這樣代碼看起來會更加簡潔,
工具類 Executors 可以實作將 Runnable 物件轉換成 Callable 物件,(Executors.callable(Runnable task) 或 Executors.callable(Runnable task, Object result)),
Runnable.java
@FunctionalInterface
public interface Runnable {
/**
* 被執行緒執行,沒有回傳值也無法拋出例外
*/
public abstract void run();
}
Callable.java
@FunctionalInterface
public interface Callable<V> {
/**
* 計算結果,或在無法這樣做時拋出例外,
* @return 計算得出的結果
* @throws 如果無法計算結果,則拋出例外
*/
V call() throws Exception;
}
執行 execute()方法和 submit()方法的區別是什么呢?
**execute()**方法用于提交不需要回傳值的任務,所以無法判斷任務是否被執行緒池執行成功與否;**submit()**方法用于提交需要回傳值的任務,執行緒池會回傳一個**Future**型別的物件,通過這個**Future**物件可以判斷任務是否執行成功,并且可以通過Future的get()方法來獲取回傳值,get()方法會阻塞當前執行緒直到任務完成,而使用get(long timeout,TimeUnit unit)方法則會阻塞當前執行緒一段時間后立即回傳,這時候有可能任務沒有執行完,
我們以 **AbstractExecutorService**** 介面** 中的一個 submit 方法為例子來看看源代碼:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
上面方法呼叫的 newTaskFor 方法回傳了一個 FutureTask 物件,
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
我們再來看看execute()方法:
public void execute(Runnable command) {
...
}
如何創建執行緒池
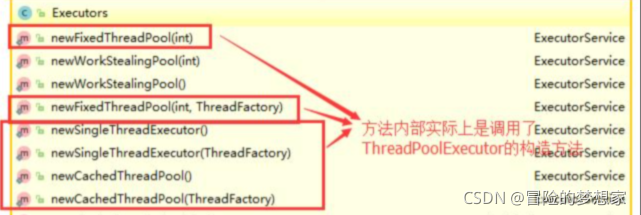
《阿里巴巴 Java 開發手冊》中強制執行緒池不允許使用 Executors 去創建,而是通過 ThreadPoolExecutor 的方式,這樣的處理方式讓寫的同學更加明確執行緒池的運行規則,規避資源耗盡的風險
Executors 回傳執行緒池物件的弊端如下:
- FixedThreadPool 和 SingleThreadExecutor : 允許請求的佇列長度為 Integer.MAX_VALUE ,可能堆積大量的請求,從而導致 OOM,
- CachedThreadPool 和 ScheduledThreadPool : 允許創建的執行緒數量為 Integer.MAX_VALUE ,可能會創建大量執行緒,從而導致 OOM,
方式一:通過構造方法實作

方式二:通過 Executor 框架的工具類 Executors 來實作
我們可以創建三種型別的 ThreadPoolExecutor:
- FixedThreadPool : 該方法回傳一個固定執行緒數量的執行緒池,該執行緒池中的執行緒數量始終不變,當有一個新的任務提交時,執行緒池中若有空閑執行緒,則立即執行,若沒有,則新的任務會被暫存在一個任務佇列中,待有執行緒空閑時,便處理在任務佇列中的任務,
- SingleThreadExecutor: 方法回傳一個只有一個執行緒的執行緒池,若多余一個任務被提交到該執行緒池,任務會被保存在一個任務佇列中,待執行緒空閑,按先入先出的順序執行佇列中的任務,
- CachedThreadPool: 該方法回傳一個可根據實際情況調整執行緒數量的執行緒池,執行緒池的執行緒數量不確定,但若有空閑執行緒可以復用,則會優先使用可復用的執行緒,若所有執行緒均在作業,又有新的任務提交,則會創建新的執行緒處理任務,所有執行緒在當前任務執行完畢后,將回傳執行緒池進行復用,
對應 Executors 工具類中的方法如圖所示:
ThreadPoolExecutor 類分析
ThreadPoolExecutor 類中提供的四個構造方法,我們來看最長的那個,其余三個都是在這個構造方法的基礎上產生(其他幾個構造方法說白點都是給定某些默認引數的構造方法比如默認制定拒絕策略是什么),這里就不貼代碼講了,比較簡單,
/**
* 用給定的初始引數創建一個新的ThreadPoolExecutor,
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
下面這些對創建 非常重要,在后面使用執行緒池的程序中你一定會用到!所以,務必拿著小本本記清楚,
?ThreadPoolExecutor建構式重要引數分析
**ThreadPoolExecutor**** 3 個最重要的引數:**
**corePoolSize**** 😗* 核心執行緒數定義了最小可以同時運行的執行緒數量,**maximumPoolSize**** 😗* 當佇列中存放的任務達到佇列容量的時候,當前可以同時運行的執行緒數量變為最大執行緒數,**workQueue**: 當新任務來的時候會先判斷當前運行的執行緒數量是否達到核心執行緒數,如果達到的話,新任務就會被存放在佇列中,
ThreadPoolExecutor其他常見引數:
**keepAliveTime**:當執行緒池中的執行緒數量大于corePoolSize的時候,如果這時沒有新的任務提交,核心執行緒外的執行緒不會立即銷毀,而是會等待,直到等待的時間超過了keepAliveTime才會被回收銷毀;**unit**:keepAliveTime引數的時間單位,**threadFactory**:executor 創建新執行緒的時候會用到,**handler**:飽和策略,關于飽和策略下面單獨介紹一下,
?ThreadPoolExecutor 飽和策略
**ThreadPoolExecutor**** 飽和策略定義:**
如果當前同時運行的執行緒數量達到最大執行緒數量并且佇列也已經被放滿了任務時,ThreadPoolTaskExecutor 定義一些策略:
**ThreadPoolExecutor.AbortPolicy**: 拋出RejectedExecutionException來拒絕新任務的處理,**ThreadPoolExecutor.CallerRunsPolicy**: 呼叫執行自己的執行緒運行任務,也就是直接在呼叫execute方法的執行緒中運行(run)被拒絕的任務,如果執行程式已關閉,則會丟棄該任務,因此這種策略會降低對于新任務提交速度,影響程式的整體性能,如果您的應用程式可以承受此延遲并且你要求任何一個任務請求都要被執行的話,你可以選擇這個策略,**ThreadPoolExecutor.DiscardPolicy**: 不處理新任務,直接丟棄掉,**ThreadPoolExecutor.DiscardOldestPolicy**: 此策略將丟棄最早的未處理的任務請求,
舉個例子: Spring 通過 ThreadPoolTaskExecutor 或者我們直接通過 ThreadPoolExecutor 的建構式創建執行緒池的時候,當我們不指定 RejectedExecutionHandler 飽和策略的話來配置執行緒池的時候默認使用的是 ThreadPoolExecutor.AbortPolicy,在默認情況下,ThreadPoolExecutor 將拋出 RejectedExecutionException 來拒絕新來的任務 ,這代表你將丟失對這個任務的處理, 對于可伸縮的應用程式,建議使用 ThreadPoolExecutor.CallerRunsPolicy,當最大池被填滿時,此策略為我們提供可伸縮佇列,(這個直接查看 ThreadPoolExecutor 的建構式原始碼就可以看出,比較簡單的原因,這里就不貼代碼了)
一個簡單的執行緒池 Demo
為了讓大家更清楚上面的面試題中的一些概念,我寫了一個簡單的執行緒池 Demo,
首先創建一個 Runnable 介面的實作類(當然也可以是 Callable 介面,我們上面也說了兩者的區別,)
MyRunnable.java
