目錄
一、pycharm的使用問題
二、首行縮進
三、深淺copy
四、字符編碼
五、閉包函式和裝飾器
身為一個python小白,在不懈的學習了快兩個月python后,已經基本學完了python的基礎語法,在學習中也遇到了很多坑,現在我希望把我遇到的坑分享一下,也是關于一些基礎問題,希望對剛開始學習的小伙伴可以有所幫助,同時里面也有幾個python里的高級語法和難理解的概念,這里面本身也包含我自己不理解的一些點,我抱著嘗試的心去講一下,要是對里面的一些代碼或者專業詞匯描述有錯或者講錯的話,還請專業人士指正,
一、pycharm的使用問題
相信很多人在學習的時候都下載了pycharm,身為python的一個集成開發環境,pycham我覺得編程環境是最好的,除此之外我也試過vs vscode等,但我覺得都沒有pycharm好用,
1、在pycharm上我建議下載tabnine的代碼補全和漢化(漢化根據個人需要,要是英語特別好或者后期其實不用漢化,甚至用起來會很別扭)
2、pycharm不同于IDLE,IDLE上使用print或者直接敲回車都可以實作輸出,但是pycharm上必須是要加一個print的,例如這樣一個查找索引值的代碼和布爾型別,在IDLE中直接敲回車就可以實作,但是pycharm中的print必不可少
a=["1","2"]
print("1" in a)
print(a.index("1"))3、pycharm最人性話的設計可能是每日小技巧了,他會每天根據你敲的代碼來給你一點小技巧使你更方便,但是這在漢化之后也也是英文顯示,但是還是建議直接耐心翻譯去看一下,
二、首行縮進
這是我碰到的最難受的一個點了,有的時候你首行縮進錯了pycharm并不會報錯,但是會讓你得到不是你想要的東西,有的時候也會大片的報錯,
而我總結了一下,主要就是邏輯問題,寫程式時候的邏輯不能錯,這件事干完該干什么,是并列還是包含,只要把本質弄清楚,就不會錯
1、if else elif 這是最基礎的但也是在邏輯上最容易出錯的,我就從我直接做的一些作業來說,例如我在之前學完回圈陳述句和條件陳述句做的一個小作業,要讓列印一個購物車的程式,回圈列印商品串列
product=[["iphone",111],["xiaomi",222],["huawei",333]]
shopping_cart=[]
while True:
print("-----商品串列--------")
for index,i in enumerate(product):
print("%s.%s %s"%(index,i[0],i[1] ))
choice = input("輸入你想買的東西的編號:")
if choice.isdigit():
choice=int(choice)
shopping_cart.append(product[choice])
print("Add product %s into shopping cart."%(product[choice]))
elif choice=="q":
print("-----你已經購買以下商品-----")
for index,p in enumerate(shopping_cart):
print("%s. %s %s" % (index,i[0],i[1]))尤其是中間,在中間開始回圈之后,利用for回圈和enumerat函式將商品產生出索引值以后,if陳述句跟for回圈是并列的,而不能將if和elif縮進進去,這樣才能使if陳述句有效,且在elif陳述句輸入q退出時,另一for也必須在elif陳述句里面這樣才能退出并列印已經加入的商品串列
2、函式類與面向物件的縮進,這兩者中的語法顯然比縮進重要,但是在這里也提一下,以這樣的一段嵌套為例
age=19
def k1():
age = 73
print(age)
def k2():
print(age)
k2()
