🌕寫在前面
- 🍊博客主頁:kikoking的江湖背景
- 🎉歡迎關注🔎點贊👍收藏??留言📝
- 🌟本文由 kikokingzz 原創,CSDN首發!
- 📆首發時間:🌹2021年12月16日🌹
- 🆕最新更新時間:🎄2021年12月16日🎄
- ??堅持和努力一定能換來詩與遠方!
- 🙏作者水平很有限,如果發現錯誤,請留言轟炸哦!萬分感謝感謝感謝!
- 熱榜文章(沒錯,以下文章全進了熱榜😎)
- 第一話·徹底搞清資料結構中的·邏輯結構&存盤結構
- 第二話·徹底搞懂資料結構之·演算法復雜度
- 第三話·408必看順序表之·人生不是“順序表”
- 第四話·資料結構必看之·單鏈表就這?
- 第五話·資料結構必看之·堆疊 真的這么簡單?
- 第六話·資料結構必看之·佇列 居然這么簡單?

目錄
🌕寫在前面
🔥1.堆的概念
🍊1.1堆的定義
🍊1.2大根堆與小根堆
📜例題1
🔥2.堆的邏輯結構
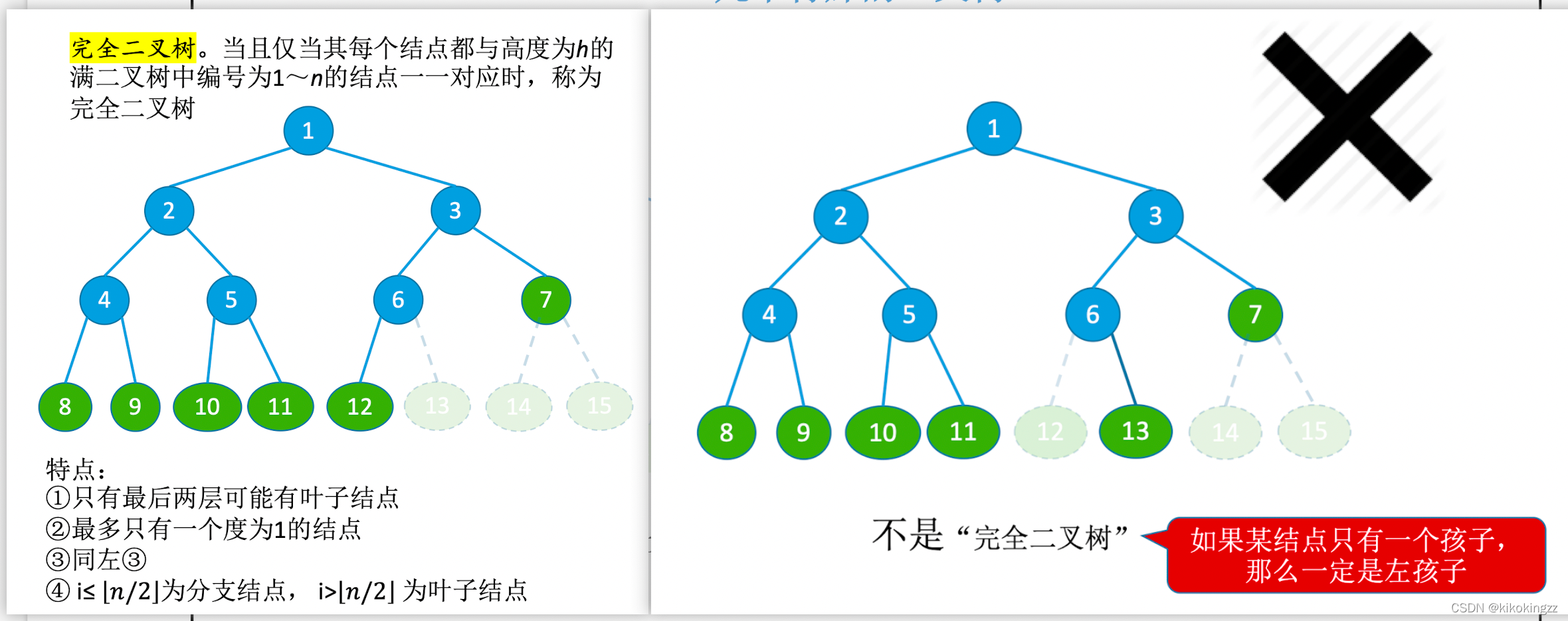
🍊2.1 完全二叉樹
🍊2.2 完全二叉樹的性質
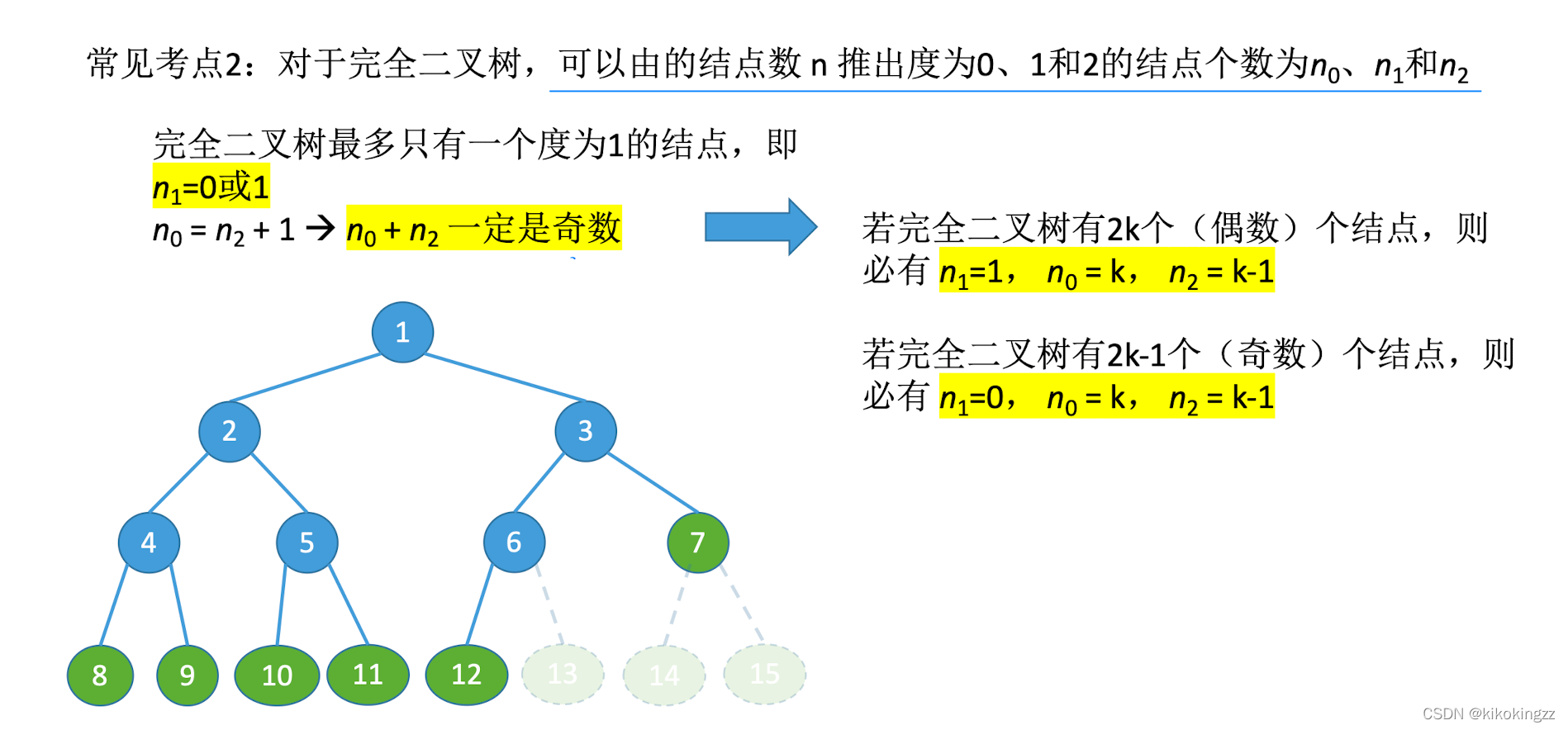
🍓性質1.已知結點個數求完全二叉樹高度
🍓性質2.已知結點總個數求各度結點個數
🔥3.堆的物理結構
🍊3.1順序存盤
🔥4.堆的實作
🍊4.1 堆向下調整演算法
🍓向下調整的時間復雜度:O(logN)
演算法實作
🍊4.2 建堆
🍓建堆的時間復雜度:O(N)
🔥5.堆排序
🍊5.1 建小堆?
