本篇博客為大家說明一下 scrapy 中代理相關知識點,
代理的使用場景
撰寫爬蟲代碼的程式員,永遠繞不開就是使用代理,在編碼程序中,你會碰到如下情形:
- 網路不好,需要代理;
- 目標站點國內訪問不了,需要代理;
- 網站封殺了你的 IP,需要代理,
使用 HttpProxyMiddleware 中間件
本次的測驗站點依舊使用 http://httpbin.org/,通過訪問 http://httpbin.org/ip 可以獲取當前請求的 IP 地址,
HttpProxyMiddleware 中間件默認是開啟的,可以查看其原始碼重點為 process_request() 方法,
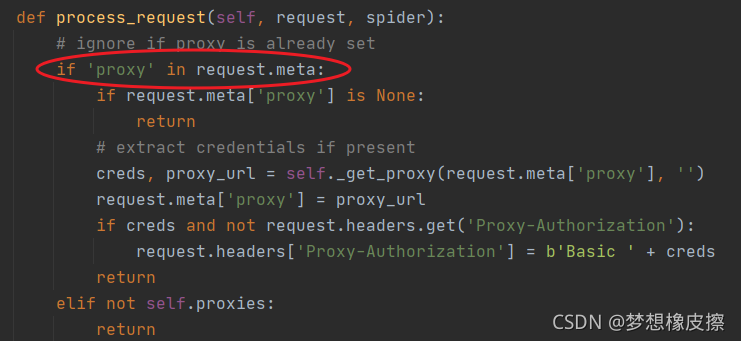
修改代理的方式非常簡單,只需要在 Requests 請求創建的時候,增加 meta 引數即可,
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/ip']
def start_requests(self):
yield scrapy.Request(url=self.start_urls[0], meta={'proxy': 'http://202.5.116.49:8080'})
def parse(self, response):
print(response.text)
接下來通過獲取一下 https://www.kuaidaili.com/free/ 網站的代理 IP,并測驗其代理是否可用,
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
start_urls = ['https://www.kuaidaili.com/free/']
def parse(self, response):
IP = response.xpath('//td[@data-title="IP"]/text()').getall()
PORT = response.xpath('//td[@data-title="PORT"]/text()').getall()
url = 'http://httpbin.org/ip'
for ip, port in zip(IP, PORT):
proxy = f"http://{ip}:{port}"
meta = {
'proxy': proxy,
'dont_retry': True,
'download_timeout': 10,
}
yield scrapy.Request(url=url, callback=self.check_proxy, meta=meta, dont_filter=True)
def check_proxy(self, response):
print(response.text)
接下來將可用的代理 IP 保存到 JSON 檔案中,
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
start_urls = ['https://www.kuaidaili.com/free/']
def parse(self, response):
IP = response.xpath('//td[@data-title="IP"]/text()').getall()
PORT = response.xpath('//td[@data-title="PORT"]/text()').getall()
url = 'http://httpbin.org/ip'
for ip, port in zip(IP, PORT):
proxy = f"http://{ip}:{port}"
meta = {
'proxy': proxy,
'dont_retry': True,
'download_timeout': 10,
'_proxy': proxy
}
yield scrapy.Request(url=url, callback=self.check_proxy, meta=meta, dont_filter=True)
def check_proxy(self, response):
proxy_ip = response.json()['origin']
if proxy_ip is not None:
yield {
'proxy': response.meta['_proxy']
}
同時修改 start_requests 方法,獲取 10 頁代理,
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
url_format = 'https://www.kuaidaili.com/free/inha/{}/'
def start_requests(self):
for page in range(1, 11):
yield scrapy.Request(url=self.url_format.format(page))
實作一個自定義的代理中間件也比較容易,有兩種辦法,第一種繼承 HttpProxyMiddleware,撰寫如下代碼:
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from collections import defaultdict
import random
class RandomProxyMiddleware(HttpProxyMiddleware):
def __init__(self, auth_encoding='latin-1'):
self.auth_encoding = auth_encoding
self.proxies = defaultdict(list)
with open('./proxy.csv') as f:
proxy_list = f.readlines()
for proxy in proxy_list:
scheme = 'http'
url = proxy.strip()
self.proxies[scheme].append(self._get_proxy(url, scheme))
def _set_proxy(self, request, scheme):
creds, proxy = random.choice(self.proxies[scheme])
request.meta['proxy'] = proxy
if creds:
request.headers['Proxy-Authorization'] = b'Basic ' + creds
代碼核心重寫了 __init__ 構造方法,并重寫了 _set_proxy 方法,在其中實作了隨機代理獲取,
同步修改 settings.py 檔案中的代碼,
DOWNLOADER_MIDDLEWARES = {
'proxy_text.middlewares.RandomProxyMiddleware': 543,
}
創建一個新的代理中間件類
class NRandomProxyMiddleware(object):
def __init__(self, settings):
# 從settings中讀取代理配置 PROXIES
self.proxies = settings.getlist("PROXIES")
def process_request(self, request, spider):
request.meta["proxy"] = random.choice(self.proxies)
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.getbool("HTTPPROXY_ENABLED"):
raise NotConfigured
return cls(crawler.settings)
可以看到該類從 settings.py 檔案中的 PROXIES 讀取配置,所以修改對應配置如下所示:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
'proxy_text.middlewares.NRandomProxyMiddleware': 543,
}
# 代碼是前文代碼采集的結果
PROXIES = ['http://140.249.48.241:6969',
'http://47.96.16.149:80',
'http://140.249.48.241:6969',
'http://47.100.14.22:9006',
'http://47.100.14.22:9006']
如果你想測驗爬蟲,可撰寫一個隨機回傳請求代理的函式,將其用到任意爬蟲代碼之上,完成本博客任務,
收藏時間
本期博客收藏過 400,立刻更新下一篇
今天是持續寫作的第 261 / 200 天,
可以關注我,點贊我、評論我、收藏我啦,
更多精彩
- Python 爬蟲 100 例教程導航帖(抓緊訂閱啦)

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/356992.html
標籤:python