目錄
一、資料集介紹
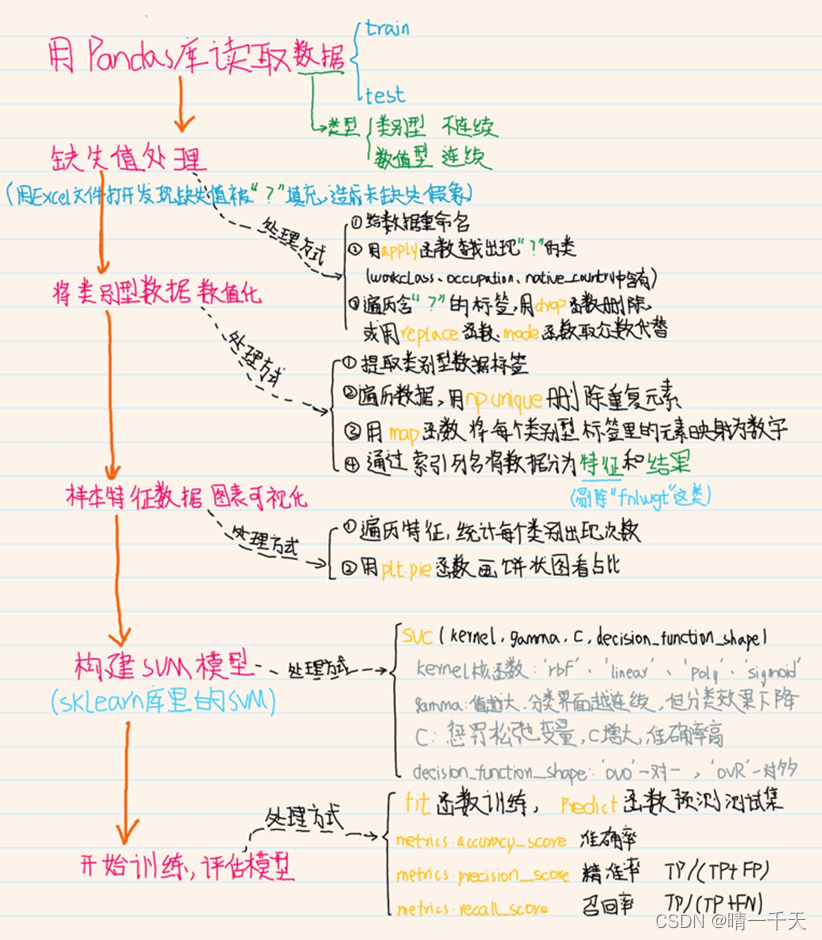
二、代碼思維導圖:
三、代碼實作
1.匯入庫包,讀取訓練集和測驗集資料
2.缺失值處理
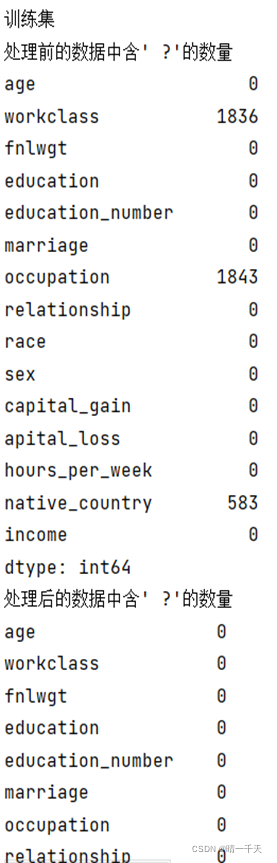
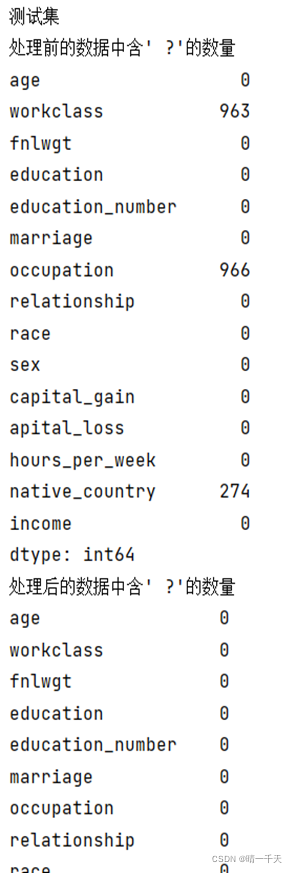
缺失值展示:
3.類別型特征數值化
4.樣本資料特征可視化
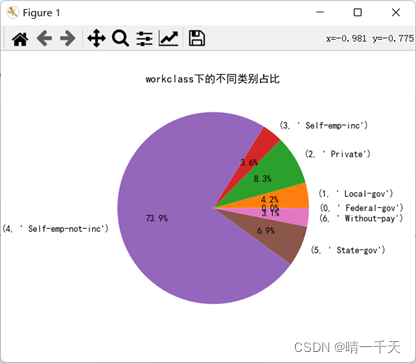
可視化展示:
5.構建svm模型
不同c值和gamma值結果展示:
6.評估模型
評估展示:
?
