一、理解指標
看懂鏈表的結構并不是很難,但是一旦把它和指標混在一起,就很容易讓人摸不著頭腦,所以,要想寫對鏈表代碼,首先就要理解好指標,
有些語言有“指標”的概念,比如 C 語言;有些語言沒有指標,取而代之的是“參考”,比如 Java、Python,不管是“指標”還是“參考”,實際上,它們的意思都是一樣的,都是存盤所指物件的記憶體地址,
將某個變數賦值給指標,實際上就是將這個變數的地址賦值給指標,或者反過來說,指標中存盤了這個變數的記憶體地址,指向了這個變數,通過指標就能找到這個變數,
p->next=q,這行代碼是說,p 結點中的 next 指標存盤了 q 結點的記憶體地址,p->next=p->next->next,這行代碼表示,p 結點的 next 指標存盤了 p 結點的下下一個結點的記憶體地址,
C語言標準規定,對于一個符號的定義,編譯器總是從它的名字開始讀取,然后按照優先級順序依次決議,對,從名字開始,不是從開頭也不是從末尾,這是理解復雜指標的關鍵!
對于初學者,有幾種運算子的優先級非常容易混淆,它們的優先級從高到低依次是:
-
定義中被括號
( )括起來的那部分, -
后綴運算子:括號
( )表示這是一個函式,方括號[ ]表示這是一個陣列, -
前綴運算子:星號
*表示“指向xxx的指標”,
在本章中我們最多只用到二級指標因此將對二級指標做下說明,比如int **p,是什么意思?
首先看 *p , “*”表示P是一個指標,但是是指向什么的指標呢?
在看前面的int* ,int是一個整型型別后面加一個“*”表示整型型別的指標,
*p就是指向整型型別指標的指標,p保存的是整型型別指標的地址,
二、警惕指標丟失和記憶體泄漏
不知道你有沒有這樣的感覺,寫鏈表代碼的時候,指標指來指去,一會兒就不知道指到哪里了,所以,我們在寫的時候,一定注意不要弄丟了指標,指標往往都是怎么弄丟的呢?我拿單鏈表的插入操作為例來給你分析一下,
指標往往都是怎么弄丟的呢?我拿單鏈表的插入操作為例來給你分析一下,
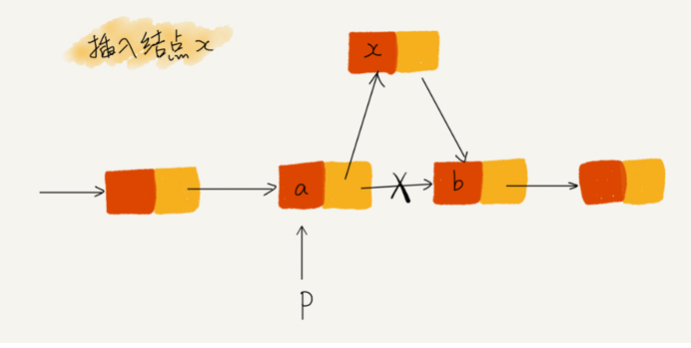
如圖所示,我們希望在結點 a 和相鄰的結點 b 之間插入結點 x,假設當前指標 p 指向結點 a,如果我們將代碼實作變成下面這個樣子,就會發生指標丟失和記憶體泄露,
1 p->next = x; // 將p的next指標指向x結點; 2 x->next = p->next; // 將x的結點的next指標指向b結點;
初學者經常會在這兒犯錯,p->next 指標在完成第一步操作之后,已經不再指向結點 b 了,而是指向結點 x,第 2 行代碼相當于將 x 賦值給 x->next,自己指向自己,因此,整個鏈表也就斷成了兩半,從結點 b 往后的所有結點都無法訪問到了,
對于有些語言來說,比如 C 語言,記憶體管理是由程式員負責的,如果沒有手動釋放結點對應的記憶體空間,就會產生記憶體泄露,所以,我們插入結點時,一定要注意操作的順序,要先將結點 x 的 next 指標指向結點 b,再把結點 a 的 next 指標指向結點 x,這樣才不會丟失指標,導致記憶體泄漏,所以,對于剛剛的插入代碼,我們只需要把第 1 行和第 2 行代碼的順序顛倒一下就可以了,同理,洗掉鏈表結點時,也一定要記得手動釋放記憶體空間,否則,也會出現記憶體泄漏的問題,當然,對于像 Java 這種虛擬機自動管理記憶體的編程語言來說,就不需要考慮這么多了,
三、單鏈表反轉的C語言實作
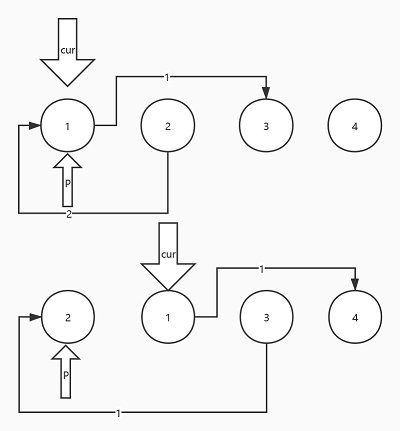
使用p指向第一個結點,cur指向當前結點,每次把cur->next結點摘掉放在p節點前面,然后更新p結點指向頭結點,具體實作代碼如下所示
47 void revers_list(list1 **l) 48 { 49 if(!(*l)||!l) 50 { 51 exit(-1); 52 } 53 54 list1 *start=*l; 55 list1 *start_next=NULL; 56 57 while (start->next) 58 { 59 // 獲取當前節點的后繼節點 60 start_next = start->next; 61 // 將后繼節點摘鏈 72 62 start->next = start_next->next; 63 // 將后繼節點提到最前面 64 start_next->next = *l; 65 // 更新頭節點 66 *l = start_next; 67 } 68 }
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/3620.html
標籤:C