k1()呼叫引數位置的不同也能影響輸出的結果,類與面向物件與函式相似,在呼叫與實體化的時候也需要注意,
注:主要在函式以及面向物件中,會出現嵌套函式以及多型問題,進而對邏輯有了更大的要求,
三、深淺copy
這算是python里面比較難理解的一個點,容易在考試里面出到,我們先從這樣一段代碼然后逐步加深理解
>>>a=1
>>>b=a
>>>a=2
>>>b
1
>>>id(a)
>>>id(b)在這段代碼里,你要是輸出b的值你會發現會輸出1,因為在b=a以后,b指向了1,而并不是指向a,所以b并不會跟隨a改變,可以用最后兩行代碼來驗證一下他們的記憶體地址(下面的代碼相當于我在IDLE里面寫的)
現在我們在串列里來看一下這段代碼
>>>n1=["hu","wang","iphone",1,2]
>>>n2=n1
>>>n2
["hu","wang","iphone",1,2]
>>>n1[2]="huawei"
>>>n1=["hu","wang","weawei",1,2]
>>>n2
大家想一想,我此時輸出n2會發生什么,按照上面的理解,n2是不會跟著n1改變的,但是他輸出的結果和改變后的n1是一樣的,這是為什么,就像我把一個東西放到杯子里面,每一個東西就是一個記憶體地址,現在n2直接指向了n1的記憶體地址,相當于n2,n1完全相同,對這兩個串列進行增刪查改,這兩個串列也仍然相同
但是如何將這兩個串列獨立呢,這是用copy可以實作
>>>n1=["hu","wang","iphone",1,2]
>>>n2=n1.copy()
>>>n1,n2
>>>(['hu', 'wang', 'iphone', 1, 2], ['hu', 'wang', 'iphone', 1, 2])
用兩種方法可以檢驗一下是否獨立,檢驗記憶體地址和改值
>>>n1=["hu","wang","iphone",1,2]
>>>n2=n1.copy()
>>>n1,n2
>>>(['hu', 'wang', 'iphone', 1, 2], ['hu', 'wang', 'iphone', 1, 2])
>>>id(n1)
2998395112000
>>>id(n2)
2998395300480
>>>n1[1]=2
>>>n1
['hu', 2, 'iphone', 1, 2]
>>>n2
['hu', 'wang', 'iphone', 1, 2]此時會發現,記憶體地址并不一樣并且修改n1后n2也不變,但是這樣做又會有一個新問題,比如這樣
>>>n1[1]=2
>>>n1
['hu', 2, 'iphone', 1, 2]
>>>n2
['hu', 'wang', 'iphone', 1, 2]
>>>n1.append(["3",3])
>>>n1
['hu', 2, 'iphone', 1, 2,["3",3]]
>>>n1[-1][0]="huhu"
>>>n1
['hu', 2, 'iphone', 1, 2,["huhu",3]]
>>>n2
['hu','wang', 'iphone', 1, 2,["huhu",3]]
大家發現了什么,我在n1這個串列里加了一個串列,不是說已經獨立了嗎,我在修改了n1這個串列里面的串列,n2也跟著改了,這是為什么,我們所說的獨立,是這個串列里面的元素獨立了,即是串列里面的串列獨立,為什么子串列里面的元素會變,因為子串列的元素都指向一個記憶體地址即這個子串列,
綜上所述
以上都是淺層次的獨立了串列,所有叫淺copy,但是如何深copy呢,這是需要匯入一個庫,當我們匯入了copy庫以后,便可以完全實作深copy了,
import copy
>>>n1=['hu', 2, 'iphone', 1, 2,["3",3]]
>>>n2=n1.copy()
>>>n2
['hu', 2, 'iphone', 1, 2,["3",3]]
>>>n1[-1][0]="huhu"
>>>n1
['hu', 2, 'iphone', 1, 2,["huhu",3]]
