前言
好久沒有寫關于技術型別的文章了,很多朋友都催我寫寫,這也快到年底了,所有抽了點時間寫一篇,希望能借此來回饋大家在過去一年中對我的支持,
PS:本文中有3張GIF效果圖太大,沒辦法上傳,追求看完美效果的朋友可以擺駕鏈接:百度網盤 請輸入提取碼 提取碼:xad4 插件高清GIF效果,
需求
今天要分享的技術方案是我在寫bg-boom這款插件當中一小塊的代碼實作方案,先從需求說起吧,其模塊整體的需求是豐富idea的背景功能,具體需求為:
-
讓idea背景功能支持圖片
-
讓idea背景功能支持gif圖片
-
讓idea背景功能支持視頻(既動態桌面的效果)
-
讓idea背景功能支持廣播收聽
-
讓idea背景功能支持TV在線收看
-
讓idea背景功能支持直播在線收看(要支持MMS、RTMP、RTCP、RTSP、M3U8等直播流協議)
-
讓idea背景功能支持音樂在線播放(既實作在線音樂播放器的功能)
-
讓idea支持從網頁中自動爬取圖片、視頻、直播流等資源自動播放
-
讓idea所有產品都能夠支持以上功能,包括但不限于IntelliJ IDEA、WebStorm、DataGrip 、Android Studio、CLion 、PhpStorm 、PyCharm等產品
-
讓idea在linux、window、mac平臺上也支持以上功能
效果
以上需求文字理解較為晦澀難懂,就先看看最終的實作效果,感受一下需求最終實作的效果吧:
PS:由于gif太大,在這里我只放了一張網路視頻的效果圖,要聽聲音的朋友可以轉看,效果更佳: Idea炫酷的視頻背景插件Bg-boom_嗶哩嗶哩_bilibili
現狀分析
簡單理解以上需求后,總是要擼起袖子干事情的,就先從idea現狀對背景的支持開始吧,經過一番原始碼的閱讀操作,最終可以發現idea背景功能支持有些簡單,如下:
-
idea自身支持背景功能(萬幸)
-
idea只支持背景圖片(非常遺憾視頻不支持)
-
idea支持圖片的翻轉、平鋪、透明度等樣式微調
2021.2.3版本的背景功能截圖如下(不同產品和版本可能存在差異):
架構設計
通過對idea現狀分析后,可以清晰的得出一個結論就是:要實作自己的需求,那么基本是對背景功能的重新實作,Do it!
第一步:拆分需求功能
先歸納一下在需求描述中對于實作的關鍵點,是讓idea支持圖片、gif圖片、視頻、直播、廣播、在線音樂的支持,就這樣理解還是不夠直觀,那就再做一次抽象轉換:
-
圖片=圖片
-
gif圖片=圖片+圖片(PS:是由多幀圖片組成)
-
視頻=圖片+聲音(PS:視頻就是由多幀圖片和聲音組成)
-
直播=圖片+聲音(PS:直播就是由多幀圖片和聲音組成)
-
電影=圖片+聲音(PS:電影就是由多幀圖片和聲音組成)
