包的下載地址:dabeaz/ply: Python Lex-Yacc (package download)
官方檔案地址:dabeaz/ply: Python Lex-Yacc (official document)
貌似本體是其他學校的編譯課設...那確實不知道比我們高到哪里去了,
這個包提供了比較強大的 Lex / Yacc 工具,能夠完成不太復雜龐大的語法的詞法、語法分析,對于學校的大作業和課設來說是足夠的,
官方檔案中介紹了該包的基本使用方法,舉的例子是運算式決議,我在使用該包做MIPS匯編的語法檢查時(代碼可見:Github: LiuRunky - SEUCSE-Lab-Minisys-1A/assembler-src),用到了大部分的特性,并且有一些檔案中沒有寫出或強調的心得,于是就在這里一邊整理一邊記錄,
目錄:
Lex
1. 簡單介紹
2. 基本結構
3. Token 型別串列
4. Token 匹配規則的宣告
5. 特殊的匹配規則
6. 匹配優先級(Token 間)
7. 匹配優先級(Token 內)
8. 函式方式定義支持的操作
9. 匹配規則的回傳值
10. 一些可能有用的東西
Yacc
1. 簡單介紹
2. 基本結構
3. Production 匹配規則的宣告
4. 特殊的匹配規則
5. Production 型別的組成與使用
6. 匹配完成后的進階操作
7. 一些可能有用的東西
Lex
1. 簡單介紹
ply 包提供的 Lex 工具能夠對于給定的文本進行詞法分析,內部的實作方式是通過正則匹配獲得一個文本中包含 Token 的串列,而我們要做的作業就是給定用于匹配的正則運算式,
其中 Token 是一個形式如下的四元組:[type, value, lineno, lexpos] ,其中 type 表示詞的型別(比如 variable / number / string,由我們來命名),value 就是文本中匹配上的內容(比如 "114514" / "0x1234" 都是合法的 number 型別),lineno 表示詞出現的行號,lexpos 表示詞出現在文本中的第幾個字符,一般來說 type 和 value 比較關鍵,而 lineno 和 lexpos 一般用于生成分析的報錯資訊,
2. 基本結構
按照功能來分類的話,整個 ply Lex 的代碼(不含主函式內)分為如下三個部分(細節在之后會展開說):
# 1. 包的引入 from ply import lex # 2. Token型別串列的宣告 tokens = ( 'TOKEN_1', 'TOKEN_2', 'TOKEN_3' ) # 3. Token匹配規則的宣告(字串,函式) t_TOKEN_1 = r"""reg_expr_1""" t_TOKEN_2 = r"""reg_expr_2""" def t_TOKEN_3(t): r"""reg_expr_3""" return t
至于主函式內的呼叫,可以如下進行(在真正 Lex Yacc 聯合使用的時候不需要呼叫 lexer.input(data),這是因為在 Yacc 內會自動地隱式呼叫 Lex,不過這個之后再說):
if __name__ == '__main__': data = 'reg_expr_3reg_expr_2reg_expr_1' lexer = lex.lex() lexer.input(data) while True: token = lexer.token() print(token) if not token: break
雖然上面的例子毫無卵用,但是其實是可以運行的,運行以上代碼,結果如下:
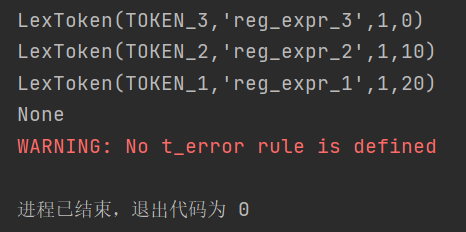
其中,輸出了一行 None 是因為使用 lexer.token() 會自動獲取下一 Token,直到讀到文本末尾則回傳 None,而 WARNING 中涉及的規則之后再議(其實不鳥它也完全沒關系),
3. Token 型別串列
從上面的例子可以看出來,Token 型別串列 tokens 就是一個簡單的、由字串組成的元組,其中每一個字串表示一種 Token 的名稱,不過這里只是宣告了“有一種叫這個的 Token”,具體的匹配規則和匹配成功后的操作需要在之后補充完整,
需要注意的是,Token 名稱最好定義成全大寫字母,這是因為要與 Yacc 中的產生式進行區分(產生式一般定義成全小寫字母),這樣在寫 Yacc 部分的代碼時不容易混淆,
一些特殊的規則,比如 error(匹配不上時的操作)、ignore(需要忽略的字符),不需要在 Token 型別串列中出現,只需要在 Token 匹配規則中宣告 t_error、t_ignore,可以看出來,這些特殊規則的名稱是全小寫字母,
