🙏相見即是有緣,如果對你有幫助,給博主一個免費的點贊以示鼓勵把QAQ?
這里是溫文艾爾の原始碼學習之路- 🙏作者水平欠佳,如果發現任何錯誤,歡迎批評指正
- 👋博客主頁 溫文艾爾の學習小屋
- 👋更多文章請關注溫文艾爾主頁
- 👋超詳細ArrayList決議!
- 👋更多文章:
- 👋HashMap底層原始碼決議上(超詳細圖解+面試題)
- 👋HashMap底層原始碼決議下(超詳細圖解)
- 👋HashMap底層紅黑樹原理(超詳細圖解)+手寫紅黑樹代碼

文章目錄
- 👋ArrayList底層原始碼
- 👋1 ArrayList繼承關系
- 👋1.1 Cloneable的底層實作
- 👋1.2 RandomAccess標記介面
- 👋2 ArrayList構造方法原始碼決議
- 👋2.1 ArrayList()構造方法
- 👋2.2 ArrayList(int initialCapacity)構造方法
- 👋2.3 ArrayList(Collection<? extends E> c)構造方法
- 👋3 ArrayList基礎方法
- 👋3.05 ArrayList中的各個變數
- 👋3.1添加方法
- 👋3.1.1 add(E e)
- 👋3.1.2 add(int index, E element)
- 👋3.1.3 addAll(Collection<? extends E> c)
- 👋3.1.4 addAll(int index, Collection<? extends E> c)
- 👋3.1.5 set(int index, E element)
- 👋3.1.6 get(int index)
- 👋3.1.7 remove(Object o)
- 👋3.1.8 clear()
- 👋4 擴展
- 👋4.1 轉換方法toString()
- 👋4.2 迭代器Iterator iterator()
- 👋5 ArrayList相關面試題
- 👋5.1 ArrayList是如何擴容的
- 👋5.2 ArrayList頻繁擴容導致添加性能急劇下降,如何處理?
- 👋5.3 ArrayList插入或洗掉元素一定比LinkedList慢嗎
- 👋5.4 ArrayList是執行緒安全的嗎
- 👋5.5 如何復制某個ArrayList到另一個ArrayList中去
- 👋5.6 已知成員變數集合存盤N多用戶名稱,在多執行緒的環境下,使用迭代器在讀取集合資料的同時如何保證還可以正常寫入資料到集合中
- 👋5.7 ArrayList和LinkedList區別
👋ArrayList底層原始碼
ArrayList的類圖示:
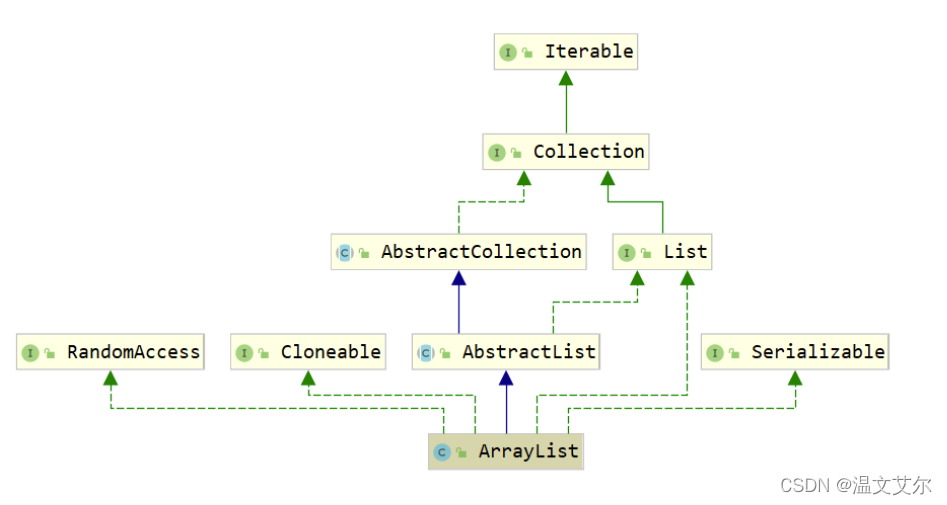
- ArrayList集合介紹
- List底層基于
動態陣列實作
- List底層基于
- 陣列結構介紹
增刪慢:每次洗掉元素都需要更改陣列長度,拷貝以及移動元素位置查詢快:由于陣列在記憶體中是一塊連續空間,因此可以根據地址+索引的方式快速獲取對應位置上的元素
👋1 ArrayList繼承關系
Serializable標記性介面
介紹 類的序列化由實作java.io.Serializable介面的類啟用,不實作此介面的類將不會使任何狀態序列化或反序列化,可序列化類的所有子型別都是可序列化的,序列化介面沒有方法或欄位,僅用于標識可串行化的語意
- 序列化:將物件的資料寫入到檔案(寫物件)
- 反序列化:將檔案中物件的資料讀取出來(讀物件)
Cloneable標記性介面
- 介紹 一個類實作Cloneable介面來指示
Object.clone()方法,該方法對于該類的實體進行欄位的復制是合法的,在不實作Cloneable介面的實體上呼叫物件的克隆方法會導致例外CloneNotSupportedException被拋出,簡言之:克隆就是依據已有的資料,創造一份新的完全一樣的資料拷貝 - 克隆的前提條件
- 被克隆物件所在的類必須
實作Cloneable介面 - 必須重寫
clone()方法
- 被克隆物件所在的類必須
Serializable介面
- 由List實作使用,以表明它們支持
快速(通常為恒定時間)隨機訪問 - 此介面的主要目的是允許演算法更改其行為,以便在應用于隨機訪問串列或順序訪問串列時提供良好的性能

👋1.1 Cloneable的底層實作
/**
* Returns a shallow copy of this <tt>ArrayList</tt> instance. (The
* elements themselves are not copied.)
*
* @return a clone of this <tt>ArrayList</tt> instance
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
可以看到通過呼叫clone()方法,回傳了一個ArrayList物件
v.elementData = Arrays.copyOf(elementData, size);
是我們能完成復制的關鍵,點進去
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType)
{
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
我們原來陣列中的資料通過System.arraycopy方法被拷貝到copy陣列中,并將這個陣列回傳
克隆牽扯到淺拷貝和深拷貝,這里簡述一下淺拷貝和深拷貝的區別
首先創建一個Student類
public class Student implements Cloneable {
private String name;
private Integer age;
public Student() {
}
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
淺拷貝實體
package ArrayListProject.CloneTest;