-
廣播=聲音(PS:廣播就是由聲音組成)
-
音樂=聲音(PS:音樂就是由聲音組成)
經過這次轉換我們就可以清楚的發現,需求中提出的功能實際對于idea來說就是單獨放圖片、單獨放聲音、同時放圖片和聲音的需求,是不是頓時簡單好理解一大半,
總結:拆分后的需求就是要求idea可以背景播放圖片和聲音,圖片和聲音可在一定條件下單獨開啟,
第二步:架構設計
-
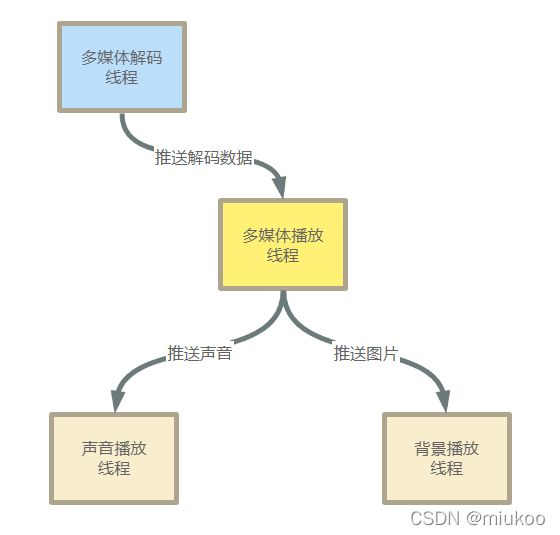
理解拆分需求之后,軟體需要實作圖片和聲音的同時播放,因此可以先架構兩個并行的執行緒:
-
聲音播放執行緒:主要用于輸出聲音資料到聲卡
-
背景播放執行緒:主要用于輸出圖片到idea背景
Q1:背景圖片播放能重用Idea自動的背景功能嗎? A1:通過原始碼的分析,Idea背景圖片的功能,存在深度快取,并且存在系列不必要的計算,在性能上不太滿足視頻的播放需要,因此背景功能也需要重實作,
-

-
在idea中圖片可以直接支持,但是視頻、流需要自己實作決議,因此還需要架構兩個執行緒來完成視頻、流的決議作業:
-
多媒體解碼執行緒:主要用于獲取視頻、直播、音樂、TV、當中的圖片和聲音解碼,并推送給多媒體播放執行緒播放
-
多媒體播放執行緒:主要實作一個播放時鐘,到播放點把聲音和圖片推送給對應執行緒進行播放處理
Q2:為什么不在解碼執行緒中直接推送聲音和圖片播放? A2:簡單說,10M的視頻,解碼指需要1s鐘,但是播放可能需要持續3分鐘,這個程序中性能處理是不對等的;再加上多媒體中聲音和圖片存在資料交叉情況,最侄訓是分成2個執行緒來處理,較為簡單易維護, ? Q3:多媒體播放執行緒只是到點推送播放資料的功能嗎? A3:多媒體播放執行緒除了推送播放資料的功能,其實還有一個非常重要的功能,就是協調聲音和圖片畫面的同步問題;因為在聲音和畫面在并行兩個執行緒中執行,一個執行緒執行慢一點,就會導致聲音和畫面的不一致,這種現象當然需要考慮并解決,
-
-
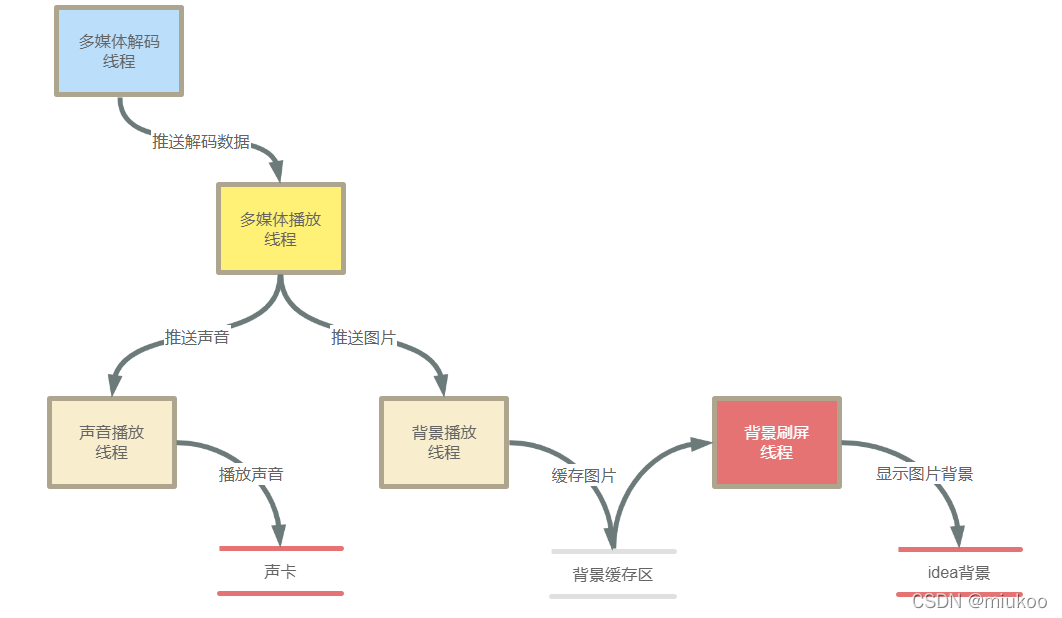
在實作程序中,由于性能和體驗的權衡,最終把方法調整成為用5個并行執行緒來實作整個功能,
-
背景刷屏執行緒:主要把背景圖片繪制到idea背景顯示
-
背景播放執行緒:調整后,最終只會把要輸出的圖片放置到背景快取區中,不負責顯示圖片
Q4:為什么增加背景刷屏執行緒? A4:在調優程序中,發現idea背景輸出引起的GUI界面重繪不能在短時間內完成,因此畫面延遲出現的情況出現較為頻繁,為解決此問題,設計一個背景緩沖區,緩沖區內的圖片只存盤即將顯示的那張圖片,如果背景刷屏執行緒過慢,就會導致緩沖區中的圖片被新的快取圖片所覆寫,這樣的效果恰是畫面延遲后跳幀顯示畫面的效果,因此巧妙的實作了當前idea畫面重繪延遲時,跳幀顯示圖片,以達到聲音和圖片同步的效果,因此增加此執行緒,即為明智,