🍊5.2 建大堆?
🍓堆排序的時間復雜度: O(N*logN)
🍊5.3 建大堆的逐步操作?
🔥6.用陣列實作堆的一些其他操作
🍊6.1 堆的向下調整操作
🍊6.2 堆的定義
🍊6.3 初始化
🍊6.4 銷毀
🍊6.5 堆的插入
🍊6.6 堆頂元素的洗掉
🍊6.7 取堆頂的資料
🍊6.8 堆的資料個數
🍊6.9 堆的判空操作
🍊6.10 堆的列印
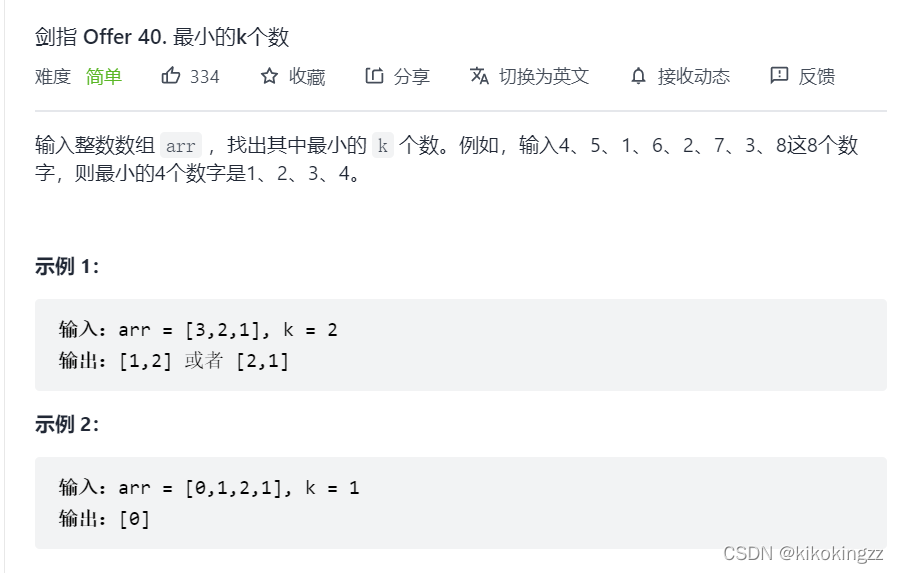
📜劍指 Offer 40. 最小的k個數
?思路一
?思路二
?思路三:TopK
📜海量資料處理問題
??解決辦法
🔥1.堆的概念
🍊1.1堆的定義
·堆通常是一個可以被看做一棵樹的陣列物件,堆總是滿足下列性質:
堆中某個結點的值總是不大于或不小于其父結點的值
堆總是一棵完全二叉樹
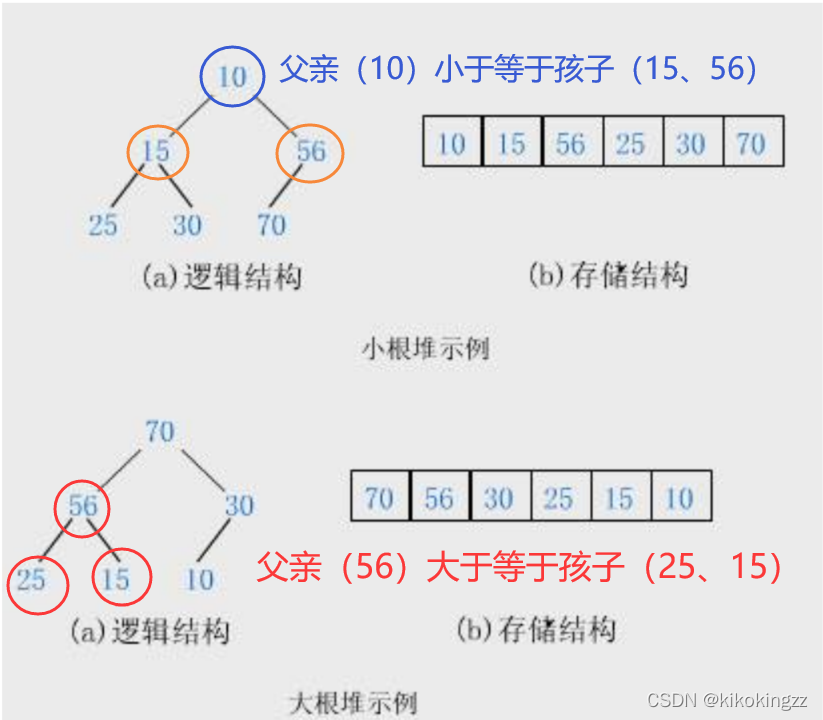
🍊1.2大根堆與小根堆
·小根堆:父親<=孩子
·大根堆:父親>=孩子
📜例題1

???我是分割線???
🔥2.堆的邏輯結構
🍊2.1 完全二叉樹
·堆的邏輯結構是一棵完全二叉樹
