??大家好,我是陳哈哈,北漂五年,相信大家和我一樣,
都有一個大廠夢,作為一名資深Java選手,深知面試重要性,接下來我準備用100天時間,基于Java崗面試中的高頻面試題,以每日3題的形式,帶你過一遍熱門面試題及恰如其分的解答,
??一路走來,隨著問題加深,發現不會的也愈來愈多,但底氣著實足了不少,相信不少朋友和我一樣,榷訓月累才是最有效的學習方式!想起高三時一個同學的座右銘:只有沉下去,才能浮上來,共勉(juan),

工地坐標:深圳
作者:胡巴
車票
- 面試題1:談談你對InnoDB和MyISAM這兩個引擎的理解吧?
- 追問:平時開發中你是怎么選擇這兩個引擎的?
- 面試題2:用過視圖么?為什么要使用視圖?
- 追問1:那視圖都有哪些優點呢?
- 面試題3:mysql里記錄貨幣用什么資料型別比較好?你們是怎么存的?
- 每日小結
??本欄目Java開發崗高頻面試題主要出自以下各技術堆疊:Java基礎知識、集合容器、并發編程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL資料庫、Redis快取、RabbitMQ訊息佇列、Linux操作技巧等,
面試題1:談談你對InnoDB和MyISAM這兩個引擎的理解吧?

一、InnoDB
??先說InnoDB吧,InnoDB 從 MySQL5.5(2010年) 版本代替 MyISAM 成為默認引擎,可以說只要玩兒過 MySQL 的,都用過InnoDB,相比MyISAM強調性能,InnoDB 側重于提供事務支持以及外部鍵等高級資料庫功能,
1、支持事務,默認的事務隔離級別為可重復讀(REPEATABLE-READ),通過MVCC(并發版本控制)來實作,
??InnoDB的
AUTOCOMMIT默認是打開的,即每條SQL陳述句會默認被封裝成一個事務,自動提交,這樣會影響速度,所以最好是把多條SQL陳述句顯示放在begin和commit之間,組成一個事務去提交,
2、使用的鎖粒度默認為行級鎖,可以支持更高的并發;當然,也支持表鎖,但不支持頁鎖,
??其實有這兩點就足以奠定InnoDB在存盤引擎中的霸主地位了,你知道的,使用場景真的太多了,
3、支持外鍵約束;外鍵約束其實降低了表的查詢速度,但是增加了表之間的耦合度,個人感覺很雞肋的功能,在我們開發中是不允許用外鍵的,表之間的關聯在業務層進行控制即可,否則投產后很可能會對功能和性能造成影響,
4、InnoDB的主鍵范圍更大,最大是MyISAM的2倍,同時,可以通過自動增長列,方法是auto_increment,
5、配合一些熱備工具可以支持在線熱備份;
6、在InnoDB中存在著緩沖管理,通過緩沖池(innodb_buffer_size),可以將部分索引和資料快取起來,加快查詢的速度;
7、對于InnoDB型別的表,其資料的物理組織形式是聚簇表,所有的資料按照主鍵來組織,資料和索引放在一塊,都位于B+樹的葉子節點上;
8、DELETE FROM table時,InnoDB不會重新建立表,而是一行一行的洗掉,其實在MySQL后臺就是給這行資料的is_delete欄位加了標識,實際不會直接清空磁盤內容,當然這也是InnoDB能通過flashback等插件快速找回誤刪資料的特性(后門兒)之一,
??不爽的是,當你洗掉一張大表后會發現磁盤空間不降反增,別驚訝,磁盤增加的那部分其實是只事務日志資訊,想詳細了解的同學可以參考我的另一篇文章《delete、truncate、drop的區別有哪些,該如何選擇》
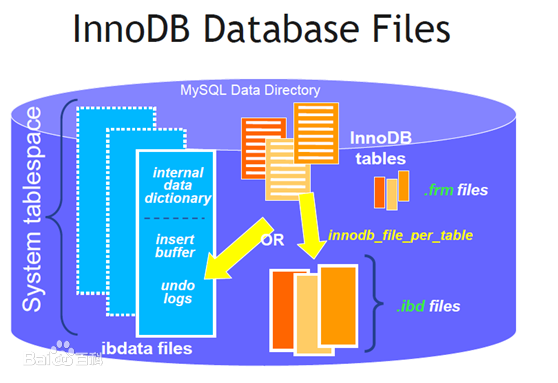
InnoDB的存盤表和索引有下面兩種形式:
- 共享表空間存盤:所有的表和索引存放在同一個表空間中,
- 多表空間存盤:表結構放在.frm檔案,資料和索引放在.ibd檔案中,磁區表的話,每個磁區對應單獨的.ibd檔案,磁區表的定義可以查看我的其他文章,使用磁區表的好處在于提升查詢效率,
- 對于
InnoDB來說,最大的優勢在于支持事務,當然這是以犧牲效率為代價的,
二、MyISAM
??還有好多同學在面試回答 InnoDB 和 MyISAM 區別的時候,依然會帶上 InnoDB 不支持全文檢索,MyISAM 支持對 BLOB 和 TEXT 的前500個字符索引云云,那是5、6年之前的答案啦,那么MyISAM有哪些特點呢?
1、不支持事務,這也算特點???沒錯,就是這么不要臉,不支持事務,像是掙脫了枷鎖,在讀寫(Insert、select)效率上,要高于InnoDB不少,場景在:日志記錄、調查統計表時,絕對值得一用,對了,不支持事務,自然就不支持鎖!
2、體積小,質量大,MyISAM的索引和資料是分開的,并且索引是有壓縮的,記憶體使用率就對應提高了不少,同時能加載更多索引,而Innodb的索引和資料是緊密捆綁的,沒有使用壓縮從而會造成 Innodb 比 MyISAM 資料檔案體積龐大很多,
每張MyISAM表在磁盤上會對應三個檔案,
- .frm檔案:存盤表的定義資料
- .MYD檔案:存放表具體記錄的資料
- .MYI檔案:存盤索引

