點擊獲取福利
15張學習路線導圖
10G學習資料
100本計算機書籍
點贊再看,養成習慣,微信搜索【一條coding】關注這個在互聯網摸爬滾打的程式員,
本文收錄于技術專家修煉,里面有我的學習路線、系列文章、面試題庫、自學資料、電子書等,歡迎star??
哈嘍,大家好,我是一條~
算下來,已有半月之久沒寫文章,都是在吃老本,再不寫估計就要廢了,下班回來告訴自己就算通宵也要把這篇寫完,
早上出門看著路邊的積雪,不禁感到凜冬已至,咦!好熟悉,這不是王昭君的臺詞嗎,

那索性今天就和大家聊聊雪花演算法,一局王者復活的時間就能學會,(死的次數有點多)
本文大綱
分布式ID
聊之前先說一下什么是分布式ID,拋磚引玉,
假設現在有一個訂單系統被部署在了A、B兩個節點上,那么如何在這兩個節點上各自生成訂單ID,且ID值不能重復呢?
即在分布式系統中,如何在各個不同的服務器上產生唯一的ID值?
通常有以下三種方案:
- 利用資料庫的自增特性,不同節點直接使用相同資料庫的自增ID
- 使用UUID演算法產生ID值
- 使用雪花演算法產生ID值
雖然Java提供了對UUID的支持,使用UUID.randomUUID()即可,但是由于UUID是一串隨機的36位字串,由32個數字和字母混合的字串和4個“-”組成,長度過長且業務可讀性差,無法有序遞增,所以一般不用,更多使用的是雪花演算法,
由來
為什么叫雪花演算法?
雪花演算法的由來有兩種說法:
- 第一種:Twitter使用scala語言開源了一種分布式 id 生成演算法——SnowFlake演算法,被翻譯成了雪花演算法,
- 第二種:因為自然界中并不存在兩片完全一樣的雪花的,每一片雪花都擁有自己漂亮獨特的形狀、獨一無二,雪花演算法也表示生成的ID如雪花般獨一無二,(有同學問為什么不是樹葉,美團的叫樹葉——Leaf)
組成
雪花演算法生成的ID到底長啥樣?
雪花演算法生成的ID是一個64 bit的long型的數字且按時間趨勢遞增,大致由首位無效符、時間戳差值、機器編碼,序列號四部分組成,
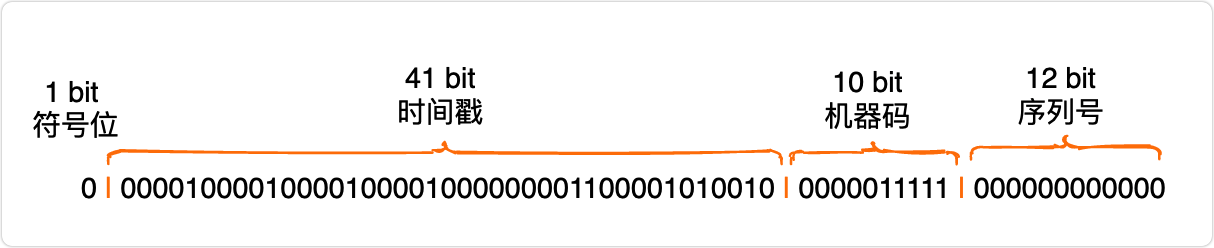
如圖:
- 首位無效符:第一個 bit 作為符號位,因為我們生成的都是正數,所以第一個 bit 統一都是 0,
- 時間戳:占用 41 bit ,精確到毫秒,41位最好可以表示
2^41-1毫秒,轉化成單位年為 69 年, - 機器編碼:占用10bit,其中高位 5 bit 是資料中心 ID,低位 5 bit 是作業節點 ID,最多可以容納 1024 個節點,
- 序列號:占用12bit,每個節點每毫秒0開始不斷累加,最多可以累加到4095,一共可以產生 4096 個ID,
代碼
Twitter官方給出的演算法實作是用Scala寫的,本文用Java實作,
原始碼地址
SnowFlake.java
/**
* 雪花演算法類
* 一條coding
*/
public class SnowFlake {
//本例將10位機器碼看成是“5位datacenterId+5位workerId”
private long workerId;
private long datacenterId;
//每毫秒生產的序列號之從0開始遞增;
private long sequence = 0L;
/*
1288834974657L是1970-01-01 00:00:00到2010年11月04日01:42:54所經過的毫秒數;
因為現在二十一世紀的某一時刻減去1288834974657L的值,正好在2^41內,
因此1288834974657L實際上就是為了讓時間戳正好在2^41內而湊出來的,
簡言之,1288834974657L(即1970-01-01 00:00:00),就是在計算時間戳時用到的“起始時間”,
*/
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
private long maxWorkerId = -1L ^ (-1L <<workerIdBits);
private long maxDatacenterId = -1L ^ (-1L <<datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L <<sequenceBits);
private long lastTimestamp = -1L;
public SnowFlake(long datacenterId, long workerId) {
if ((datacenterId >maxDatacenterId || datacenterId <0)
||(workerId >maxWorkerId || workerId <0)) {
throw new IllegalArgumentException("datacenterId/workerId值非法");
}
this.datacenterId = datacenterId;
this.workerId = workerId;