-
看到這里,不容易,看會電視先休息一下吧~~
技術選型
以上需求要實作,用到的技術其實并不多,簡單介紹一下以上方案的關鍵技術選型:
-
視頻解碼:選型使用的是javacv;(ps:java對視頻解碼支持并不完善,只能借助javacv完成,實際上javacv是封裝了ffmpeg)
-
執行緒同步:這里5個執行緒之間需要協作同步,主要使用ReentrantLock鎖來同步
-
畫面顯示:畫面顯示不需要特殊技術,重新Idea的PaintersHelper即可,但由于idea源代碼的作用域限制,實作改步需要使用大量反射操作來完成
技術實作
由于實作的代碼過多,再這里就不粘貼出來了,感興趣的同學可以到我個人訂閱號領取:
-
掃描訂閱
-
在訂閱號
-
回復【視頻代碼】4個字領取以上功能的多執行緒實作原始碼
-
回復【動態背景】4個字查看效果演示視頻
-
性能優化
感興趣代碼實作的朋友可以同上述方式,自行領取資料,在這里我主要分享一下實作完成功能之后對代碼的優化程序,
01、完成第一版發現問題
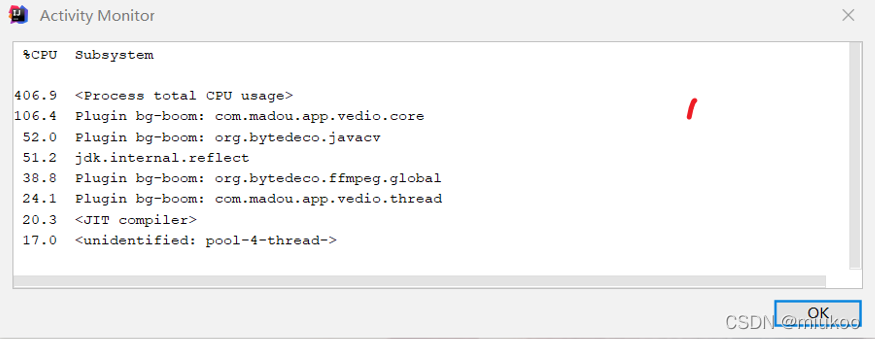
功能基本實作完成之后,發現運行效果能達到預期,但是CPU占用非常高,如下圖:
-
下圖中帶有 madou、javacv、ffmpeg都是自身程式的實作,發現占用CPU非常高
02、拆包定位性能消耗點
在com.madou.app.vedio.core和thread包中都有多個實作類,不夠直觀發現那個類會有問題,因此建立多個包,每個包下只放一個類檔案,再次運行:
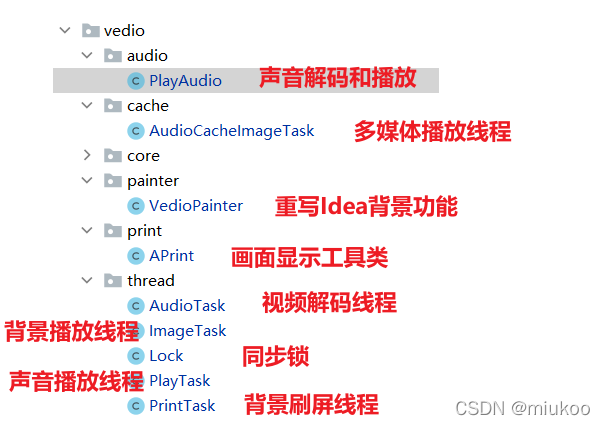
PS:下圖中第一次CPU占406%,第二次占270%,這是由計算機自身的狀態產生的偏差,在此忽略,
從下圖可以看出:
-
com.madou.app.vedio.print占用非常高,其下面的類主要用于把圖片重繪到idea背景區域顯示
-
com.madou.app.vedio.audio占用非常高,其下面的類主要是進行聲音解碼和聲音播放的代碼
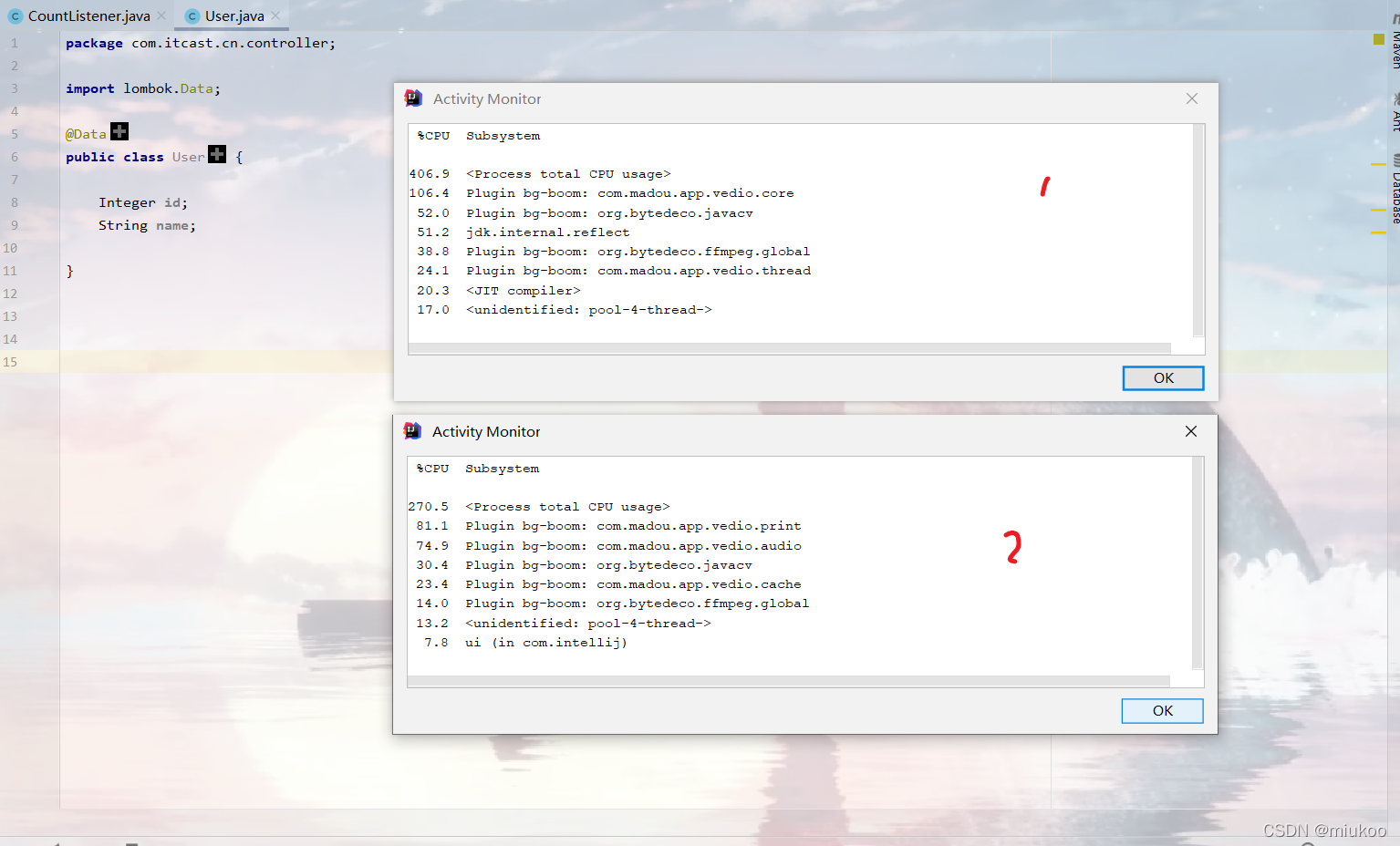
03、原因分析
-
先分析com.madou.app.vedio.print包,其下面只有一個用于把Image繪制到Idea背景區域顯示的程式,非常簡單,貌似此代碼的優化空間不太大,先跳過,