4. Token 匹配規則的宣告
上文已經介紹過了,Token 匹配規則的宣告有兩種方式:字串與函式,無論哪種方式,都需要與 Token 名稱相對應、在名稱前加上"t_"(比如 Token 叫 "TOKEN_TYPE_1",那么匹配規則就應該命名為 "t_TOKEN_TYPE_1"),
可以認為字串方式定義的規則是簡化版的函式方式,即以下兩種定義方式在功能上是等價的:
t_TOKEN = r"""expr""" def t_TOKEN(t) r"""expr""" return t
簡單比較兩者的區別的話,字串方式比較簡單(只是進行匹配)、代碼長度短,而函式方式能夠在匹配成功后進行自定義的操作、功能更強,兩者除了功能以外,還在匹配優先級上有所區別,相對而言函式方式的優先級比較容易規定,這個在之后專門開了兩小節展開說,如果不放心的話可以全定義成函式方式,
之前代碼給出的匹配規則有點太弱了,現在給兩個畫風稍微正常一點的:
def t_IDNAME(t): r"""[a-zA-Z][0-9a-zA-Z]*""" return t def t_VALUE(t): r"""(0[xX][0-9a-fA-F]+)|([0-9]+)|([01]+[bB])""" return t
其中,t_IDNAME 約定了變數名的匹配規則(首字母不為數字,之后可以是字母或數字;原代碼不是C語言的規則,所以沒考慮下劃線),而 t_VALUE 約定了數值的匹配規則(可以是二進制、十進制、十六進制,當為二進制時末尾必須有 "b" 或 "B",當為十六進制時開頭必須為 "0x" 或 "0X"),
這些匹配規則都是需要通過正則運算式給出的,如果不太了解Python的規則的話可以參考Python 正則運算式 | 菜鳥教程 ,
5. 特殊的匹配規則
(1) t_ignore:在匹配時忽略的一些字符,比如空格與制表符 "\t"
一個比較常用的定義方式如下,過濾了空格與 "\t",注意這里不為raw string(由于 t_ignore 屬于優先級最低的規則了,所以往往用字串方式定義,類似的用法可見 官方檔案4.8 - literal characters):
t_ignore = ' \t'
不過這樣存在了一個問題:如果我們在 t_ignore 中規定過濾空格,那么就不能用詞法分析直接獲得含空格的 Token(比如C中的 "long long"型別),示例代碼與運行結果如下:


# 1. 包的引入 from ply import lex # 2. Token型別串列的宣告 tokens = ( 'TOKEN_1', 'TOKEN_2', 'TOKEN_3' ) # 3. Token匹配規則的宣告(字串,函式) t_TOKEN_1 = r"""long long""" # 優先級最高 t_TOKEN_2 = r"""longlong""" # 優先級次高 t_TOKEN_3 = r"""long""" # 優先級最低 t_ignore = ' \t' if __name__ == '__main__': data = 'long long longlong' lexer = lex.lex() lexer.input(data) while True: token = lexer.token() print(token) if not token: break示例代碼
> WARNING: No t_error rule is defined > LexToken(TOKEN_3,'long',1,0) > LexToken(TOKEN_3,'long',1,5) > LexToken(TOKEN_1,'longlong',1,10) > None運行結果
(2) t_error:在匹配失敗時的動作
一般用于報錯,沒什么特別高級的功能,寫了和不寫差距不大,大概只是消除 WARNING 吧,
def t_error(t): raise Exception('Lex error {} at line {}, illegal character {}' .format(t.value[0], t.lineno, t.value[0]))
(3) 其他:t_eof 寫和不寫感覺是真沒區別...另外的規則參考官方檔案吧,不過貌似就只有這三個,
6. 匹配優先級(Token 間)
優先級規則其實是 ply 包中最重要的內容了(畢竟別的東西都封裝好了),而官方檔案在這里講的太粗了,我在檔案的基礎上再多補充寫內容,
之前說到用字串方式和函式方式定義匹配規則在優先級方面有所區別,具體區別如下:
(1) 如果用字串方式定義,那么用于匹配的正則運算式越長則匹配優先級越高;
(2) 如果用函式方式定義,函式在代碼中出現的位置越靠前則匹配優先級越高;
(3) 用函式方式定義的匹配規則優先級永遠高于用字串定義的,
