利用python爬取城市公交站點
頁面分析
https://guiyang.8684.cn/line1


爬蟲
我們利用requests請求,利用BeautifulSoup來決議,獲取我們的站點資料,得到我們的公交站點以后,我們利用高德api來獲取站點的經緯度坐標,利用pandas決議json檔案,接下來開干,我推薦使用面向物件的方法來寫代碼,
import requests
import json
from bs4 import BeautifulSoup
import pandas as pd
?
?
class bus_stop:
## 定義一個類,用來獲取每趟公交的站點名稱和經緯度
def __init__(self):
self.url = 'https://guiyang.8684.cn/line{}'
self.starnum = []
for start_num in range(1, 17):
self.starnum.append(start_num)
self.payload = {}
self.headers = {
'Cookie': 'JSESSIONID=48304F9E8D55A9F2F8ACC14B7EC5A02D'}
## 呼叫高德api獲取公交線路的經緯度
### 這個key大家可以自己去申請
def get_location(self, line):
url_api = 'https://restapi.amap.com/v3/bus/linename?s=rsv3&extensions=all&key=559bdffe35eec8c8f4dae959451d705c&output=json&city=貴陽&offset=2&keywords={}&platform=JS'.format(
line)
res = requests.get(url_api).text
# print(res) 可以用于檢驗傳回的資訊里面是否有自己需要的資料
rt = json.loads(res)
dicts = rt['buslines'][0]
# 回傳df物件
df = pd.DataFrame.from_dict([dicts])
return df
## 獲取每趟公交的站點名稱
def get_line(self):
