作者: Tom哥
簡介:計算機研究生,校招進阿里,期間還拿過百度、華為、中興、騰訊等6家大廠offer,P7 技術專家,出過專利,CSDN博客專家,
公眾號:微觀技術,分享其他地方看不到的知識與思考,歡迎關注
大家好,我是Tom哥~
哲學里有一句很經典的話,”下層基礎決定上層建筑“,相信很多人都聽過,廣泛用于我們生活中,
那么我們軟體開發行業的下層基礎是什么,有人說是作業系統、是網路、是HTTP協議、是TCP,這些雖然也是底層,但其實不夠原子化,
軟體行業講究的是抽象,那么他們的共同點是什么,那就是資料和計算,
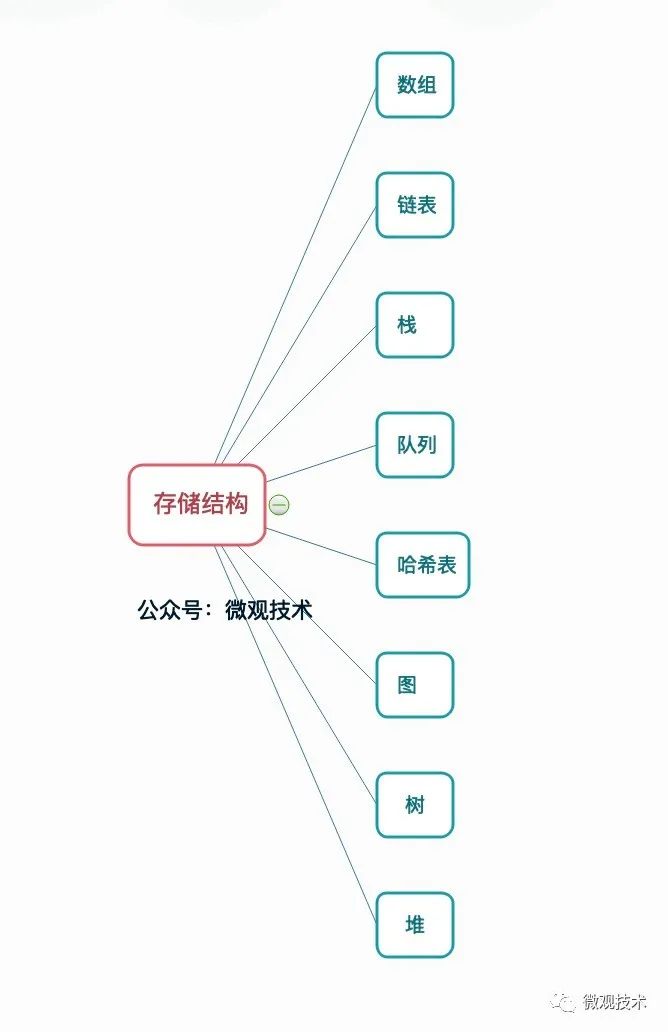
1、陣列
定義:
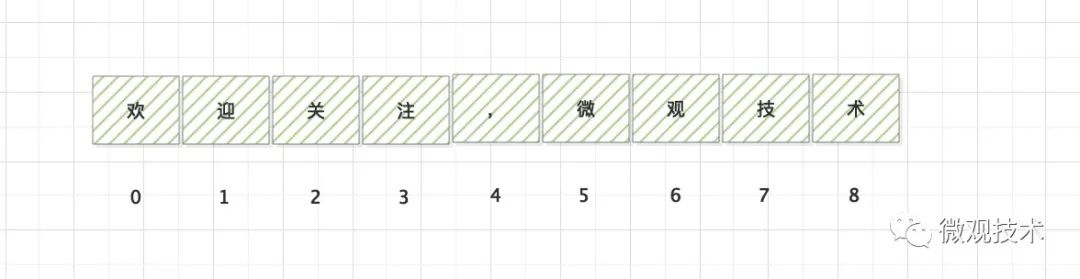
陣列是一組連續記憶體空間存盤的具有相同型別的資料,整個排列像一條線一樣,是一種線性表資料結構,
整理了一份大廠常考面試題,這份pdf包括 Java基礎、Java并發、JVM、MySQL、Redis、Spring、MyBatis、Kafka、設計模式等面試題,分享給大家,
下載地址:百度云鏈接:https://pan.baidu.com/s/1XHT4ppXTp430MEMW2D0-Bg 提取碼: s3ab
劃重點:
-
連續記憶體空間
-
相同資料型別
-
線性結構
像常見的陣列、鏈表、堆疊、佇列,都是線性結構,
優勢:
隨機訪問,為什么呢?因為他的型別固定,決定它的資料長度也就固定,另外就是連續,所以基于初始地址,可以直接計算出陣列任意位置的記憶體地址,查詢速度很多,
缺點:
-
為了保持連續性,中間位置插入或洗掉資料,需要做資料搬移,效率會較低,可以看下
ArrayList相關API的原始碼 -
成也蕭何敗蕭何,陣列初始化需要連續的記憶體空間,如果空間不夠怎么辦?我們可以選擇
鏈表
注意點:
-
使用陣列要注意越界問題
-
陣列擴容需要申請記憶體、資料搬移,成本較大,如果開始時能確定大小,那么在初始化時指定其大小,
2、鏈表
定義:
鏈表一種非連續、非順序的存盤結構,由一系列節點組成,節點間通過指標完成了串聯,每個節點包含資料和下一個節點指標兩部分,
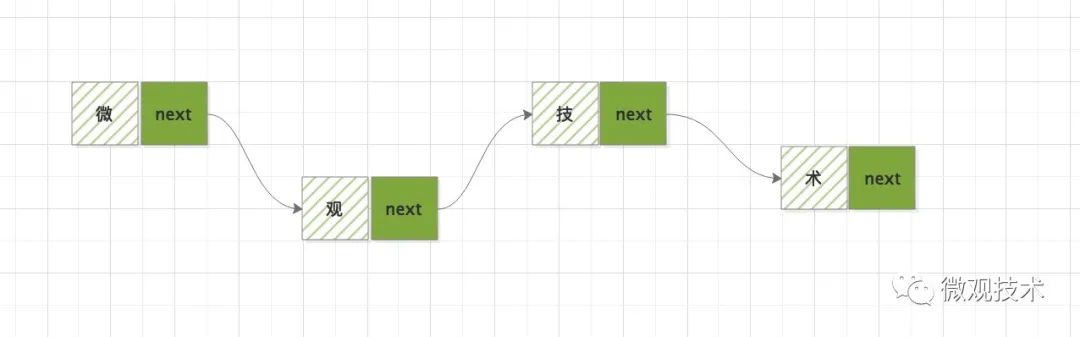
根據指標的方向可以分為:
-
單向鏈表
-
回圈鏈表
-
雙向鏈表
-
雙向回圈鏈表
劃重點:
-
不需要連續記憶體空間
-
通過指標將這些空間串起來,形成一條鏈
優勢:
-
不需要連續的記憶體空間,較靈活
-
允許插入、洗掉鏈表上任意位置的節點,只需要修改指標的值,不需要像陣列一樣搬移資料,系統開銷成本大大降低
缺點:
-
鏈表除了存盤資料,還要存盤指標,會額外占用一些存盤空間
-
由于非順序存盤,所以不支持
隨機存取
注意點:
陣列擅長按下標隨機訪問,鏈表擅長插入、洗掉操作,平常大家使用時,根據具體使用場景是讀多還是寫多靈活選擇,
