您好,我是碼農飛哥,感謝您閱讀本文,歡迎一鍵三連哦,
本文只是記錄我優化的心酸歷程,無他,唯記錄爾,,,,,小伙伴們可圍觀,可打call,可以私信與我交流,
干貨滿滿,建議收藏,需要用到時常看看, 小伙伴們如有問題及需要,歡迎踴躍留言哦~ ~ ~,
文章目錄
- 問題背景
- 系統環境
- 優化歷程
- 小小分析一波
- 第一階段:直接上torch.cuda.empty_cache()清理,
- 第二階段(創建子行程加載模型并進行訓練)
- 第三階段(全域執行緒池+釋放GPU)
- 總結
- 參考
- 粉絲專屬福利
問題背景
現有一個古詩自動生成的訓練介面,該介面通過Pytorch來生訓練模型(即生成古詩)為了加速使用到了GPU,但是訓練完成之后GPU未能釋放,故此需要進行優化,即在古詩生成完成之后釋放GPU,
該專案是一個通過Flask搭建的web服務,在服務器上為了實作并發采用的是gunicorn來啟動應用,通過pythorch來進行古詩訓練,專案部署在一個CentOS的服務器上,
系統環境
| 軟體 | 版本 |
|---|---|
| flask | 0.12.2 |
| gunicorn | 19.9.0 |
| CentOS 6.6 | 帶有GPU的服務器,不能加機器 |
| pytorch | 1.7.0+cpu |
因為特殊的原因這里之后一個服務器供使用,故不能考慮加機器的情況,
優化歷程
pytorch在訓練模型時,需要先加載模型model和資料data,如果有GPU顯存的話我們可以將其放到GPU顯存中加速,如果沒有GPU的話則只能使用CPU了,
由于加載模型以及資料的程序比較慢,所以,我這邊將加載程序放在了專案啟動時加載,
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = GPT2LMHeadModel.from_pretrained(os.path.join(base_path, "model"))
model.to(device)
model.eval()
這部分耗時大約在6秒左右,cuda表示使用torch的cuda,模型資料加載之后所占的GPU顯存大小大約在1370MB,優化的目標就是在訓練完成之后將這部分占用的顯存釋放掉,
小小分析一波
現狀是專案啟動時就加載模型model和資料data的話,當模型資料在GPU中釋放掉之后,下次再進行模型訓練的話不就沒有模型model和資料data了么?如果要釋放GPU的話,就需要考慮如何重新加載GPU,
所以,模型model和資料data不能放在專案啟動的時候加載,只能放在呼叫訓練的函式時加載,但是由于加載比較慢,所以只能放在一個異步的子執行緒或者子行程中運行,
所以,我這邊首先將模型資料的加載程序以及訓練放在了一個單獨的執行緒中執行,
第一階段:直接上torch.cuda.empty_cache()清理,
GPU沒釋放,那就釋放唄,這不是很簡單么?百度一波pytorch怎么釋放GPU顯存,
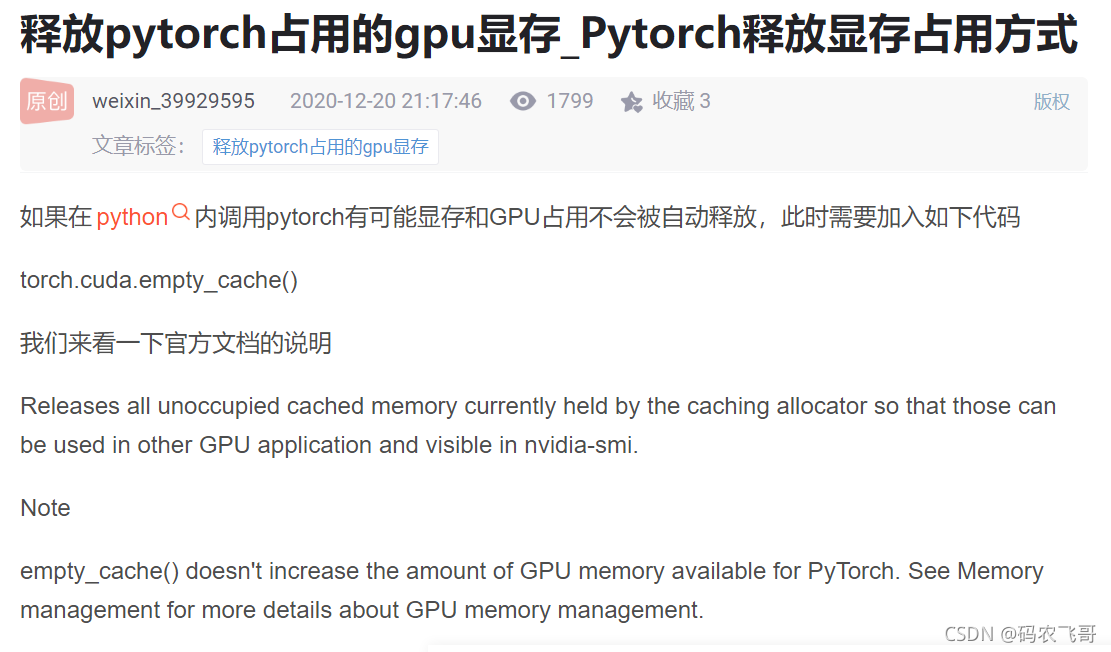
輕點一下,即找到了答案,那就是在訓練完成之后torch.cuda.empty_cache() ,代碼加上之后再運行,發現并沒啥卵用!!!!,CV大法第一運用失敗
這到底是啥原因呢?我們后面會分析到!!!