private void drawGraphics(Image image, Graphics2D g, Rectangle dstBounds) { if(image!=null) { g.drawImage(image,dstBounds.x,dstBounds.y, Double.valueOf(dstBounds.getWidth()).intValue(), Double.valueOf(dstBounds.getHeight()).intValue(),null); } } -
解密幀資料
public byte[] parseToByte(Buffer[] samples) { if(samples==null){ return null; } int k; buf = samples; switch(sampleFormat){ case avutil.AV_SAMPLE_FMT_FLTP://平面型左右聲道分開, leftData = (FloatBuffer)buf[0]; TLData = floatToByteValue(leftData,vol); rightData = (FloatBuffer)buf[1]; TRData = floatToByteValue(rightData,vol); tl = TLData.array(); tr = TRData.array(); combine = new byte[tl.length+tr.length]; k = 0; for(int i=0;i<tl.length;i=i+2) {//混合兩個聲道, for (int j = 0; j < 2; j++) { combine[j+4*k] = tl[i + j]; combine[j + 2+4*k] = tr[i + j]; } k++; } return combine; case avutil.AV_SAMPLE_FMT_S16://非平面型左右聲道在一個buffer中, ILData = (ShortBuffer)buf[0]; TLData = shortToByteValue(ILData,vol); tl = TLData.array(); return tl; case avutil.AV_SAMPLE_FMT_FLT://float非平面型 leftData = (FloatBuffer)buf[0]; TLData = floatToByteValue(leftData,vol); tl = TLData.array(); return tl; case avutil.AV_SAMPLE_FMT_S16P://平面型左右聲道分開 ILData = (ShortBuffer)buf[0]; IRData = (ShortBuffer)buf[1]; TLData = shortToByteValue(ILData,vol); TRData = shortToByteValue(IRData,vol); tl = TLData.array(); tr = TRData.array(); combine = new byte[tl.length+tr.length]; k = 0; for(int i=0;i<tl.length;i=i+2) { for (int j = 0; j < 2; j++) { combine[j+4*k] = tl[i + j]; combine[j + 2+4*k] = tr[i + j]; } k++; } return combine; default: break; } return null; } -
再分析com.madou.app.vedio.audio包,其PlayAudio類主要是用于解密幀資料和播放幀資料、還有檢查聲卡快取剩余資料
-
播放幀資料
public void play(byte[] data) { if(sourceDataLine!=null&&data!=null){ sourceDataLine.write(data,0,data.length); } } -
檢查聲卡剩余播放資料
public boolean shouldLoadVoice(){ if(sourceDataLine!= null&&sourceDataLine.isRunning()){ return sourceDataLine.available()>sourceDataLine.getBufferSize()*9/10; } return false; }
-
04、聲音解碼優化
從以上分析可以初步定位到聲音解碼最有可能引起CPU占用高,因此優先對此優化,那么優化的思路是怎樣的呢?大致有以下幾種方式:
-
從演算法上優化:聲卡資料基本都需要單位元組的進行處理,所以此方式基本優化空間不大(直接PASS),
-
從記憶體上優化:提前把聲卡資料一次性解碼后快取起來,這樣再播放的時候就不再占用CPU解碼了(唯一方案,Do it!),
經過以上分析,從記憶體上快取來減少CPU的使用的方案是優先方案,因此先證明一下可行性,
04.1 測驗幾個視頻的聲卡資料,看快取方案是否可行
先提取幾個視頻的聲卡資料,通過大小判斷一下是否記憶體能夠快取存盤,于是測驗了3個視頻,結果如下:
| 序號 | 視頻大小 | 聲卡資料大小 |
|---|---|---|
| 1 | 3M | 1.7M |
| 2 | 122M | 34M |
| 3 | 6G | 1.8G |
通過上述簡單的測驗,我們的需求中定位的視頻大小在100M以內,聲卡在34M左右,一般電腦的記憶體都能夠完全存盤,因此記憶體方案基本可行,但是如果萬一有用戶弄4K高清視頻怎么辦呢?上G的聲卡資料并不是每個用戶都能負擔的,因此完全快取又似乎不可行,
