文章目錄
- 環境準備
- 資源讀取
- 讀取圖片
- 讀取視頻
- 資源操作
- 修改圖片
- 繪制圖形
- 尺寸修改
- 灰度處理圖片
- 圖片保存
- 使用模型
- 模型訓練
- 訓練模型加載
- 手勢識別
- 純opencv版本
- mediapipe版本
- HandTrackingModule.py
- Main.py
環境準備
編輯器 pycharm
python 版本3.7x
pip3 install opencv-python
pip3 install opencv-contrib-python
基本要求:
熟練掌握 python3.x
懂得基本Pycahrm操作以及圖片基本知識
資源讀取
讀取圖片
import cv2.cv2 as cv
Image = cv.imread("Image/face1.jpg")
cv.imshow("Image",Image)
cv.waitKey(0)
cv.destroyAllWindows()
讀取視頻
import cv2
cap = cv2.VideoCapture(0)
# 0 表示讀取攝像頭
# 加入具體資源路徑就表示直接讀取路徑對應的媒體資源
while True:
flag,img = cap.read()
cv2.imshow("Vido",img)
if(cv2.waitKey(1)==ord("q")):
#cv2.waitKey(0) 表示死回圈等待
#cv2.waitKey(time)表示等待time ms 記錄用戶的輸入獲取對應的ASCII值
#這里表示等待一ms并且如果用戶輸入 q 就退出
break
資源操作
修改圖片
繪制圖形
這個在我們的圖片框選當中是很有必要的
#繪制直線
cv2.line( img , (0,0),(511,511),( 255,0,0),5)
#繪制矩形
cv2.rectangle(img,(x,y,x+w,y+h),color=(0,0,255),thickness=1) # 方框顏色,粗細 -1表示實心
#繪制圓形
cv2.circle(img,center=(x+w,y+h),radius=100,color=(255,0,0),thickness=5)
#寫字
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img , ' OpencV',(10,500), font,4,(255,255,255),2,cv.LINE_AA)
#在哪顯示,顯示字體,顯示位置(開始),字體,大小,顏色,線條粗細,什么線條(實線,虛線...)
尺寸修改
Image_resize = cv.resize(Image,dsize=(200,200))
灰度處理圖片
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
事實上
Image = cv.imread("Image/face1.jpg",0)
也可以,但是我們讀取攝像頭的時候是吧,有要處理的,
例如:
import cv2
cap = cv2.VideoCapture(0)
cap.set(3,640)
cap.set(4,480)
while True:
flag,img = cap.read()
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv2.imshow("Vido",img)
if(cv2.waitKey(1)==ord("q")):
#cv2.waitKey(0) 表示死回圈等待
#cv2.waitKey(time)表示等待time ms 記錄用戶的輸入獲取對應的ASCII值
#這里表示等待一ms并且如果用戶輸入 q 就退出
break
圖片保存
cv2.imwrite(filename,imgage)
使用模型
import cv2.cv2 as cv
import cv2.data as data
#讀取影像
img = cv.imread('Image/face1.jpg')
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_alt2.xml")
face = face_detect.detectMultiScale(gary)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.imshow('result',img)
cv.waitKey(0)
#釋放記憶體
cv.destroyAllWindows()
CascadeClassifier()就是加載
例如:
import cv2.cv2 as cv
import cv2.data as data
cap = cv.VideoCapture(0)
cap.set(3,640)
cap.set(4,480)
while True:
flag,img = cap.read()
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier(data.haarcascades + "haarcascade_frontalface_alt2.xml")
face = face_detect.detectMultiScale(gary)
for x, y, w, h in face:
cv.rectangle(img, (x, y), (x + w, y + h), color=(0, 0, 255), thickness=2)
cv.imshow("Vido",img)
if(cv.waitKey(1)==ord("q")):
#cv2.waitKey(0) 表示死回圈等待
#cv2.waitKey(time)表示等待time ms 記錄用戶的輸入獲取對應的ASCII值
#這里表示等待一ms并且如果用戶輸入 q 就退出
break
cap.release()
#釋放記憶體
cv.destroyAllWindows()
模型訓練
recognizer=cv.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids))
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
加載預測模型
這個直接看例子吧:
import os
import cv2.cv2 as cv
import numpy as np
import cv2.data as data
def getImageIds(path):
#函式作用是提取人臉然后回傳人物的人臉和id
faceseare=[] # 保存檢測出的人臉
ids=[] #
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
#人臉檢測
