??人類社會已經進入大資料時代,大資料深刻改變著我們的作業和生活,隨著互聯網、移動互聯網、社交網路等的迅猛發展,各種數量龐大、種類繁多、隨時隨地產生和更新的大資料,蘊含著前所未有的社會價值和商業價值!!!
文章目錄
- 一、前言
- 二、實體引入
- 三、爬蟲
- 四、爬取思路
- 五、爬蟲實戰
- 1、單頁爬取
- 1.1、匯入模塊
- 1.2、確定URL
- 1.3、發起請求
- 1.4、獲得回應
- 1.5、資料決議
- 1.6、寫入檔案
- 2、我是如何“放棄”爬取多頁資料的
- 3、我是如何完成爬取多頁資料的
- 六、資料可視化分析 Echarts
- 1、匯入pyecharts模塊
- 2、各地區上映電影數量前十
- 3、電影評價人數前二十
- 4、各年份上映電影數量
- 5、其他可視化分析實體
- 七、后記
一、前言
??本文是一篇爬蟲實戰學習筆記,記錄近些時日對網路爬蟲的認識和學習心得,主要使用了 requests、 re 、Beautifulsoup 和pandas庫,初學爬蟲,代碼寫的有點爛,望包涵!
本文同步發表在我的個人博客上,歡迎訪問 :https://sunguoqi.com/2021/11/07/douban_top250/
二、實體引入
??假設由于作業或者專案要求,我們需要獲取豆瓣電影 Top250 上的影片資料,進行可視化分析,
??資料包括 影片名 上映年份 評分 導演 主演 電影類別 上映地區 影片名言 等
??原始的資料存放在豆瓣的網頁上,像這樣,
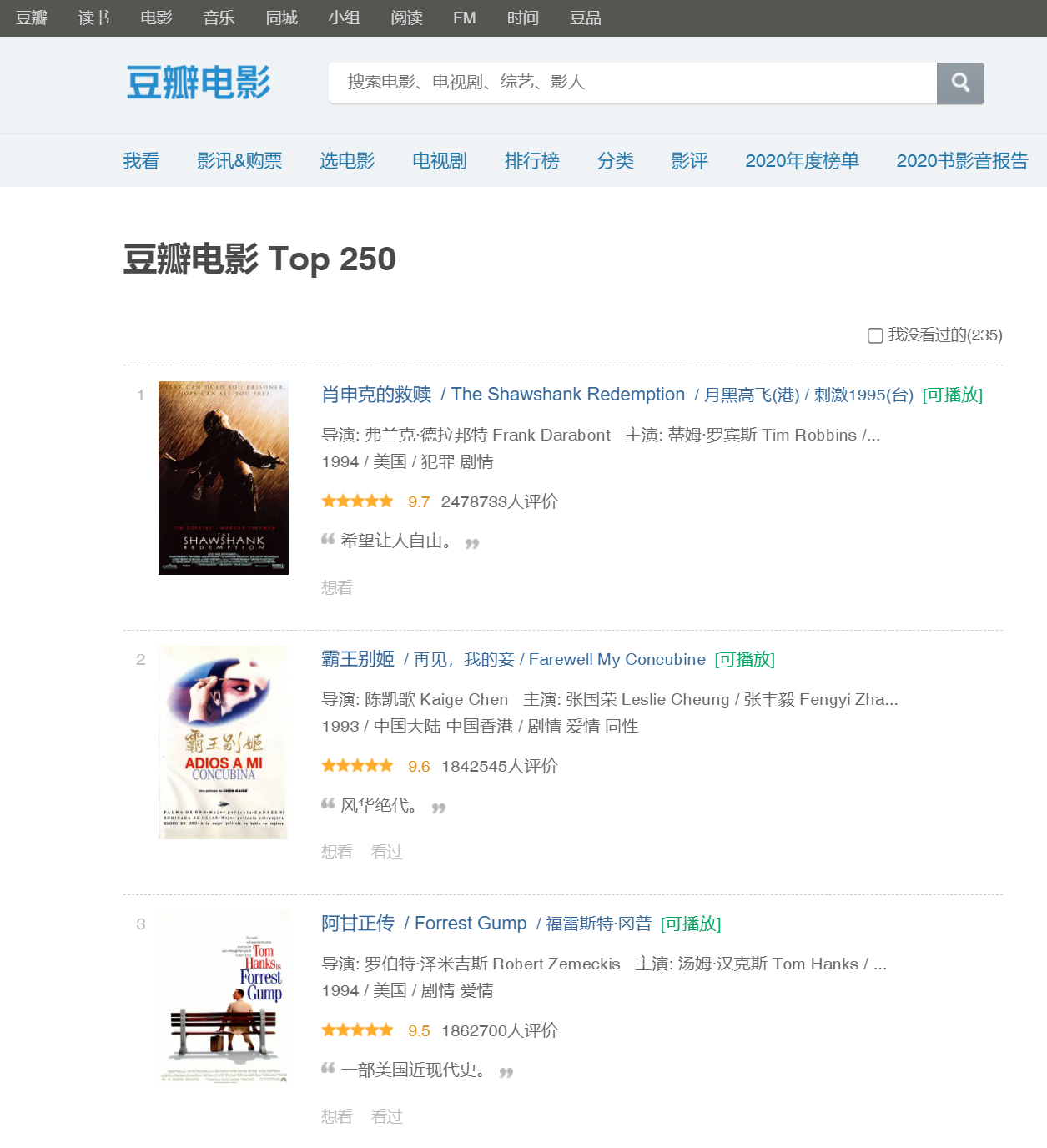

??試想一下,我們該怎么做?
??天大寒,硯冰堅,手指不可屈伸,弗之怠,錄畢,走送之,不敢稍逾約?
??我想人工摘錄是一個極不明智的選擇,在資訊時代,我們有計算機,我們有python,我們應該想方設法讓計算機去做這些事情,

三、爬蟲
??爬蟲,其實就是代替人力去完成資訊抓取作業的一門技術,他能按照一定的規則,從互聯網上抓取任何我們想要的資訊,
四、爬取思路
??如何寫爬蟲?我們寫爬蟲的思路是什么?
??前文提到,爬蟲是代替人去完成資訊抓取作業的,那么接下我們需要思考的問題便是,人是如何完成資訊抓取作業的,
??首先,我們打開豆瓣電影 TOP250 排行榜,分析我們需要的資料存放在哪里,然后復制粘貼,把我們的資料存放在excel表格里,依次重復如此枯燥乏味的作業對吧,
??是的,其實爬蟲要做的作業也是如此,寫爬蟲的大致思路如下,
??確定URL——>發起請求獲得服務器回應資料——>決議資料——> 資料存盤
五、爬蟲實戰
1、單頁爬取
??先把單頁爬取的代碼放在這里,稍后我會做詳細解釋,
"""
-*- coding: utf-8 -*-
@Time : 2021/11/6 下午 4:59
@Author : SunGuoqi
@Website : https://sunguoqi.com
@Github: https://github.com/sun0225SUN
"""
# 匯入一些模塊
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
# 首先確定URL
url = 'https://movie.douban.com/top250'
# UA偽裝
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
# 發起請求
response = requests.get(url, headers=headers)
# 獲得回應檔案文本
# print(response.text)
html = response.text
# 創建BeautifulSoup物件,方便決議
soup = BeautifulSoup(html, 'lxml')
# 找出所有的li標簽
all_li = soup.find('ol', {'class': 'grid_view'}).find_all('li')
# 創建一個空串列,存放我們的資料,
datas = []
for item in all_li:
# 提取影片名稱(只提取了中文名稱)
name = item.find('span', {'class': 'title'}).text
# 提取影片評分
score = item.find('span', {'property': 'v:average'}).text
# 提取影片經典語錄
quote = item.find('span', {'class': "inq"}).text
# 下面提取影片資訊部分
info = item.find_all('p', {'class': ''})
# print(info.text)
# 回傳的是一個串列,串列里是一個元組
# print(info[0].text)
info_contents = info[0].text
# 分割影片資訊,提取影片 導演 || 主演 || 上映年份 || 國家/地區 || 型別
result = re.findall(
'^.*?\u5bfc\u6f14:\s(.*?)\s.*?\u4e3b\u6f14:\s(.*?)\s.*?(\d{4})\s.*?([\u4e00-\u9fa5].*)\xa0.*?\u002f.*?([\u4e00-\u9fa5].*?)\s\s.*$',
info_contents, re.S)
# 把資料按找字典的格式存放到串列里
datas.append({
'片名': name,
'年份': result[0][2],
'評分': score,
'導演': result[0][0],
'主演': result[0][1],
'型別': result[0][4],
'國家/地區': result[0][3],
'經典臺詞': quote
})
print("爬取完成!!!")