for start in self.starnum:
start = str(start)
# 構造url
url = self.url.format(start)
res = requests.request(
"GET", url, headers=self.headers, data=https://www.cnblogs.com/truggling-zx/p/self.payload)
soup = BeautifulSoup(res.text,"lxml")
div = soup.find('div', class_='list clearfix')
lists = div.find_all('a')
for item in lists:
line = item.text # 獲取a標簽下的公交線路
lines.append(line)
return lines
?
?
if __name__ == '__main__':
bus_stop = bus_stop()
stop_df = pd.DataFrame([])
lines = []
bus_stop.get_line()
# 輸出路線
print('一共有{}條公交路線'.format(len(lines)))
print(lines)
# 例外處理
error_lines = []
for line in lines:
try:
df = bus_stop.get_location(line)
stop_df = pd.concat([stop_df, df], axis=0)
except:
error_lines.append(line)
# 輸出例外的路線
print('例外路線有{}條公交路線'.format(len(error_lines)))
print(error_lines)
# 輸出檔案大小
print(stop_df.shape)
stop_df.to_csv('bus_stop.csv', encoding='gbk', index=False)

資料清洗
我們先來看效果,我需要對busstops列進行清洗,我們的總體思路,分列->逆透視->分列,我會接受兩種方法,一是Excel PQ,二是python,
