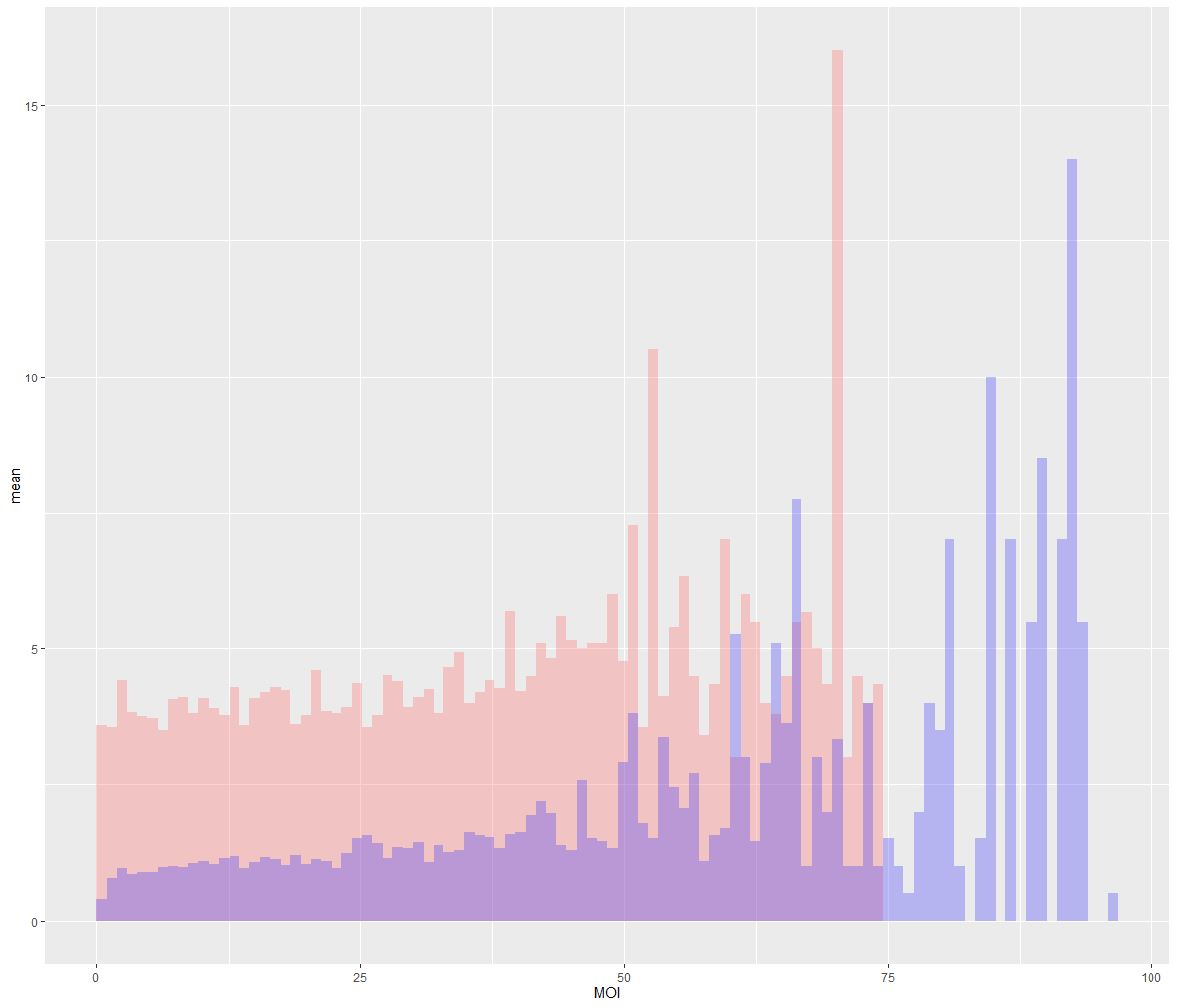
我想出了以下腳本來將 X 值的資料分箱,并在重疊的條形圖中繪制這些分箱的均值。它作業正常,但我似乎無法生成圖例,可能是由于對美學映射的理解不足。
這是腳本,請注意“MOI”和“T_cell_contacts”是每個 DF 中的兩個資料列。
ggplot(mapping=aes(MOI, T_cell_contacts)) stat_summary_bin(data = Cleaned24hr4, fun = "mean", geom="bar", bins= 100, fill = "#FF6666", alpha = 0.3) stat_summary_bin(data = cleaned24hr8, fun = "mean", geom="bar", bins= 100, fill = "#3733FF", alpha = 0.3) ylab("mean")
我還添加了它繪制的圖表。
uj5u.com熱心網友回復:
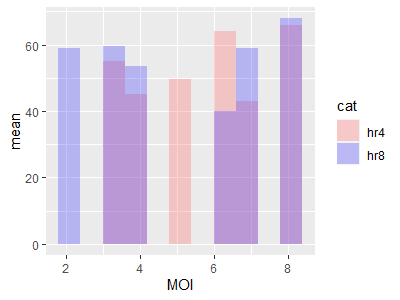
我認為困難與用兩個不同的幾何體構建單個圖例有關。我的方法是將您的資料合并到一個資料框中。每個記錄由一個新的類別列分開,我將簡稱為“貓”。使用流行的 dplyr 包:
Cleaned24hr4 <- mutate(Cleaned24hr4, cat = "hr4")