import java.util.ArrayList;
import java.util.List;
/**
* Description
* User:
* Date:
* Time:
*/
public class Test {
public static void main(String[] args) {
ArrayList list = new ArrayList();
Student stu = new Student("zs",18);
list.add("123");
list.add(stu);
System.out.println("未拷貝之前的陣列:"+list);
ArrayList clone = (ArrayList)list.clone();
System.out.println("拷貝之后的陣列:"+clone);
System.out.println("兩個陣列地址是否相等:"+(list==clone));
System.out.println("兩個陣列中的stu物件是否相等:");
System.out.println("list中的stu物件:"+list.get(1));
System.out.println("修改stu物件之前,clone中的stu物件:"+clone.get(1));
Student stu1 = (Student)list.get(1);
stu1.setName("ls");
System.out.println("修改stu物件之后,clone中的stu物件:"+clone.get(1));
System.out.println("兩者stu物件的地址是否相同"+(list.get(1)==clone.get(1)));
}
}
未拷貝之前的陣列:[123, Student{name='zs', age=18}]
拷貝之后的陣列:[123, Student{name='zs', age=18}]
兩個陣列地址是否相等:false
兩個陣列中的stu物件是否相等:
list中的stu物件:Student{name='zs', age=18}
修改stu物件之前,clone中的stu物件:Student{name='zs', age=18}
修改stu物件之后,clone中的stu物件:Student{name='ls', age=18}
兩者stu物件的地址是否相同true
由此我們得出
- 克隆之后的物件是一個新物件,
list==clone為false可知二者地址不相同 - 由list.get(1)==clone.get(1)為true可知,兩者中的
stu物件為同一物件 - 修改list中的stu物件,clone中的stu物件也會隨之改變可知,克隆的是stu
物件的地址,并沒有創建新的物件,它僅僅是拷貝了一份參考地址 - 基本資料型別可以達到
完全復制,而參考資料型別則不可以
深拷貝和淺拷貝不同,深拷貝中拷貝的物件是一個完全新的物件,他拷貝的并不是參考地址,而是實實在在的創建了一個物件

👋1.2 RandomAccess標記介面
- 由List實作使用,以表明它們支持快速(通常為恒定時間)隨機訪問
- 此介面的主要目的是允許演算法更改其行為,以便在應用于隨機訪問串列或順序訪問串列時提供良好的性能
因此List實作RandomAccess在執行隨機訪問時,性能會比順序訪問更快
public interface RandomAccess {
}
我們通過一個案例來證明
我們以1000000個資料作為測驗
package ArrayListProject.CloneTest;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test02 {
public static void main(String[] args) {
//創建ArrayList集合
List<String> list = new ArrayList<>();
//添加100W條資料
for (int i = 0; i < 1000000; i++) {
list.add(i+"a");
}
//測驗隨機訪問時間
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
//取出集合的每一個元素
list.get(i);
}
long endTime = System.currentTimeMillis();
System.out.println("隨機訪問耗時:"+(endTime-startTime));
//測驗順序訪問時間
long startTime2 = System.currentTimeMillis();
Iterator<String> it = list.iterator();
while (it.hasNext()){
it.next();
}
long endTime2 = System.currentTimeMillis();
System.out.println("順序訪問耗時:"+(endTime2-startTime2));
}
}
隨機訪問耗時:3
順序訪問耗時:4
由此可見,在資料量極大的情況下,ArrayList隨機訪問的效率遠高于順序訪問
而LinkedList的資料結構是鏈表,且未實作RandomAccess介面,他的效率和ArrayList相比如何呢,我們來做一個
測驗
package ArrayListProject.CloneTest;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class Test03 {
public static void main(String[] args) {
List<String> list1 = new LinkedList<>();
for (int i = 0; i < 100000; i++) {
list1.add(i+"a");
}
