前言
機器學習應用博客中,將核心介紹三大類學習,即:無監督學習、監督學習、強化學習,
本篇將簡要介紹:
1.無監督學習概念(最常應用場景:聚類(clustering)和降維(Dimension Reduction))
2.聚類——kmeans方法(居民家庭消費調查)、DBSCAN方法(學生上網時間分布)
3.降維——PCA方法(鳶尾花資料)、NMF方法(人臉資料特征提取)
一、無監督學習簡要介紹
1.目標&定義
(1)無監督學習:利用無標簽的資料,學習資料的分布或資料與資料之間的關系被稱作無監督學習
(2)有監督學習和無監督學習的最大區別在于資料是否有標簽
(3)無監督學習最常應用的場景是聚類(clustering)和降維(Dimension Reduction)
2.聚類(clustering)
(1)聚類:根據資料的“相似性”將資料分為多類的程序
(2)評估兩個不同樣本之間的“相似性”,通常使用的方法就是計算兩個樣本之間的“距離”
(3)使用不同的方法計算樣本間的距離會關系到聚類結果的好壞
(4)常用距離計算方法
①歐氏距離:最常用的一種距離度量方法,源于歐式空間中兩點的距離
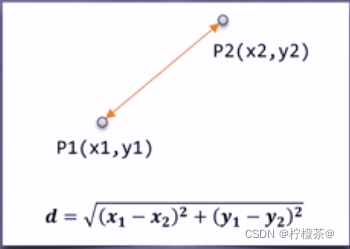
該圖為二維空間中歐式距離的計算
②曼哈頓距離:稱作“城市街區距離”,類似于在城市之中駕車行駛,從一個十字路口到另外一個十字樓口的距離,
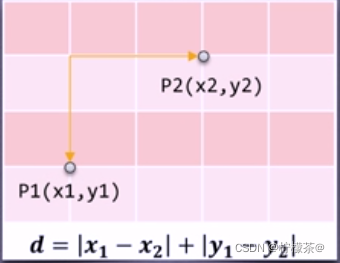
該圖為二維空間中曼哈頓距離的計算
③馬氏距離:表示資料的協方差距離,是一種尺度無關的度量方式,也就是說馬氏距離會先將樣本點的各個屬性標準化,再計算樣本間的距離,


其中,s是協方差矩陣
④余弦相似度:用向量空間中兩個向量夾角的余弦值作為衡量兩個樣本差異的大小,余弦值越接近1,說明兩個向量夾角越接近0度,表明兩個向量越相似,
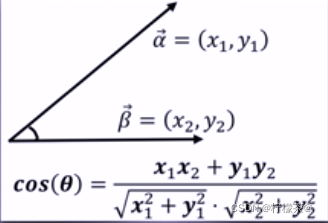
3.sklearn.cluster
(1)scikit-learn庫(簡稱sklearn庫)提供的常用聚類演算法函式包含在sklearn.cluster這個模塊中,如:K-Means,近鄰傳播演算法,DBSCAN,等,
(2)注:以同樣的資料集應用于不同的演算法,可能會得到不同的結果,演算法所耗費的時間也不盡相同,這是由演算法的特性決定的,
(3)sklearn.cluster模塊提供的各聚類演算法函式可以使用不同的資料形式作為輸入
①相似性矩陣輸人格式:即由[樣本數目]定義的矩陣形式,矩陣中的每一個元素為兩個樣本的相似度,如DBSCAN,AffinityPropagation(近鄰傳播演算法)接受這種輸人,
② 如果以余弦相似度為例,則對角線元素全為1,矩陣中每個元素的取值范圍為[0,1],
4.降維
(1)定義:在保證資料所具有的代表性特性或者分布的情況下,將高維資料轉化為低維資料的程序,
(2)作用
①資料的可視化
②精簡資料
(3)分類vs.降維
①聚類和分類都是無監督學習的典型任務,任務之間存在關聯
②比如某些高緯資料的分類可以通過降維處理更好的獲得
③另外學界研究也表明代表性的分類演算法如k-means與降維演算法如NMF之間存在等價性
(4)sklearn vs.降維
①降維是機器學習領域的一個重要研究內容,有很多被工業界和學術界接受的典型演算法,截止到目前sklearn庫提供7種降維演算法,
②降維程序也可以被理解為對資料集的組成成份進行分解(decomposition)的程序,因此sklearn為降維模塊命名為decomposition,在對降維演算法呼叫需要使用sklearn.decomposition模塊,
③幾個常用降維演算法