import java.util.Date;
/**
* 這是一個簡單的Runnable類,需要大約5秒鐘來執行其任務,
* @author shuang.kou
*/
public class MyRunnable implements Runnable {
private String command;
public MyRunnable(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
processCommand();
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return this.command;
}
}
撰寫測驗程式,我們這里以阿里巴巴推薦的使用 ThreadPoolExecutor 建構式自定義引數的方式來創建執行緒池,
ThreadPoolExecutorDemo.java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推薦的創建執行緒池的方式
//通過ThreadPoolExecutor建構式自定義引數創建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//創建WorkerThread物件(WorkerThread類實作了Runnable 介面)
Runnable worker = new MyRunnable("" + i);
//執行Runnable
executor.execute(worker);
}
//終止執行緒池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
可以看到我們上面的代碼指定了:
corePoolSize: 核心執行緒數為 5,maximumPoolSize:最大執行緒數 10keepAliveTime: 等待時間為 1L,unit: 等待時間的單位為 TimeUnit.SECONDS,workQueue:任務佇列為ArrayBlockingQueue,并且容量為 100;handler:飽和策略為CallerRunsPolicy,
Output:
pool-1-thread-3 Start. Time = Sun Apr 12 11:14:37 CST 2020
pool-1-thread-5 Start. Time = Sun Apr 12 11:14:37 CST 2020
pool-1-thread-2 Start. Time = Sun Apr 12 11:14:37 CST 2020
pool-1-thread-1 Start. Time = Sun Apr 12 11:14:37 CST 2020
pool-1-thread-4 Start. Time = Sun Apr 12 11:14:37 CST 2020
pool-1-thread-3 End. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-4 End. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-1 End. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-5 End. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-1 Start. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-2 End. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-5 Start. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-4 Start. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-3 Start. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-2 Start. Time = Sun Apr 12 11:14:42 CST 2020
pool-1-thread-1 End. Time = Sun Apr 12 11:14:47 CST 2020
pool-1-thread-4 End. Time = Sun Apr 12 11:14:47 CST 2020
pool-1-thread-5 End. Time = Sun Apr 12 11:14:47 CST 2020
pool-1-thread-3 End. Time = Sun Apr 12 11:14:47 CST 2020
pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
執行緒池原理分析
承接 4.6 節,我們通過代碼輸出結果可以看出:執行緒池首先會先執行 5 個任務,然后這些任務有任務被執行完的話,就會去拿新的任務執行, 大家可以先通過上面講解的內容,分析一下到底是咋回事?(自己獨立思考一會)
現在,我們就分析上面的輸出內容來簡單分析一下執行緒池原理,
**為了搞懂執行緒池的原理,我們需要首先分析一下 ****execute**方法, 在 4.6 節中的 Demo 中我們使用 executor.execute(worker)來提交一個任務到執行緒池中去,這個方法非常重要,下面我們來看看它的原始碼:
// 存放執行緒池的運行狀態 (runState) 和執行緒池內有效執行緒的數量 (workerCount)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static int workerCountOf(int c) {
return c & CAPACITY;
}
private final BlockingQueue<Runnable> workQueue;
public void execute(Runnable command) {
// 如果任務為null,則拋出例外,
if (command == null)
throw new NullPointerException();
// ctl 中保存的執行緒池當前的一些狀態資訊
int c = ctl.get();
// 下面會涉及到 3 步 操作
// 1.首先判斷當前執行緒池中執行的任務數量是否小于 corePoolSize
// 如果小于的話,通過addWorker(command, true)新建一個執行緒,并將任務(command)添加到該執行緒中;然后,啟動該執行緒從而執行任務,
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2.如果當前執行的任務數量大于等于 corePoolSize 的時候就會走到這里
// 通過 isRunning 方法判斷執行緒池狀態,執行緒池處于 RUNNING 狀態才會被并且佇列可以加入任務,該任務才會被加入進去
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次獲取執行緒池狀態,如果執行緒池狀態不是 RUNNING 狀態就需要從任務佇列中移除任務,并嘗試判斷執行緒是否全部執行完畢,同時執行拒絕策略,
if (!isRunning(recheck) && remove(command))
reject(command);
// 如果當前執行緒池為空就新創建一個執行緒并執行,
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//3. 通過addWorker(command, false)新建一個執行緒,并將任務(command)添加到該執行緒中;然后,啟動該執行緒從而執行任務,
//如果addWorker(command, false)執行失敗,則通過reject()執行相應的拒絕策略的內容,
else if (!addWorker(command, false))
reject(command);
}
通過下圖可以更好的對上面這 3 步做一個展示,下圖是我為了省事直接從網上找到,原地址不明,
現在,讓我們在回到 4.6 節我們寫的 Demo, 現在是不是很容易就可以搞懂它的原理了呢?