//測驗隨機訪問時間
long startTime = System.currentTimeMillis();
for (int i = 0; i < list1.size(); i++) {
//取出集合的每一個元素
list1.get(i);
}
long endTime = System.currentTimeMillis();
System.out.println("隨機訪問耗時:"+(endTime-startTime));
//測驗順序訪問時間
long startTime2 = System.currentTimeMillis();
Iterator<String> it = list1.iterator();
while (it.hasNext()){
it.next();
}
long endTime2 = System.currentTimeMillis();
System.out.println("順序訪問耗時:"+(endTime2-startTime2));
}
}
隨機訪問耗時:11676
順序訪問耗時:4
由此可見,沒有實作RandomAccess介面的LinkedList集合的隨機訪問速度遠遠小于順序訪問

👋2 ArrayList構造方法原始碼決議
| Constructor | Constructor描述 |
|---|---|
| ArrayList() | 構造一個初始容量為10的空串列 |
| ArrayList(int initialCapacity) | 構造具有指定初始容量的空串列 |
| ArrayList(Collection<? extends E> c) | 構造一個包含指定集合的元素的串列,按照它們由集合的迭代器回傳的順序 |
👋2.1 ArrayList()構造方法
/**
* Constructs an empty list with an initial capacity of ten.
*/
//構造一個初始容量為10的陣列
//DEFAULTCAPACITY_EMPTY_ELEMENTDATA:默認的空容量的陣列
//elementData:集合真正存盤資料的容器
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
👋2.2 ArrayList(int initialCapacity)構造方法
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//如果傳進來的變數大于0,則初始化一個指定容量的空陣列
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//傳進來的變數=0,則不去創建新的陣列,直接將已創建的EMPTY_ELEMENTDATA空陣列傳給
//ArrayList
this.elementData = EMPTY_ELEMENTDATA;
} else {
//傳進來的指定陣列容量不能<0
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
👋2.3 ArrayList(Collection<? extends E> c)構造方法
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
//將構造方法中的引數轉換成陣列形式,其底層是呼叫了System.arraycopy()
elementData = c.toArray();
//將陣列的長度賦值給size
if ((size = elementData.length) != 0) {
//檢查elementData是不是Object[]型別,不是的話將其轉換成Object[].class型別
if (elementData.getClass() != Object[].class)
//陣列的創建與拷貝
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
//size為0,則把已創建好的空陣列直接給它
this.elementData = EMPTY_ELEMENTDATA;
}
}

👋3 ArrayList基礎方法
👋3.05 ArrayList中的各個變數
//長度為0的空陣列
private static final Object[] EMPTY_ELEMENTDATA = {};
//默認容量為0的空陣列
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//集合存元素的陣列
transient Object[] elementData;
//集合的長度
private int size;
//集合默認容量
private static final int DEFAULT_CAPACITY = 10;
👋3.1添加方法
| 方法名 | 描述 |
|---|---|
| add(E e) | 將指定的元素追加到此串列的末尾 |
| add(int index, E element) | 在此串列中的指定位置插入指定的元素 |
| addAll(Collection<? extends E> c) | 按指定集合的Iterator回傳的順序將指定集合中的所有元素追加到此串列的末尾 |
| addAll(int index, Collection<? extends E> c) | 將指定集合中的所有元素插入到此串列中,從指定的位置開始 |
👋3.1.1 add(E e)
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
//將指定的元素追加到此串列的末尾
public boolean add(E e) {
//每增加1個元素,陣列所需容量+1,并檢查增加陣列容量后是否要擴容
ensureCapacityInternal(size + 1); // Increments modCount!!