3、堆疊
定義:
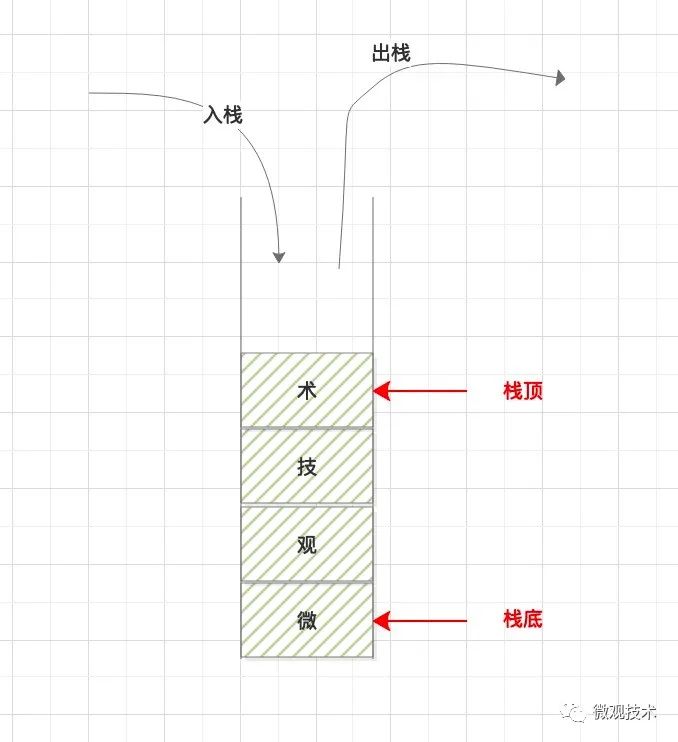
又名堆疊,它是一種運算受限的線性表,上面成為堆疊頂,下面稱為堆疊底,向堆疊插入新元素稱為入堆疊,新元素放到堆疊頂;從一個堆疊洗掉元素又稱作出堆疊,它是把堆疊頂元素洗掉掉,使其下面相鄰的元素成為新的堆疊頂元素,
根據底層結構不同,可以分為陣列實作的順序堆疊、鏈表實作的鏈式堆疊,
劃重點:
-
兩個動作:入堆疊、出堆疊
-
先進后出,后進先出
優勢:
- 只能操作堆疊頂元素,規則限制的死死地,不像其他資料結構非常靈活,可控性好,非常適合一些特殊業務場景
缺點:
- 只能從上往下依次讀取,不能從中間讀取資料
典型場景:
-
JVM的本地方法堆疊,函式呼叫
-
瀏覽器的前進、后退
4、佇列
定義:
佇列是一種特殊的線性表,只允許在表的前端進行洗掉操作,而在表的后端進行插入操作,和堆疊一樣,佇列是一種操作受限制的線性表,插入的資料放在隊尾,讀取資料的端稱為隊頭,佇列中沒有元素時,稱為空佇列,
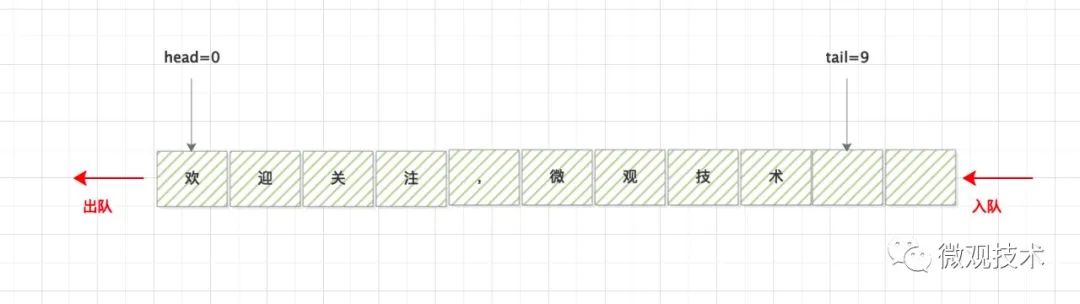
根據支持的高級特性,可以分為:回圈佇列、阻塞佇列、并發佇列,根據底層結構不同,可以分為順序佇列、鏈式佇列,
劃重點:
-
兩個動作:入隊、出隊
-
需要兩個指標,一個head指標,指向隊頭;一個tail指標,指向隊尾,隨著入隊和出隊,兩個指標也會相應的移動,
-
先進先出,與堆疊相反
