凡爾賽文學火了,這種特殊的網路文體,常出現在朋友圈或微博,以波瀾不驚的口吻,假裝不經意地炫富、秀恩愛,
普通的炫耀,無非在社交網路發發跑車照片,或不經意露出名牌包包 logo,但凡爾賽文學還不這么直接,微博博主還專門制作過凡爾賽文學教學視頻,講解其三大精髓要素:

在豆瓣上,也有一個名叫凡爾賽學研習小組,組員們將凡爾賽定義為一種表演高級人生的精神,好了,進入主題,今天來快速爬取知乎里有關凡爾賽語錄有關的回答,開始,
1.爬取的網站
在知乎搜索凡爾賽語錄,第二個比較適合,就用這個,
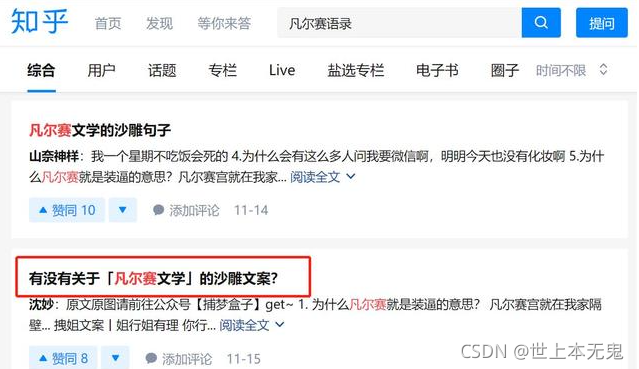
點進去后可以發現關于這個提問共有 393 個回答,
網址:https://www.zhihu.com/question/429548386/answer/1575062220

去掉 answer 以及后面的部分就是這個要爬取的問題網址,特別是后面的一串數字是問題 id:https://www.zhihu.com/question/429548386,作為知乎問題的唯一標識,
2.爬取問題有關的回答
研究一下上面的網址,我們發現需要爬取兩部分資料:
- 爬取的詳情,包括創建時間、關注人數、瀏覽量、問題描述等
- 爬取的回答,包括每個答主的用戶名、粉絲數等資訊,問題回答的具體內容、發布時間、評論數、點贊數等資訊
其中,這個問題詳情可以直接爬取上面的網址,通過 bs4 決議頁面內容拿到資料,而問題的回答則需要通過下面的鏈接,通過設定每頁的起始下標和頁面內容偏移量確定,有點類似于分頁內容的爬取,
def init_url(question_id, limit, offset):
base_url_start = "https://www.zhihu.com/api/v4/questions/"
base_url_end = "/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit={0}&offset={1}".format(limit, offset)
return base_url_start + question_id + base_url_end
設定每頁回答數 limit=20,offset 則可以是0、20、40…而 question_id 則是上面提到的網址后面的一串數字,這里是 429548386,邏輯想明白之后就是通過寫爬蟲獲取資料了,下面是完整的爬蟲代碼,運行的時候你只需要修改問題的 id 即可,
3.完整代碼
# 匯入相應的庫
import json
import re
import time
from datetime import datetime
from time import sleep
import pandas as pd
import numpy as np
import warnings
import requests
from bs4 import BeautifulSoup
import random
import warnings
warnings.filterwarnings('ignore')
def get_ua():
"""
在UA庫中隨機選擇一個UA
:return: 回傳一個庫中的隨機UA
"""
ua_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Opera/8.0 (Windows NT 5.1; U; en)",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13",
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Macintosh; U; IntelMac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
return random.choice(ua_list)
def filter_emoij(text):
"""
過濾emoij表情符
@param text:
@return:
"""
try:
co = re.compile(u'[\U00010000-\U0010ffff]')
except re.error:
co = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]')
text = co.sub('', text)
return text
def get_question_base_info(url):
"""
獲取問題的詳細描述
@param url:
@return:
"""
response = requests.get(url=url, headers={'User-Agent': get_ua()}, timeout=10)
"""獲取資料并決議"""
soup = BeautifulSoup(response.text, 'lxml')
# 問題標題
title = soup.find("h1", {"class": "QuestionHeader-title"}).text
# 具體問題
question = ''
try:
question = soup.find("div", {"class": "QuestionRichText--collapsed"}).text.replace('\u200b', '')
except Exception as e:
print(e)
# 關注者
follower = int(soup.find_all("strong", {"class": "NumberBoard-itemValue"})[0].text.strip().replace(",", ""))
# 被瀏覽
watched = int(soup.find_all("strong", {"class": "NumberBoard-itemValue"})[1].text.strip().replace(",", ""))
# 問題回答次數
answer_str = soup.find_all("h4", {"class": "List-headerText"})[0].span.text.strip()
# 抽取xxx 個回答中的數字:【正則】數字出現次數>=0
answer_count = int(re.findall('\d*', answer_str)[0])
# 問題標簽
tag_list = []
tags = soup.find_all("div", {"class": "QuestionTopic"})
for tag in tags:
tag_list.append(tag.text)
return title, question, follower, watched, answer_count, tag_list
def init_url(question_id, limit, offset):
"""
構造每一頁訪問的url
@param question_id:
@param limit:
@param offset:
@return:
"""
base_url_start = "https://www.zhihu.com/api/v4/questions/"
base_url_end = "/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed" \
"%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by" \
"%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count" \
"%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info" \
"%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting" \
"%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B" \
"%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics" \
"&limit={0}&offset={1}".format(limit, offset)
return base_url_start + question_id + base_url_end
def get_time_str(timestamp):
"""
將時間戳轉換為標準日期字符
@param timestamp:
@return:
"""
datetime_str = ''
try:
# 時間戳timestamp 轉datetime時間格式
datetime_time = datetime.fromtimestamp(timestamp)
# datetime時間格式轉為日期字串
datetime_str = datetime_time.strftime("%Y-%m-%d %H:%M:%S")
except Exception as e:
print(e)
print("日期轉換錯誤")
return datetime_str
def get_answer_info(url, index):
"""
決議問題回答
@param url:
@param index:
@return:
"""
response = requests.get(url=url, headers={'User-Agent': get_ua()}, timeout=10)
text = response.text.replace('\u200b', '')
per_answer_list = []
try:
question_json = json.loads(text)
"""獲取當前頁的回答資料"""
print("爬取第{0}頁回答串列,當前頁獲取到{1}個回答".format(index + 1, len(question_json["data"])))
for data in question_json["data"]:
"""問題的相關資訊"""
# 問題的問題型別、id、提問型別、創建時間、修改時間
question_type = data["question"]['type']
question_id = data["question"]['id']
question_question_type = data["question"]['question_type']
question_created = get_time_str(data["question"]['created'])
question_updated_time = get_time_str(data["question"]['updated_time'])
"""答主的相關資訊"""
# 答主的用戶名、簽名、性別、粉絲數
author_name = data["author"]['name']
author_headline = data["author"]['headline']
author_gender = data["author"]['gender']
author_follower_count = data["author"]['follower_count']
"""回答的相關資訊"""
# 問題回答id、創建時間、更新時間、贊同數、評論數、具體內容
id = data['id']
created_time = get_time_str(data["created_time"])
updated_time = get_time_str(data["updated_time"])
voteup_count = data["voteup_count"]
comment_count = data["comment_count"]
content = data["content"]
per_answer_list.append([question_type, question_id, question_question_type, question_created,
question_updated_time, author_name, author_headline, author_gender,
author_follower_count, id, created_time, updated_time, voteup_count, comment_count,
content
])
except:
print("Json格式校驗錯誤")
finally:
answer_column = ['問題型別', '問題id', '問題提問型別', '問題創建時間', '問題更新時間',
'答主用戶名', '答主簽名', '答主性別', '答主粉絲數',
'答案id', '答案創建時間', '答案更新時間', '答案贊同數', '答案評論數', '答案具體內容']
per_answer_data = pd.DataFrame(per_answer_list, columns=answer_column)
return per_answer_data
if __name__ == '__main__':
# question_id = '424516487'
question_id = '429548386'
url = "https://www.zhihu.com/question/" + question_id
"""獲取問題的詳細描述"""
title, question, follower, watched, answer_count, tag_list = get_question_base_info(url)
print("問題url:"+ url)
print("問題標題:" + title)
print("問題描述:" + question)
print("該問題被定義的標簽為:" + '、'.join(tag_list))
print("該問題關注人數:{0},已經被 {1} 人瀏覽過".format(follower, watched))
print("截止 {},該問題有 {} 個回答".format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), answer_count))
"""獲取問題的回答資料"""
# 構造url
limit, offset = 20, 0
page_cnt = int(answer_count/limit) + 1
answer_data = pd.DataFrame()
for page_index in range(page_cnt):
answer_url = init_url(question_id, limit, offset+page_index*limit)
# 獲取資料
data_per_page = get_answer_info(answer_url, page_index)
answer_data = answer_data.append(data_per_page)
sleep(3)
print("\n爬取完成,資料已保存!!")
answer_data.to_csv('凡爾賽沙雕語錄_{0}.csv'.format(question_id), encoding='utf-8', index=False)