//添加元素
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
//如果是默認的DEFAULTCAPACITY_EMPTY_ELEMENTDATA陣列
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//將兩者之中的最大值最為新的容量
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//檢查是否需要擴容
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
//記錄操作次數
modCount++;
/*
elementData.length:原集合中實際的元素數量
minCapacity:集合的最小容量
*/
if (minCapacity - elementData.length > 0)
//擴容的核心方法
grow(minCapacity);
}
private void grow(int minCapacity) {
//獲取為添加元素之前的集合元素數量,設定為oldCapacity
int oldCapacity = elementData.length;
//右移位運算子:oldCapacity>>1=oldCapacity/2
//新容量為原有容量的1.5倍
//擴容的核心代碼
int newCapacity = oldCapacity + (oldCapacity >> 1);
//第一次add時newCapacity為0,故newCapacity - minCapacity會小于0
//如果新容量比所需要的容量還小
if (newCapacity - minCapacity < 0)
//新容量就等于所需要的容量
newCapacity = minCapacity;
//如果新容量比規定的最大容量還大,最新容量等于最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//將原陣列拷貝到一個更大容量的陣列中
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
我們總結一下流程:
- 每增加一個元素,都要判斷增加后容量是否達到了規定的
最大容量值,如果達到就觸發擴容操作grow - 在擴容操作中,設定
新容量為老容量的1.5倍(int newCapacity = oldCapacity + (oldCapacity >> 1)),如果新容量小于所需容量,則新容量等于所需容量(newCapacity = minCapacity),如果新容量比規定的最大值還要大,則新容量等于最大容量newCapacity = hugeCapacity(minCapacity); - 將原陣列拷貝進長度為新容量的新陣列中
👋3.1.2 add(int index, E element)
在指定索引處添加元素
public void add(int index, E element) {
//判斷所傳入的索引是否符合規則(既不能<0,也不能大于原陣列容量)
rangeCheckForAdd(index);
//陣列所需容量+1,并判斷增加元素之后是否需要擴容
ensureCapacityInternal(size + 1);
//陣列元素拷貝,index之后的元素向后移一位,把index的位置空了出來
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//在index位置上填充要插入的元素
elementData[index] = element;
//元素個數+1
size++;
}
//判斷index是否符合規則
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
我們總結一下流程:
- 檢查傳入index是否符合規則
- 判斷陣列是否需要進行擴容
- 創建新陣列,并將原陣列元素進行拷貝,拷貝原理是使index之后的元素向后移動一位,將index位置空出,再在該位置填充元素
- 元素個數+1
👋3.1.3 addAll(Collection<? extends E> c)
按指定集合的Iterator回傳的順序將指定集合中的所有元素追加到此串列的末尾
public boolean addAll(Collection<? extends E> c) {
//將有資料的集合c轉換成陣列形式
Object[] a = c.toArray();
//將資料集合長度賦值給numNew
int numNew = a.length;
//判斷增加元素后是否需要擴容
ensureCapacityInternal(size + numNew);
//將a拷貝進elementData最后
System.arraycopy(a, 0, elementData, size, numNew);
//陣列中元素個數=原陣列中元素個數+新陣列中元素個數
size += numNew;
//c容量為0則回傳false,容量不為0則回傳true
return numNew != 0;
}
我們總結一下流程:
- 將原集合轉換為陣列形式
- 判斷陣列是否需要擴容
- 將傳進來的集合元素拷貝到原集合的末尾
- 元素個數變化
👋3.1.4 addAll(int index, Collection<? extends E> c)
將指定集合中的所有元素插入到此串列中,從指定的位置開始
public boolean addAll(int index, Collection<? extends E> c) {