文章參考:
一、資料集介紹
該資料從美國1994年人口普查資料庫中抽取而來,因此也稱作“人口普查收入”資料集,共包含48842條記錄,年收入大于50k$的占比23.93%,年收入小于50k$的占比76.07%,資料集已經劃分為訓練資料32561條和測驗資料16281條,
14個屬性變數具體介紹如下:
| 屬性名 | 型別 | 含義 |
| age | continuous | 年齡 |
| workclass | discrete | 作業類別 |
| fnlwgt | continuous | 序號 |
| education | discrete | 受教育程度 |
| education-num | continuous | 受教育時間 |
| marital-status | discrete | 婚姻狀況 |
| occupation | discrete | 職業 |
| relationship | discrete | 社會角色 |
| race | discrete | 種族 |
| sex | discrete | 性別 |
| capital-gain | continuous | 資本收益 |
| capital-loss | continuous | 資本支出 |
| hours-per-week | continuous | 每周作業時間 |
| native-country | discrete | 國籍 |
下載地址:Index of /ml/machine-learning-databases/adult
二、代碼思維導圖:
平板字有些丑,將就一下?'?'? ???
三、代碼實作
1.匯入庫包,讀取訓練集和測驗集資料
import pandas as pd
import numpy as np
from sklearn import svm
from sklearn import metrics
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")#忽視警告
#匯入Adult資料
train_filepath = "E:\\Pycharm\\Data_mining\\data\\Adult\\adult.data"#訓練集
test_filepath = "E:\\Pycharm\\Data_mining\\data\\Adult\\adult.test"#測驗集
adult_data = pd.read_csv(train_filepath,header=None)
adult_test = pd.read_csv(test_filepath,header=None)
warnings.filterwarnings("ignore"):python通過呼叫warnings模塊中定義的warn()函式來發出警告,我們可以通過警告過濾器進行控制是否發出警告訊息
2.缺失值處理
#缺失值處理
def mis_value(data):
# 添加標題
# 年齡、作業型別、編號、受教育程度、受教育時長、婚姻狀況、職位、家庭關系
# 種族、性別、資本收益、資本損失、每周作業時長、原籍、收入
data.rename(columns={0: 'age',
1: 'workclass',
2: 'fnlwgt',
3: 'education',
4: 'education_number',
5: 'marriage',
6: 'occupation',
7: 'relationship',
8: 'race',
9: 'sex',
10: 'capital_gain',
11: 'apital_loss',
12: 'hours_per_week',
13: 'native_country',
14: 'income'},
inplace=True)
#檔案中缺失值用' ?'這一字串填充,造成沒有缺失值的假象
#使用lambda公式查看是否有' ?'這樣的缺失值
#得到workclass(1列)、occupation(6列)、native-country(13列)含有缺失值
print("處理前的資料中含' ?'的數量")
print(data.apply(lambda x:np.sum(x==' ?')))
#缺失值處理,由于樣本比較多,就選擇洗掉缺失值
for i in range(len(data)):
if data['workclass'][i] == ' ?':
data.drop(index=i,axis=0,inplace=True)
elif data['occupation'][i] == ' ?':
data.drop(index=i,axis=0,inplace=True)
elif data['native_country'][i] == ' ?':
data.drop(index=i, axis=0, inplace=True)
print("處理后的資料中含' ?'的數量")
print(data.apply(lambda x: np.sum(x == ' ?')))
