我在 SQL Server 2016 中有一個有趣的情況。我使用的是 T-SQL 語言。
我有一個名為 (#dataset) 的資料集:
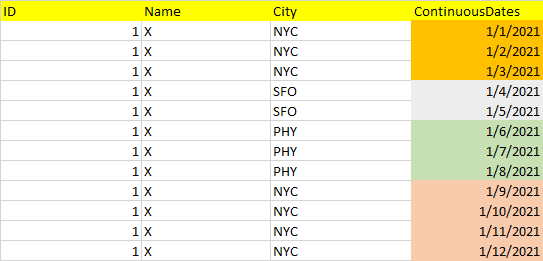
名為 ContinuousDates 的最后一列將始終具有無間隙的連續日期值,例如 2021 年 1 月 1 日至 2021 年 12 月 31 日。它永遠不會有相同 ID 或名稱的重復日期,即給定日期的一個人只能有一個行資料。(在這個例子中,我只展示了一個人,ID = 1,Name = X。在我的實際資料中,我有多個人)。
請注意,NYC city 在資料集中出現的較早,并在最后 4 行中重復。
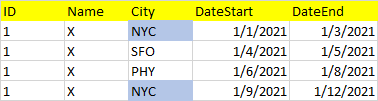
我需要根據日期范圍獲取以下資料集:
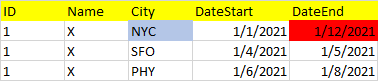
我嘗試在資料集上使用簡單的 MINIMUM 和 MAXIMUM,但我意識到有時我會得到錯誤的輸出,如下所示:
我使用 RANK() 和 DENSE_RANK() 函式嘗試了一些選項,但無法找到解決方案。有人可以為我提供幫助嗎?
我在這里附上了代碼:
CREATE TABLE #dataset
(
ID int,
Name varchar(20),
City varchar(20),
ContinuousDates date
)
INSERT INTO #dataset
VALUES(1,'X','NYC','1/1/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/2/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/3/2021')
INSERT INTO #dataset
VALUES(1,'X','SFO','1/4/2021')
INSERT INTO #dataset
VALUES(1,'X','SFO','1/5/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/6/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/7/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/8/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/9/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/10/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/11/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/12/2021')
SELECT *
FROM #dataset
ORDER BY ContinuousDates
我有一組新代碼,以便更好地演示:
CREATE TABLE #dataset
(
ID int,
Name varchar(20),
City varchar(20),
ContinuousDates date
)
INSERT INTO #dataset
VALUES(1,'X','NYC','1/1/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/2/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/3/2021')
INSERT INTO #dataset
VALUES(1,'X','SFO','1/4/2021')
INSERT INTO #dataset
VALUES(1,'X','SFO','1/5/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/6/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/7/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/8/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/9/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/10/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/11/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/12/2021')
INSERT INTO #dataset
VALUES(2,'Y','MEL','1/13/2021')
INSERT INTO #dataset
VALUES(3,'Z','SYD','1/14/2021')
INSERT INTO #dataset
VALUES(3,'Z','SYD','1/15/2021')
INSERT INTO #dataset
VALUES(3,'Z','PER','1/16/2021')
INSERT INTO #dataset
VALUES(4,'A',NULL,'1/16/2021')
INSERT INTO #dataset
VALUES(4,'A', NULL,'1/17/2021')
SELECT *
FROM #dataset
ORDER BY ID, ContinuousDates
uj5u.com熱心網友回復:
解決步驟:
- 帶有按日期排序的 ID 和名稱的數字部分 (row_id)
- 按日期排序的帶有 ID、名稱和城市的數字部分 (p_row_id)
- 計算 row_id - p_row_id
現在,您在唯一的一組值中擁有每個時期的組號。
您所需要的只是按此號碼、ID、姓名和城市分組
| ID | 姓名 | 城市 | 連續日期 | p_row_id | row_id | row_id - p_row_id |
|---|---|---|---|---|---|---|
| 1 | X | 紐約市 | 2021-01-01 | 1 | 1 | 0 |
| 1 | X | 紐約市 | 2021-01-02 | 2 | 2 | 0 |
| 1 | X | 紐約市 | 2021-01-03 | 3 | 3 | 0 |
| 1 | X | 證券及期貨事務處 | 2021-01-04 | 1 | 4 | 3 |
| 1 | X | 證券及期貨事務處 | 2021-01-05 | 2 | 5 | 3 |
| 1 | X | 物理層 | 2021-01-06 | 1 | 6 | 5 |
| 1 | X | 物理層 | 2021-01-07 | 2 | 7 | 5 |
| 1 | X | 物理層 | 2021-01-08 | 3 | 8 | 5 |
| 1 | X | 紐約市 | 2021-01-09 | 4 | 9 | 5 |
| 1 | X | 紐約市 | 2021-01-10 | 5 | 10 | 5 |
| 1 | X | 紐約市 | 2021-01-11 | 6 | 11 | 5 |
| 1 | X | 紐約市 | 2021-01-12 | 7 | 12 | 5 |
select
CD.ID
,CD.[Name]
,CD.City
,min(CD.ContinuousDates) as DateStart
,max(CD.ContinuousDates) as DateEnd
from
(
select *
,row_number() over(partition by CD.ID, CD.[Name], CD.City order by CD.ContinuousDates) as p_row_id
,row_number() over(partition by CD.ID, CD.[Name] order by CD.ContinuousDates) as row_id
from #dataset CD
) CD
group by CD.row_id - CD.p_row_id
,CD.ID
,CD.[Name]
,CD.City
order by DateStart
多列模板:
select
CD.GroupColumn1
,CD.GroupColumn2
..
,CD.Column1
,CD.Column2
,CD.Column3
,CD.Column4
..
,min(CD.ContinuousDates) as DateStart
,max(CD.ContinuousDates) as DateEnd
from
(
select *
,row_number() over(partition by
CD.GroupColumn1
,CD.GroupColumn2
..
,CD.Column1
,CD.Column2
,CD.Column3
,CD.Column4
..
order by CD.ContinuousDates) as p_row_id
,row_number() over(partition by
CD.GroupColumn1
,CD.GroupColumn2
..
order by CD.ContinuousDates) as row_id
from #dataset CD
) CD
group by CD.row_id - CD.p_row_id
,CD.GroupColumn1
,CD.GroupColumn2
..
CD.Column1
,CD.Column2
,CD.Column3
,CD.Column4
..
order by DateStart
uj5u.com熱心網友回復:
這是一種間隙和島嶼問題。
有許多不同的解決方案。這是一個簡單的
- 使用
LAG以確定啟動每個島行 - 運行條件計數為我們提供了每個島的 ID
- 然后簡單地按該 ID 分組(以及任何其他磁區列)
WITH StartPoints AS (
SELECT *,
IsStart = CASE WHEN LAG(City, 1, '') OVER (PARTITION BY ID ORDER BY ContinuousDates)
<> City THEN 1 END
FROM #dataset ds
),
Groups AS (
SELECT *,
GroupId = COUNT(IsStart) OVER (PARTITION BY ID ORDER BY ContinuousDates ROWS UNBOUNDED PRECEDING)
FROM StartPoints
)
SELECT
ID,
Name,
City = MIN(City),
DateStart = MIN(ContinuousDates),
DateEnd = MAX(ContinuousDates)
FROM Groups
GROUP BY
ID,
Name,
GroupId;
資料庫<>小提琴
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/361954.html
標籤:sql-server 日期 查询语句 sql-server-2016 缝隙和岛屿