文章目錄
- 1. 二叉樹的順序存盤
- 1.1 存盤方式
- 1.2 下標關系
- 1.3 順序存盤和堆的關系
- 2. 堆
- 2.1 概念
- 2.2 堆的創建(以大根堆為例)
- 2.3 創建堆的時間復雜度(易錯)
- 3. 堆的應用(1)優先級佇列
- 3.1 概念
- 3.2 內部原理
- 3.3 入佇列操作
- 3.4 出佇列操作
- 3.5 回傳隊首元素操作
- 4. 堆的應用(2)TopK 問題
- 4.1 介紹
- 4.2 方法
- 4.3 思路
- 4.4 實作代碼
- 4.5 拓展(找第 k 大/小的元素)
- 5. 堆的應用(3)堆排序
- 5.1 思路
- 5.2 實作代碼
- 6. 練習題——查找和最小的 k 對數字
在上一章 《二叉樹的實作(超多圖、超詳解)》 中,我們介紹了二叉樹的存盤分為: 類似于鏈表的鏈式存盤和 順序存盤,鏈式存盤在上一節介紹過了,今天將從二叉樹的順序存盤過度到堆的實作,
1. 二叉樹的順序存盤
1.1 存盤方式
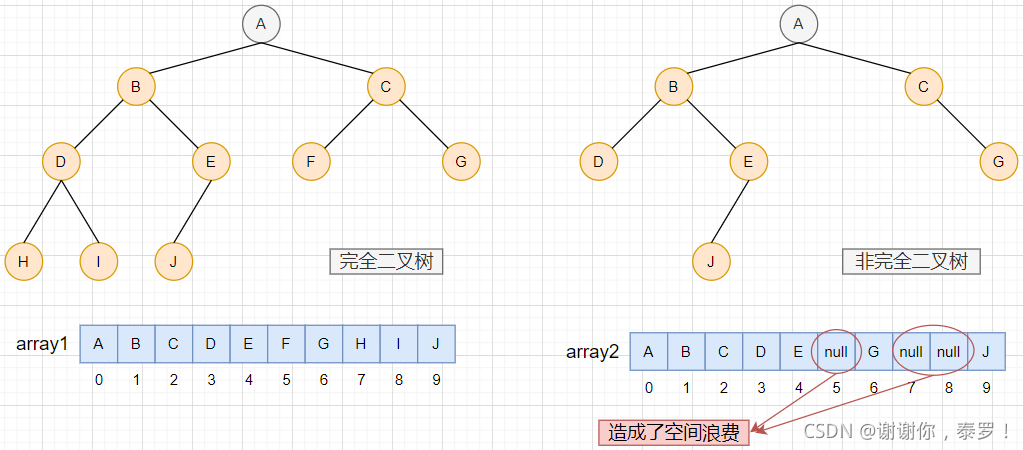
二叉樹的順序存盤:
是通過層序遍歷的方式將二叉樹存入陣列中
注意:
順序存盤一般只使用于完全二叉樹,因為非完全二叉樹會造成空間浪費
1.2 下標關系
由于二叉樹存盤在陣列中,父親節點和孩子節點的下標有以下關系:
- 已知父親節點的下標 i: 左孩子節點下標為 2i+1;右孩子節點下標為:2i+2
- 已知孩子節點的下標 i: 父親節點下標為 (i-1)/2
1.3 順序存盤和堆的關系
其實二叉樹的順序存盤,即將一棵完全二叉樹通過層序遍歷的方式存入陣列中,這種方式主要的用法其實就是今天的主角堆,堆的底層就是一棵完全二叉樹,并且是存盤在陣列中的,
2. 堆
2.1 概念
- 堆的邏輯上: 是一棵完全二叉樹
- 堆的物理上: 是保存在陣列中
堆的特類:
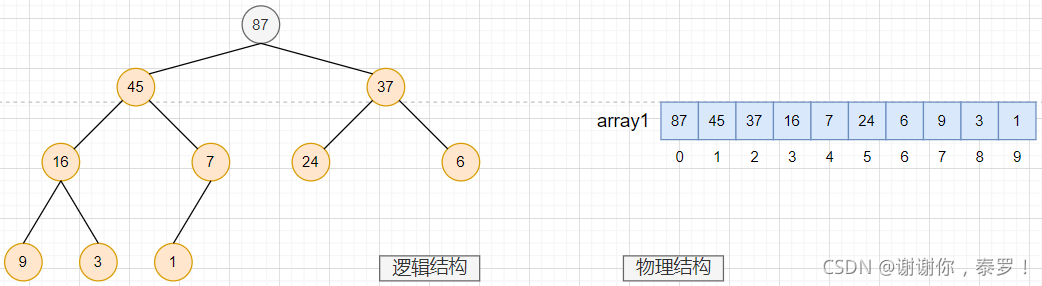
- 大根堆: 滿足任意節點的值都大于其子樹中節點的值(也叫大堆或最大堆)
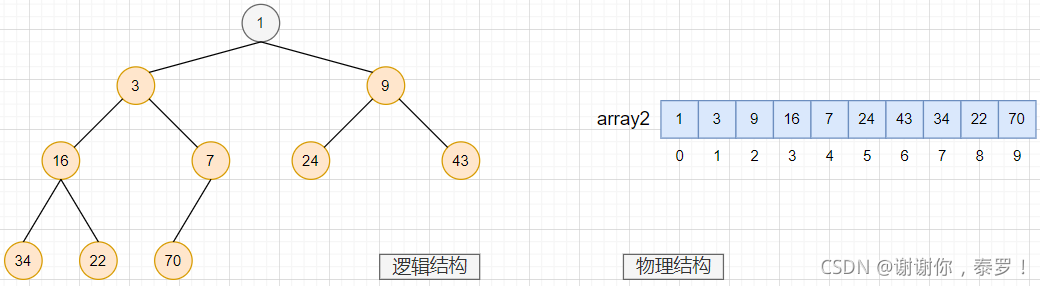
- 小根堆: 滿足任意節點的值都小于其子樹中節點的值(也叫小隊或最小堆)
大根堆示例圖:
小根堆示例圖:
注意:
只有整個二叉樹當中的每棵子樹都是大堆/小堆時,整棵樹才是大堆/小堆
堆的基本作用:
通過上圖演示大根堆和小根堆,我們很清晰的知道,堆的最基本的作用就是:快速找到集合中的最值
2.2 堆的創建(以大根堆為例)
步驟:
-
既然我們知道堆的物理底層是一個陣列,那么我們就可以先創建一個類,寫成這樣
public class TestHeap { public int[] elem; public int usedSize; public TestHeap(){ this.elem=new int[10]; } } -
我們得到了一個堆的類,接下來我們來實作這個類的最基本的操作,創建一個堆(這里以大根堆為例)
// 創建一個大根堆 public void createHeap(int[] array){ } -
該方法中我們可以首先把需要的資料直接存盤在 elem 中,之后直接對 elem 進行操作
// 創建一大根個堆 public void createHeap(int[] array){ // 首先把需要的資料直接存放在 elem 中,一會建堆時直接操作 elem for(int i=0;i<array.length;i++){ this.elem[i]=array[i]; this.usedSize++; } } -