# 缺失值處理,也可以采用眾數替換法(mode()方法取眾數)
# data.replace(['workclass',' ?'],['workclass',data['workclass'].mode()[0]])#Workclass
# data.replace(['occupation',' ?'],['occupation',data['occupation'].mode()[0]])#Occupation
# data.replace(['native_country', ' ?'], ['native_country', data['native_country'].mode()[0]])#Native country
return data
drop(labels=None, axis=0, index=None, columns=None,
level=None, inplace=False, errors='raise'):labels:一個字符或者數值,加上axis ,表示帶label標識的行或者列;如 (labels='A', axis=1) 表示A列
axis:axis=0表示行,axis=1表示列
columns:列名
index:表示dataframe的index, 如index=1, index=a
inplace:True表示洗掉某行后原dataframe變化,False不改變原始dataframe
缺失值展示:
3.類別型特征數值化
#將類別型的屬性轉變為數值型
def digitalization(data):
adult_clean = mis_value(data)#獲取處理缺失值后的資料
#包含作業型別、受教育程度、婚姻狀況、職位、家庭關系、種族、性別、原籍、收入
tar_col = ['workclass','education','marriage','occupation','relationship','race','sex','native_country','income']
adult_digi = pd.DataFrame()#創建dataframe存放資料
no_map = []#創建用來存取未映射前的特征標簽
for col in adult_clean.columns:
if col in tar_col:
unique_value = list(enumerate(np.unique(adult_clean[col])))#洗掉重復元素
no_map.append(list(unique_value))
dict_data = {key:value for value,key in unique_value}
adult_digi[col] = adult_clean[col].map(dict_data)#把類別型映射成數值型
else:
adult_digi[col] = adult_clean[col]
#通過索引列名構造樣本特征和結果
character = adult_digi[['age', 'workclass', 'education', 'education_number','marriage', 'occupation',
'relationship', 'race', 'sex','capital_gain','apital_loss','hours_per_week', 'native_country']]#特征
result = adult_digi[['income']]#結果
return character,result,no_map
map是python內置函式,會根據提供的函式對指定的序列做映射
map(function,iterable,...):
第一個引數接受一個函式名,后面的引數接受一個或多個可迭代的序列,回傳的是一個集合,把函式依次作用在list中的每一個元素上,得到一個新的list并回傳,
4.樣本資料特征可視化
catgory_col = ['workclass','education','marriage','occupation','relationship','race','sex','native_country']#類別型資料標簽
#樣本特征資料統計圖表可視化
def chart_visual(name,j):
col = x_train[name]#獲取特征集某列資料
lenth = np.max(col) - np.min(col) + 1 #統計特征映射到數值的個數
col_cla = np.linspace(np.max(col),np.min(col),lenth)#創建等間距陣列,便于參考
count = [] #統計不同數值出現的次數
label = []#讀取每個特征下的標簽
lab = nomap1[j]
for i in range(lenth):
count.append(np.sum(col==col_cla[i]))
label.append(lab[i])
plt.pie(count,labels=label,autopct='%.1f%%')
#解決中文不能顯示問題
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.title(name+"下的不同類別占比")