小插曲:比如下面有哥們真用idea真試了試播放了4K高清的007電影,電影檔案6.87G,觀賞一下效果吧~~~
沒錯上面放4K高清電影的哥們就是本人,作為一個技術控,絕不容忍IDEA不能放電影做背景,因此必須解決大視頻聲卡快取資料的問題,那么怎么解決了,如果聲卡資料都快取,記憶體不夠,不快取CPU又高,這種情況呀就只能找一個平衡點,依然使用記憶體快取聲卡資料,但是要設定一個快取上限,防止大視頻聲卡資料超出 JVM 堆大小,進而引起GC,GC導致畫面卡頓,但是選這個快取上限應該設定多少呢?每個用戶的記憶體大小不相同,這個上限點不好定義,怎么辦?可不可以動態設定記憶體快取空間大小呢?答案是可以的,
經過上述糾結后,最終定的方案是依然使用記憶體快取聲卡資料,并依據空閑記憶體大小動態設定快取上限,防止大視頻聲卡資料超出JVM堆大小,進而引起GC,GC導致畫面卡頓,
記憶體上限計算公式為:動態快取上限幀數 = JVM 空閑記憶體大小 / 2 / 每幀音頻大小中值
以上公式的基本理解是,把用戶電腦中 JVM 一半的空閑空間拿來作為幀資料快取空間,并除以平均每幀音頻大小,即得到總的快取幀數,
04.2 測驗幾個視頻的每幀音頻大小
通過以下粗糙的測驗,簡單取65KB作為平均每幀音頻的大小,
| 序號 | 視頻大小 | 聲卡資料大小 | 每幀音頻大小 |
|---|---|---|---|
| 1 | 3M | 1.7M | 20KB |
| 2 | 122M | 34M | 73KB |
| 3 | 6G | 1.8G | 65KB |
04.3 實作動態音頻快取
明白以上計算公式之后,其實實作就較為簡單了,但是在這里一定要提醒一下各位,JAVA中快取的實作一定要用軟參考去實作,以保障在IDEA程式大量使用記憶體的時候可以有效的釋放音頻幀的快取,畢竟IDEA的功能是優先需要去保障的,
/**
* 快取音瞥澩,減少CPU資源的消耗
*/
SoftReference<ConcurrentHashMap<Long,PlayFrame>> voiceLocalCache = new SoftReference<ConcurrentHashMap<Long,PlayFrame>>(new ConcurrentHashMap<>());
?
/**
* 動態計算最大的快取數量
*/
volatile int maxLocalCache = 0;
?
/**
* 動態計算最大的快取數量,在第一次播放完成后,動態調整計算
*/
volatile int avgLocalCache = 0;04.4 驗證第一版本優化思路
下圖中標記為3的圖片就是優化后的性能,發現CPU有所下降,但是不明顯,難道我們搞錯了?