接下來我們要解決怎么將存入的無規則的資料,轉換成我們需要的大根堆的存盤的順序,
- 先看一個已經在 elem 中存放了資料的示例圖,它的邏輯結構和物理結構如下:
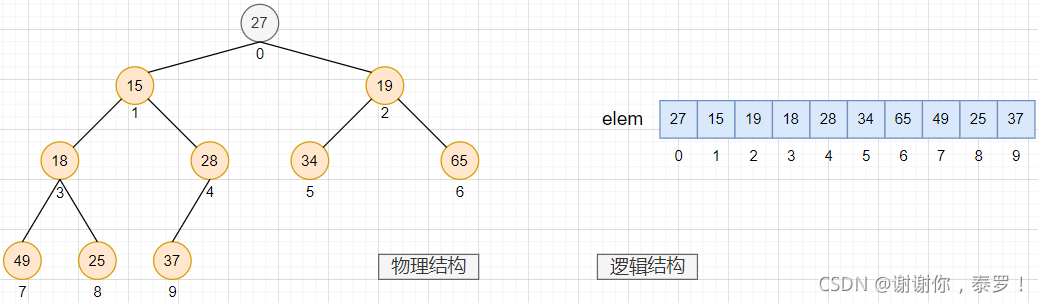
- 接下來通過向下調整的操作,從 elem 中的最后一個值,即最后一個節點開始,找到它的父節點,再找到這個父節點的左右子樹的較大的節點,如果它比父節點的值還大就進行交換,完成以后再繼續向前依次進行該操作,注意: 父節點與孩子節點若交換,以孩子節點為跟節點的子樹要判斷是否還事一個大根堆,
- 我們再通過子節點如果是 i,那么父節點就是 (i-1)/2 的關系,將這棵樹的子節點和父節點關聯起來
- 先看一個已經在 elem 中存放了資料的示例圖,它的邏輯結構和物理結構如下:
實作代碼:
// 創建一大根個堆
public void createHeap(int[] array){
// 首先把需要的資料直接存放在 elem 中,一會建堆時直接操作 elem
for(int i=0;i<array.length;i++){
this.elem[i]=array[i];
this.usedSize++;
}
// 從最后一個節點的父親節點開始對其進行向下操縱
for(int parent=(this.usedSize-2)/2;parent>=0;parent--){
shiftDown(parent);
}
}
public void shiftDown(int parent){
int child=2*parent+1;
// 進入該回圈說明你有左孩子,進行向下調整操作
while (child<this.usedSize){
if(child+1<this.usedSize&&this.elem[child]<this.elem[child+1]){
child++;
}
// child 所保存的下標就是左右孩子的最大值
if(this.elem[parent]<this.elem[child]){
int tmp=this.elem[parent];
this.elem[parent]=this.elem[child];
this.elem[child]=tmp;
parent=child;
child=2*parent+1;
}else {
// 該子樹的向下調整操作結束
break;
}
}
}
2.3 創建堆的時間復雜度(易錯)
錯誤計算方式(時間復雜度為:O(Nlog(N))):
- shiftDown 方法中: 最壞的情況就是從根節點開始要一直往下調整到葉子節點,通過性質我們知道:具有 n 個節點的完全二叉樹的深度為 log2(n+1) 向上取整,故該方法時間復雜度為:
O(log(N))- createHeap 方法中: 由于被向下調整的父節點的個數為 N/2,所以最終時間復雜度可以估算為:
O(Nlog(N))
正確計算方式(時間復雜度為:O(N)):
- 假設這棵樹的高度為 h,并且是一棵滿二叉樹(最壞情況)
- 從第1層到第 h 層,每層的節點個數分別為:20、21、22、…、2h-2、2h-1
- 從第1層到第 h 層,每層需要向下調整的高度為:h-1、h-2、h-3、…、1、0
- 由于最后一層我們不需要調整,只要調整第1層到倒數第1層即可,故得到時間復雜度的數學公式為:T(n) = 20 * (h-1) + 21* (h-2) + 22 * (h-3) + … + 2h-2 * 1,其中 n 為節點總數