plt.show()
for j in range(len(catgory_col)):
chart_visual(catgory_col[j],j)
可視化展示:
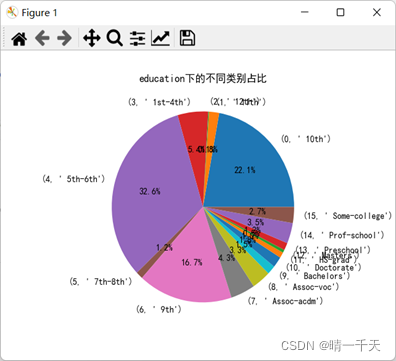
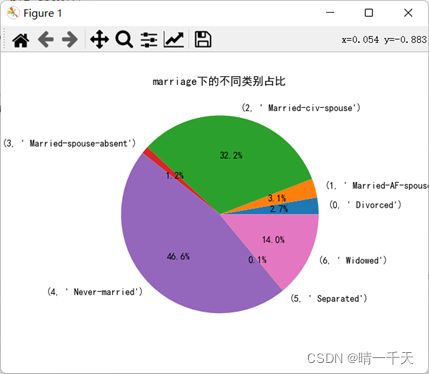
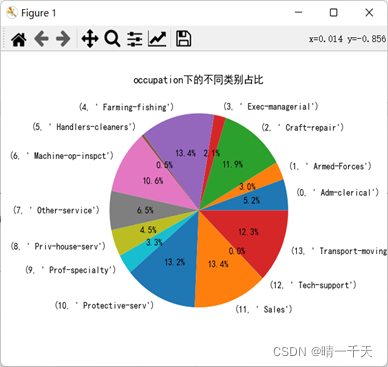
5.構建svm模型
#構建svm模型
#測驗不同gamma值下的測驗集準確率,得到當gamma=0.1時最大
# for g in range(1,7,1):
# #kenel='rbf'為高斯函式,gamma值越大,分類界面越連續;gamma值越小,分類效果越好
# #'ovo'兩兩之間進行劃分
# gamma = g/10#gamma值在0-1之間
# classify = svm.SVC(kernel='rbf',gamma=gamma,decision_function_shape='ovo',C=0.8)
# classify.fit(x_train,y_train)#開始訓練
# test_predict = classify.predict(x_test)#用訓練好的模型預測測驗集標簽
# print("gamma=" + str(gamma) + ":測驗集準確率:%.4f"%accuracy_score(y_test,test_predict))
#測驗不同c值下測驗集準確率,得到當c=0.9時最大
# for c in range(1,10,1):
# #kenel='rbf'為高斯函式,c值越大,訓練樣本準確率越高,泛化能力越低
# #'ovo'兩兩之間進行劃分
# C = c/10#C值在0-1之間
# classify = svm.SVC(kernel='rbf',gamma=0.1,decision_function_shape='ovo',C=C)
# classify.fit(x_train,y_train)#開始訓練
# test_predict = classify.predict(x_test)#用訓練好的模型預測測驗集標簽
# print("C=" + str(C) + ":測驗集準確率:%.4f"%accuracy_score(y_test,test_predict)
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
主要調節的引數有:
C、kernel、degree、gamma、coef0
C越大,相當于懲罰松弛變數,希望松弛變數接近0,即對誤分類的懲罰增大,趨向于對訓練集全分對的情況,這樣對訓練集測驗時準確率很高,但泛化能力弱,C值小,對誤分類的懲罰減小,允許容錯,將他們當成噪聲點,泛化能力較強,
kernel :核函式,默認是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
degree:多項式poly函式的維度,默認是3,選擇其他核函式時會被忽略,
gamma: ‘rbf’,‘poly’ 和‘sigmoid’的核函式引數,默認是’auto’,則會選擇1/n_features
decision_function_shape:‘ovo’, ‘ovr’ or None, default=None3
coef0:核函式的常數項,對于‘poly’和 ‘sigmoid’有用
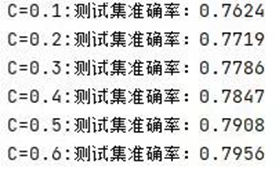
不同c值和gamma值結果展示:
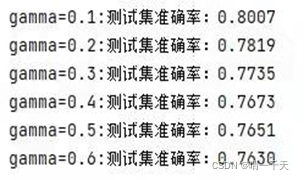
6.評估模型
classify = svm.SVC(kernel='rbf',gamma=0.1,decision_function_shape='ovo',C=0.9)
classify.fit(x_train,y_train)#開始訓練
test_predict = classify.predict(x_test)#預測測驗集
print("gamma=0.1,C=0.9:測驗集準確率:%.4f"%metrics.accuracy_score(y_test,test_predict))#正確分類的樣本數與總樣本數之比
print("gamma=0.1,C=0.9:測驗集精準率:%.4f"%metrics.precision_score(y_test,test_predict))#正確被預測的正樣本(TP)占所有被預測為正樣本(TP+FP)的比例
print("gamma=0.1,C=0.9:測驗集召回率:%.4f"%metrics.recall_score(y_test,test_predict))#正確被預測的正樣本(TP)占所有真正 正樣本(TP+FN)的比例
評估展示:

文章參考:
1.【機器學習】svm.SVC引數詳解_小蘇打的學習博客-CSDN博客_svm.svc
2.使用隨機森林與支持向量機實作Adult資料集上的分類_dianqijiaojianshuo的博客-CSDN博客
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/389174.html
標籤:python