這也是為什么說“不確定就用函式”,因為函式相對字串更容易控制優先級,一般來說,用字串方式定義的規則只有 t_ignore 和一些不容易成為其他規則前綴的匹配規則,比如逗號 ","、分號 ";" 一般是可以用字串方式定義的;而保留字(如 "int"、"double")則不合適,因為其容易被識別成變數名,
官方檔案關于優先級的討論到前文的規則 (1) (2) (3) 就結束了,但在實際使用中真正容易遇到的問題卻被忽略了:變數名與保留字沖突應該如何解決?
根據對于字串定義方式的分析,我們知道了保留字應當用函式方式定義(保留字 > 變數名);但是在現實中,我們經常可能定義一個前綴是保留字的變數,比如:
int int_number = 1; bool true_or_false = true;
如果我們規定保留字的優先級高于變數名,那么經過詞法分析,我們會得到這樣的 Token:"int", "int", "_number", "=", "1", ";", "bool", "true", "_or_false", "=", "true", ";",顯然,"int_number" 和 "true_or_false" 這兩個變數的決議是存在問題的,而這樣的問題在真正debug遇到的時候很難定位到,
如果想要解決這樣的問題,我們又需要規定前綴為保留字的變數優先級高于保留字(變數名 > 保留字),這下就產生矛盾了,
對于這樣的問題沒有一個簡單的解決方法,我們必須通過分解問題來解決,我想出的解決方案是,將變數名分為兩類:保留字前綴類(必須為保留字+其他字符) 和 非保留字前綴類,保留字前綴類的優先級高于保留字,非保留字前綴類的優先級低于保留字,不過這樣一來保留字類的匹配規則就會長得十分惡心,必須考慮到所有的保留字才能實作,所以我寫了一個C++代碼來根據保留字串列自動生成保留字前綴類的匹配規則,主要思想是對保留字建 trie 樹、打標記,然后在 trie 樹上 dfs,如果遇到標記(保留字的結尾)就再進行第二個 dfs,從而生成描述保留字與保留字之間互為前綴關系的匹配規則,
#include <map> #include <cstdio> #include <vector> #include <cstring> #include <iostream> #include <algorithm> using namespace std; typedef pair<int,int> pii; const int MAX_SYMBOL=300; const int MAX_STR_LEN=100; const int MAX_NODE_NUM=10000; int symbol=63; string full_collec="[a-zA-Z0-9_]"; int mapping[300]; char rmapping[MAX_SYMBOL]; bool init_symbol[MAX_SYMBOL]; bool extra_bslash[MAX_SYMBOL]; int tot=1; int tag[MAX_NODE_NUM]; int trie[MAX_NODE_NUM][MAX_SYMBOL]; bool pool[MAX_SYMBOL]; char pref[MAX_STR_LEN]; vector<string> solve(int x,int pos,int st_pos) { vector<string> ans; if(tag[x] && pos!=st_pos) return ans; memset(pool,false,sizeof(pool)); vector<int> v; for(int i=0;i<symbol;i++) if(trie[x][i]) pool[i]=true,v.emplace_back(i); vector<pii> v_res; for(int i=0;i<symbol;) { while(i<symbol && pool[i]) i++; if(i==symbol) break; int j=i+1; while(j<symbol && !pool[j] && !init_symbol[j]) j++; v_res.emplace_back(pii(i,j-1)); i=j; } if(v.empty()) return ans; string expr; for(int i=st_pos;i<pos;i++) expr=expr+pref[i]; expr=expr+'['; for(pii tmp: v_res) { char l=rmapping[tmp.first],r=rmapping[tmp.second]; if(l==r) { if(extra_bslash[tmp.first]) expr=expr+'\\'; expr=expr+l; } else