大家好,我是小小明,
最近有不少博主有需求,需要快速提取Markdown檔案中的目錄并轉換為xmind思維導圖,據說官方提供了用python直接生成xmind思維導圖的方法,但有人反映生成的檔案打不開,那么基于這個現狀,我將開發一個效率輔助工具,幫助大家快速將Markdown轉換為xmind,
軟體使用介紹
首先打開程式,界面如下:
我們可以先選擇被加載的Markdown檔案所在的檔案夾:
此時再點擊加載按鈕:
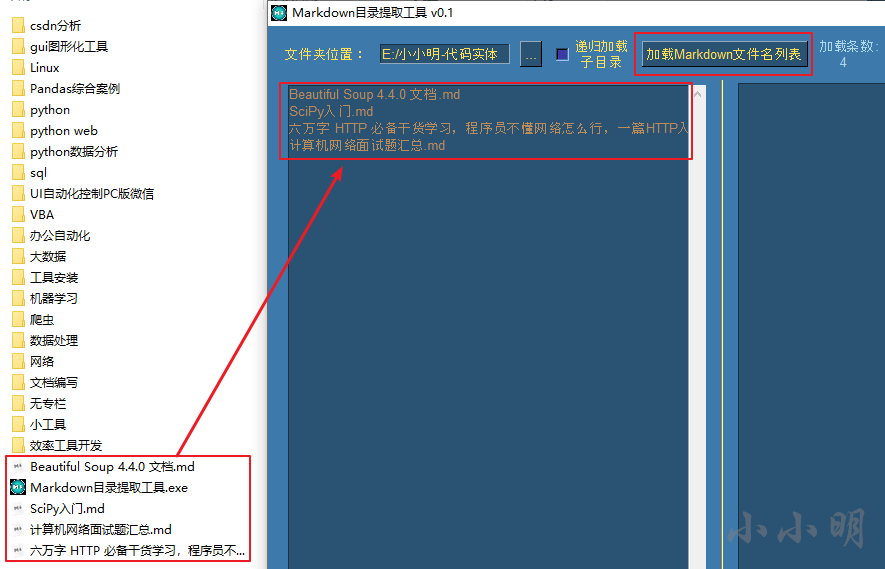
該目錄下的所有md檔案就都被加載到串列中,我們還可以再勾選 遞回 復選框后進行加載:
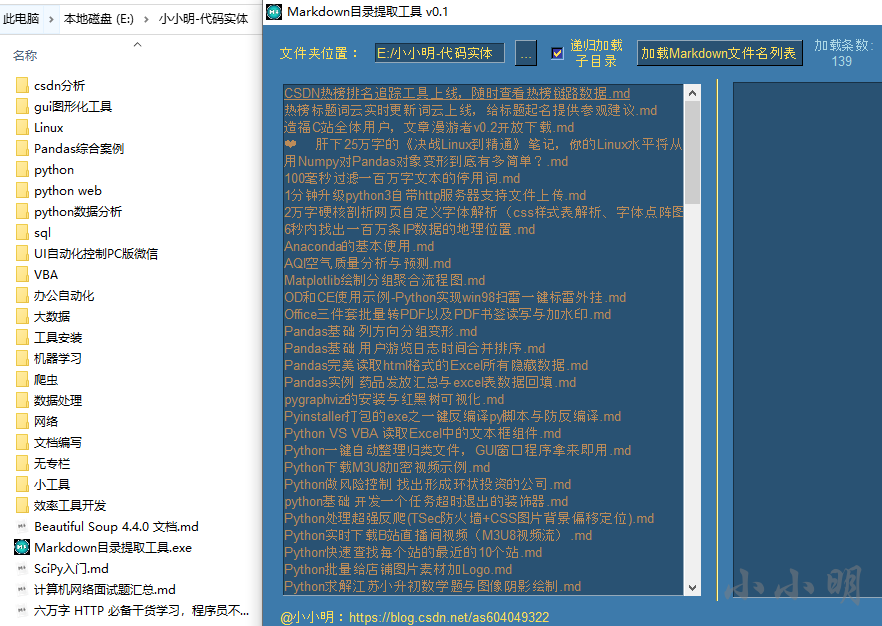
此時包含子檔案就都被加載到串列中,
如何將獲取指定Markdown檔案對應的目錄呢?
