初識C語言
大家好,我是新來的菜鳥,我來開始給大家講解自己理解的C語言,講的不好還望不要噴的太厲害了(手動滑稽),謝謝大家的觀看!!!
什么是C語言?
首先我們講一下啥是語言,人和人不就是用語言交流嘛,那語言種類有很多種比如說漢語呀、英語(想必大家多多少少都學過一點吧,我這種菜鳥就是英語沒學(手動滑稽))、德語或者日語等等其他語言,那我們知道了語言就是用來進行交流的嘛,人和人可以用上面所述的語言交流,但是人和機器呢?那不就是機器語言咯(明知故問),是的,機器語言,說到機器語言這就得提起我所熟悉的那幾個,匯編語言(好像現在很少用了吧?)、C語言、C++、C#(有木有跟我剛見到這個語言一樣的念成c井,其實它叫C sharp)、Java、Python呀,其他的我就好像聽得比較少了吧,畢竟新人嘛,嘿嘿,都體諒體諒一下哈,多謝!回歸正題什么是C語言,書上是這樣說的:
C語言是一門通用計算機編程語言,廣泛應用于底層開發,C語言的設計目標是提供一種能以簡易的方式編譯、處理低級存盤器、產生少量的機器碼以及不需要任何運行環境支持便能運行的編程語言,
盡管C語言提供了許多低級處理的功能,但仍然保持著良好跨平臺的特性,以一個標準規格寫出的C語言程式可在許多電腦平臺上進行編譯,甚至包含一些嵌入式處理器(單片機或稱MCU)以及超級電腦等作業平臺,
二十世紀八十年代,為了避免各開發廠商用的C語言語法產生差異,由美國國家標準局為C語言制定了一套完整的美國國家標準語法,稱為ANSI C,作為C語言最初的標準, [1] 目前2011年12月8日,國際標準化組織(ISO)和國際電工委員會(IEC)發布的C11標準是C語言的第三個官方標準,也是C語言的最新標準,該標準更好的支持了漢字函式名和漢字識別符號,一定程度上實作了漢字編程,
C語言是一門面向程序的計算機編程語言,與C++,Java等面向物件的編程語言有所不同,
其編譯器主要有Clang、GCC、WIN-TC、SUBLIME、**MSVC、Turbo C等,
看了這么多籠統的解釋還是有繁瑣的,所以就這樣認為吧,C語言就是一門計算機編程語言,是人和計算機交流的語言,個人理解有錯誤的話希望大家指點指點,感謝!
第一個C語言程式
說了這么多概念,還是來點實際的吧,大家可以去網上搜索C語言編程軟體,各種各樣的都有,這里分享一下我使用的軟體,我使用的是Vs2022,下面我給大家演示一下第一個C語言程式:
#include <stdio.h> //頭檔案的包含 //-->注釋符號
int main()
{
printf("Hello World!\n");
return 0;
}
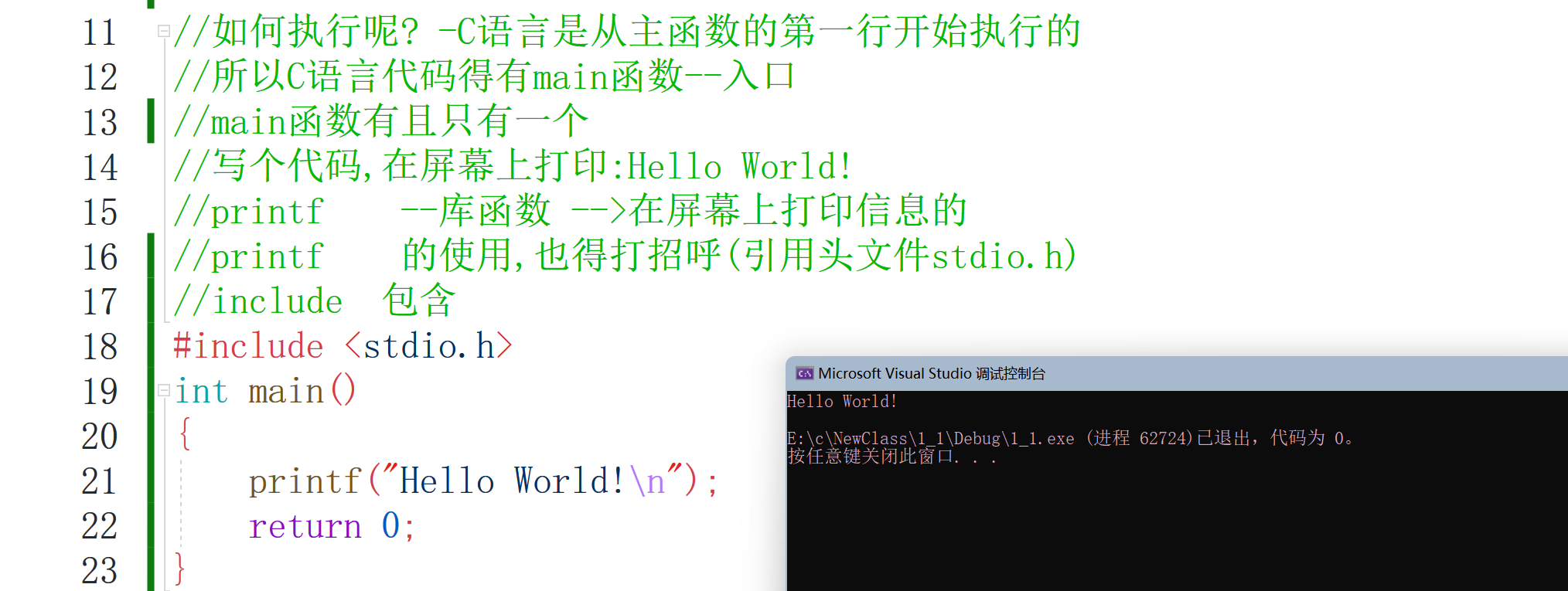
上面是代碼塊,我們可以看到這個黑色的框框里面出現了HelloWorld這幾個字符,
C語言規定每個程式都要主函式(main),C語言代碼都是從主函式開始執行的,而且主函式有且只有一個哦,stdio.h 是一個頭檔案 (標準輸入輸出頭檔案) , #include 是一個預處理命令,用來引入頭檔案, 當編譯器遇到 printf() 函式時,如果沒有找到 stdio.h 頭檔案,會發生編譯錯誤,return 0; 陳述句用于表示退出程式,printf()函式是列印函式,就是用來在螢屏上列印資訊的,
資料型別
資料型別什么是資料型別呢?在生活中有許多不一樣的資料,比如說我有一個朋友他年齡20歲,身高190cm,名字叫“小顧”,或者比如說買個瓶水2元錢,或者是買菜16.9元錢.....等等,我們需要記錄這些不同型別的數字,在計算機中就需要不同的資料型別來表示,而C語言中基本資料型別有這幾種:
char //字符資料型別
short //短整型
int //整形
long //長整型
long long //更長的整形
float //單精度浮點數
double //雙精度浮點數
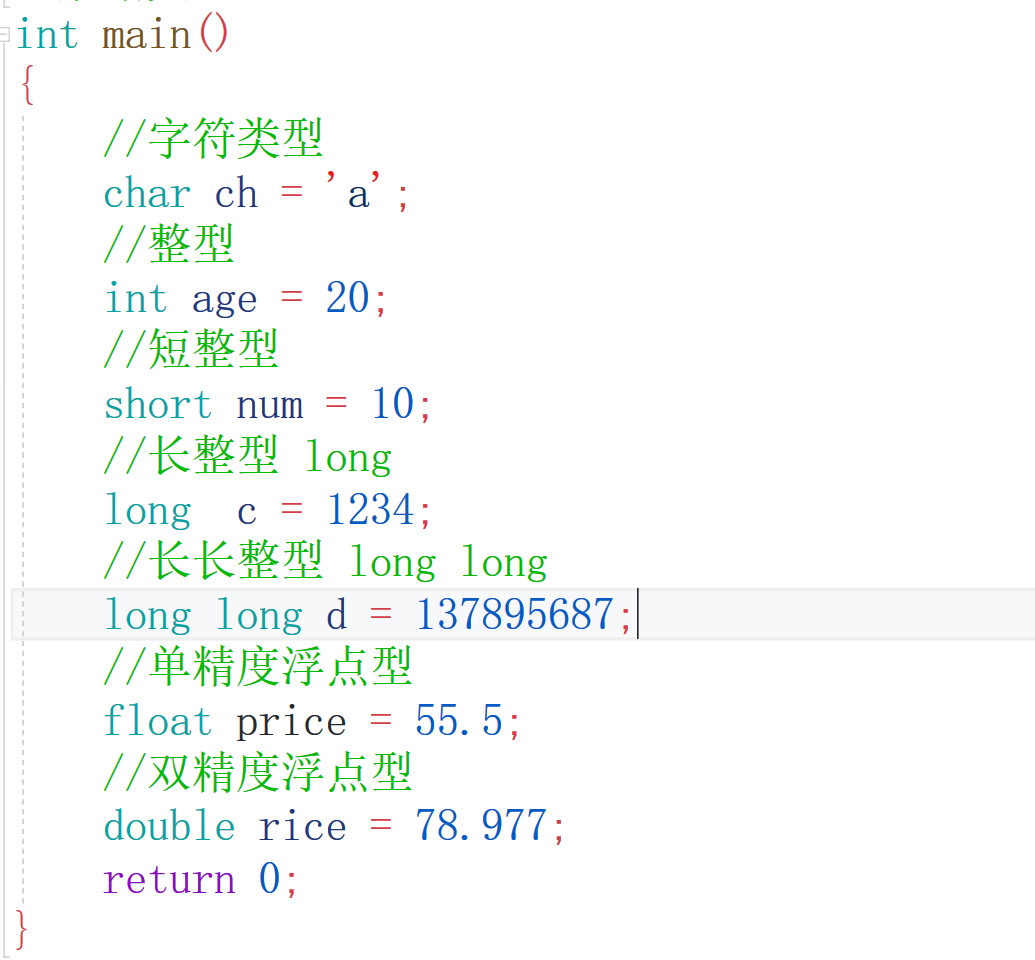
解釋一下這幾個不同型別吧,char型別是用來表示一個字符型別的,就比如說字符a,而short int long long long這幾個都是用來表示整數的,比如說20、100、50000等等,float double這兩種呢就是用來表示小數的,比如說3.1415....后面列舉不出來了忘了這個圓周率了,只是說它們的精度不同也就是小數點后面的個數不同,那C語言沒有字串型別嗎?也就是像這樣的“i like China”,好像確實沒有明確哪種型別是字串型別,但是有個是用char [12]="i like China"表示字串型別的,
那既然有這么多型別,那它們的大小是多少呢?C語言中規定求型別大小是用sizeof關鍵字,大小是位元組
#include <stdio.h>
int main()
{
printf("%d\n", sizeof(char));
printf("%d\n", sizeof(short));
printf("%d\n", sizeof(int));
printf("%d\n", sizeof(long));
printf("%d\n", sizeof(long long));
printf("%d\n", sizeof(float));
printf("%d\n", sizeof(double));
printf("%d\n", sizeof(long double));
return 0;
}

通過觀察我們可以知道
| 資料型別 | 型別大小 |
|---|---|
char |
1 |
short |
2 |
int |
4 |
long |
4 |
long long |
8 |
float |
4 |
double |
8 |
大家第一次看到這個位元組可能有點疑問,其實換個符號大家可能就認識了,byte,大家看見有木有點熟悉,不熟悉的話再換一個KB或者MB、GB這樣大家應該會熟悉了,其實在計算機當中,單位有位元位,位元組這一說,計算機中最小的單位是位元組,而一個位元組是8個位元位,一個位元位很簡單,就是0或者1,
說明一下:為什么會出現這么多不同型別呢?
這是因為每個型別所占的記憶體空間大小不同,所以我們合理使用不同的型別,可以節省記憶體空間,避免浪費嘛,你說是吧(手動滑稽),
變數和常量
看見這兩個詞會怎么理解?我用最通俗易懂的話來講:變數就是那些可以被改變的值,常量就是不能被改變的值,
舉個例子:
變數:年齡、體重、薪資、存款等.....
常量:圓周率、身份證號碼、血型等.....
變數
定義變數
在C語言中定義變數的方法是怎樣的呢?
之前了解了資料型別是什么,定義變數那就是想要什么型別的變數就定義什么型別的變數,
C語言定義變數的方式是:型別 變數名 = 初始化值;
int age = 20;
float weight = 45.5f;
char ch = 'w';
變數的分類
- 區域變數 定義在函式體內或者說 在
{}內部 - 全域變數 定義在函式體外
#include <stdio.h>
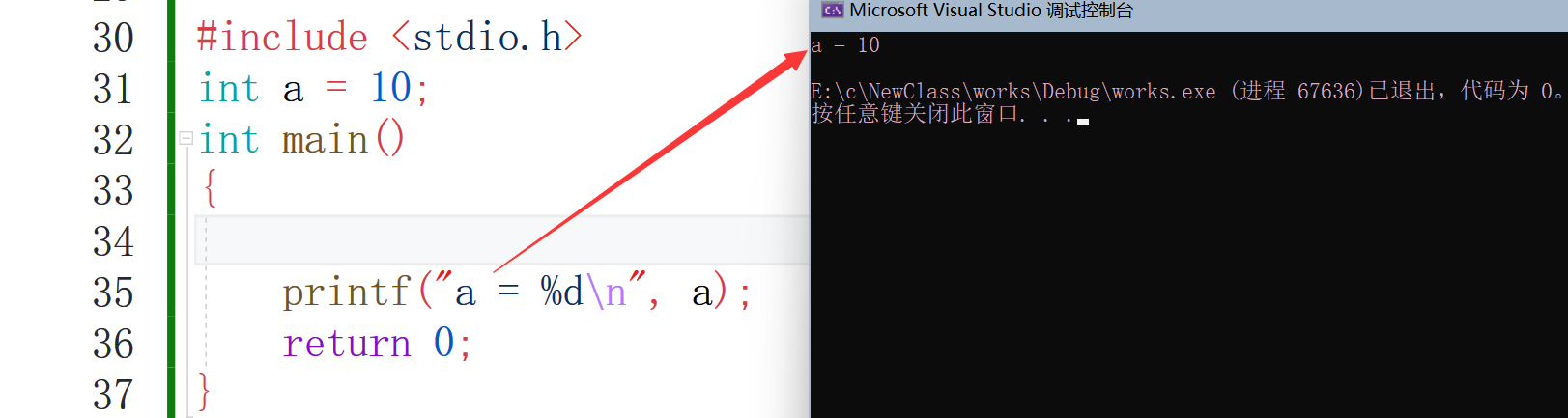
int a = 10;//全域變數
int main()
{
int a = 100;//區域變數
return 0;
}
通過上面代碼大家應該知道了什么是全域變數和區域變數了吧,
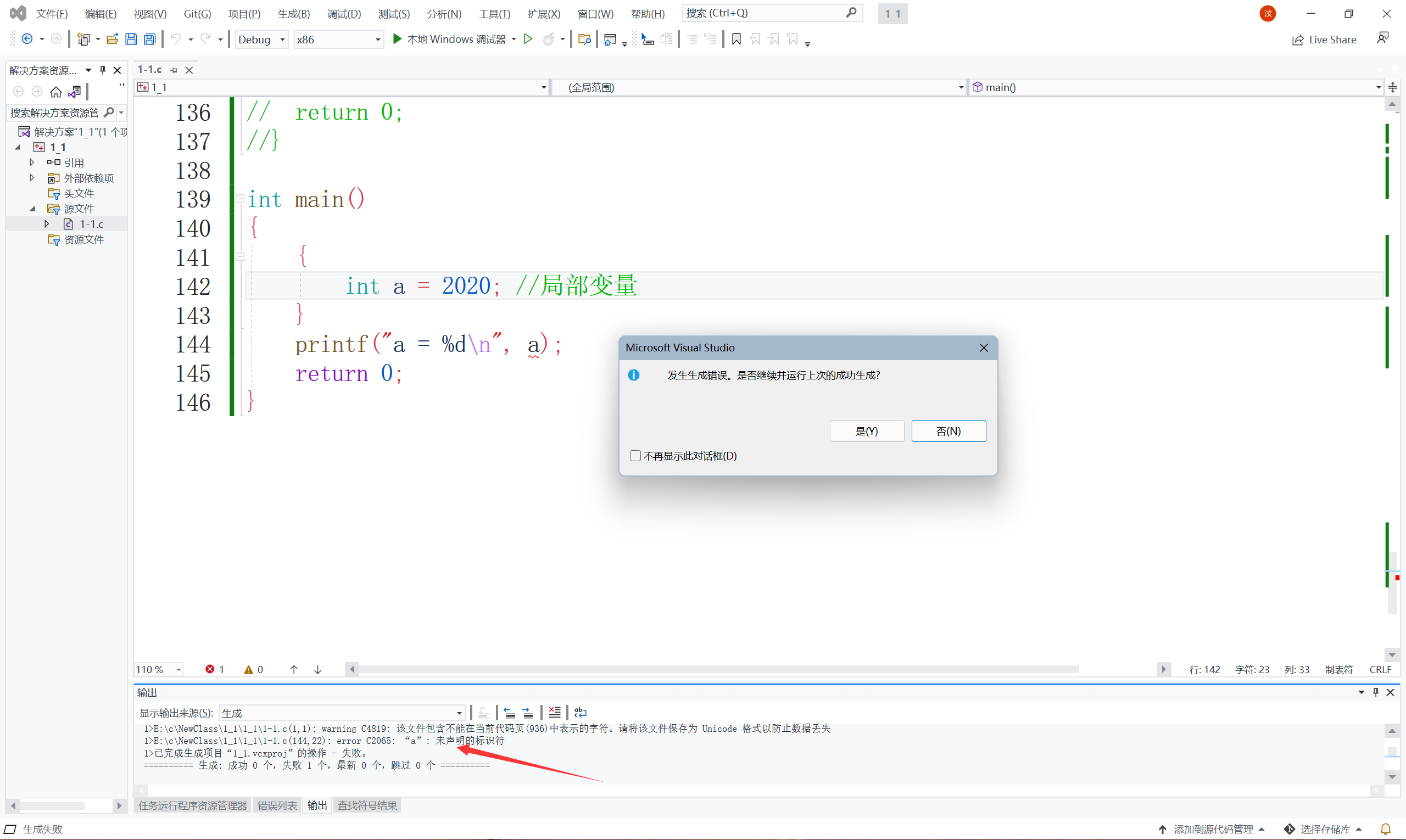
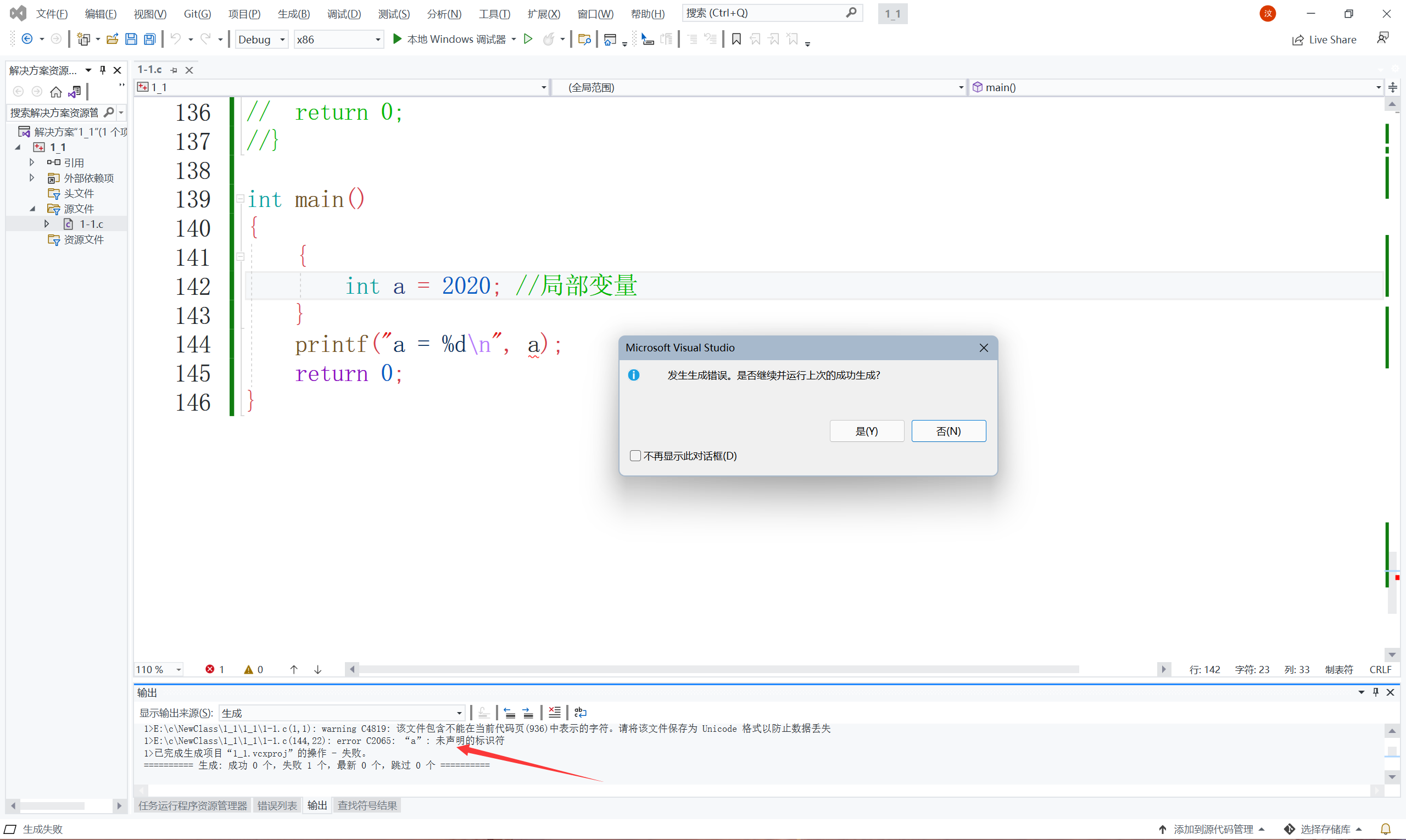
看為什么出錯了呢?雖然a變數是在函式體中,也是區域變數,但是為什么就錯了呢?那是因為{}限制它的作用范圍,再看
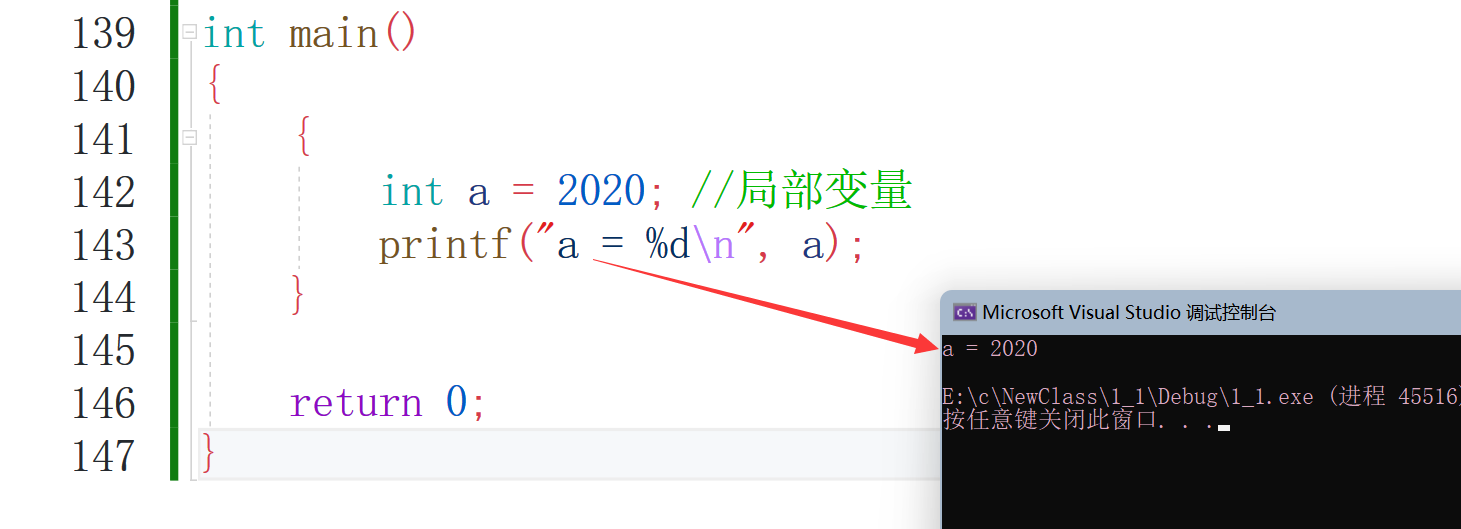
這樣又沒有問題了,所以說在函式內部的雖然是區域變數但是它的作用范圍會被限制的,作用范圍下面會說到的,各位客官請勿著急,
接下來我們看個例子
#include <stdio.h>
int b = 2019;//全域變數
int main()
{
int a = 2020;//區域變數
//這里區域變數與全域變數同名了 會發生什么呢?
