所以我有這些資料用于訓練模型。某些列中有一些值標記為未知。假設這將是缺失值。
我還得到了一組查詢/測驗資料,這些查詢也有未知值。
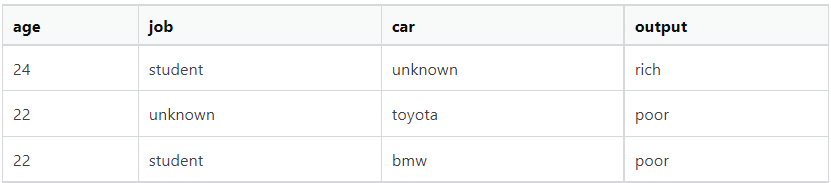
幾個示例資料,訓練集:
預測查詢:

我想根據訓練集中缺失值(未知)的百分比進行插補。但是,查詢也包含一些未知值。最好的方法是什么?是否也可以將未知值視為一個類別?
uj5u.com熱心網友回復:
沒有處理缺失值的通用“最佳方法”。您已經列出了兩個常見的:插補和將“缺失”視為附加類。兩者都“可以”,哪個更合適取決于場景。
在您的情況下,我可以想象缺失實際上是提供資訊的(例如,由于害怕社會污名化,失業人員或從事低薪作業的人更有可能缺少作業特征的值?)。
在這種情況下,將缺失添加到一個額外的類可能是一個好方法。
請注意,一些常見的梯度提升庫(如lightgbm、xgboost )可以默認處理缺失值,因此您可以為您的資料集嘗試其中之一。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/371343.html
下一篇:如何洗掉R中的不規則單詞塊?