>>>n2
['hu','wang', 'iphone', 1, 2,["3",3]]四、字符編碼
python中的字符編碼真的好復雜好復雜,甚至python2和python3也有不同,這里面也涉及到有的時候為什么你輸出的結果變成了亂碼,我其實也不知道我現在到底理解了沒有,但是先講一下,看看我到底能不能把這個最基本的講清楚
1、什么是字符編碼
學計算機的朋友們應該都知道,計算機只能通過0和1來識別我們的語言,所以字符編碼就是將我們的語言全部轉為二進制來讓計算機去理解
2、一些常見的字符編碼
①ASCII
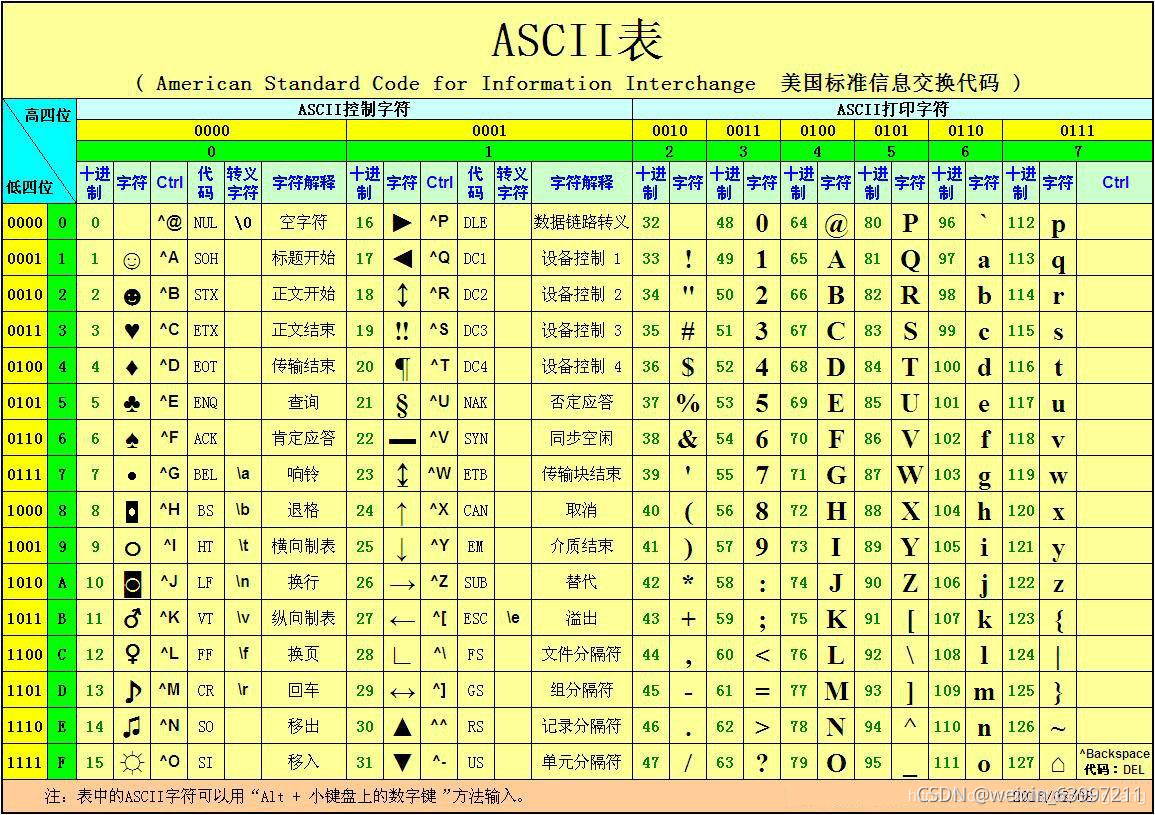
這是美國人發明的包含了最基本的128個字符的編碼表,通過這些使計算機可以了解我們的語言,但是這里面是英文字符啊,中國人要是想用怎么辦,于是Unicode誕生了
②unicode
Unicode又被稱為統一碼、萬國碼;它為每種語言中的每個字符設定了統一并且唯一的二進制編碼,以滿足跨語言、跨平臺進行文本轉換、處理的要求,
③GB2312與GBK
中國國家標準總局1980年發布《資訊交換用漢字編碼字符集》提出了GB2312編碼,用于解決漢字處理的問題,1995年又頒布了《漢字編碼擴展規范》(GBK),這樣就解決了我們國家的編碼問題,
④UTF :UTF-8,UTF-16 UTF-32
既然unicode這么好用,為什么不全世界一直用unicode呢,unicode存在這樣的一個問題,使用unicode來表示一個字符,至少占兩個位元組,而ASCII碼只需要一個,這樣會導致浪費記憶體空間,所以UTF出現了,UTF就是為unicode編碼設計的一種在存盤和傳輸時節省空間的編碼方案,可以理解為對unicode的一種壓縮,最常用的為UTF-8
UTF-8使用1、2、3、4個位元組表示所有字符,無法滿足則增加一個位元組
3、python2與python3的字符編碼
python3字串默認unicode 而檔案默認編碼是UTF-8,python2中,檔案編碼和字串編碼中都為ASCII,若檔案頭宣告gbk,則字串編碼為gbk
4、編碼在windows上的顯示
這里涉及到你寫的程式在終端上的運行,我也還沒有學習只是簡單了聽了一點,例如windows智能顯示unicode和gbk,否則會變成亂碼,
5、字符編碼的轉換
你可以通過以下代碼來進行字符編碼的轉換
>>>s="hu"
>>>s2=1.decode("utf-8")
總結:我對于字符編碼的理解也只是這些基礎知識,這里面有的東西還涉及到終端里的輸出 與unicode編碼的詳解我都不拿出來說了,希望后續可以有大佬來進行詳解,
五、閉包函式和裝飾器
關于閉包函式和裝飾器,這是我講的唯一一個高級語法,我看了視頻里面說這也是在面試里比較容易出到的問題,首先何為裝飾器,以我的理解,就是升級你的函式功能,但是,升級函式的方法又很多種,你可以定義多個函式,可以多次呼叫函式,但是、、、、
第一,有的時候你的代碼實作了功能但是卻會違反一些原則,例如“開放-封閉”原則:
開放:已實作的功能代碼塊不能被修改
封閉:對現有的功能進行拓展開發
第二,軟體開發需要的是多個團隊的運營和除錯,包含成千上萬的代碼,你這邊實作了自己的模塊,下一組的人呢,或許之后的代碼就需要重復修改幾千次甚至幾萬次或者直接報錯,現在我以這樣的一個功能來一步步進行講解
比如這樣,你的老板要讓你將查找數字和記錄時間整合到一起,可能你會寫出這樣一段代碼(這里參考了b站up主‘嘉然今晚吃槍子’的講解視頻,想學習的同學也可以去看一下)
import time
def kprint_odds():
start_time=time.perf_counter()
for i in range(100):
if i in range(100):
print(i)
end_time=time.perf_counter()