int b = 2021;//區域變數
printf("b = %d\n",b);
return 0;
}
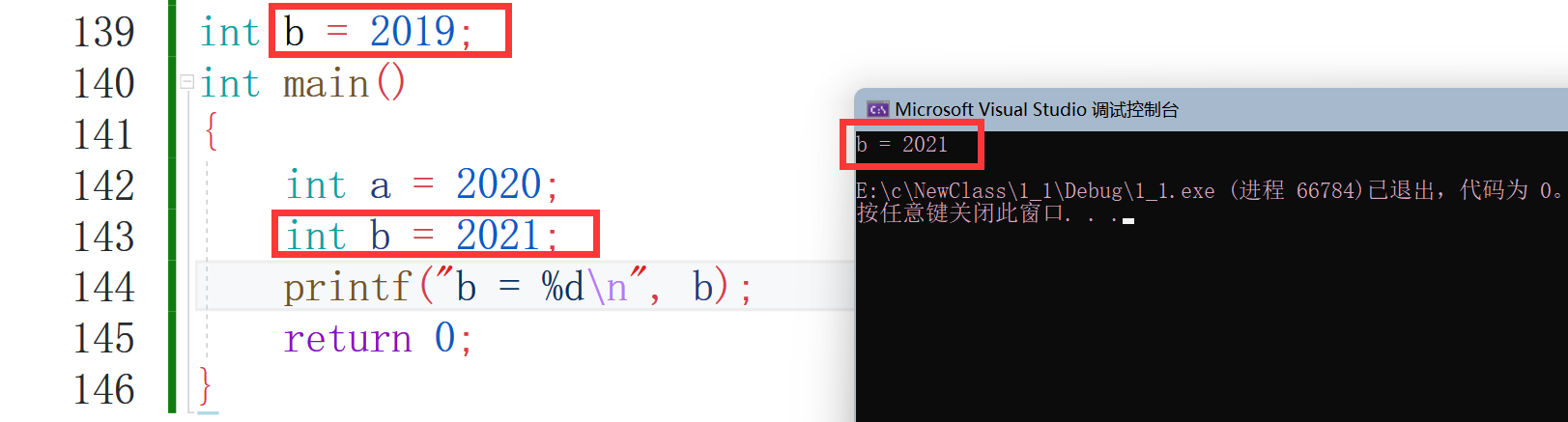
可以看到,當全域變數與區域變數同名時候,優先使用的是區域變數,
變數的使用
我們了解了怎么定義變數,現在我們了解怎么去使用它,
計算兩個數的和,num1,num2,從鍵盤輸入數值,求和然后列印到螢屏上代碼如下:
#include <stdio.h>
int main()
{
int num1 = 0;
int num2 = 0;
int sum = 0;
printf("輸入兩個運算元:>");
scanf("%d %d", &num1, &num2);
sum = num1 + num2;
printf("sum = %d\n", sum);
//這里介紹一下輸入,輸出陳述句
//scanf 輸入陳述句 顧名思義是向計算機輸入值
//printf 輸出陳述句 上面有使用過,就是在螢屏上列印一段資訊
return 0;
}
大家如果也是用的是VS2022或者VS2019,在這個代碼運行時會出現一個錯誤,那就是scanf函式unsafe,意思就是這個函式不安全,這個時候我們可以在后面加上 _s 就變成了scanf_s,或者大家不想這么麻煩的話就在源檔案最上面加上define _CRT_SECURE_NO_WARNINGS 1即可,
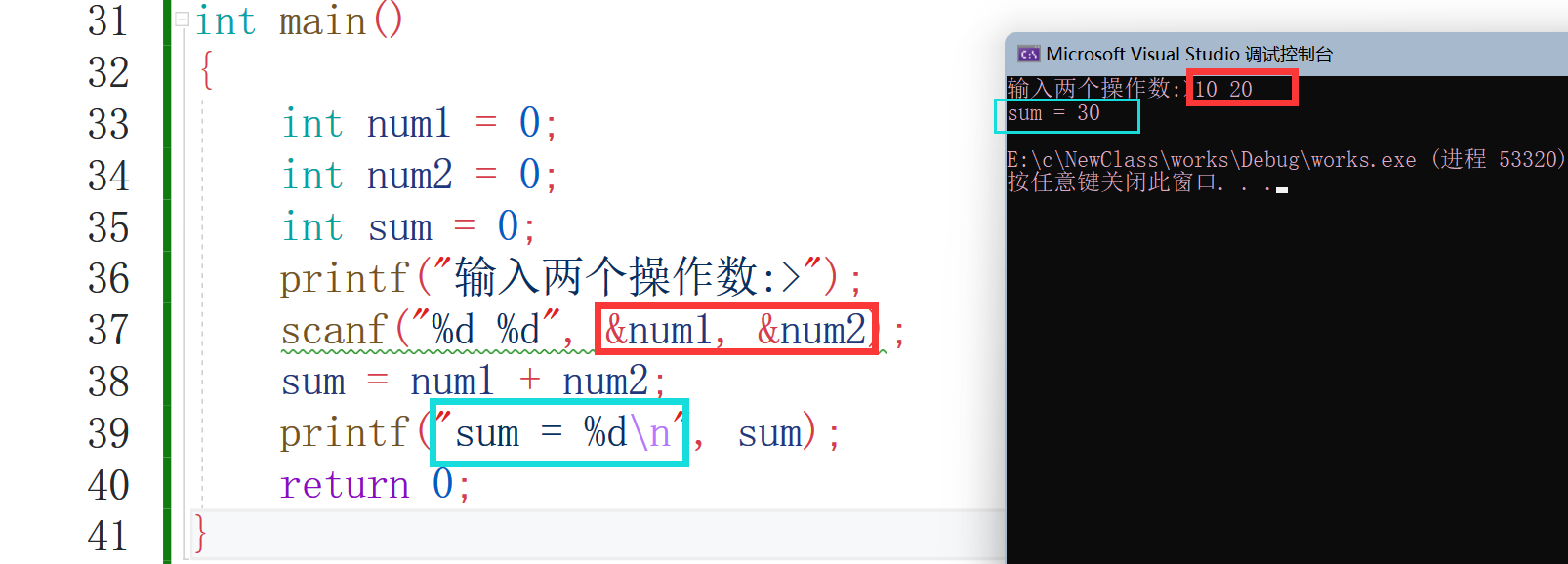
上述圖片只是展示了變數的一種用法,后續還會有其他用法,之后用到再說,現在只是初步認識一下C語言,
變數的作用域和生命周期
之前有提到過作用范圍,而接來下要講的作用域就跟作用范圍有關,
作用域
作用域(scope),程式設計概念,通常來說,一段程式代碼中所用到的名字并不總是有效/可用的
而限定這個名字的可用性的代碼范圍就是這個名字的作用域 ,
可以這樣理解作用域就是作用范圍,個人的理解哈,我們用代碼形式來觀察
可以看見,程式可以正常運行,那我們看下面:
這下報錯了,為啥呢?這就是作用域的問題了,看完區域變數,我們來看全域變數:
可以看見全域變數作用域是整個工程,得出結論
- 區域變數的作用域是變數所在的區域范圍,
- 全域變數的作用域是整個工程,
生命周期
看見生命周期我們會想到什么?人的一生?從出生到離開這個世界,這也算是是生命周期,
官方的解釋是:
變數的生命周期指的是變數的創建到變數的銷毀之間的一個時間段,
那變數的宣告周期呢?變數什么時候創建、什么時候銷毀,這之間的時間段,
用事實來說話,眼見為實,咱們看代碼效果圖:
我們之前講作用域時,不輸入下面那條printf()函式陳述句時是不會報錯的,但是添加了后為什么又報錯了呢?這就是這個變數a的生命周期到了,出了{}后a變數生命周期到了就自行銷毀了,所以后面的輸出陳述句執行就會報錯,全域變數的生命周期應該不用我說了吧(手動滑稽)?跟全域變數的作用域有關,
小結:
- 區域變數的生命周期:進入作用域生命周期開始,出作用域宣告周期結束,
- 全域變數的生命周期:整個程式的生命周期,程式結束了全域變數生命周期也就到頭了,
常量
常量:不可變的值,C語言中定義常量和定義變數的形式是不同的,
C語言中常量可以分為以下幾種
-
字面常量
-
const修飾的常變數 -
#define定義的識別符號常量 -
列舉常量
#include <stdio.h>
#define MAX 1000 //#define的識別符號常量
//列舉常量
enum COLOR
{
RED,
GREEN,
BLUE
}
//RED,GREEN,BLUE皆是列舉常量
int main()
{
//1.字面常量
3.1415926;//浮點型常量
1000;//整型常量
'a';//字符常量
"hello"//字串常量
//2.const修飾常變數
//int num = 20;//變數
const num = 20;
num = 50;//加上const后能否改變?
printf("num = %d\n",num);
return 0;
}
看代碼作用還是小了點,咱們看點實際點的,
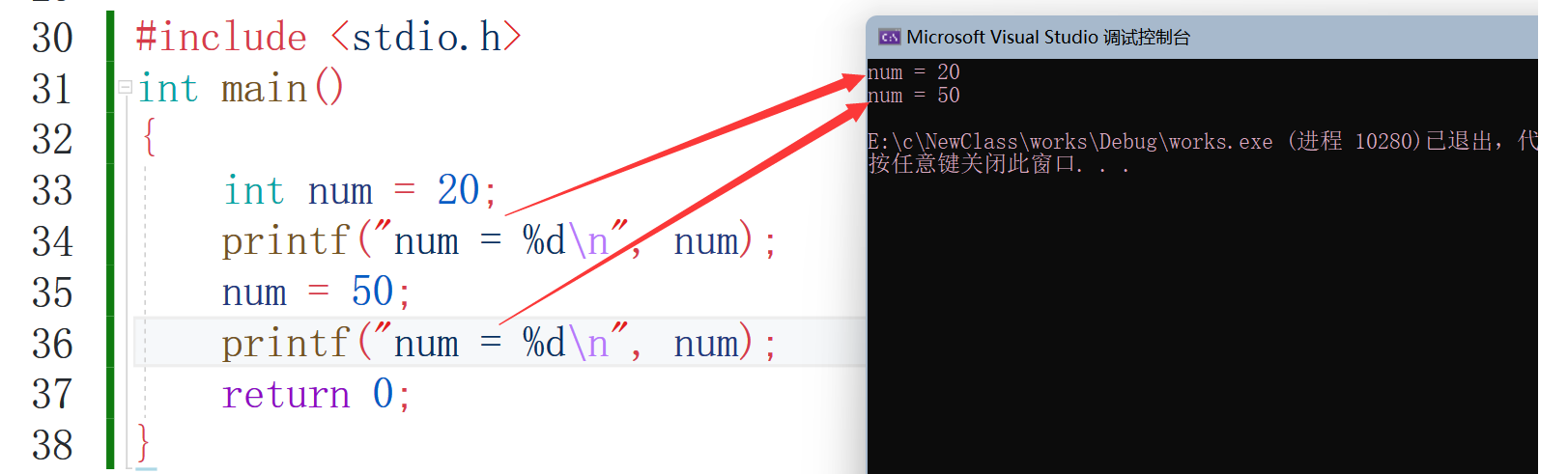
可以看到num這個變數是可以被改變的,接下來再看:
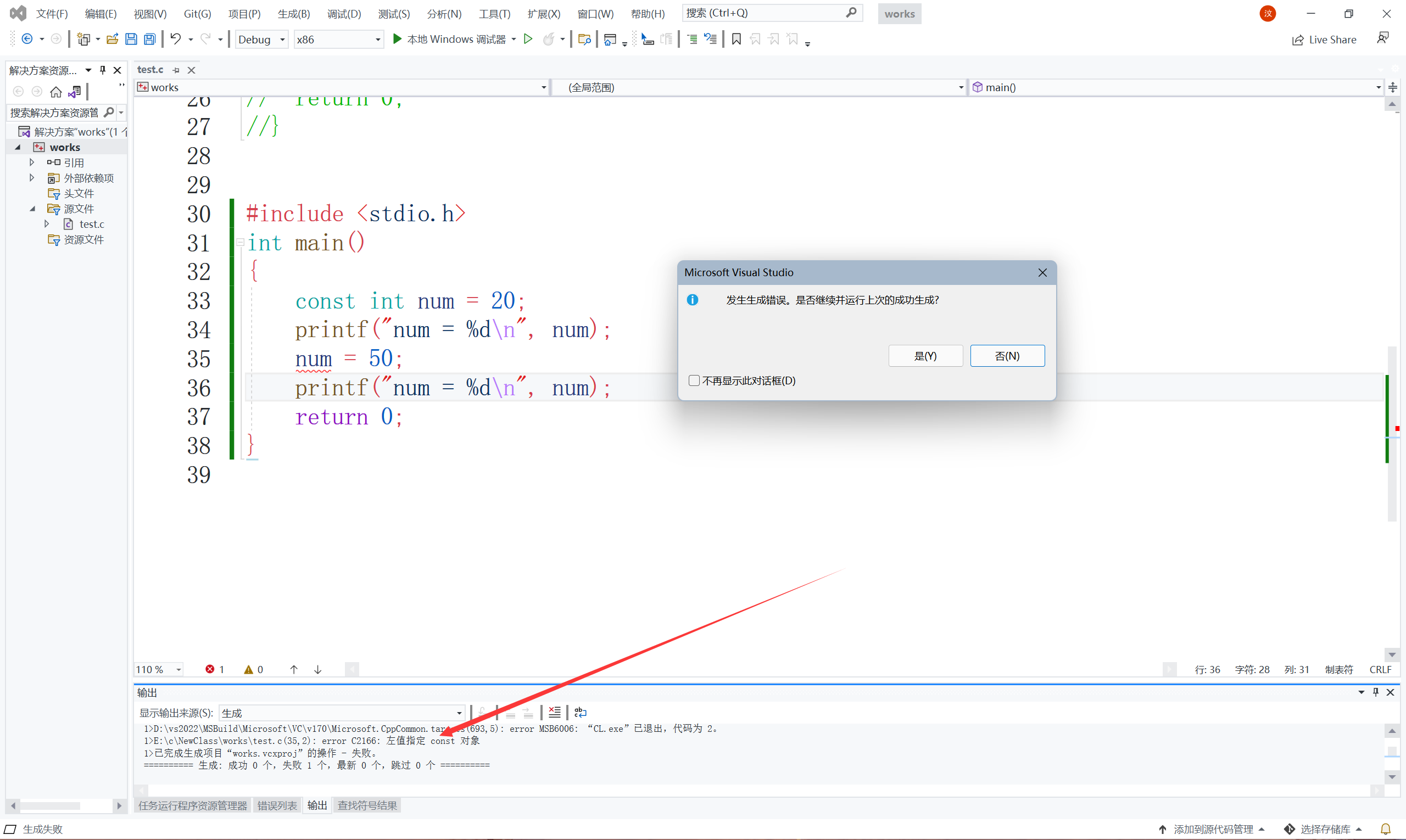
加上const就修改不了了,這是怎么回事?因為被const修飾的變數叫做常變數,具有常屬性,常屬性就是不能被改變的屬性,雖然不能被改變,但是它本質上還是個變數,
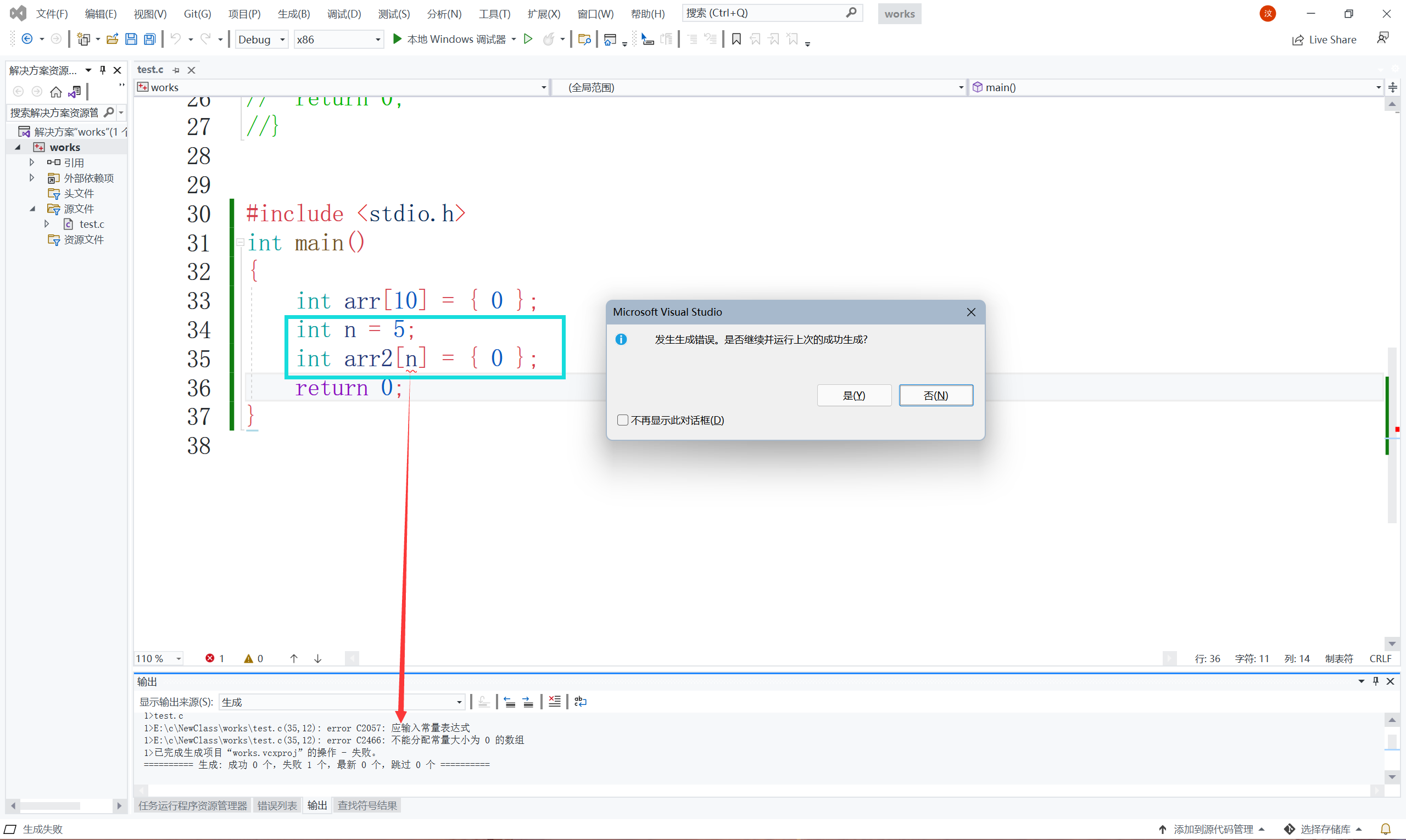
我們創建陣列時,[]內要是個常量,大家可以看到錯誤資訊,這說明n是個變數,你這不是廢話嘛又沒加上const修飾,那好我們加上const修飾一下看看會怎樣?