第二階段(創建子行程加載模型并進行訓練)
既然子執行緒加載模型并進行訓練不能釋放GPU的話,那么我們能不能轉變一下思路,創建一個子行程來加載模型資料并進行訓練,
當訓練完成之后就將這個子行程殺掉,它所占用的資源(主要是GPU顯存)不就被釋放了么?
這思路看起來沒有絲毫的毛病呀,說干就干,
- 定義加載模型資料以及訓練的方法 training,(代碼僅供參考)
def training(queue):
manage.app.app_context().push()
current_app.logger.error('基礎加載開始')
with manage.app.app_context():
device = "cuda" if torch.cuda.is_available() else "cpu"
current_app.logger.error('device1111開始啦啦啦')
model.to(device)
current_app.logger.error('device2222')
model.eval()
n_ctx = model.config.n_ctx
current_app.logger.error('基礎加載完成')
#訓練方法
result_list=start_train(model,n_ctx,device)
current_app.logger.error('完成訓練')
#將訓練方法回傳的結果放入佇列中
queue.put(result_list)
- 創建子行程執行training方法,然后通過阻塞的方法獲取訓練結果
from torch import multiprocessing as mp
def sub_process_train():
#定義一個佇列獲取訓練結果
train_queue = mp.Queue()
training_process = mp.Process(target=training, args=(train_queue))
training_process.start()
current_app.logger.error('子行程執行')
# 等訓練完成
training_process.join()
current_app.logger.error('執行完成')
#獲取訓練結果
result_list = train_queue.get()
current_app.logger.error('獲取到資料')
if training_process.is_alive():
current_app.logger.error('子行程還存活')
#殺掉子行程
os.kill(training_process.pid, signal.SIGKILL)
current_app.logger.error('殺掉子行程')
return result_list
- 因為子行程要阻塞獲取執行結果,所以需要定義一個執行緒去執行sub_process_train方法以保證訓練介面可以正常回傳,
import threading
threading.Thread(target=sub_process_train).start()
代碼寫好了,見證奇跡的時候來了,
首先用python manage.py 啟動一下,看下結果,運行結果如下,報了一個錯誤,從錯誤的提示來看就是不能在forked的子行程中重復加載CUDA,"Cannot re-initialize CUDA in forked subprocess. " + msg) RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method,
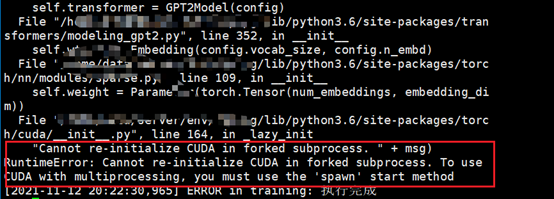
這里有問題,就是 forked 是啥,spawn 又是啥?這里就需要了解創建子行程的方式了,
通過torch.multiprocessing.Process(target=training, args=(train_queue)) 創建一個子行程
fork和spawn是構建子行程的不同方式,區別在于
1. fork: 除了必要的啟動資源,其余的變數,包,資料等都集成自父行程,也就是共享了父行程的一些記憶體頁,因此啟動較快,但是由于大部分都是用的自父行程資料,所有是不安全的子行程,
2. spawn:從頭構建一個子行程,父行程的資料拷貝到子行程的空間中,擁有自己的Python解釋器,所有需要重新加載一遍父行程的包,因此啟動叫慢,但是由于資料都是自己的,安全性比較高,
回到剛剛那個報錯上面去,為啥提示要不能重復加載,
