??一周以后就是圣誕節啦,作為程式猿的你,……
??好了,前言結束(哈哈哈自行腦補),下面是代碼:
ps: 所有素材掩碼已經打包好,文末領取
??
1 依賴庫安裝
??程式用到了wordcloud、PIL、numpy、jieba四個庫,缺啥裝啥:
pip install wordcloud
pip install PIL
pip install numpy
pip install jieba
??安裝完成后,就可以開始生成詞云了,下面的示例都是小紅帽這個故事,其中中文版小紅帽故事是直接通過百度翻譯獲得的,存在少許錯別字,但是對最終結果影響不大,
??
2 英文詞云
??英文詞云的生成比較簡單,不需要額外的分詞及停用詞,代碼如下:
from wordcloud import WordCloud
import PIL.Image as image
import numpy as np
# 一些變數值,依據自己實際情況進行設定
edcoding_type = "utf-8" # 編碼方式
background_color = "white" # 生成圖片的背景顏色
txt_path = "little red-cap.txt" # 文本路徑
mask_path = "mask.png" # 詞云形狀掩碼路徑
img_path = "red-cap_wordcloud.png" # 輸出生成的詞云圖片路徑
max_words = 200 # 最大顯示詞數量
# 讀取文本內容
def get_txt(txtpath):
with open(txtpath, encoding = edcoding_type) as f:
text = f.read()
return text
# 生成詞云
def generate_wordcloud(wordlist, maskpath, backgroundcolor, maxwords):
mask = np.array(image.open(maskpath)) # 設定圖形掩碼
wordcloud = WordCloud(
background_color = backgroundcolor, # 設定圖片背景顏色
mask = mask, # 設定掩碼
max_words = maxwords # 設定最大顯示詞數
).generate(wordlist)
return wordcloud
text = get_txt(txt_path) # 獲取文本
word_cloud = generate_wordcloud(text, # 生成詞云
mask_path,
background_color,
max_words)
image_file = word_cloud.to_image() # 生成圖片
image_file.show() # 顯示圖片
word_cloud.to_file(img_path) # 保存生成的圖片
??生成的結果如下:
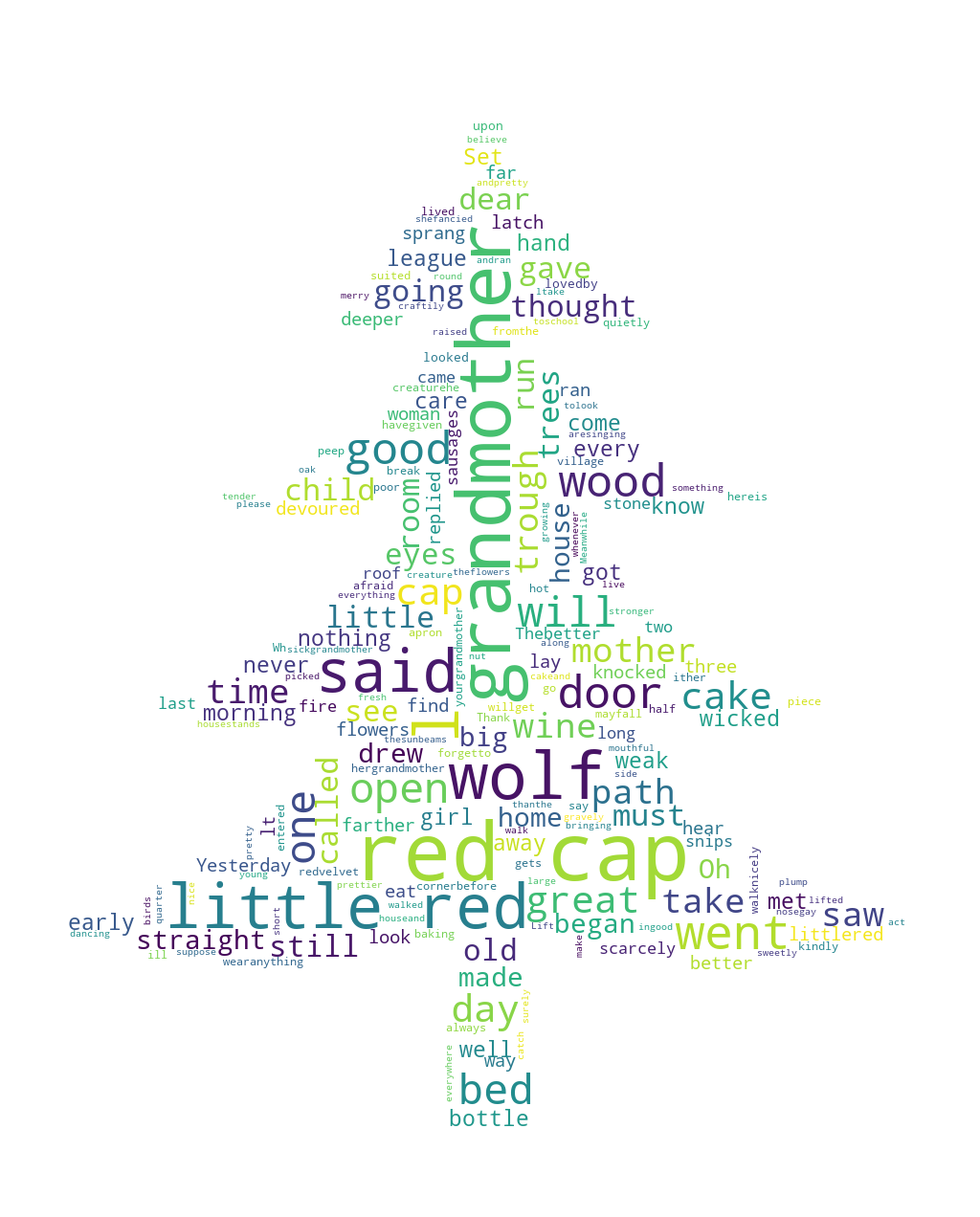
??
3 中文詞云
??中文詞云生成比較復雜,需要自己進行分詞(使用jieba),需要自己設定中文字體(這里使用黑體simhei),需要自己手動剔除停用詞(停用詞的意思就是去掉一些無意義的詞,比如“的”、“和”、“或”等等,英文里面之所以不用,是因為wordcloud自帶了有默認停用詞庫并且默認把分出的詞給過濾了),代碼如下:
from wordcloud import WordCloud
import PIL.Image as image
import numpy as np
import jieba
# 一些變數值,依據自己實際情況進行設定
edcoding_type = "utf-8" # 編碼方式
background_color = "white" # 生成圖片的背景顏色
txt_path = "小紅帽.txt" # 文本路徑
font_path = "simhei.ttf" # 字體路徑
