假設我有以下文本:
Yes: [x]
Yes: [ x]
Yes: [x ]
Yes: [ x ]
No: [x
No: x]
我對regex具有兩個捕獲組的運算式感興趣,如下所示:
組
$1:匹配括號[并]包含一個xin 之間,周圍有可變數量的水平空間x。我可以使用基于分支重置組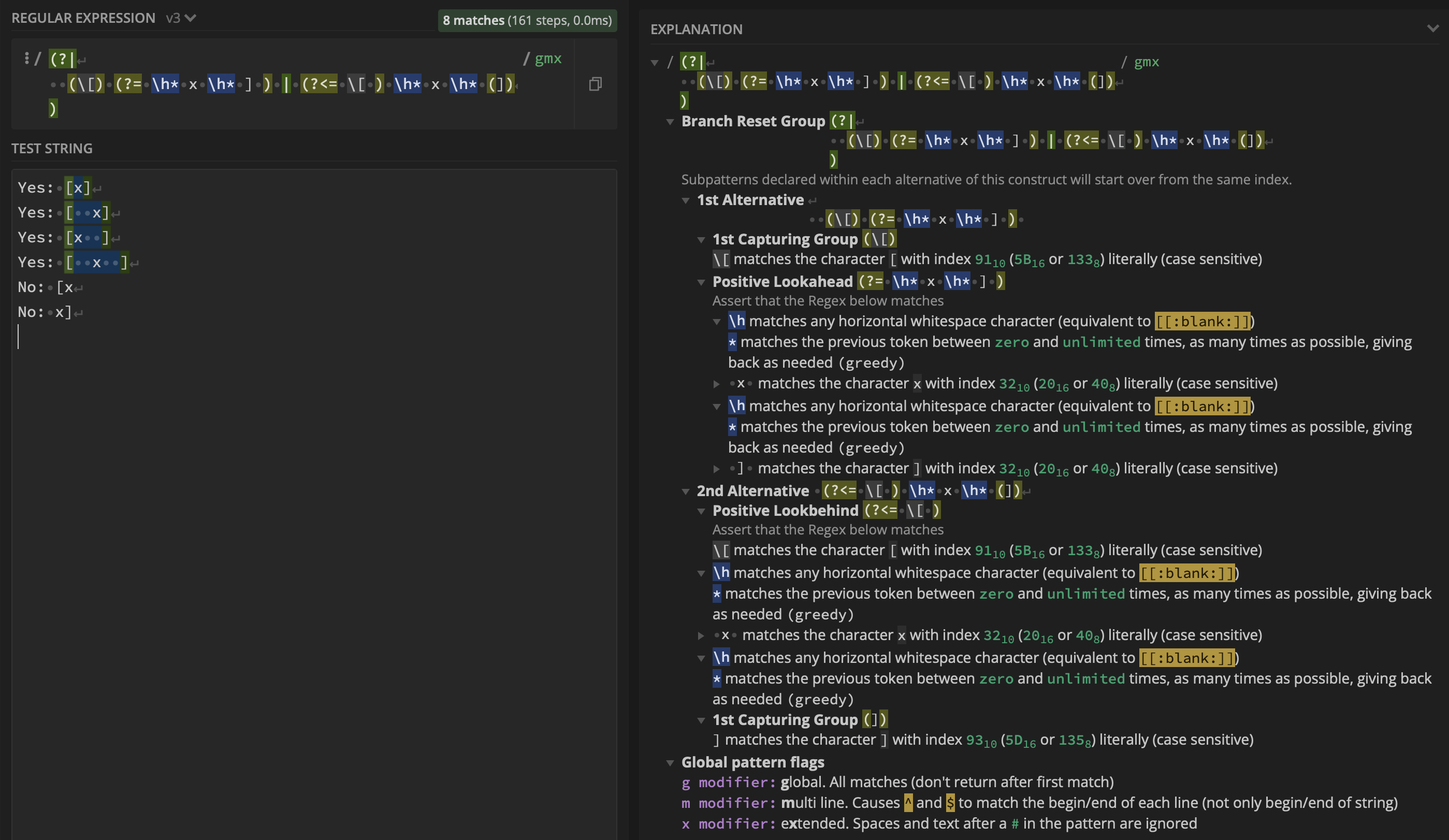
group $2: 應與x括號中包含的[和匹配]。為此,我可以使用一個非捕獲組,結合積極的后向和前瞻斷言:
regex:(?:(?<=\[)\h*(x)(?=\h*]))這導致:
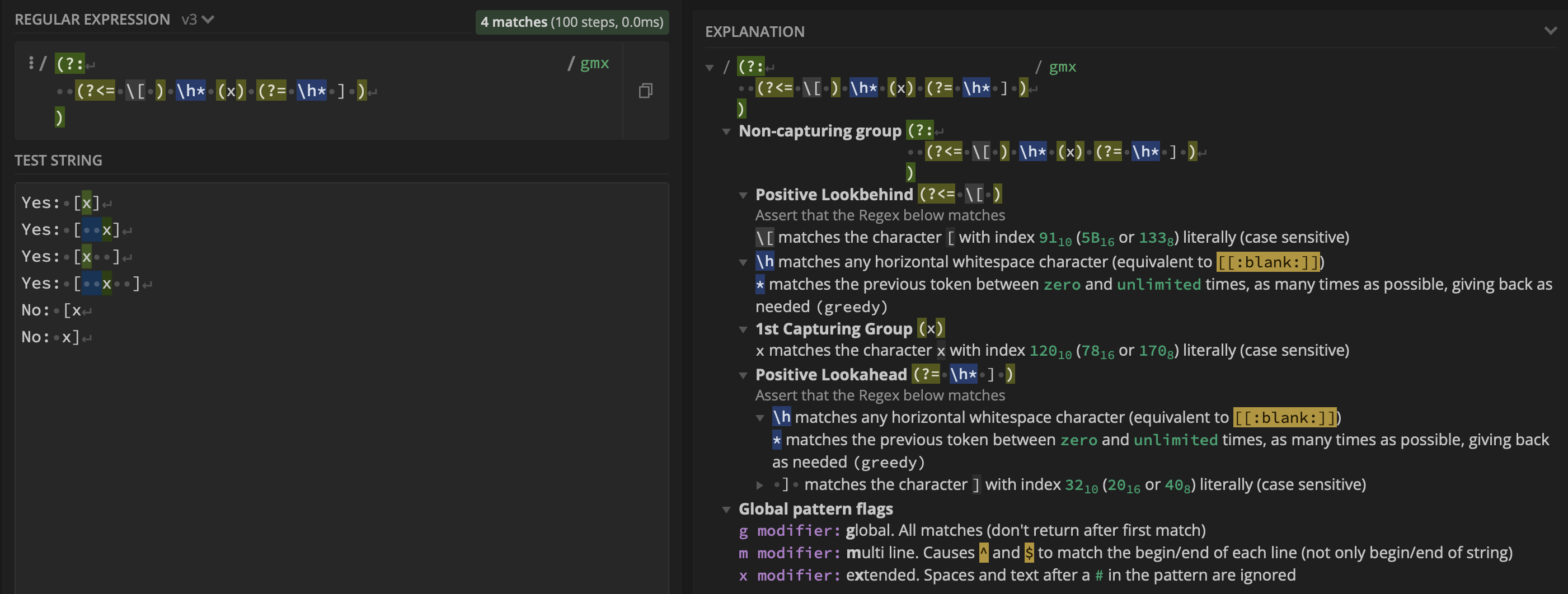