優勢:
- 規則固定,頭部只能讀取,插入只能在隊尾進行,規則固定,可控性&安全性好,非常適合一些特殊業務場景
缺點:
- 只能從對頭讀取資料,不能從中間讀取資料
典型場景:
-
java執行緒池
ThreadPoolExecutor,來不及處理的任務會臨時放在任務佇列中 -
各種MQ訊息中間件,如:kafka、RocketMQ 等
位元組、阿里等一線大廠面試題,點擊下載
5、哈希表
定義:
哈希表(Hash table)也叫散串列,根據鍵(Key)而直接訪問在記憶體儲存位置的資料結構,它通過計算一個關于鍵值的函式,將所需查詢的資料映射到表中一個位置來訪問記錄,加快查找速度,這個映射函式稱為散列函式,存放記錄的陣列稱做散串列,
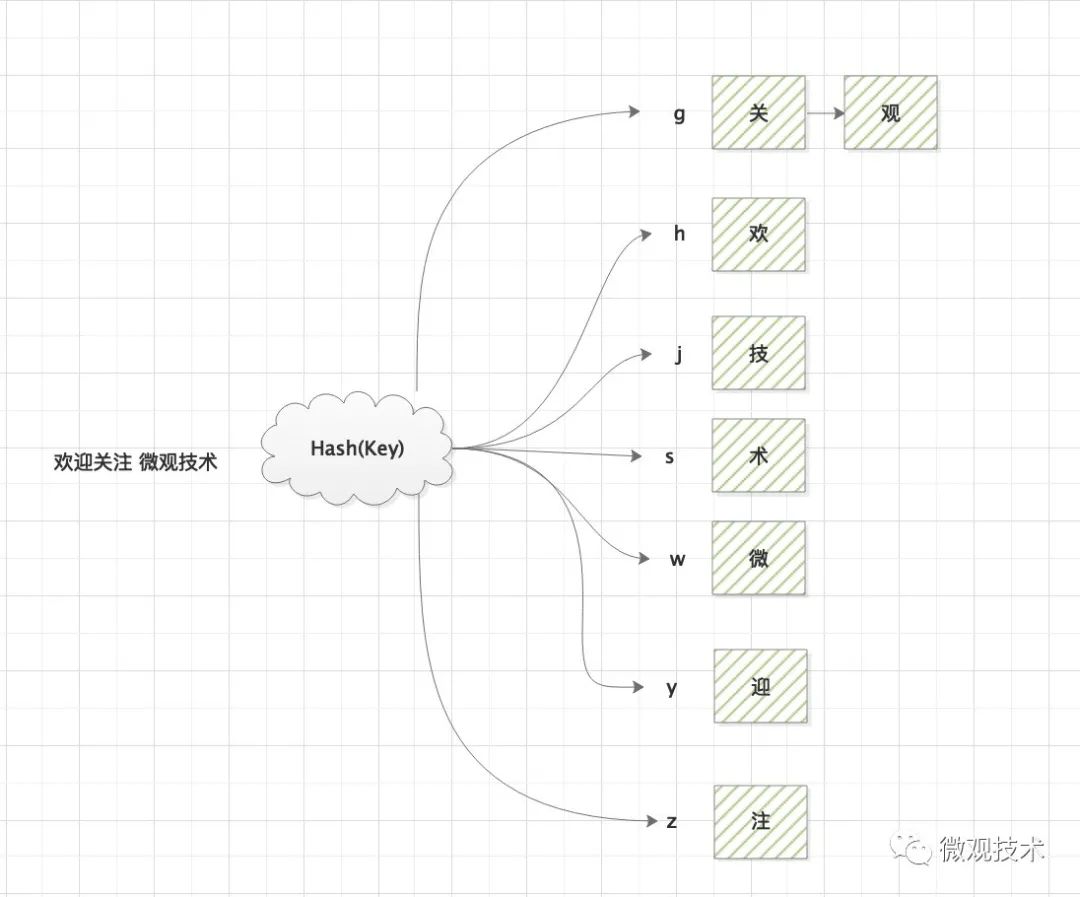
劃重點:
-
Hash函式,建立key與value的映射關系,
-
常用的哈希函式有MD5、SHA、CRC等
優勢:
-
分為治之,化大為小,降低了復雜度
-
通過key計算直接獲取目標位置,提高查找速度
缺點:
可能存在哈希沖突,在每個沖突處構建鏈表,將所有沖突值鏈入鏈表,如果是惡意攻擊,哈希表可能會退化為鏈表,所有元素都被存盤在同一個節點的鏈表中,此時哈希表的查找速度=鏈表遍歷查找速度=O(n)
為了描述沖突,引入裝載因子=哈希表中的元素個數 / 哈希表長度,裝載因子越大,說明鏈表的長度越長,性能會越低,