🍊2.2 完全二叉樹的性質
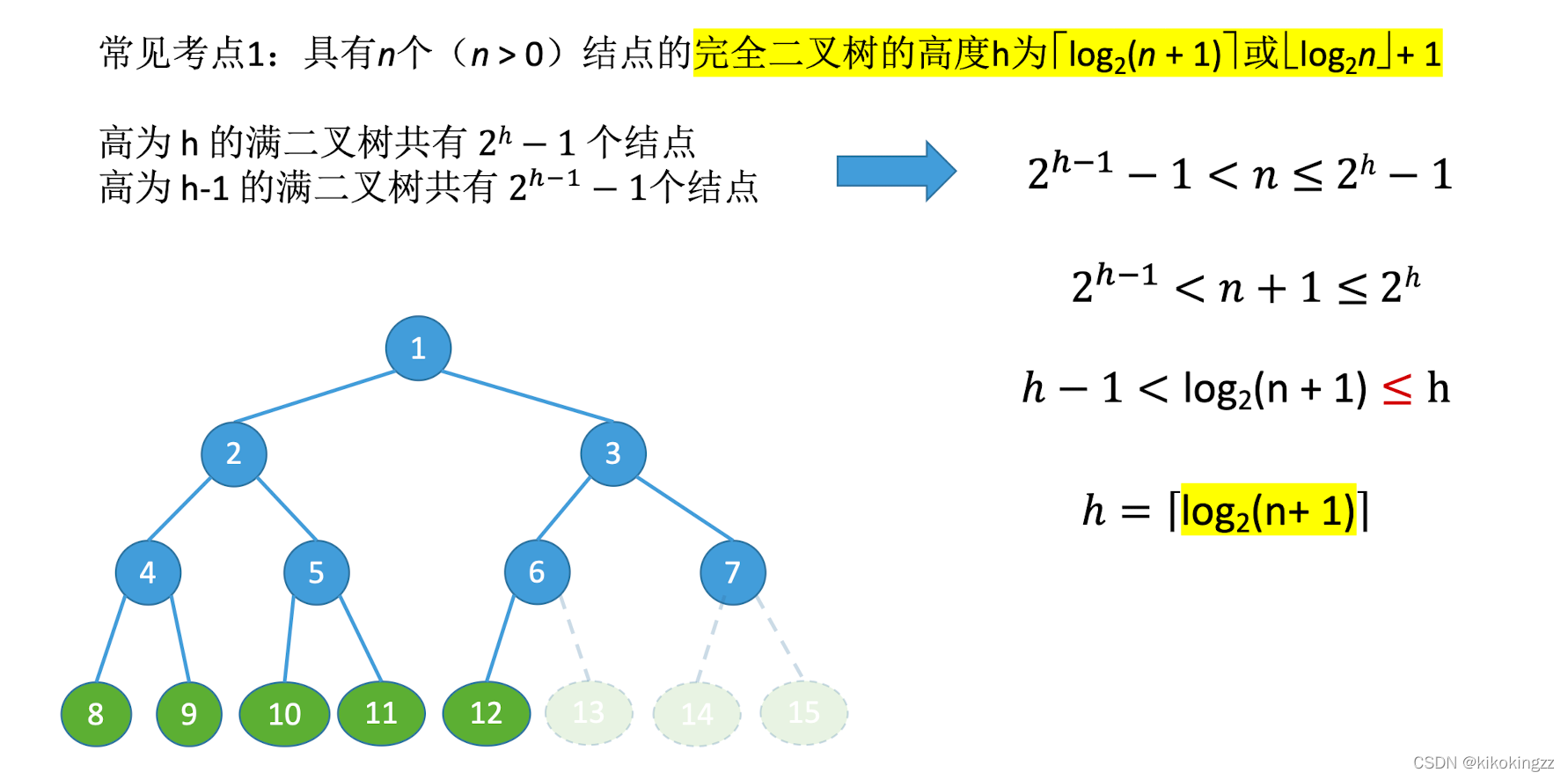
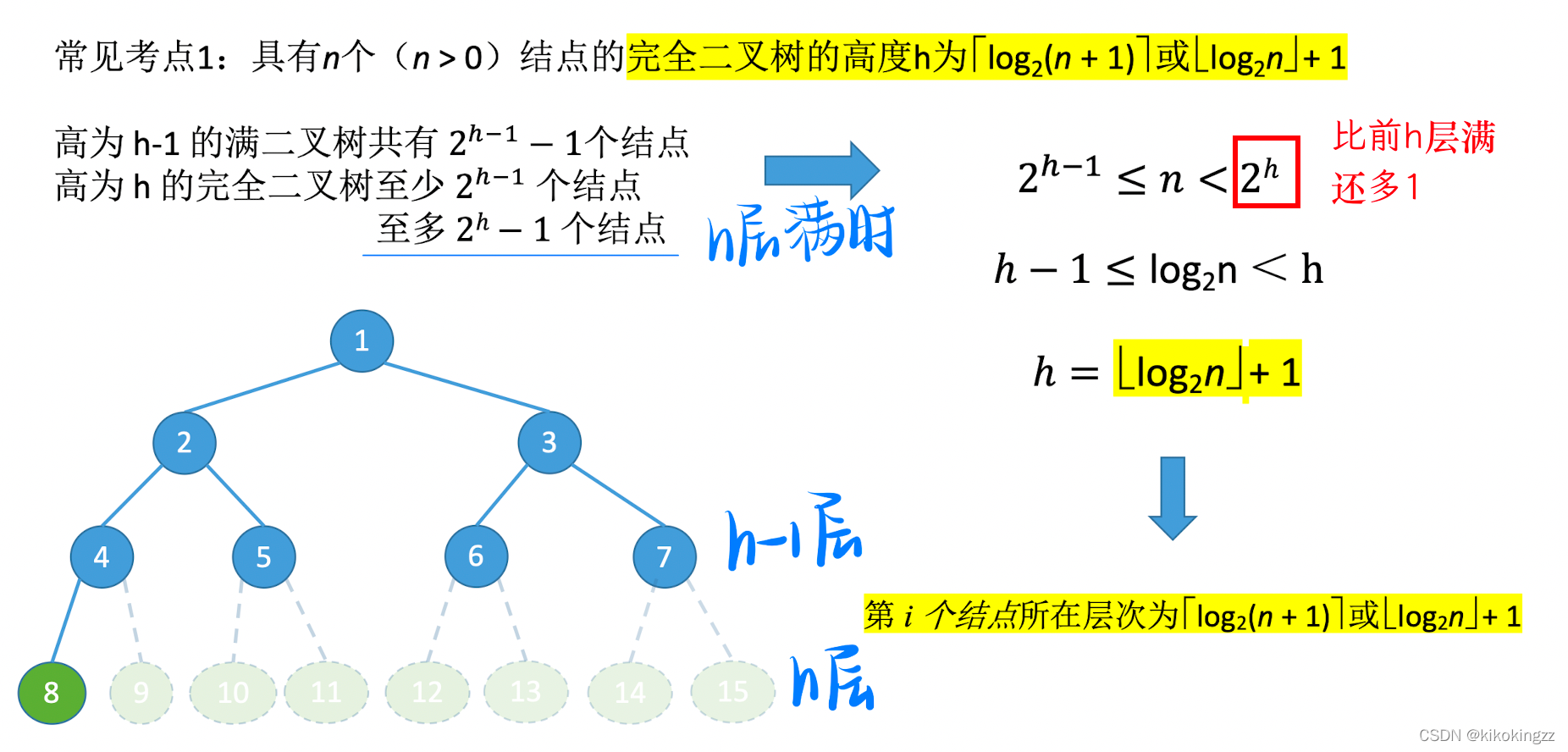
🍓性質1.已知結點個數求完全二叉樹高度
?證明方法1
?證明方法2
🍓性質2.已知結點總個數求各度結點個數
???我是分割線???
🔥3.堆的物理結構
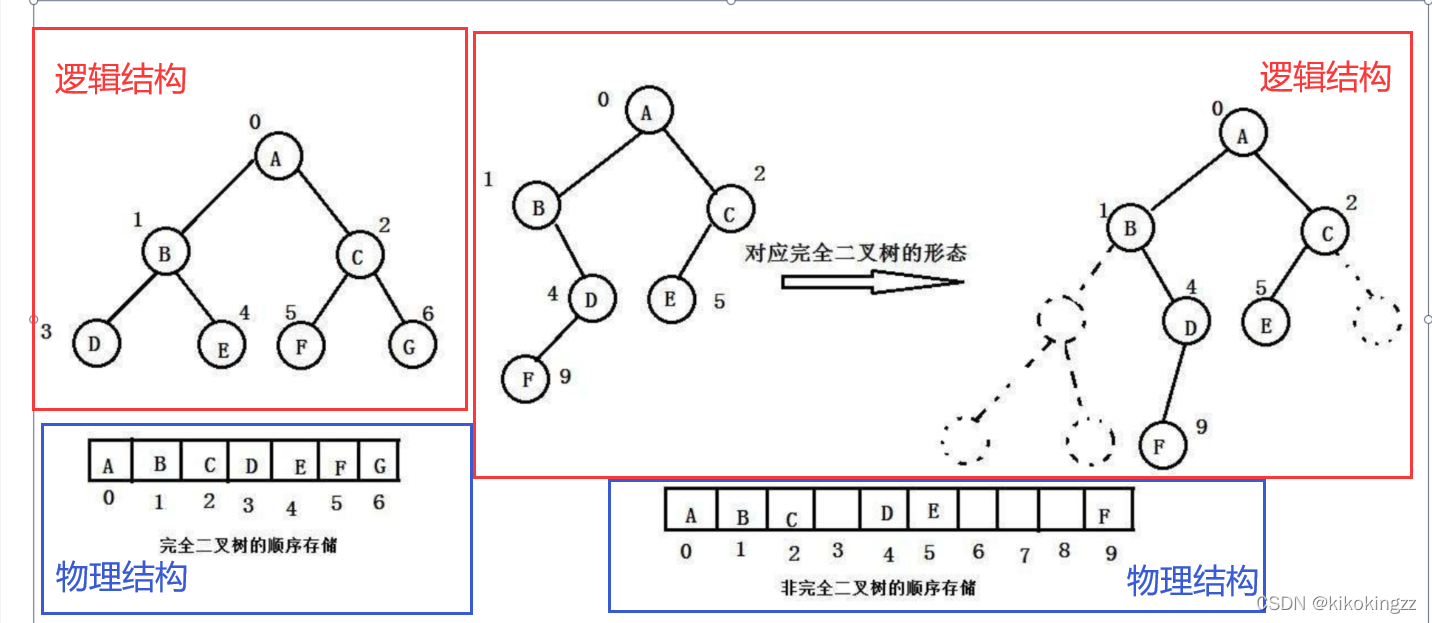
🍊3.1順序存盤
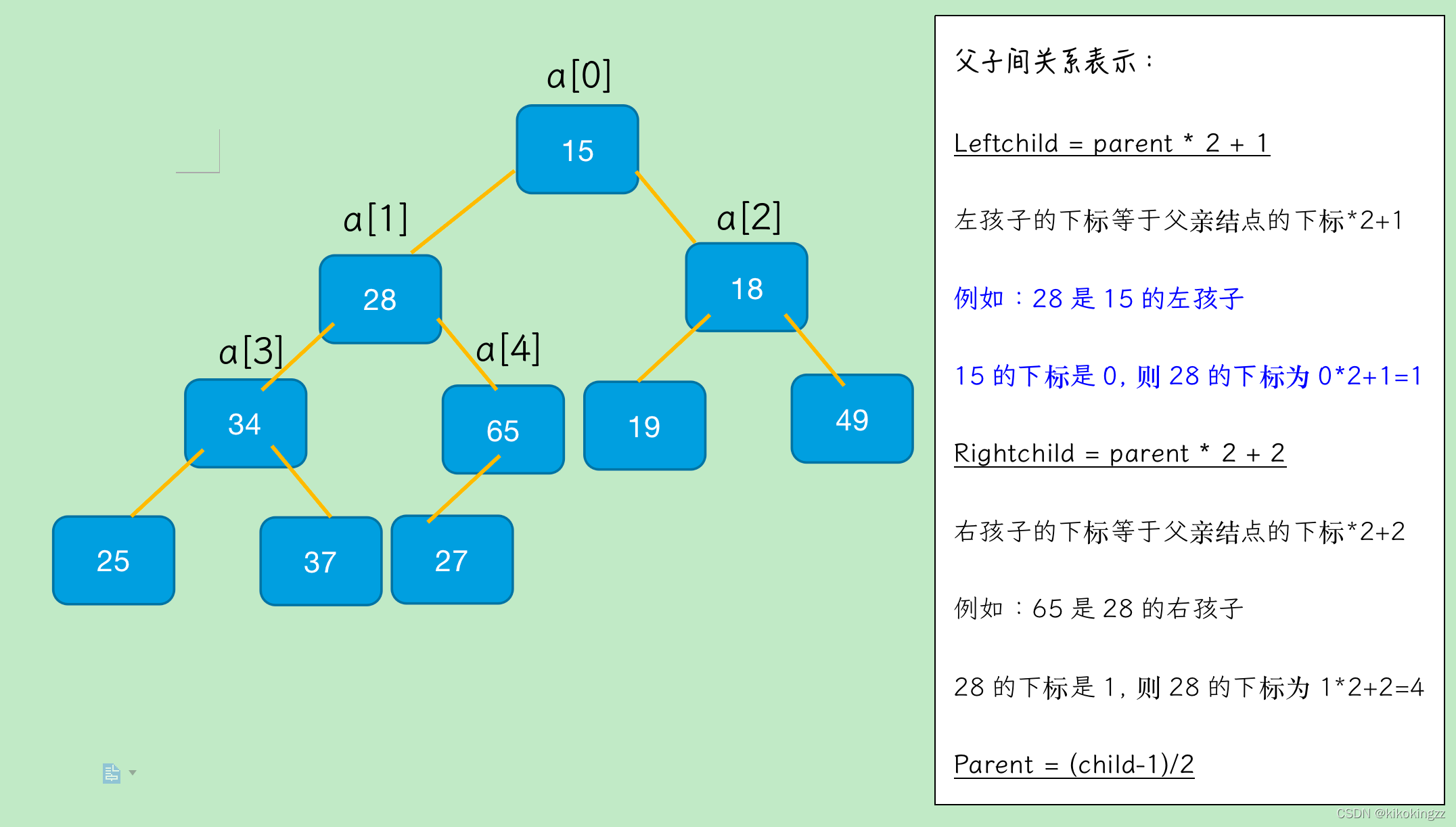
堆的物理結構采用順序存盤的存盤方式
二叉樹的順序存盤是指用一組地址連續的存盤單元依次自上而下、自左向右存盤完全二叉樹上的結點元素,即將完全二叉樹上編號為A、B、C、D····的結點元素存盤在一維陣列下標為[0]、[1]、[2]、[3]····的分量中
???我是分割線???
🔥4.堆的實作
🍊4.1 堆向下調整演算法
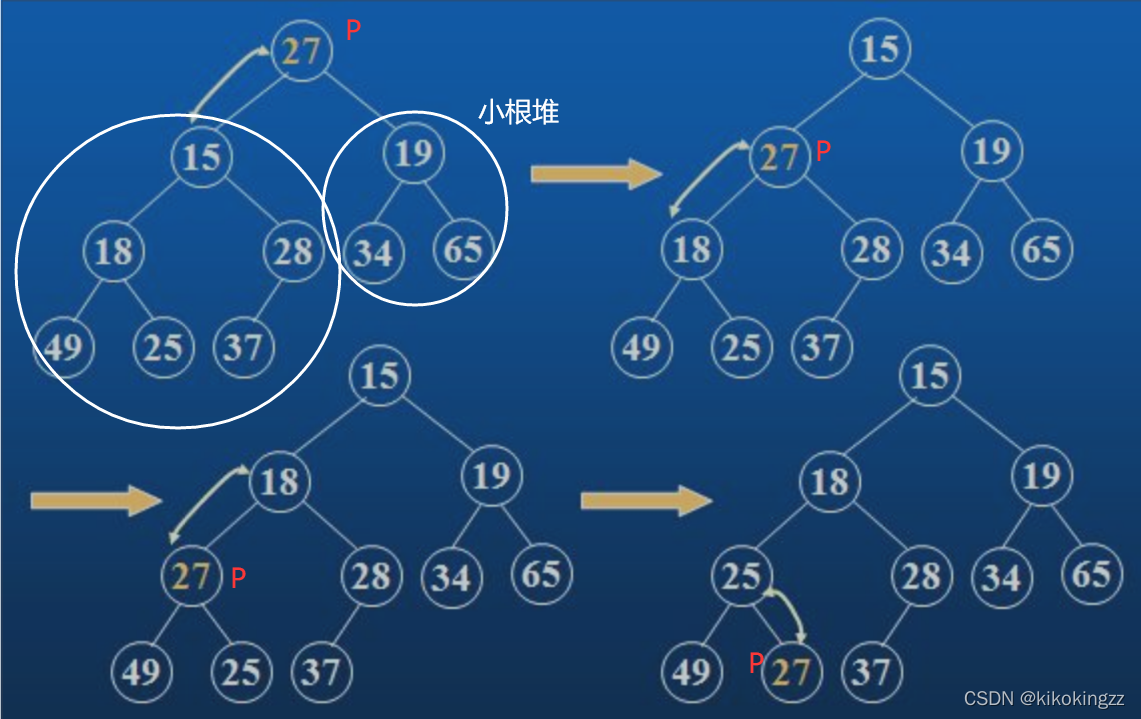
現在我們給出一個陣列,邏輯上看做一顆完全二叉樹,我們通過從根節點開始的向下調整演算法可以把它調整成一個小堆,