問題是,當我嘗試加入運算式 by 時OR,第二個運算式不匹配任何內容。例如:
(?|(\[)(?=\h*x\h*])|(?<=\[)\h*x\h*(]))|(?:(?<=\[)\h*(x)(?=\h*]))
結果(即,見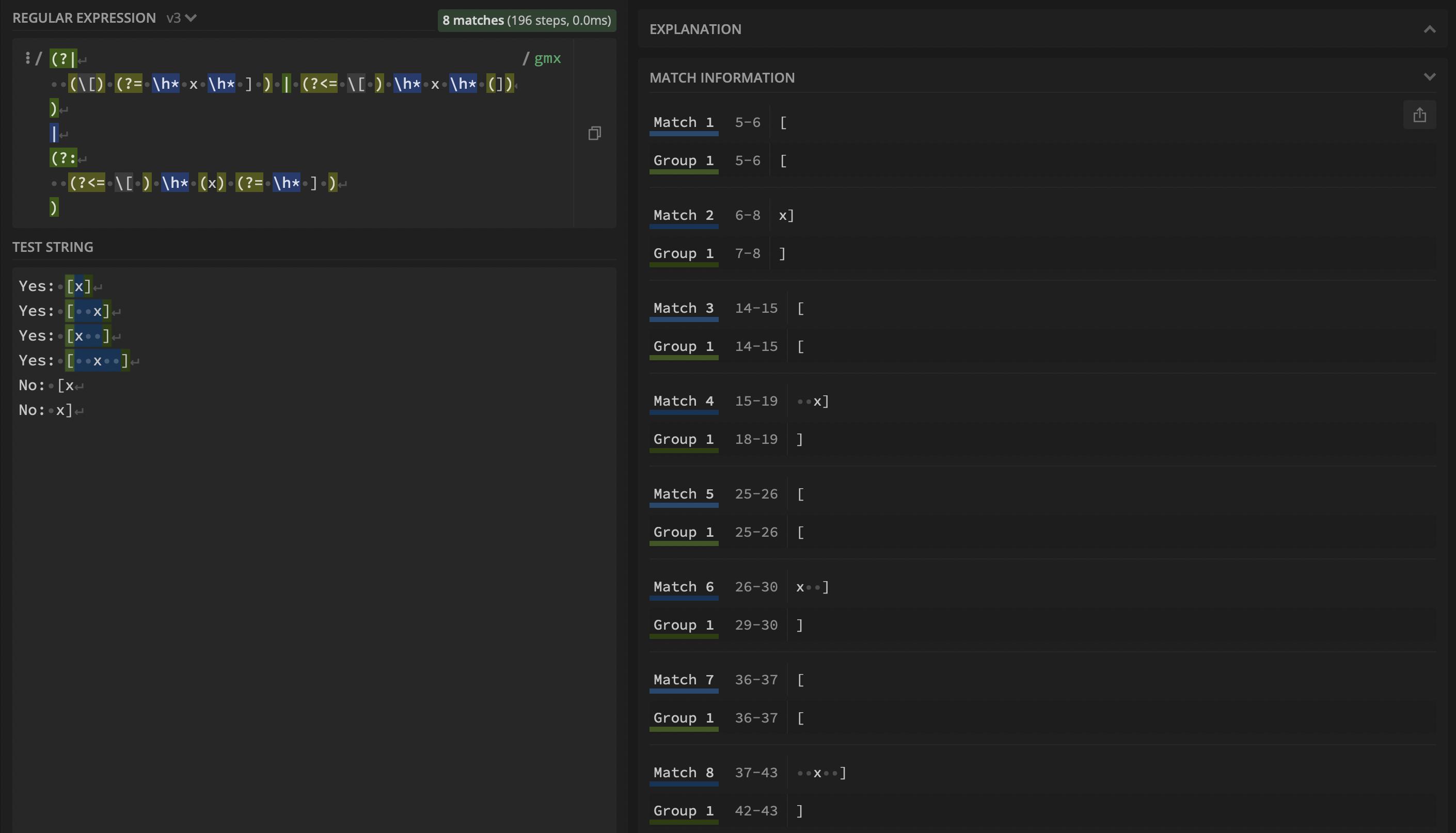
我的直覺(即,可能不正確)是x第二個運算式沒有匹配的余地,因為x在第一個運算式(即 group $0)中匹配。例如,將第二個運算式簡化為(?:(x))(即,參見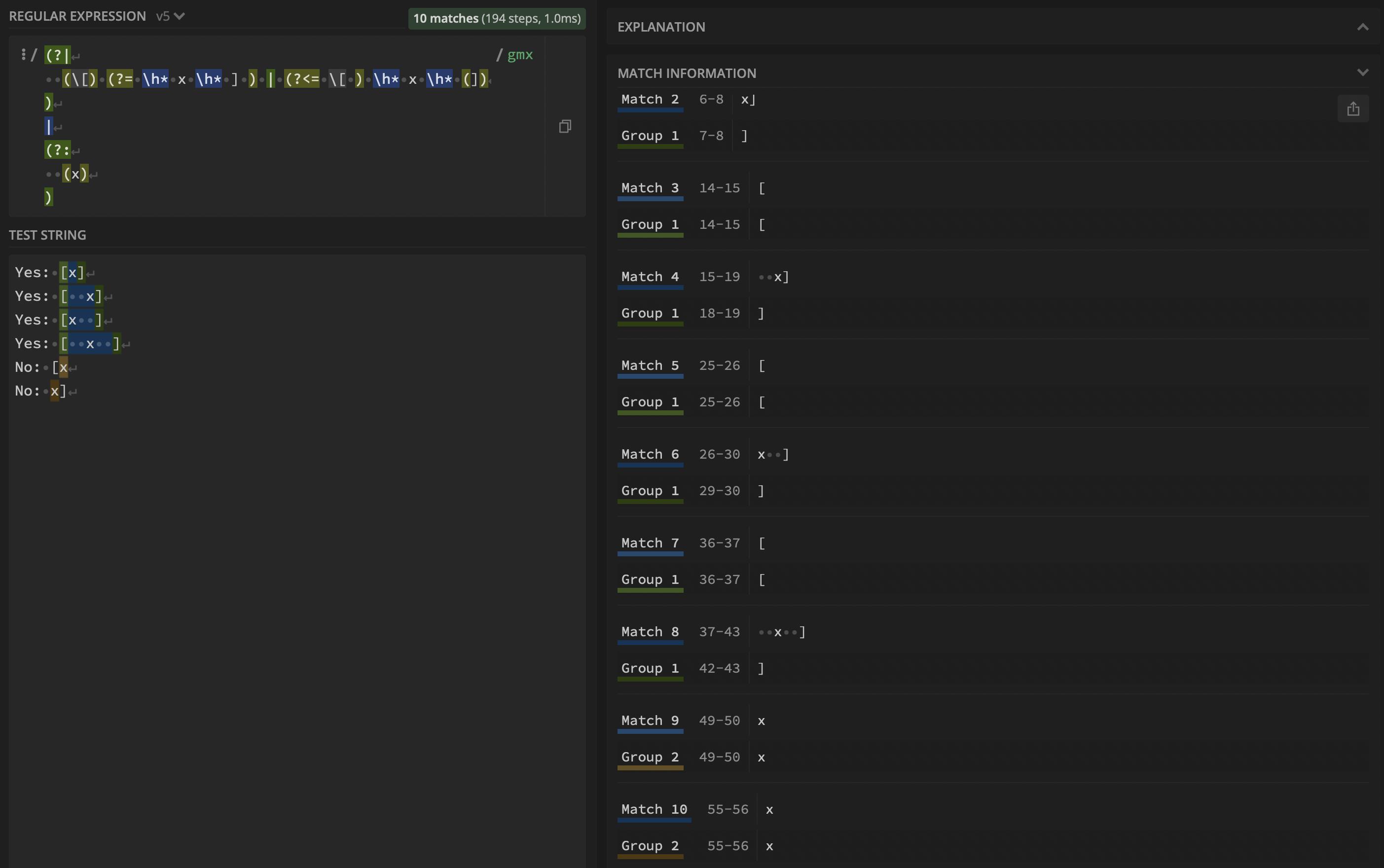
因此,我想我應該以某種方式$0從第一個運算式中重置組匹配。所以我嘗試將\K元轉義添加到之前的第一個運算式中(]),但這并沒有解決任何問題。