//判斷index是否符合規則
rangeCheckForAdd(index);
//將要添加的集合轉為陣列形式
Object[] a = c.toArray();
//將陣列長度賦給numNew
int numNew = a.length;
//判斷增加元素之后是否需要擴容
ensureCapacityInternal(size + numNew); \
//記錄有多少位元素需要向后移動
int numMoved = size - index;
//如果有元素需要移動
if (numMoved > 0)
//進行陣列拷貝,這一步只是進行移動操作,并沒有添加資料,將陣列中index之后的所有元素向后移動numNew位
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
//進行陣列填充,將集合c中的元素從陣列index處開始填充
System.arraycopy(a, 0, elementData, index, numNew);
//陣列中元素個數=原陣列中元素個數+新陣列中元素個數
size += numNew;
//回傳c集合是否為空的布林值
return numNew != 0;
}
我們總結一下流程:
- 將原集合轉換為陣列形式
- 判斷陣列是否需要擴容
- 記錄下需要有多少元素進行移動
- 如果有元素需要移動,新陣列中index之后的所有元素向后移動numNew位
- 對陣列進行填充
- 陣列元素個數變化
👋3.1.5 set(int index, E element)
根據索引修改集合元素
public E set(int index, E element) {
//判斷索引是否符合規則,索引不能超過陣列長度
rangeCheck(index);
//獲得下標處的元素
E oldValue = elementData(index);
//修改索引處的元素值
elementData[index] = element;
//將舊的元素值回傳
return oldValue;
}
//校驗索引
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//獲得下標處的元素
E elementData(int index) {
return (E) elementData[index];
}
👋3.1.6 get(int index)
獲得索引處的元素值
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
//校驗索引范圍
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//回傳索引處元素
E elementData(int index) {
return (E) elementData[index];
}
👋3.1.7 remove(Object o)
移除指定元素值的元素
public boolean remove(Object o) {
//如果要洗掉的元素是否為空
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
//遍歷集合
for (int index = 0; index < size; index++)
//將集合中的每一個元素進行比對,比對成功則洗掉
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*集合真正洗掉元素的方法
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
//對集合的實際修改次數+1
modCount++;
//計算要移動的元素的個數
int numMoved = size - index - 1;
//如果移動的元素的個數>0
if (numMoved > 0)
//移動元素
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//將要洗掉的元素置為null,就是為了盡快被垃圾回識訓制回收
elementData[--size] = null;
}
ArrayList中使用迭代器遍歷時洗掉元素會爆ConcurrentModificationException()并發修改例外的原因:這種情況只出現在要洗掉的元素位于集合尾部的時候
迭代器在遍歷時會呼叫next()方法,next方法會在checkForComodification()方法中對expectedModCount
(期待修改次數)和modCount(實際修改次數)進行比對
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
expectedModCount值的變化只與第一次創建迭代器時的modCount有關,而modCount值的變化與增加和洗掉
(不考慮其他情況)都有關,如果在迭代器遍歷時洗掉元素,會導致modCount與expectedModCount不一致,故
拋出ConcurrentModificationException例外
結論
-
當要洗掉的元素在集合的倒數第二個位置的時候,不會產生并發修改例外,因為在呼叫
hashNext方法的時候,游標的值和集合的長度一樣,那么就會回傳false,因此就不會再去呼叫next方法獲取集合的元素,既然不會呼叫next方法,那么底層就不會產生并發修改例外 -
集合每次呼叫add方法的時候,實際修改次數變數的值都會
自增一次 -