# 寫入到檔案
df = pd.DataFrame(datas)
df.to_csv("豆瓣電影.csv", index=False, header=True, encoding='utf_8_sig')
print("已寫入豆瓣.csv檔案")
1.1、匯入模塊
?首先我們需要匯入四個模塊,沒有下面四個庫的同學需要PIP安裝下,
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
1.2、確定URL
??我們請求的URL是明確的,就是https://movie.douban.com/top250?start=0&filter=,其后面的引數是和多頁爬取和過濾相關的,這個我們后面會用到,
url = 'https://movie.douban.com/top250'
1.3、發起請求
??我們打開瀏覽器,輸入網址,按下enter鍵后便可獲得精美的頁面,但其實在這期間,計算機和瀏覽器為我們做了很多事情,
??不妨我們試一下,打開我們的瀏覽器,輸入網址https://movie.douban.com/top250,然后按下我們電腦上的F12鍵,打開開發者工具,選擇Network選項卡,重繪一下頁面,你會看到很多資料包,這便是我們按下enter鍵后獲得的資料本身,瀏覽器根據相應的規則對這些資料包進行決議和渲染,便生成了我們見到的網頁,
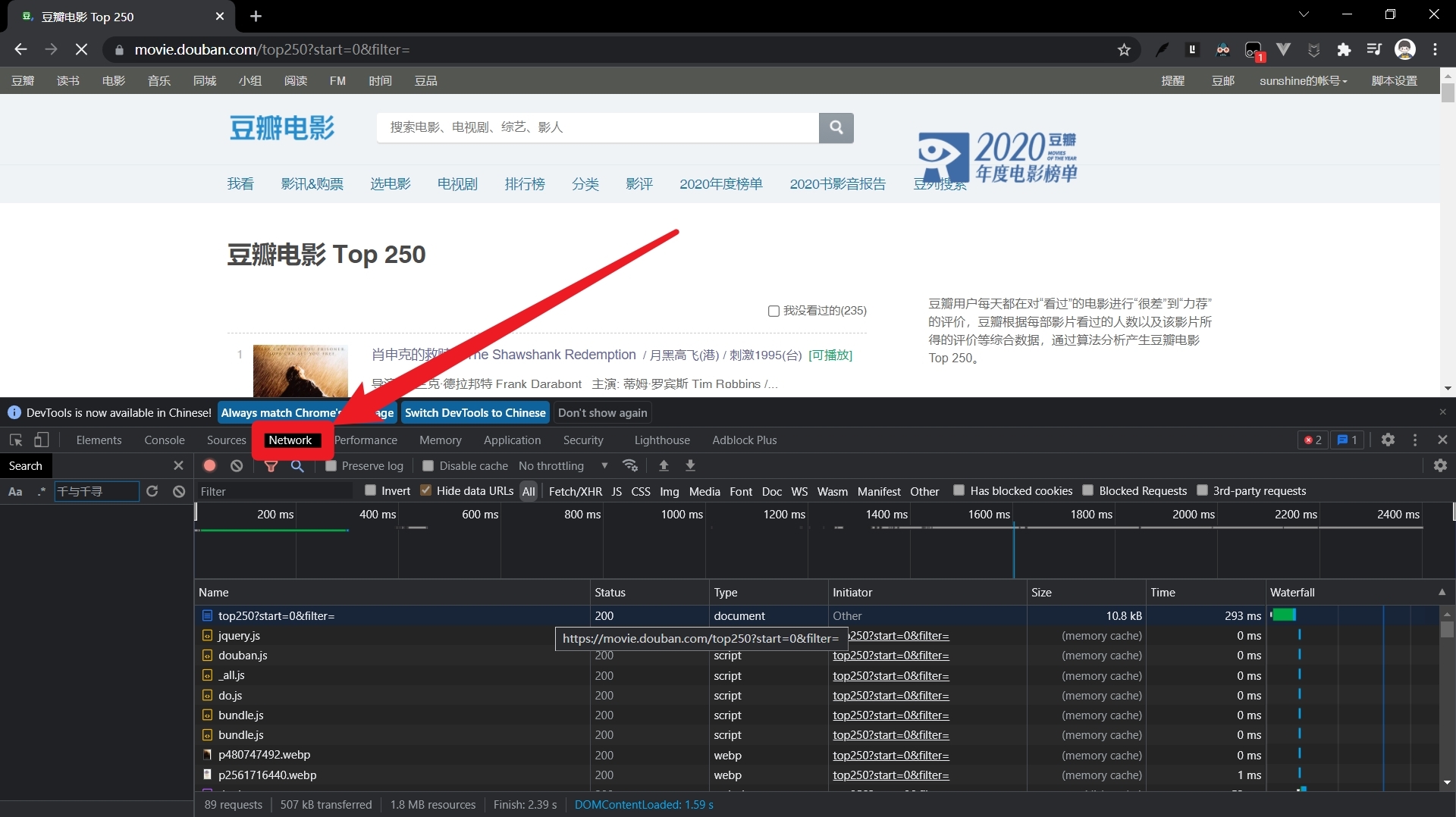
??我們是通過瀏覽器去獲取和決議資料的,那么爬蟲如何像瀏覽器一樣去請求資料呢?