mask_path = "mask.png" # 詞云形狀掩碼路徑
stopwords_path = "chinese_stopwords.txt" # 停用詞路徑
img_path = "小紅帽詞云.png" # 輸出生成的詞云圖片路徑
max_words = 200 # 最大顯示詞數量
# 讀取文本內容
def get_txt(txtpath):
with open(txtpath, encoding = edcoding_type) as f:
text = f.read()
return text
# 進行分詞
def cut_words(text):
words = " ".join(jieba.cut(text, cut_all = False)) # cut_all=False是精確模式
wordslist = words.split(" ") # 按空格進行分詞
return wordslist
# 讀取停用詞
def get_stopwordslist(stopwordspath):
stopwords = [line.strip() for line in open(stopwordspath, encoding = edcoding_type).readlines()]
return stopwords
# 去掉停用詞
def refined_words(wordlist, stopwordlist):
wordlistrefined = " "
for word in wordlist:
if word not in stopwordlist:
if word != '\t':
wordlistrefined += word
wordlistrefined += " "
return wordlistrefined
# 生成詞云
def generate_wordcloud(wordlist, maskpath, fontpath, backgroundcolor, maxwords):
mask = np.array(image.open(maskpath)) # 設定圖形掩碼
wordcloud = WordCloud(
font_path = fontpath, # 設定字體路徑
background_color = backgroundcolor, # 設定圖片背景顏色
mask = mask, # 設定掩碼
max_words = maxwords # 設定最大顯示詞數
).generate(wordlist)
return wordcloud
text = get_txt(txt_path) # 獲取文本
words_list = cut_words(text) # 獲取詞表
stop_words = get_stopwordslist(stopwords_path) # 加載停用詞表
refined_words = refined_words(words_list, stop_words) # 去掉停用詞
word_cloud = generate_wordcloud(refined_words, # 生成詞云
mask_path,
font_path,
background_color,
max_words)
image_file = word_cloud.to_image() # 生成圖片
image_file.show() # 顯示圖片
word_cloud.to_file(img_path) # 保存生成的圖片
??生成的結果如下:

??
4 資料
??資料內容如下圖:
??資料下載鏈接:wordcloud_source.zip
??
??
- 鳴謝:圣誕節到了,寫一個炫酷的圣誕樹和平安果,送給你最愛的人吧
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/386589.html
標籤:python
上一篇:Java期末(一)