沒搞懂的話,也沒關系,可以看看我的分析:
我們在代碼中模擬了 10 個任務,我們配置的核心執行緒數為 5 、等待佇列容量為 100 ,所以每次只可能存在 5 個任務同時執行,剩下的 5 個任務會被放到等待佇列中去,當前的5個任務中如果有任務被執行完了,執行緒池就會去拿新的任務執行,
AQS
AQS 介紹
AQS 的全稱為(AbstractQueuedSynchronizer),這個類在java.util.concurrent.locks包下面,
AQS 是一個用來構建鎖和同步器的框架,使用 AQS 能簡單且高效地構造出大量應用廣泛的同步器,比如我們提到的 ReentrantLock,Semaphore,其他的諸如 ReentrantReadWriteLock,SynchronousQueue,FutureTask 等等皆是基于 AQS 的,當然,我們自己也能利用 AQS 非常輕松容易地構造出符合我們自己需求的同步器,
6.2. AQS 原理分析
AQS 原理這部分參考了部分博客,在 5.2 節末尾放了鏈接,
在面試中被問到并發知識的時候,大多都會被問到“請你說一下自己對于 AQS 原理的理解”,下面給大家一個示例供大家參加,面試不是背題,大家一定要加入自己的思想,即使加入不了自己的思想也要保證自己能夠通俗的講出來而不是背出來,
下面大部分內容其實在 AQS 類注釋上已經給出了,不過是英語看著比較吃力一點,感興趣的話可以看看原始碼,
6.2.1. AQS 原理概覽
AQS 核心思想是,如果被請求的共享資源空閑,則將當前請求資源的執行緒設定為有效的作業執行緒,并且將共享資源設定為鎖定狀態,如果被請求的共享資源被占用,那么就需要一套執行緒阻塞等待以及被喚醒時鎖分配的機制,這個機制 AQS 是用 CLH 佇列鎖實作的,即將暫時獲取不到鎖的執行緒加入到佇列中,
CLH(Craig,Landin and Hagersten)佇列是一個虛擬的雙向佇列(虛擬的雙向佇列即不存在佇列實體,僅存在結點之間的關聯關系),AQS 是將每條請求共享資源的執行緒封裝成一個 CLH 鎖佇列的一個結點(Node)來實作鎖的分配,
看個 AQS(AbstractQueuedSynchronizer)原理圖:
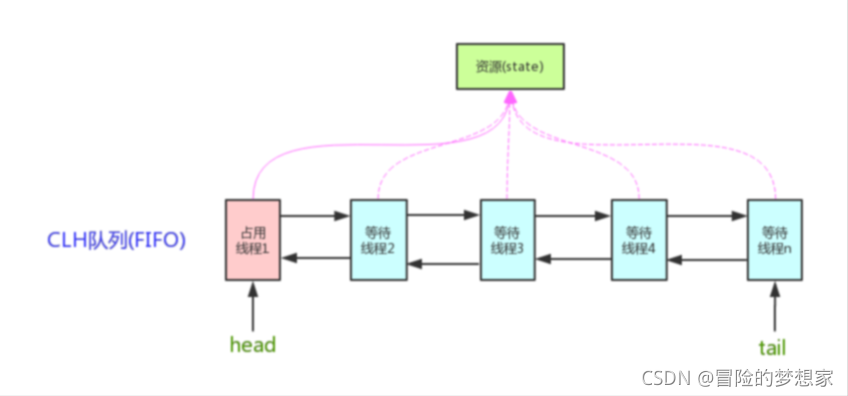
AQS 使用一個 int 成員變數來表示同步狀態,通過內置的 FIFO 佇列來完成獲取資源執行緒的排隊作業,AQS 使用 CAS 對該同步狀態進行原子操作實作對其值的修改,
private volatile int state;//共享變數,使用volatile修飾保證執行緒可見性
狀態資訊通過 protected 型別的 getState,setState,compareAndSetState 進行操作
//回傳同步狀態的當前值
protected final int getState() {
return state;
}
//設定同步狀態的值
protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)將同步狀態值設定為給定值update如果當前同步狀態的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
6.2.2. AQS 對資源的共享方式
AQS 定義兩種資源共享方式
- Exclusive(獨占):只有一個執行緒能執行,如
ReentrantLock,又可分為公平鎖和非公平鎖:- 公平鎖:按照執行緒在佇列中的排隊順序,先到者先拿到鎖
- 非公平鎖:當執行緒要獲取鎖時,無視佇列順序直接去搶鎖,誰搶到就是誰的
- Share(共享):多個執行緒可同時執行,如
CountDownLatch、Semaphore、CyclicBarrier、ReadWriteLock我們都會在后面講到,
ReentrantReadWriteLock 可以看成是組合式,因為 ReentrantReadWriteLock 也就是讀寫鎖允許多個執行緒同時對某一資源進行讀,
不同的自定義同步器爭用共享資源的方式也不同,自定義同步器在實作時只需要實作共享資源 state 的獲取與釋放方式即可,至于具體執行緒等待佇列的維護(如獲取資源失敗入隊/喚醒出隊等),AQS 已經在頂層實作好了,
6.2.3. AQS 底層使用了模板方法模式
同步器的設計是基于模板方法模式的,如果需要自定義同步器一般的方式是這樣(模板方法模式很經典的一個應用):
- 使用者繼承
AbstractQueuedSynchronizer并重寫指定的方法,(這些重寫方法很簡單,無非是對于共享資源 state 的獲取和釋放) - 將 AQS 組合在自定義同步組件的實作中,并呼叫其模板方法,而這些模板方法會呼叫使用者重寫的方法,
這和我們以往通過實作介面的方式有很大區別,這是模板方法模式很經典的一個運用,
AQS 使用了模板方法模式,自定義同步器時需要重寫下面幾個 AQS 提供的模板方法:
isHeldExclusively()//該執行緒是否正在獨占資源,只有用到condition才需要去實作它,
tryAcquire(int)//獨占方式,嘗試獲取資源,成功則回傳true,失敗則回傳false,
tryRelease(int)//獨占方式,嘗試釋放資源,成功則回傳true,失敗則回傳false,
tryAcquireShared(int)//共享方式,嘗試獲取資源,負數表示失敗;0表示成功,但沒有剩余可用資源;正數表示成功,且有剩余資源,
tryReleaseShared(int)//共享方式,嘗試釋放資源,成功則回傳true,失敗則回傳false,
默認情況下,每個方法都拋出 UnsupportedOperationException, 這些方法的實作必須是內部執行緒安全的,并且通常應該簡短而不是阻塞,AQS 類中的其他方法都是 final ,所以無法被其他類使用,只有這幾個方法可以被其他類使用,
以 ReentrantLock 為例,state 初始化為 0,表示未鎖定狀態,A 執行緒 lock()時,會呼叫 tryAcquire()獨占該鎖并將 state+1,此后,其他執行緒再 tryAcquire()時就會失敗,直到 A 執行緒 unlock()到 state=0(即釋放鎖)為止,其它執行緒才有機會獲取該鎖,當然,釋放鎖之前,A 執行緒自己是可以重復獲取此鎖的(state 會累加),這就是可重入的概念,但要注意,獲取多少次就要釋放多少次,這樣才能保證 state 是能回到零態的,
再以 CountDownLatch 以例,任務分為 N 個子執行緒去執行,state 也初始化為 N(注意 N 要與執行緒個數一致),這 N 個子執行緒是并行執行的,每個子執行緒執行完后countDown() 一次,state 會 CAS(Compare and Swap)減 1,等到所有子執行緒都執行完后(即 state=0),會 unpark()主呼叫執行緒,然后主呼叫執行緒就會從 await() 函式回傳,繼續后余動作,
一般來說,自定義同步器要么是獨占方法,要么是共享方式,他們也只需實作tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一種即可,但 AQS 也支持自定義同步器同時實作獨占和共享兩種方式,如ReentrantReadWriteLock,
推薦兩篇 AQS 原理和相關原始碼分析的文章:
- https://www.cnblogs.com/waterystone/p/4920797.html
- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
6.3. AQS 組件總結
**Semaphore**(信號量)-允許多個執行緒同時訪問:synchronized和ReentrantLock都是一次只允許一個執行緒訪問某個資源,Semaphore(信號量)可以指定多個執行緒同時訪問某個資源,**CountDownLatch**(倒計時器):CountDownLatch是一個同步工具類,用來協調多個執行緒之間的同步,這個工具通常用來控制執行緒等待,它可以讓某一個執行緒等待直到倒計時結束,再開始執行,**CyclicBarrier**(回圈柵欄):CyclicBarrier和CountDownLatch非常類似,它也可以實作執行緒間的技術等待,但是它的功能比CountDownLatch更加復雜和強大,主要應用場景和CountDownLatch類似,CyclicBarrier的字面意思是可回圈使用(Cyclic)的屏障(Barrier),它要做的事情是,讓一組執行緒到達一個屏障(也可以叫同步點)時被阻塞,直到最后一個執行緒到達屏障時,屏障才會開門,所有被屏障攔截的執行緒才會繼續干活,CyclicBarrier默認的構造方法是CyclicBarrier(int parties),其引數表示屏障攔截的執行緒數量,每個執行緒呼叫await()方法告訴CyclicBarrier我已經到達了屏障,然后當前執行緒被阻塞,
6.4. 用過 CountDownLatch 么?什么場景下用的?