當裝載因子過大時,需要動態擴容,申請一個更大的哈希表,將原哈希表的資料遷移到新的哈希表,
典型場景:
-
Redis 資料庫
-
Java中的哈希表實作,HashMap
6、圖
定義:
圖(Graph)是由頂點的有窮非空集合和頂點之間的集合組成,通常表示為:G(V, E),其中 G 表示一個圖,V 是圖 G 中頂點的集合,E 是圖 G 中邊的集合,
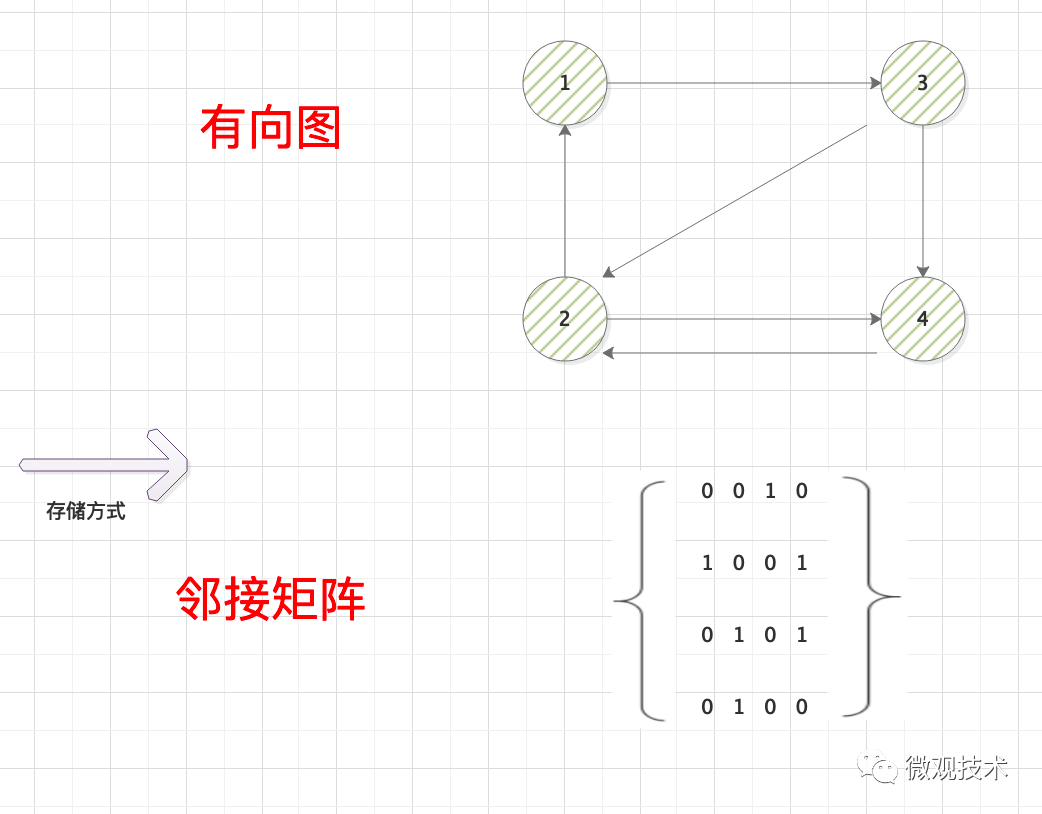
上圖是一個有向圖G,G=(V,E),其中頂點集合 V = 1、2、3、4,邊集合是 E = (1,3)、(2,1)、(2,4)、(3,2)、(3,4)、(4,2)
根據圖是否有方向、權重等可以分為:有向圖、無向圖、帶權圖
劃重點:
-
非線性表
-
任意兩個節點關系
優勢:
-
存盤的資訊完備
-
為任意兩個頂點建立關系,稱之為邊,而樹只能表示相鄰兩個節點的關系
缺點:
任意點都可以建立關系,所以資料量會比較大,為了便于存盤,我們將圖用多維陣串列示,從而將很多圖運算轉換為矩陣運算,
當然,如果圖比較稀疏的話,可以采用鄰接表的存盤方式,與哈希表類似,可以節省很多空間,
典型場景:
-
地圖如何計算出最優出行路線
-
深度優先搜索
-
廣度優先搜索
-
最小生成樹
注意:
-
圖主要有以下兩種存盤方式:
-
鄰接矩陣,比較浪費空間,但是優點是查詢效率高
-