Cleaned24hr8 <- mutate(Cleaned24hr8, cat = "hr8")
然后把它們放在一起:
Cleaned <- union(Cleaned24hr4,Cleaned24hr8)
定義你的顏色:
colorcode <- c("hr4" = "#FF6666", "hr8" = "#3733FF")
這是我的 ggplot 宣告:
ggplot(Cleaned, mapping=aes(MOI, T_cell_contacts))
stat_summary_bin(fun = "mean", geom="bar", bins= 100, aes(fill = cat), alpha = 0.3)
scale_fill_manual(values = colorcode)
ylab("mean")
使用一些虛擬資料輸出。
uj5u.com熱心網友回復:
完全披露:當@schumacher 發布他們的回復時,我正在寫這篇文章:)。還是決定結束。
有兩種方法可以解決這個問題。一種方法(更復雜)是將資料框分開并要求ggplot2通過映射創建圖例,第二種(更簡單)方法是組合成一個類似于@schumacher 發布的資料集并將填充顏色映射到額外的 id 列創建。
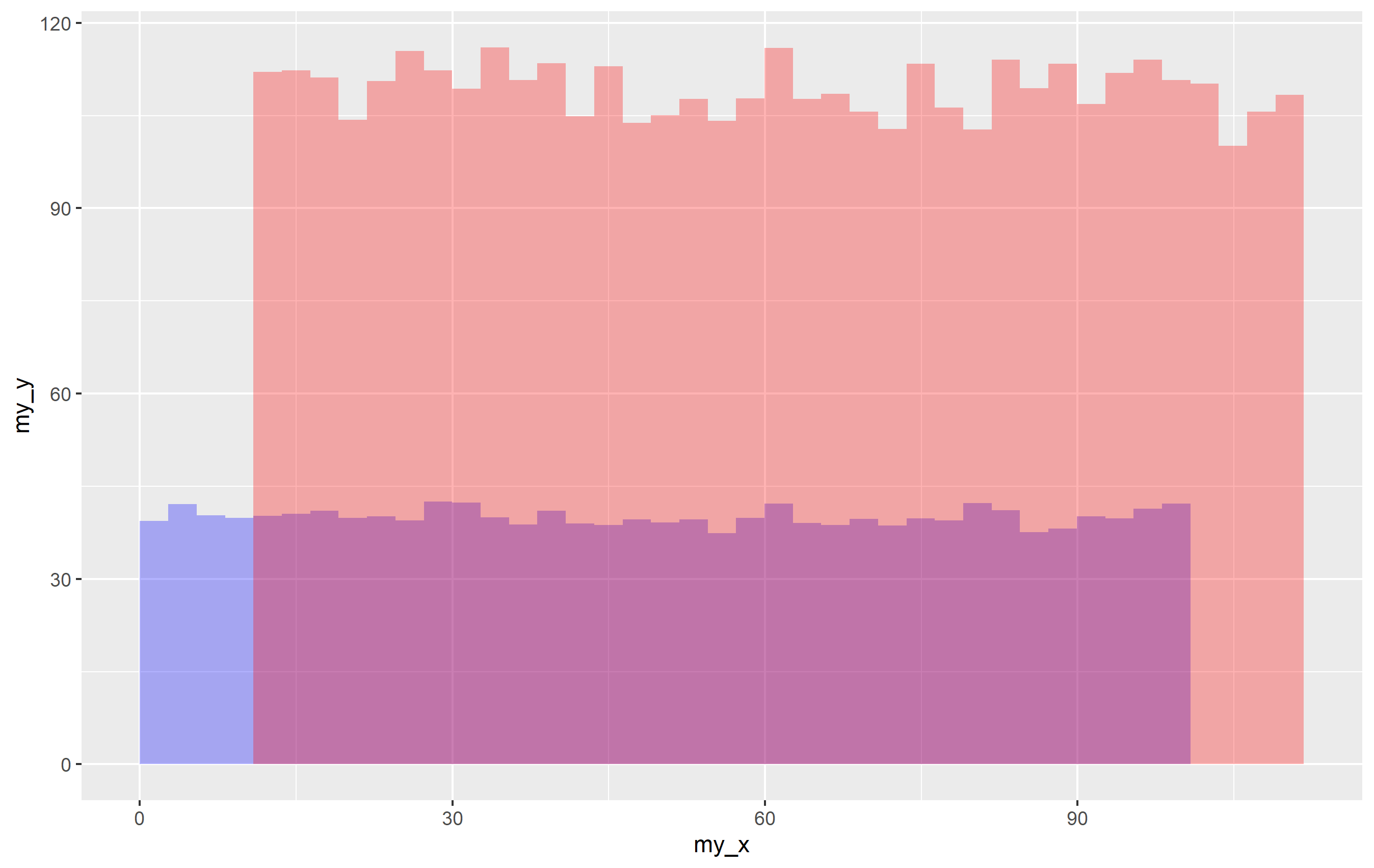
我將向您展示兩者,但首先,這是一個示例資料集:
library(ggplot2)