CountDownLatch 的作用就是 允許 count 個執行緒阻塞在一個地方,直至所有執行緒的任務都執行完畢,之前在專案中,有一個使用多執行緒讀取多個檔案處理的場景,我用到了 CountDownLatch ,具體場景是下面這樣的:
我們要讀取處理 6 個檔案,這 6 個任務都是沒有執行順序依賴的任務,但是我們需要回傳給用戶的時候將這幾個檔案的處理的結果進行統計整理,
為此我們定義了一個執行緒池和 count 為 6 的CountDownLatch物件 ,使用執行緒池處理讀取任務,每一個執行緒處理完之后就將 count-1,呼叫CountDownLatch物件的 await()方法,直到所有檔案讀取完之后,才會接著執行后面的邏輯,
偽代碼是下面這樣的:
public class CountDownLatchExample1 {
// 處理檔案的數量
private static final int threadCount = 6;
public static void main(String[] args) throws InterruptedException {
// 創建一個具有固定執行緒數量的執行緒池物件(推薦使用構造方法創建)
ExecutorService threadPool = Executors.newFixedThreadPool(10);
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
final int threadnum = i;
threadPool.execute(() -> {
try {
//處理檔案的業務操作
//......
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//表示一個檔案已經被完成
countDownLatch.countDown();
}
});
}
countDownLatch.await();
threadPool.shutdown();
System.out.println("finish");
}
}
有沒有可以改進的地方呢?
可以使用 CompletableFuture 類來改進!Java8 的 CompletableFuture 提供了很多對多執行緒友好的方法,使用它可以很方便地為我們撰寫多執行緒程式,什么異步、串行、并行或者等待所有執行緒執行完任務什么的都非常方便,
CompletableFuture<Void> task1 =
CompletableFuture.supplyAsync(()->{
//自定義業務操作
});
......
CompletableFuture<Void> task6 =
CompletableFuture.supplyAsync(()->{
//自定義業務操作
});
......
CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
try {
headerFuture.join();
} catch (Exception ex) {
//......
}
System.out.println("all done. ");
上面的代碼還可以接續優化,當任務過多的時候,把每一個 task 都列出來不太現實,可以考慮通過回圈來添加任務,
//檔案夾位置
List<String> filePaths = Arrays.asList(...)
// 異步處理所有檔案
List<CompletableFuture<String>> fileFutures = filePaths.stream()
.map(filePath -> doSomeThing(filePath))
.collect(Collectors.toList());
// 將他們合并起來
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
fileFutures.toArray(new CompletableFuture[fileFutures.size()])
);
4、Spring
什么是 Spring 框架?
Spring 是一款開源的輕量級 Java 開發框架,旨在提高開發人員的開發效率以及系統的可維護性,
Spring 翻譯過來就是春天的意思,可見其目標和使命就是為 Java 程式員帶來春天啊!感動!
題外話 : 語言的流行通常需要一個殺手級的應用,Spring 就是 Java 生態的一個殺手級的應用框架,
我們一般說 Spring 框架指的都是 Spring Framework,它是很多模塊的集合,使用這些模塊可以很方便地協助我們進行開發,
比如說 Spring 自帶 IoC(Inverse of Control:控制反轉) 和 AOP(Aspect-Oriented Programming:面向切面編程)、可以很方便地對資料庫進行訪問、可以很方便地集成第三方組件(電子郵件,任務,調度,快取等等)、對單元測驗支持比較好、支持 RESTful Java 應用程式的開發,
Spring 最核心的思想就是不重新造輪子,開箱即用!
Spring 提供的核心功能主要是 IoC 和 AOP,學習 Spring ,一定要把 IoC 和 AOP 的核心思想搞懂!
- Spring 官網:https://spring.io/
- Github 地址: https://github.com/spring-projects/spring-framework
列舉一些重要的 Spring 模塊?
下圖對應的是 Spring4.x 版本,目前最新的 5.x 版本中 Web 模塊的 Portlet 組件已經被廢棄掉,同時增加了用于異步回應式處理的 WebFlux 組件,
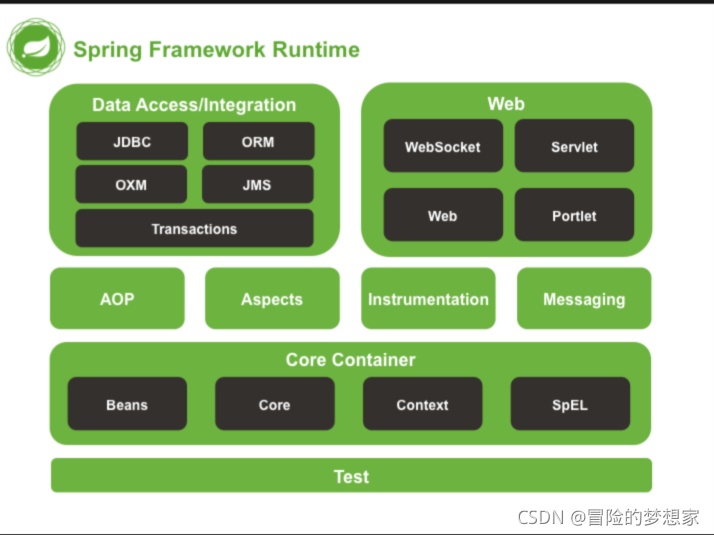
Spring Core
核心模塊, Spring 其他所有的功能基本都需要依賴于該類別庫,主要提供 IoC 依賴注入功能的支持,
Spring Aspects
該模塊為與 AspectJ 的集成提供支持,
Spring AOP
提供了面向切面的編程實作,
Spring Data Access/Integration :
Spring Data Access/Integration 由 5 個模塊組成:
- spring-jdbc : 提供了對資料庫訪問的抽象 JDBC,不同的資料庫都有自己獨立的 API 用于操作資料庫,而 Java 程式只需要和 JDBC API 互動,這樣就屏蔽了資料庫的影響,
- spring-tx : 提供對事務的支持,
- spring-orm : 提供對 Hibernate 等 ORM 框架的支持,
- spring-oxm : 提供對 Castor 等 OXM 框架的支持,
- spring-jms : Java 訊息服務,
Spring Web
Spring Web 由 4 個模塊組成:
- spring-web :對 Web 功能的實作提供一些最基礎的支持,
- spring-webmvc : 提供對 Spring MVC 的實作,
- spring-websocket : 提供了對 WebSocket 的支持,WebSocket 可以讓客戶端和服務端進行雙向通信,
- spring-webflux :提供對 WebFlux 的支持,WebFlux 是 Spring Framework 5.0 中引入的新的回應式框架,與 Spring MVC 不同,它不需要 Servlet API,是完全異步.