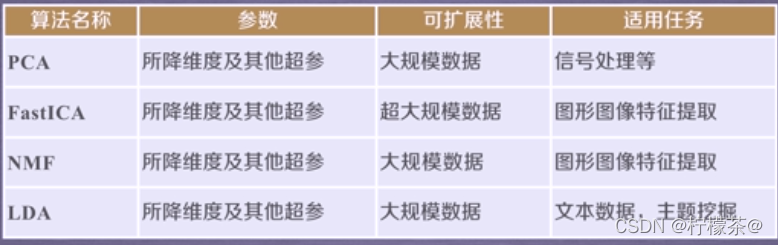
(5)在后續中將通過實體展示如何利用sklearn庫提供的分類和降維演算法解決具體問題
①31省市居民家庭消費調查
②學生月上網時間分布調查
③人臉影像特征抽取
④影像分割
二、聚類
1.K-means方法
(1)k-means演算法以k為引數,把n個物件分成k個簇,使簇內具有較高的相似度,而簇間的相似度較低,
(2)主要處理程序
①隨機選擇k個點作為初始的聚類中心,
②對于剩下的點,根據其與聚類中心的距離,將其歸人最近的簇,
③對每個簇,計算所有點的均值作為新的聚類中心,
④重復2、3直到聚類中心不再發生改變,
(3)舉例
①在5個點中隨機選取兩個聚類中心

②計算距離后,歸入簇
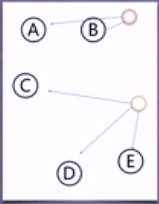
③重新計算聚類中心,重新計算距離,將點歸入簇
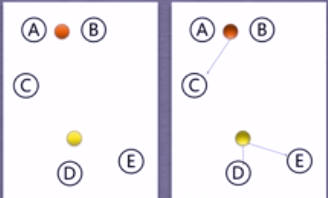
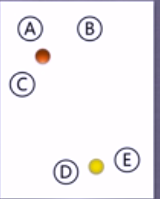
④直到簇的組成穩定
2.K-means應用
(1)問題分析
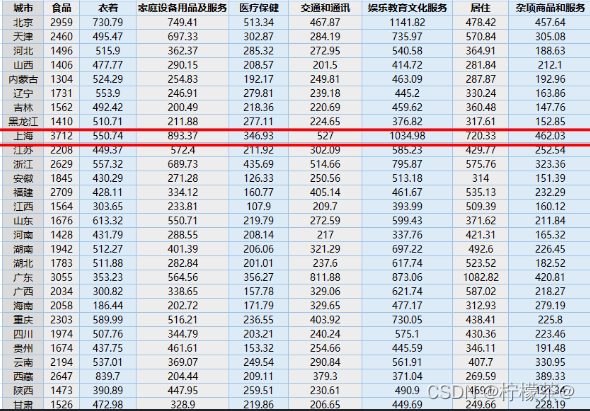
①資料介紹:現有1999年全國31個省份城鎮居民家庭平均每人全年消費性支出的八個主要變數資料,這八個變數分別是:食品、衣著、家庭設備用品及服務、醫療保健、交通和通訊、娛樂教育文化服務、居住以及雜項商品和服務,利用已有資料,對31個省份進行聚類,
②實驗目的:通過聚類,了解1999年各個省份的消費水平在國內的情況,
③技術路線:sklearn.cluster.Kmeans
④資料實體
(2)程序
①使用演算法:K-means聚類演算法
②實作程序
1)建立程序,匯入sklearn相關包
import numpy as np
from sklearn.cluster import KMeans
2)加載資料,創建K-means演算法實體,并進行訓練,獲得標簽
注1:呼叫K-Means方法所需引數
1)n_cluster:用于指定聚類中心的個數
2)init:初始聚類中心的初始化方法
3)max_iter:最大的迭代次數
4)一般呼叫時只給出n_clusters即可,init默認是k-means++,max_iter默認是300
注2:其他引數
1)data:加載的資料
2)label:聚類后資料所屬的標簽
3)fit_predict():計算簇中心以及為簇分配序號
③輸出標簽,查看結果
1)將城市按照消費水平n clusters類,消費水平相近的城市聚集在一類中,
import numpy as np
from scipy.sparse import data
from sklearn.cluster import KMeans
def loadData(filePath):
fr = open(filePath, 'r+') # 讀寫打開一個文本檔案
lines = fr.readline() # 一次讀取整個檔案
retData = [] #存盤城市的各項消費資訊
retCityName = [] #用于存盤城市名稱
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i])
for i in range(1, len(items))])
for i in range(1,len(items)):
return retData, retCityName # 回傳城市名稱及各項消費資訊
# 加載資料,創建K-means演算法實體,并進行訓練,獲得標簽
if __name__ == '__main__':