??站在巨人的肩膀上,Python大牛們已經解決了這個問題,并把它封裝成了一個庫,這個庫便是requests庫,我們只需要呼叫庫里面封裝好的函式就可以模擬瀏覽器請求資料了,
??似憾訓需要講一個東西,就是請求頭 請求體和回應頭 回應體的問題,
??打開我們的開發者工具,點擊一條資料,選擇headers選項卡,我們便可以看到此次請求的請求頭,其中包括我們請求的URL 請求方法 UA標識 請求引數等等
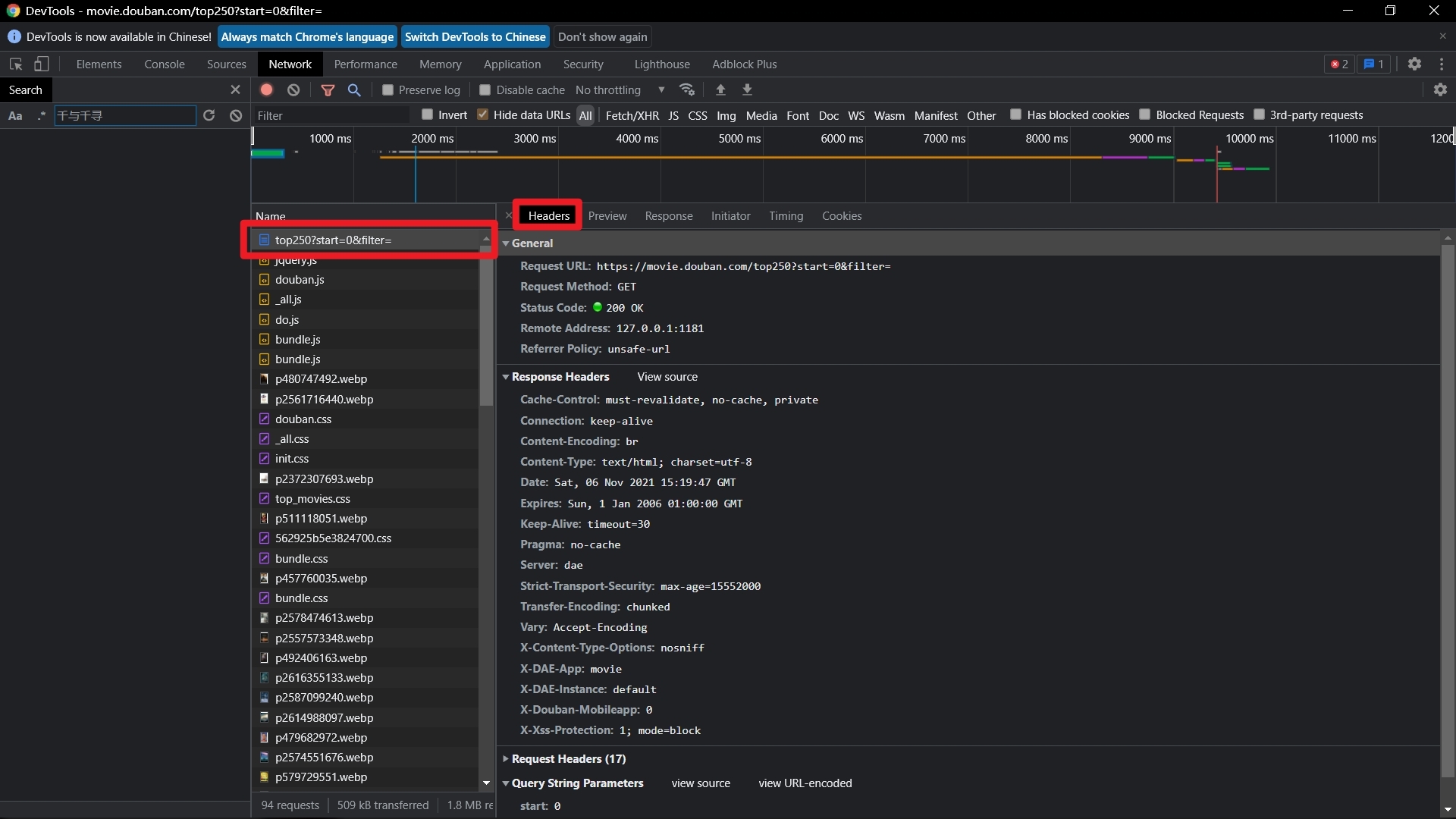
??包裹是有身份的,就像我們收到的快遞一樣,資料包也是如此,我們需要知道這個資料是誰發送的,要干嘛,所以我們需要請求頭 請求體這樣一個東西,
??一些網站會設定反爬蟲機制,如果服務器發現請求是python發送的,便不會正常回應,所以我們需要偽裝一下身份,
??解決方法就是利用請求頭進行UA偽裝
# 首先確定URL
url = 'https://movie.douban.com/top250'
# UA偽裝
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
# 發起請求
response = requests.get(url, headers=headers)
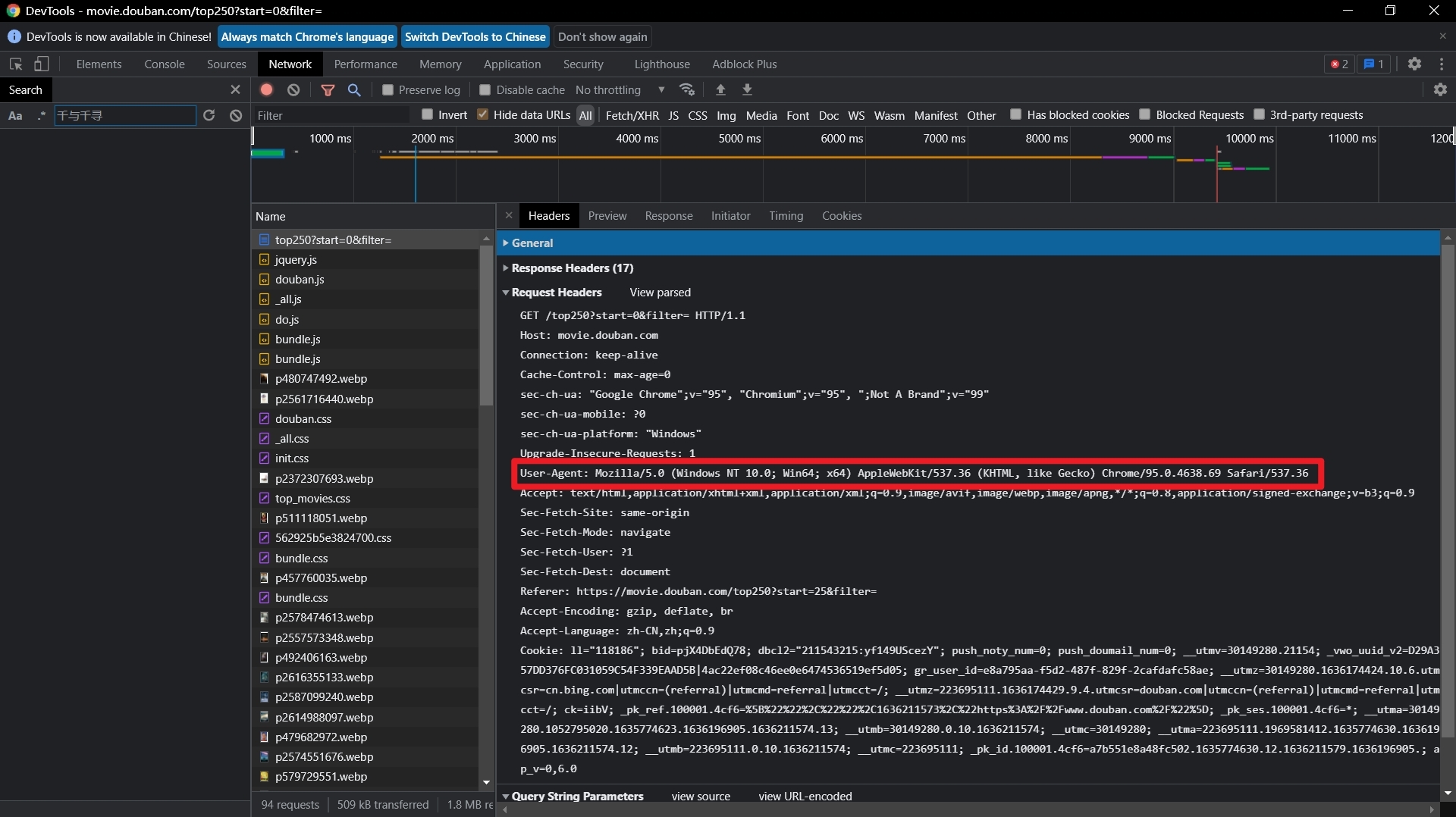
??如何查看自己電腦的UA表示呢?打開開發者工具,找到我們headers選項卡,展開第三條資料即可看到我們電腦的UA
1.4、獲得回應
??如果程式正常運行,便會發送URL對應的資源檔案,我們可以列印一下他的回應內容,
print(response.text)
??螢屏應該會列印一大堆HTML文本,我們的資料就存放在里面,
1.5、資料決議
??我們成功獲取了HTML檔案,我們需要的資料就存放在里面,但是如何過濾掉我們不需要的東西呢?
