基于CNN的影像/語意分割演算法主要有Unet FCN PSPnet DAnet DeepLabV3+,HRnet+OCR等,去年年底基于Transform的各類CV演算法(如ViT,Swin等)在分割/分類任務上都表現了相比CNN更為優秀的分割精度,
這里就簡單介紹一下基于Swin模塊的Unet分割演算法:來自慕尼黑工業大學的Swin-Unet
論文:https://arxiv.org/abs/2105.05537
代碼:https://github.com/HuCaoFighting/Swin-Unet
首先我們看模型結構:
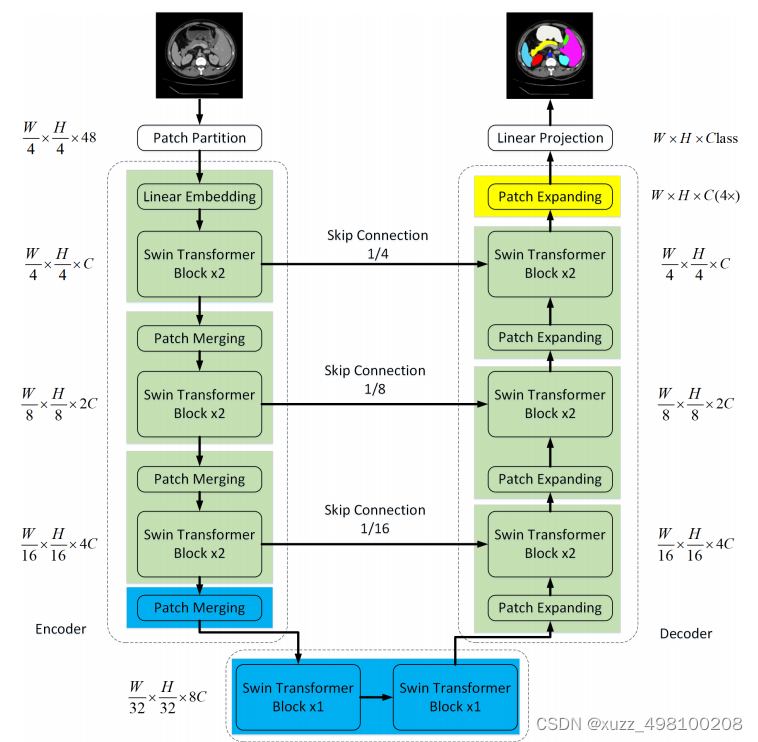
整個網路結構看起來非常的清楚,可以說基本上就相當于把Unet中的2D卷積換成了Swin模塊,對于Swin提出的W-MSA和SW-MSA在前面Swinformer那一期介紹了一下,更詳細的還是得看代碼,Swin論文那里我認為為了講故事這塊結構寫的的有點玄學了,
整體結構和演算法部分下面我跟著代碼一起詳細介紹:
首先是資料增廣:
Swin-Unet代碼結構比較清晰清爽,整體邏輯非常清晰:
def random_rot_flip(image, label): #隨機翻轉
k = np.random.randint(0, 4)
image = np.rot90(image, k)
label = np.rot90(label, k)
axis = np.random.randint(0, 2)
image = np.flip(image, axis=axis).copy()
label = np.flip(label, axis=axis).copy()
return image, label
def random_rotate(image, label): #正負20度旋轉
angle = np.random.randint(-20, 20)
image = ndimage.rotate(image, angle, order=0, reshape=False)
label = ndimage.rotate(label, angle, order=0, reshape=False)
return image, label
影像增廣方面就用了兩個,一個是影像和label同步進行隨機翻轉,一個是影像和label進行正負20度隨機旋轉
其他的就很常規了:
首先寫了一個Synapse_dataset類,通過繼承torch的Dataset類,復寫Dataset中的__len__和__getitem__方法,其中__getitem__主要是讀影像和label的numpy陣列,利用上面的影像增廣做同步矩陣變換之后轉換成pytorch的torch.tensor后喂入模型,__getitem__主要是讀到影像時同步為影像和label做對應的操作,這里我為了博客輕量把具體實作代碼去掉了,想看的同學可以去看這塊原始碼,很簡單,