data.cityName = loadData('city.txt') #利用loadData方法讀取資料,此處檔案需自行準備
km = KMeans(n_clusters=3) # 創建實體
lable = km.fit_predict(data) # 呼叫Kmeans() fit_predict()進行聚類計算
expenses = np.num(km.cluster_centers_,axis=1) #expenses:聚類中心的數值加和,即平均消費水平
# print
CityCluster = [[],[],[]] # 將城市按lable分成設定的簇
for i in range(len(cityName)):
CityCluster[lable[i]].append(data.cityName[i])
for i in range(len(CityCluster)):
print("Expenses:%.2f"%expenses[i]) # 將每個簇的平均花費輸出
print(CityCluster[i]) # 將每個簇的城市輸出
2)結果展示:
-1:聚成2類:km = KMeans(n_clusters=2)

-2:聚成3類:km= KMeans(n_clusters=3)

-3:聚成4類:km= KMeans(n_clusters=4)

(3)拓展&&改進
①計算兩條資料相似性時,Sklearn的K-Means默認用的是歐式距離,雖然還有余弦相似度,馬氏距離等多種方法,但沒有設定計算距離方法的引數,
②想自定義計算距離的方式時,可更改此處源代碼

建議使用scipy.spatial.distance.cdist方法
3.DBSCAN方法
(1)DBSCAN演算法是一種基于密度的聚類演算法
①聚類的時候不需要預先指定簇的個數最終的
②簇的個數不定
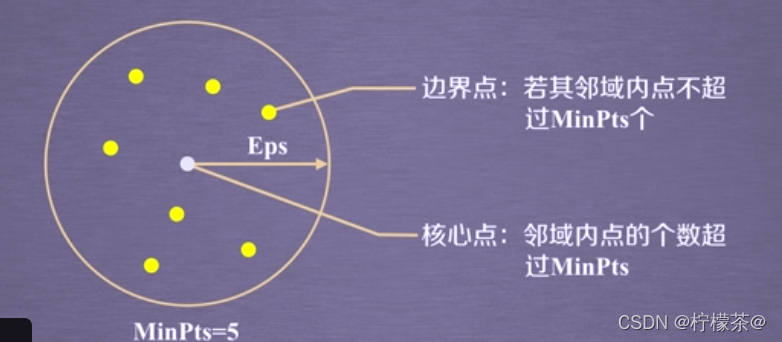
(2)DBSCAN演算法將資料點分為三類:
①核心點:在半徑Eps內含有超過MinPts數目的點,
②邊界點:在半徑Eps內點的數量小于MinPts,但是落在核心點的鄰域內,
③噪音點:既不是核心點也不是邊界點的點,
(3)DBSCAN演算法流程
①將所有點標記為核心點、邊界點或噪聲點
②洗掉噪聲點
③為距離在Eps之內的所有核心點之間賦予一條邊
④每組連通的核心點形成一個簇
⑤將每個邊界點指派到一個與之關聯的核心點的簇中(即在哪一個核心點的半徑范圍之內)
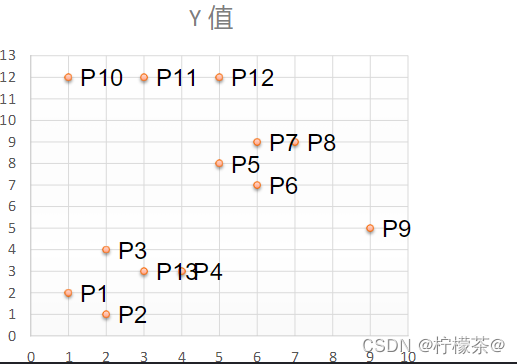
(4)舉例:如下13個樣本點,使用DBSCAN進行聚類

①取Eps=3,MinPts=3,依據DBSACN對所有點進行聚類(這里使用曼哈頓距離)
②對每個點計算其鄰域Eps=3內的點的集合,集合內點的個數超過MinPts=3的點為核心點
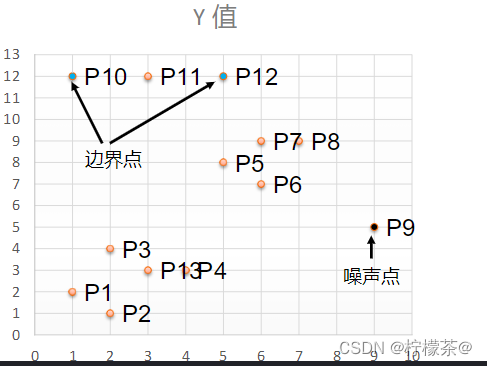
③查看剩余點是否在核心點的鄰域內,若在,則為邊界點,否則為噪聲點,
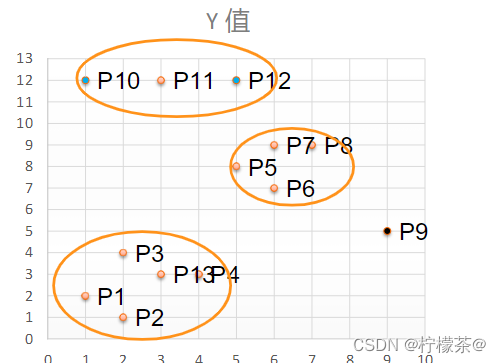
④將距離不超過Eps=3的點相互連接構成一個簇,核心點鄰域內的點也會被加入到這個簇中,
4.DBSCAN應用
(1)問題分析
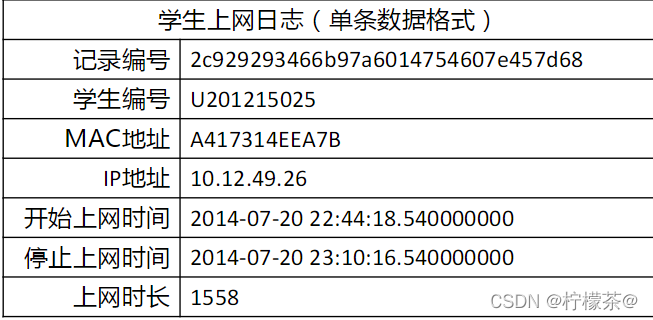
①現有大學校園網的日志資料,為290條大學生的校園網使用情況資料
②資料包括用戶ID,設備的MAC地址,IP地址,開始上網時間,停止上網時間,上網時長,校園網套餐等,
③利用已有資料,分析學生上網的模式,
(2)實驗目的