?當米開朗琪羅被問及如何完成《大衛》這樣匠心的雕刻作品時,他有一段著名的回答: 很簡單,你需要用錘子把石頭上不像大衛的地方敲掉就行了,
??再次站在前人的肩膀上,BeautifulSoup庫閃亮出場,
??在使用BeautifulSoup庫之前,我們應該很清楚的知道我們需要的資料存放在什么位置,
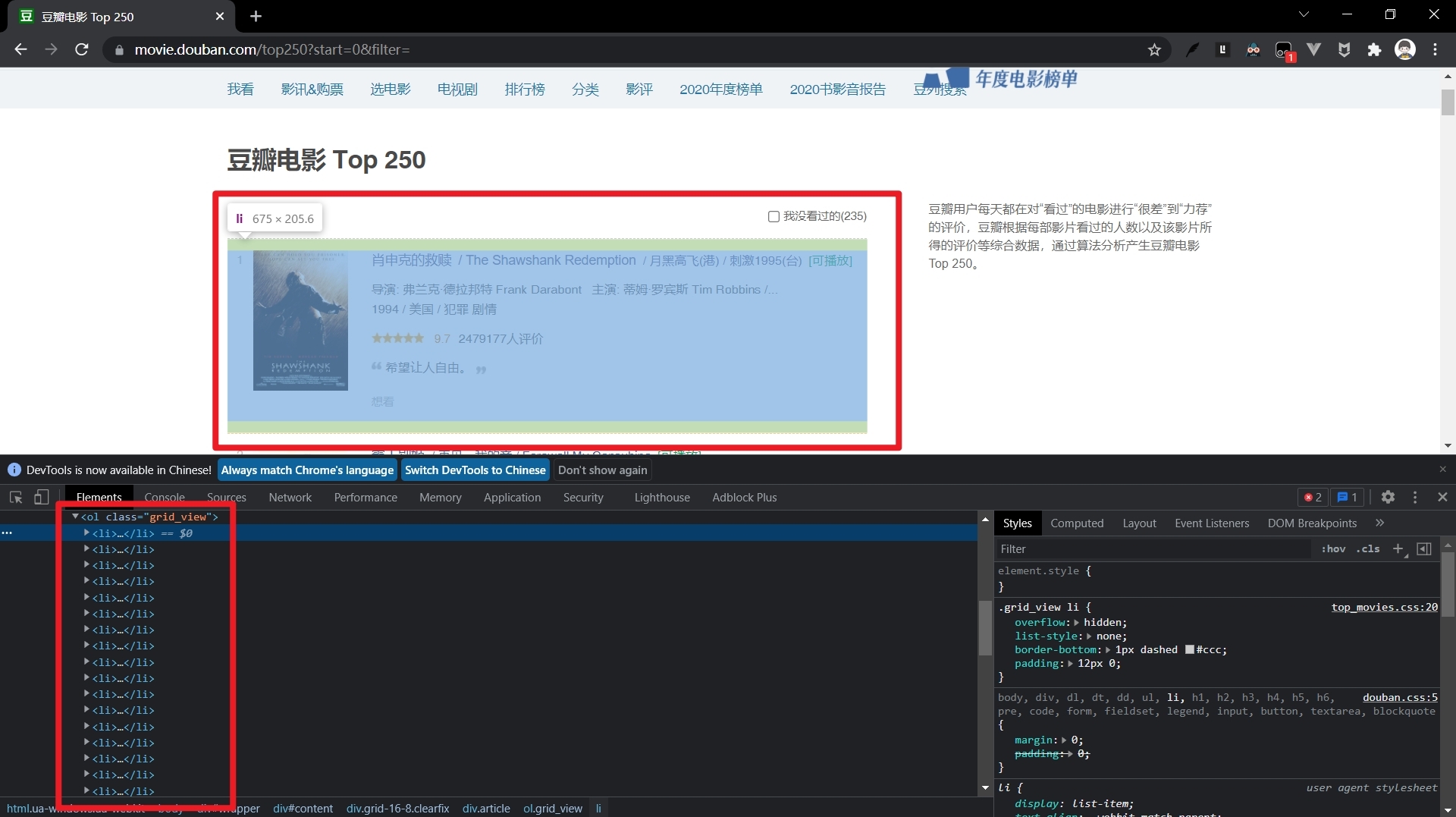
??很顯然,我們需要的資料存放在一個ol有序串列里,每條資料的便是一個串列項li,每個li標簽又長什么樣子呢?
??因為豆瓣后臺源代碼有點亂,我們把它復制到vscode里格式化一下再看,
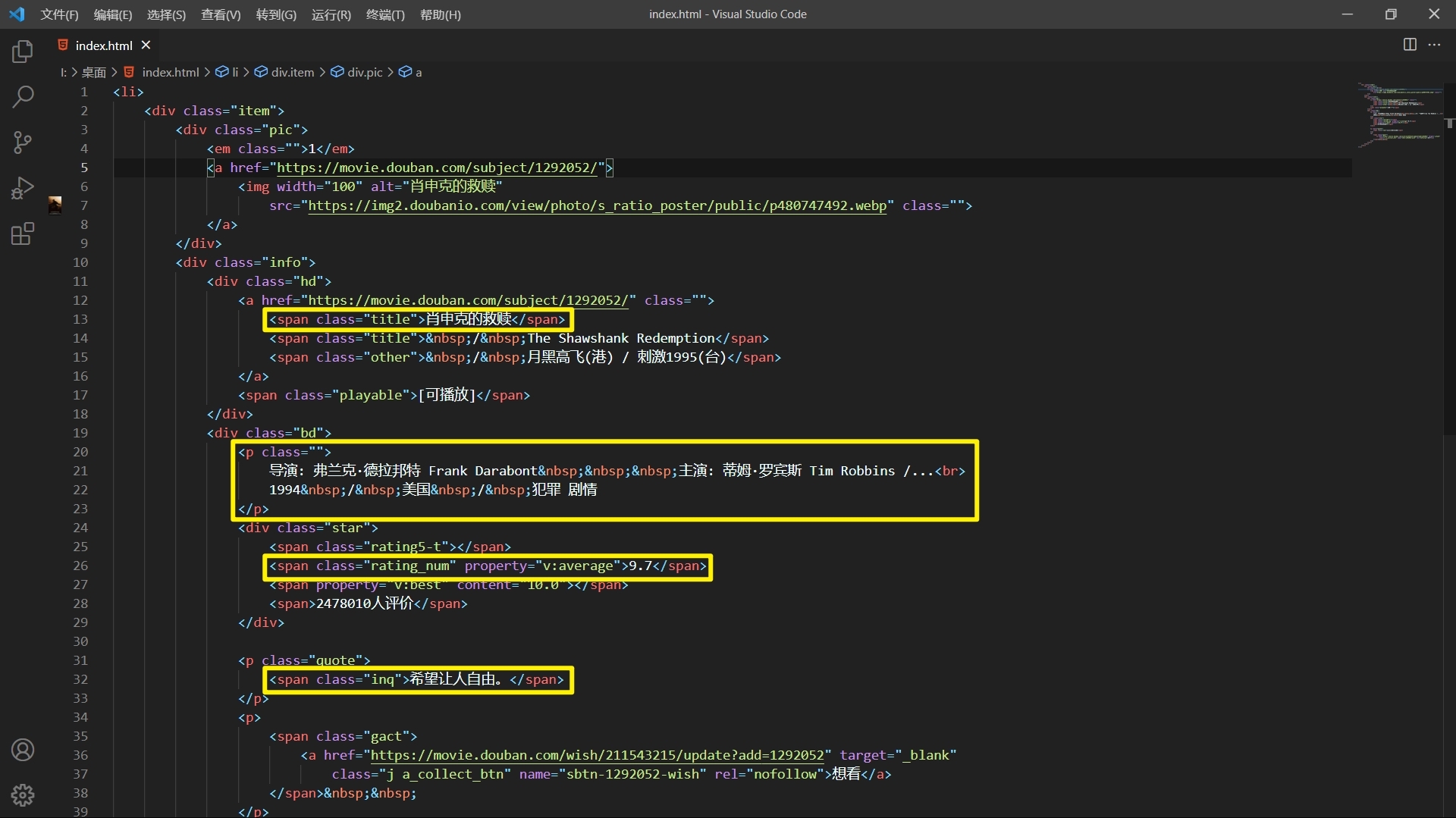
??我們需要的資料存放的位置就更加明顯了,好了,現在我們可以喝一碗美味的湯了(BeautifulSoup)
??先將我們獲取的HTML文本封裝成BeautifulSoup物件,物件里包含了很多屬性和方法,方便我們查找和獲取我們需要的資料,
# print(response.text)
html = response.text
# 創建BeautifulSoup物件,方便決議
soup = BeautifulSoup(html, 'lxml')
??這里我們首先獲取所有的li標簽,然后遍歷all_li 獲得每個li里的資料,在進行決議就可以了,
# 找出所有的li標簽
all_li = soup.find('ol', {'class': 'grid_view'}).find_all('li')
??我們創建一個空串列,將以后獲得得每條資料,都存放在里面,
datas = []
??我們通過上面的分析發現,影片名稱存放在下面這一小塊,
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救贖</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飛(港) / 刺激1995(臺)</span>
</a>
<span class="playable">[可播放]</span>
</div>
??其對應的決議便是name = item.find('span', {'class': 'title'}).text
??影片得分,存放在下面這一小塊,
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2478010人評價</span>
</div>
??其對應的決議便是name = item.find('span', {'class': 'title'}).text
??影片語錄存放在下面這一小塊,
<p class="quote">
<span class="inq">希望讓人自由,</span>
</p>
??其對應的決議便是quote = item.find('span', {'class': "inq"}).text
??其他內容都在這里面,
<p class="">
導演: 弗蘭克·德拉邦特 Frank Darabont 主演: 蒂姆·羅賓斯 Tim Robbins /...<br>
1994 / 美國 / 犯罪 劇情
</p>
??有些同學可能會發現,如果我們依舊按照上面的方式去決議,我們只能獲得p標簽里面的內容,沒法把導演哇,主演哇,等等分離出來,emmm,怎么辦呢?