Spring Test
Spring 團隊提倡測驗驅動開發(TDD),有了控制反轉 (IoC)的幫助,單元測驗和集成測驗變得更簡單,
Spring 的測驗模塊對 JUnit(單元測驗框架)、TestNG(類似 JUnit)、Mockito(主要用來 Mock 物件)、PowerMock(解決 Mockito 的問題比如無法模擬 final, static, private 方法)等等常用的測驗框架支持的都比較好,
Spring IOC & AOP
談談自己對于 Spring IoC 的了解
IoC(Inverse of Control:控制反轉) 是一種設計思想,而不是一個具體的技術實作,IoC 的思想就是將原本在程式中手動創建物件的控制權,交由 Spring 框架來管理,不過, IoC 并非 Spirng 特有,在其他語言中也有應用,
為什么叫控制反轉?
- 控制 :指的是物件創建(實體化、管理)的權力
- 反轉 :控制權交給外部環境(Spring 框架、IoC 容器)
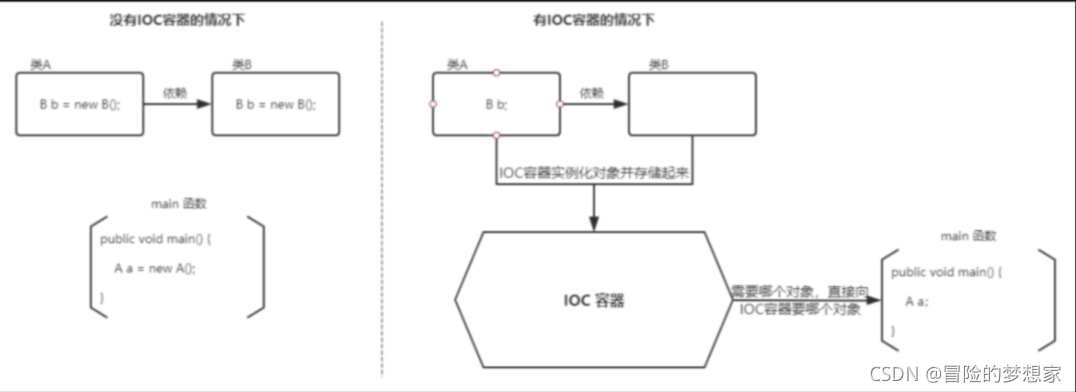
將物件之間的相互依賴關系交給 IoC 容器來管理,并由 IoC 容器完成物件的注入,這樣可以很大程度上簡化應用的開發,把應用從復雜的依賴關系中解放出來, IoC 容器就像是一個工廠一樣,當我們需要創建一個物件的時候,只需要配置好組態檔/注解即可,完全不用考慮物件是如何被創建出來的,
在實際專案中一個 Service 類可能依賴了很多其他的類,假如我們需要實體化這個 Service,你可能要每次都要搞清這個 Service 所有底層類的建構式,這可能會把人逼瘋,如果利用 IoC 的話,你只需要配置好,然后在需要的地方參考就行了,這大大增加了專案的可維護性且降低了開發難度,
在 Spring 中, IoC 容器是 Spring 用來實作 IoC 的載體, IoC 容器實際上就是個 Map(key,value),Map 中存放的是各種物件,
Spring 時代我們一般通過 XML 檔案來配置 Bean,后來開發人員覺得 XML 檔案來配置不太好,于是 SpringBoot 注解配置就慢慢開始流行起來,
相關閱讀:
- IoC 原始碼閱讀
- 面試被問了幾百遍的 IoC 和 AOP ,還在傻傻搞不清楚?
談談自己對于 AOP 的了解
AOP(Aspect-Oriented Programming:面向切面編程)能夠將那些與業務無關,卻為業務模塊所共同呼叫的邏輯或責任(例如事務處理、日志管理、權限控制等)封裝起來,便于減少系統的重復代碼,降低模塊間的耦合度,并有利于未來的可拓展性和可維護性,
Spring AOP 就是基于動態代理的,如果要代理的物件,實作了某個介面,那么 Spring AOP 會使用 JDK Proxy,去創建代理物件,而對于沒有實作介面的物件,就無法使用 JDK Proxy 去進行代理了,這時候 Spring AOP 會使用 Cglib 生成一個被代理物件的子類來作為代理,如下圖所示:
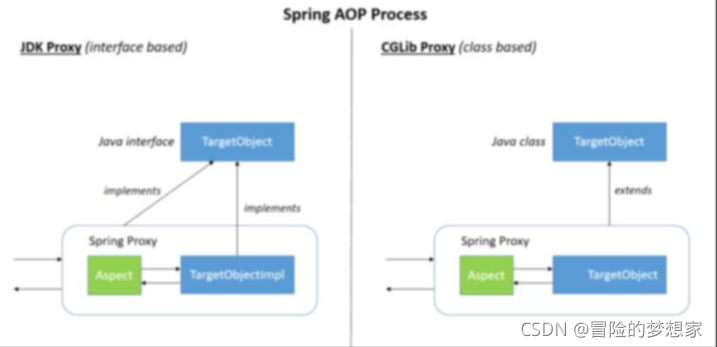
當然你也可以使用 AspectJ !Spring AOP 已經集成了 AspectJ ,AspectJ 應該算的上是 Java 生態系統中最完整的 AOP 框架了,
Spring AOP 和 AspectJ AOP 有什么區別?
Spring AOP 屬于運行時增強,而 AspectJ 是編譯時增強, Spring AOP 基于代理(Proxying),而 AspectJ 基于位元組碼操作(Bytecode Manipulation),
Spring AOP 已經集成了 AspectJ ,AspectJ 應該算的上是 Java 生態系統中最完整的 AOP 框架了,AspectJ 相比于 Spring AOP 功能更加強大,但是 Spring AOP 相對來說更簡單,
如果我們的切面比較少,那么兩者性能差異不大,但是,當切面太多的話,最好選擇 AspectJ ,它比 Spring AOP 快很多,
?
Spring bean
什么是 bean?