通過DBSCAN聚類,分析學生上網時間和上網時長的模式,
(3)技術路線
采用sklearn.cluster.DBSCAN模塊
(4)資料實體
(5)實驗程序
(6)代碼實作
①建立工程,匯入sklearn相關包
import numpy as np
from sklearn.cluster import DBSCAN
②DBSCAN主要引數
1)eps:兩個樣本被看作鄰居節點的最大距離
2)min_samples:簇的樣本數
3)metric:距離計算方式
例:sklearn.cluster.DBSCAN(eps=0.5,min_samples=5,metric=‘euclidean’)
③對上網時間聚類,創建DBSCAN演算法實體,并進行訓練,獲得標簽
附碼import numpy as np
import sklearn.cluster
from sklearn import metrics
from sklearn.cluster import DBSCAN
mac2id=dict() # 字典
onlinetimes=[]
f = open('TestData.txt')
for line in f:
mac = line.split(',')[2] # 讀取每條中的mac地址
onlinetime = int(line.split(',')[6]) # 讀取上網時長
starttime=int(line.split(',')[4].split(' ')[1].split(':')[0]) # 讀取開始上網時間
if mac not in mac2id:
mac2id[mac]=len(onlinetimes) # 其中key是mac地址
onlinetimes.append((starttime,onlinetime)) # value是對應mac地址的上網時長以及開始上網時間
else:
onlinetimes[mac2id[mac]]=[(starttime,onlinetime)]
real_X=np.array(onlinetimes).reshape((-1,2))
#對上網時間聚類,創建DBSCAN演算法實體,并進行訓練,獲得標簽
X = real_X[:,0:1]
db = sklearn.cluster.DBSCAN(eps=0.01,min_samples=20).fit(X) #呼叫DBSCAN方法進行訓練
labels=db.labels # labels為每個資料的簇標簽
print('Labels:')
print(labels) # 列印資料被記上的標簽
ratio=len(labels[labels:]==-1)/len(labels) #計算標簽為-1,即噪聲資料的比例
print('Noise ratio:',format(ratio,'.2%'))
# Number of clusters in labels,ignoring noise if present
n_clusters_=len(set(labels))-(1 if -1 in labels else 0) # 計算簇的個數并列印
print('Estimated number of clusters: %d'% n_clusters_)
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X,labels)) #評價聚類效果
for i in range(n_clusters_): # 列印各簇標號及簇內資料
print('Cluster',i,':')
print(list(X[labels==i].flatten()))
#對上網時長聚類,創建DBSCAN演算法實體,并進行訓練,獲得標簽