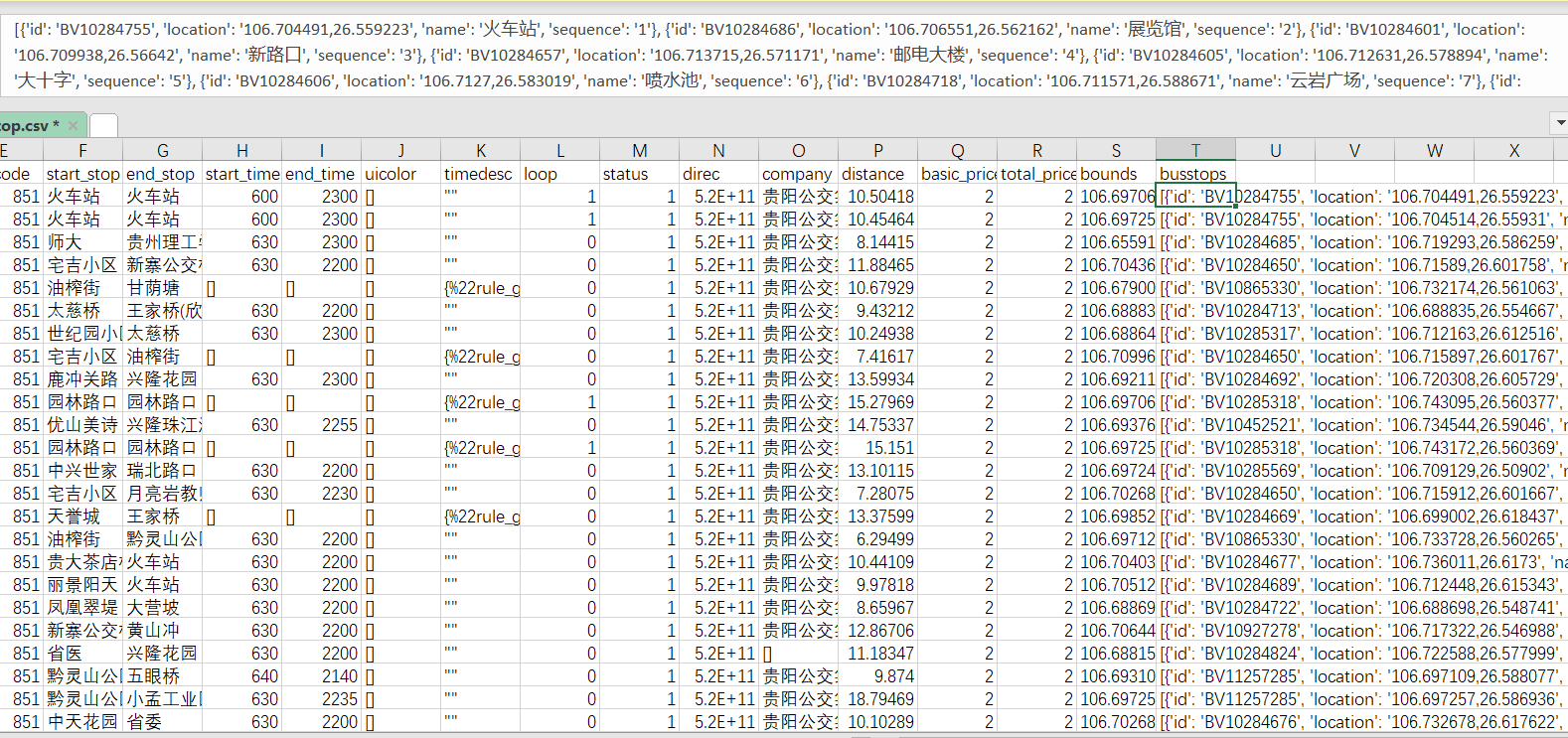
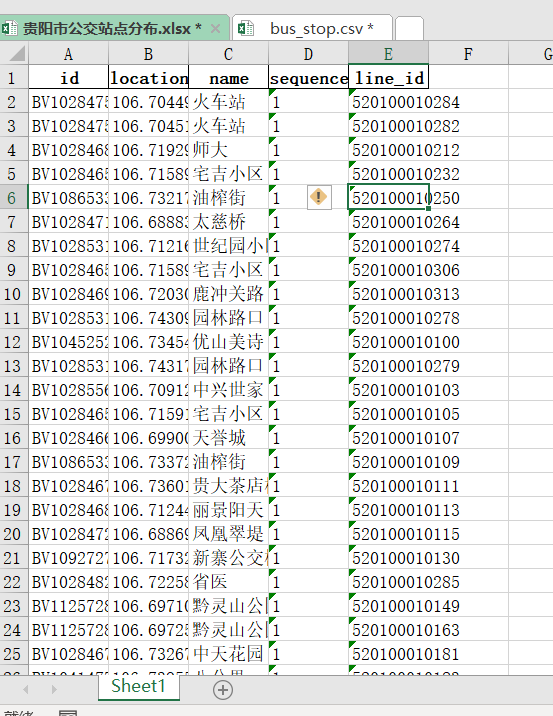
Excel PQ 資料清洗
這一方法完全利用PQ,純界面操作,問題不大,所以我們看看流程就可以了,核心步驟就是和上面一樣的,
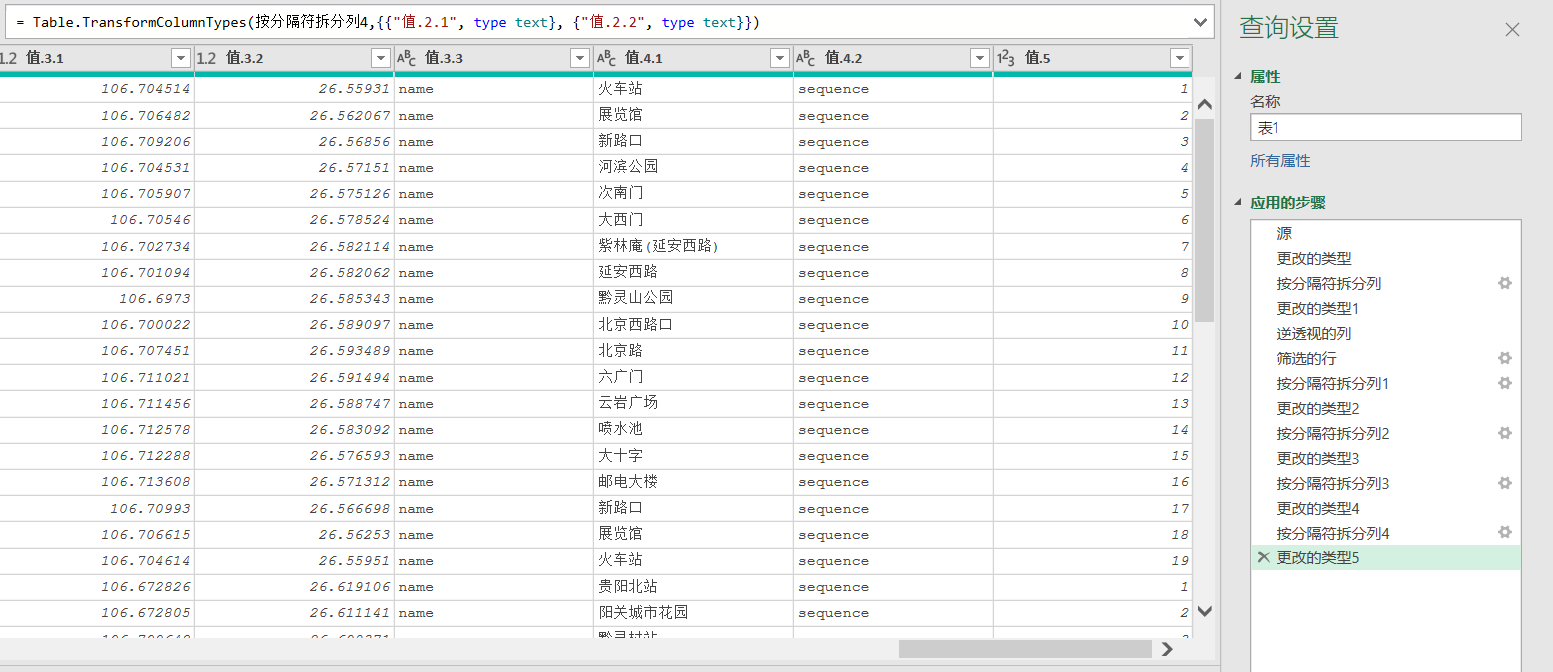
python資料清洗
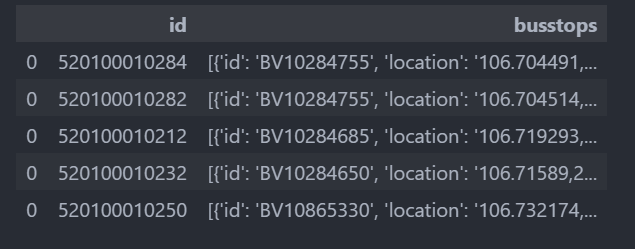
## 我們需要處理的busstops列和ID列
data = https://www.cnblogs.com/truggling-zx/p/stop_df[['id','busstops']]
data.head()
## 字典或者串列分列
df_pol = data.copy()
### 設定索引列
df_pol.set_index('id',inplace=True)
df_pol.head()
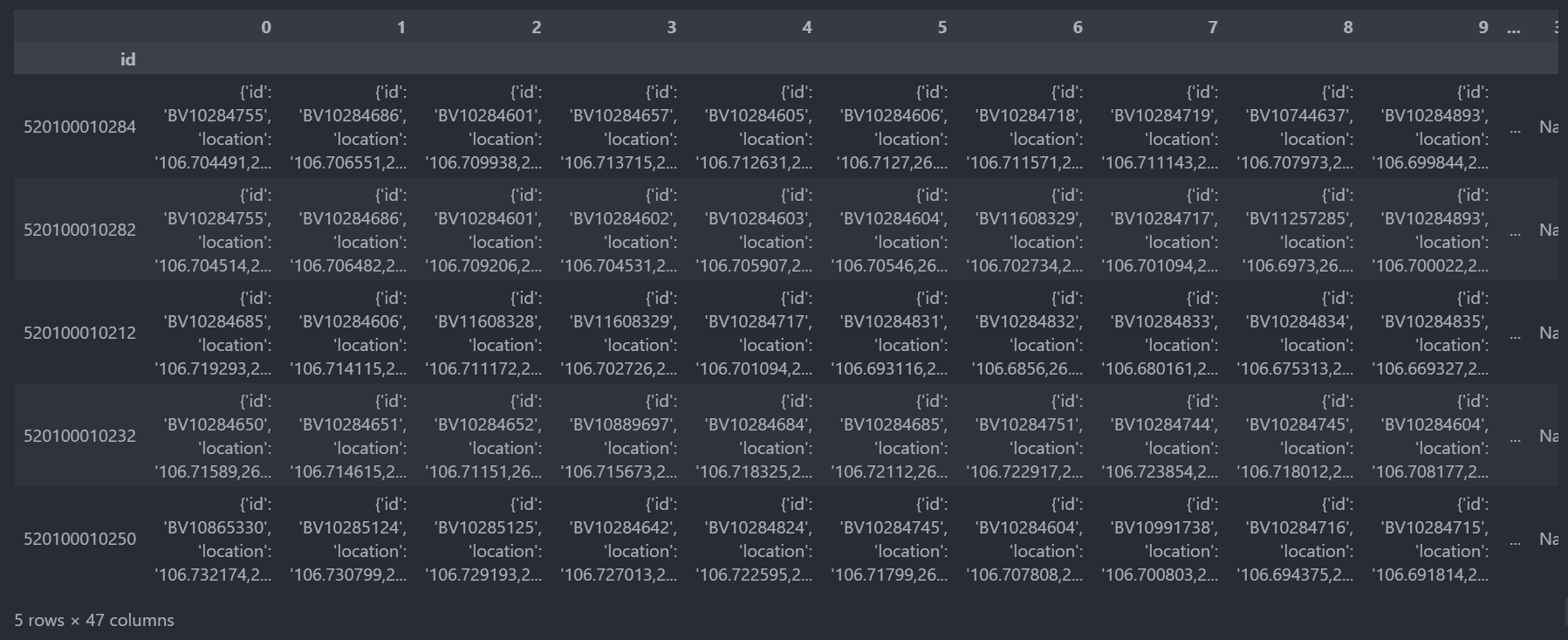