class Synapse_dataset(Dataset):
def __init__(self, base_dir, list_dir, split, transform=None):
def __len__(self):
return len(self.sample_list)
def __getitem__(self, idx):
return sample
最后老辦法喂入torch的dataloader后通過epoch的for回圈同步讀取訓練資料的image和label的tensor:
trainloader = DataLoader(db_train, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True,
worker_init_fn=worker_init_fn)
資料預處理說完了,接下來介紹網路實作步驟:
首先是transform的PatchEmbed結構:
整個結構基本上就是照搬Swin的PatchEmbed方法,直接通過一個2D卷積
表征位置資訊(事實上目前很多基于Transform的演算法都這么干的)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
熟悉Unet結構的同學應該清楚整個Unet核心其實就三部分:
編碼頭:
對影像特征進行聚合,同時下采樣,WH減半,channel同步增加(由于Swin輸入多少輸出多少,所以下采樣功能是通過torch的linear層實作的)
解碼頭:
將影像上采樣要原圖大小方便進行像素點分類
跳連接:
網路層越深得到的特征圖,有著更大的感受野,淺層卷積關注紋理特征,深層網路關注本質的那種特征,通過跳連接可以使特征向量同時具有深層和表層特征(cat方法),由于影像在上采樣程序(CNN的影像分割一般通過2Dconv+雙線性插值進行上采樣)本身不增加新的資訊,但是每一次下采樣提煉特征的同時,也必然會損失一些邊緣特征,而失去的特征并不能從上采樣中找回,因此通過特征的拼接,來實作邊緣特征的一個找回,
上采樣:
作者嘗試了雙線性插值/轉置卷積/Patch expand三種方法,通過對比實驗證明了其有效性:

Patch expand方法其實很簡單,首先通過一個線性層把長采樣到兩倍,然后通過torch.view()通道數變成1/4,wh各增加2倍,cat后剛好和encode對齊
class PatchExpand(nn.Module):