X = np.log(1+real_X[:,1:])
db = sklearn.DBSCAN(eps=0.1401,min_samples=10).fit(X) #呼叫DBSCAN方法進行訓練
labels=db.labels # labels為每個資料的簇標簽
print('Labels:')
print(labels) # 列印資料被記上的標簽
ratio=len(labels[labels:]==-1)/len(labels) #計算標簽為-1,即噪聲資料的比例
print('Noise ratio:',format(ratio,'.2%'))
# Number of clusters in labels,ignoring noise if present
n_clusters_=len(set(labels))-(1 if -1 in labels else 0) # 計算簇的個數并列印
print('Estimated number of clusters: %d'% n_clusters_)
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X,labels)) #評價聚類效果
for i in range(n_clusters_): # 統計每一個簇內的樣本個數,均值,標準差
print('Cluster',i,':')
count=len(X[labels==i])
mean=np.mean(real_X[labels==i][:,1])
std=np.std(real_X[labels==i][:,1])
print('\t number of sample:',count)
print('\t mean of sample:',format(mean,'.1f'))
print('\t std of sample:',format(std,'.1f'))
④輸出標簽,查看結果

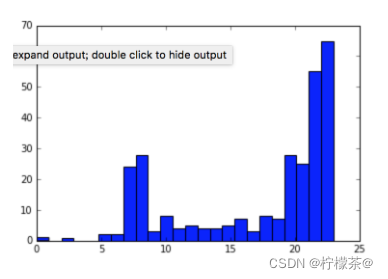
⑤畫直方圖,分析實驗結果
import matplotlib.pyplot as pet
plt.hist(X,24)
觀察得出:上網時間大多聚集在22:00和23:00
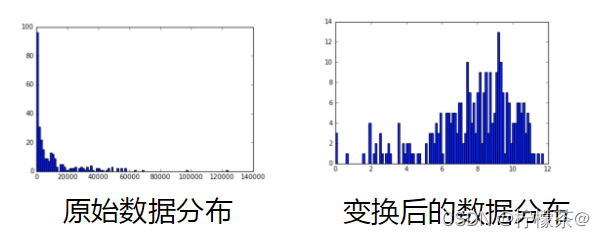
⑥資料分布vs聚類
技巧:對數變換
⑦對上網時長聚類,創建DBSCAN演算法實體,并進行訓練,獲得標簽
⑧輸出標簽,查看結果


1)按照上網時長DBSCAN聚了5類,上圖所示,顯示了每個聚類的樣本數量、聚類的均值、標準差,
2)時長聚類效果不如時間的聚類效果明顯,
三、降維
1.PCA方法
(1)主成分分析(PCA)
①主成分分析(Principal Component Analysis,PCA)是最常用的一種降維方法,通常用于高維資料集的探索與可視化,還可以用作資料壓縮和預處理等,
②PCA可以把具有相關性的高維變數合成為線性無關的低維變數,稱為主成分,主成分能夠盡可能保留原始資料的資訊,
(2)涉及到的相關術語:
①方差:是各個樣本和樣本均值的差的平方和的均值,用來度量一組資料的分散程度
②協方差:用于度量2個辯論直接的線性相關性程度,羅為0,則可認為二者線性無關,
③協方差矩陣:由變數的協方差值構成的矩陣(對稱陣)
④特征向量:描述資料集結構的非零向量
公式如圖
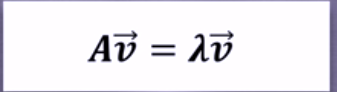
A是方陣,v是特征向量,λ是特征值
(3)原理
①矩陣的主成分:其協方差矩陣對應的特征向量,按照對應的特征值大學進行排序
②最大特征值為第一主成分,其次是第二主成分,以此類推