??魔法終究可以被魔法打敗,我們有最強的字串處理工具,就是正則運算式,在使用之前,我們應該先參考先匯入此模塊,
??首先我們獲取的p標簽里的內容,它長下面這個樣子,
導演: 弗蘭克·德拉邦特 Frank Darabont 主演: 蒂姆·羅賓斯 Tim Robbins /...
1994 / 美國 / 犯罪 劇情
??其對應的決議便是result = re.findall('^.*?\u5bfc\u6f14:\s(.*?)\s.*?\u4e3b\u6f14:\s(.*?)\s.*?(\d{4})\s.*?([\u4e00-\u9fa5].*)\xa0.*?\u002f.*?([\u4e00-\u9fa5].*?)\s\s.*$',info_contents, re.S)
??這里關于正則運算式就不多說了,有興趣的同學可以研究研究,
計算機科學領域有一個笑話,如果你有一個問題打算用正則運算式來解決,那么就是兩個問題了,
??于是,程式就變成下面這樣了,
for item in all_li:
# 提取影片名稱(只提取了中文名稱)
name = item.find('span', {'class': 'title'}).text
# 提取影片評分
score = item.find('span', {'property': 'v:average'}).text
# 提取影片經典語錄
quote = item.find('span', {'class': "inq"}).text
# 下面提取影片資訊部分
info = item.find_all('p', {'class': ''})
# print(info.text)
# 回傳的是一個串列,串列里是一個元組
# print(info[0].text)
info_contents = info[0].text
# 分割影片資訊,提取影片 導演 || 主演 || 上映年份 || 國家/地區 || 型別
result = re.findall(
'^.*?\u5bfc\u6f14:\s(.*?)\s.*?\u4e3b\u6f14:\s(.*?)\s.*?(\d{4})\s.*?([\u4e00-\u9fa5].*)\xa0.*?\u002f.*?([\u4e00-\u9fa5].*?)\s\s.*$',
info_contents, re.S)
??接著我們把資料以字典的方式存放到串列里,
# 把資料按找字典的格式存放到串列里
datas.append({
'片名': name,
'年份': result[0][2],
'評分': score,
'導演': result[0][0],
'主演': result[0][1],
'型別': result[0][4],
'國家/地區': result[0][3],
'經典臺詞': quote
})
??OK,這樣其實我們就把單張的豆瓣影片資料爬取完成了!
1.6、寫入檔案
??寫入檔案用的是強大的pandas庫,這里需要注意下編碼格式,否則打開的可能是亂碼,
df = pd.DataFrame(datas)
df.to_csv("豆瓣電影.csv", index=False, header=True, encoding='utf_8_sig')
2、我是如何“放棄”爬取多頁資料的
??接下來我們要做的問題就是多頁爬取了,單頁爬取對應的是一個URL,多頁爬取對應的當然就是多個URL了
??emmm,不太嚴格,嚴格來說應該是我們每次請求的URL附加的引數變了,我們找到每次請求附加的引數變化規律就可以了,
??第一頁對應的URL:https://movie.douban.com/top250?start=0&filter=
??第二頁對應的URL:https://movie.douban.com/top250?start=25&filter=
??…
??第十頁對應的URL:https://movie.douban.com/top250?start=225&filter=
??很簡單就發現了對吧,就是start引數的值變了,于是我們可以這樣構造URL
url = 'https://movie.douban.com/top250?start=' + str(k * 25)
??用for回圈遍歷就好了,(當然還要注意data=[]要放在最外面,要不然獲取每頁資料時,data就被清空了)
for k in range(10):
print("正在抓取第{}頁資料...".format(k+1))
url = 'https://movie.douban.com/top250?start=' + str(k * 25)
......再把之前的代碼加上去就可以了,
??大功告成!!!
??可是,真的這樣么,我太天真了,現實給我來了當頭一棒,
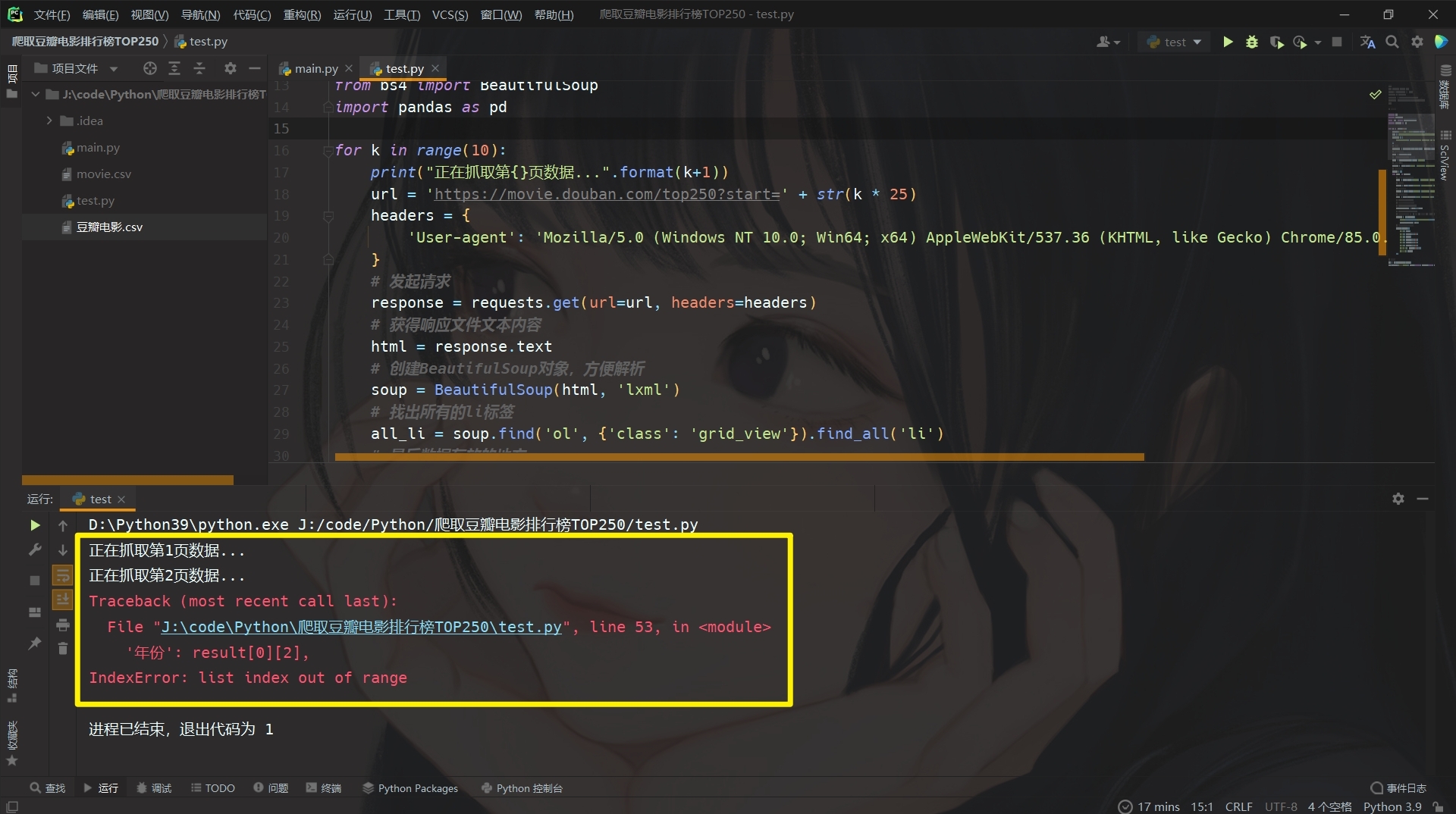
??第二頁資料就報錯了,沒有result[0][2]條資料,也就是年份,emmm,其實不是年份,是因為我們寫的正則運算式沒有捕捉到主演資訊,所以串列索引超了,仔細查找下問題,看下圖!