在獲取迭代器的時候,集合只會執行一次將時機修改集合的次數賦值給預期修改集合的次數
-
集合在洗掉元素的時候也會針對實際修改次數進行自增的操作
👋3.1.8 clear()
清空集合
public void clear() {
//修改次數
modCount++;
//將陣列中的每個元素都設為null
for (int i = 0; i < size; i++)
elementData[i] = null;
//陣列元素個數清空
size = 0;
}

👋4 擴展
👋4.1 轉換方法toString()
public String toString()把集合中所有元素轉換成字串
ArrayList集合本身并沒有toString,我們需要到它的父類AbstractList的父類AbstractCollection中去尋找

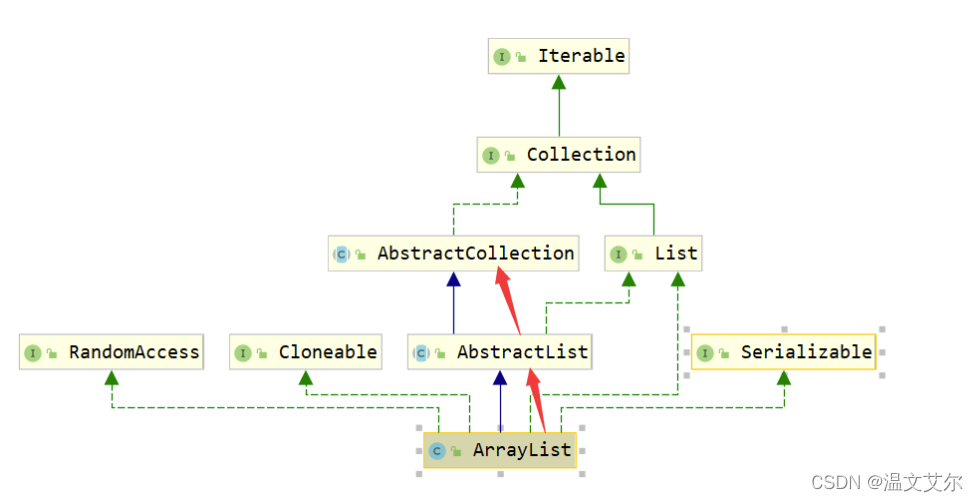
/**
* Returns a string representation of this collection. The string
* representation consists of a list of the collection's elements in the
* order they are returned by its iterator, enclosed in square brackets
* (<tt>"[]"</tt>). Adjacent elements are separated by the characters
* <tt>", "</tt> (comma and space). Elements are converted to strings as
* by {@link String#valueOf(Object)}.
*
* @return a string representation of this collection
*/
public String toString() {
//獲取集合元素的迭代器
Iterator<E> it = iterator();
//判斷迭代器是否為空
if (! it.hasNext())
return "[]";//為空直接回傳空
//創建StringBuilder物件便于拼接字串,StringBuilder執行緒安全
StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {
E e = it.next();//迭代器向后移動
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())//迭代器執行完畢,將整個緩沖區物件轉換為String物件
return sb.append(']').toString();
sb.append(',').append(' ');//否則拼接','' '
}
}
👋4.2 迭代器Iterator iterator()
ArrayList對迭代器方法進行了重寫
//獲取迭代器物件
public Iterator<E> iterator() {
return new Itr();
}
//迭代器原始碼,不同集合實作的迭代器底層原始碼都是不一樣的
private class Itr implements Iterator<E> {
int cursor; //游標,默認值就是0
int lastRet = -1; //記錄-1這個位置
//將集合實際修改次數賦值給預期修改次數
int expectedModCount = modCount;
//集合是否還有元素
public boolean hasNext() {
//判斷游標是否不等于集合元素總量
return cursor != size;
}
public E next() {
checkForComodification();
//將游標賦值給i 第一次i=0
int i = cursor;
//如果游標大于等于集合size就說明集合中已經沒有元素
if (i >= size)
throw new NoSuchElementException();
//將集合存盤資料的地址賦值給該方法的區域變數
Object[] elementData = ArrayList.this.elementData;
//針對多執行緒環境,如果成立,觸發并發修改例外
if (i >= elementData.length)
throw new ConcurrentModificationException();
//游標向前移動1位
cursor = i + 1;
//將游標位的元素回傳
return (E) elementData[lastRet = i];
}
//校驗預期修改次數是否和實際修改次數一樣
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
if (i >= elementData.length)
throw new ConcurrentModificationException();的作用:
防止多并發修改例外,如果多個執行緒同時呼叫next(),i的值會增加,如果在容量之內會回傳0,但如果增加的i的值大于容量,證明并發數量過多,對i的準確性造成破壞性影響,拋出ConcurrentModificationException()例外

👋5 ArrayList相關面試題
👋5.1 ArrayList是如何擴容的
第一次擴容10 以后每次都是原容量的1.5倍
👋5.2 ArrayList頻繁擴容導致添加性能急劇下降,如何處理?