(4)演算法程序

(5)主要引數
在sklearn庫中,可使用sklearn.decomposition.PCA加載PCA進行降維
①n_components:指定主成分的個數,即降維后資料的維度
②svd_solver:設定特征值分解的方法,默認為’auto’,其他可選有’full’,‘arpack’,‘randomized’,可參考官網API
2.PCA應用實體:鳶尾花資料
————PCA實作高維資料可視化
(1)問題分析
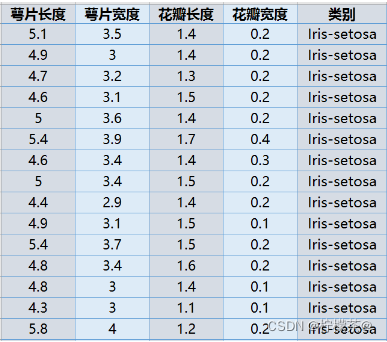
①已知鳶尾花資料是4維的,共三類樣本,
②使用PCA實作對鳶尾花資料進行降維,實作在二維平面上的可視化,
(2)代碼實作
①建立工程,匯入sklearn相關工具包
# 加載matplotlib用于資料可視化
import matplotlib.pyplot as plt
#加載PCA演算法包
from sklearn.decomposition import PCA
#加載鳶尾花資料集匯入函式
from sklearn.datasets import load_iris
②加載資料并進行降維
③按類別對降維后的資料進行保存
④降維后資料點的可視化
#建立工程,匯入sklearn相關工具包
# 加載matplotlib用于資料可視化
import matplotlib.pyplot as plt
#加載PCA演算法包
from sklearn.decomposition import PCA
#加載鳶尾花資料集匯入函式
from sklearn.datasets import load_iris
#加載資料并進行降維
data = load_iris() #以字典形式加載鳶尾花資料集
y = data.target #使用y表示資料集中的標簽
X = data.data #使用x表示資料集中的屬性標簽
pca = PCA(n_components=2) # 加載PCA演算法,設定降維后主成分數目為2
reduced_X = pca.fit_transform(X) #對原始資料進行降維,保存在reduce_X中
# 按類別對降維后的資料進行保存
red_x,red_y = [],[] #第一類資料點
blue_x,blue_y = [],[]#第二類資料點
green_x,green_y = [],[] #第三類資料點
for i in range(len(reduced_X)): #按照鳶尾花的類別,將降維后的資料點保存在不同的串列中
if y[i]==0:
red_x.append(reduced_X[i][0])
red_y.append(reduced_X[i][1])
elif y[i]==1:
blue_x.append(reduced_X[i][0])
blue_y.append(reduced_X[i][1])
else:
green_x.append(reduced_X[i][0])
green_y.append(reduced_X[i][1])
#降維后資料點的可視化
plt.scatter(red_x,red_y,c='r',marker='x') #第一類資料點
plt.scatter(blue_x,blue_y,c='b',marker='D') #第二類資料點
plt.scatter(green_x,green_y,c='g',marker='.') #第三類資料點
plt.show() #可視化
(3)結果展示
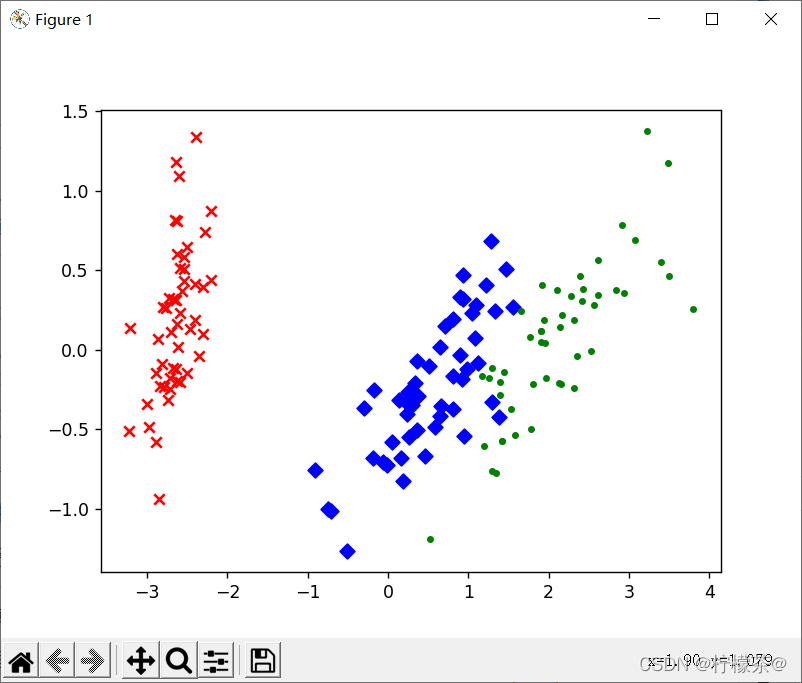
①可以看出,降維后的資料仍能夠清晰地分成三類,
②這樣不僅能削減資料的維度,降低分類任務的作業量,還能保證分類的質量,
