概述
京東的商品評論目前已達到數十億條,每天提供的服務呼叫也有數十億次,而這些資料每年還在成倍增長,而資料存盤是其中最重要的部分之一,接下來就介紹下京東評論系統的資料存盤是如何設計的,
整體資料存盤包括基礎資料存盤、文本存盤、資料索引、資料快取幾個部分,
基礎資料存盤
基礎資料存盤使用 MySQL,因用戶評論為文本資訊,通常包含文字、字符等,占用的存盤空間比較大,為此 MySQL 作為基礎資料庫只存盤非文本的評論基礎資訊,包括評論狀態、用戶、時間等基礎資料,以及圖片、標簽、點贊等附加資料,而不同的資料又可選擇不同的庫表拆分方案,參考如下:
- 評論基礎資料按用戶 ID 進行拆庫并拆表;
- 圖片及標簽處于同一資料庫下,根據商品編號分別進行拆表;
- 其它的擴展資訊資料,因資料量不大、訪問量不高,處理于同一庫下且不做分表即可,
因人而異、因系統而異,根據不同的資料場景選擇不同存盤方案,有效利用資源的同時還能解決資料存盤問題,為高性能、高可用服務打下堅實基礎,
文本存盤
文本存盤使用了 mongodb、hbase,選擇 nosql 而非 mysql,一是減輕了 mysql 存盤壓力,釋放 msyql,龐大的存盤也有了可靠的保障;二是 nosql 的高性能讀寫大大提升了系統的吞吐量并降低了延遲,存盤的升級程序嘗試了 cassandra、mongodb 等分布式的 nosql 存盤,cassandra 適用于寫多讀少的情況,而 mongodb 也是基于分布式檔案存盤的資料庫,介于關系型資料庫與非關系型資料庫之間,同時也是記憶體級資料庫,mongo 寫性能不及 cassandra,但讀寫分離情況下讀性能相當不錯,因此從應用場景上我們選擇了 mongodb,mongodb 確實不錯,也支持了系統穩定運行了好幾年,
但從今后的資料增長、業務擴增、應用擴展等多方面考慮,hbase 才是最好的選擇,它的存盤能力、可靠性、可擴展性都是毋庸置疑的,選擇了 hbase,只需要根據評論 ID 構建 Rowkey,然后將評論文本資訊進行存盤,查詢時只需要根據 ID 便能快速讀取評論的文本內容,當然也可將評論的其它欄位資訊進行冗余存盤,這樣根據評論 ID 讀取評論資訊后不用再從 mysql 進行讀取,減少資料操作,提升查詢性能,
資料索引
京東的評論是以用戶和商品兩個維度進行劃分的,對于用戶而言,用戶需要發表評論、上傳曬圖、查看自己的評論等,因此 mysql 資料庫中只要根據用戶 ID 對評論資料進行拆庫拆表進行存盤,便能解決用戶資料讀寫問題,而對于商品而言,前臺需要將統計商品的評論數并將所有評論展示出來,后臺需根據評論的全欄位進行檢索同時還帶模糊查詢,而評論資料是按 userId 進行庫表拆分的,現在要按商品去獲取評論,顯然當前的拆分庫是無法實作的,起初考慮過根據商品編號再進行拆庫拆表,但經過多層分析后發現行不通,因為再按商品編號進行拆分,得再多加一倍機器,硬體成本非常高,同時要保持用戶及商品兩維度的分庫資料高度一致,不僅增加了系統維護成本及業務復雜度,同時也無法解決評論的資料統計、串列篩選、模糊查詢等問題,為此引入了全文檢索框架solr(前臺)/elasticsearch(后臺)進行資料索引,