簡單來說,bean 代指的就是那些被 IoC 容器所管理的物件,
我們需要告訴 IoC 容器幫助我們管理哪些物件,這個是通過配置元資料來定義的,配置元資料可以是 XML 檔案、注解或者 Java 配置類,
<!-- Constructor-arg with 'value' attribute -->
<bean id="..." class="...">
<constructor-arg value="..."/>
</bean>
下圖簡單地展示了 IoC 容器如何使用配置元資料來管理物件,
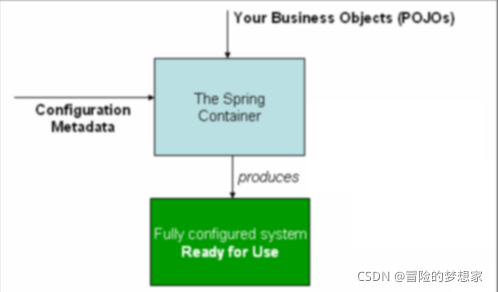
org.springframework.beans和 org.springframework.context 這兩個包是 IoC 實作的基礎,如果想要研究 IoC 相關的原始碼的話,可以去看看
bean 的作用域有哪些?
Spring 中 Bean 的作用域通常有下面幾種:
- singleton : 唯一 bean 實體,Spring 中的 bean 默認都是單例的,對單例設計模式的應用,
- prototype : 每次請求都會創建一個新的 bean 實體,
- request : 每一次 HTTP 請求都會產生一個新的 bean,該 bean 僅在當前 HTTP request 內有效,
- session : 每一次來自新 session 的 HTTP 請求都會產生一個新的 bean,該 bean 僅在當前 HTTP session 內有效,
- global-session : 全域 session 作用域,僅僅在基于 portlet 的 web 應用中才有意義,Spring5 已經沒有了,Portlet 是能夠生成語意代碼(例如:HTML)片段的小型 Java Web 插件,它們基于 portlet 容器,可以像 servlet 一樣處理 HTTP 請求,但是,與 servlet 不同,每個 portlet 都有不同的會話,
如何配置 bean 的作用域呢?
xml 方式:
<bean id="..." class="..." scope="singleton"></bean>
注解方式:
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
單例 bean 的執行緒安全問題了解嗎?
大部分時候我們并沒有在專案中使用多執行緒,所以很少有人會關注這個問題,單例 bean 存在執行緒問題,主要是因為當多個執行緒操作同一個物件的時候是存在資源競爭的,
常見的有兩種解決辦法:
- 在 bean 中盡量避免定義可變的成員變數,
- 在類中定義一個
ThreadLocal成員變數,將需要的可變成員變數保存在ThreadLocal中(推薦的一種方式),
不過,大部分 bean 實際都是無狀態(沒有實體變數)的(比如 Dao、Service),這種情況下, bean 是執行緒安全的,
@Component 和 @Bean 的區別是什么?
@Component注解作用于類,而@Bean注解作用于方法,@Component通常是通過類路徑掃描來自動偵測以及自動裝配到 Spring 容器中(我們可以使用@ComponentScan注解定義要掃描的路徑從中找出標識了需要裝配的類自動裝配到 Spring 的 bean 容器中),@Bean注解通常是我們在標有該注解的方法中定義產生這個 bean,@Bean告訴了 Spring 這是某個類的實體,當我需要用它的時候還給我,@Bean注解比@Component注解的自定義性更強,而且很多地方我們只能通過@Bean注解來注冊 bean,比如當我們參考第三方庫中的類需要裝配到Spring容器時,則只能通過@Bean來實作,
@Bean注解使用示例:
@Configuration
public class AppConfig {
@Bean
public TransferService transferService() {
return new TransferServiceImpl();
}
}
上面的代碼相當于下面的 xml 配置
<beans>
<bean id="transferService" class="com.acme.TransferServiceImpl"/>
</beans>
下面這個例子是通過 @Component 無法實作的,
@Bean
public OneService getService(status) {
case (status) {
when 1:
return new serviceImpl1();
when 2:
return new serviceImpl2();
when 3:
return new serviceImpl3();
}
}
將一個類宣告為 bean 的注解有哪些?
我們一般使用 @Autowired 注解自動裝配 bean,要想把類標識成可用于 @Autowired 注解自動裝配的 bean 的類,采用以下注解可實作:
@Component:通用的注解,可標注任意類為Spring組件,如果一個 Bean 不知道屬于哪個層,可以使用@Component注解標注,@Repository: 對應持久層即 Dao 層,主要用于資料庫相關操作,@Service: 對應服務層,主要涉及一些復雜的邏輯,需要用到 Dao 層,@Controller: 對應 Spring MVC 控制層,主要用戶接受用戶請求并呼叫 Service 層回傳資料給前端頁面,
bean 的生命周期?
下面的內容整理自:https://yemengying.com/2016/07/14/spring-bean-life-cycle/ ,除了這篇文章,再推薦一篇很不錯的文章 :https://www.cnblogs.com/zrtqsk/p/3735273.html ,
- Bean 容器找到組態檔中 Spring Bean 的定義,