向下調整演算法有一個前提:左右子樹必須是一個堆,才能調整,
上述例題中滿足:滿足左子樹和右子樹都是小堆,采用向下調整演算法:
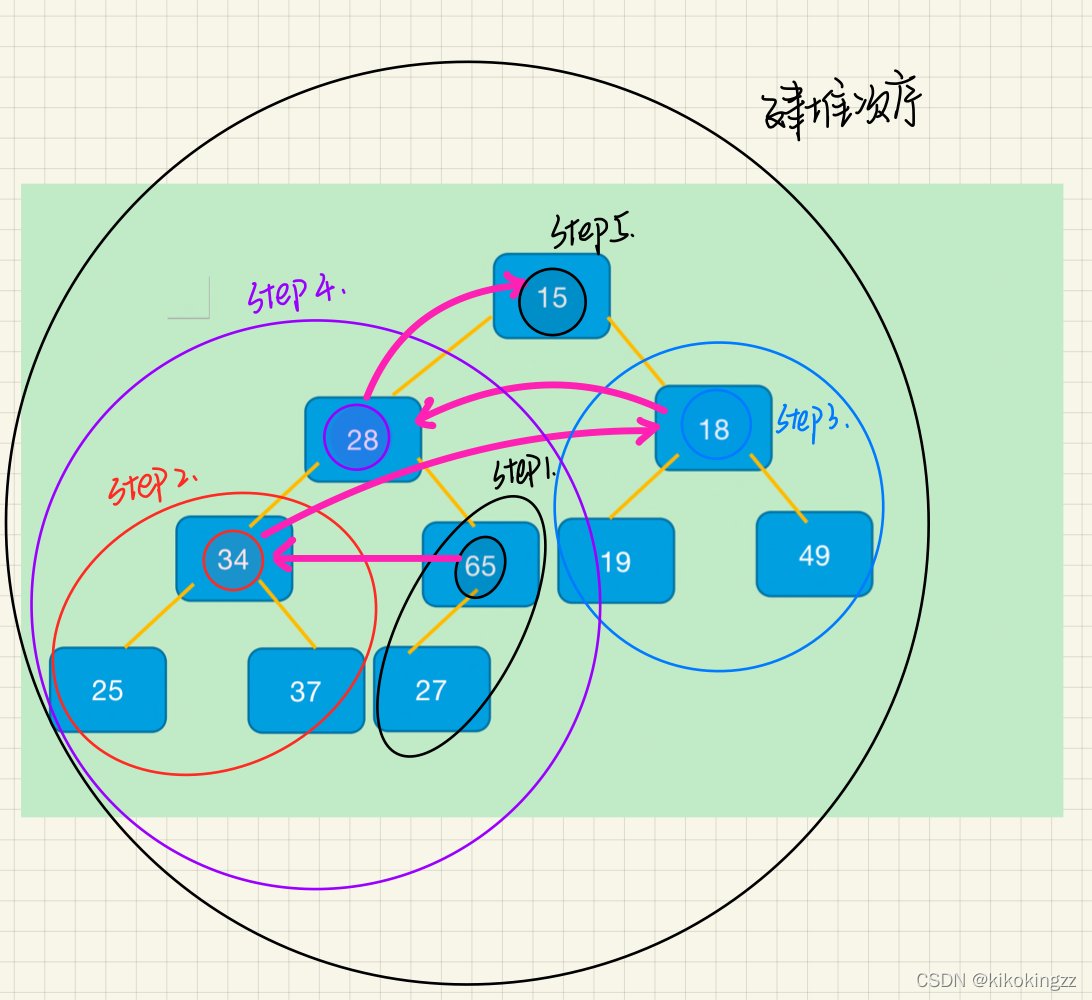
step1.選出左右孩子中小的那一個(上圖中是15)
step2.拿小的這個孩子跟父親比較
(a)如果小的孩子比父親小,就跟父親交換,并且把原來孩子的位置當成父親,繼續向下調整(重復步驟1、2),直到p走到葉子結點,
(b)如果小的孩子比父親大,則不需要處理,此時整個樹已經是小堆
🍓向下調整的時間復雜度:O(logN)
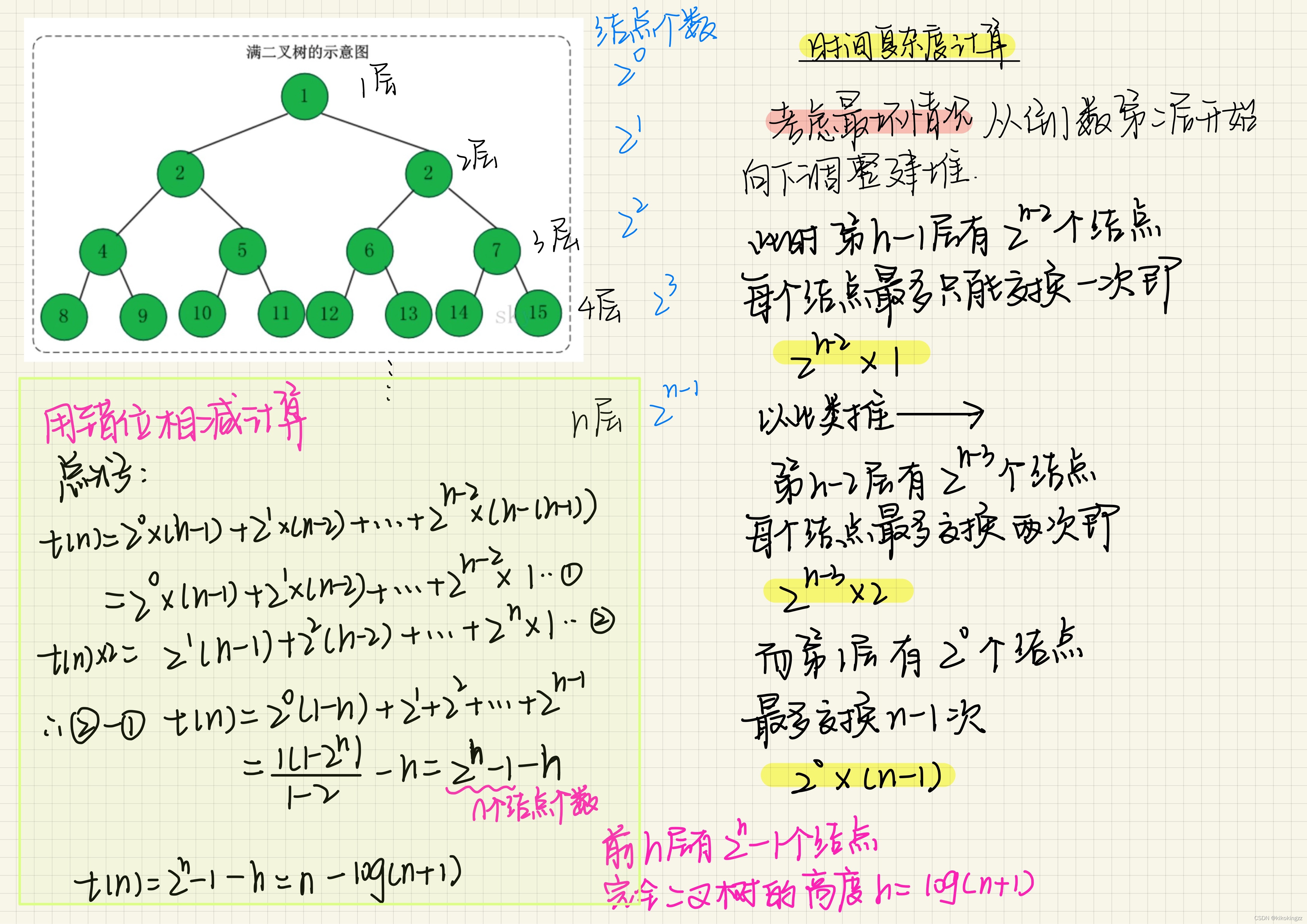
向下調整的次數就是完全二叉樹的深度,對于n個結點的完全二叉樹,其深度為log2(N)+1向下取整,因此時間復雜度取O(logN)
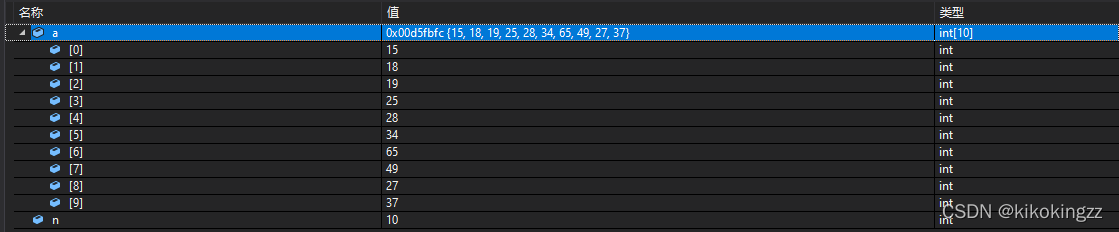
演算法實作
可見如上圖所示,演算法成功實作
//向下調整 void AdjustDown(int* a, int n, int parent) { //parent接收0<------>訪問陣列a[0] int child = parent * 2 + 1; while (child < n) { //選出左右孩子中小的那個 if ( child + 1< n && a[child + 1] < a[child]) //前提右孩子存在才進行比較,否則陣列越界了 //如果右孩子小于左孩子 { ++child;//選擇右孩子 } //否則默認選擇左孩子 if (a[child] < a[parent]) { Swap(&a[parent], &a[child]); parent = child; child = parent * 2 + 1; } else { break; } } } int main() { int a[] = { 27,15,19,18,28,34,65,49,25,37 }; int n = sizeof(a) / sizeof(a[0]); AdjustDown(a, n, 0);//從位置0開始調整 return 0; }
🍊4.2 建堆
當左右子樹不是小堆時,怎么辦?
