微信搜索 【微觀技術】,關注這個不喜歡內卷的程式員,
精彩文章匯總 GitHub https://github.com/aalansehaiyang/technology-talk ,Star 12K ,匯總java生態圈常用技術框架、開源中間件,系統架構、資料庫、大公司架構案例、常用三方類別庫、專案管理、線上問題排查、個人成長、思考等知識
大家好,我是Tom哥~
作為一名技術從業人員,性能優化是每個人的必修課
就像大學時期給漂亮妹子修電腦的絕招就是“重啟電腦一樣”,性能優化也有自己的必殺技

你一定聽過一句話:性能不夠,快取來湊!對,你沒聽錯,就是快取,
但是,哈哈,也不是拿來主義,張手就來,
這不,小王接到一個秒殺活動任務,設計技術方案,大量的資料扔到快取里,想借助Redis的高吞吐量來抗住峰值壓力,
這個思路也沒錯,這不一評估快取內容占用的空間大小,需要30來個G,
你覺得有沒有問題?
覺得沒問題的同學,可以去打游戲了
我們知道Redis集群有主從模式或者哨兵模式
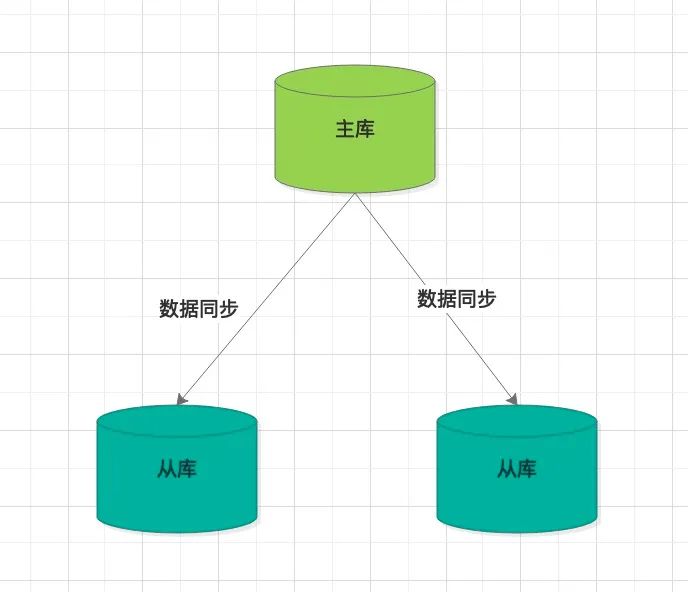
無論采用采用那種模式,從節點同步資料時,開始需要fork子行程,生成RDB檔案,如果資料容量過大,那么占用的時間會很長,如果主節點再開啟持久化機制,那性能就更沒法保證,
為了解決這個問題,Redis 又提出了一個新的解決方案,將大資料碎片化
假如原來一個節點存了30G的資料,現在我們拆分6個實體,每個實體的資料就只有5個G,壓力一下小了很多
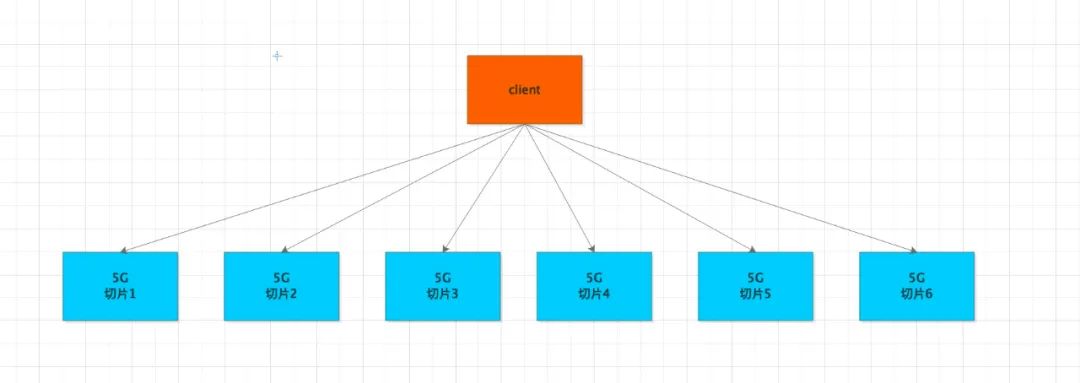
特別說明:由于key的路由規則基于特殊的負載演算法,實際上并不是均等分配,
接下來,我們重點討論的是,這個拆分方案要如何設計?
