🚀 作者 :“大資料小禪”
🚀 粉絲福利 :加入小禪的大資料社群
🚀 歡迎小伙伴們 點贊👍、收藏?、留言💬
目錄
- python函式式編程
- lambda運算式的用法及其使用場景
- 什么是匿名函式?
- ambda運算式的基本格式
- lambda運算式的使用場景
- Python中的高階函式之map
- 函式中帶兩個引數的map函式格式
- Python中的高階函式之reduce
- Python中的高階函式之 filter
- Python中的高階函式之sorted
- 對序列做升序排序
- 對序列做降序排序
- 對存盤多個串列的串列做排序
python函式式編程
高級知識點:介紹匿名函式lambda,高階函式map,reduce,filter,sorted的使用
lambda運算式的用法及其使用場景
什么是匿名函式?
匿名函式,顧名思義就是沒有名字的函式,在程式中不用使用def進行定義,可以直接使用lambda關鍵字撰寫簡單的代碼邏輯,lambda本質上是一個函式物件,可以將其賦值給另一個變數,再由該變數來呼叫函式,也可以直接使用,**
平時,我們是先定義函式,再進行呼叫:
def power(x):
return x ** 2
print(power(2))
使用lambda運算式的時候,我們可以這樣操作
power = lambda x : x ** 2 #前面的x表示函式的一個入參,后面的是表示對入參的一個運算
print(power(2))
輸出:
4
覺得太麻煩,還可以這樣呼叫
print((lambda x: 2 * x)(8))
輸出:16
ambda運算式的基本格式
lambda 入參 : 運算式
入參可以有多個,比如
power = lambda x, n: x ** n
print(power(2, 3))
lambda運算式的使用場景
一般適用于創建一些臨時性的,小巧的函式,比如上面的 power函式,我們當然可以使用 def來定義,但使用 lambda 來創建會顯得很簡潔,尤其是在高階函式的使用中,
定義一個函式,傳入一個list,將list每個元素的值加1
def add(l = []):
return [x +1 for x in l]
print(add([1,2,3]))
輸出:
【2,3,4】
上面的函式改成將所有元素的值加2 可能大家會說,這還不簡單,直接把return里的1改成2就行了,但是真的行嗎?如果函式被多個地方使用,而其他地方并不想加2,怎么辦?這好辦,把變得那部分抽出來,讓呼叫者自己傳.
def add(func,l = []):
return [func(x) for x in l]
def add1(x):
return x+1
def add2(x):
return x+2
print(add(add1,[1,2,3]))
print(add(add2,[1,2,3]))
輸出:
[2, 3, 4]
[3, 4, 5]
一個簡簡單單的問題,一定要用這么多代碼實作?
def add(func,l = []):
return [func(x) for x in l]
print(add(lambda x:x+1,[1,2,3]))
print(add(lambda x:x+2,[1,2,3]))
Python中的高階函式之map
*map的基本格式 map(func, iterables)
map()函式接收兩個以上的引數,開頭一個是函式,剩下的是序列,將傳入的函式依次作用到序列
的每個元素,并把結果作為新的序列回傳,也就是類似map(func,[1,2,3])
同樣的,我們還是來完成這樣一個功能:將list每個元素的值加1
def add(x):
return x + 1
result = map(add, [1, 2, 3, 4]) #等于是對后面的序列都執行了add的操作
print(type(result))
print(list(result)) #不加這個list進行轉化的話會輸出:<map object at 0x000002168C98EDC8>
輸出:
<class 'map'>
[2, 3, 4, 5]
使用lambda運算式簡化操作
result = map(lambda x: x + 1, [1, 2, 3, 4])
print(type(result))
print(list(result))
函式中帶兩個引數的map函式格式
使用map函式,將兩個對應位置求和,之后回傳,也就是對[1,2,3],[4,5,6]兩個序列進行操作之后,回傳結果[5,7,9],
print(list(map(lambda x, y: x + y, [1, 2, 3], [4, 5, 6])))
輸出:
[5, 7, 9]
對于兩個序列元素個數一樣的,相對好理解,如果兩個序列個數不一樣的,會不會報錯?