此外,我想盡可能地堅持這種格式,(?|regex)|(?:regex)|...因為我希望能夠進一步擴展其他組的表達方式。我正在使用Oniguruma 正則運算式和PCRE味道。您對如何實作這一目標有任何想法嗎?
PS如果問題的標題不完全準確,請道歉。
uj5u.com熱心網友回復:
主要問題是第一個選項中的部分x已經被消耗\h*x\h*(]),而\h*(x)在第二個選項中不能重新匹配已經消耗的部分。
如果您將第二個交替放在前瞻中的分支重置組中,您可以“釋放”x第二個選擇來捕捉它:
(?|
(\[) (?= \h* x \h* ] ) | (?<= \[ )(?= \h* x \h* (])) # <--- here
)
|
(?:
(?<= \[ ) \h* (x) (?= \h* ] )
)
請參閱正則運算式演示。注意(?=\h*x\h*(]))部分:現在是正向前瞻,只在右邊立即檢查其模式匹配,但不將匹配的文本放入匹配值緩沖區,也不推進正則運算式索引,以便后續子模式可以嘗試將他們的模式與此文本相匹配。
為了適應更多的替代方案,請確保使用此技術:嘗試盡可能接近字串的開頭進行匹配,并且只使用不需要重新匹配的文本,否則,使用正向前瞻并在其中捕獲組。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/383631.html
標籤:正则表达式 regex-lookarounds 聚氯乙烯 正则表达式组
上一篇:捕獲一個模式的多個實體