我正在使用 selenium 從谷歌圖片自動下載多張圖片,因為我之前在互聯網上找到的所有其他解決方案都太慢或無法正常作業,但現在我需要提取圖片的來源,但是當我嘗試時使用 element.get_attribute('src') 它回傳影像的 base64,甚至當我在 chrome devtools 上搜索 xpath 標簽的 src 屬性時,它實際上是一個 url
代碼試驗:
for i in range(n):
element = self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div/a/img')))
src = element.get_attribute('src')
print(element)
self.download_file(src,keyword)
編輯:
我實際上嘗試了你們中的一些人所說的,而不是下載影像,而是將 base 64 轉換為影像并保存,這比使用請求和 URL 保存要快得多,但猜測這更多是谷歌腳本的問題與我的代碼相比,有時我的代碼會損壞,因為 src 實際上回傳了一個 URL,最后,我不得不創建兩個不同的函式,一個如果 src 回傳一個 url,另一個如果回傳 base64
uj5u.com熱心網友回復:
要列印的價值SRC屬性需要引起WebDriverWait的visibility_of_element_located(),你可以使用以下的定位策略:
使用
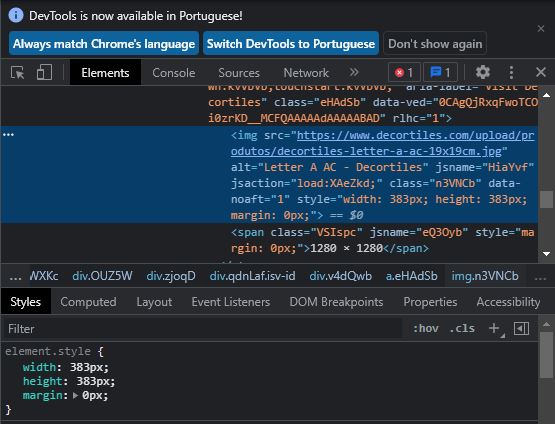
CSS_SELECTOR:print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "img[alt='Letter A AC - Decortiles'][src]"))).get_attribute("src"))使用
XPATH:print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//img[@alt='Letter A AC - Decortiles' and @src]"))).get_attribute("src"))注意:您必須添加以下匯入:
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/352753.html
標籤:Python 硒 硒网络驱动程序 路径 css-选择器