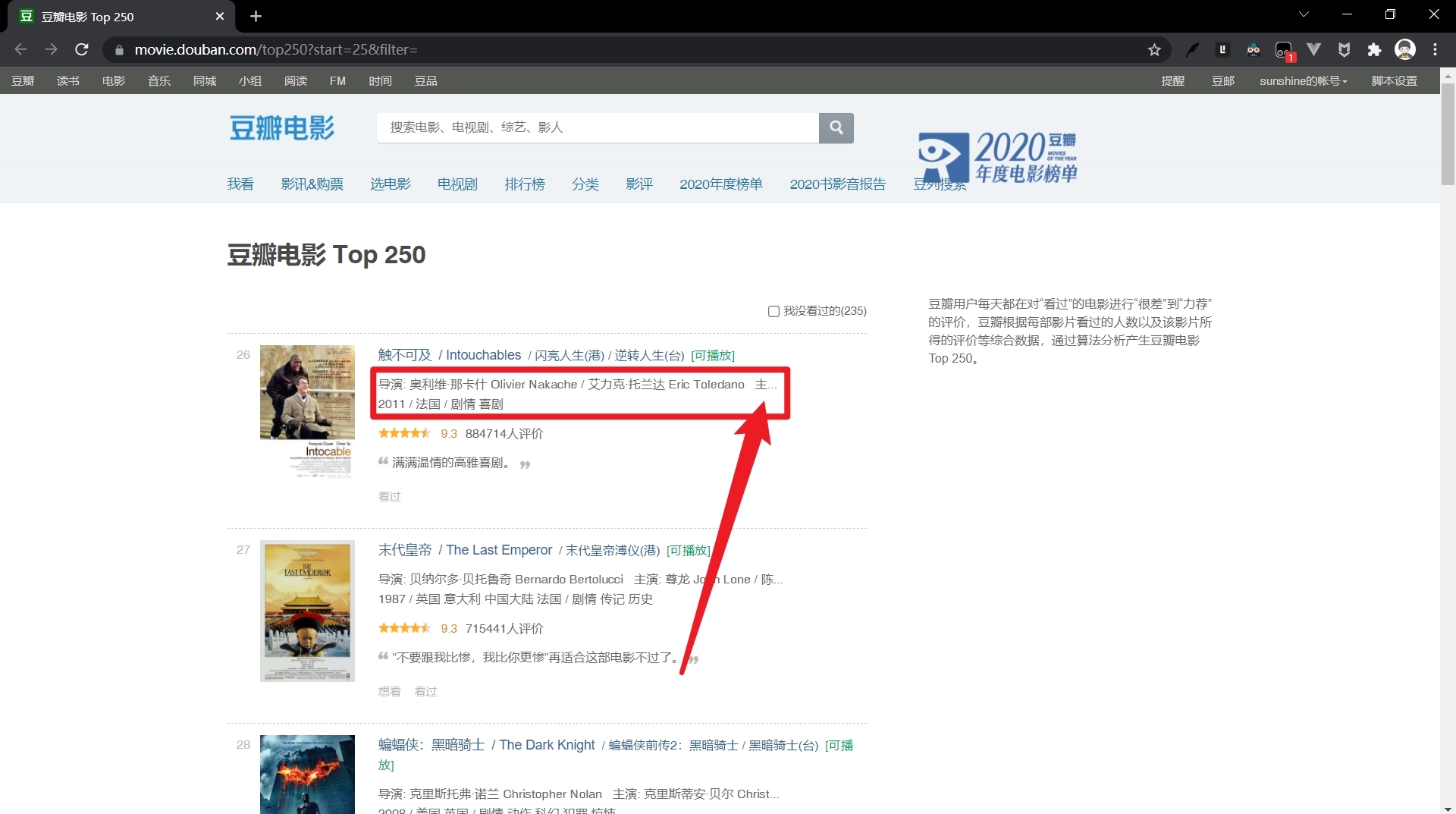
??好吧,我確實忽略這個問題了,因為這個top榜主要是簡介,字數什么的有限制,并不能完成主演等等詳細資料的爬取任務,而且我們也沒有去寫例外處理,
??仔細分析后,網頁內容不只這一條不符合規范,如果要加入例外處理的話,需要加入很多,況且資料也不全,所以我放棄爬取多頁了???
3、我是如何完成爬取多頁資料的
??在參考了其他同類的爬蟲文章后,我發現,top 250 頁面只是電影簡介,詳情都在點開電影鏈接之后,
??比如,我們打開《肖申克的救贖》這部電影,該電影的所有資訊都會按規范的格式展現在了我們的面前,
??我們再寫一個爬蟲,爬取每個電影的鏈接,然后打開電影詳情鏈接,去決議詳情文本就可以了,

??具體代碼如下,這個我就不做具體分析了,思路和上面差不多,最復雜的就是決議資料和資料清洗那里,需要一點點嘗試,
"""
-*- coding: utf-8 -*-
@Time : 2021/11/7 下午 4:25
@Author : SunGuoqi
@Website : https://sunguoqi.com
@Github: https://github.com/sun0225SUN
"""
import re
import time
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 資料存放在串列里
datas = []
# 遍歷十頁資料
for k in range(10):
print("正在抓取第{}頁資料...".format(k + 1))
url = 'https://movie.douban.com/top250?start=' + str(k * 25)
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
# 查找電影鏈接
lists = soup.find_all('div', {'class': 'hd'})
# 遍歷每條電影鏈接
for item in lists:
href = item.a['href']
# 休息一下,防止被封
time.sleep(0.5)
# 請求每條電影,獲得詳細資訊
response = requests.get(href, headers=headers)
# 把獲取好的電影資料打包成BeautifulSoup物件
movie_soup = BeautifulSoup(response.text, 'lxml')
# 決議每條電影資料
# 片名
name = movie_soup.find('span', {'property': 'v:itemreviewed'}).text.split(' ')[0]
# 上映年份
year = movie_soup.find('span', {'class': 'year'}).text.replace('(', '').replace(')', '')
# 評分
score = movie_soup.find('strong', {'property': 'v:average'}).text
# 評價人數
votes = movie_soup.find('span', {'property': 'v:votes'}).text
infos = movie_soup.find('div', {'id': 'info'}).text.split('\n')[1:11]
# infos回傳的是一個串列,我們只需要索引提取就好了
# 導演
director = infos[0].split(': ')[1]
# 編劇
scriptwriter = infos[1].split(': ')[1]
# 主演
actor = infos[2].split(': ')[1]
# 型別
filmtype = infos[3].split(': ')[1]
# 國家/地區
area = infos[4].split(': ')[1]
# 資料清洗一下
if '.' in area:
area = infos[5].split(': ')[1].split(' / ')[0]