def __init__(self, input_resolution, dim, dim_scale=2, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.expand = nn.Linear(dim, 2*dim, bias=False) if dim_scale==2 else nn.Identity() #輸出feature的channel加倍
self.norm = norm_layer(dim // dim_scale)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
x = self.expand(x)
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
x = rearrange(x, 'b h w (p1 p2 c)-> b (h p1) (w p2) c', p1=2, p2=2, c=C//4)
x = x.view(B,-1,C//4) #wh翻倍,channel減少4倍
x= self.norm(x)
return x
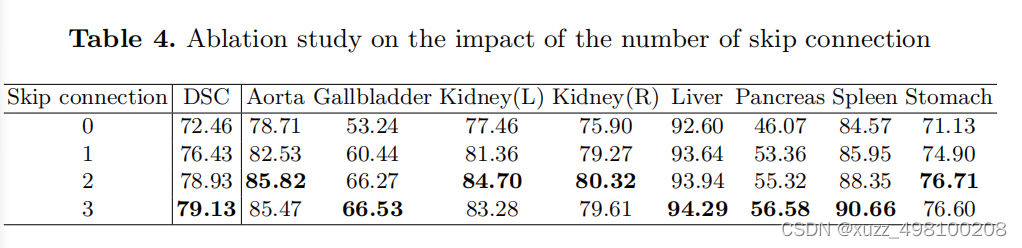
跳連接個數:
如下表顯示跳連接確實是work的
損失函式部分:
Swin-Unet的損失函式沒有任何的改進,是0.4的交叉熵+0.6的dice-loss構成
outputs = model(image_batch)
loss_ce = ce_loss(outputs, label_batch[:].long())
loss_dice = dice_loss(outputs, label_batch, softmax=True)
loss = 0.4 * loss_ce + 0.6 * loss_dice
效果:
Swin-Unet憑借Swin中MSA強大特征提取能力,相比一眾演算法展現了sota的效果:
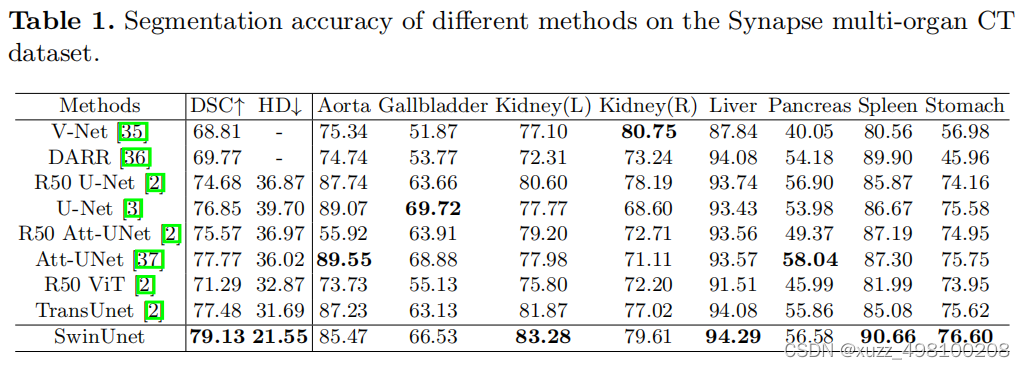
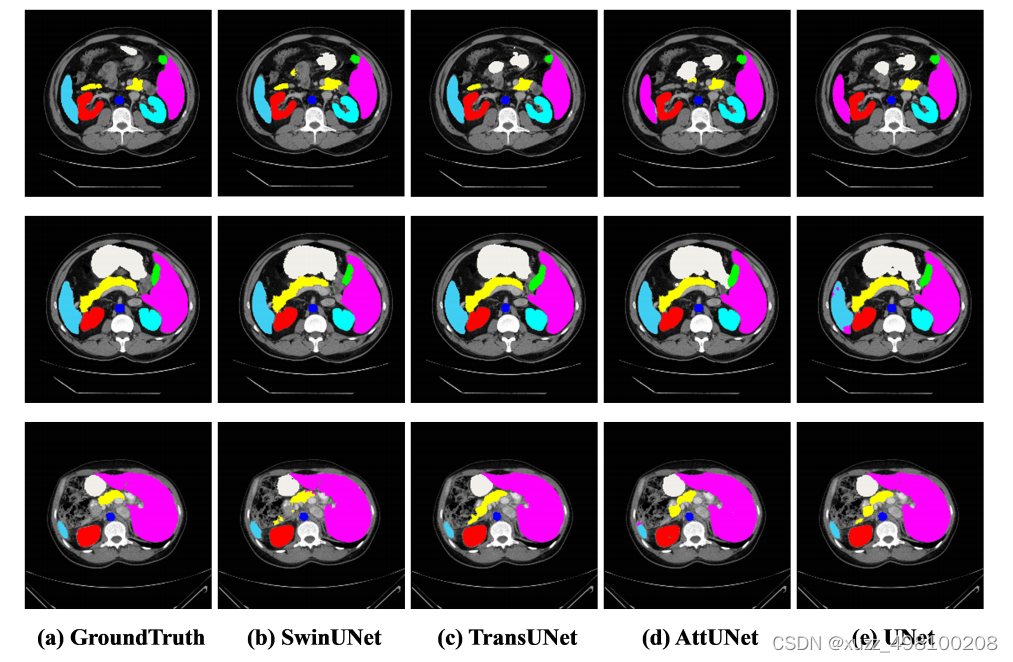
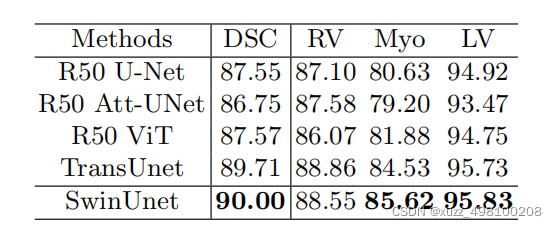
總結:Swin-Unet只是在各個特征提取模塊將Unet的2D卷積換成了Swin結構,在Swin結構和Unet結構上基本沒有改變,損失函式也沒有做變化,再次說明了Swin模塊的強大特征提取能力(感覺創新不太夠啊,不過代碼挺清爽的)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/381243.html
標籤:python