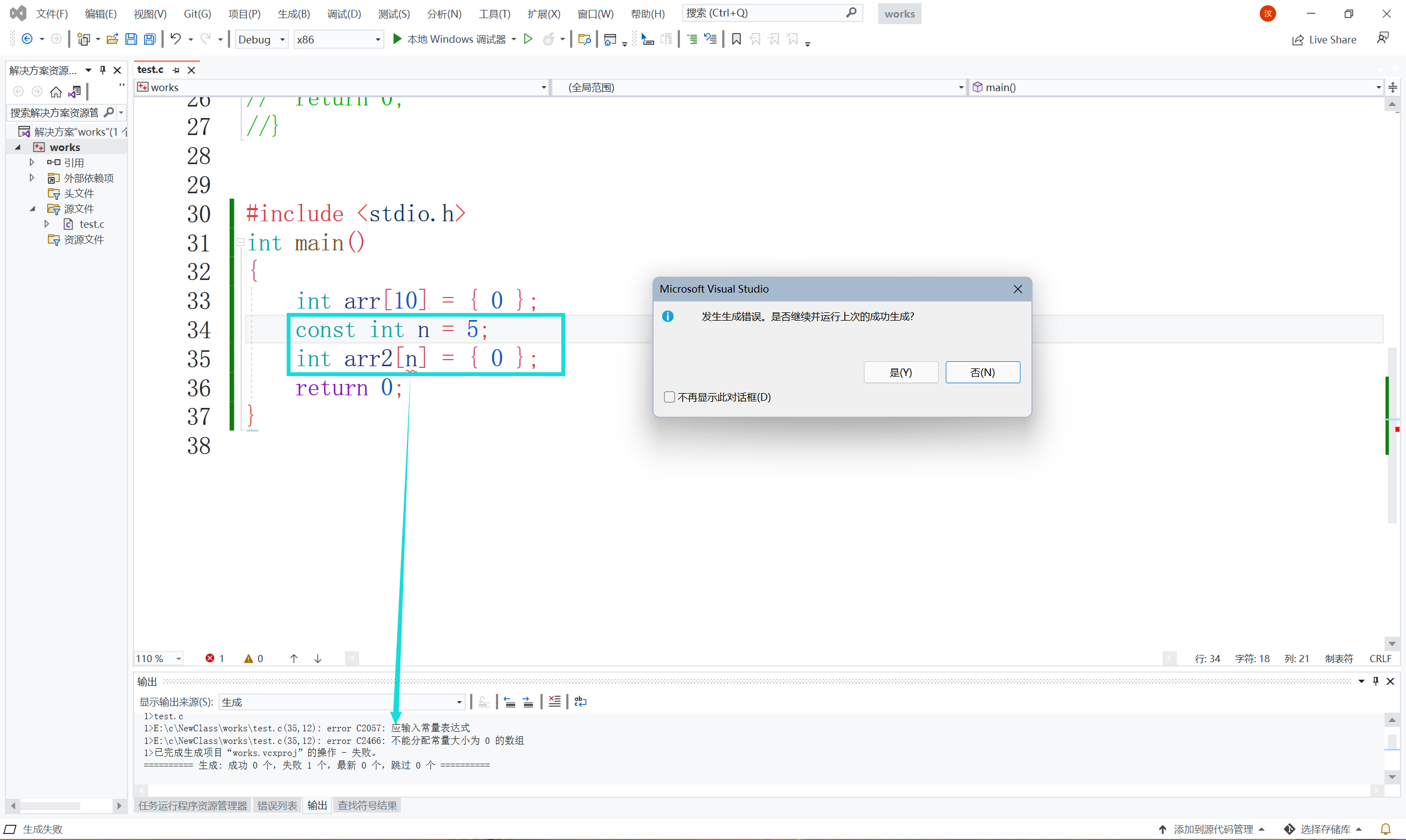
喏,看見沒,即便加上const修飾,結果還是一樣的,這證明了什么,這就證明了const修飾的變數,本質上還是個變數,只是具備了常屬性,也就是不能被修改的屬性,
再看一個列舉常量,列舉就是一一列出來,像三原色、性別等等可以一一列舉出來的值,它們都是有實際值得,我們也可以列印出來的,
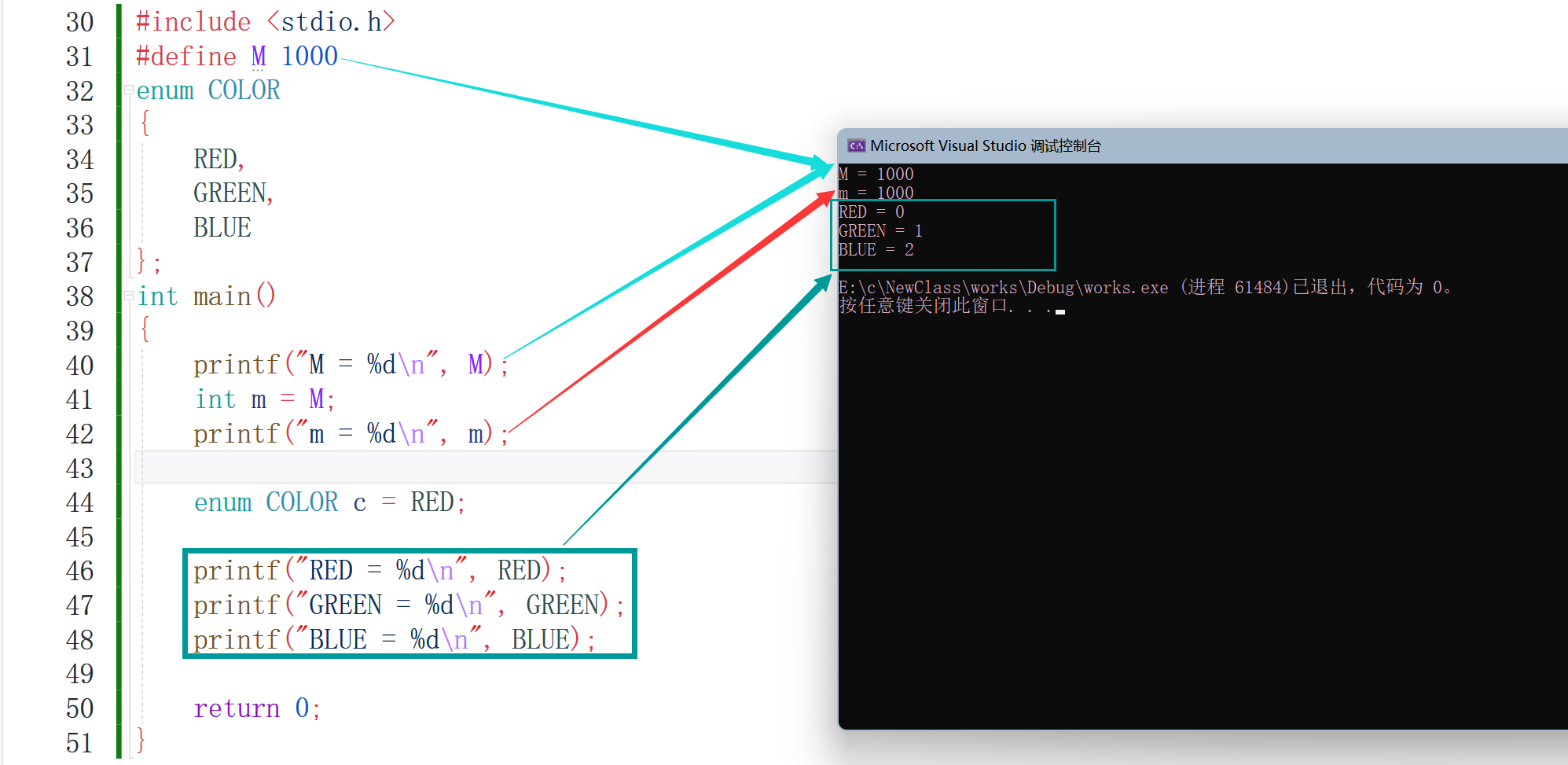
這里我把#define定義的識別符號常量也放進去了,定義了列舉常量三原色,并且也一一列舉了,可以看到#define定義的也是個常量,無法被修改,再看列舉常量它們其實也是有值的,而且還是遞增的值,但能不能改呢?其實不能,但是可以給它賦初值,
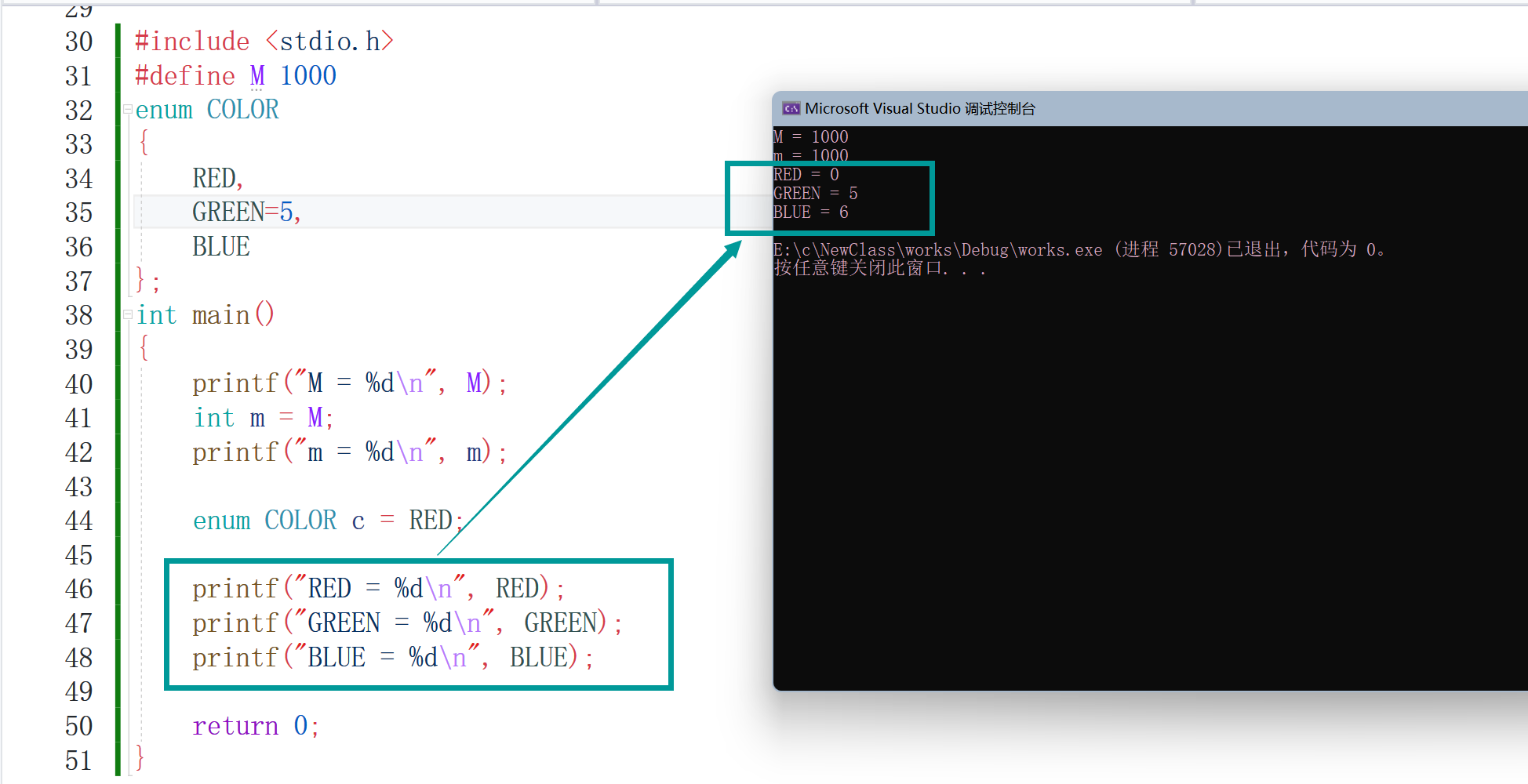
可以看到賦初值后,下一個也會跟著上面的初值改動而改動的,
字串+轉義字符+注釋
字串
什么是字串?在C語言中,字串就是一串字符,怎么表述的呢?用“”括起來的一串字符就是字串,
最重要的一點是,字串結束的標志是一個‘\0’的轉移字符,因為在計算字串長度的時候‘\0’是結束標志,不算做字串的內容,但是用陣列存盤字串的時候,陣列的長度需要將‘\0’計算上,只是單獨計算字串長度是不計算‘\0’
#include <stdio.h>
int main()
{
//C語言中用字符陣列存盤字串,陣列也就是一組型別相同的元素的集合
char str1[]="hello";
char str2[]={'h','e','l','l','o'};
char str3[]={'h','e','l','l','o','\0'};
printf("%s\n",str1);
printf("%s\n",str2);
printf("%s\n",str3);
return 0;
}
我們來看一下上面代碼的執行效果:
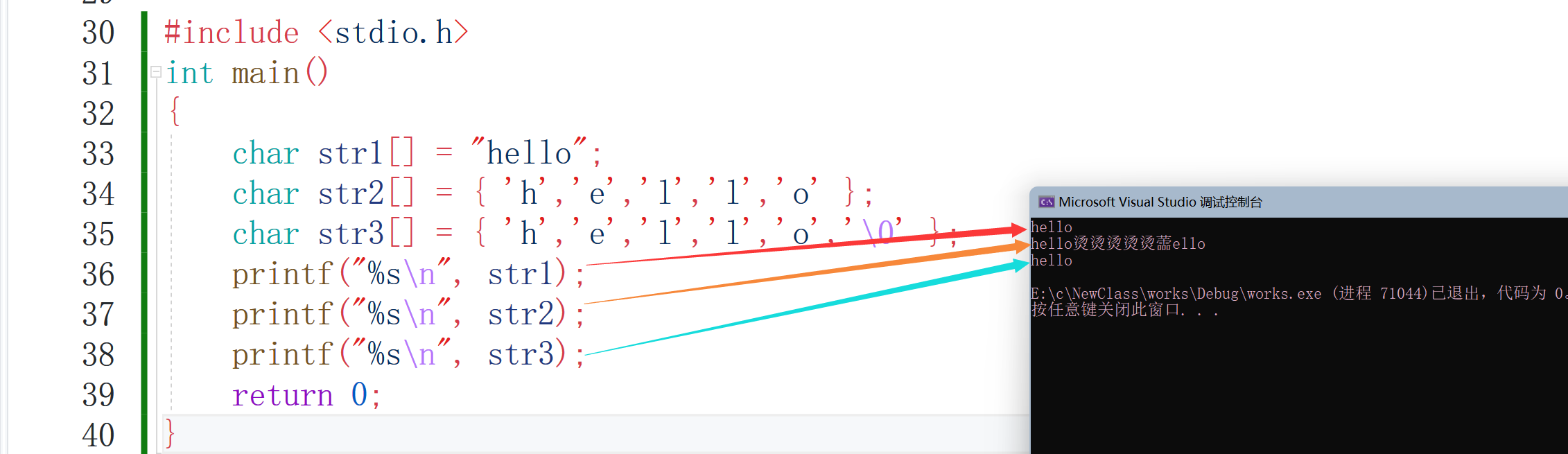
咦?為什么第二個跟其他兩個不一樣呀?這就是跟字串結束的標志有關,我們除錯一下看看這幾個陣列中放的是什么,
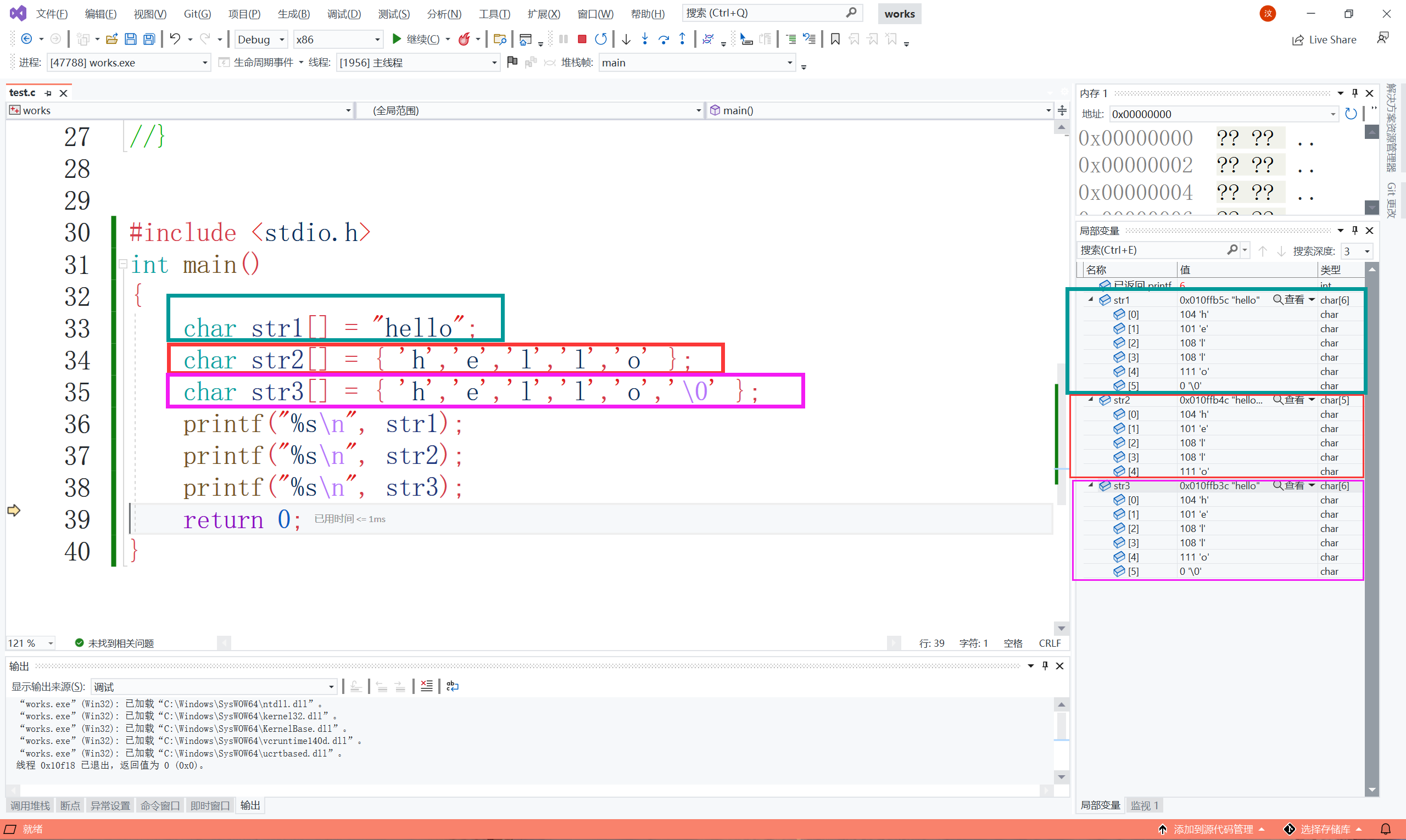
可以看到第一個和第三個陣列放的都是一樣的,而第二個少了個‘\0’,而且第一個陣列不是5個字符嗎,怎么多了一個,之前說字串結束的標志是‘\0’,因為第一個陣列是用來存盤字串的,所以會默認在結尾加上‘\0’只是不會顯示出來,但是在計算陣列長度的時候就會把‘\0’加上去,接著說第二個為啥是這樣的,因為第二個陣列最后一個不是‘\0’所以會在記憶體中后面去找‘\0’,找到‘\0’之前的資料也會被列印出來,所以第二個就是會是這樣列印的,
轉義字符
轉義字符?啥是轉義字符呢?字面意思,轉變意思的字符,
如果我們要在螢屏上列印一個目錄:d:\vs2022\test.c,我們該如何寫代碼呢?之前我們用過printf函式列印資訊,
#include <stdio.h>
int main()
{
printf("d:\vs2022\test.c\n");
return 0;
}
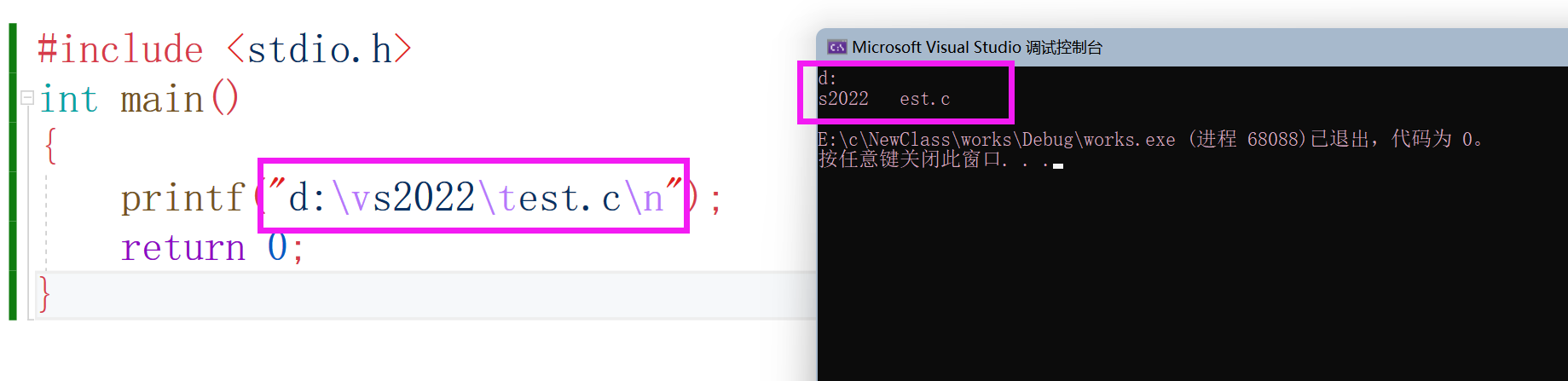
為啥跟我們期待的不一樣呢?我們看代碼上面有語法高亮,\v \t 跟\n這個都改變了顏色,說明它們是一樣型別的,之前列印其他資訊的時候會看見‘\n’,這個我們通過觀察應該知道這是一個換行的標志,相當于在末尾加了一個回車鍵,這就是轉義字符了,那在C語言中又有那些轉移字符呢,下面我列一張表給大家觀看觀看,
| 轉義字符 | 意義 |
|---|---|
| ? | 在書寫連續多個問號時使用,防止它們被決議成三字母詞 |
| \ ' | 用于表示字符常量 ‘ |
| \ ‘’ | 用于表示一個字串內部的雙引號 |
| \ \ | 用于表示一個反斜桿,防止它被解釋為一個轉移字符 |
| \a | 警告字符,會發出蜂鳴聲 |
| \b | 退格符號 |
| \f | 進制符號 |
| \n | 換行 |
| \r | 回車 |
| \t | 水平制表符號 |
| \v | 垂直制表符號 |
| \ddd | ddd表示1~3個八進制數字,如:\157X |
| \xdd | dd表示2個十六進制數字, 如:\xFF 1 |
#include <stdio.h>
int main()
{
printf("%c\n",'\'');
printf("%s\n", "\"\" ");
return 0;
}
會列印什么呢?

這樣大家知道轉移字符的用法了嗎?下面我們再看一道題提示:strlen()是計算字串長度(不計算‘\0’哦),
#include <stdio.h>
int main()
{
printf("%d\n", strlen("abcdef"));
// \32被決議成一個轉義字符 8進制里是不會有8的哦
printf("%d\n", strlen("c:\test\328\test.c"));
return 0;
}
大家答案是多少呢?6 18 還是6 14呢?

答案是6 18 的小伙伴算錯了哦,大家可以看上面的轉義字符表再來計算哦,
注釋
注釋大家應該一下子就能理解吧,就是用來解釋代碼的意思或者是有些不需要的代碼也可以注釋哦,
注釋用兩種風格:
-
C語言風格的注釋
/*xxxxxxx*/- 缺陷是不能嵌套注釋
-
C++風格的注釋
//xxxxxxxx- 可以注釋一行也可以注釋多行
選擇陳述句
選擇陳述句顧名思義就是用來選擇的陳述句,就好比,我們進入了學校,是好好學習呢?還是不學習呢?好好學習,畢業了就有好作業,不學習,畢業了就回家種田吧,這就是選擇,選擇陳述句也叫分支陳述句,
graph TD A[進入學校] --> C{好好學習?} C --> |好好學習| D[好作業] C --> |不學習| E[回家種田]用代碼的形式表示:
#include <stdio.h>
int main()
{
int option = 0;
printf("你會好好學習嘛?(選擇 1 or 0):")
scanf("%d",&option);
if(1 == option)
{
printf("好好學習,你會有好作業\n");
}
else
{
printf("不學習,回家種田吧\n");
}
return 0;
}
還有其他形式嘛?會有的,在后續的博客里都會有,現在只是初步認識一下C語言,
回圈陳述句
顧名思義就是回圈的做某一件事情,比如我們選擇日復一日的學習,
C語言中如何實作回圈呢?
- while陳述句
- for陳述句
- do...while陳述句