我們通過一個案例解答
public class Test04 {
public static void main(String[] args) {
//未指定容量的list
ArrayList<String> list = new ArrayList<>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list.add(i+"");
}
long endTime = System.currentTimeMillis();
System.out.println("未指定容量時添加100W條資料用時:"+(endTime-startTime));
//指定容量的list1
ArrayList<String> list1 = new ArrayList<>(1000000);
long startTime1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list.add(i+"");
}
long endTime1 = System.currentTimeMillis();
System.out.println("指定容量時添加100W條資料用時:"+(endTime1-startTime1));
}
}
未指定容量時添加100W條資料用時:95
指定容量時添加100W條資料用時:69
由此我們可得,在資料量較大時,為了避免擴容,我們最好創建ArrayList時便指定容量
👋5.3 ArrayList插入或洗掉元素一定比LinkedList慢嗎
首先我們要確定ArrayList和LinkedList的底層資料結構
- ArrayList資料結構是·動態陣列·
- LinkedList資料結構是·鏈表·
我們從原始碼層面去分析
觀察LinkedList的remove原始碼
public E remove(int index) {
//對索引的校驗,我們這里不做討論
checkElementIndex(index);
//主要看node(int index)方法
return unlink(node(index));
}
//根據索引雖然可以直接去除一半的元素參與判斷,但是效率依然很低,需要不斷遍歷
Node<E> node(int index) {
//這里是判斷index在鏈表的前半部分還是后半部分,因為是雙向的
//判斷index是否小于集合長度的一半
if (index < (size >> 1)) {
//在前半部分的話,第一個節點就為x,從前往后找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//在后半部分的話,最后一個節點為x,從后往前找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//通過node(int index)方法找到了index所在節點的位置
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
//獲取下一個節點
final Node<E> next = x.next;
//獲取上一個節點
final Node<E> prev = x.prev;
//如果x在鏈表的開頭
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//如果x在鏈表的末尾
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
由此我們可以得出結論:
- 要洗掉的節點位于集合中間位置,則LinkedList的速度慢
- 要洗掉的節點位于集合的頭部和尾部,則LinkedList的速度快(如果不從添加元素時就開始計算時間的話是這樣,但是如果要把添加元素的時間計算在內那么ArrayList快,因為LinkedList中的last節點每次在add元素時都會向后移動一位,也是需要花費時間的)
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
👋5.4 ArrayList是執行緒安全的嗎
先回答問題:ArrayList不是執行緒安全的,我們使用一個案例來演示
package ArrayListProject.CloneTest;
import java.util.ArrayList;
import java.util.List;
public class CollectionTask implements Runnable {
private List<String> list;
public CollectionTask(List<String> list) {
this.list = list;
}
@Override
public void run() {
try {
Thread.sleep(50);
}catch (Exception e){
e.printStackTrace();
}
list.add(Thread.currentThread().getName());
}
}
class MyTest{
public static void main(String[] args) throws Exception {
List<String> list = new ArrayList<>();
CollectionTask ct = new CollectionTask(list);
//開啟50條執行緒
for (int i = 0; i < 50; i++) {
new Thread(ct).start();
}
//確保子執行緒執行完畢
Thread.sleep(3000);
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("集合長度:"+list.size());
}
}
Thread-47
Thread-45
Thread-44
Thread-41
Thread-34
Thread-35
Thread-39
Thread-33
Thread-27
Thread-26
Thread-40
Thread-32
Thread-20
Thread-21
Thread-15
Thread-29
Thread-14
Thread-9
Thread-8
Thread-28
Thread-23
Thread-3
null
null
null
null
null
null
null
Thread-22
Thread-38
Thread-49
Thread-48
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
Thread-43
集合長度:49
由輸出結果可知:ArrayList是執行緒不安全的
那么如何避免執行緒安全問題呢?