print("it takes {} s to find all the odds".format(end_time-start_time)
if __name__="__main__"
print_odds()這一個函式你會發現你成功的實作了功能,但是你會發現一個函式兩個輔助功能,有的代碼里面或許不止兩個輔助功能,萬一出錯修改非常麻煩甚至影響了主要功能,代碼函式一多,這樣寫函式幾乎就是一個災難,于是我們可以這樣修改
import time
def count_time(func):
start_time=time.perf_counter()
func()
end_time=time.perf_counter()
print("it takes {} s to find all the odds".format(end_time-start_time)
def print_odds():
for i in range(100):
if i%2 == 1:
print(i)
id __name__="__main__":
count_time(print_odds)
這樣定義兩個函式便可以減少錯誤,但是這樣的寫法仍有一個缺點,最后是通過在輔助函式里傳入主要函式進行運行,語法上可行,在可讀性上不好,給讀者顯示的應該是直接顯示主要函式,輔助函式應該被隱藏起來,于是我們就引入閉包函式,
閉包函式:一個函式的引數和回傳值都是函式
注:閉包本質上是一個函式
閉包函式的傳入引數和回傳值也都是函式
閉包函式的回傳值函式是對傳入函式增強后的結果
import time
def print_odds():
for i in range(100):
if i%2 ==1:
print(i)
def count_time_wrapper(func):
#閉包,用于增強函式func,給函式func增加統計時間的功能
def improved_func():
start_time = time.perf_counter()
func()
end_time = time.perf_counter()
print("it takes {} s to find all the odds".format(end_time - start_time))
return improved_func
if __name__ == "__main__":
#呼叫count_time_wrapper增強函式
print_odds = count_time_wrapper(print_odds)
print_odds()
print(print_odds())這是我們手動寫了一段增強函式的代碼來增強函式功能
print_odds = count_time_wrapper(print_odds)
然而我們需要一種機制,讓python解釋器自動增強,這時候python裝飾器就來了
import time
def count_time_wrapper(func):
def improved_func():
start_time = time.perf_counter()
func()
end_time = time.perf_counter()
print("it takes {} s to find all the odds".format(end_time - start_time))
return improved_func
@count_time_wrapper
def print_odds():
for i in range(100):
if i % 2 == 1:
print(i)
if __name__ == "__main__":
print_odds()
所有python裝飾器本質上就是函式閉包,并且裝飾器在第一次呼叫被裝飾函式時進行增強,
上面的裝飾器你會發現,里面并沒有回傳值和沒有輸入引數的,如果我的函式又回傳值和輸入引數,還能加強嗎?
這里需要注意