- 再通過錯位相減法,我們可以將 T(n) 簡化為:T(n) = 2h - 1 - n
- 由于 n = 2h - 1,故 T(n) = n - log2(n+1) ,估算為時間復雜度為:
O(N)
3. 堆的應用(1)優先級佇列
3.1 概念
實際應用:
在很多應用中,我們通常需要按照優先情況對待處理物件進行處理,比如首先處理優先級最高的物件,然后處理次高的物件,最簡單的一個例子就是,在手機上玩游戲時,如果有來電,那么系統應該優先處理進來的電話,
優先級佇列:
在這種情況下,我們的資料結構應該提供兩個最基本的操作:一個是回傳最高優先級,另一個是添加新的物件,這種資料結構就是優先級佇列(Priority Queue)
3.2 內部原理
優先級佇列的實作方式有很多,但最常見的方式是:使用堆來構建
我們知道堆有兩個特類:大根堆和小根堆,而這兩個堆的根節點肯定是優先級最高的,故我們如果構建的這個大根堆或小根堆,不管是入佇列還是出佇列,在操作結束后,這個堆仍然是大根堆或小根堆,那么這個堆就一直保持著優先級的特點,
3.3 入佇列操作
思想(以大根堆為例):
- 將新元素尾查到陣列中
- 通過向上調整的方式,比較它與父親節點的值的大小,如果更大則交換
- 如果不交換則符合大根堆特點,則完成入佇列;如果交換,則將父節點變為孩子節點,再找到新的孩子節點的父節點進行重復操作直到孩子節點下標為0或父節點小標小于0結束
實作代碼:
// 判斷堆是否為空
public boolean isFull(){
return this.usedSize==this.elem.length;
}
// 入堆操縱
public void push(int val){
if(isFull()){
this.elem= Arrays.copyOf(this.elem,2*this.elem.length);
}
this.elem[this.usedSize++]=val;
shiftUp(this.usedSize-1);
}
// 向上調整
public void shiftUp(int child){
int parent=(child-1)/2;
while(parent>=0) {
if (this.elem[parent] < this.elem[child]) {
int tmp = this.elem[parent];
this.elem[parent] = this.elem[child];
this.elem[child] = tmp;
child = parent;
parent = (child - 1) / 2;
} else {
break;
}
}
}
3.4 出佇列操作
思想(以大根堆為例):
- 由于大根堆的堆頂元素一定是優先級最高的,故我們將它進行出佇列操作,
- 但是為了防止破壞堆的結構,洗掉時并不是直接將堆頂元素洗掉,而是用陣列的最后一個元素替換堆頂元素,然后通過向下調整的方式重新調整堆
實作代碼:
// 判斷堆是否為空
public boolean isEmpty(){
return this.usedSize==0;
}
// 出佇列
public int poll(){
if(isEmpty()){
throw new RuntimeException("佇列空,不能進行出佇列操作");
}
int val=this.elem[0];