#include <stdio.h>
int main()
{
printf("加入學習\n");
int line = 0;
while(line <=30000)
{
line++;
printf("敲代碼\n");
}
if(line>30000)
{
printf("成為高手\n");
}
return 0;
}
這里是以while回圈來舉個例子,后面的兩個回圈會在后續文章講到,看一下運行的效果如何:
?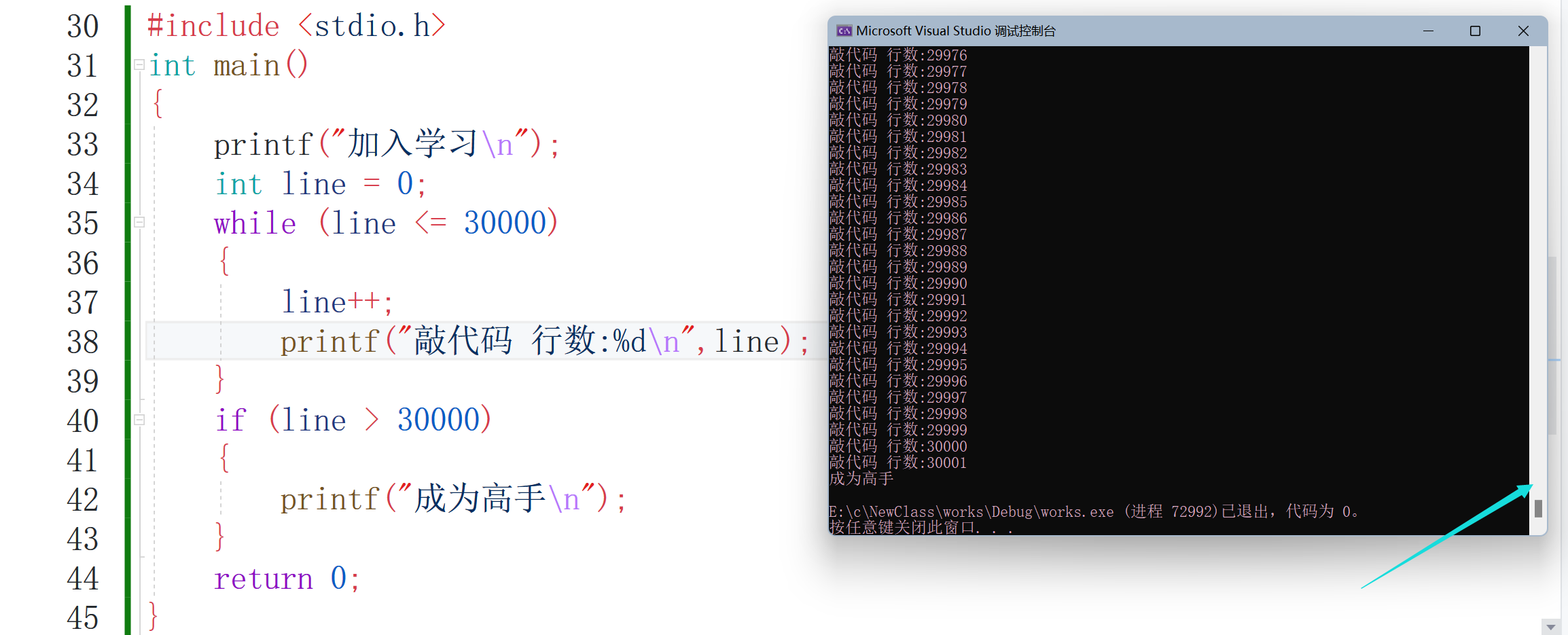
看到箭頭指向的滾動條,上面其實還有很多行資訊,這就是回圈陳述句的效果,重復的做某一件事情,
函式
大家看到函式會想到什么?我們學過數學中的函式,數學中的函式是怎么樣的?f(x)=2*x+5,這就是數學中的函式,C語言中的函式呢?
函式是一段可以重復使用的代碼,用來獨立地完成某個功能,它可以接收用戶傳遞的資料,也可以不接收,接收用戶資料的函式在定義時要指明引數,不接收用戶資料的不需要指明,根據這一點可以將函式分為有參函式和無參函式,
在C語言中函式是這樣定義的:函式的回傳型別 函式名(函式引數型別 函式引數名){函式體,函式要實作的功能},我們把上面那段相加的代碼改造一下:
#include <stdio.h>
int main()
{
int num1 = 0;
int num2 = 0;
int sum = 0;
printf("輸入兩個運算元:>");
scanf("%d %d", &a, &b);
sum = num1 + num2;
printf("sum = %d\n", sum);
return 0;
}
上述代碼,寫成函式如下:
#include <stdio.h>
int Add(int x, int y)
{
int z = x+y;
return z;
}
int main()
{
int num1 = 0;
int num2 = 0;
int sum = 0;
printf("輸入兩個運算元:>");
scanf("%d %d", &num1, &num2);
sum = Add(num1, num2);
printf("sum = %d\n", sum);
return 0;
}
我們看實作的效果:
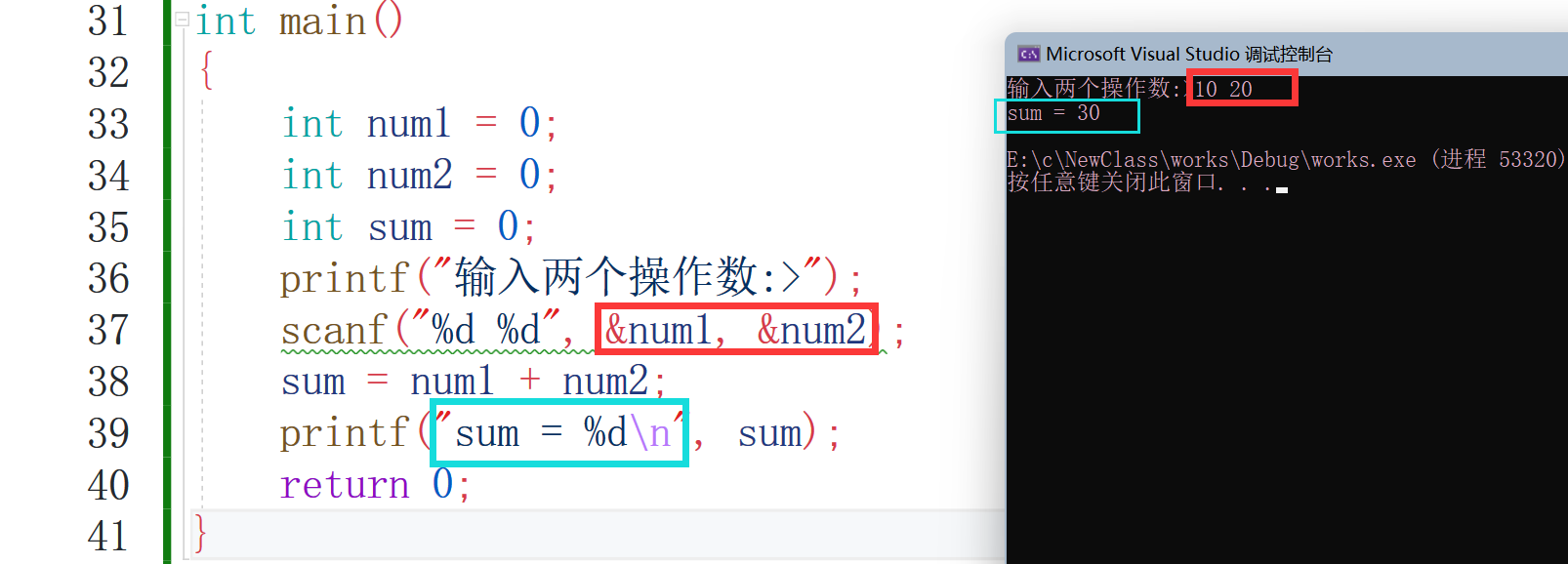
這是第一段代碼的實作效果,下面我們看用函式的形式是怎么樣的:
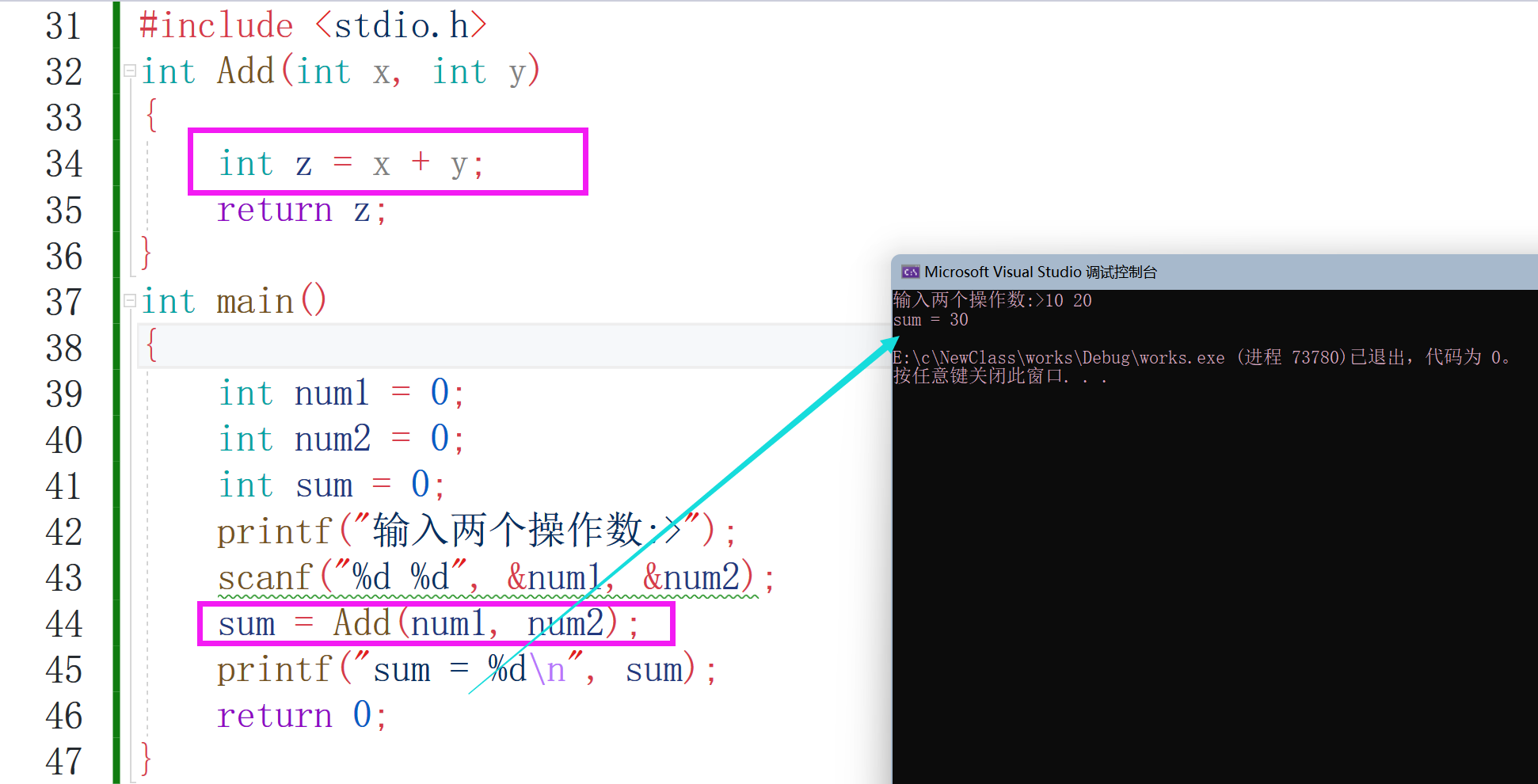
我們發現效果是一樣的,只是說相加的功能是在Add函式內部去實作了,因此我們知道函式的特點:
簡化代碼,提高代碼的復用性,
這只是自定義函式,在C語言中還有許多庫函式可以給我們使用,就是我們用到的printf 、scanf等,
陣列
在介紹陣列之前,問一下大家,我們要定義1~10的數字,是怎樣定義呢?是一個一個的定義嘛?這樣會不會太麻煩了,其實也不是不行,那換作是100個或者是1000個呢?那我們這樣一個變數一個變數的定義實屬麻煩,所以我們要參考——陣列這個概念了,
陣列是一組相同型別元素的集合,就好比我要存整數1~10,
陣列定義
在C語言中是這樣定義的:型別名 陣列名[陣列元素個數]={初始值},
int arr[10]={1,2,3,4,5,6,7,8,9,10}
char arr[5]={'a','b','c'};
可以使用如上代碼定義一個任何型別的陣列,當然除了那幾種基本資料型別哈,定義后我們可以對它進行初始化,也可不進行初始化,或者只初始化一部分就比如我上面創建的字符陣列,不初始化的話,陣列元素的值會被定義成隨機值的,所以一般在我們建立陣列后,我們都將它初始化為0,和定義變數一樣,這是一個好習慣哦,
陣列的使用
陣列都是通過下標來訪問的,上代碼:
#include <stdio.h>
int main()
{
int i = 0;
int arr[10] = {1,2,3,4,5,6,7,8,9,10};//定義陣列并初始化
for(i = 0;i < 10;i++)
{
printf("%d ",arr[i]);//列印陣列內容
}
printf("\n");
return 0;
}
以上代碼意思是定義了一個有十個整型大小的陣列并在定義時進行初始化,然后使用for回圈將陣列元素列印出來,for回圈后面會講,陣列的使用:通過陣列名+下標的方式進行參考,arr[i],其中[]里的數字就是我們的陣列下標,大家可以看到陣列下標是從0開始的,即想要獲取陣列第一個元素可以寫成:arr[0],因此我們知道陣列下標最大的是 陣列元素個數-1,第一個元素下標為0,以此類推,
運算子
指令系統的每一條指令都有一個運算子,它表示該指令應進行什么性質的操作,運算子也就是不同的運算子有對應不同的操作嘛,
運算子的分類
- 算術運算子
- 移位運算子
- 位運算子
- 賦值運算子
- 單目運算子
- 關系運算子
- 邏輯運算子
- 條件運算子
- 逗號運算式
- 下標參考操作、函式呼叫和結構成員
<span id="“1"">算術運算子
| 運算子 | 作用 |
|---|---|
| + | 加 |
| - | 減 |
| * | 乘 |
| / | 除 |
| % | 取余(取模) |
1.加、減、乘和平常數學中運算規則一樣,
2./(除)這個運算子需要注意一點:除的時候如果除號(/)兩邊只要有一個或者兩個浮點數,采用的是浮點型除法,若兩邊都是整型,則采用整數的除法,沒有余數,
3.%這個運算子兩邊只能是整數,它回傳的是整除之后的余數,
算術運算子還算簡單,需要注意的地方我也標出來了,
移位運算子
| 運算子 | 作用 |
|---|---|
| << | 左移運算子,二進制序列左移 |
| >> | 右移運算子,二進制序列右移 |
- 移位運算子作用的物件是一個數的補碼;
- 對于左移:左邊拋棄,右邊補0;
- 對于右移:右邊拋棄,左邊補原來的符號位(采用算術移位);
- 對于’>>’運算子,分為兩種移位規則:一種邏輯移位,另一種是算術移位,
- a.邏輯移位規則是右邊拋棄,左邊最高位直接補0,不考慮之前數的符號位,
- b.算術移位規則是右邊拋棄,左邊最高位補和之前數相同的符號位,而目前編譯器通常采用的是算術移位規則,
- 但這里需要注意,對一個數移位操作完成后,當前的數不會改變的,除非把它賦值給另外一個變數,
- 對于移位運算子,不要移動負數位,這個是標準未定義的,
上面提到了補碼,我要強調一個概念 原碼反碼補碼 (如果沒有基礎的,建議百度下)
并且一個整數4個位元組,由32位組成
其中正數的 原碼反碼補碼 相同
負數的 反碼等于原來相對應的正整數的原碼所有位按位取反.