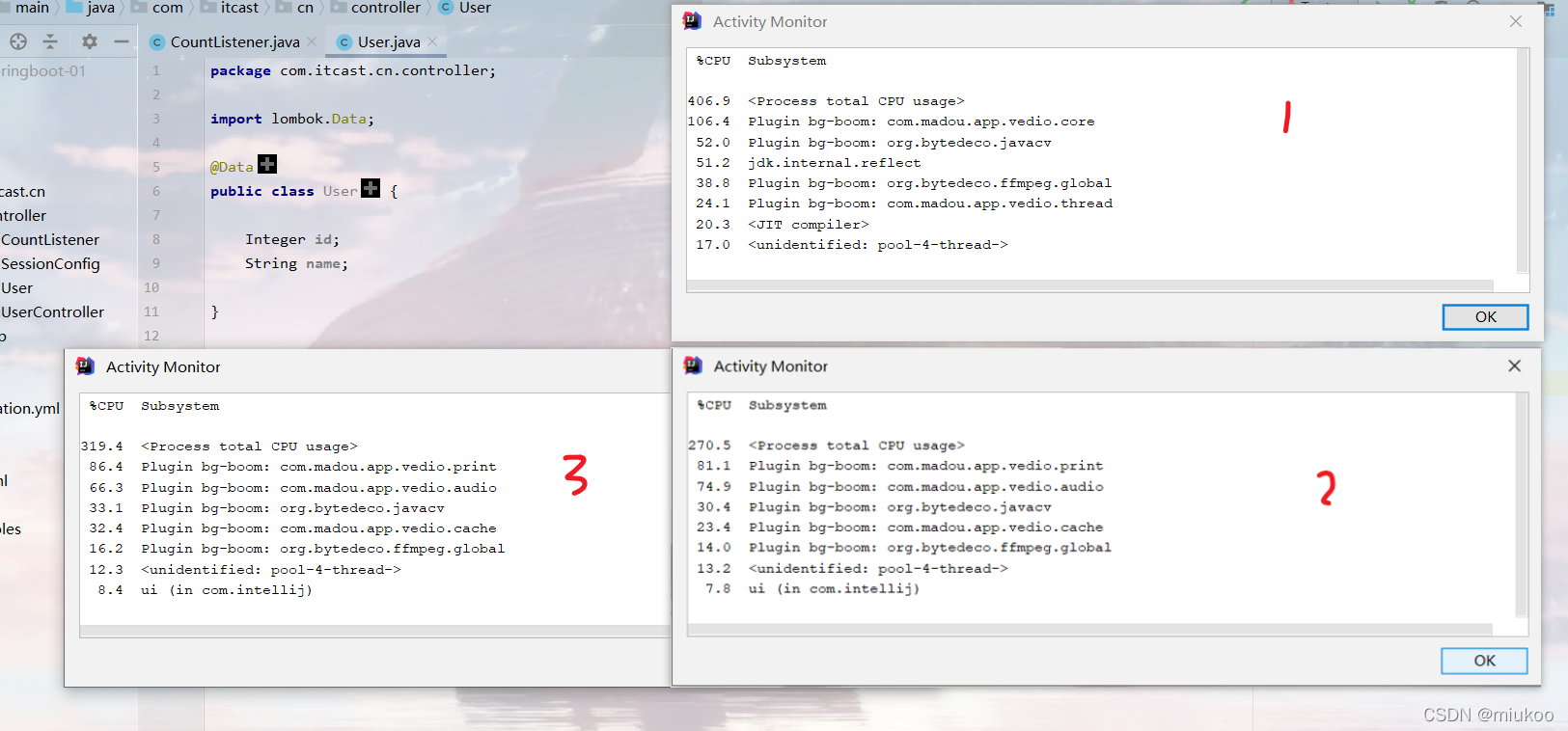
05、最終優化
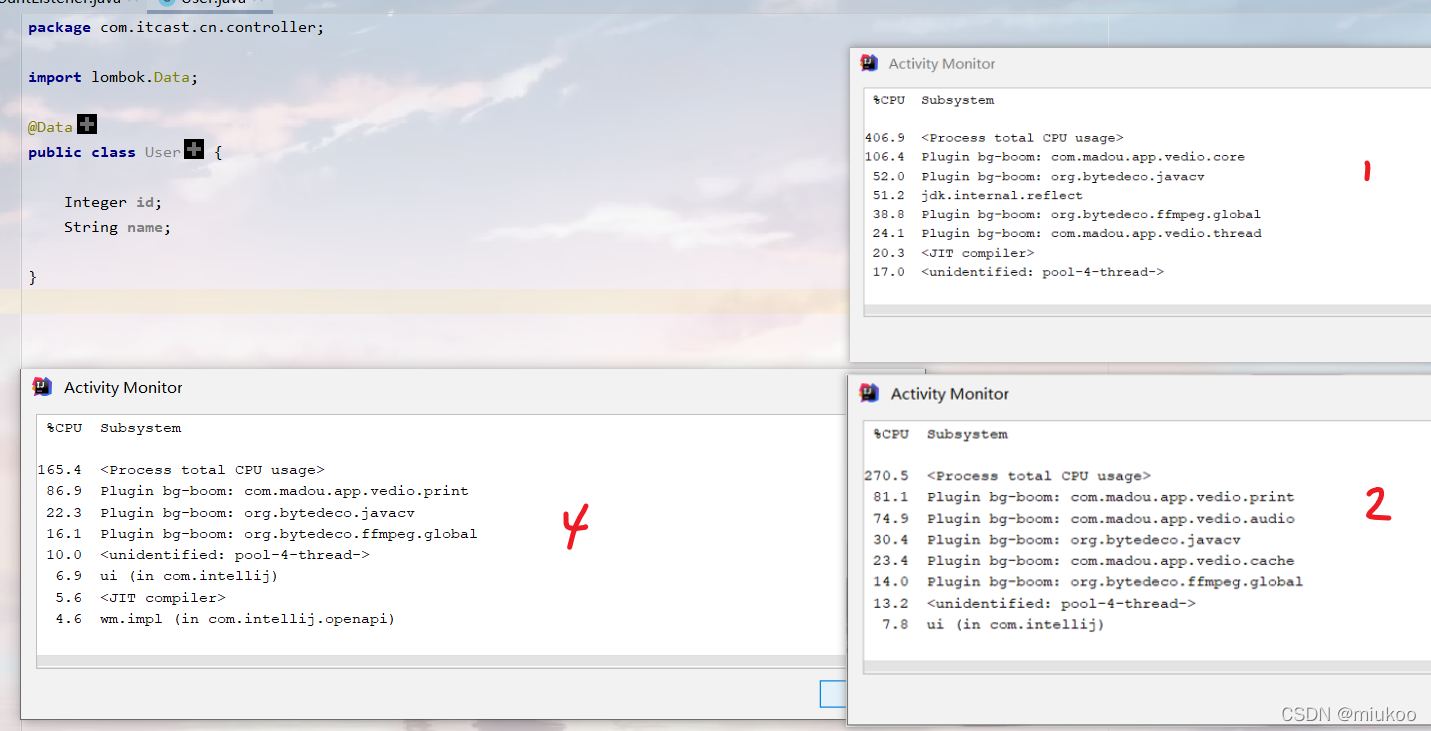
經過對上述聲音解碼的優化效果并不明顯,那么說明程式CPU消耗點并不在此上面,因此繼續分析,上面提到的聲卡就是寫資料,不可能存在性能問題,即使存在也優化不了,所以先跳過,再排查"檢查聲卡剩余播放資料"的程式,通過日志列印的方式,發現上層「多媒體播放執行緒」每微妙就會呼叫"檢查聲卡剩余播放資料"程式,導致CPU過高,(PS:多媒體播放執行緒中是一個回圈計時程式,每回圈一次就檢查一次聲卡是否還有播放的資料,如果不夠,就立即寫入新的聲卡資料,實作邏輯是正常的),定位到這個問題之后,其實解決起來就比上述優化簡單多了,直接通過休眠執行緒來減少對"檢查聲卡剩余播放資料"程式的呼叫即可,最終優化后成功降下了CPU指標,
結束
經過上述優化,插件性能指標能夠基本使用,但是CPU還是占用太高,所以優化會再繼續,無止境!有意思的是我和迅雷影音比較過CPU使用率,在播放開始的時候CPU消耗差不多,但是隨著播放的時間推移,迅雷影音就會下降一半CPU占用率,這是否得益于迅雷影音使用了硬體加速?懷揣好奇的心態嘗試了把java中BufferedImage圖片換成了支持硬體加速的VolatileImage圖片,發現JAVA中死活都開啟不了硬體加速,就等于VolatileImage的性能是無效的,研究了一天,無結果,就先把這個版本先提交了吧!下個版本再來優化~,點贊~ 收藏~ 一起加油吧~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/374740.html
標籤:java
上一篇:一文看懂JVM運行時記憶體分布
下一篇:【資料結構】圖解七大排序