expr=expr+l+'-'+r; } expr=expr+']'; ans.emplace_back(expr); for(int y: v) { pref[pos]=rmapping[y]; vector<string> ans_nxt=solve(trie[x][y],pos+1,st_pos); ans.insert(ans.end(),ans_nxt.begin(),ans_nxt.end()); } return ans; } map<string,vector<string>> combine; void dfs(int x,int pos) { vector<int> v; for(int i=0;i<symbol;i++) if(trie[x][i]) v.emplace_back(i); if(tag[x]) { string str_pref,expr; for(int i=0;i<pos;i++) str_pref=str_pref+pref[i]; vector<string> v_mid=solve(x,pos,pos); if(v_mid.size()>1) { expr=expr+'('; for(int i=0;i<v_mid.size();i++) expr=expr+v_mid[i]+(i+1==v_mid.size()?')':'|'); } else if(!v_mid.empty()) expr=expr+v_mid[0]; expr=expr+full_collec+(v_mid.empty()?'+':'*'); combine[expr].emplace_back(str_pref); } for(int y: v) { pref[pos]=rmapping[y]; dfs(trie[x][y],pos+1); } } int n; char buf[MAX_STR_LEN]; void init() { init_symbol[0]=true; for(int i=0;i<26;i++) mapping['a'+i]=i,rmapping[i]='a'+i; init_symbol[26]=true; for(int i=0;i<26;i++) mapping['A'+i]=26+i,rmapping[26+i]='A'+i; init_symbol[52]=true; for(int i=0;i<10;i++) mapping['0'+i]=52+i,rmapping[52+i]='0'+i; init_symbol[62]=extra_bslash[62]=false; mapping['_']=62,rmapping[62]='_'; } int main() { freopen("keywords.txt","r",stdin); init(); while(~scanf("%s",buf)) { n=strlen(buf); int cur=1; for(int i=0;i<n;i++) { int ch=mapping[buf[i]]; if(!trie[cur][ch]) trie[cur][ch]=++tot; cur=trie[cur][ch]; } tag[cur]=1; } /* for(int i=1;i<=tot;i++) for(int j=0;j<26;j++) if(trie[i][j]) printf("trie[%d][%c]=%d\n",i,char(j+'a'),trie[i][j]); */ pref[0]='\0'; dfs(1,0); vector<string> items; map<string,vector<string>>::iterator it; for(it=combine.begin();it!=combine.end();it++) { string r=it->first; vector<string> vl=it->second; sort(vl.begin(),vl.end()); reverse(vl.begin(),vl.end()); string item; if(vl.size()>1) item=item+'('; for(int i=0;i+1<vl.size();i++) { item=item+vl[i]+'|'; if((i+1)%5==0) item=item+'\n'; } item=item+vl.back(); if(vl.size()>1) item=item+')'; item=item+r; items.emplace_back(item); } for(int i=0;i<items.size();i++) { cout<<"(\n"<<items[i]<<"\n)"; if(i+1<items.size()) cout<<'|'; cout<<'\n'; } return 0; }View Code