set.seed(8675309)
df1 <- data.frame(my_x=rep(1:100, 3), my_y=rnorm(300, 40, 4))
df2 <- data.frame(my_x=rep(11:110, 3), my_y=rnorm(300, 110, 10))
# and the plot code similar to OP's question
ggplot(mapping=aes(x = my_x, y = my_y))
stat_summary_bin(data=df1, fun="mean", geom="bar", bins=40, fill="blue", alpha=0.3)
stat_summary_bin(data=df2, fun="mean", geom="bar", bins=40, fill="red", alpha=0.3)
方法 1:組合資料幀
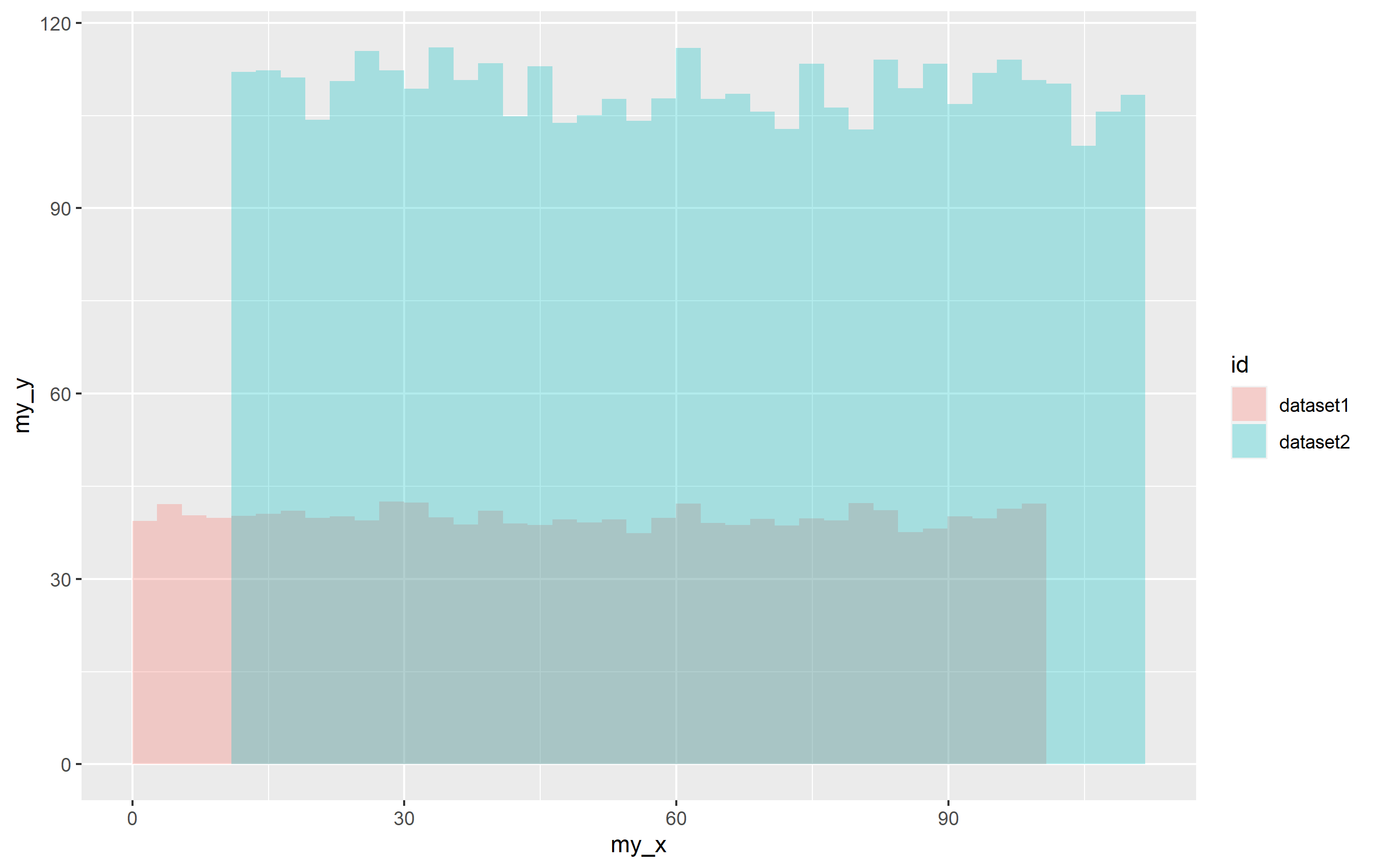
由于各種原因,我無法在此處完整列出,因此這是首選方法。有很多選項可用于組合資料集。一種是使用union()或rbind()在向您的資料添加某種 ID 列之后,但您可以使用bind_rows()from一次性完成所有操作dplyr:
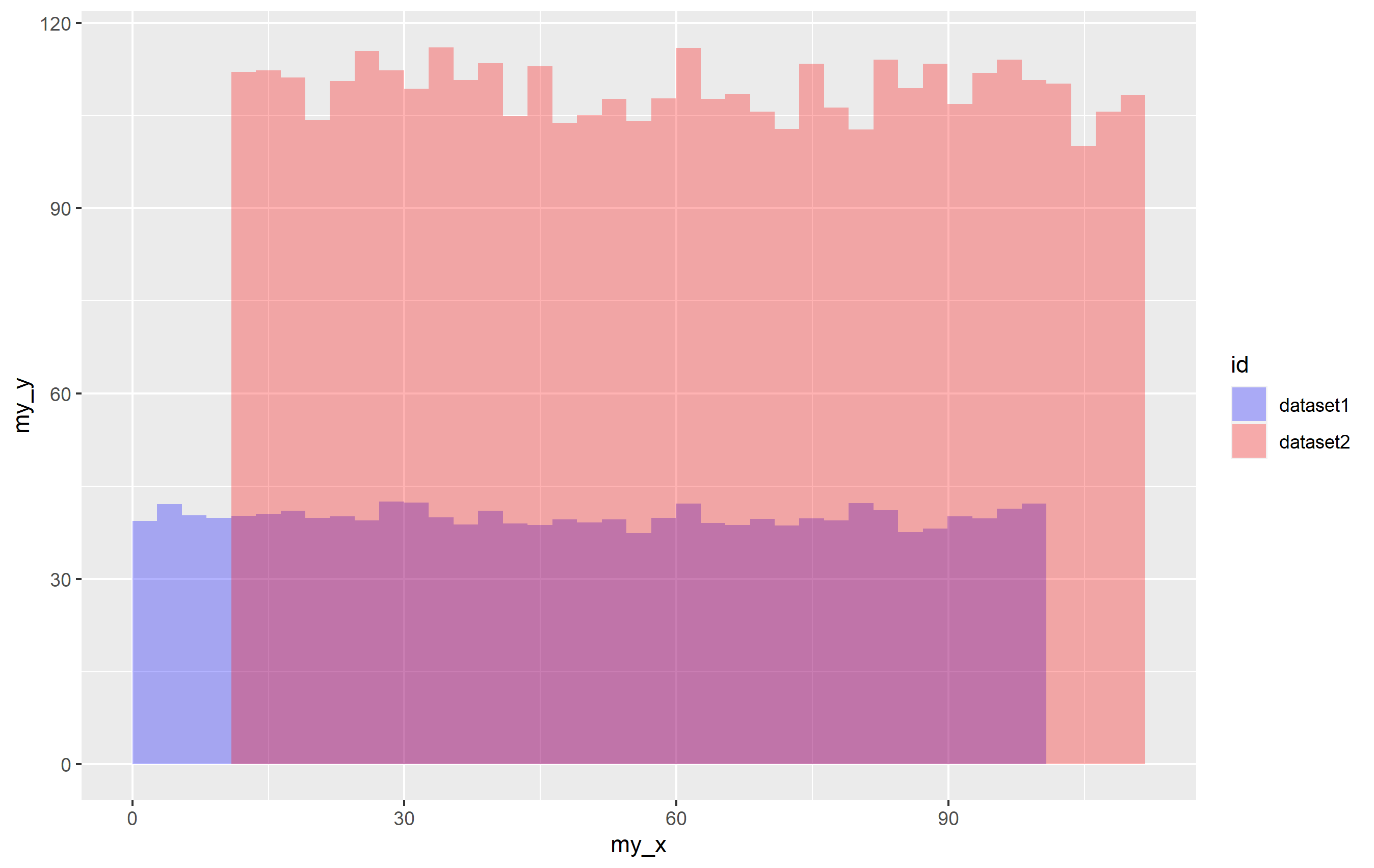