this.elem[0]=this.elem[this.usedSize-1];
this.usedSize--;
// 通過向下調整
shiftDown(0);
return val;
}
3.5 回傳隊首元素操作
思想(以大根堆為例):
直接回傳堆頂元素
實作代碼:
// 回傳隊首元素
public int peek(){
if(isEmpty()){
throw new RuntimeException("堆為空");
}
return this.elem[0];
}
4. 堆的應用(2)TopK 問題
4.1 介紹
TopK 問題是在一組資料當中,找到前 k 個最大的或最小的資料,
示例:
如我們有一百個資料,我們要得到前十個最大或最小的元素
4.2 方法
處理 TopK 問題的方法有很多,如:簡單的排序、堆、分治法、減治法等等,
今天將用堆來處理這個 TopK 問題
4.3 思路
下面思路以找到前 k 個最大的元素為例,如果是找前 k 個最小的幾個元素,則做法相反
- 關于優先級的問題,我們往往就想到用大根堆或者小根堆,
- 而要找到最大的幾個元素,第一想法應該是大堆,但是如果我們用大堆的話,我們就要存盤含100個資料的大堆,并且每找到一個最大的元素就出堆,再通過向上調整,故最先出堆的10個元素就是最大的10個資料,但時間復雜度其實為:
O(N*log(N))- 如果我們反向思考,使用小堆的話,我們就可以先用小堆存盤前10個資料,再將后面的90個資料依次與小堆的堆頂元素(即最小元素)比較,如果大于堆頂元素,則將堆頂元素出堆,再通過向上調整將該堆再變成一個小堆,然后新的資料補上空缺的位置,故到最后,最小的元素其實都通過堆頂出堆了,剩下的就是10個最大的元素,時間復雜度為:
O(N*log(k))- 而 k 比 N 小的多,故用小堆去找前 k 個最大的元素更好
4.4 實作代碼
下面代碼以找到前 k 個最大的元素為例,如果是找前 k 個最小的幾個元素,則做法相反
// 找到前 k 個最大的元素
public static int[] topK(int[] array, int k){
// 默認建小堆
PriorityQueue<Integer> minHeap=new PriorityQueue<>();
for(int i=0;i<array.length;i++){
if(i<k){
minHeap.offer(array[i]);
}else {
if (array[i] > minHeap.peek()) {
minHeap.poll();
minHeap.offer(array[i]);
}
}
}
int[] elem=new int[k];
for(int i=k-1;i>=0;i--){
elem[i]=minHeap.poll();
}
return elem;
}
4.5 拓展(找第 k 大/小的元素)
思路:
- 找第 k 大的元素: 建小堆,得到前 k 個最大的元素,堆頂元素就是第 k 大的元素
- 找第 k 小的元素: 建大堆,得到前 k 個最小的元素,堆頂元素就是第 k 小的元素
5. 堆的應用(3)堆排序
如果我們要使用堆去對一些資料進行排序,那么我們該怎么做呢?
5.1 思路
這里以從小到大排序為例,如果要從大到小的話以下思路就是反的
首先我們明確是建一個大根堆,然后堆頂元素就是最大的,然后我們將堆頂元素與堆尾元素交換,此時最后一個元素就是最大的元素,然后通過向上調整,保證堆頂元素為最大的,然后與堆的倒數第二個元素進行交換,這樣我們就可以在每次交換中使從最末尾的元素開始依次變小的排序,