}
//通過SnowFlake生成id的核心演算法
public synchronized long nextId() {
//獲取計算id時刻的時間戳
long timestamp = System.currentTimeMillis();
if (timestamp <lastTimestamp) {
throw new RuntimeException("時間戳值非法");
}
//如果此次生成id的時間戳,與上次的時間戳相同,就通過機器碼和序列號區
//分id值(機器碼已通過構造方法傳入)
if (lastTimestamp == timestamp) {
/*
下一條陳述句的作用是:通過位運算保證sequence不會超出序列號所能容納的最大值,
例如,本程式產生的12位sequence值依次是:1、2、3、4、...、4094、4095
(4095是2的12次方的最大值,也是本sequence的最大值)
那么此時如果再增加一個sequence值(即sequence + 1),下條陳述句就會
使sequence恢復到0,
即如果sequence==0,就表示sequence已滿,
*/
sequence = (sequence + 1) &sequenceMask;
//如果sequence已滿,就無法再通過sequence區分id值;因此需要切換到
//下一個時間戳重新計算,
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
//如果此次生成id的時間戳,與上次的時間戳不同,就已經可以根據時間戳區分id值
sequence = 0L;
}
//更新最近一次生成id的時間戳
lastTimestamp = timestamp;
/*
假設此刻的值是(二進制表示):
41位時間戳的值是:00101011110101011101011101010101111101011
5位datacenterId(機器碼的前5位)的值是:01101
5位workerId(機器碼的后5位)的值是:11001
sequence的值是:01001
那么最終生成的id值,就需要:
1.將41位時間戳左移動22位(即移動到snowflake值中時間戳應該出現的位置);
2.將5位datacenterId向左移動17位,并將5位workerId向左移動12位
(即移動到snowflake值中機器碼應該出現的位置);
3.sequence本來就在最低位,因此不需要移動,
以下<<和|運算,實際就是將時間戳、機器碼和序列號移動到snowflake中相應的位置,
*/
return ((timestamp - twepoch) <<timestampLeftShift)
| (datacenterId <<datacenterIdShift) | (workerId <<workerIdShift)
| sequence;
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
/*
如果當前時刻的時間戳<=上一次生成id的時間戳,就重新生成當前時間,
即確保當前時刻的時間戳,與上一次的時間戳不會重復,
*/
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
}
TestSnowFlake.java
/**
* 測驗類
* 一條coding
*/
public class TestSnowFlake {
//測驗1秒能夠生成的id個數
public static void generateIdsInOneSecond() {
SnowFlake idWorker = new SnowFlake(1, 1);
long start = System.currentTimeMillis();
int i = 0;
for (; System.currentTimeMillis() - start <1000; i++) {
idWorker.nextId();
}
long end = System.currentTimeMillis();
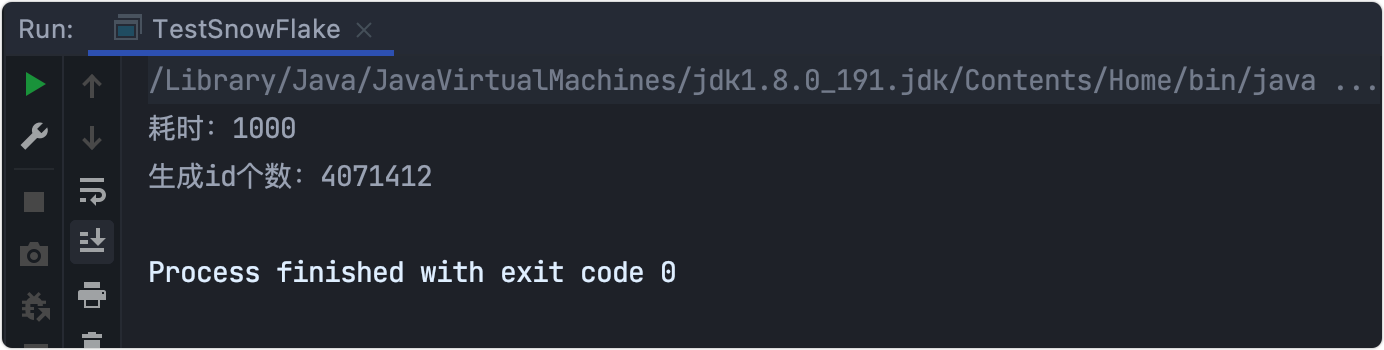
System.out.println("耗時:"+ (end - start));
System.out.println("生成id個數:"+ i);
}
public static void main(String[] args) {
generateIdsInOneSecond();
}
}
測驗結果
疑問
雪花演算法有缺點嗎?
- 雪花演算法生成ID一定是唯一的嗎?
- 機器碼最多可以容納 1024 個節點,超過 1024 怎么辦?
- 資料庫的自增ID為什么不用雪花演算法?
不要慌,下期和大家聊聊這些問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/356793.html
標籤:java
上一篇:cgb2109-day11