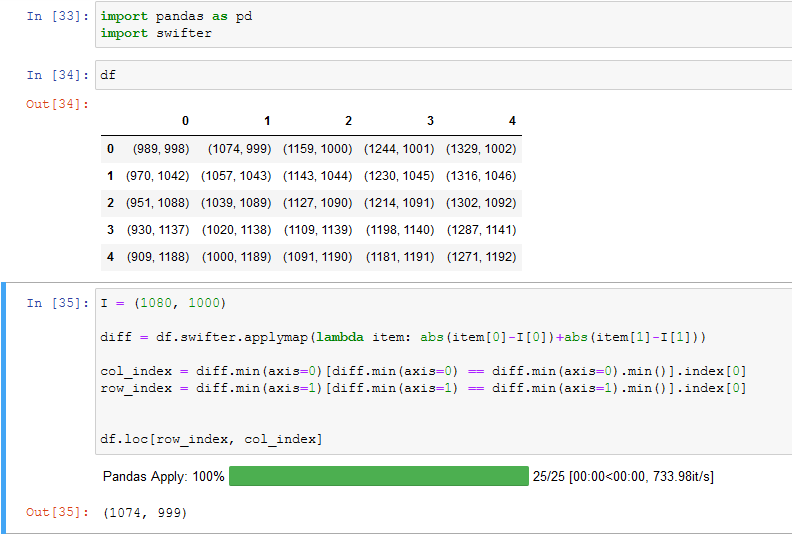
假設我有一個如下所示的資料框,
0 1 2 3 4
0 (989, 998) (1074, 999) (1159, 1000) (1244, 1001) (1329, 1002)
1 (970, 1042) (1057, 1043) (1143, 1044) (1230, 1045) (1316, 1046)
2 (951, 1088) (1039, 1089) (1127, 1090) (1214, 1091) (1302, 1092)
3 (930, 1137) (1020, 1138) (1109, 1139) (1198, 1140) (1287, 1141)
4 (909, 1188) (1000, 1189) (1091, 1190) (1181, 1191) (1271, 1192)
每個單元格在元組中有 x 和 y 坐標。我有一個名為 I 的輸入,它也是元組中的 x 和 Y 坐標。我的目標是找到輸入 I 的最近點。
樣本輸入:
(1080, 1000)
示例輸出:
(1074, 999)
我試過下面的代碼片段。
def find_nearest(array, key):
min_ = 1000
a = 0
b = 0
for item in array:
diff = abs(item[0]-key[0]) abs(item[1]-key[1])
if diff<min_:
min_ = diff
a,b = item
if diff==0:
return (a,b)
return (a,b)
find_nearest(sum(df.values.tolist(), []), I)
這給了我我所期望的。但是,對于這個問題有什么有效的解決方案嗎?
uj5u.com熱心網友回復:
嘗試:
# Setup
data = [[(989, 998), (1074, 999), (1159, 1000), (1244, 1001), (1329, 1002)],
[(970, 1042), (1057, 1043), (1143, 1044), (1230, 1045), (1316, 1046)],
[(951, 1088), (1039, 1089), (1127, 1090), (1214, 1091), (1302, 1092)],
[(930, 1137), (1020, 1138), (1109, 1139), (1198, 1140), (1287, 1141)],
[(909, 1188), (1000, 1189), (1091, 1190), (1181, 1191), (1271, 1192)]]
df = pd.DataFrame(data)
l = (1080, 1000)
out = min(df.to_numpy().flatten(), key=lambda c: (c[0]- l[0])**2 (c[1]-l[1])**2)
print(out)
# Output:
(1074, 999)
更新:
有什么辦法,我可以獲得最近元素的 df 索引?
dist = df.stack().apply(lambda c: (c[0]- l[0])**2 (c[1]-l[1])**2)
idx = dist.index[dist.argmin()]
val = df.loc[idx]
print(idx)
print(val)
# Output:
(0, 1)
(1074, 999)
更新 2
但是,對于這個問題有什么有效的解決方案嗎?
arr = df.to_numpy().astype([('x', int), ('y', int)])
dist = (arr['x'] - l[0])**2 (arr['y'] - l[1])**2
idx = tuple(np.argwhere(dist == np.min(dist))[0])
val = arr[idx] # or df.loc[idx]
uj5u.com熱心網友回復:
我寫的這個片段怎么樣?
# cordinates: np.ndarray(n, 2)
def find_nearest(cordinates, x, y):
x_d = np.abs(cordinate[:, 0] - x)
y_d = np.abs(cordinate[:, 1] - y)
nearest_idx = np.argmin(x_d y_d)
return cordinate[nearest_idx]
uj5u.com熱心網友回復:
您可以使用 swifter 和 applymap 進行更快的處理
I = (1080, 1000)
diff = df.swifter.applymap(lambda item: abs(item[0]-I[0]) abs(item[1]-I[1]))
col_index = diff.min(axis=0)[diff.min(axis=0) == diff.min(axis=0).min()].index[0]
row_index = diff.min(axis=1)[diff.min(axis=1) == diff.min(axis=1).min()].index[0]
df.loc[row_index, col_index]
uj5u.com熱心網友回復:
看起來您只需要一個兩列的 DataFrame 并找到每行和樣本坐標之間的距離。所以這是我的實作:
您的資料在復制時以字串形式出現。你實際上并不需要這一行:
data = pd.Series(df.to_numpy().flatten()).str.strip().str.strip('()').str.split(',', expand=True).astype(int)
sample = (1080, 1000)
解決方案從這里開始:
distances = data.apply(lambda x: (x[0]-sample[0])**2 (x[1]-sample[1])**2, axis=1)
out = tuple(data[distances == distances.min()].to_numpy()[0])
輸出:
(1074, 999)
uj5u.com熱心網友回復:
您可以使用
更新 2
但是,在較大的 Dataframe 中,它開始下拉:

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/389940.html
下一篇:fft和rfft之間的差異