鄰接表,每個頂點對應一個鏈表,比較節省存盤空間,但是查詢效率會低些,當然為了提高查詢效率,可以將里面的鏈表替換成紅黑樹、跳表、或者平衡二叉樹,
7、樹
定義:
顧名思義,跟現實的樹一樣,樹上的每一個元素成為節點,節點與節點之間有一定的關系,上下稱為父子節點,左右稱為兄弟節點,
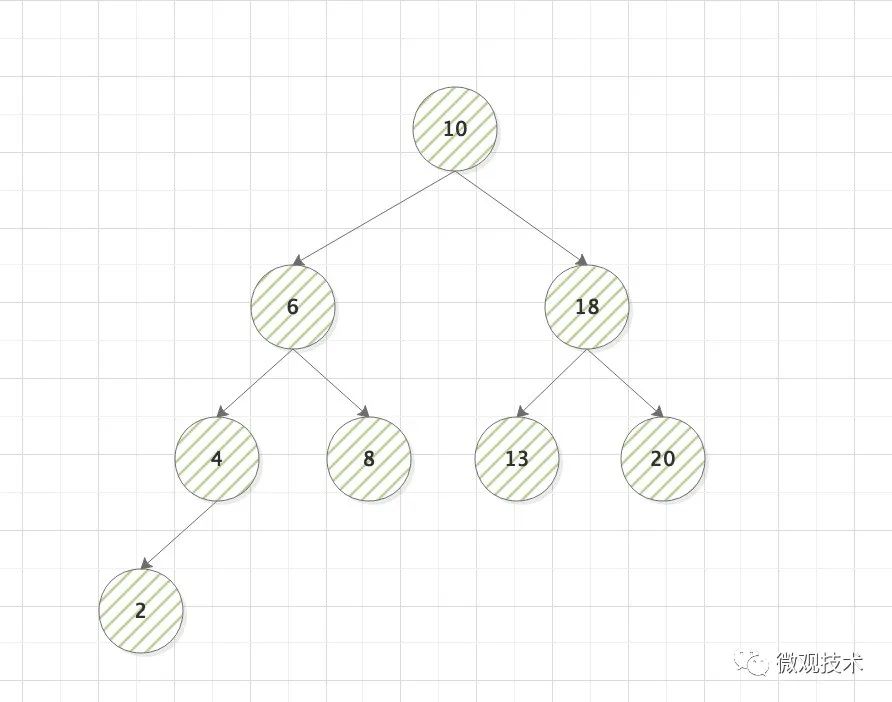
按照樹的表現結構,可以具體分為以下幾種型別:二叉樹、平衡二叉樹、滿二叉樹、完全二叉樹、遞回樹、紅黑樹、B- 樹、B+ 樹 ,等
劃重點:
-
非線性結構
-
父子節點
-
兄弟節點
-
樹型結構
-
每個節點包含3塊資訊:資料值、左右子節點指標,
優勢:
-
樹形結構,支持資料的快速插入、查找、洗掉
-
支持多種遍歷方式:前序遍歷、中序遍歷、后序遍歷
-
結構特殊,適合用遞回來實作
缺點:
樹中洗掉一個節點操作較復雜,需要根據其子節點的個數(0、1、2)分多種情況考慮,遷移部分節點,重新構造樹結構,當然,也可以采用邏輯標記洗掉,物理空間沒有釋放,但會產生碎片,影響查詢效率,
注意點:
-
紅黑樹出鏡率很高,風頭甚至蓋過了平衡二叉樹,因為紅黑樹只要求近似平衡,維護成本比AVL樹要低,但性能損失不大,當HashMap中的鏈表資料較多時,也會將鏈表結構升級為紅黑樹結構,
-
B+樹主要是采用更加扁平的結構存盤海量資料,降低樹的深度,主要用在 mysql 資料庫索引構建,有興趣同學可以看下之前的文章
面試題:mysql 一棵 B+ 樹能存多少條資料?