## 逆透視
### 釋放索引
df_pol.reset_index(inplace=True)
### 逆透視操作
df_pol_ps = df_pol.melt(id_vars=['id'], value_name='busstops')
df_pol_ps.head()
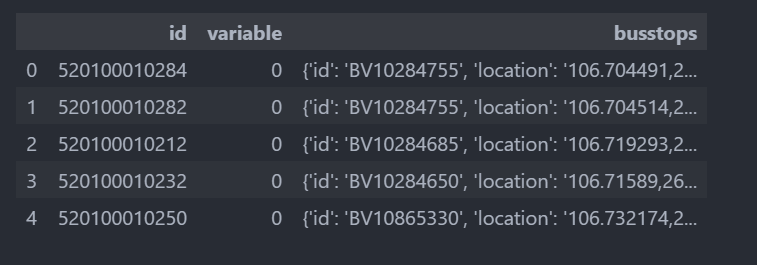
## 洗掉空行
df_pol_ps.dropna(inplace=True,axis=0)
df_pol_ps.shape
## 分列
### 設定line_id
df_parse['line_id'] = df_pol_ps['id']
df_parse = df_pol_ps['busstops'].apply(pd.Series)
df_parse
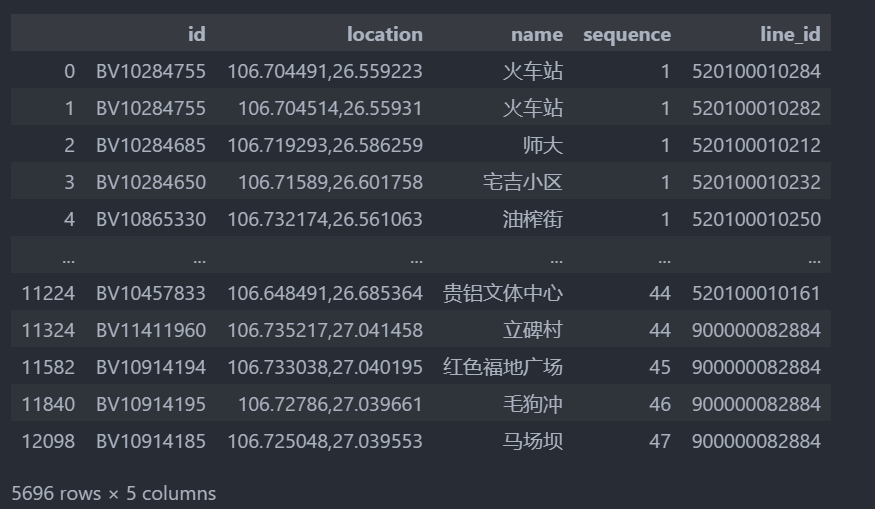
我這里補充一下,我們一般還要對location列進行分列,把Long,lat分列出來,但是我們這里就不做了,都是重復勞動,而且我用的pq清洗,快很多,