負數的 補碼等于其反碼最低位 加 1
2>>1
00000000 00000000 00000000 00000010 //這是原碼 00000000 00000000 00000000 00000001 //這是右移1之后2<<1
00000000 00000000 00000000 00000010 00000000 00000000 00000000 00000100 //這是左移之后-1 << 1
10000000 00000000 00000000 00000001//這是-1的原碼 最高位 是符號位 11111111 11111111 11111111 11111110//這是-1的反碼 11111111 11111111 11111111 11111111//這是-1的補碼 11111111 11111111 11111111 11111110//這是-1左移1之后 這是補碼! 11111111 11111111 11111111 11111101//補碼-1 10000000 00000000 00000000 00000010//這是補碼還原之后 值為-2-1 >>1
11111111 11111111 11111111 11111111//這是-1的補碼 11111111 11111111 11111111 11111111//這是-1右移1之后第一個1是加上去的 右邊丟棄左邊補補符號位,
int main()
{
int a=0,b=0,n=2;
a=n<<1;
printf("%d",a);
b=n>>1;
printf("%d",b);
}
觀察輸出的值可以得出結論:左移操作相當于給之前的數乘2,右移操作相當于給之前的數除2;
位運算子
位運算子針對的是二進制位的,
| 運算子 | 作用 |
|---|---|
| & | 按位與 |
| | | 按位或 |
| ^ | 按位異或 |
- 同樣這里位運算子作用的物件也是一個數的補碼,并且它們的運算元必須是整數,
- 對于’&’,兩個數補碼對應位置的值都為1,結果為1,否則為0;對于’|’,兩個數補碼對應位置都是0,結果是0,否則為1;
賦值運算子
賦值運算子很簡單,顧名思義就是賦值用的,賦值運算子其實就是=,但是其他的也叫復合賦值符,
| 運算子 | 作用 |
|---|---|
| = | 給一個變數賦值 |
| += | 相加之后賦值 |
| -= | 相減之后賦值 |
| *= | 相乘之后賦值 |
| /= | 相除之后賦值 |
| &= | 按位與之后賦值 |
| ^= | 按位異或之后賦值 |
| |= | 按位或之后賦值 |
| >>= | 右移之后賦值 |
| <<= | 左移之后賦值 |
用復合運算子可以使代碼更簡潔,
單目運算子
| 運算子 | 作用 |
|---|---|
| ! | 邏輯取反操作 |
| + | 正值 |
| - | 負值 |
| & | 取地址 |
| sizeof | 運算元的型別長度(以位元組為單位) |
| ~ | 對一個數的二進制按位整體取反 |
| -- | 前置、后置-- |
| ++ | 前置、后置++ |
| * | 間接訪問運算子(解參考運算子) |
| (型別) | 強制型別轉換 |
- sizeof運算子計算的是變數(型別)所占空間的大小,是按位元組來計算,重要的是,sizeof (a+b)里面的運算式不參與計算,若a,b都是int行型別,其結果依然是4;
- 當陣列作為引數為函式傳參時,由于陣列要發生降級,其會降級為一個指標,如果此時在一個函式中sizeof計算陣列的大小是不可以的,其計算的是陣列降級為指標的大小(4個位元組),所以,若函式要得到一個陣列的大小,應該在主函式中計算,
- 對于前置++或 - -,先操作,再使用,對于后置++或 - -,先使用,再操作,
關系運算子
關系運算子就是用來判斷兩者之前的關系的,
| 運算子 | 作用 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| != | 不等于 |
| == | 等于 |
這些關系運算子,比較簡單,不多說,但需要注意,不要將等于(==)寫成賦值操作(=),
邏輯運算子
邏輯運算子用來判斷兩者之前邏輯關系的,與和或,想必大家高中有學過,
| 運算子 | 作用 |
|---|---|
| && | 邏輯與 |
| || | 邏輯或 |
不同與按位與和按位或,
條件運算子
| 運算子 | 作用 |
|---|---|
| exp1?exp2:exp3 | exp1為真,結果為exp2,反之exp3 |
注:exp是運算式的意思 比如說 ( x > y ) ? x : y;,
逗號運算式
| 運算子 | 作用 |
|---|---|
| exp1,epx2,....expN | 從左往后依次執行,整個運算式結果是最后一個運算式的結果 |
比如:int a = 3,b = 4;c = ( a > b, a = b * 4, b = a + 2);結果是啥呢?我們來算算:
c = (3 > 4,a=4*4=16,b=16+2 ) 結果是18
下標參考操作、函式呼叫和結構成員
| 運算子 | 作用 |
|---|---|
| [] | 陣列下標運算子,運算元:陣列名+索引 |
| () | 函式呼叫運算子 |
| . | 訪問結構體成員 |
| - > | 訪問結構體成員 |
用例子來解釋吧:
int arr[10]={1,2,3,4,5,6,7,8,9,10};
arr[2] = 3;
Add(a,b) 函式呼叫
.運算子
struct people
{
char name[10];//姓名
int age;//年齡
char sex[5];//性別
};
#include <stdio.h>
int main()
{
struct people x = {"許諾",20,"男"};
// .運算子訪問結構體成員
printf("姓名:%s\n",x.name);
printf("年齡:%d\n",x.age);
printf("性別:%s\n",x.sex);
return 0;
}
- >運算子
struct people
{
char name[10];//姓名
int age;//年齡
char sex[5];//性別
};
#include <stdio.h>
int main()
{
struct people x = {"許諾",20,"男"};
struct people n = &x;
// ->運算子訪問結構體成員
printf("姓名:%s\n",n->name);
printf("年齡:%d\n",n->age);
printf("性別:%s\n",n->sex);
return 0;
}
. ---> 結構體物件.成員名 -> ---> 結構體指標->成員名
常見關鍵字
關鍵字(Keywords)是由C語言規定的具有特定意義的字串,通常也稱為保留字,例如 int、char、long、float、unsigned 等,我們定義的識別符號不能與關鍵字相同,否則會出現錯誤,
你也可以將關鍵字理解為具有特殊含義的識別符號,它們已經被系統使用,我們不能再使用了,
標準C語言規定了32個關鍵字,
| 關鍵字 | 說明 |
|---|---|
| auto | 宣告自動變數 |
| short | 宣告短整型變數或函式 |
| int | 宣告整型變數或函式 |
| long | 宣告長整型變數或函式 |
| float | 宣告浮點型變數或函式 |
| double | 宣告雙精度浮點型變數或函式 |