# 語言
language = infos[6].split(': ')[1].split(' / ')[0]
else:
area = infos[4].split(': ')[1].split(' / ')[0]
# 語言
language = infos[5].split(': ')[1].split(' / ')[0]
if '大陸' in area or '香港' in area or '臺灣' in area:
area = '中國'
if '戛納' in area:
area = '法國'
# 時長
times0 = movie_soup.find(attrs={'property': 'v:runtime'}).text
times = re.findall('\d+', times0)[0]
# 將資料寫入串列
datas.append({
'片名': name,
'上映年份': year,
'評分': score,
'評價人數': votes,
'導演': director,
'編劇': scriptwriter,
'主演': actor,
'型別': filmtype,
'國家/地區': area,
'語言': language,
'時長(分鐘)': times
})
print("電影《{0}》已爬取完成...".format(name))
# 寫入到檔案
df = pd.DataFrame(datas)
df.to_csv("top250.csv", index=False, header=True, encoding='utf_8_sig')
??infos那里直接提取這個div里面所有的子孫節點的文本,回傳的是一個串列,像下面這樣,然后用索引去提取,再清洗下就可以存盤到字典串列里了,還有要注意豆瓣反爬機制,不要請求過快,time.sleep(0.5)
['',
'導演: 弗蘭克·德拉邦特',
'編劇: 弗蘭克·德拉邦特 / 斯蒂芬·金',
'主演: 蒂姆·羅賓斯 / 摩根·弗里曼 / 鮑勃·岡頓 / 威廉姆·賽德勒 / 克蘭西·布朗 / 吉爾·貝羅斯 / 馬克·羅斯頓 / 詹姆斯·惠特摩 / 杰弗里·德曼 / 拉里·布蘭登伯格 / 尼爾·吉恩托利 / 布賴恩·利比 / 大衛·普羅瓦爾 / 約瑟夫·勞格諾 / 祖德·塞克利拉 / 保羅·麥克蘭尼 / 芮妮·布萊恩 / 阿方索·弗里曼 / V·J·福斯特 / 弗蘭克·梅德拉諾 / 馬克·邁爾斯 / 尼爾·薩默斯 / 耐德·巴拉米 / 布賴恩·戴拉特 / 唐·麥克馬納斯',
'型別: 劇情 / 犯罪',
'制片國家/地區: 美國',
'語言: 英語',
'上映日期: 1994-09-10(多倫多電影節) / 1994-10-14(美國)',
'片長: 142分鐘',
'又名: 月黑高飛(港) / 刺激1995(臺) / 地獄諾言 / 鐵窗歲月 / 消香克的救贖',
'IMDb: tt0111161',
'']
??因為我們這次請求的鏈接,決議的文本確實比較多,所以我們需要稍等一會才可以拿到我們的資料了,不妨去喝杯咖啡~
六、資料可視化分析 Echarts
??關于資料爬取我們就完成了,接下來我們要做的就是可視化分析,
??可視化分析這塊我還沒有系統學習,以下內容是借鑒其他博主的,
??參考鏈接:
https://blog.csdn.net/weixin_42512684/article/details/90708037
https://blog.csdn.net/weixin_42152811/article/details/115366846
1、匯入pyecharts模塊
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
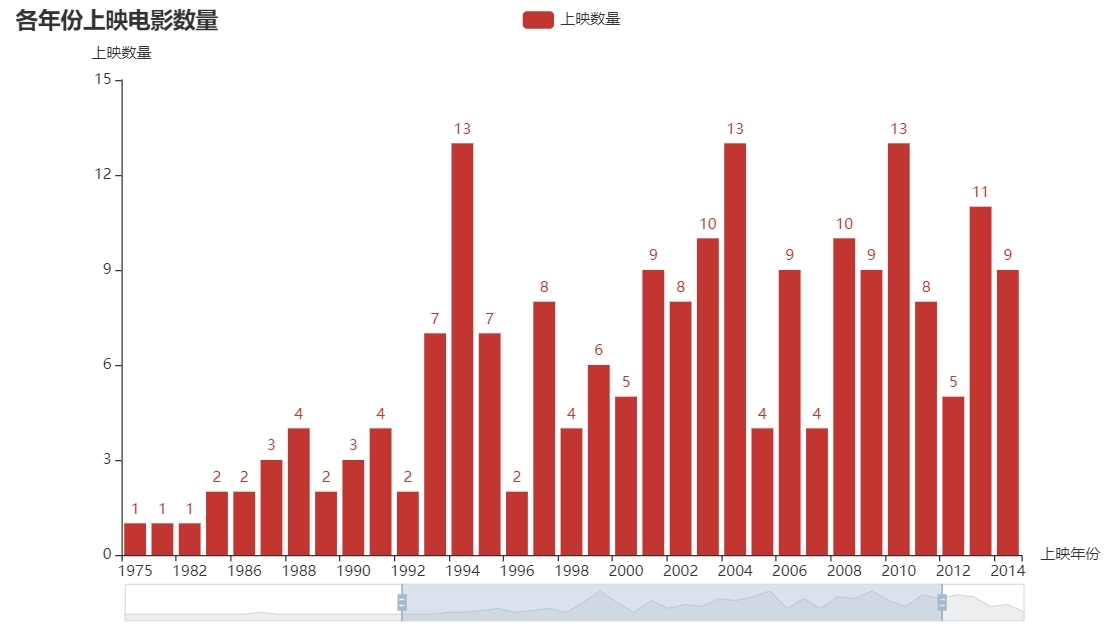
2、各地區上映電影數量前十
data = pd.read_csv('top250.csv')
year_counts = data['上映年份'].value_counts()
year_counts.columns = ['上映年份', '數量']