3、從以往經驗來說,select count(*)和order by大概是使用最頻繁的,大概能占了整個sql總陳述句的60%以上的操作,而這種操作Innodb其實也是會鎖表的,很多人以為Innodb是行級鎖,那個只是where對它主鍵是有效,非主鍵的還是會鎖全表的,
當然,我也可以給where、group by、order by的欄位都加索引對吧,不用想了,就是都會加,
4、常常應用部門需要我給他們定期某些表的資料,MyISAM的話很方便,只要發給他們對應那表的(frm.MYD,MYI)的檔案,讓他們自己在對應版本的資料庫啟動就行,而Innodb就需要匯出.sql了,因為光給別人檔案,受字典資料檔案的影響,對方是無法使用的,
5、沒有where的count(*)使用MyISAM要比InnoDB快得多,的select count() 是非常快的;MyISAM內置了一個計數器,把表的總行數(row)存盤在磁盤上,當執行 select count() from t 時,直接回傳總資料,當時,當 count(*) 陳述句包含 where條件時,兩種引擎的操作流程是一樣的,
6、DELETE FROM table時,MyISAM會先將表結構備份到一張虛擬表中,然后執行drop,最后根據備份重建該表,這是我使用這兩個引擎時讓我感覺區分最明顯的特性之一,
追問:平時開發中你是怎么選擇這兩個引擎的?
- 是否要支持事務;
- 讀多寫少可以傾向 MyISAM,如果寫比較頻繁就用InnoDB,
- 系統奔潰后,MyISAM恢復起來更困難,我之前出現過表損壞情況,能否接受,不能接受選 InnoDB;
- 不知道用什么就用InnoDB,

課間休息,來記錄一下小梅同學出差西安前一天,坐標:濟南,
作者:帥玉陽
面試題2:用過視圖么?為什么要使用視圖?
??視圖是一個虛擬表,其內容由查詢定義,同真實的表一樣,視圖包含一系列帶有名稱的列和行資料,但是,視圖并不在資料庫中以存盤的資料值集形式存在,行和列資料來自由定義視圖的查詢所參考的表,并且在參考視圖時動態生成,
??視圖是存盤在資料庫中的查詢的SQL陳述句,視圖有兩個特點:
- 安全,方便控制權限,我們知道視圖是可以隱藏一些資料的,如:個稅表,可以用視圖查詢只顯示姓名,地址,而不顯示個稅號和工資數等,
- 可使復雜的查詢易于理解和使用,這個視圖就像一個視窗,從中只能看到你想看的資料列,或許你查詢一個視圖時感覺很簡單,其實這個視圖資料是通過復雜的得來的,真是紙上得來終覺淺,
??其實在我們日常作業中,公司對資料庫的管理,不僅僅細化到用戶權限這層,用戶權限下又包括用戶能訪問哪些表、那些視圖、哪些存盤程序,對于很多資料并不會公開的,因此在你們開發時,DBA同事只給你們部門分幾個視圖也是常見的事兒,
追問1:那視圖都有哪些優點呢?
1、 視圖能簡化用戶操作
??視圖機制使用戶可以將注意力集中在所關心地資料上,如果這些資料不是直接來自基本表,則可以通過定義視圖,使資料庫看起來結構簡單、清晰,并且可以簡化用戶的的資料查詢操作,例如,那些定義了若干張表連接的視圖,就將表與表之間的連接操作對用戶隱藏起來了,換句話說,用戶所作的只是對一個虛表的簡單查詢,而這個虛表是怎樣得來的,用戶無需了解,
2、 視圖使用戶能以多種角度看待同一資料
??視圖機制能使不同的用戶以不同的方式看待同一資料,當許多不同種類的用戶共享同一個資料庫時,這種靈活性是非常必要的,
??例如,Student表涉及全校15個院系學生資料,可以在其上定義15個視圖,每個視圖只包含一個院系的學生資料,并只允許每個院系的主任查詢和修改本原系學生視圖,
??一般是這樣做的:創建一個視圖,定義好該視圖所操作的資料,之后將用戶權限與視圖系結,這樣的方式是使用到了一個特性:grant陳述句可以針對視圖進行授予權限給不同的用戶使用,
3、 視圖對重構資料庫提供了一定程度的邏輯獨立性
??資料的物理獨立性是指用戶的應用程式不依賴于資料庫的物理結構,資料的邏輯獨立性是指當資料庫重構造時,如增加新的關系或對原有的關系增加新的欄位,用戶的應用程式不會受影響,層次資料庫和網狀資料庫一般能較好地支持資料的物理獨立性,而對于邏輯獨立性則不能完全的支持,
??在關系型資料庫中,資料庫的重構造往往是不可避免的,重構資料庫最常見的是將一個基本表“垂直”地分成多個基本表,例如:將學生關系Student(ID,Sname,sex,age,class),分為SX(SID,Sname,age)和SY(SID,sex,class)兩個關系,這時原表Student為SX表和SY表自然連接的結果,如果建立一個視圖Student:
CREATE VIEW Student(SID,Sname,sex,age,class)AS SELECT SX.ID,SX.Sname,SY.sex,
SX.age,SY.class FROM Student1 SX,Student2 SY WHERE SX.SID=SY.SID;
??這樣盡管資料庫的邏輯結構改變了(變為SX和SY兩個表了),但應用程式不必修改,因為新建立的視圖定義為用戶原來的關系,使用戶的外模式保持不變,用戶的應用程式通過視圖仍然能夠查找資料,
??當然,視圖只能在一定程度上提供資料的邏輯獨立,比如由于視圖的更新是有條件的,因此應用程式中修改資料的陳述句可能仍會因為基本表構造的改變而改變,
4、安全性
??有了視圖機制,就可以在設計資料庫應用系統時,對不同的用戶定義不同的視圖,使機密資料不出現在不應該看到這些資料的用戶視圖上,這樣視圖機制就自動提供了對機密資料的安全保護功能,