如果使用的話,需要根據實際需求修改的包括全域變數的 symbol(保留字數量)、full_collec(保留字中所有可能出現的字符,用正則運算式給出),以及 init() 函式中字符對可用字符標號的映射規則 mapping 與其逆映射 rmapping,另外,init_symbol[i] = true 表示標號 i 為某一類連續可用字符的開始(這里的“開始”指的是 "0-9" 中的 "0" 和 "a-z" 中的 "a" 等)或單獨的字符(比如 "_" 和 "$" 等),extra_bslash[i] = true 表示標號 i 代表的字符在輸出的時候需要加反斜杠 "\\"(在使用正則運算式定義的規則中,"+|-|*|/" 需要用轉義符寫作 "\+|\-|\*|\/",因為這些符號在正則運算式中有具體意義;需不需要加雙反斜杠取決于Python的正則運算式規則),
7. 匹配優先級(Token 內)
Token 內的優先級指的是正則運算式內部的模式串互為前綴時,應當優先匹配哪個,比如存在兩種型別 "longlong" 與 "long"(之前說過了 ply.lex 不能匹配帶空格的規則 "long long"),而我們想用同一個規則 t_LONG_INT 來匹配,
對于這種情況,我們需要把較長的串寫在前面、較短的串寫在后面,即:
def t_LONG_INT(t): r"""longlong|long""" return t
在這種情況下,即使匹配上了 "long"、而在匹配 "longlong" 的程序中失敗了(比如文本為 "longdouble"),仍然會正確地回傳 "long",并且在 "long" 之后接著匹配;而如果將匹配規則寫作 r"""long|longlong""",當目標串為 "longlong" 時則會回傳兩個 "long",就不是預期的結果了,
8. 函式方式定義支持的操作
上面說到函式方法定義的規則支持相對比較復雜的操作,這里就挑兩個例子說明一下,
(1) 維護當前行號
ply.lex 本身是不會維護行號的(畢竟在一些語言中,"\n" 是應該被放進 t_ignore 中的),所以需要在掃到文本中的 "\n" 時維護 lexer.lineno:
def t_ENDL(t): r"""\n+""" t.lexer.lineno += len(t.value) return t
(2) 與全域變數聯動(例子:統計單詞數)
token_1_cnt = 0 def t_TOKEN_1(t): r"""token_1""" global token_1_cnt token_1_cnt += 1 return t
(3) 修改返回資訊
在下一節回傳值中細講,
9. 匹配規則的回傳值
在之前的函式方式定義中,我們都在最后寫上了 return t(t 為 Token 型別),不過并沒有說明它的用途;而在字串方法中甚至完全不顯式地產生回傳值(其實內部實作也只是單純地 return t),現在我們來進一步分析回傳值的機制和作用,
return t 到底被用到哪里去了,如果不回傳會有什么后果?本著這樣的思路,我們采用函式方法定義如下的規則,并將 return t 刪去:
def t_TOKEN(t): r"""token"""
然后用文本 data = 'https://www.cnblogs.com/LiuRunky/archive/2021/11/09/token' 進行詞法分析,結果會報錯,資訊如下:

定位到錯誤拋出的地點,發現代碼段的注釋資訊為 "No match. Call t_error() if defined.",可以看出如果不將 t 回傳,Lex 就會認為沒有匹配上規則,
通過進一步分析(比如修改 t.value 并輸出),我們能夠發現,回傳的 t 不僅是 lexer.token() 所獲得的 Token,t.value 更會出現在 Yacc 的語法分析中(而 t.type、t.lineno 和 t.lexpos 則在語法分析時不會保留,詳見 Yacc 部分的第5小節),所以,我們不僅有必要將 t 回傳,還可能需要將重要的資訊額外保存在 t.value 中(比如 t.type,或是其他一些標記),
我們可以自由地選擇 t.value 中保存的資訊格式,Python中獨特的List型別是一個不錯的選擇:
# 這里僅給出了關鍵代碼 def t_VALUE(t): r"""(0[xX][0-9a-fA-F]+)|([0-9]+)|([01]+[bB])""" t.value = [t.type, t.value] return t data = '0x233'
運行后的 Token 輸出結果為:
> LexToken(VALUE,['VALUE', '0x8c'],1,0)
10. 一些可能有用的東西
官方檔案中還介紹了一些我覺得有用的特性,不過我沒有用過,如果有需求可以自行閱讀,
官方檔案4.12 - the @TOKEN decorator:關于如何用 docstring 作為匹配規則;
官方檔案4.15 - alternative specification of lexers:關于如何將 lexer 封裝進自定義類中;
官方檔案4.19 - conditional lexing and start conditions:大概是允許在多種匹配模式中切換?有點沒看懂,
Yacc
1. 簡單介紹
ply 包提供的 Yacc 工具能夠對于給定的文本進行語法分析,Yacc 采用類似 .y 檔案的格式表示產生式,而我們需要給定這些產生式,
與 Lex 工具能夠獲得 Token 序列不太一樣,如果只使用最基本的 Yacc 只能夠檢查詞法分析后的 Token 序列是否滿足給定的語法規則,并沒有什么輸出,Yacc 真正強大的地方在于完成模式匹配后,能夠方便地確定每個 Token 在模式串中的角色,從而能夠在基礎語法檢查的基礎上稍加修改就能進行更高層級的檢查(比如檢查變數的未定義/重定義)以及高級語言向低級語言的轉化,
2. 基本結構
按照功能來分類的話,整個 ply Yacc 的代碼(不含 Lex 部分以及主函式內)分為如下兩個部分(細節在之后會展開說):
# 1. 包的引入 from ply import yacc # 2. Production匹配規則的宣告 start = 'production' # 默認的起始產生式為p_start,可以通過給start賦值來修改為p_production def p_production(p): r"""production : TOKEN_1 | production TOKEN_2"""
主函式的呼叫如下所示,需要顯式地定義 lexer,但不需要向其中喂文本:
if __name__ == '__main__': data = '0x233' lexer = lex.lex() parser = yacc.yacc(debug=True) parser.parse(data)
如果沒有 Token 能接收十六進制數的話,就會產生形如下面的 Lex 報錯資訊(匹配不到合適的詞,詞法分析失敗):

如果有 Token 能接受十六進制數、但不是 TOKEN_1 時,就會產生形如下面的 Yacc 報錯資訊(根據產生式可知,production 的開頭必須為 TOKEN_1):
![]()
如果 TOKEN_1 可以接收十六進制數的話,就會產生形如下面的運行成功資訊:
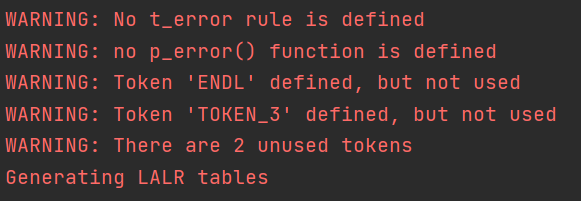
除了一堆 WARNING 以外就是生成 LALR table 的提示(這句提示在對于同一份規則第二次運行時就沒有了),之后啥輸出都沒有,所以往往需要采用后文介紹的方法通過輸出產生式的資訊來進行debug,
3. Production 匹配規則的宣告
Production 匹配規則只有函式宣告的方式,函式的名稱為 "p_" + 產生式名稱,且產生式的左項需要與產生式名稱相同,產生式的名稱不需要像 Token 名稱一樣預先寫在串列中,
當只有一個產生式時,raw string的格式為:
r"""production_name : token_name_1 production_name_2"""
當有多個產生式時,需要換行后寫在 "|" 符號的后面:
r"""production_name : token_name_1 token_name_2 | production_name token_name_3 | token_name_4"""
為了與詞法分析得到的 Token 區分,Production 的名稱一般定義為全小寫字母,
另外需要特別注意的是,假如產生式中需要遞回,那么必須采用左遞回,以下是一個簡單的運算式的例子:
def p_expr(p): r"""expr : expr OPERATOR NUMBER | NUMBER"""
這里再給出一個畫風比較正常的 Production 匹配規則的宣告:
def p_if(p): r"""if : IF LBRACKET TRUE RBRACKET | IF LBRACKET FALSE RBRACKET | IF LBRACKET expr BRACKET"""