只需單擊對應的串列項即可:
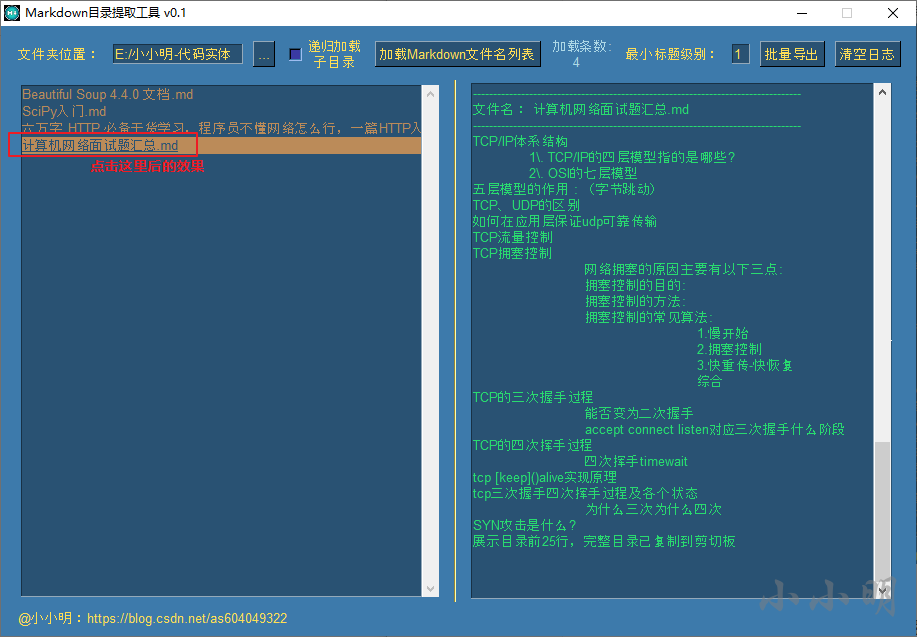
此時,Markdown目錄已經被復制到剪切版,此時我們可以粘貼到xmind軟體中,打開xmind軟體后,洗掉多余節點后,選中中心節點,再粘貼:
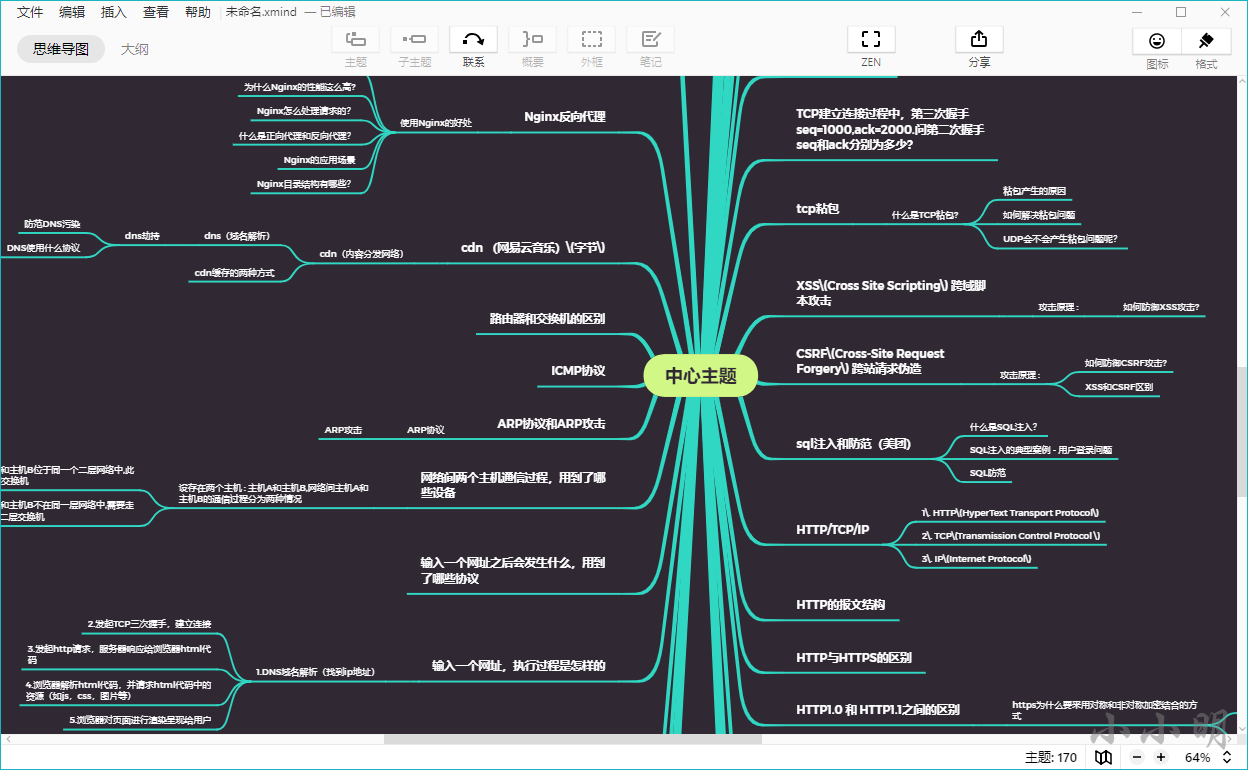
可以看到結果已經成為比較完美的思維導圖,此時我們只需修改中心節點的名稱后保存即可,
當然有部分Markdown檔案比較特殊,比如:
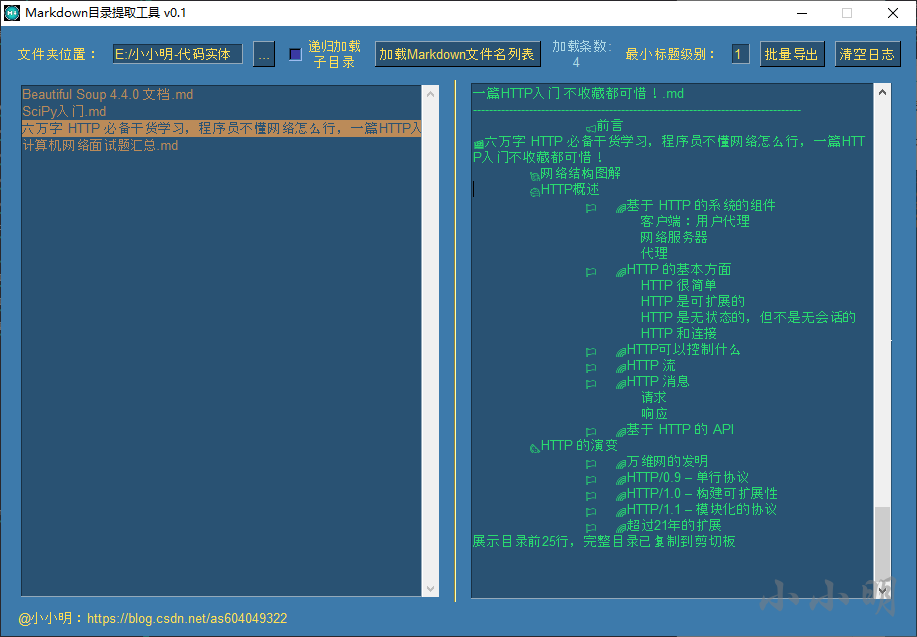
我們希望把一級標題去掉,其他級別的標題提高一級,可以將最小標題級別修改為2之后再單擊該文章:
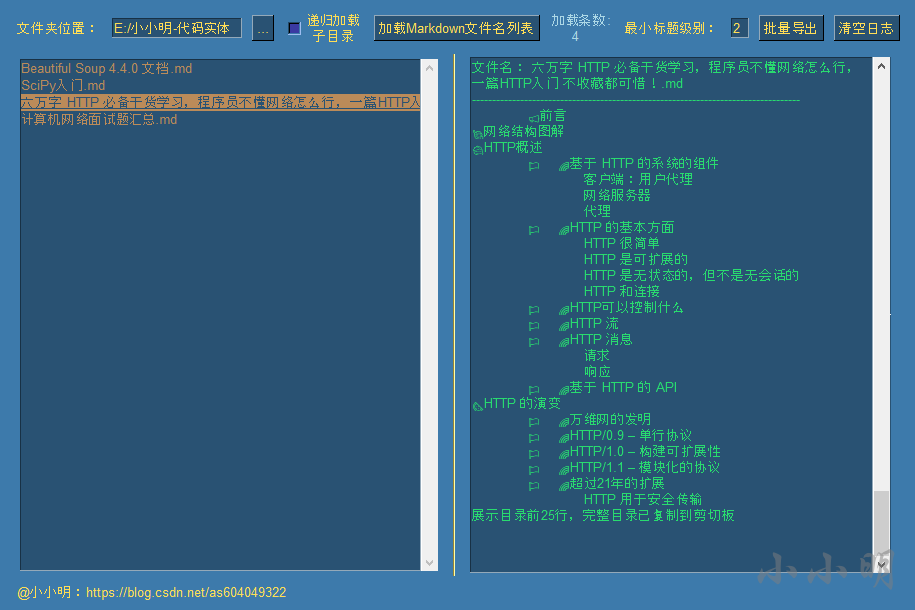
此時再去xmind粘貼就能獲取想要的效果,
當然對于串列中的檔案,我們還可以批量匯出目錄檔案,點擊批量匯出即可,點擊批量匯出后,先選擇一個保存的位置,選擇后則開始匯出:

若點擊后取消保存檔案夾的選擇就會終止匯出任務的執行,
開發代碼
先開發一個提取Markdown目錄的功能:
import cchardet
def load_md(filename, min_level=1):
with open(filename, "rb") as f:
md_bytes = f.read()
encoding = cchardet.detect(md_bytes)['encoding']
if encoding is None:
encoding = "u8"
md = md_bytes.decode(encoding)
code_area = False
result = []
for line in md.splitlines():
if line.startswith("```"):
code_area = not code_area
if code_area or not line.startswith("#") or line.find(" ") == -1:
continue
num_sign, title = line.split(maxsplit=1)
if not title:
continue
tab_num = len(num_sign) - min_level
if tab_num < 0:
continue
result.append("\t" * tab_num + title)
return result
這里我使用了cchardet進行編碼識別,未使用過的讀者需要安裝:
pip install cchardet
上述代碼的原理就是按行讀取Markdown文本,碰到#開頭而且含空格的文本就認為是含標題的行,同時排除掉#是處于代碼區域的情況,
其他代碼,感興趣的童鞋自行研究噢,完整代碼和已打包好的工具請到codeChina下載,
工具和開源代碼下載地址:
https://codechina.csdn.net/as604049322/python_gui
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/350964.html
標籤:python
上一篇:投射Spark資料框的架構