3.NMF方法
(1)非負矩陣分解(Non-negative Matrix Factorization,NMF)是在矩陣中所有元素均為非負數約束條件之下的矩陣分解方法
(2)基本思想:給定一個非負矩陣V,NMF能夠找到一個非負矩陣W和一個非負矩陣H,使得矩陣W和H的乘積近似等于矩陣V中的值
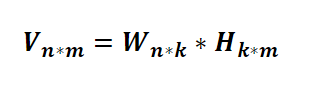
①W矩陣:基礎影像矩陣,相當于從原矩陣V中抽取出來的特征
②H矩陣:系數矩陣
③NMF能夠廣泛應用于影像分析、文本挖掘和語音處理等領域
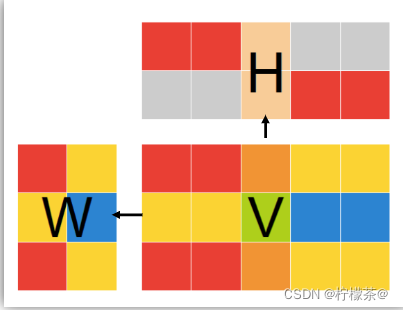
(3)矩陣分解優化目標:最小化“W與矩陣H的乘積”和“原始矩陣”之間的差別
①目標函式如下(基于歐氏距離)
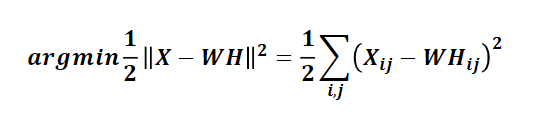
②基于KL散度的優化目標,損失函式如下
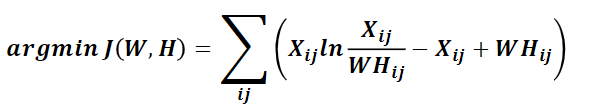
③W矩陣和H矩陣的求解為迭代演算法,在此不詳細講述,參考鏈接:
http://blog.csdn.net/acdreamers/article/details/44663421/
(4)在sklearn庫中,可以使用sklearn.decomposition.NMF加載NMF演算法,主要引數有
①n_components:用于指定分解后矩陣的單個維度k
②init:W矩陣和H矩陣的初始化方式,默認為’nndsvdar’
③其他引數參考官網API
4.NMF應用:人臉資料特征提取
(1)問題分析
①目標:已知Olivetti人臉資料共400個,每個資料是64*64大小,由于NMF分解得到的W矩陣相當于從原始矩陣中提取的特征,那么就可以使用NMF對400個人臉資料進行特征提取,
②通過設定k的大小,設定提取的特征的數目,在本實驗中設定k=6,隨后將提取的特征以影像的形式展示出來,
(2)代碼實作
①建立工程,匯入sklearn相關工具包
# 加載matplotlib用于資料的可視化
import matplotlib.pyplot as plt
# 加載PCA演算法包
from sklearn import decomposition
# 加載Olivetti人臉資料集匯入函式
from sklearn.datasets import fetch_olivetti_faces
# 加載RandomState用于創建隨機種子
from numpy.random import RandomState
②設定基本引數并加載資料
③設定影像的展示方式
④創建特征提取的物件NMF,使用PCA作為對比
# 建立工程,匯入sklearn相關工具包
# 加載matplotlib用于資料的可視化
import matplotlib.pyplot as plt
# 加載PCA演算法包
from sklearn import decomposition
# 加載Olivetti人臉資料集匯入函式
from sklearn import datasets
# 加載RandomState用于創建隨機種子
from numpy.random import RandomState
# 設定基本引數并加載資料
n_row, n_col = 2, 3 # 設定影像展示時的排列情況(2行3列),如圖
n_components = n_row*n_col # 設定提取的特征的數目
image_shape = (64,64) #設定人臉資料圖片的大小
dataset = datasets.fetch_olivetti_faces(shuffle=True,random_state=RandomState(0))