4.結果
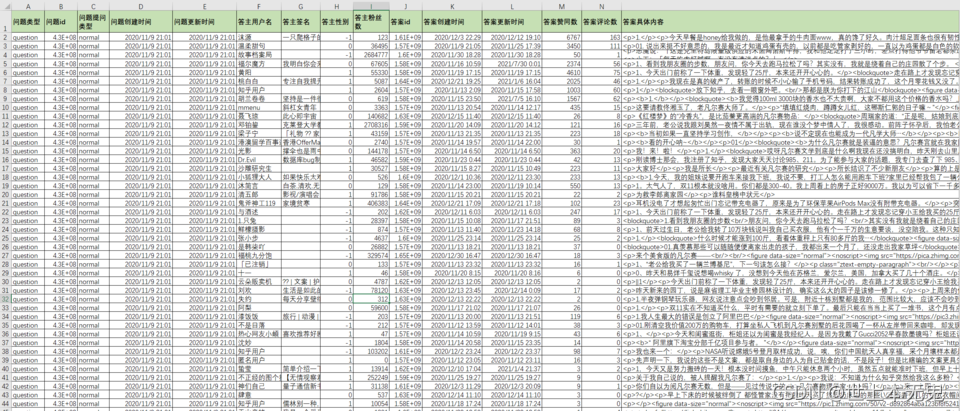
一共爬取到 393 個答案,需要注意一下,最后保存的檔案格式為 UTF-8,讀取亂碼的同學請先檢查格式是否一致,
爬取的結果部分截圖如下:
感謝看到這里,更多Python精彩內容可以關注我看我主頁,你們的三連(點贊,收藏,評論)是我持續更新下去的動力,感謝,
點擊領取🎁 Q群號: 675240729(純技術交流和資源共享)以自助拿走,
①行業咨詢、專業解答
②Python開發環境安裝教程
③400集自學視頻
④軟體開發常用詞匯
⑤最新學習路線圖
⑥3000多本Python電子書
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/354643.html
標籤:python