對于有回傳值的函式,呼叫閉包增強后,不能成功回傳,但是增強了函式的輔助功能
import time
def count_time_wrapper(func):
def improved_func():
start_time = time.perf_counter()
func()
end_time = time.perf_counter()
print("it takes {} s to find all the odds".format(end_time - start_time))
return improved_func
@count_time_wrapper
count=0
def count_odds(): #統計計數的個數
for i in range(100):
if i % 2 == 1:
count+=1
return count #這里增加了函式的回傳值
if __name__ == "__main__":
print_odds()對于含有引數的函式,呼叫閉包增強后,不能成功接收引數
import time
def count_time_wrapper(func):
def improved_func():
start_time = time.perf_counter()
func()
end_time = time.perf_counter()
print("it takes {} s to find all the odds".format(end_time - start_time))
return improved_func
@count_time_wrapper
count=0
def count_odds(lim=1000): #統計計數的個數 這里還增加了引數
for i in range(100):
if i % 2 == 1:
count+=1
return count #這里增加了函式的回傳值
if __name__ == "__main__":
print_odds(lim=1000)但是我們如何讓這個閉包接識訓傳值和引數呢,參考如下代碼
import time
def print_odds(lim=10000):
cnt=0
for i in range(100):
if i%2 ==1:
cnt+=1
return cnt
def count_time_wrapper(func):
def improved_func(*args, **kwargs): #增強函式應該吧接收到的所有引數傳給原函式
start_time = time.perf_counter()
res=func(*args, **kwargs) #傳入引數并記錄回傳值
end_time = time.perf_counter()
print("it takes {} s to find all the odds".format(end_time - start_time))
return res #回傳未增強函式的回傳值
return improved_func
if __name__ == "__main__":
print_odds = count_time_wrapper(print_odds)
print_odds(lim=10000)
這樣我們便實作了完美的閉包,后面還有多個裝飾器的問題,但我就到此為止吧,
總結
在學習完python的基礎語法之后,就可以學習網路編程和爬蟲了,這又是一個漫長的道路,在編程這條路上,我需要學習的東西還很多很多,并且需要不停學習,充實自己,現在python作為世界第一編程語言,的確有一些地方相對于c和java來說使用非常方便,這是也是我第一次第一次寫博客,希望大家可以支持,同時身為智能科學與技術的大一新生,我也希望在編程這條路上我可以一直走下去,不斷努力學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/353400.html
標籤:python