- Bean 容器利用 Java Reflection API 創建一個 Bean 的實體,
- 如果涉及到一些屬性值 利用
set()方法設定一些屬性值, - 如果 Bean 實作了
BeanNameAware介面,呼叫setBeanName()方法,傳入 Bean 的名字, - 如果 Bean 實作了
BeanClassLoaderAware介面,呼叫setBeanClassLoader()方法,傳入ClassLoader物件的實體, - 如果 Bean 實作了
BeanFactoryAware介面,呼叫setBeanFactory()方法,傳入BeanFactory物件的實體, - 與上面的類似,如果實作了其他
*.Aware介面,就呼叫相應的方法, - 如果有和加載這個 Bean 的 Spring 容器相關的
BeanPostProcessor物件,執行postProcessBeforeInitialization()方法 - 如果 Bean 實作了
InitializingBean介面,執行afterPropertiesSet()方法, - 如果 Bean 在組態檔中的定義包含 init-method 屬性,執行指定的方法,
- 如果有和加載這個 Bean 的 Spring 容器相關的
BeanPostProcessor物件,執行postProcessAfterInitialization()方法 - 當要銷毀 Bean 的時候,如果 Bean 實作了
DisposableBean介面,執行destroy()方法, - 當要銷毀 Bean 的時候,如果 Bean 在組態檔中的定義包含 destroy-method 屬性,執行指定的方法,
圖示:
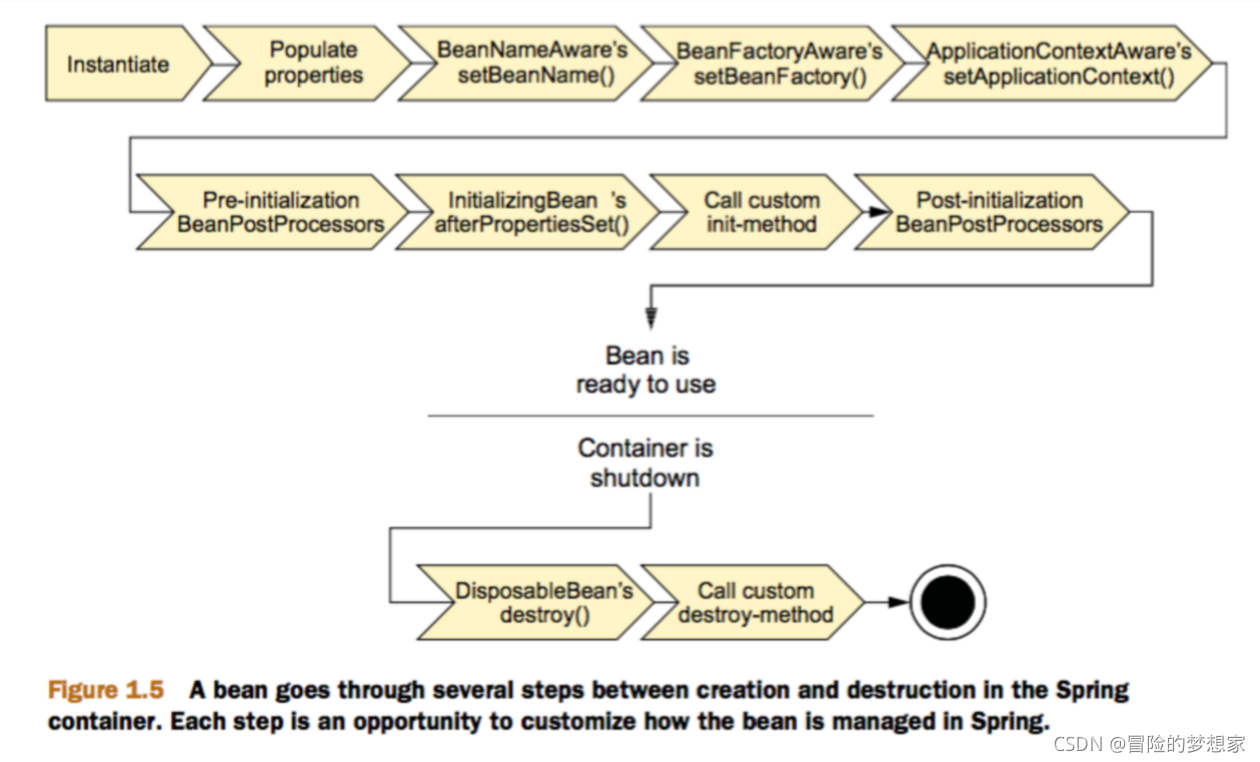
與之比較類似的中文版本:
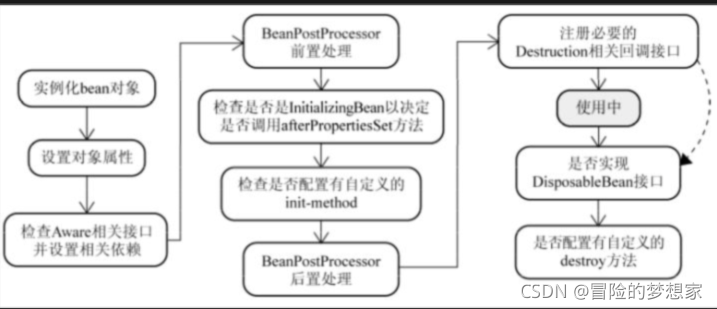
Spring MVC
說說自己對于 Spring MVC 了解?
MVC 是模型(Model)、視圖(View)、控制器(Controller)的簡寫,其核心思想是通過將業務邏輯、資料、顯示分離來組織代碼,
網上有很多人說 MVC 不是設計模式,只是軟體設計規范,我個人更傾向于 MVC 同樣是眾多設計模式中的一種,java-design-patterns 專案中就有關于 MVC 的相關介紹,
想要真正理解 Spring MVC,我們先來看看 Model 1 和 Model 2 這兩個沒有 Spring MVC 的時代,
Model 1 時代
很多學 Java 后端比較晚的朋友可能并沒有接觸過 Model 1 時代下的 JavaWeb 應用開發,在 Model1 模式下,整個 Web 應用幾乎全部用 JSP 頁面組成,只用少量的 JavaBean 來處理資料庫連接、訪問等操作,
這個模式下 JSP 即是控制層(Controller)又是表現層(View),顯而易見,這種模式存在很多問題,比如控制邏輯和表現邏輯混雜在一起,導致代碼重用率極低;再比如前端和后端相互依賴,難以進行測驗維護并且開發效率極低,
Model 2 時代
學過 Servlet 并做過相關 Demo 的朋友應該了解“Java Bean(Model)+ JSP(View)+Servlet(Controller) ”這種開發模式,這就是早期的 JavaWeb MVC 開發模式,
- Model:系統涉及的資料,也就是 dao 和 bean,
- View:展示模型中的資料,只是用來展示,
- Controller:處理用戶請求都發送給 ,回傳資料給 JSP 并展示給用戶,
Model2 模式下還存在很多問題,Model2 的抽象和封裝程度還遠遠不夠,使用 Model2 進行開發時不可避免地會重復造輪子,這就大大降低了程式的可維護性和復用性,
于是,很多 JavaWeb 開發相關的 MVC 框架應運而生比如 Struts2,但是 Struts2 比較笨重,
Spring MVC 時代
隨著 Spring 輕量級開發框架的流行,Spring 生態圈出現了 Spring MVC 框架, Spring MVC 是當前最優秀的 MVC 框架,相比于 Struts2 , Spring MVC 使用更加簡單和方便,開發效率更高,并且 Spring MVC 運行速度更快,
MVC 是一種設計模式,Spring MVC 是一款很優秀的 MVC 框架,Spring MVC 可以幫助我們進行更簡潔的 Web 層的開發,并且它天生與 Spring 框架集成,Spring MVC 下我們一般把后端專案分為 Service 層(處理業務)、Dao 層(資料庫操作)、Entity 層(物體類)、Controller 層(控制層,回傳資料給前臺頁面),
SpringMVC 作業原理了解嗎?
Spring MVC 原理如下圖所示:
SpringMVC 作業原理的圖解我沒有自己畫,直接圖省事在網上找了一個非常清晰直觀的,原出處不明,
流程說明(重要):
- 客戶端(瀏覽器)發送請求,直接請求到
DispatcherServlet, DispatcherServlet根據請求資訊呼叫HandlerMapping,決議請求對應的Handler,- 決議到對應的
Handler(也就是我們平常說的Controller控制器)后,開始由HandlerAdapter配接器處理, HandlerAdapter會根據Handler來呼叫真正的處理器開處理請求,并處理相應的業務邏輯,- 處理器處理完業務后,會回傳一個
ModelAndView物件,Model是回傳的資料物件,View是個邏輯上的View, ViewResolver會根據邏輯View查找實際的View,DispaterServlet把回傳的Model傳給View(視圖渲染),- 把
View回傳給請求者(瀏覽器)
Spring 框架中用到了哪些設計模式?