民間方案
Redis 3.0 版本之前,官方還沒有提供集群方案,但是單臺實體受記憶體限制,無法實作垂直擴展,怎么辦?
一些人提出了基于客戶端的磁區方案,
比如:基于客戶端磁區的 ShardedJedis,基于代理的 Codis、Twemproxy 等,后面掛載著若干個Redis實體,不同實體間完全隔離,互不通信,通過客戶端代理組成了一個邏輯上的集群,從而解決龐大的資料容量問題,
官方方案
Redis 官方在 3.0 版本 提出一個集群方案,稱為 Redis Cluster,
Redis Cluster 核心設計引入一個哈希槽(Hash Slot),將整個集群切成了 16384 個哈希槽,你可以理解成一個個小的資料磁區,
當我們操作Redis 時,根據傳入的 key ,按照 CRC16演算法計算出一個16位的二進制值,然后再對16384取模,便得到一個哈希槽編號,
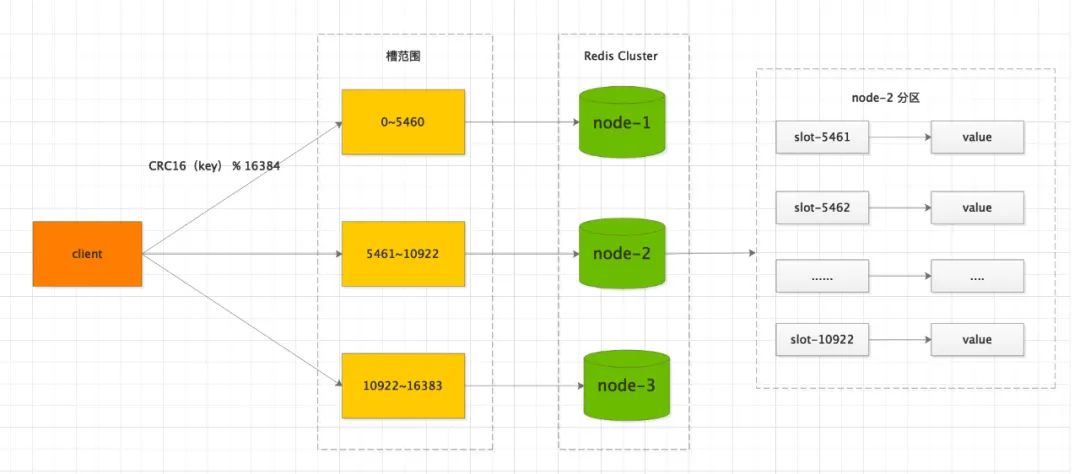
注意:如果手動分配哈希槽,一定要把16384全部分配完,否則 Redis 集群無法作業,
Redis Cluster 如何構建
分為手動搭建和自動搭建
我們先來看下純手動如何搭建一個Redis Cluster集群,
首先,準備機器,為了方便測驗,我們只用一臺,通過不同埠模擬出 6個Redis 實體
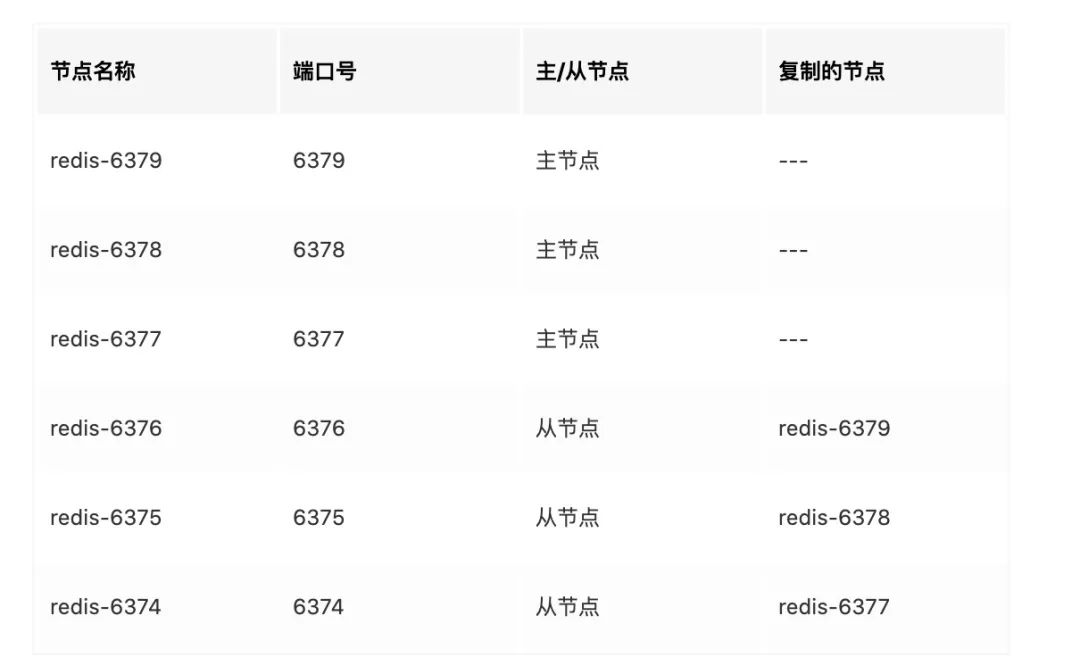
1、構建三個目錄:conf、data、log,分別存放 配置、資料 和 日志 相關檔案,
修改conf組態檔如下
# redis后臺運行
daemonize yes