df <- dplyr::bind_rows(list(dataset1 = df1, dataset2 = df2), .id="id")
結果會將行系結在一起,并通過指定.id引數,它將在名為的資料集中創建一個新列,該列"id"使用串列中每個資料集的名稱作為值。在這種情況下, thddf$id列中的值要么"dataset1"來自 ,df1要么"dataset2"來自df2。
然后使用aes(fill=...)將填充顏色映射到"id"組合資料集中的列。
p <- ggplot(df, aes(x=my_x, y=my_y))
stat_summary_bin(aes(fill=id), fun="mean", geom="bar", bins=40, alpha=0.3)
p
這將創建一個具有默認顏色的圖fill,因此如果您想提供自己scale_fill_manual(values=...)的顏色,只需使用指定特定顏色。使用命名向量values=確保每種顏色都按照您希望的方式應用,但您可以只提供一個未命名的顏色名稱向量。
p scale_fill_manual(values = c("dataset1" = "blue", "dataset2" = "red"))
方法二:使用映射添加圖例
While Method 1 is preferred, there is another way that does not force you to combine your dataframes. This is also useful to illustrate a bit about how ggplot2 decides to create and draw legends. The legend is created automaticaly via the mapping= argument, specifically via aes(). If you put any aesthetic inside of aes() that would normally impart a different appearance and not location (with some exceptions like x, y, and label), then this initiates the creation of a legend. You can map either a column in your dataset (like above), or you can just supply a single value and that will be applied to the entire dataset used for the geom. In this case, see what happens when you change the fill= argument for each geom call to be within aes() and assign it to a character value:
p1 <- ggplot(mapping = aes(x=my_x, y=my_y))
stat_summary_bin(aes(fill="first"), data=df1, fun="mean", geom="bar", bins=40, alpha=0.3)
stat_summary_bin(aes(fill="second"), data=df2, fun="mean", geom="bar", bins=40, alpha=0.3)
scale_fill_manual(values = c("first" = "blue", "second" = "red"))
p1
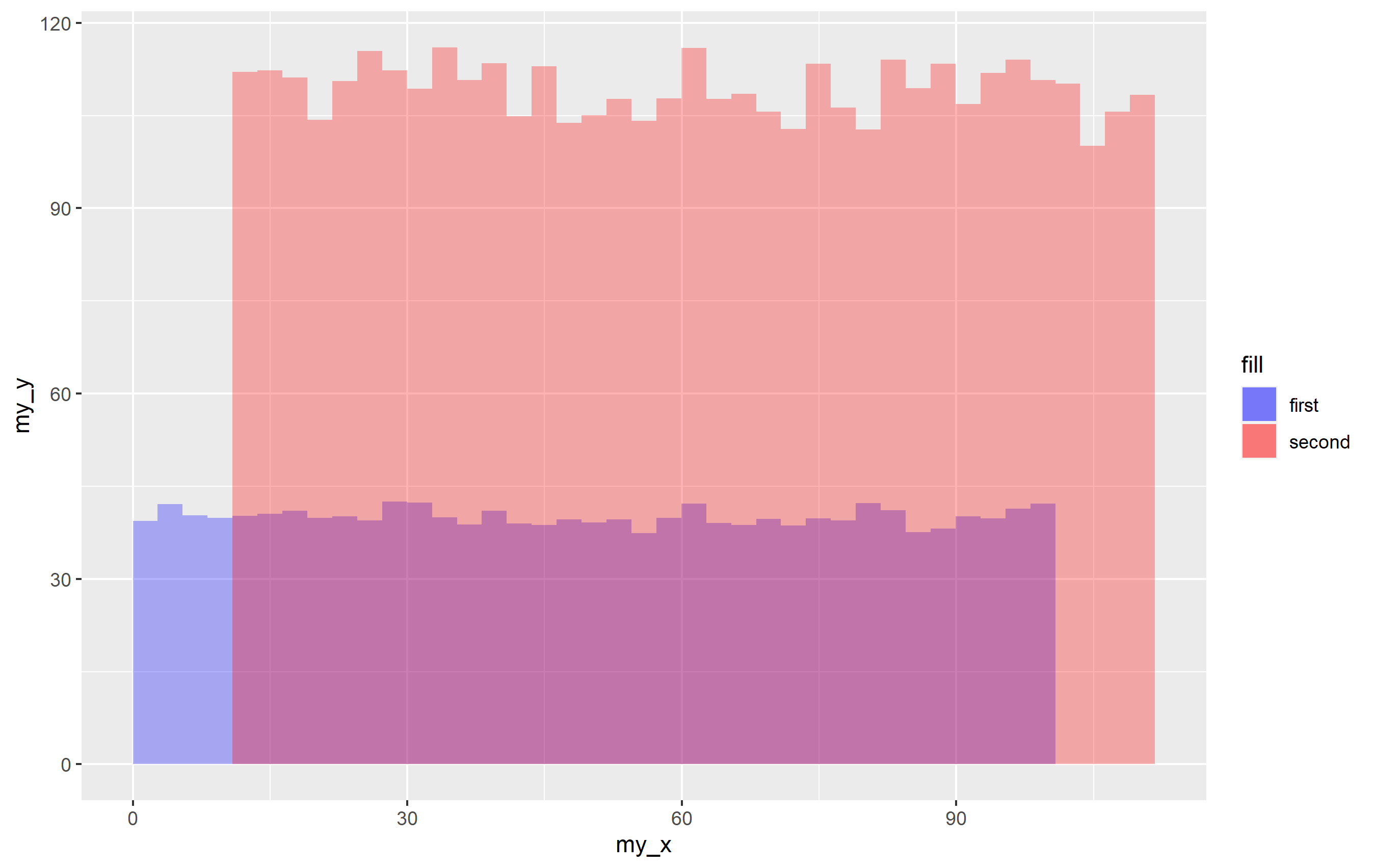
It works! When you provide a character value for the fill= aesthetic inside aes(), it's basically labeling every observation in that data to have the value "first" or "second" and using that to make the legend. Cool, right?