| char | 宣告字符型變數或函式 |
| struct | 宣告結構體變數或函式 |
| union | 宣告共用資料型別(聯合體or共同體) |
| enum | 宣告列舉型別 |
| typedef | 用給資料型別取別名 |
| const | 宣告只讀變數 |
| unsigned | 宣告無符號型別變數或函式 |
| signed | 宣告有符號型別變數或函式 |
| extern | 宣告變數是在其他檔案正宣告 |
| register | 宣告暫存器變數 |
| static | 宣告靜態變數或函式 |
| volatile | 說明變數在程式執行中可悲隱含地改變 |
| void | 宣告函式無回傳值或無引數,宣告無型別指標 |
| if | 條件陳述句 |
| else | 條件陳述句否定分支(與if連用) |
| switch | 用于分支陳述句 |
| case | 分支陳述句分支 |
| for | 回圈陳述句 |
| do | 回圈陳述句的回圈體 |
| while | 回圈陳述句的回圈條件 |
| goto | 無條件跳轉陳述句 |
| continue | 結束當前回圈,開始下一輪回圈 |
| break | 跳出當前回圈 |
| default | 分支陳述句中“其他”分支 |
| sizeof | 計算資料型別長度 |
| return | 子程式回傳陳述句(可以帶引數,也可以不帶引數)回圈條件 |
這里提一下幾個關鍵字:
typedef
typedef 型別定義,就是給已知的型別重新起個名字,
typedef unsigned int u_int;//給unsigned int 型別重新起了個名字叫 u_int 實際上還是unsigned int
int main()
{
unsigned int num1 = 10;
u_int num2 = 10;
//其實這兩個變數型別是相同的
return 0;
}
static
在C語言中:
static是用來修飾變數和函式的,
- 修飾區域變數-靜態區域變數
- 修飾全域變數-靜態全域變數
- 修飾函式-靜態函式
修飾區域變數
#include <stdio.h>
//1
void test()
{
int a = 0;
a++;
printf("%d ",a);
}
//1 1 1 1 1
int main()
{
int i = 0;
while(i<5)
{
test();
i++;
}
return 0;
}
//2
void test()
{
static int a = 0;//static修飾區域變數
a++;
printf("%d ",a);
}
//1 2 3 4 5
int main()
{
int i = 0;
while(i<5)
{
test();
i++;
}
return 0;
}
對比一下代碼1和代碼2的輸出結果,我們可以得出結論
static修飾區域變數改變了變數的生命周期,讓靜態區域變數出了作用域還存在不會自動銷毀,直到程式結束,生命周期才結束,
修飾全域變數
這里需要兩個源檔案來舉個例子:
//1
//test1.c
int a = 2021;
//test.c
int main()
{
extern int a;
printf("%d\n",a);
return 0;
}
//2
//test1.c
static int a = 2021;
//test.c
int main()
{
extern int a;
printf("%d\n",a);
return 0;
}
代碼1效果:
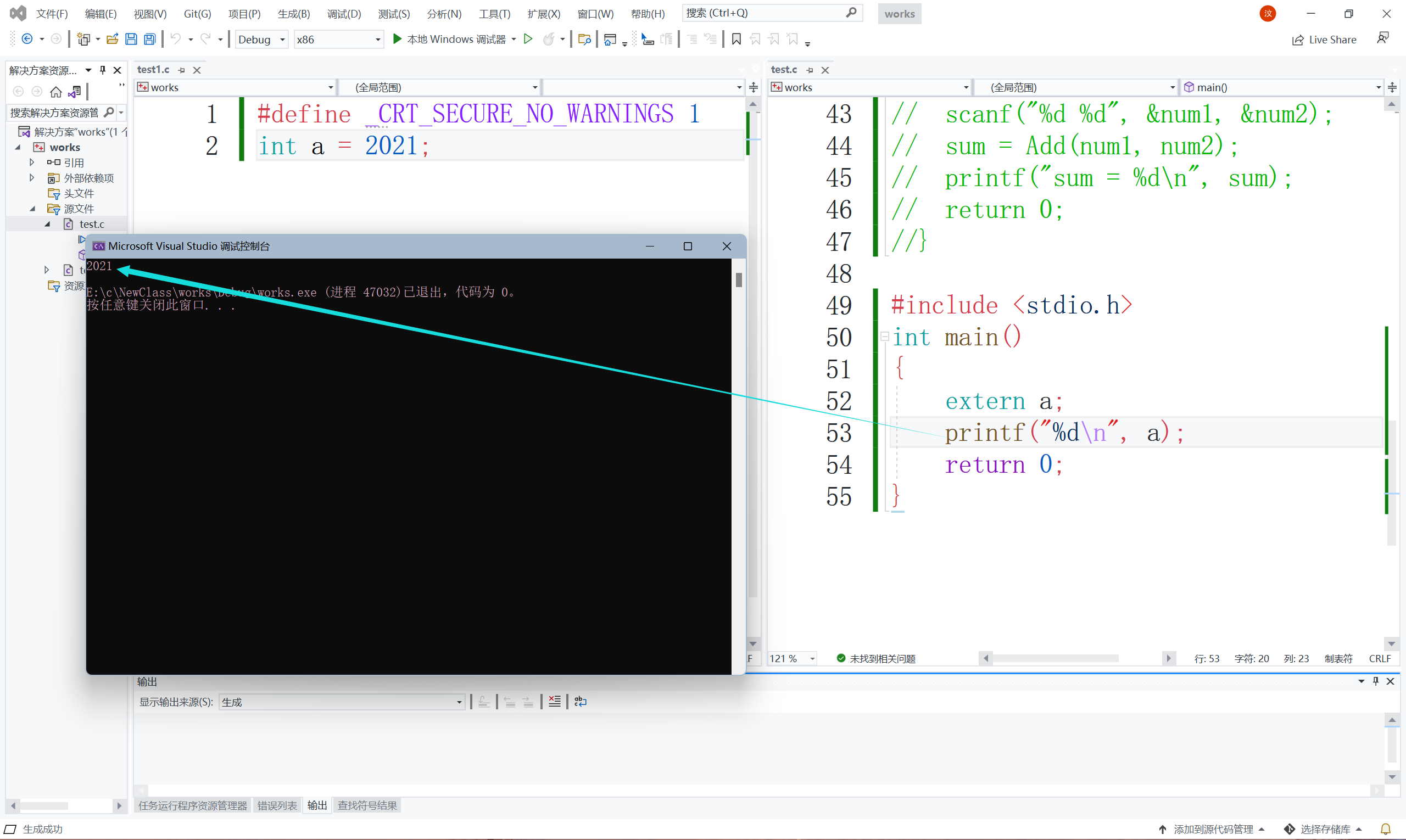
可以看到程式正常運行,那我們看代碼2效果:
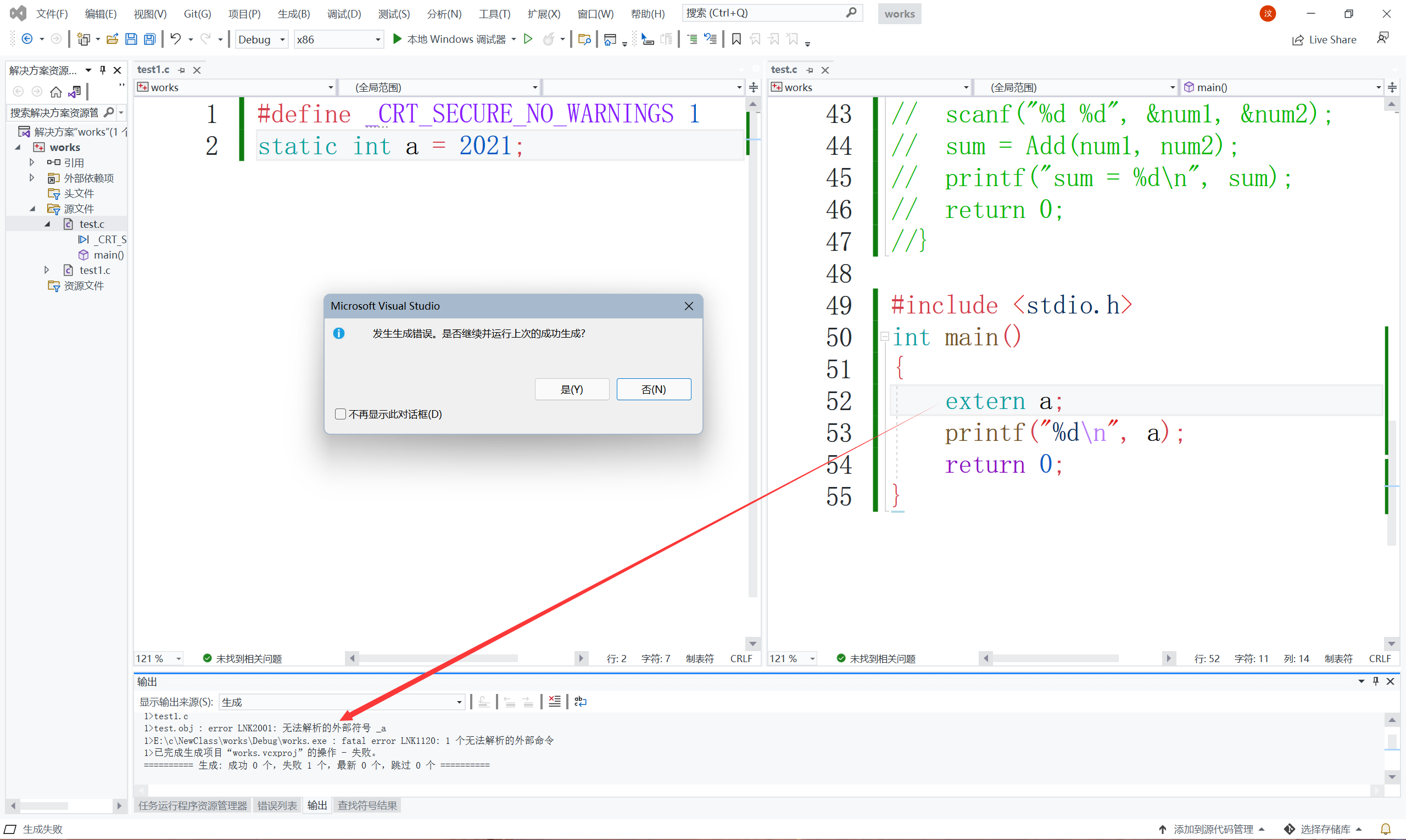
可以看到程式報錯了,為啥呢?全域變數,在其他源檔案內部可以被使用,是因為全域變數具有外部鏈接屬性但是被static修飾之后,就變成了內部鏈接屬性,其他源檔案就不能鏈接到這個靜態的全域變數了,
一個全域變數被static修飾,使得這個全域變數只能在本源檔案中使用,不能在其他源檔案中使用,
修飾函式
這也用兩個源檔案來舉例子:
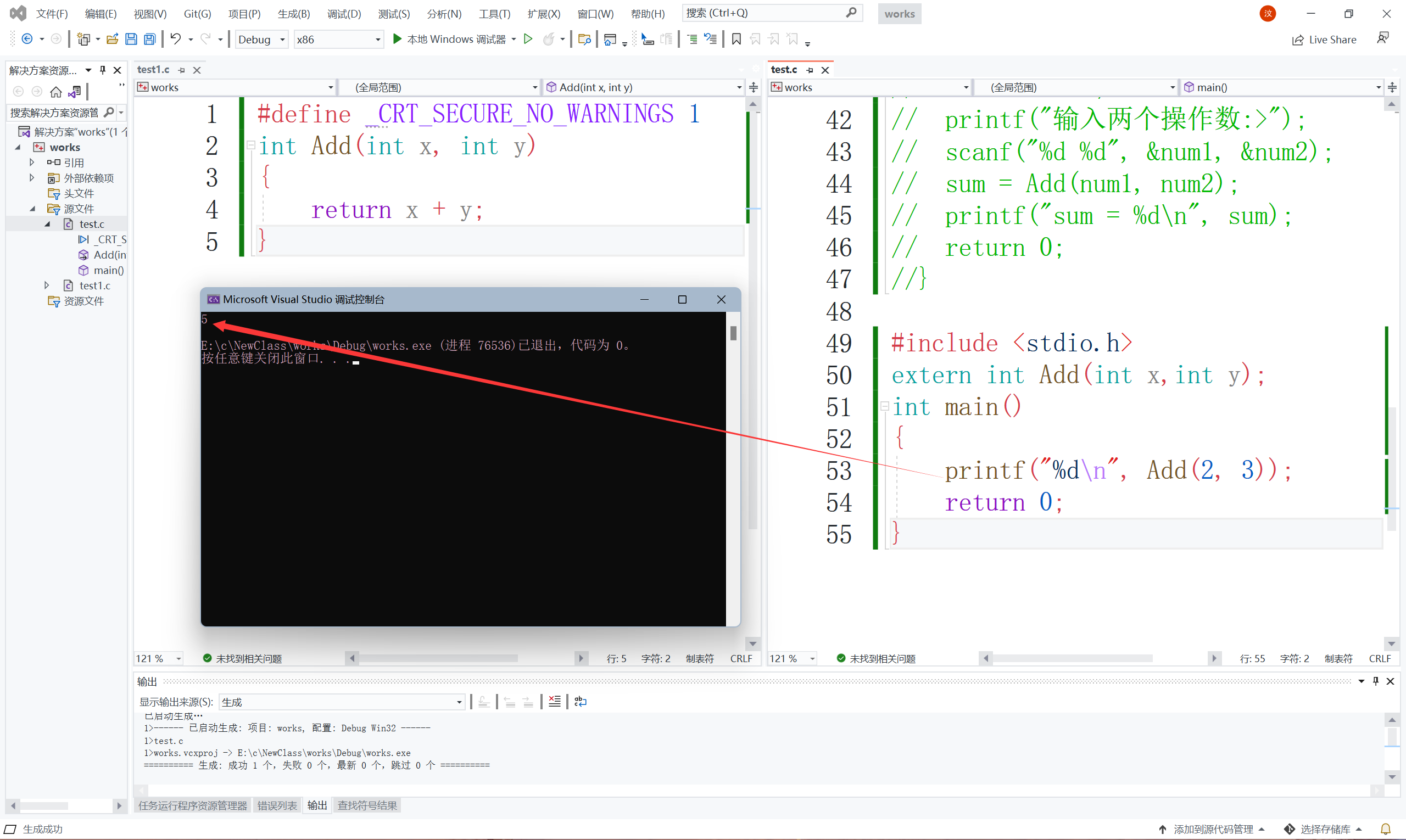
//代碼1
//test1.c
int Add(int x, int y)
{
return x+y;
}
//test.c
int main()
{
printf("%d\n", Add(2, 3));
return 0;
}
//代碼2
//test1.c
static int Add(int x, int y)
{
return x+y;
}
//test.c
int main()
{
printf("%d\n", Add(2, 3));
return 0;
}
我們來看效果:
程式也是正常運行,那加上static修飾一下試試:
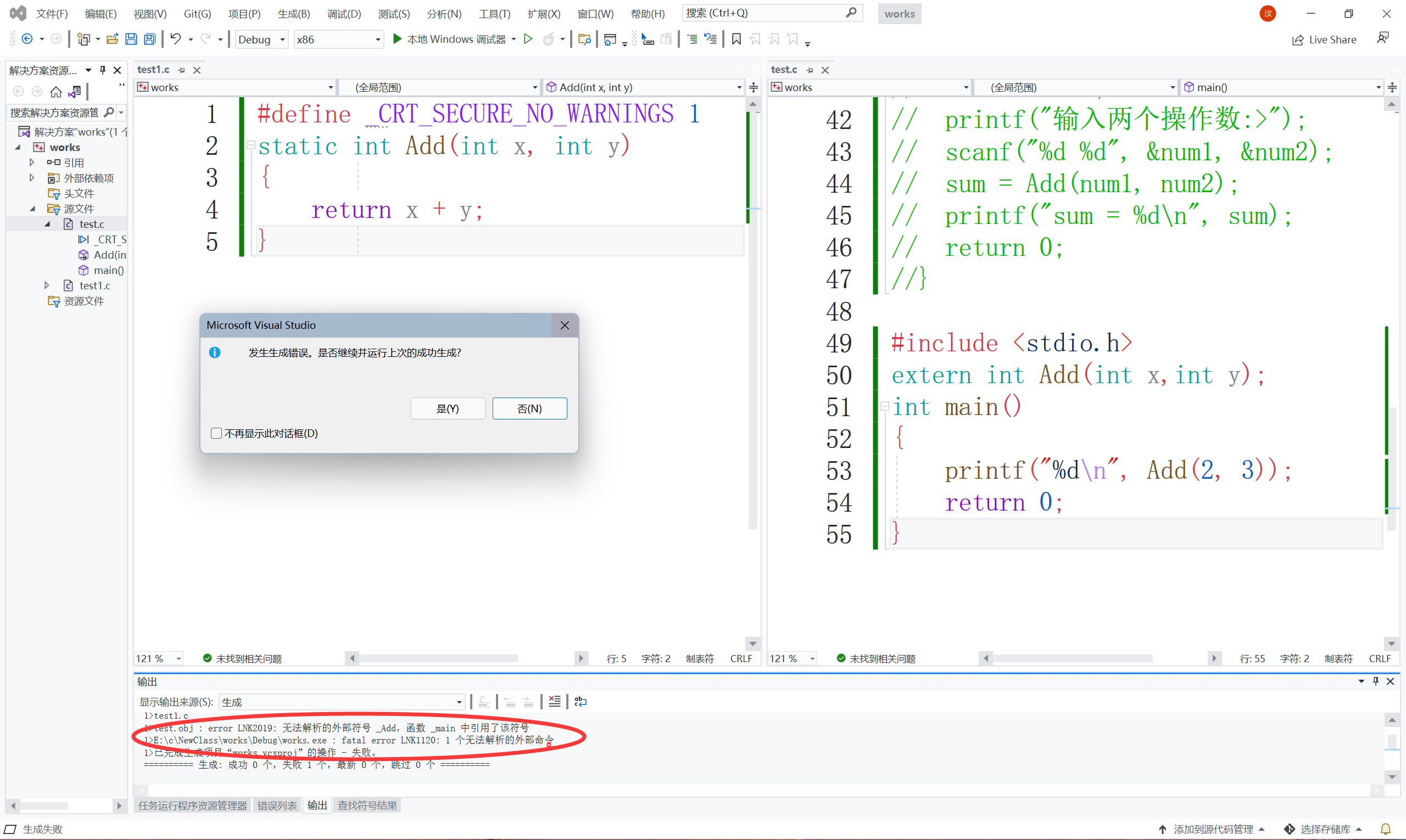
報錯了,跟上面修飾全域變數有點相似,可以得出結論,
一個函式被static修飾,使得這個函式只能在本源檔案內使用,不能在其他源檔案內使用,
本質上: static是將函式的外部鏈接屬性變成了內部鏈接屬性! ( 和static修飾全域變數一樣! )
#define 定義常量和宏
之前常量有提到過#define定義常量,大家應該也有點印象吧, define其實是一個預處理指令,
define的用法:
define 定義符號 常量
#define MAX 1000define 定義宏
#define ADD(X,Y) ((X)+(Y))
我來解釋一下宏是什么,用官方一點的話來說就是:#define 機制包括了一個規定,允許把引數替換到文本中,這種實作通常稱為宏(macro)或定義宏(definemacro),啥意思呢?咱們用代碼來看看:
#include <stdio.h>
#define MAX 100
#define ADD(X,Y) ((X)+(Y))
int main()
{
int sum = ADD(10,20);
printf("sum = %d\n", sum);
sum = 10 * ADD(10,20);
printf("sum = %d\n", sum);
return 0;
}
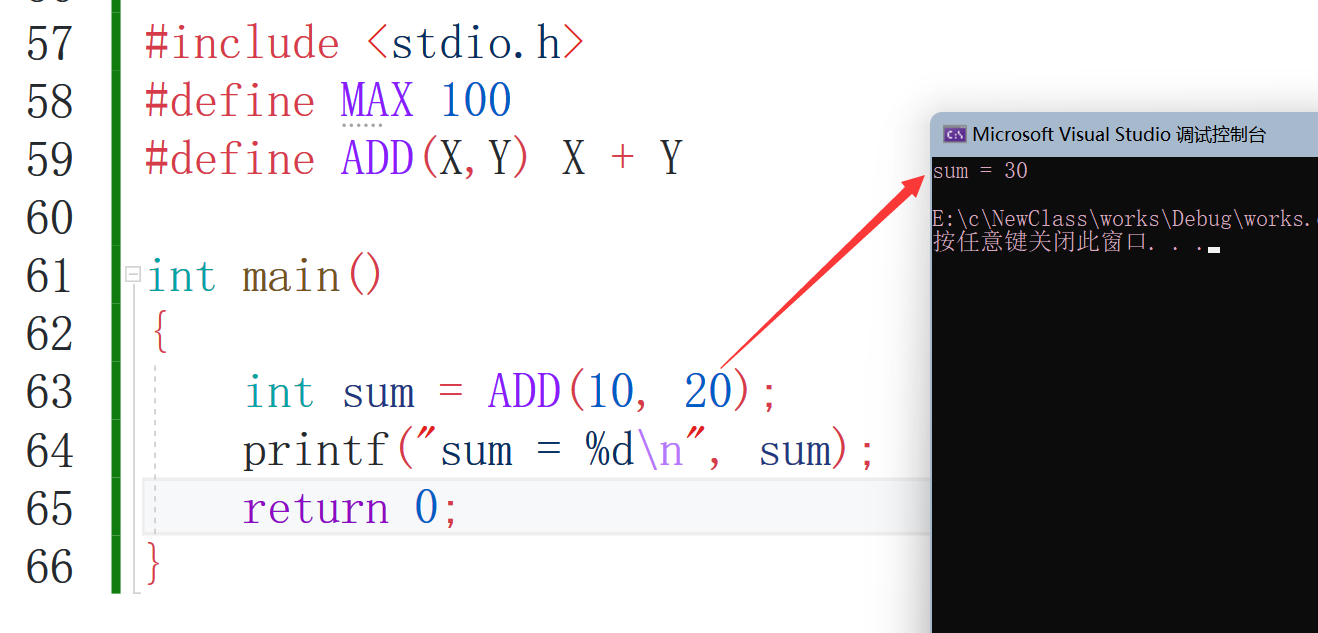
大家看效果,是不是跟函式有點像,但又不是函式,之后深入了解,需要注意的是不要吝嗇括號這個東西哦,這個非常重要,有細心的有伙伴發現我把括號都給去掉了嘛?重這樣會造成問題的,比如說我把ADD()括號內部的值改一下,大家看效果:
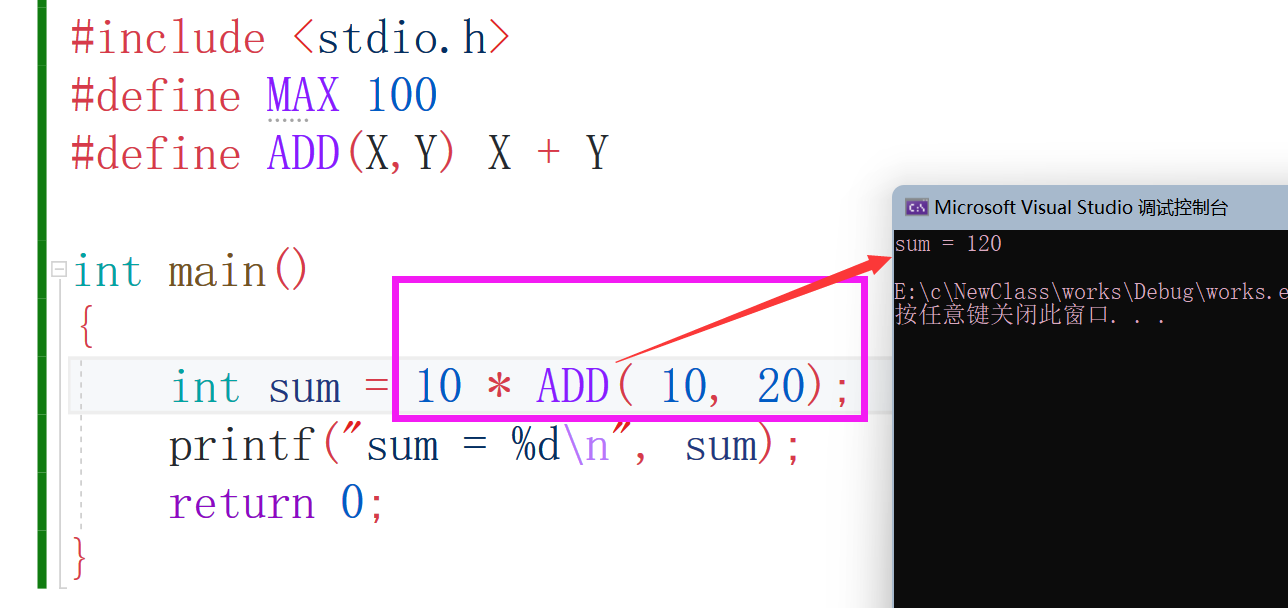
結果是120????這是嘛肥事?不應該是300嗎???還記得之前說的注意點嗎?不要吝嗇括號哦,按照宏的定義來決議:
int sum = 10 * ADD(10,20); int sum = 10 * 10 + 20;//先算乘除加算加減
懂了,在上面加上括號不就好了,嗯對,大家不要吝嗇括號哦,
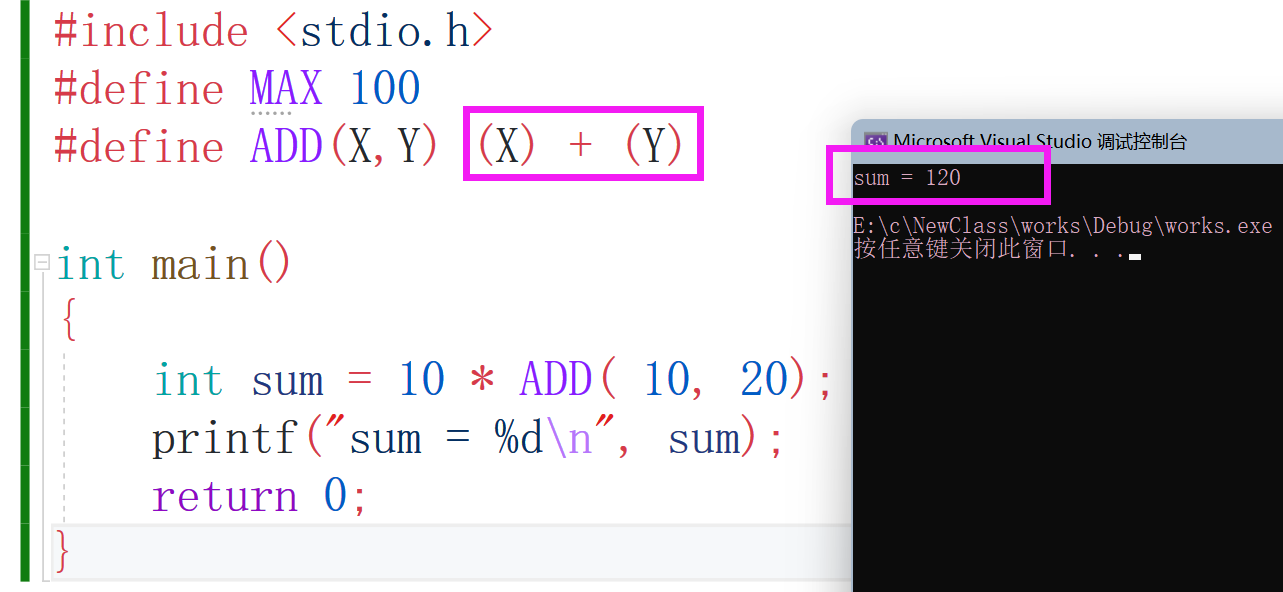
???為啥還是120?我不是加了括號嘛?我們再來決議一下:
int sum = 10 * ADD(10,20); int sum = 10 * (10) + (20);
啊這....那要怎么加括號呢?如果你想得到相加之后再乘以10是不是應該把這個相加的程序給括起來呢?