5.2 實作代碼
這里以從小到大排序為例,如果要從大到小的話以下思路就是反的
public static void heapSort(int[] array){
// 下面將默認的大堆改成小堆,并且使用了匿名內部類的方式
PriorityQueue<Integer> maxHeap=new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
for(int i=0;i<array.length;i++){
maxHeap.offer(array[i]);
}
int end=array.length-1;
while(end>=0){
int val=maxHeap.poll();
array[end]=val;
end--;
}
}
6. 練習題——查找和最小的 k 對數字
題目(OJ 鏈接):
給定兩個以升序排列的整數陣列 nums1 和 nums2 , 以及一個整數 k ,
定義一對值 (u,v),其中第一個元素來自 nums1,第二個元素來自 nums2 ,
請找到和最小的 k 個數對 (u1,v1), (u2,v2) … (uk,vk) ,
代碼:
class Solution {
public List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) {
PriorityQueue<List<Integer>> maxHeap=new PriorityQueue<>(new Comparator<List<Integer>>(){
@Override
public int compare(List<Integer> o1, List<Integer> o2){
return (o2.get(0)+o2.get(1))-(o1.get(0)+o1.get(1));
}
});
for(int i=0;i<Math.min(k,nums1.length);i++){
for(int j=0;j<Math.min(k,nums2.length);j++){
List<Integer> list=new ArrayList<>();
if(maxHeap.size()<k){
list.add(nums1[i]);
list.add(nums2[j]);
maxHeap.offer(list);
}else{
int top=maxHeap.peek().get(0)+maxHeap.peek().get(1);
if((nums1[i]+nums2[j])<top){
maxHeap.poll();
list.add(nums1[i]);
list.add(nums2[j]);
maxHeap.offer(list);
}
}
}
}
List<List<Integer>> minKList=new ArrayList<>();
for(int i=0;i<k && !maxHeap.isEmpty();i++){
minKList.add(maxHeap.poll());
}
return minKList;
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/350929.html
標籤:java
上一篇:Sequential And Linked Lists - 順序表 和 鏈表 - 鏈表部分 - java(圖文并茂,你值得一看)