資料索引其實就是將評論資料構建成索引存盤于索引服務中,便于進行評論資料的模糊查詢、條件篩選及切面統計等,以彌補以上資料存盤無法完成的功能,京東評論系統為此使用了 solr/elasticsearch 搜索服務,它們都是基于 Lucene 的全文檢索框架,也是分布式的搜索框架( solr4.0 后增加了solr cloud 以支持分布式),支持資料分片、切面統計、高亮顯示、分詞檢索等功能,利用搜索框架能有效解決前臺評論資料統計、串列篩選問題,也能支持后臺系統中的關鍵詞顯示、多欄位檢索及模糊查詢,可謂是一舉多得,
搜索在構建索引時,屬性欄位可分為存盤欄位與索引欄位,存盤欄位在創建索引后會將內容存盤于索引檔案中,同時也會占用相應的索引空間,查詢后可回傳原始內容,而索引欄位創建索引后不占用索引空間也無法回傳原始內容,只能用于查詢,因此對于較長的內容建議不進行存盤索引,
評論搜索在構建索引時,主鍵評論 ID 的索引方式設定為存盤,其它欄位設定為索引,這樣不僅減少索引檔案的存盤空間,也大大提升了索引的構建效率與查詢性能,當然,在使用搜索框架時,業務資料量比較小的也可選擇將所有欄位進行存盤,這樣在搜索中查詢出結果后將不需要從資料庫上查詢其它資訊,也減輕了資料庫的壓力,
為了更好地應對前后臺不同的業務場景,搜索集群被劃分為前臺搜索集群和后臺搜索集群,
前臺搜索集群根據商品編號進行索引資料分片,用于解決評論前臺的評論數統計、評論串列篩選功能,評論數統計,如果使用常規資料庫進行統計時,需要進行 sql 上的 group 分組統計,如果只有單個分組統計性能上還能接受,但京東的評論數統計則需要對 1 到 5 分的評論分別進行統計,分組增加的同時隨著統計量的增加資料庫的壓力也會增加,因此在 mysql 上通過 group 方式進行統計是行不通的,而使用solr 的切面統計,只需要一次查詢便能輕松地統計出商品每個分級的評論數,而且查詢性能也是毫秒級的,切面統計用法如下:
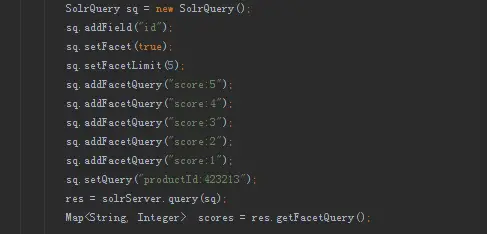
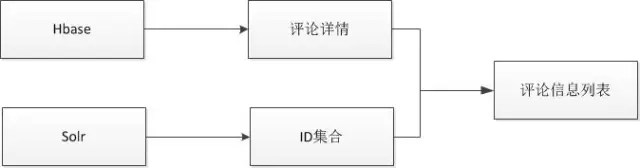
評論串列,只需根據條件從搜索中查詢出評論 ID 集合,再根據評論 ID 到 mysql、Hbase 中查詢出評論的其它欄位資訊,經過資料組裝后便可回傳前臺進行展示,
后臺搜索集群 評論后臺系統需要對評論進行查詢,其中包括關鍵詞高亮顯示、全欄位檢索、模糊查詢等,為此 solr/elasticsearch 都是個很好的選擇,目前使用 elasticsearch,
資料快取
面對數十億的資料請求,直接擊穿到 mysql、搜索服務上都是無法承受的,所以需要對評論資料進行快取,在此選擇了高性能快取 redis,根據不同的業務資料進行集群劃分,同時采用多機房主從方式部署解決單點問題,這樣只需要對不同的快取集群進行相應的水平擴展便能快速提升資料吞吐能力,也有效地保證了服務的高性能、高可用,
當然,快取設計時還有很多細節可以進行巧妙處理的,如:
- 當用戶新發表一條評論,要實作前臺實時展示,可以將新增的評論數向首屏串列快取中追加最新的評論資訊;
- 評論數是讀多寫少,這樣就可以將評論數持久化到 redis 當中,只有當資料進行更新時通過異步的方式去將快取重繪即可;評論數展示可通過 nginx+lua 的方式提供服務,服務請求無需回源到應用上,不僅提升服務性能,也能減輕應用系統的壓力;