## 寫入檔案
df_parse.to_excel('貴陽市公交站點分布.xlsx', index=False)</pre>
QGIS坐標糾偏
QGIS基礎操作,我就不說了,順便說一下QGIS對csv格式支持較好,我推薦我們匯入QGIS的檔案為csv格式的檔案,
匯入csv檔案
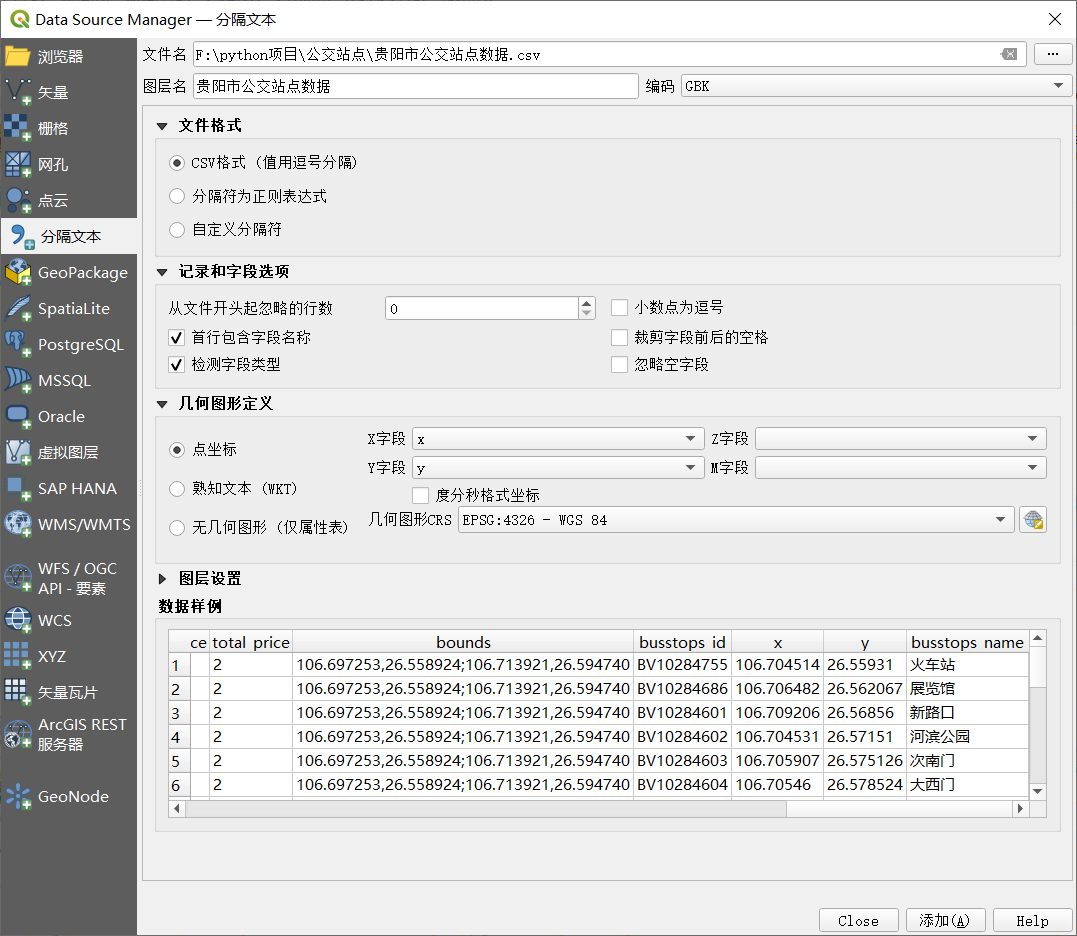
坐標糾偏
以前說了很多,我們高德地圖上的坐標是GCJ02坐標,我們需要轉成WGS 1984坐標,我們在QGIS里面需要借助GeoHey插件,
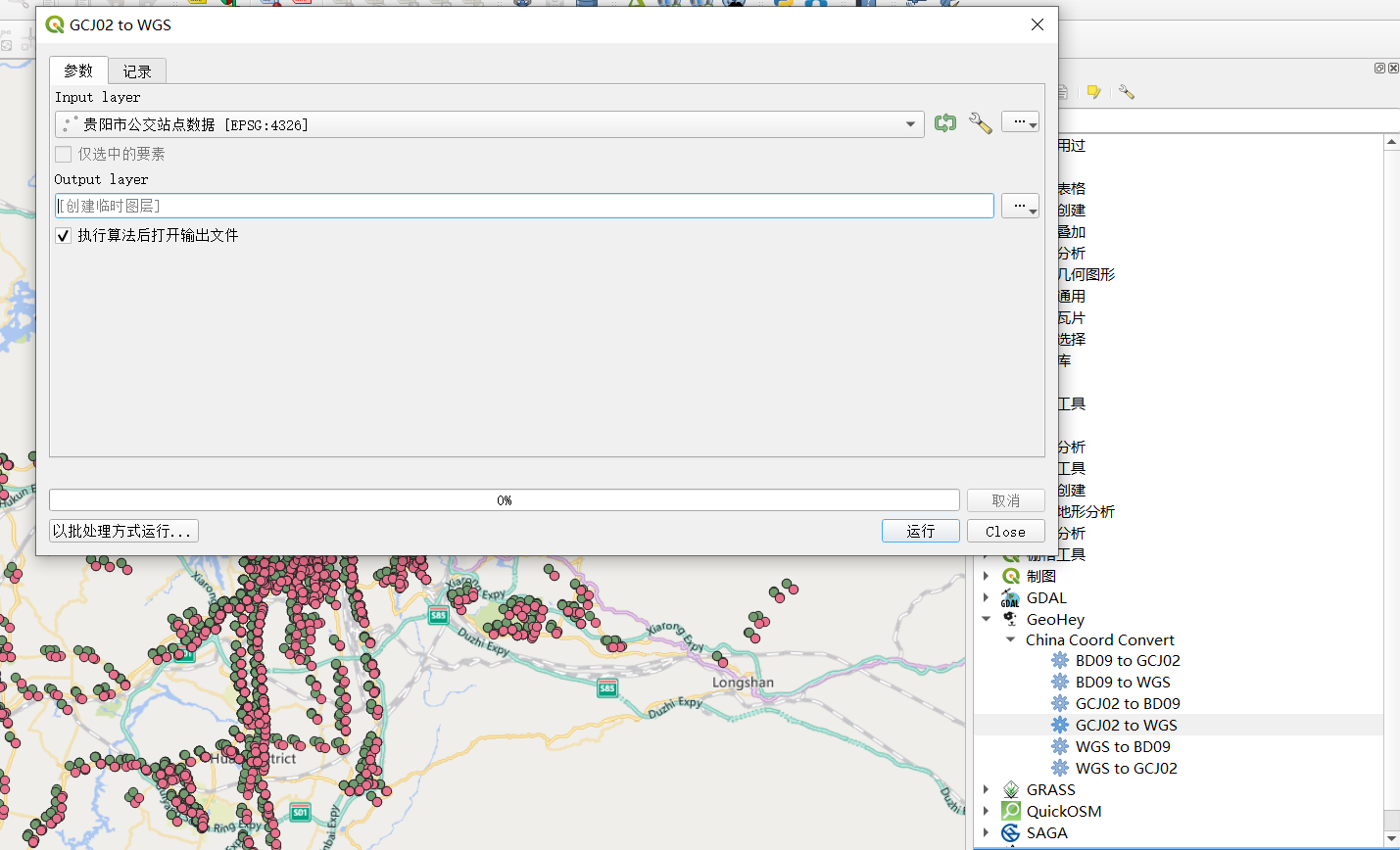
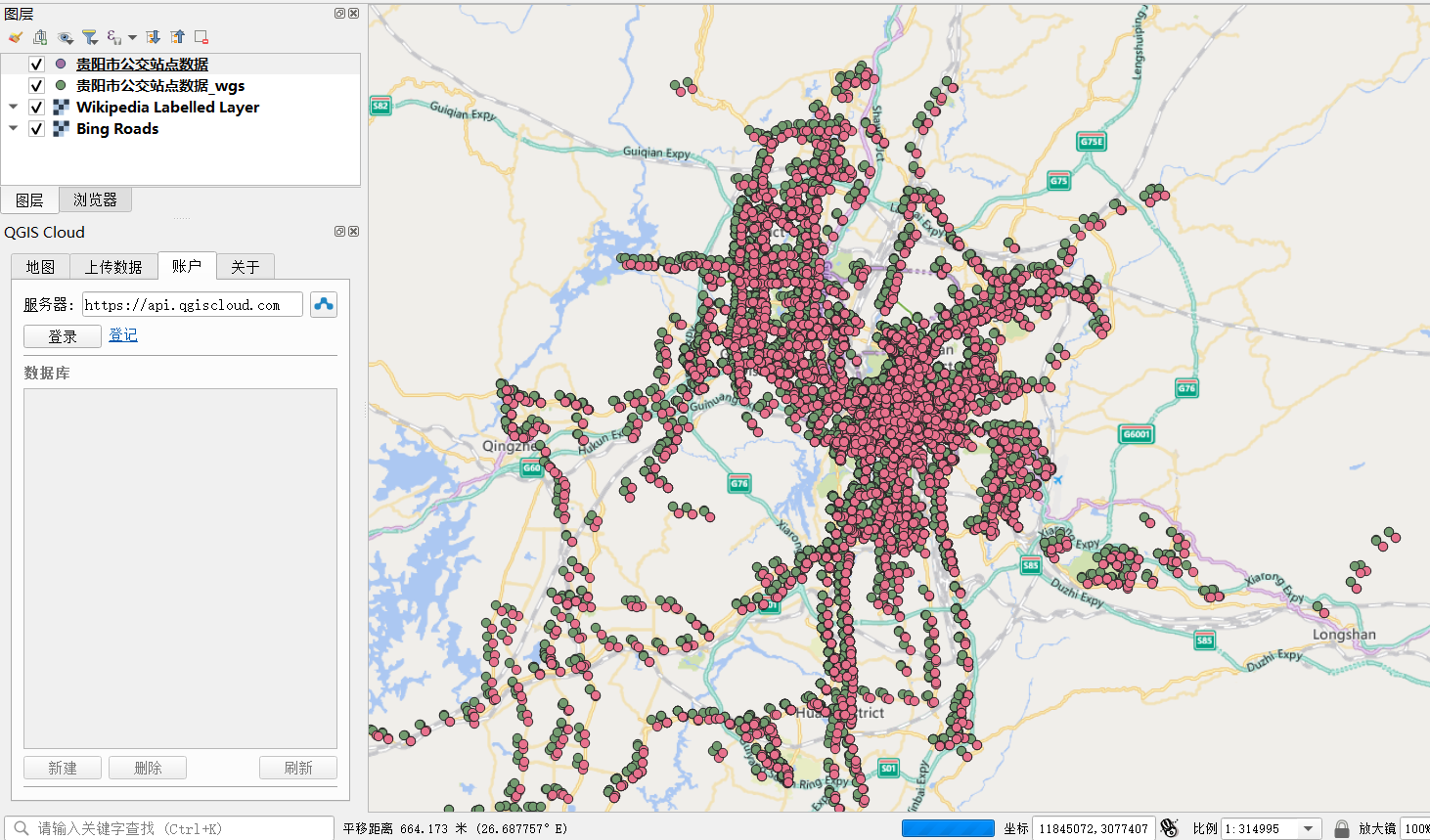
看一下這個坐標糾偏,區別還是很大,
總結
總的來說,我們還是推薦使用使用面向物件的方法來寫代碼,還有就是例外處理必不可少,我這次面對的問題是某些公交路線,高德API里面沒有,這樣就會例外,所以這次的例外處理不可缺少,從資料處理的角度來看,這次從速度和方便來說,pq完勝python,我推薦大家資料清洗就用pq,有些時候,我都會給出多種處理方法,pq看起來復雜,但是其實pq是最簡單的,總之,我高度推薦pq進行資料清洗,還有一點,python里面的索引比較麻煩,這次我要保證和bus_stop_id和line_id,這樣公交站點表和公交路線表才可以連接,其實這就是SQL里面的外鍵連接,所以我在python資料清洗的時候,涉及到大量的索引操作,在pq里面沒有這么復雜,說到這個索引,感謝我的SQL老師,當年她講解SQL里面的索引,約束,仿佛就在昨天,高德的這個key大家可以自己去申請,這個key可能有數量的限制,我接下來會把代碼上傳到Gitee,這個代碼的管理還是很重要的,自己也學習一下代碼的管理,接下來,感謝小學妹給的這個小專案,也感謝崔工對我的鼓勵,其實,我最近很忙,不太想寫文章的,最后,感謝認識的一個小學妹,她真的蠻優秀的,最后希望大家2021年最后這一個月萬事如意,開開心心,也希望我們都有一個光明的未來,還有一個坑,我建議大家在簡書上寫文章,真的本地的話,圖片上傳有問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/378101.html
標籤:Python
上一篇:演算法高級學習1