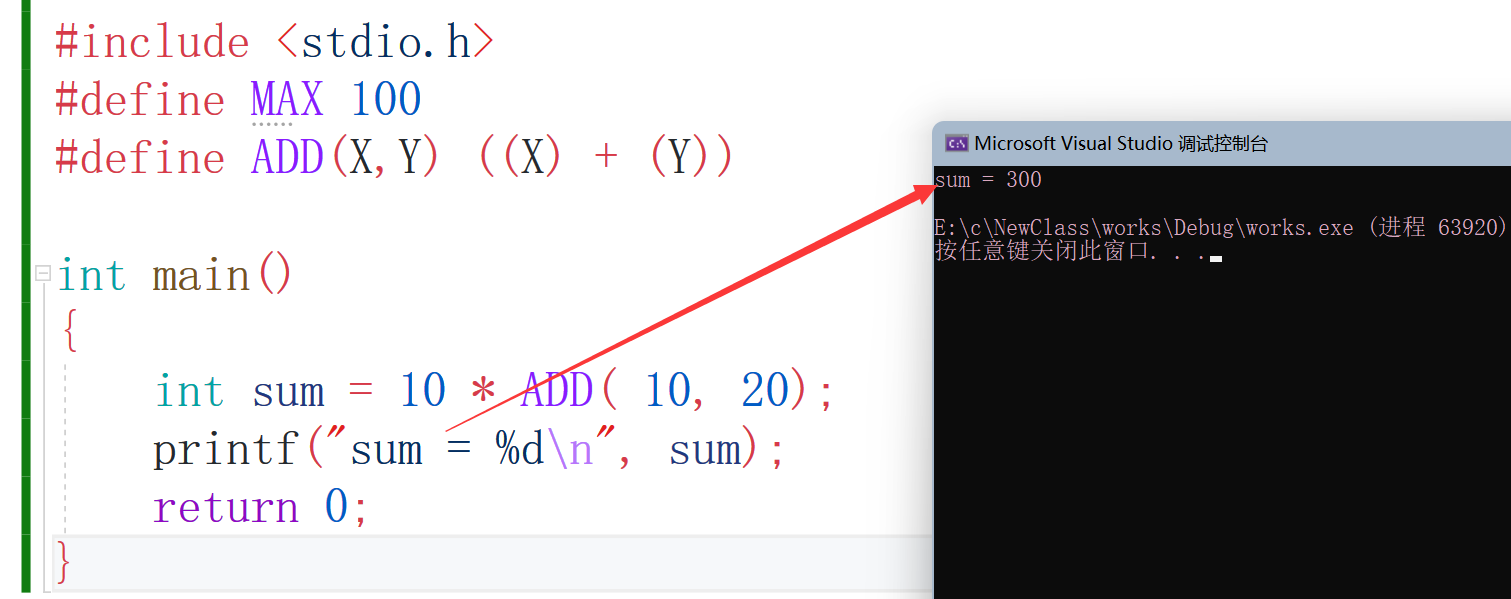
這樣就沒問題了,
指標
指標,沒學之前聽別人說過指標是C語言的靈魂,也是C語言的重點難點,簡單介紹一下指標是什么吧,但是在學指標之前,我們要搞清楚一個東西,那就是記憶體,哈!記憶體,記憶體不就記憶體條嗎?NONONO,如果就只是個記憶體條的話那就不用學這玩意了,其實記憶體是電腦上特別重要的存盤器,計算機中所有程式的運行都是在記憶體中進行的,為了有效的管理記憶體空間,就把記憶體劃分成一個個小的記憶體單元,每個記憶體單元的大小是1個位元組,為了有效的訪問記憶體單元,就給記憶體編號,這些編號就被稱為該記憶體單元的地址,地址我們知道就比如我們住在亞洲中國34個省份的某一個城市某一個城區中,下面我畫個跟記憶體有關的圖,我假設我畫的的是記憶體:

上面我寫了一個位元位作為一個地址太浪費了而且管理起來也不方便,之前介紹過基本型別發現char型別是最小的而且大小只有一個位元組,那么一個位元組作為記憶體單元的大小這樣不就好了嗎?確實C語言規定記憶體單元的大小就是1個位元組,大家多多少少都對記憶體有大概的了解了吧,接著我們說指標,
在計算機科學中,指標( Pointer )是編程語言中的一個物件,利用地址,它的值直接指向( points to )存在電腦存盤器中另一個地方的值,由于通過地址能找到所需的變數單元,可以說,地址指向該變數單元,因此,將地址形象化的稱為“指標",意思是通過它能找到以它為地址的記憶體單元,
變數都會有地址,簡單的來說,指標就是一個變數,而這個變數只是用來存盤地址的,下面以代碼為例子:
int main()
{
int num = 10;
#//取出num的地址
printf("%p\n", &num);//列印地址,%p--以地址的形式列印
return 0;
}
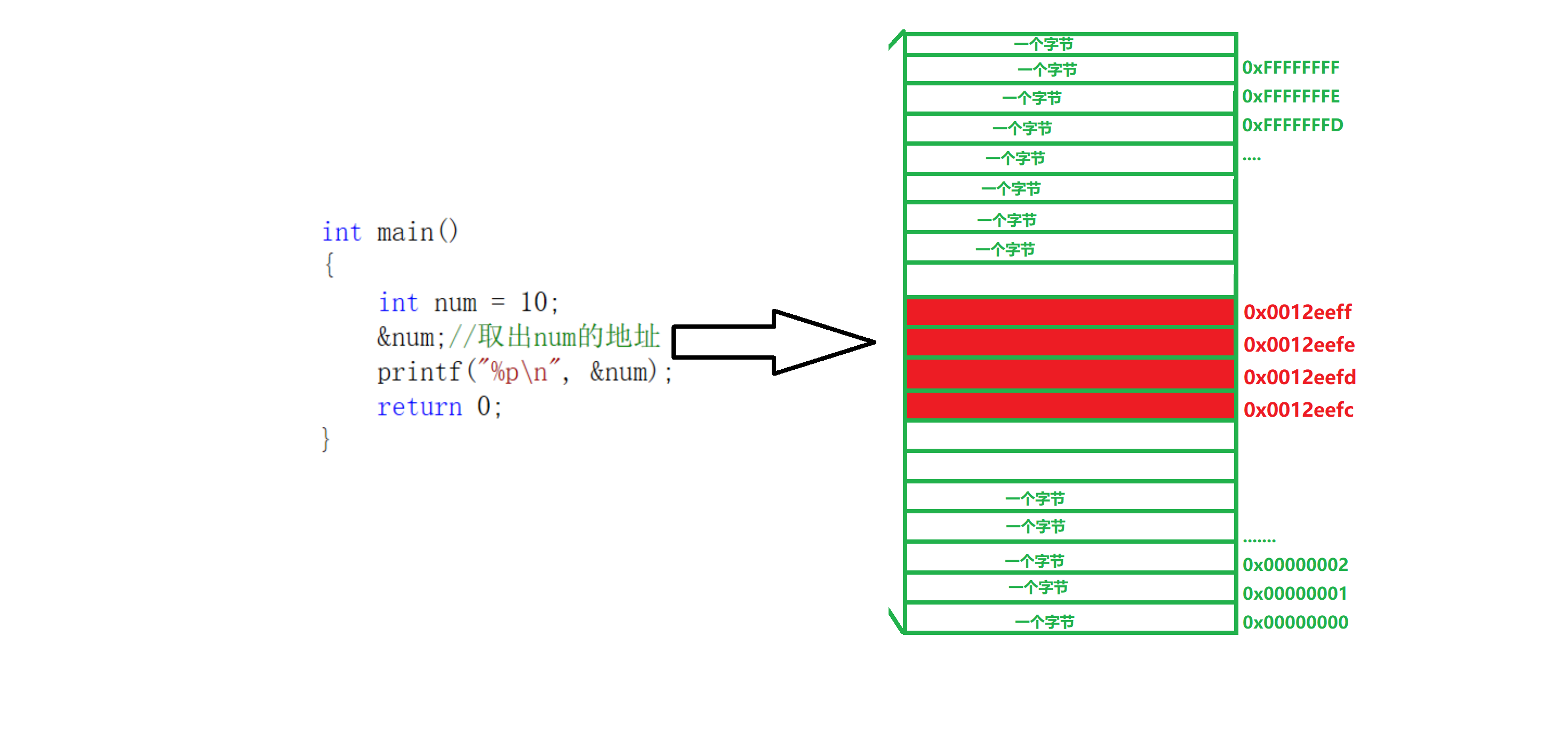
指標就是用來存盤地址的,而且指標也是個變數,那么就可以定義指標變數來存盤地址:
#include <stdio.h>
int main()
{
int num = 10;
int* p = #
printf("%p\n",p);
*p = 20;
printf("%d\n",num);
return 0;
}
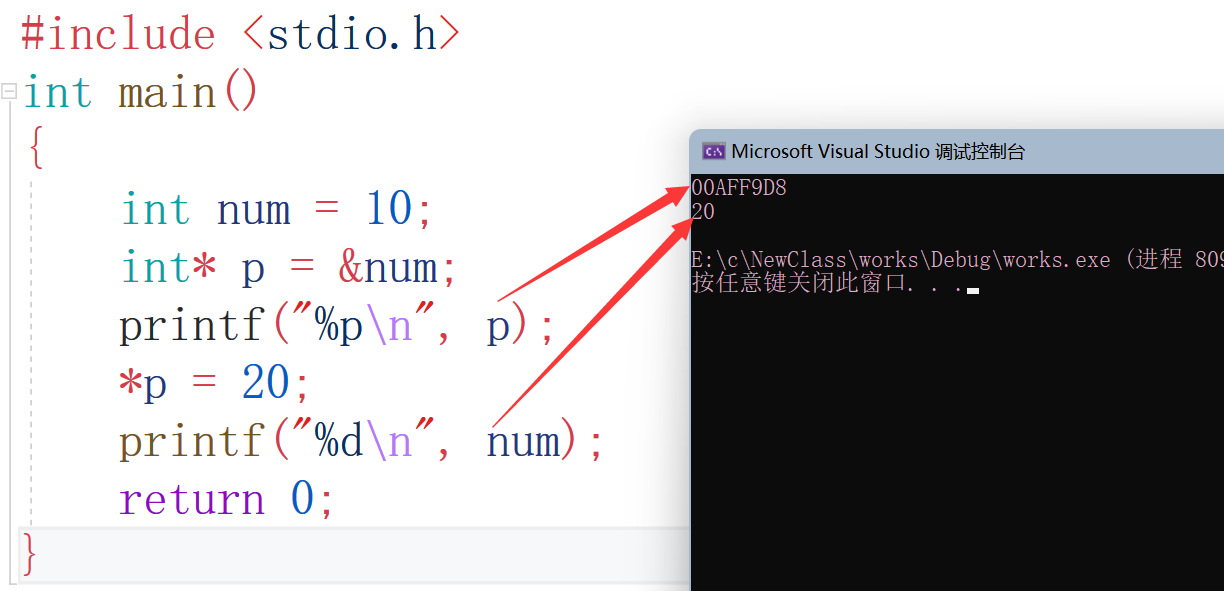
我們看結果,第一個是00AFF9D8,第二個是20,咦我的num怎么被改變了呢?第一個是地址是因為指標變數存的是num的地址,因為p變數指向的是num,也就是p變數通過地址找到了num,*解參考運算子,間接訪問了num,*p找到的就是num,這樣num的值就被改變了,這只是整型指標,我們可以以此類推到其他型別,比如:
#include <stdio.h>
int main()
{
char ch = 'w';
char* p = &ch;
*p = 'q';
printf("%c\n",ch);
return 0;
}
畫個圖大家應該可以更清楚一點:
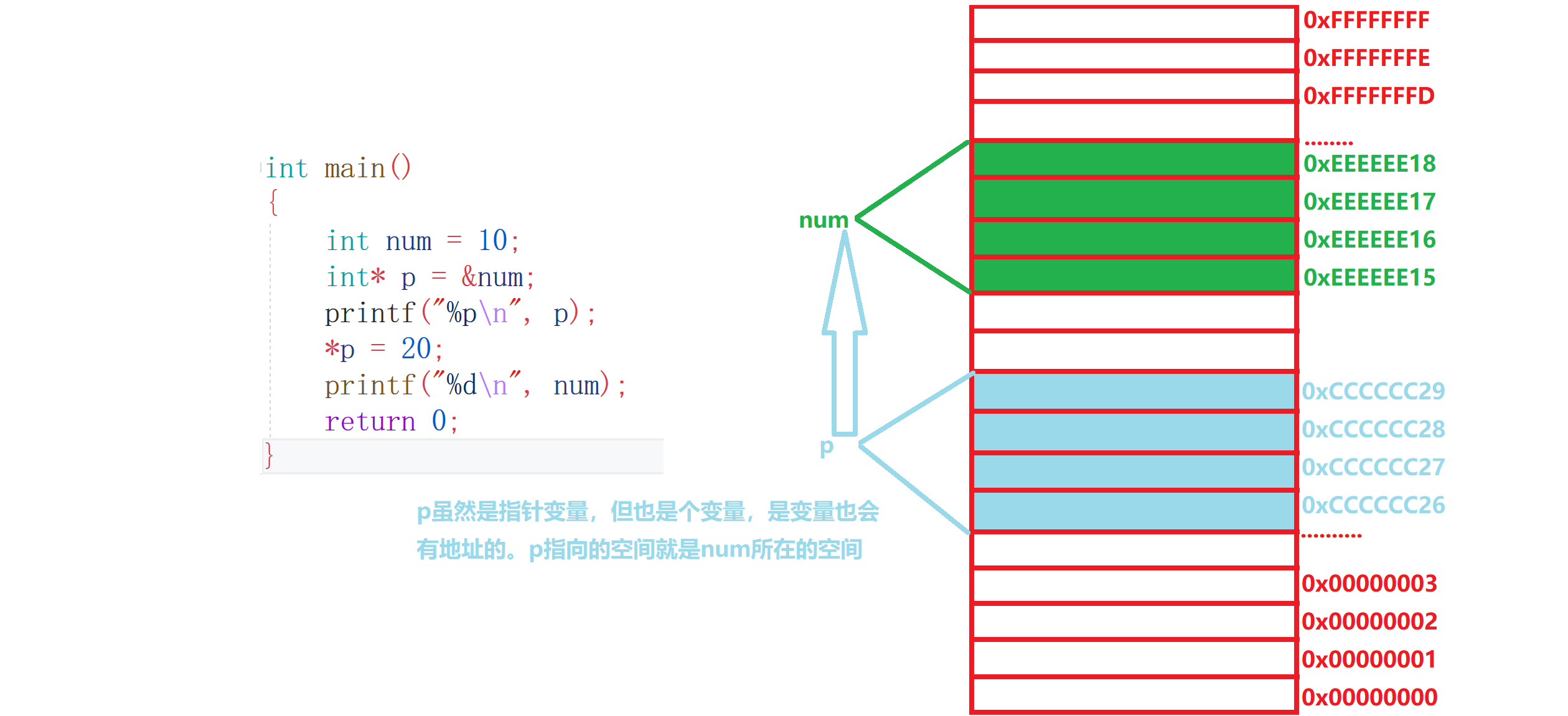
p的值是地址哦,比如int* p = 20;它會被決議成:
int * p = 20 == 0x00000014;//20會被決議成地址 而地址是十六進制的
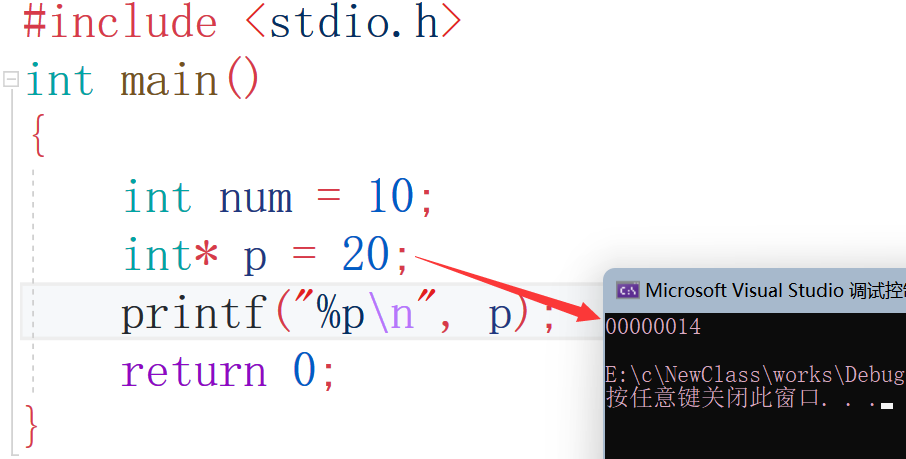
可以看到int* p = 某個值,某個值都會被決議成地址的形式,大家要注意哦!
指標的大小
我們知道了指標是個用來存放地址的變數,那指標變數的大小是多少呢?