print(list(map(lambda x, y: x + y, [1, 2, 3], [4, 5])))
輸出:
【5,7】
我們可以看到不會報錯,但是結果以個數少的為準
Python中的高階函式之reduce
reduce函式的基本格式
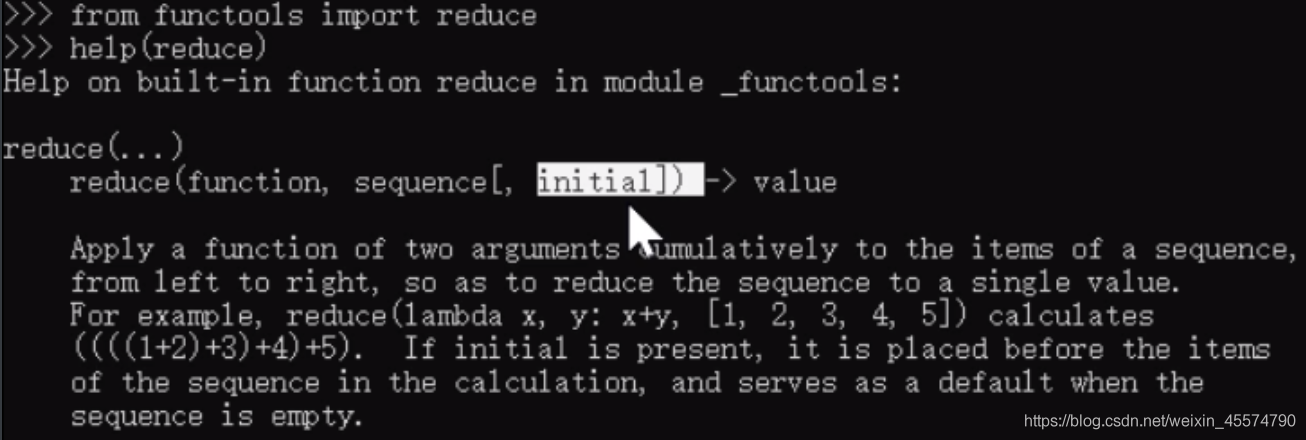
reduce(function, sequence, initial=None)
reduce把一個函式作用在一個序列上,這個函式必須接收兩個引數,reduce函式把結果繼續和序列的下一個元素做累積計算,跟遞回有點類似,reduce函式會被上一個計算結果應用到本次計算中,
reduce(func, [1,2,3]) = func(func(1, 2), 3) #意思是會先計算1跟2的結果并且運用到下一次的計算中
使用reduce函式,計算一個串列的乘積
from functools import reduce
def func(x, y):
return x * y
print(reduce(func, [1, 2, 3, 4])) #1*2,2*3,6*4
輸出:
24
from functools import reduce
def func(x, y):
return x * y
print(reduce(func, [1, 2, 3, 4],2)) #后面的那個2是初始值,不用寫initial=2,直接寫2就好,計算的結果是48,計算程序,初始值2會先跟1相乘,之后結果2跟2相乘,依次累加
結合lambda運算式,簡化操作
from functools import reduce
print(reduce(lambda x, y: x * y, [1, 2, 3, 4]))
Python中的高階函式之 filter
filter顧名思義是過濾的意思,帶有雜質的(非需要的資料),經過filter處理之后,就被過濾掉,
filter函式的基本格式
filter(function_or_None, iterable)
filter()接收一個函式和一個序列,把傳入的函式依次作用于每個元素,然后根據回傳值是**
True還是False決定保留還是丟棄該元素,
使用filter函式對給定序列進行操作,最后回傳序列中所有偶數
print(list(filter(lambda x: x % 2 == 0, [1, 2, 3, 4, 5])))
輸出:
【2,4】
Python中的高階函式之sorted
orted從字面上就可以看去這是個用來拍序的函式,sorted 可以對所有可迭代的物件進行排序操作
sorted的基本格式:
sorted(iterable, key=None, reverse=False)
iterable -- 可迭代物件,
key -- 主要是用來進行比較的元素,只有一個引數,具體的函式的引數就是取自于可迭代物件中,指
定可迭代物件中的一個元素來進行排序,
reverse -- 排序規則,reverse = True 降序 , reverse = False 升序(默認),
對序列做升序排序
print(sorted([1, 6, 4, 5, 9]))
對序列做降序排序
print(sorted([1, 6, 4, 5, 9], reverse=True))
對存盤多個串列的串列做排序
data = [["Python", 99], ["c", 88]]
print(sorted(data, key=lambda item: item[1])) #item: item[1])定位到后面那個數字,根據后面那個數字進行排序,不指定的話就是按照第一個數字的大小進行排序,key=lambd這樣子就表示把這個大的串列中的小的一個串列,作為item,去傳入我們的匿名運算式,item不是關鍵字,可以更改
#輸出:
[['c', 88], ['Python', 99]]
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/389171.html
標籤:python