這個匹配規則給出了一個簡化的C++中 if 陳述句條件的語法規則,其中 IF 匹配保留字 "if",LBRACKET 匹配左括號 "(",RBRACKET 匹配右括號 ")",TRUE 匹配保留字 "true",FALSE 匹配保留字 "false",expr 匹配一個產生運算式的 Production,
4. 特殊的匹配規則
要說 Yacc 中比較特殊的匹配規則,大概只有 p_empty 了,p_empty 就是一般意義上的 $\epsilon$,定義方法如下:
def p_empty(p): """empty :""" pass
那么一個 $\mathrm{production}\rightarrow \epsilon$ 的產生式就可以寫作:
def p_production(p): r"""production : empty"""
5. Production 型別的組成與使用
在我們宣告 Production 的匹配規則時,傳入了一個引數 p,這個引數是我們獲得該完成匹配的模式串的唯一途徑,
p 是一個長度不固定的 List,實際長度等于 匹配上的產生式長度 + 1(因為當前產生式名稱作為左項占據了 p[0]),舉個例子:
def p_production(p): r"""production : TOKEN_1 production_2 TOKEN_2 | TOKEN_3""" # ^ ^ ^ ^ # p[0] p[1] p[2] p[3]
假如產生式 production 的匹配結果是 TOKEN_1 production_2 TOKEN_2,那么 List 的長度為 4;假如匹配結果是 TOKEN_3,那么 List 的長度為 2,
p 里面裝的是什么東西呢?對于 Token 而言,p[i] 的值就是 Token.value,而 Token.type 的資訊都被丟掉了(這個在介紹 Token 匹配規則的回傳值時提到過);而對于 Production 而言,如果不做任何操作,p[i] 的值是 None,如果想讓此時代表 production_2 的 p[i] 有值,我們就需要在 production_2 的匹配規則 p_production_2 中為 p[0] 賦值,示例如下:
def p_production_2(p): r"""production : empty""" p[0] = ['production_2', 'empty']
因為 Yacc 的匹配是一個遞回的程序,所以當我們完成了 production 的匹配時,一定在此之前也完成了 production_2 的匹配,所以此時的 p[2] = ['production_2', 'empty'],
知道了 p 是什么東西以后,對于有多個產生式的 Production,我們可以通過分類討論 len(p) 的大小 以及具體某個 p[i] 的值來加以區分,訪問和操作也與正常操作 List 沒什么區別,
由于 p 是一個 List,所以我們可以往 p[i] 里塞任何東西,不過如果要塞多個屬性的話,最好用 List 裝起來便于操作,
除了 List 中的內容以外,Production 還支持獲取 Token.lineno 和 Token.lexpos,使用方法為 p.lineno(i) 和 p.lexpos(i),還有一些細節有需要的話可以參考 官方檔案6.9 - line number and position tracking,
6. 匹配完成后的進階操作
一時半會并不能想起來什么太高端的操作...就拿運算式求值 和 檢查變數是否未定義/重定義來說一說吧,
(1) 運算式求值
這個是官方檔案中描述的例子,其實整體思路很簡單:對于 Token,將 Token.value 轉為 int 型別;對于 Production,根據運算的型別(通過檢查運算子對應的 p[i] 的值加以分辨)執行相應的運算,將結果賦給 p[0] 即可,
為了簡單起見,只實作運算子為加減的運算式求值,更加復雜的運算式需要根據運算優先級設計 Production 的匹配規則,這里就不展開說了,
from ply import lex, yacc tokens = ( 'NUMBER', 'PLUS', 'MINUS' ) t_PLUS = r"""\+""" t_MINUS = r"""\-""" t_ignore = ' \t' def t_NUMBER(t): r"""[0-9]+""" t.value = int(t.value) return t start = 'expr' def p_expr(p): r"""expr : NUMBER | expr PLUS NUMBER | expr MINUS NUMBER""" if len(p) == 2: p[0] = p[1] elif p[2] == '+': p[0] = p[1] + p[3] else: p[0] = p[1] - p[3] if __name__ == '__main__': data = '1+2-3+4-5' lexer = lex.lex() parser = yacc.yacc(debug=True) print(parser.parse(data)) # 運行結果:-1