8、堆
定義:
一種特殊的二叉樹,需要滿足兩個條件:1、是一棵完全二叉樹 2、堆中每個節點的值必須>=或<=其左右子節點的值,
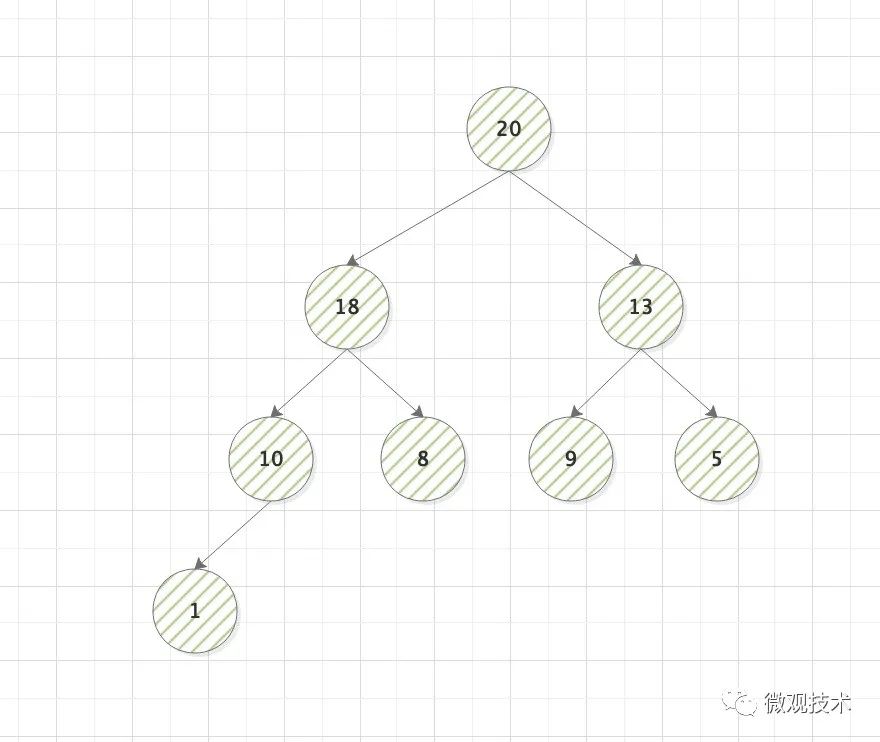
具體,根據每個節點的值是>= 還是 <= 子樹中每個節點的值,分為大頂堆、小頂堆,
劃重點:
- 節點的值要比左右子樹的值大或小,只能一種選擇
優勢:
-
時間復雜度較低
-
獲取堆頂元素的時間復雜度為 O(1)
-
假設完全二叉樹包含n個節點,插入元素、洗掉元素,時間復雜度為 O(logn)
缺點:
-
特殊的二叉樹
-
只能滿足特殊的需求
典型場景:
-
堆排序
-
優先級佇列
-
求 TOP K
-
求中位數
示例:從10億個資料中找到最大的前10個?
-
假設10億個資料存在陣列中
-
取前10個資料,構建一個小頂堆,那么根節點是最小的
-
然后,從陣列中依次取出一個資料與堆頂比較,如果大于,替換掉堆頂元素,堆內部調整;如果小于等于堆頂,不做處理
-
同樣邏輯,依次回圈處理陣列中每一個元素,
-
當10億個資料處理完后,堆中的資料就是Top 10
關于我:前阿里架構師,出過專利,競賽拿過獎,CSDN博客專家,負責過電商交易、社區生鮮、營銷、金融等業務,多年團隊管理經驗,愛思考,喜歡結交朋友
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/356982.html
標籤:java
上一篇:五分鐘學會冒泡排序