faces = dataset.data #加載資料并打亂順序
# 設定影像的展示方式
def plot_gallery(title, images, n_col=n_col, n_row=n_row):
plt.figure(figsize=(2.*n_col, 2.26*n_row)) #創建圖片并指定圖片大小(英寸)
plt.suptitle(title,size=16) #設定標題及字號大小
for i,comp in enumerate(images):
plt.subplot(n_row,n_col,i+1) # 選擇畫制的子圖
vmax = max(comp.max(),-comp.min())
plt.imshow(comp.reshape(image_shape),cmap=plt.cm.gray,
interpolation='nearest',vmin=-vmax,vmax=vmax) #對數值歸一化,并以灰度圖形式顯示
plt.xticks(())
plt.yticks(()) #去除子圖的坐標軸標簽
plt.subplots_adjust(0.01,0.05,0.99,0.93,0.04,0.) # 對子圖位置及間隔進行調整
plot_gallery("First centered Olivetti faces",faces[:n_components])
plt.show()
# 創建特征提取的物件NMF,使用PCA作為對比
estimators = { # 將他們存放在一個串列中
('Eigenfaces - PCA using randomized SVD', # 提取方法名稱
decomposition.PCA(n_components=6, whiten=True)), # PCA實體
('Non-nefative components - NMF', # 提取方法名稱
decomposition.NMF(n_components=6, init='nndsvda', tol=5e-3))} # NMF實體
# 降維后資料點的可視化
for name,estimator in estimators: #分別呼叫PCA和NMF
print("Extracting the top %d %s..."%(n_components,name))
print(faces.shape)
estimator.fit(faces) # 呼叫PCA或NMF提取特征
components_ = estimator.components_
plot_gallery(name,components_[:n_components]) # 獲取提取的特征
plt.show() # 按照固定格式進行排列
(3)效果展示



總結
關于無監督學習,比較核心的就是聚類和降維問題,在此僅用4個實體說明兩大核心的四大典型方法,其余便不多做贅述,關于代碼之中的一些改進問題,由于用到庫中的其他方法,且本人能力有限,大家感興趣可自行查閱官網API,
兩點問題:
(1)代碼運行需要基礎資料支撐,py的自帶庫中有些內含所需資料,有些則沒有,本篇并未放上資料txt檔案,只是為了展示無監督學習的體系流程以作演示
(2)在庫的包匯入若發生問題,看看版本更新問題,以及部分包在近年來命名和函式有所調整,各位客官可面向百度
ps:人臉資料運行結果出來真是把我送走了,機器學習讓人頭禿
代碼非原創,內容乃課件整理所得,
如有問題,歡迎指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/375908.html
標籤:python