- 對于評論串列,通常訪問的都是第一屏的資料,也就是第一頁的資料,可以將第一頁的資料快取到 redis當中,有資料更新時再通過異步程式去更新;
- 對于秒殺類的商品,評論資料可以結合本地快取提前進行預熱,這樣當秒殺流量瞬間涌入的時候也不會對快取集群造成壓力;通過減短 key 長度、去掉多余屬性、壓縮文本等方式節省記憶體空間,提高記憶體使用率,
資料容災與高可用
引入了這么多的存盤方案就是為了解決大資料量存盤問題及實作資料服務的高可用,同時合理的部署設計與相應的容災處理也必須要有的,以上資料存盤基本都使用多機房主從方式部署,各機房內部實作主從結構進行資料同步,如圖:
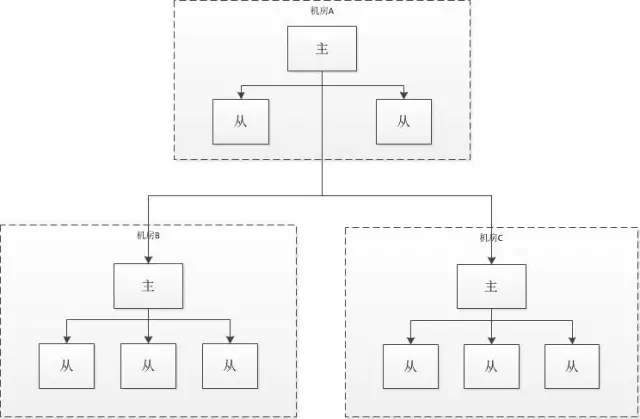
MySQL 集群資料庫拆庫后需要對各分庫進行多機房主從部署,系統應用進行讀寫分離并根據機房進行就近呼叫,當主機房資料庫出現故障后將故障機房的資料操作都切換到其它機房,待故障排除后再進行資料同步與流量切換,
使用主從機房部署的方式,所有資料更新操作都要在主庫上進行,而當主機房故障是需要通過資料庫主從關系的重建、應用重新配置與發布等一系列操作后才能解決流量切換,程序較為復雜且影響面較大,所以這是個單點問題,為此實作資料服務多中心將是我們下一個目標,
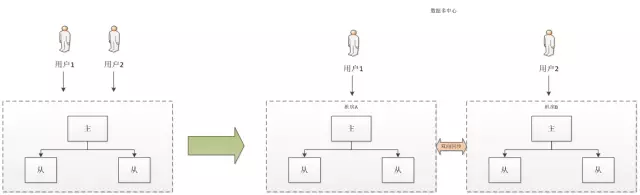
多中心根據特定規則將用戶分別路由到不同機房進行資料讀寫,各機房間通過資料總線進行資料同步,當某一機房出現故障,只需要一鍵操作便能快速地將故障機房的用戶流量全部路由到其它機房,實作了資料的多寫多活,也進一步實作了服務的高可用,資料多中心如下:
hbase 集群目前使用的是京東的公有集群,實作了雙機房主備部署,主集群出現故障后自動將流量切換到備用集群,而當 hbase 整個集群故障時還可對其進行降級,同步只寫入快取及備用存盤 mongo,待集群恢復后再由后臺異步任務將資料回寫到 hbase 當中,
搜索集群根據商品編號進行索引資料分片多機房主從部署,并保證至少 3個從節點并部署于多個機房當中,當主節點出現故障后從這些從節點選取其中一個作為新的主提供服務,集群主節點只提供異步任務進行索引更新操作,從節點根據應用機房部署情況提供索引查詢服務,
Redis 快取集群主從部署仍是標配,主節點只提供資料的更新操作,從節點提供前臺快取讀服務,實作快取資料的讀寫分離,提升了快取服務的處理能力,當主節點出現故障,選取就近機房的一個從節點作為新主節點提供寫服務,并將主從關系進行重新構建,任何一從節點出現故障都可通過內部的配置中心進行一鍵切換,將故障節點的流量切換到其它的從節點上,
總結
整體資料架構并沒有什么高大上的設計,而且整體資料架構方案也是為了解決實際痛點和業務問題而演進過來的,資料存盤方案上沒有最好的,只有最適合的,因此得根據不同的時期、不同的業務場景去選擇合適的設計才是最關鍵的,大家有什么好的方案和建議可以相互討論與借鑒,系統的穩定、高性能、高可用才是王道,
原文鏈接:https://mp.weixin.qq.com/s/X5dsgH5JpmETDjw_UEn7ww
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/375113.html
標籤:Java