?思路:從底向上進行建堆,在每個子堆中進行向下調整
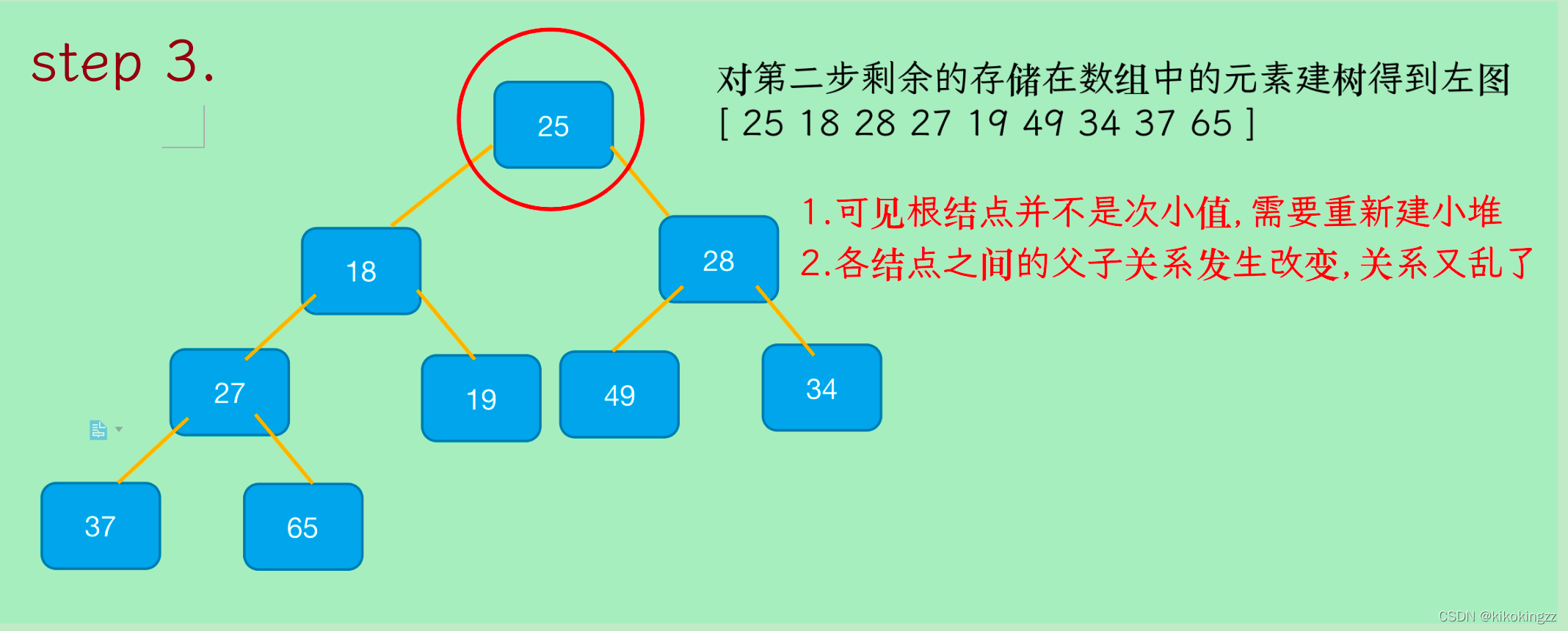
1.找到最后一個結點對應的父結點(上圖中即找到27元素的父結點為65)
2.從結點65開始向下調整,調整完了以后,陣列下標i--為a[3],即接下來從結點34開始向下調整
3.結點34向下調整完畢后,陣列i--為a[2],即從結點18開始向下調整
4.一直i--到a[0]為止,此時所有的元素都向下調整完畢,建堆完成?
//建堆 //n-1是最后一個結點的下標 //(n-1)-1是為了計算父節點下標 for (int i = (n - 1 - 1) / 2; i >= 0; --i)//從最后一個結點對應的父節點開始向根結點操作 { AdjustDown(a, n, i);//從第i個位置,從底向上調整 } return 0;🍓建堆的時間復雜度:O(N)
證明如下:
·可見,當N不斷增大,log(N+1)可以忽略不計,即時間復雜度為O(N)
???我是分割線???
🔥5.堆排序
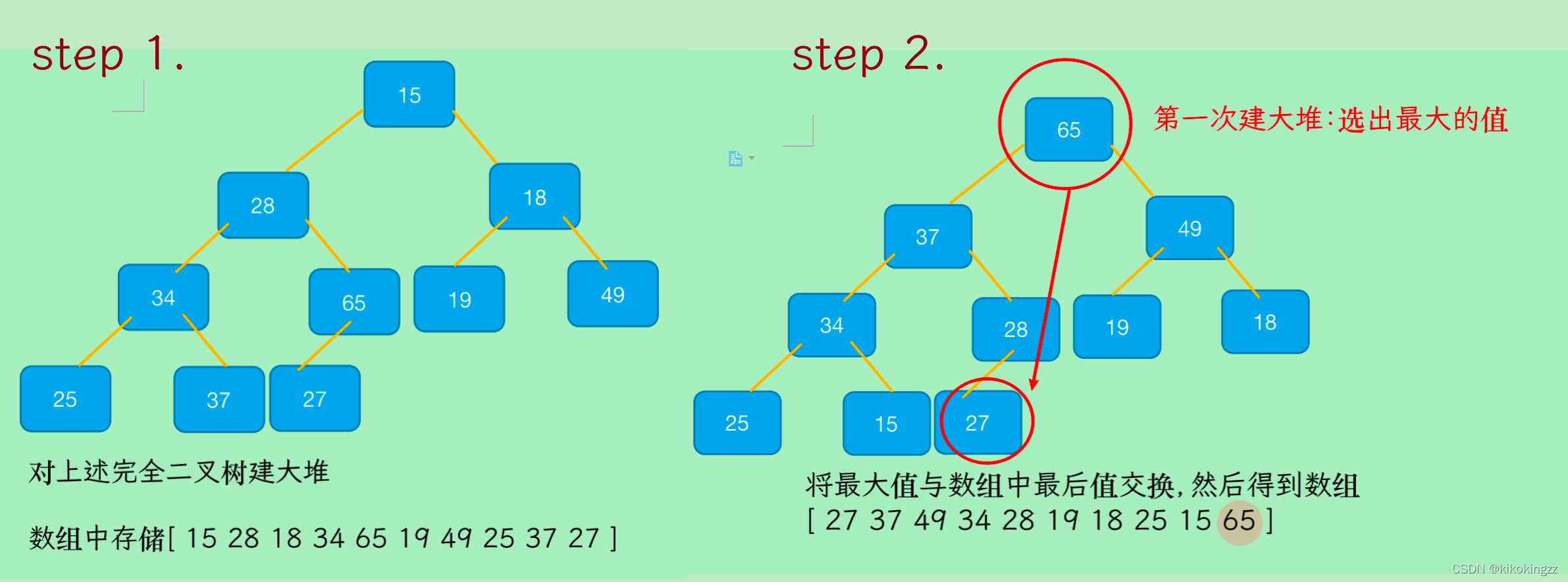
🍊5.1 建小堆?
Q:升序為什么不能建小堆呢?
·建小堆的問題在于:選出最小的數放到第一個位置,緊接著需要選出次小的,如何選?此時如果讓18去做根,整棵樹的關系都亂了,需要重新建堆,才能選出次小的,建堆時間復雜度為O(N);如果通過建堆來選數,還不如直接遍歷比較選數,堆排序就沒有意義了
因為建堆選出最小的數,花了O(N),緊接再用O(N)選出剩下的(N-1)個數中的次小的數,同時剩下的數父子關系全亂了,只能重新建堆,效率太低
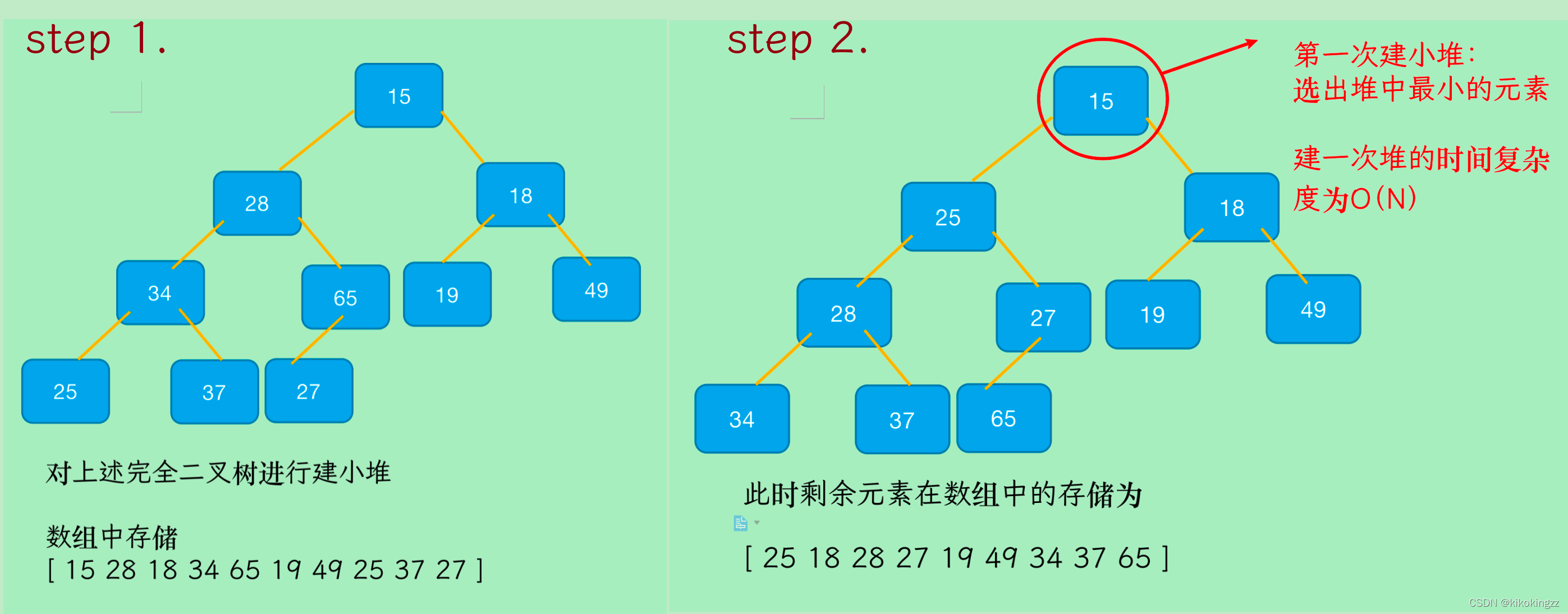
🍊5.2 建大堆?