方案一:加同步代碼塊,保證代碼在執行時不被其他執行緒干擾
@Override
public void run() {
synchronized (this){
try {
Thread.sleep(50);
}catch (Exception e){
e.printStackTrace();
}
list.add(Thread.currentThread().getName());
}
}
方案二:使用Vector集合代替ArrayList
- Vector類實作了可擴展的物件陣列,并且其add方法上有synchronized關鍵字,但是其效率相比ArrayList較低,如果不需要執行緒安全的實作,建議使用ArrayList代替Vector
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}
方案三:利用Collections.synchronizedList(List list)方法
List<String> list = new ArrayList<>();
List<String> list1 = Collections.synchronizedList(list);
ArrayList什么情況下需要加同步鎖?
ArrayList作為區域變數時不需要加鎖,因為它是專屬以某一執行緒的,而成員變數被所有執行緒共享,ArrayList作為成員變數時需要加同步鎖
👋5.5 如何復制某個ArrayList到另一個ArrayList中去
- 使用clone()方法
- 使用ArrayList構造方法
- 使用addAll方法
👋5.6 已知成員變數集合存盤N多用戶名稱,在多執行緒的環境下,使用迭代器在讀取集合資料的同時如何保證還可以正常寫入資料到集合中
package ArrayListProject.CloneTest;
import java.util.ArrayList;
public class CollectionThread implements Runnable {
private static ArrayList<String> list = new ArrayList<>();
static {
list.add("Jack");
list.add("Lucy");
list.add("Jimmy");
}
@Override
public void run() {
//迭代器
for (String s : list) {
System.out.println(s);
list.add("coco");
}
}
}
class MyTest01{
public static void main(String[] args) {
CollectionThread ct = new CollectionThread();
for (int i = 0; i < 10; i++) {
new Thread(ct).start();
}
}
}
報錯資訊:
Jack
Jack
Jack
Jack
Jack
Jack
Exception in thread "Thread-1" Exception in thread "Thread-2" Exception in thread "Thread-5" Exception in thread "Thread-6" Exception in thread "Thread-4" Exception in thread "Thread-0" Jack
Exception in thread "Thread-7" Jack
Exception in thread "Thread-3" Jack
Exception in thread "Thread-8" Jack
Exception in thread "Thread-9" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:901)
at java.util.ArrayList$Itr.next(ArrayList.java:851)
at ArrayListProject.CloneTest.CollectionThread.run(CollectionThread.java:23)
at java.lang.Thread.run(Thread.java:748)
java.util.ConcurrentModificationException
我們可以看到ConcurrentModificationException并發修改例外出現,為了解決這個問題,我們可以利用下面集合來完成讀寫
CopyOnWriteArrayList
但是代價是昂貴的,除非我們的程式里有很多讀寫操作,否則還是用ArrayList
private static CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
Jack
Jack
Jack
Jack
Jack
Jack
Jack
Jack
Jack
Jack
Lucy
Lucy
Lucy
Lucy
Lucy
Lucy
Lucy
Lucy
Lucy
Jimmy
Jimmy
Jimmy
Jimmy
Jimmy
Jimmy
Jimmy
Jimmy
Lucy
Jimmy
Jimmy
👋5.7 ArrayList和LinkedList區別
- ArrayList
- 基于
動態陣列的資料結構 - 對于隨機訪問的get和set,ArrayList要優于LInkedList
- 對于隨機操作的add和remove,ArrayList不一定比LInkedList慢(ArrayList底層由于是動態陣列,因此并不是每次add和remove都需要創建新陣列)
- 基于
- LinkedList
- 基于
鏈表的資料結構 - 對于順序操作,LinkedList不一定比ArrayList慢
- 對于隨機操作,LinkedList效率明顯較低
- 基于
🙏相見即是有緣,如果對你有幫助,給博主一個免費的點贊以示鼓勵把QAQ?
這里是溫文艾爾の原始碼學習之路- 🙏作者水平欠佳,如果發現任何錯誤,歡迎批評指正
- 👋博客主頁 溫文艾爾の學習小屋
- 👋更多文章請關注溫文艾爾主頁
- 👋超詳細ArrayList決議!
- 👋更多文章:
- 👋HashMap底層原始碼決議上(超詳細圖解+面試題)
- 👋HashMap底層原始碼決議下(超詳細圖解)
- 👋HashMap底層紅黑樹原理(超詳細圖解)+手寫紅黑樹代碼

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/379532.html
標籤:java
上一篇:Mybatis中萬能的Map