year_counts = year_counts.sort_index()
c = (
Bar()
.add_xaxis(list(year_counts.index))
.add_yaxis('上映數量', year_counts.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='各年份上映電影數量'),
yaxis_opts=opts.AxisOpts(name='上映數量'),
xaxis_opts=opts.AxisOpts(name='上映年份'),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_='inside')], )
.render('各年份上映電影數量.html')
)
3、電影評價人數前二十
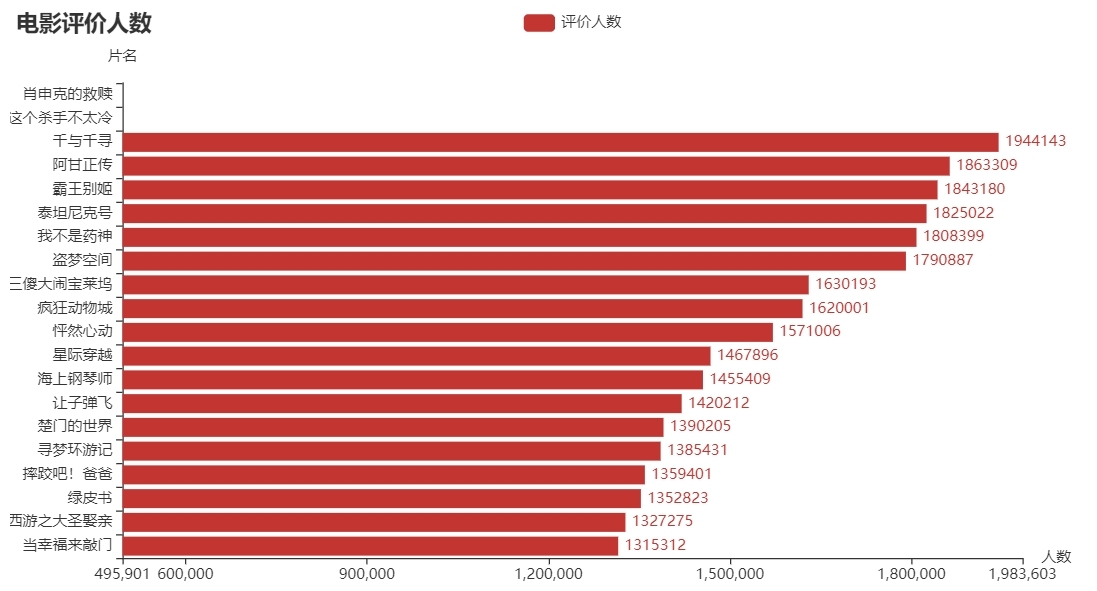
data = pd.read_csv('top250.csv')
df = data.sort_values(by='評價人數', ascending=True)
c = (
Bar()
.add_xaxis(df['片名'].values.tolist()[-20:])
.add_yaxis('評價人數', df['評價人數'].values.tolist()[-20:])
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title='電影評價人數'),
yaxis_opts=opts.AxisOpts(name='片名'),
xaxis_opts=opts.AxisOpts(name='人數'),
datazoom_opts=opts.DataZoomOpts(type_='inside'),
)
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.render('電影評價人數前二十.html')
)
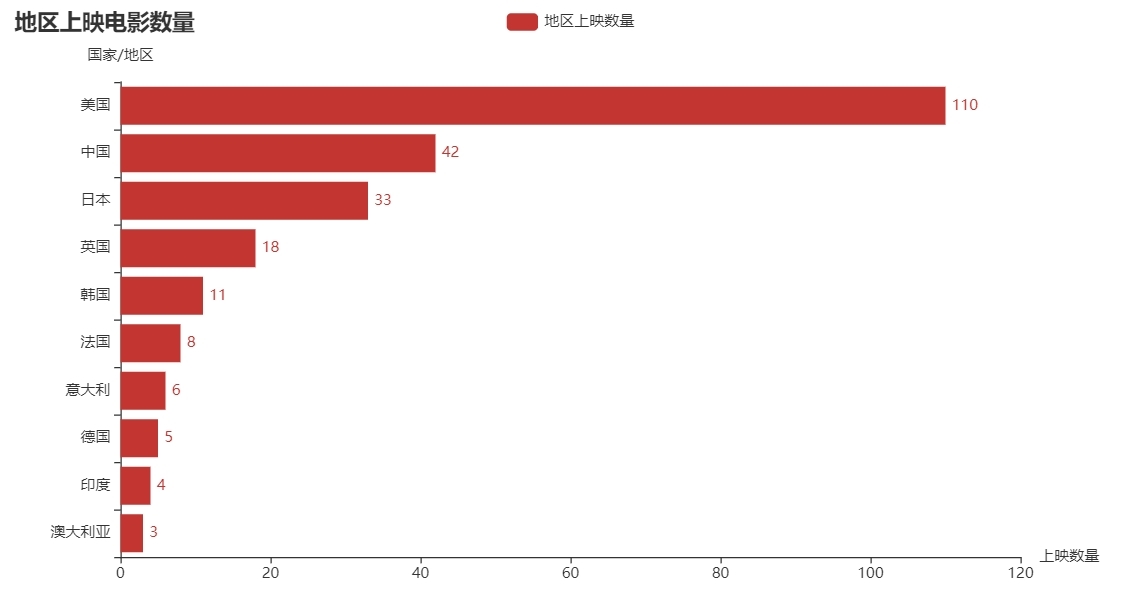
4、各年份上映電影數量
data = pd.read_csv('top250.csv')
country_counts = data['國家/地區'].value_counts()
country_counts.columns = ['國家/地區', '數量']
country_counts = country_counts.sort_values(ascending=True)
c = (
Bar()
.add_xaxis(list(country_counts.index)[-10:])
.add_yaxis('地區上映數量', country_counts.values.tolist()[-10:])
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title='地區上映電影數量'),
yaxis_opts=opts.AxisOpts(name='國家/地區'),
xaxis_opts=opts.AxisOpts(name='上映數量'),
)
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.render('各地區上映電影數量前十.html')
)
5、其他可視化分析實體
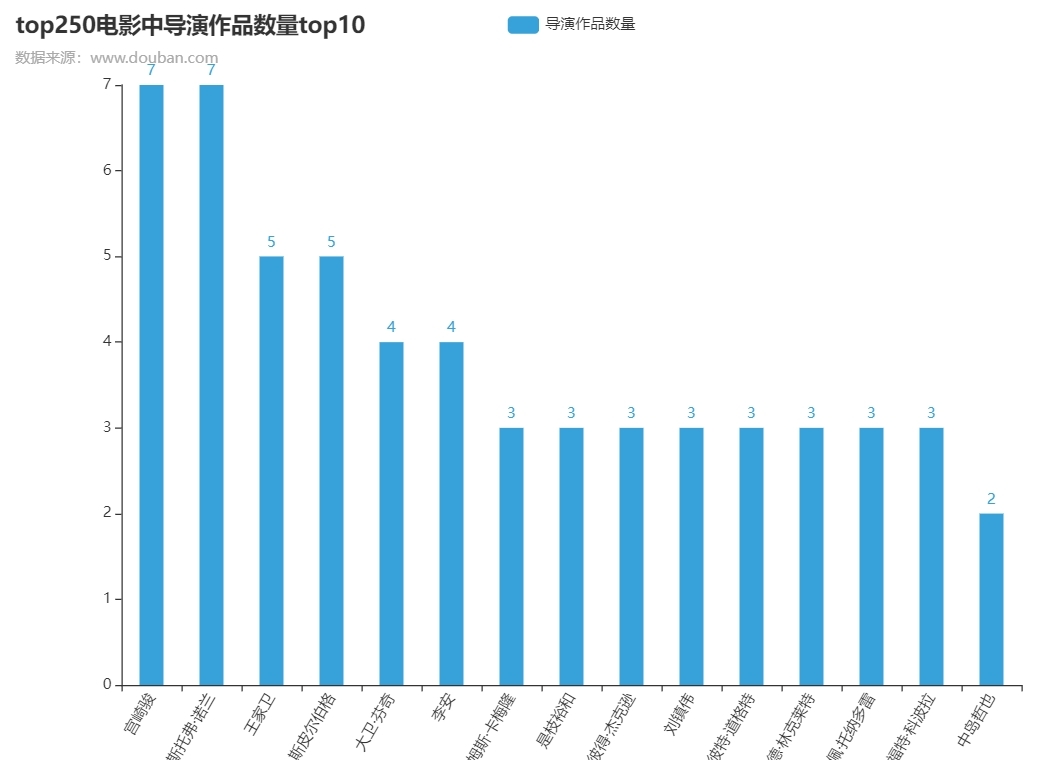
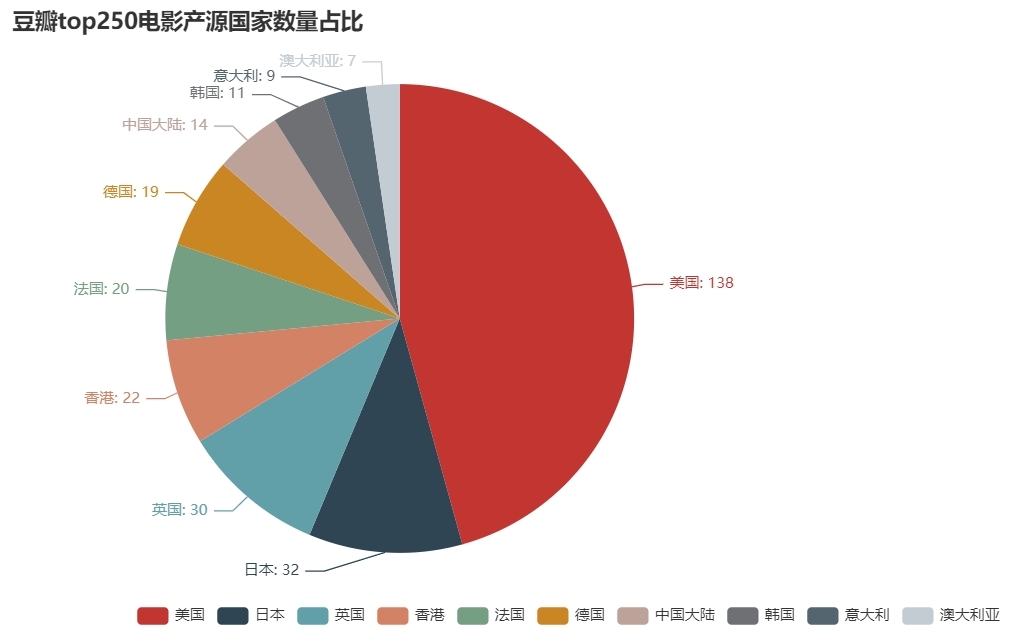
七、后記
??資料可視化還是很酷的,大家可以點進去網址查看,圖表是可以動態互動的,
??到此,本文就結束了!爬蟲代碼寫的確實比較爛,并沒有進行模塊化撰寫以及例外處理,僅供交流!
??歡迎關注小孫同學的個人公眾號【不負人間理想】,愿你我都可以不負人間理想,成為更好的自己!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/353408.html
標籤:python