嘗試開發 Java 8 風格的正則運算式以匹配幾個不同字串中的所有非單詞字符,因此我可以拆分它們。唯一的例外是當“:”位于數字之間時,例如“8:00AM”。
到目前為止,我想出了這個:"\W(?:(?<!\d)(?!\d))|[-/](?=\d)"
鑒于下面的字串,我得到了以下結果:
MF:上午 10 點至下午
6 點 MD:上午 9 點/下午 6 點 F:上午 9 點/下午 4 點
Seg-Qui:08h às 17h 性別:08h às 16h
LV:上午 8:00 - 下午 6:00 CST
M、F,上午 10 點到下午 5 點
Lun-Jeu:9 18 小時文:9/17 小時
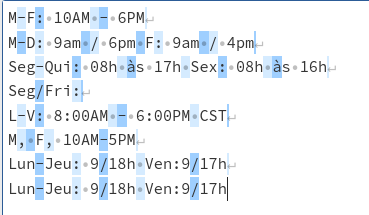
但是,存在以下問題:
在字串Lun-Jeu: 9/18h Ven:9/17h 中,它沒有選擇Ven:9 中的“:” 。
在字串Seg-Qui: 08h às 17h Sex: 08h às 16h 中,如果可能,我還想選擇整個單詞“às”。
任何人都可以幫助修復正則運算式或提供更好的解決方案來實作這一目標嗎?
uj5u.com熱心網友回復:
您可以使用
(?U)\W(?<!\d:(?=\d))
在 Java 中:
String regex = "(?U)\\W(?<!\\d:(?=\\d))";
請參閱正則運算式演示。
詳情:
(?U)-Pattern.UNICODE_CHARACTER_CLASS嵌入標志選項,品牌\d以及\W和其他速記識別Unicode\W- 任何字字符(?<!\d:(?=\d))- 一個否定的lookbehind,匹配一個位置,前面沒有一個數字和:,緊跟一個數字。
要也使數字內的點匹配失敗,請使用(?U)\W(?<!\d[:.](?=\d)). 如果您愿意,您可以在那里添加更多字符。
uj5u.com熱心網友回復:
嘗試這個:
(?<!\d)[^\p{L}\d]|[^\p{L}\d](?!\d)
它選擇任何不是 unicode 字母(即包括à)或數字的東西,但前提是前面沒有數字,或者后面沒有數字。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/370919.html