關于下面一些設計模式的詳細介紹,可以看筆主前段時間的原創文章《面試官:“談談 Spring 中都用到了那些設計模式?”,》 ,
- 工廠設計模式 : Spring 使用工廠模式通過
BeanFactory、ApplicationContext創建 bean 物件, - 代理設計模式 : Spring AOP 功能的實作,
- 單例設計模式 : Spring 中的 Bean 默認都是單例的,
- 模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 結尾的對資料庫操作的類,它們就使用到了模板模式, - 包裝器設計模式 : 我們的專案需要連接多個資料庫,而且不同的客戶在每次訪問中根據需要會去訪問不同的資料庫,這種模式讓我們可以根據客戶的需求能夠動態切換不同的資料源,
- 觀察者模式: Spring 事件驅動模型就是觀察者模式很經典的一個應用,
- 配接器模式 : Spring AOP 的增強或通知(Advice)使用到了配接器模式、spring MVC 中也是用到了配接器模式適配
Controller, - …
Spring 事務
Spring/SpringBoot 模塊下專門有一篇是講 Spring 事務的,總結的非常詳細,通俗易懂,
Spring 管理事務的方式有幾種?
- 編程式事務 : 在代碼中硬編碼(不推薦使用) : 通過
TransactionTemplate或者TransactionManager手動管理事務,實際應用中很少使用,但是對于你理解 Spring 事務管理原理有幫助, - 宣告式事務 : 在 XML 組態檔中配置或者直接基于注解(推薦使用) : 實際是通過 AOP 實作(基于
@Transactional的全注解方式使用最多)
Spring 事務中哪幾種事務傳播行為?
事務傳播行為是為了解決業務層方法之間互相呼叫的事務問題,
當事務方法被另一個事務方法呼叫時,必須指定事務應該如何傳播,例如:方法可能繼續在現有事務中運行,也可能開啟一個新事務,并在自己的事務中運行,
正確的事務傳播行為可能的值如下:
1.**TransactionDefinition.PROPAGATION_REQUIRED**
使用的最多的一個事務傳播行為,我們平時經常使用的@Transactional注解默認使用就是這個事務傳播行為,如果當前存在事務,則加入該事務;如果當前沒有事務,則創建一個新的事務,
**2.TransactionDefinition.PROPAGATION_REQUIRES_NEW**
創建一個新的事務,如果當前存在事務,則把當前事務掛起,也就是說不管外部方法是否開啟事務,Propagation.REQUIRES_NEW修飾的內部方法會新開啟自己的事務,且開啟的事務相互獨立,互不干擾,
3.**TransactionDefinition.PROPAGATION_NESTED**
如果當前存在事務,則創建一個事務作為當前事務的嵌套事務來運行;如果當前沒有事務,則該取值等價于TransactionDefinition.PROPAGATION_REQUIRED,
4.**TransactionDefinition.PROPAGATION_MANDATORY**
如果當前存在事務,則加入該事務;如果當前沒有事務,則拋出例外,(mandatory:強制性)
這個使用的很少,
若是錯誤的配置以下 3 種事務傳播行為,事務將不會發生回滾:
**TransactionDefinition.PROPAGATION_SUPPORTS**: 如果當前存在事務,則加入該事務;如果當前沒有事務,則以非事務的方式繼續運行,**TransactionDefinition.PROPAGATION_NOT_SUPPORTED**: 以非事務方式運行,如果當前存在事務,則把當前事務掛起,**TransactionDefinition.PROPAGATION_NEVER**: 以非事務方式運行,如果當前存在事務,則拋出例外,
Spring 事務中的隔離級別有哪幾種?
和事務傳播行為這塊一樣,為了方便使用,Spring 也相應地定義了一個列舉類:Isolation
public enum Isolation {
DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
private final int value;
Isolation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
下面我依次對每一種事務隔離級別進行介紹:
**TransactionDefinition.ISOLATION_DEFAULT**:使用后端資料庫默認的隔離級別,MySQL 默認采用的REPEATABLE_READ隔離級別 Oracle 默認采用的READ_COMMITTED隔離級別.**TransactionDefinition.ISOLATION_READ_UNCOMMITTED**:最低的隔離級別,使用這個隔離級別很少,因為它允許讀取尚未提交的資料變更,可能會導致臟讀、幻讀或不可重復讀**TransactionDefinition.ISOLATION_READ_COMMITTED**: 允許讀取并發事務已經提交的資料,可以阻止臟讀,但是幻讀或不可重復讀仍有可能發生**TransactionDefinition.ISOLATION_REPEATABLE_READ**: 對同一欄位的多次讀取結果都是一致的,除非資料是被本身事務自己所修改,可以阻止臟讀和不可重復讀,但幻讀仍有可能發生,**TransactionDefinition.ISOLATION_SERIALIZABLE**: 最高的隔離級別,完全服從 ACID 的隔離級別,所有的事務依次逐個執行,這樣事務之間就完全不可能產生干擾,也就是說,該級別可以防止臟讀、不可重復讀以及幻讀,但是這將嚴重影響程式的性能,通常情況下也不會用到該級別,
[@Transactional(rollbackFor ](/Transactional(rollbackFor ) = Exception.class)注解了解嗎?
Exception 分為運行時例外 RuntimeException 和非運行時例外,事務管理對于企業應用來說是至關重要的,即使出現例外情況,它也可以保證資料的一致性,
當 @Transactional 注解作用于類上時,該類的所有 public 方法將都具有該型別的事務屬性,同時,我們也可以在方法級別使用該標注來覆寫類級別的定義,如果類或者方法加了這個注解,那么這個類里面的方法拋出例外,就會回滾,資料庫里面的資料也會回滾,
在 @Transactional 注解中如果不配置rollbackFor屬性,那么事務只會在遇到RuntimeException的時候才會回滾,加上 rollbackFor=Exception.class,可以讓事務在遇到非運行時例外時也回滾,
JPA
如何使用 JPA 在資料庫中非持久化一個欄位?
假如我們有下面一個類:
@Entity(name="USER")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "ID")
private Long id;
@Column(name="USER_NAME")
private String userName;
@Column(name="PASSWORD")
private String password;
private String secrect;
}
如果我們想讓secrect 這個欄位不被持久化,也就是不被資料庫存盤怎么辦?我們可以采用下面幾種方法:
static String transient1; // not persistent because of static
final String transient2 = "Satish"; // not persistent because of final
transient String transient3; // not persistent because of transient
@Transient
String transient4; // not persistent because of @Transient
一般使用后面兩種方式比較多,我個人使用注解的方式比較多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/350903.html
標籤:java