課間休息,來一波我們家小哈近照~啥都要學,難道你還想穿鞋?
作者:陳小哈
面試題3:mysql里記錄貨幣用什么資料型別比較好?你們是怎么存的?
??在支付類專案中,只要涉及到錢,就是大事,稍有不注意就可能出個p0事故,這不,前段時間位元組一位同事又因一個p0事故壓力過大出了意外,惋惜,
??在MySQL中,FLOAT、DOUBLE、DECIMAL都是常用來存小數的型別,我們先看看他們各資料型別的特點:
- FLOAT:浮點型,含位元組數為4,32bit,
近似數值,尾數精度 16,數值范圍為-3.4E38~3.4E38(7個有效位) - DOUBLE:
雙精度實型,含位元組數為8,64bit數值范圍-1.7E308~1.7E308(15個有效位) - DECIMAL(x,y):數字型,128bit,
不存在精度損失,常用于銀行帳目計算,(28個有效位)
Decimal(n,m)表示數值中共有n位數,其中整數n-m位,小數m位,例:decimal(10,6),數值中共有10位數,其中整數占4位,小數占6位,
例:decimal(2,1),此時,插入資料18.8、18等會出現資料溢位錯誤的例外;插入1.23或1.2345…會自動四舍五入成1.2;插入2會自動補成2.0,以確保2位的有效長度,其中包含1位小數,
一般用decimal(18,2),長度18,保存2位小數,
??不使用float或者double的原因,是因為float和double是以二進制存盤的,所以有一定的誤差,
??比如:在資料庫中c1,c2,c3分別存盤型別是float(10,2),decimal(10,2),float型別,
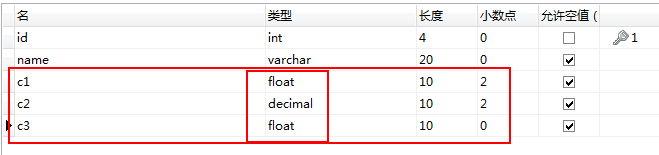
INTO test (c1,c2,c3) VALUES (1234567.23,1234567.23,1234567.23)
新增后的資料如下圖:

??可以看出,使用float型別存盤有一定的誤差,因此使用decimal(x,y)型別,其實每個公司具體情況不同,像我們公司在資料庫記錄金額時使用的是擴大10000倍的整數來存,如存1.5元時,庫中存的就是15000,不用小數來存,在業務代碼層控制轉換,個人感覺挺香的,
每日小結
??今天我們復習了面試中常問的資料庫相關問題,今天的內容你做到心中有數了么?對了,如果你的朋友也在準備面試,請將這個系列扔給他,如果他認真對待,肯定會感謝你的!!好了,今天就到這里,學廢了的同學,記得在評論區留言:打卡,,給同學們以激勵,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/389146.html
標籤:java
上一篇:java課設——租房管理系統