# 資料存放目錄
dir /usr/local/redis-cluster/data/redis-6379
# 日志檔案
logfile /usr/local/redis-cluster/log/redis-6379.log
# 埠號
port 6379
# 開啟集群模式
cluster-enabled yes
# 集群的配置,組態檔首次啟動自動生成
# 這里只需指定檔案名即可,集群啟動成功后會自動在data目錄下創建
cluster-config-file "nodes-6379.conf"
# 請求超時,設定10秒
cluster-node-timeout 10000
2、啟動節點
sudo redis-server conf/redis-6379.conf
3、集群中各個節點握手通信,組成集群,握手命令 cluster meet {ip} {port},握手成功后該狀態通過Gossip協議在集群中傳播,其它節點就會自動發現新節點并發起握手,最后所有節點都彼此感知并組成集群)
127.0.0.1:6379> cluster meet 127.0.0.1 6378
127.0.0.1:6379> cluster meet 127.0.0.1 6377
127.0.0.1:6379> cluster meet 127.0.0.1 6376
127.0.0.1:6379> cluster meet 127.0.0.1 6375
127.0.0.1:6379> cluster meet 127.0.0.1 6374
4、分配哈希槽,總共有16384個槽位,每個節點實體分配了一定數量的哈希槽
redis-cli -p 6379 cluster addslots {0..5461}
redis-cli -p 6378 cluster addslots {5462..10922}
redis-cli -p 6377 cluster addslots {10922..16383}
5、三個主節點分配完槽位后,每個主節點掛載相應的從節點,用于緊急情況下故障轉移,從節點負責復制主節點槽資訊和業務資料
# 進入從節點客戶端
redis-cli -p 6376
127.0.0.1:6376> cluster replicate 7d480c106752e0ba4be3efaf6628bd7c8c124013(6379主節點的實體ID)述:
詳細步驟:https://juejin.cn/post/6844904057044205582
6、執行命令 cluster slots,查看集群各個節點的槽位分布
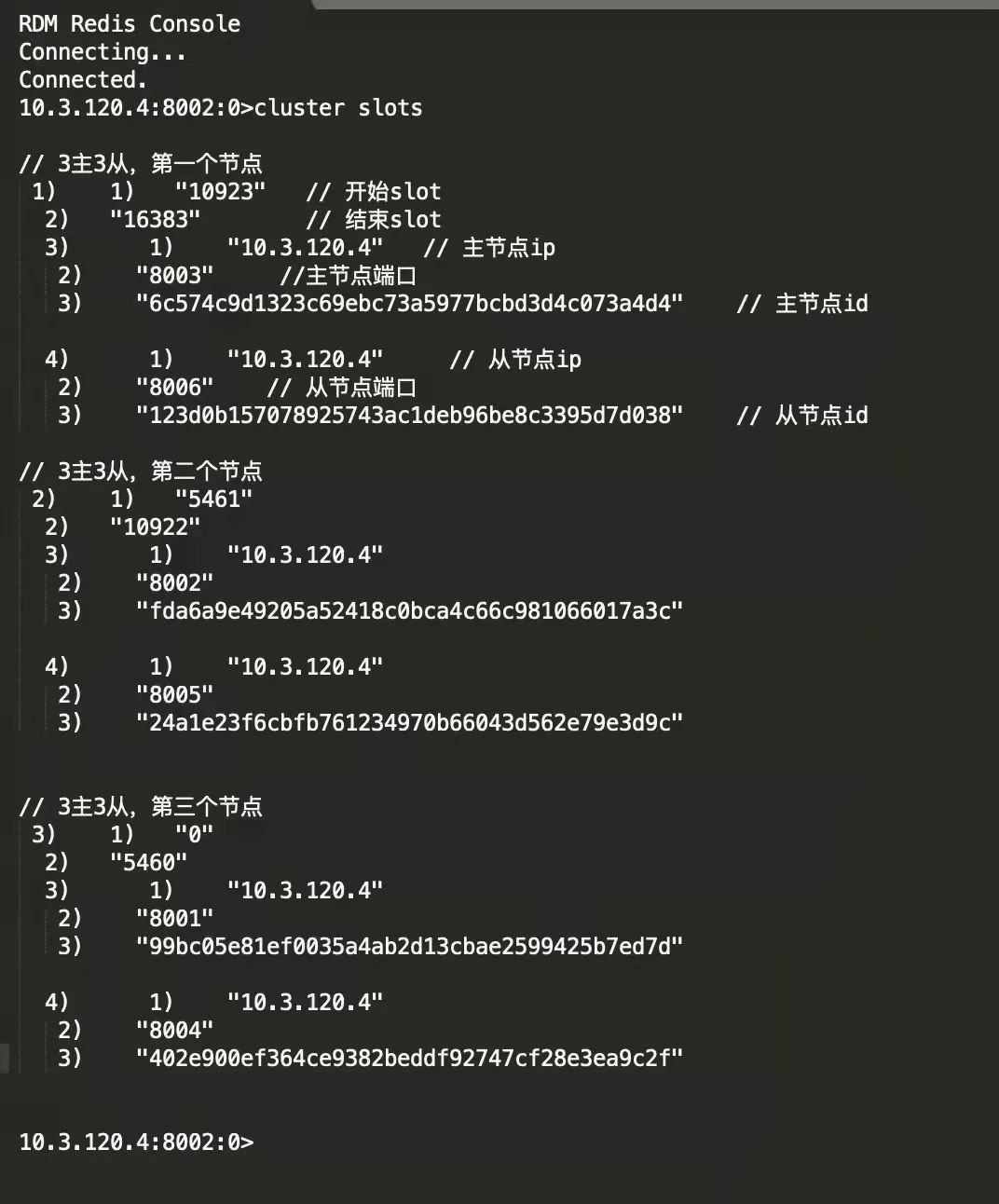
客戶端如何知曉一個key歸屬于哪個Redis切片實體
Redis Cluster集群采用分片,雖然每個實體只有部分的槽位資料,但是整個槽位分布會彼此間同步,有點類似病毒擴散,
最后,每個實體都有了全部的slot哈希槽與實體的映射關系,
應用啟動后,客戶端與Redis建立關聯,會從一臺Redis實體拉取全部的槽位映射關系,并快取在本地,
當接到key操作命令時,先計算key的哈希槽,然后將命令發送給對應的Redis實體,從而完成了分布式路由邏輯,
當然,也有特殊情況發生,比如集群擴容、縮容,會打亂原有的哈希槽分布

如果slot與實體的映射關系發生了變化,客戶端要如何處理?