這是因為Python3中使用 spawn啟動方法才支持在行程之間共享CUDA張量,而用的multiprocessing 是使用 fork 創建子行程,不被 CUDA 運行時所支持,
所以,只有在創建子行程之前加上mp.set_start_method('spawn') 方法,即
def sub_process_train(prefix, length):
try:
mp.set_start_method('spawn')
except RuntimeError:
pass
train_queue = mp.Queue()
training_process = mp.Process(target=training, args=(train_queue))
##省略其他代碼
再次通過 python manage.py 運行專案,運行結果圖1和圖2所示,可以看出可以正確是使用GPU顯存,在訓練完成之后也可以釋放GPU,


一切看起來都很prefect, But,But,通過gunicorn啟動專案之后,再次呼叫介面,則出現下面結果,
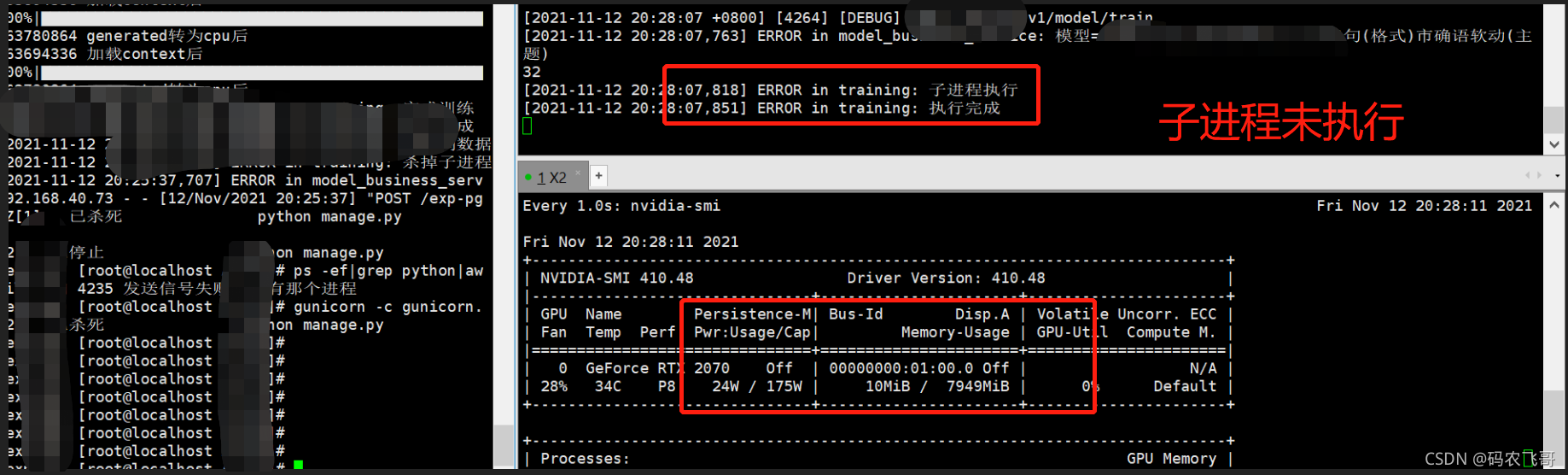
用gunicorn啟動專案子行程竟然未執行,這就很頭大了,不加mp.set_start_method(‘spawn’) 方法模型資料不能加載,
加上這個方法子行程不能執行,真的是一個頭兩個大,
第三階段(全域執行緒池+釋放GPU)
子行程的方式也不行了,只能回到前面的執行緒方式了,前面創建執行緒的方式都是直接通過直接new一個新執行緒的方式,當同時運行的執行緒數過多的話,則很容易就會出現GPU占滿的情況,從而導致應用崩潰,所以,這里采用全域執行緒池的方式來創建并管理執行緒,然后當執行緒執行完成之后釋放資源,
- 在專案啟動之后就創建一個全域執行緒池,大小是2,保證還有剩余的GPU,
from multiprocessing.pool import ThreadPool
pool = ThreadPool(processes=2)
- 通過執行緒池來執行訓練
pool.apply_async(func=async_produce_poets)
- 用執行緒加載模型和釋放GPU
def async_produce_poets():
try:
print("子行程開始" + str(os.getpid())+" "+str(threading.current_thread().ident))
start_time = int(time.time())
manage.app.app_context().push()
device = "cuda" if torch.cuda.is_available() else "cpu"
model = GPT2LMHeadModel.from_pretrained(os.path.join(base_path, "model"))
model.to(device)
model.eval()
n_ctx = model.config.n_ctx
result_list=start_train(model,n_ctx,device)
#將模型model轉到cpu
model = model.to('cpu')
#洗掉模型,也就是洗掉參考
del model
#在使用其釋放GPU,
torch.cuda.empty_cache()
train_seconds = int(time.time() - start_time)
current_app.logger.info('訓練總耗時是={0}'.format(str(train_seconds)))
except Exception as e:
manage.app.app_context().push()
這一番操作之后,終于達到了理想的效果,
這里因為使用到了gunicorn來啟動專案,所以gunicorn 相關的知識必不可少,在CPU受限的系統中采用sync的作業模式比較理想,
詳情可以查看gunicorn的簡單總結
問題分析,前面第一階段直接使用torch.cuda.empty_cache() 沒能釋放GPU就是因為沒有洗掉掉模型model,模型已經加載到了GPU了,
總結
本文從實際專案的優化入手,記錄優化方面的方方面面,希望對讀者朋友們有所幫助,
參考
multiprocessing fork() vs spawn()
粉絲專屬福利
軟考資料:實用軟考資料
面試題:5G 的Java高頻面試題
學習資料:50G的各類學習資料
脫單秘籍:回復【脫單】
并發編程:回復【并發編程】
👇🏻 驗證碼 可通過搜索下方 公眾號 獲取👇🏻
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/356995.html
標籤:python