(2) 檢查變數定義
這是在寫課設時碰到的問題,實作起來也并不困難,在全域維護一個 Dict,當完成變數的定義時就檢查 Dict 中是否已有該變數名,從而檢查是否重定義;當使用到某個變數時,同樣在 Dict 中檢查該變數名,從而檢查是否未定義,
因為只是展示一下思路,所以對于語法做了很多簡化,通過 define 來定義變數,在運算式中使用變數,
from ply import lex, yacc tokens = ( 'VARIABLE', 'NUMBER', 'DEFINE', 'PLUS', 'MINUS', 'ENDL' ) t_PLUS = r"""\+""" t_MINUS = r"""\-""" t_ignore = ' \t' def t_DEFINE(t): r"""define""" return t def t_VARIABLE(t): r"""[a-zA-Z][0-9a-zA-Z]*""" t.value = ['VARIABLE', t.value] return t def t_NUMBER(t): r"""[0-9]+""" t.value = ['NUMBER', t.value] return t def t_ENDL(t): r"""\n+""" t.lexer.lineno += len(t.value) return t start = 'codes' dict_variable = {} def p_codes(p): r"""codes : code | codes ENDL code""" def p_code(p): r"""code : expr | define""" def p_define(p): r"""define : DEFINE VARIABLE""" if p[2][1] in dict_variable: raise Exception('redefined {} at line {}' .format(p[2][1], p.lineno(2))) else: dict_variable[p[2][1]] = p.lineno(2) def p_expr(p): r"""expr : NUMBER | VARIABLE | expr PLUS NUMBER | expr PLUS VARIABLE | expr MINUS NUMBER | expr MINUS VARIABLE""" if p[len(p)-1][0] == 'VARIABLE': if p[len(p)-1][1] not in dict_variable: raise Exception('undefined {} at line {}' .format(p[len(p)-1][1], p.lineno(2)))
if __name__ == '__main__': data = r"""define x define a x + a + 4 + b""" lexer = lex.lex() parser = yacc.yacc(debug=True) print(parser.parse(data)) # 報錯資訊:Exception: undefined b at line 3
7. 一些可能有用的東西
官方檔案6.6 - dealing with ambiguous grammars:一般來說ambiguous grammer會導致產生shift-reduce或者reduce-reduce沖突,是應當盡量避免的,不過 ply.yacc 支持通過規定優先級的方式來避免這些沖突,
官方檔案6.8 - syntax error handling:更加高階的語法錯誤檢測,不會像目前的做法一樣遇到任何錯誤就終止,不過需要設定不少東西,
官方檔案6.11 - embedded actions:算是一個trick吧,可以在語法分析的程序中輸出中間資訊,為什么這樣說起來感覺就很trivial...
牡蠣~ 感覺身體被掏空
感覺自己的contribution主要在于 Lex 那邊變數名避免撞保留字前綴的代碼生成,看了一遍document應該是沒有處理吧...如果里面直接解決了就顯得我很蠢了...
(完)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/353158.html
標籤:其他
上一篇:C語言 assert 函式 - C語言零基礎入門教程
下一篇:LeetCode 76~80