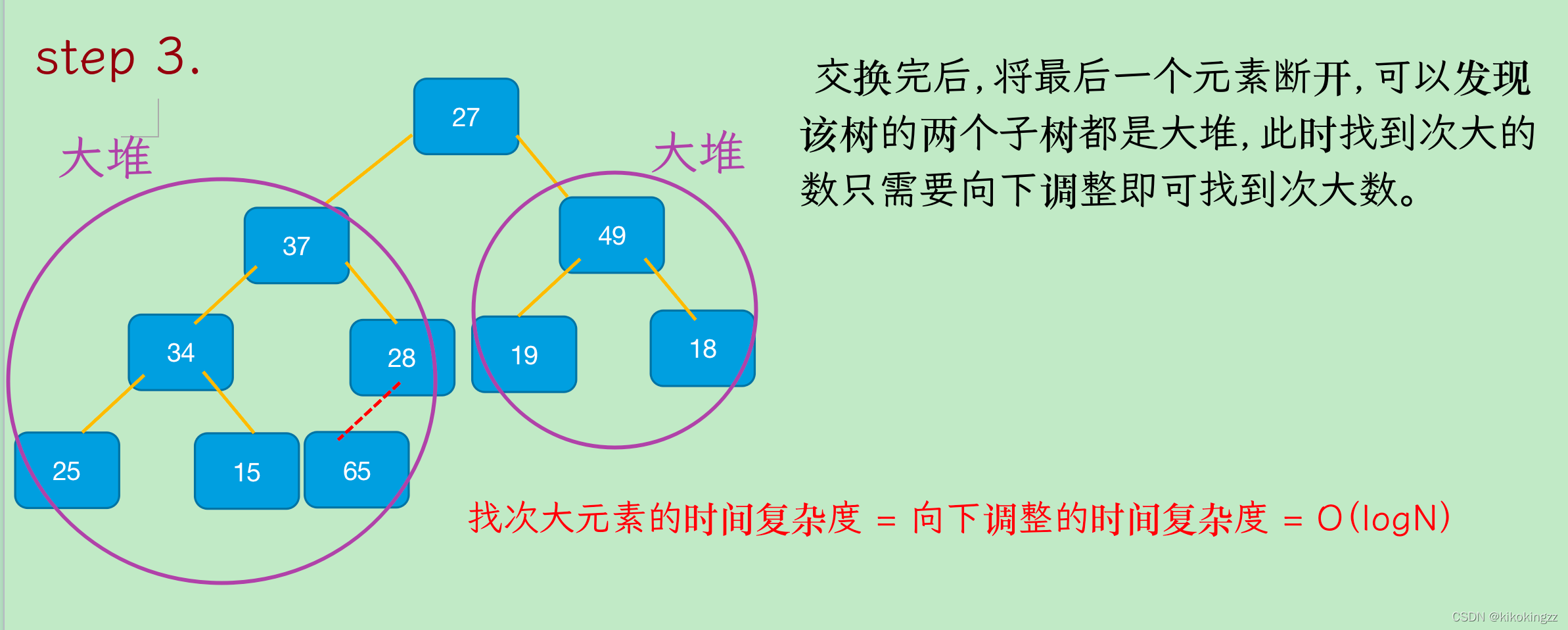
如上圖所示,第一次將最大的數與最后一個數交換;然后不把最后一個數看做堆里面,直接向下調整就能選出次大的(因為父子間的關系沒動),
建大堆時間復雜度:O(N)
排序時間復雜度:O(N*logN)
只需要向下調整完全二叉樹的高度次,最壞的調整次數是logN次;假設有N個元素,最壞需要調整N*logN次;時間復雜度也就是O(N*logN)
總的時間復雜度:O(N*logN)+O(N) ---> O(N*logN)
🍓堆排序的時間復雜度: O(N*logN)
·簡單分析:堆排序和冒泡排序的差別有多大呢?
假設排100w個數
冒泡排序:N^2 --> 10000億次
堆排序: N*logN --> 2000萬次
//排升序-->建大堆 void HeapSort(int* a, int n) { //建堆的時間復雜度是O(N) for (int i = (n - 1 - 1) / 2; i >= 0; --i) { AdjustDown(a, n, i);//從第i個位置,從底向上調整 } int end = n - 1; while (end>0) { Swap(&a[0], & a[end]); AdjustDown(a, end, 0);//n-1個數 //選出次大的 --end; }
🍊5.3 建大堆的逐步操作?
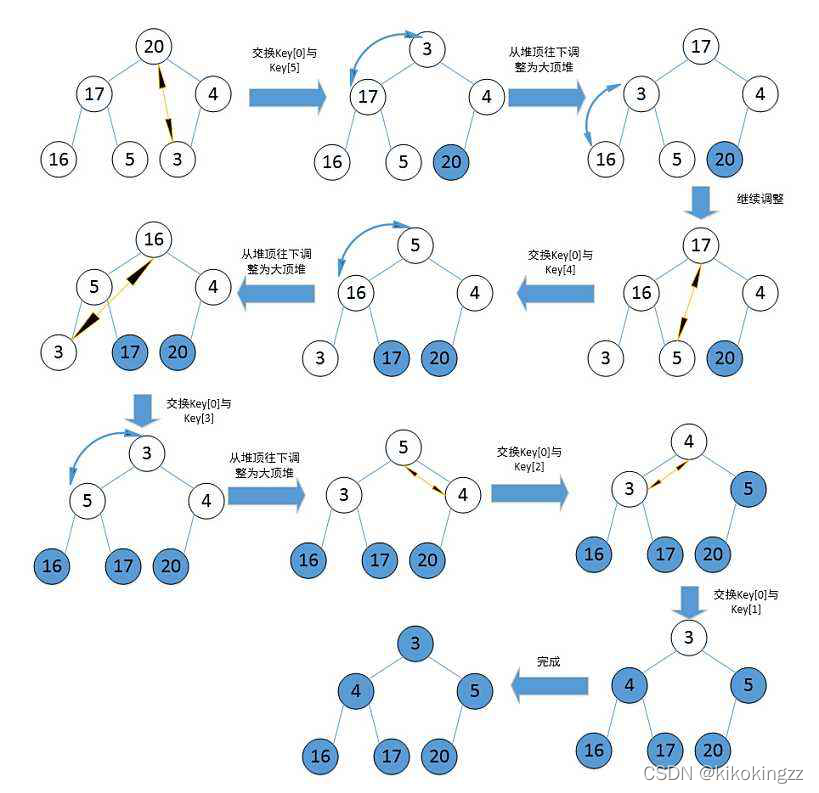
???我是分割線???