但是,您注意到一個問題,即圖例的 alpha 值不正確。這是因為你得到了overplotting。這只是你不應該真正這樣做的原因之一,但是......有點作業。只有當你有一個 alpha 值時才會明顯。你可以讓它看起來正常,但你需要用它guide_legend()來覆寫美學。由于代碼有效地導致為每個幾何圖形完全繪制圖例......您必須將 alpha 值減半才能正確顯示。
p1 guides(fill=guide_legend(override.aes = list(alpha=0.15)))
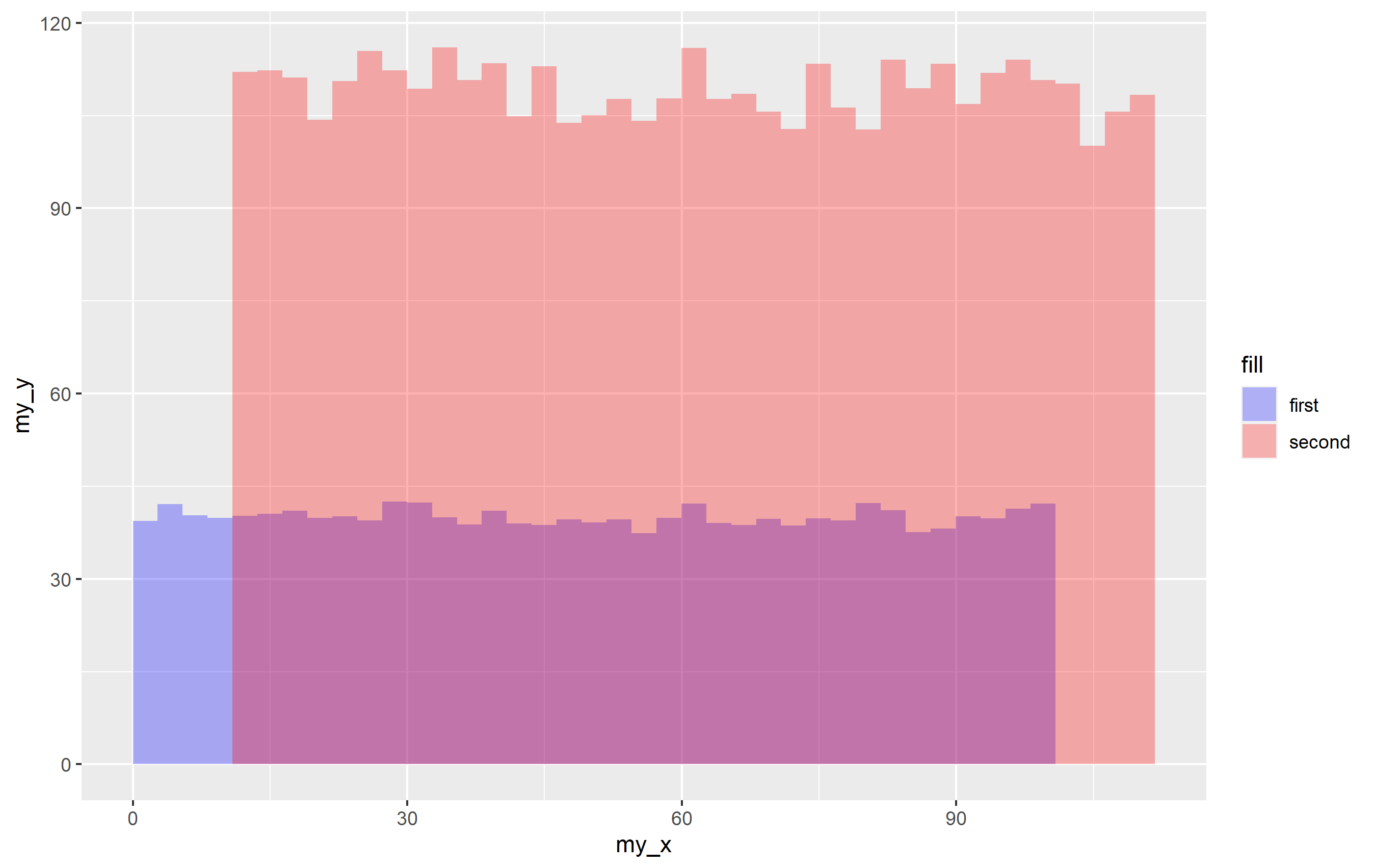
哦,不使用方法 2 的真正原因是.... 想想對 5 個資料集再做一次... 10 怎么樣?... 20怎么樣?.....
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/377678.html
上一篇:如何將自定義圖例添加到多個geom_function()?
下一篇:是否可以將x軸標題與軸的值對齊?