#include <stdio.h>
int main()
{
printf("int* = %d\n",sizeof(int*));
printf("char* = %d\n",sizeof(char*));
printf("short* = %d\n",sizeof(short*));
printf("float* = %d\n",sizeof(float*));
printf("boule* = %d\n",sizeof(double*));
return 0
}
我們在不同的平臺上運行一下,32位:
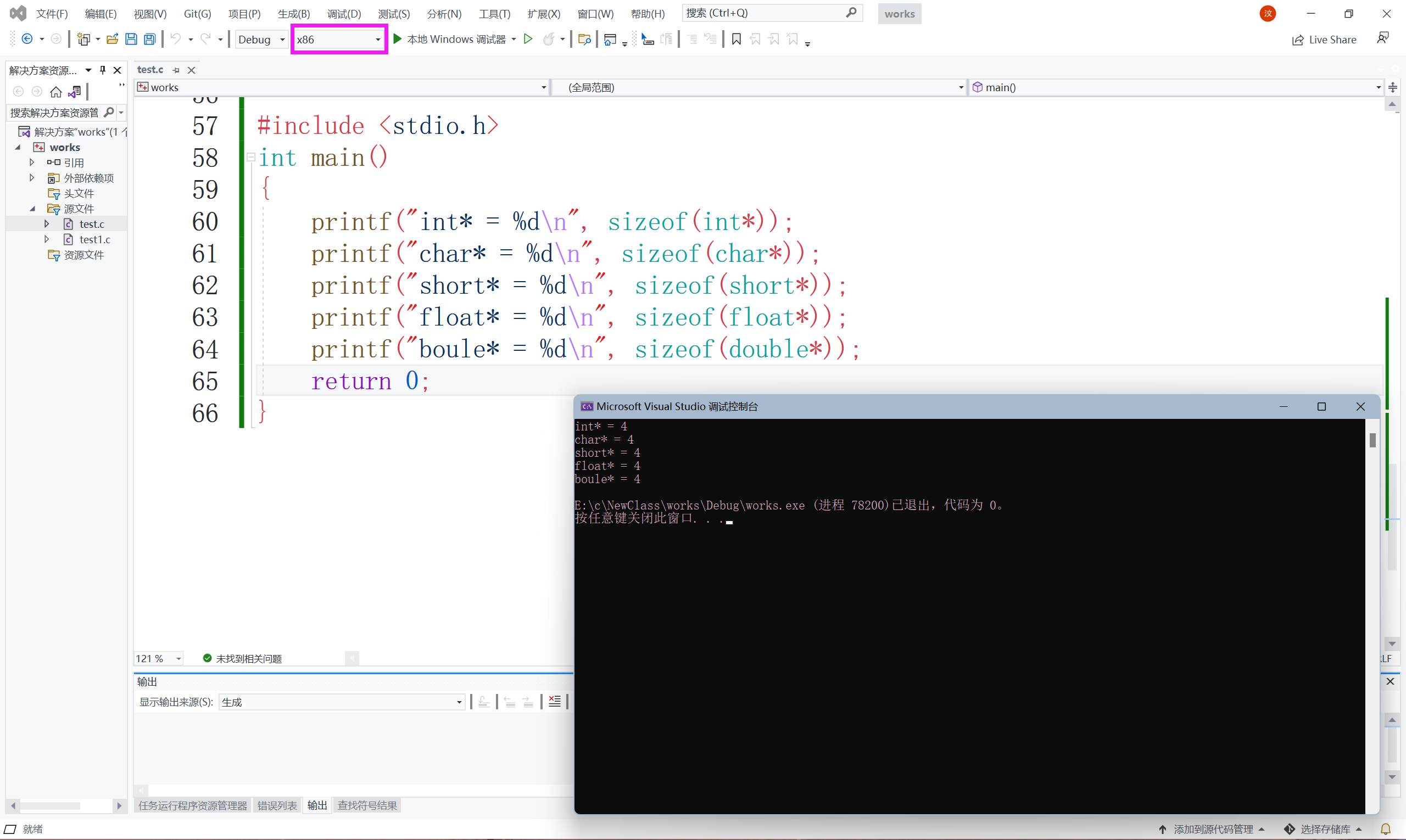
我們發現在32位平臺上,所有型別指標都是4位元組,
64位:
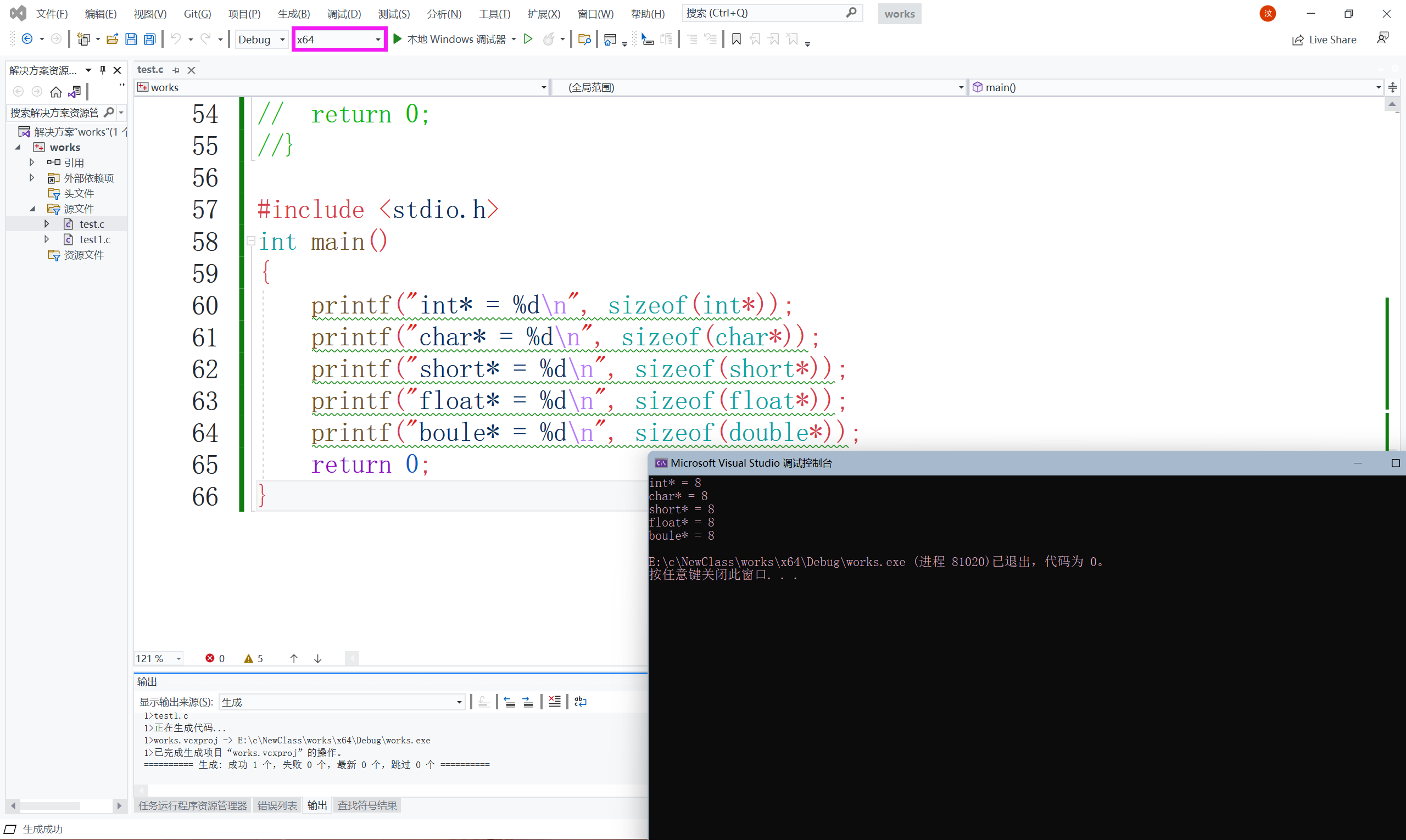
我們看到在64位平臺上都是8個位元組,我們可以得出結論:
指標大小在32位平臺上是4個位元組,64位平臺上是8個位元組,
結構體
我們在介紹一本書的時候會怎樣描述呢?書名+價格+書號+出版社等等,對吧,或者描述一個學生,學生有姓名、年齡、性別、學號等,這些在C語言中又是怎樣描述的呢?這就牽扯到了C語言中的結構體了,結構體可以讓C語言有能力描述這些復雜的型別,那我們用結構體來描述一個學生型別:
struct Student
{
char name[10];//名字
int age; //年齡
char sex[5]; //性別
char id[19]; //學號
};
結構體的定義方式:
struct 結構體名稱
{
型別 結構體成員1;
型別 結構體成員2;
型別 結構體成員3;
.....
};
初始化并定義結構體變數方式位:
struct 結構體名稱 結構體變數名 = {成員1賦值,成員2賦值,.....};
#include <stdio.h>
//定義一個結構體型別 結構體名稱Student
struct Student
{
char name[10];//名字
int age; //年齡
char sex[5]; //性別
char id[19]; //學號
};
int main()
{
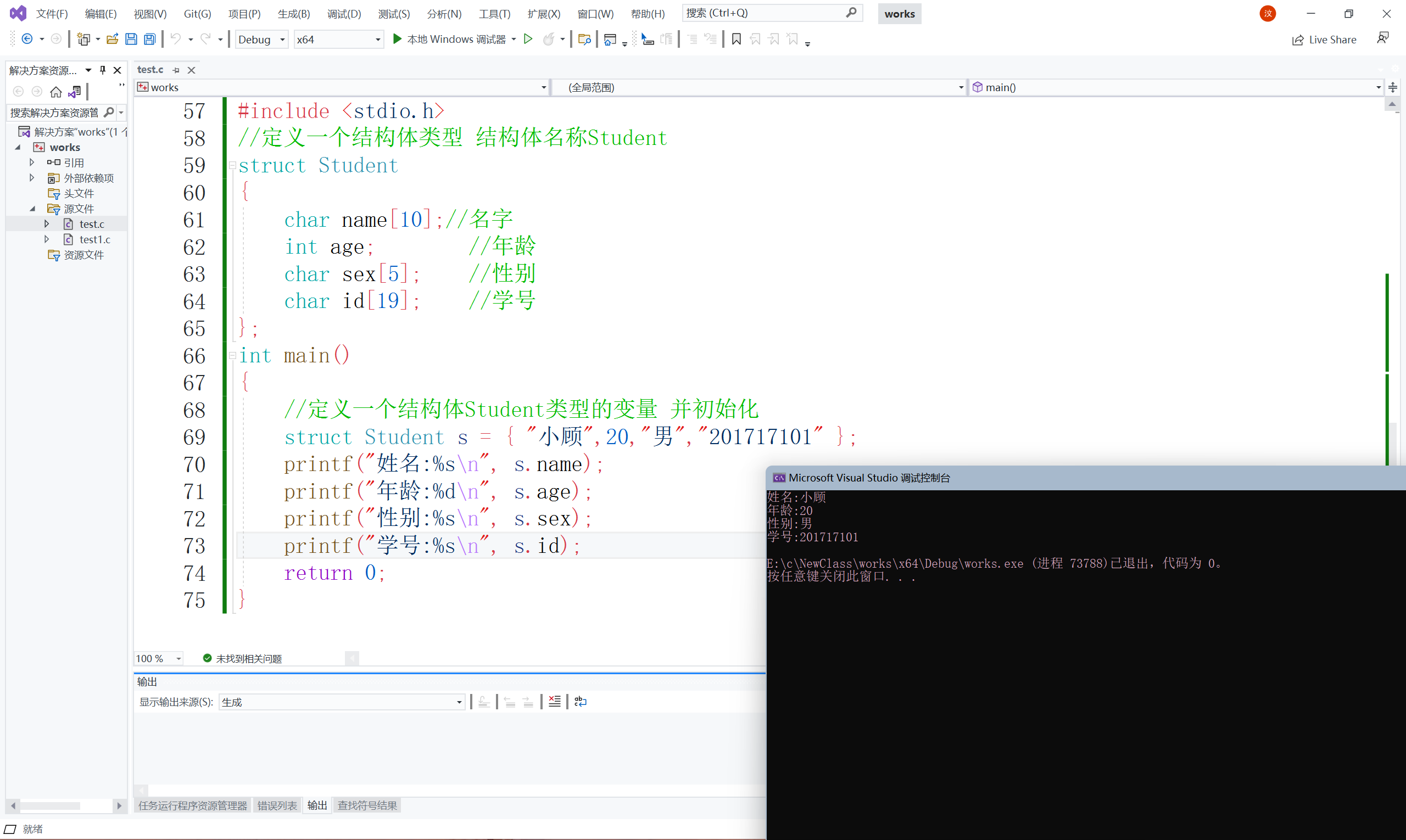
//定義一個結構體Student型別的變數 并初始化
struct Student s = {"小顧",20,"男","201717101"};
printf("姓名:%s\n",s.name);
printf("年齡:%d\n",s.age);
printf("性別:%s\n",s.sex);
printf("學號:%s\n",s.id);
return 0;
}
也可以使用 - >運算子來訪問哦:
#include <stdio.h>
//定義一個結構體型別 結構體名稱Student
struct Student
{
char name[10];//名字
int age; //年齡
char sex[5]; //性別
char id[19]; //學號
};
int main()
{
//定義一個結構體Student型別的變數 并初始化
struct Student s = {"小顧",20,"男","201717101"};
struct Student* p = &s;
printf("姓名:%s\n",s->name);
printf("年齡:%d\n",s->age);
printf("性別:%s\n",s->sex);
printf("學號:%s\n",s->id);
return 0;
}
效果跟上圖是一樣的大家可以試試,
同樣的跟修改變數類似,也可以對結構體變量中的值操作,改變結構體成員的值,
#include <stdio.h>
//定義一個結構體型別 結構體名稱Student
struct Student
{
char name[10];//名字
int age; //年齡
char sex[5]; //性別
char id[19]; //學號
};
int main()
{
//定義一個結構體Student型別的變數 并初始化
struct Student s = {"小顧",20,"男","201717101"};
struct Student* p = &s;
printf("%-20s\t%-20s\t%-20s\t%-20s\n","姓名","年齡","性別","學號");
printf("%-20s\t%-20d\t%-20s\t%-20s\n", s.name, s.age, s.sex, s.id);
printf("%-20s\t%-20d\t%-20s\t%-20s\n", p->name, p->age, p->sex, p->id);
s.name = "小明";
printf("修改后的姓名:%s\n",s.name);
p->age = 19;
printf("修改后的年齡:%d\n", p->age);
return 0;
}
代碼效果圖:
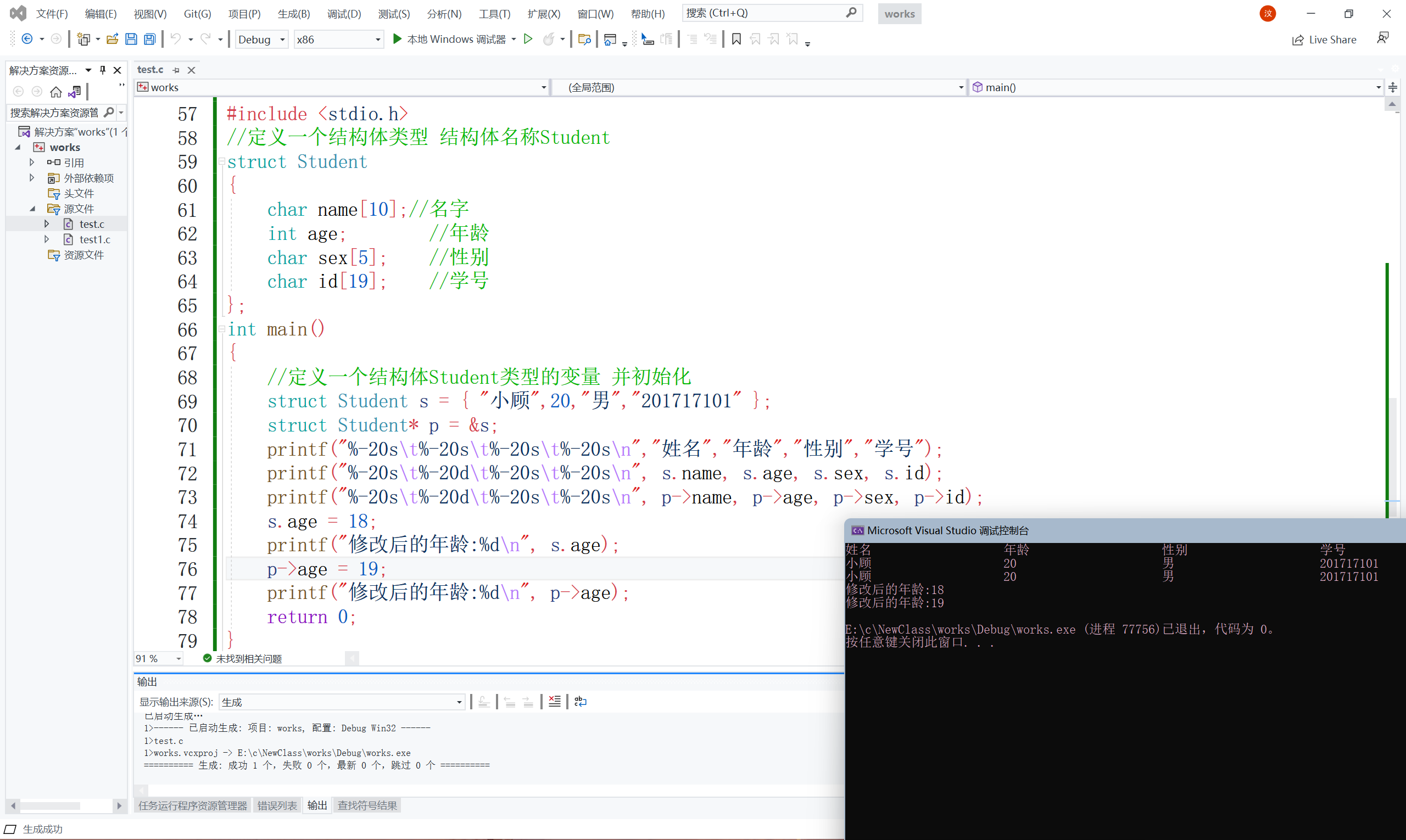
大家可以看到效果正如我們所改動的一樣,但是呢,為啥沒有改變名字呀?因為姓名是字串陣列是不可以直接改變的,得用字串函式來改變,給大家演示一下吧,既然需要字串函式,那就需要引入相對應的頭檔案string.h,字串函式其中的strcpy函式,用來拷貝字串的,
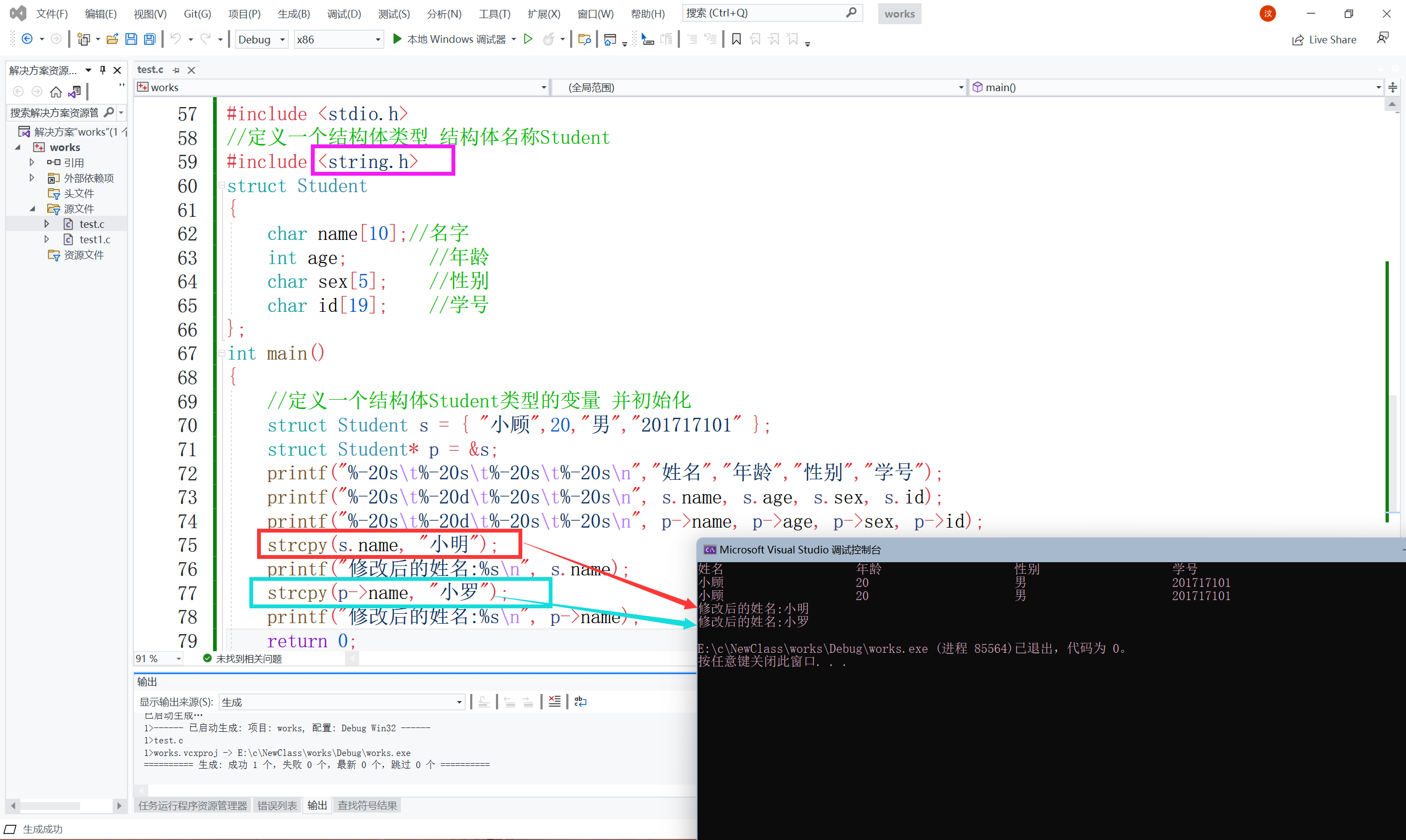
有關于字串操作函式,放到后面再說,
感謝大家的觀看!謝謝大家!!!本人也只是菜鳥一枚,有哪些寫的不好的地方,講的不明白的地方大家都可以指點指點,謝謝大家!本人也沒學的好,所以也難免有些地方沒有寫好,還望大家體諒體諒,謝謝大家!本人寫這篇博客也是為了分享一下自己的理解,有一起學習的小伙伴可以互相支持一下哦!這篇也只是初步的認識一下C語言,認識C語言都有哪些內容,好了謝謝大家的觀看!!!阿里嘎多擴散一碼事!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/379041.html
標籤:C
上一篇:C/C++語言結構體指標的使用