沒關系,Redis 官方也想到這個問題
解決方案,就是采用重定向機制,
當客戶端執行一個key命令時,如果指向的實體位置已經變化,會回應 MOVED 結果,里面帶有新目標實體的地址,
此時客戶端會更新本地快取,后續對于該槽位的請求直接打到新實體上,
但是如果此時槽位的key較多,部分key還沒遷移完,怎么辦?
GET Tom哥:key
(error) ASK 6504 127.0.0.1:6379
客戶端請求key時,會收到一條 ASK 錯誤資訊,此時,并不會更新客戶端本地快取的哈希槽映射關系,
客戶端給新的目標實體發送 ASKING 命令,然后再發送原來的get命令,這一次的命令操作會在新實體上執行,但是僅限這一次,
同一個key下次再操作時,還是路由到老的實體,直到該槽位全部遷移完成,
Redis Cluster 主節點宕機,如何是好?
只要是系統,就有宕機的風險,哨兵模式,通過單獨部署哨兵集群,對整個Redis集群進行監控,具體的操作流程之前文章有介紹過,
Redis Cluster 并沒有單獨部署哨兵節點,而是通過master節點之間的心跳來彼此監控,
簡單來說,針對A節點,某一個節點認為A宕機了,那么此時是主觀下線,而如果集群內超過半數的節點認為A掛了, 那么此時A就會被標記為客觀下線,
一旦節點A被標記為了客觀下線,集群就會開始執行故障轉移,其余正常運行的master節點會進行投票選舉,從A節點的slave節點中選舉出一個,將其切換成新的master對外提供服務,當某個slave獲得了超過半數的master節點投票,就成功當選,
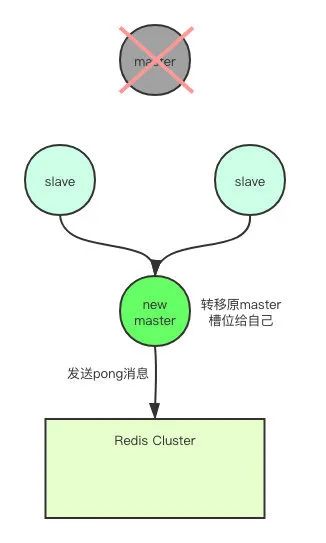
來源:https://segmentfault.com/a/1190000038528812
當選成功之后,新的master會執行slaveof no one來讓自己停止復制A節點,使自己成為master,然后將A節點所負責處理的slot,全部轉移給自己,然后就會向集群發PONG訊息來廣播自己的最新狀態,
注意:Redis Cluster中的讀、寫請求都是在master上完成,從節點只是用于資料的容災備份,
關于我:Tom哥,前阿里P7技術專家,出過專利,多年大廠實戰經驗,歡迎關注,我會持續輸出更多經典原創文章,為你大廠助力,
歡迎小伙伴找Tom哥嘮嗑聊天, 技術交流,圍觀朋友圈,人生打怪不再寂寞,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/375879.html
標籤:java
下一篇:python批處理將圖片進行放大