🔥6.用陣列實作堆的一些其他操作
🍊6.1 堆的向下調整操作
void AdjustDown(HPDataType* a, int n, int parent) { HPDataType child = parent * 2 + 1; while (child < n) { //選出左右孩子中小的那個 if (child + 1 < n && a[child + 1] > a[child]) { //前提右孩子存在才進行比較,否則陣列越界了 //如果右孩子小于左孩子 ++child;//選擇右孩子 } //否則默認選擇左孩子 if (a[child] > a[parent]) { Swap(&a[parent], &a[child]); parent = child; child = parent * 2 + 1; } else { break; } } }
🍊6.2 堆的定義
typedef int HPDataType; struct Heap { HPDataType* a;//a指向陣列的首元素地址 int size; int capacity;//擴容需要加入capacity }; typedef struct Heap HP;//用HP代替struct Heap
🍊6.3 初始化
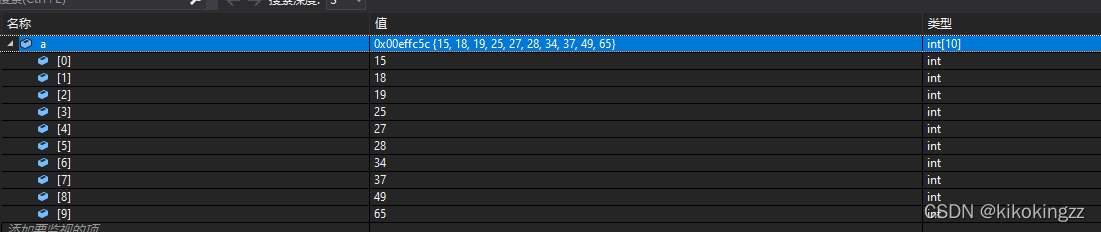
void HeapInit(HP* php, HPDataType* a, int n)//要求以php回傳 { assert(php); php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);//動態申請一片空間 if (php->a == NULL) { printf("malloc fail\n"); exit(-1); } memcpy(php->a, a, sizeof(HPDataType) * n);//將n個資料從a中拷貝到php->a中 php->size = n; php->capacity = n; //建堆 for (int i = (php->size - 1 - 1) / 2; i >= 0; --i) { AdjustDown(php->a, php->size, i);//在堆php->a中,從第i個元素開始向下調整 } }
🍊6.4 銷毀
void HeapDestroy(HP* php) { assert(php); free(php->a);//釋放堆 php->a = NULL;//將指標php->a置空 php->size = php->capacity = 0;//將php->size和php->capacity置為0 }
🍊6.5 堆的插入
在堆的末尾最后插入一個數,因為不確定最后一個數的大小,因此需要向上調整,如果該結點的父結點比插入的數小,則交換這兩個結點;然后用交換后的結點再與新的父結點比較,一直比到最后的父結點為根結點為止;因此我們要寫一個向上調整演算法:
//向上調整演算法 void AdjustUp(HPDataType* a, int child) { int parent = (child - 1) / 2;//找該結點的父結點 while (child > 0) { if (a[parent] < a[child]) { Swap(&a[parent], &a[child]);//如果父結點小于孩子,就交換 child = parent;//將父結點的下標賦給孩子 parent = (child - 1) / 2; } else { break;//跳出回圈 } } }//堆的插入 void HeapPush(HP* php, HPDataType x) { //滿了需要增容 if (php->size == php->capacity) { assert(php); HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * php->capacity * 2);//對原來已有的空間擴容到2倍 if (tmp == NULL) { printf("realloc fail\n"); exit(-1); } php->a = tmp; php->capacity *= 2; } php->a[php->size] = x;//在陣列的尾部插入x php->size++; AdjustUp(php->a, php->size - 1);//從size-1的位置向上調整 }
🍊6.6 堆頂元素的洗掉
void HeapPop(HP* php) { assert(php); assert(php->size > 0);//堆中有元素才向下運行 Swap(&php->a[php->size - 1], &php->a[0]);//交換首尾元素的值 //刪掉換到最后的這個資料 php->size--; AdjustDown(php->a, php->size,0);//向下調整 }
🍊6.7 取堆頂的資料
HPDataType HeapTop(HP* php)//回傳堆堆頂的資料 { assert(php); assert(php->size > 0); return php->a[0];//回傳陣列中第一個元素的值 }
🍊6.8 堆的資料個數
int HeapSize(HP* php) { assert(php); return php->size; }
🍊6.9 堆的判空操作
bool HeapEmpty(HP* php) { assert(php); return php->size == 0; }
🍊6.10 堆的列印
void HeapPrint(HP* php) { for (int i = 0; i < php->size; ++i) { printf("%d->", php->a[i]); } printf("\n"); int num = 1; int i = 0; while (num < php->size)//控制每一層的個數 { for (int j = 0; j < num; ++j) { if(i<php->size)//防止陣列越界 printf("%d ", php->a[i++]); } printf("\n"); num *= 2; } }
???我是分割線???
📜劍指 Offer 40. 最小的k個數
?思路一
采用排序,使用最好的排序演算法,需要N*logN的時間復雜度
?思路二
采用堆排序(效率更高)
對于含有N個數的陣列:
1.把N個數建成小堆 -----> 需要O(N)
2.選一個刪一個,不斷選出前K個最小 -----> 需要O(logN*k)
因為洗掉堆頭元素的本質是將首尾元素交換,將陣列的size-1,然后進行向下調整獲得次小的數,向下調整的次數最多為完全二叉樹的深度;而選出k個數,就要將此步驟進行k次,因此時間復雜度為O(logN*k)
時間復雜度:O(N)+O(logN*K)
空間復雜度:O(N)
注意:上述代碼中呼叫了之前寫好的堆排序代碼int* getLeastNumbers(int* arr, int arrSize, int k, int* returnSize){ HP hp; HeapInit(&hp,arr,arrSize);//建堆,建小堆 int* retArr=(int*)malloc(sizeof(int)*k); for(int i=0;i<k;++i) { retArr[i]=HeapTop(&hp); HeapPop(&hp); } HeapDestroy(&hp); *returnSize=k; return retArr; }
?思路三:TopK
📜海量資料處理問題
Q:對于含有N個數的陣列:假設N是100億時,k是100
對于上述這個問題,我們先計算一下存盤100億個整除需要多大的空間
1 KB=1024 Byte
1 MB=1024 KB
1 GB=1024 MB
1 GB=2^30 Byte=10億+ Byte
100億個整數-->400億Byte ==40G左右(存在檔案中)
如果此時采用思路二,空間復雜度過大!
??解決辦法
1.先把陣列中的前K個資料,建成大堆
2.然后剩下的N-K個數,跟堆頂的資料比較,如果比堆頂的資料小,則替換堆頂的資料,進堆
3.最后堆里面就是最小的K個數
空間復雜度:O(K)
·建立了一個K個資料的陣列(額外空間),因此空間復雜度為O(K)
時間復雜度:O(N*logK)
·將N個數進行比較,最壞的情況就是N個數都要進行向下調整,每個數向下調整的最多次數就是這個完全二叉樹的深度,因為該數的結點數為K,因此最大深度為logK,因此時間復雜度為N*logK
int* getLeastNumbers(int* arr, int arrSize, int k, int* returnSize){ if(k==0) { *returnSize=0; return NULL; } int* arrRet=(int*)malloc(sizeof(int)*k); //前k個數建立大堆 for(int i=0;i<k;++i) { arrRet[i]=arr[i];//把前k個數給arrRet } for(int j=(k-1-1)/2;j>=0;--j)//找父節點向下調整 { AdjustDown(arrRet,k,j); } //剩下的N-k個數 for(int i=k;i<arrSize;++i) { if(arr[i]<arrRet[0]) { arrRet[0]=arr[i];//比堆頂的小,就替換堆頂資料,進堆 AdjustDown(arrRet,k,0);//重新向下調整 } } *returnSize=k; return arrRet; }
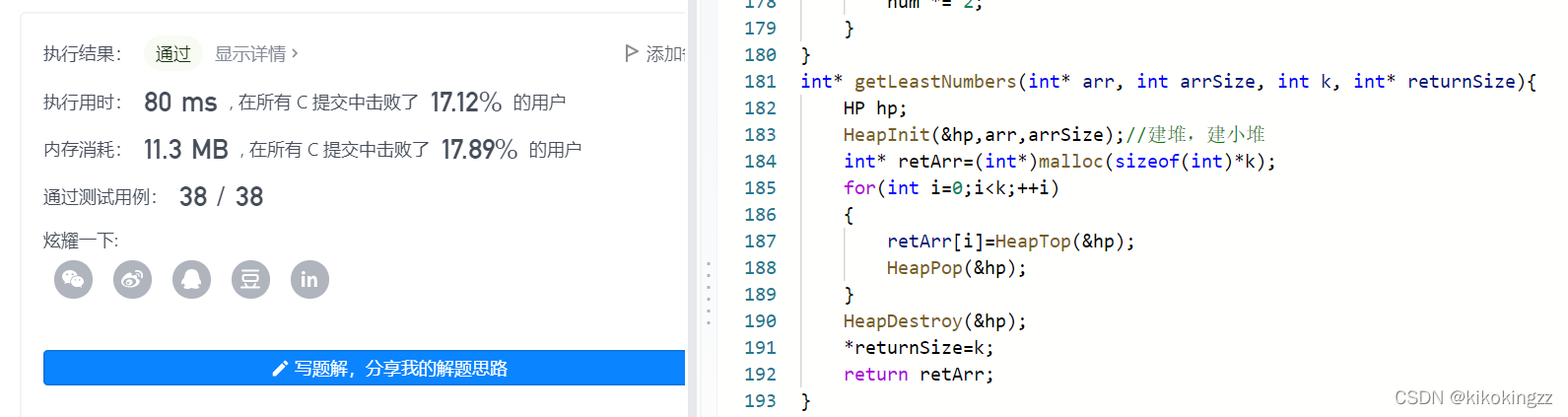
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/382868.html
標籤:java