face_detector = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.xml")
if imagePaths:
print('訓練圖片為:',imagePaths)
else:
print("請先錄入人臉")
return
for imagePath in imagePaths:
#二值化處理
img = cv.imread(imagePath)
img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
img_numpy=np.array(img,'uint8')#獲取圖片矩陣
faces = face_detector.detectMultiScale(img_numpy)
id = int(os.path.split(imagePath)[1].split('.')[0])
for x,y,w,h in faces:
ids.append(id)
faceseare.append(img_numpy[y:y+h,x:x+w])
print('已獲取id:', id)
return faceseare,ids
if __name__ == '__main__':
#圖片路徑
path='Image/InPutImg'
#獲取影像陣列和id標簽陣列和姓名
faces,ids=getImageIds(path)
#獲取訓練物件
recognizer=cv.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids)) #把對應的人臉和id聯系起來訓練
#保存訓練檔案
model_save = "trainer/"
if not os.path.exists(model_save):
os.makedirs(model_save)
recognizer.write('trainer/trainer.yml')
完整的例子如下:
https://blog.csdn.net/futerox/article/details/120685898
訓練模型加載
這個也是例子
使用
recogizer=cv.face.LBPHFaceRecognizer_create()#加載訓練資料集檔案
recogizer.read(‘trainer/trainer.yml’)
import cv2.cv2 as cv
import os
import cv2.data as data
recogizer=cv.face.LBPHFaceRecognizer_create()#加載訓練資料集檔案
recogizer.read('trainer/trainer.yml')
names=[]
warningtime = 0
#準備識別的圖片
def face_detect_demo(img):
global warningtime
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detector=cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.xm")
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人臉識別
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
if confidence > 80: #評分越大可信度越低
warningtime += 1
if warningtime > 100:
warningtime = 0
print("未識別出此人") #這塊的話其實可以再搞一套對應的懲罰機制
cv.putText(img, 'unkonw', (x + 10, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
#這里也對應一套識別后的機制
cv.putText(img,str(names[ids-1]), (x + 10, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv.imshow('result',img)
def get_name(names):
path = 'Image/InPutImg/'
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
cap=cv.VideoCapture(0)
get_name(names)
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv.waitKey(10): #按下空格關了
break
cap.release()
cv.destroyAllWindows()
手勢識別
純opencv版本
這個的話有點超綱了,在本篇博文,其實寫這篇博文的目的還是翻筆記的時候找到了這篇筆記,順便整理一下,其實就是那篇
分分鐘自制人臉識別(如何快速識別心儀的小姐姐~)
的邊角料
但是,突然想到最近那個手勢識別比較火,那就來一下唄,識別你的手勢是哪個數字,識別1~5
這個原理如下:
1.選擇手勢區域,我們這個比較那啥需要選定一個區域來放置我們的手勢
2. 進行高斯濾波
3.之后我們就能夠通過找到手的輪廓,之后找到凹凸位置,那么這樣一來就能夠判斷你的手勢是幾
那么這個局限性也就很明顯了,我們是通過凹凸點來確定你的手勢是數字幾的,這個就有點那啥了,只能說能用,
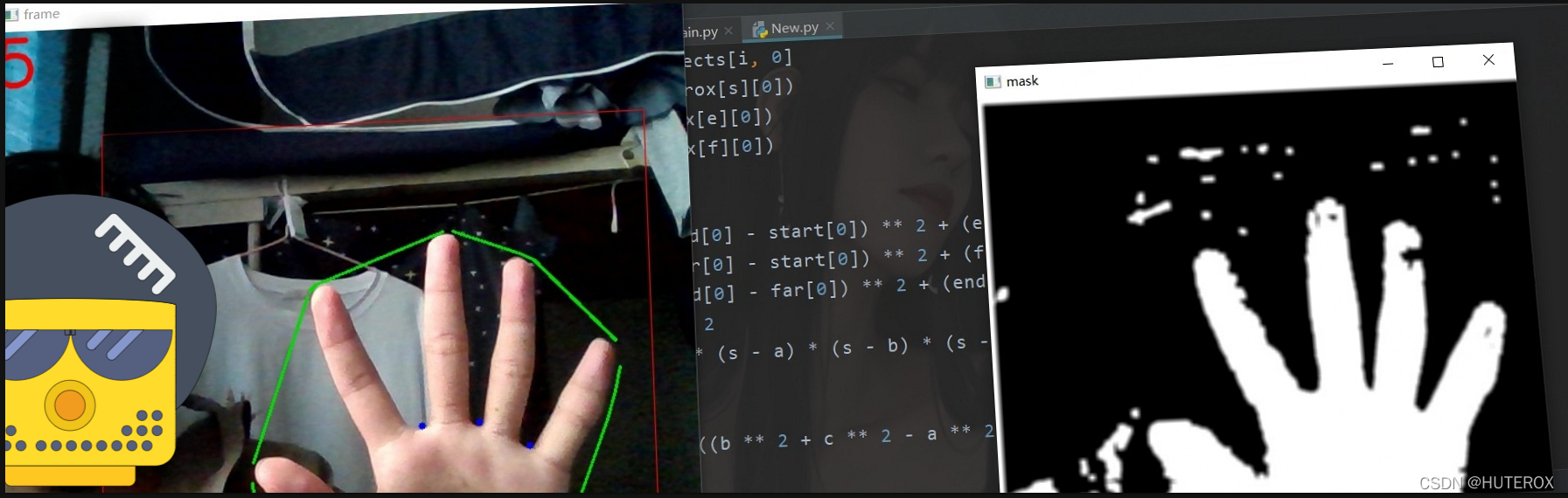
import cv2
import numpy as np
import math
cap = cv2.VideoCapture(0)
while (cap.isOpened()):
ret, frame = cap.read() # 讀取攝像頭每幀圖片
frame = cv2.flip(frame, 1)
kernel = np.ones((2, 2), np.uint8)
roi = frame[100:600, 100:600] # 選取圖片中固定位置作為手勢輸入
cv2.rectangle(frame, (100, 100), (600, 600), (0, 0, 255), 0) # 用紅線畫出手勢識別框
# 基于hsv的膚色檢測
hsv = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
lower_skin = np.array([0, 28, 70], dtype=np.uint8)
upper_skin = np.array([20, 255, 255], dtype=np.uint8)
# 進行高斯濾波
mask = cv2.inRange(hsv, lower_skin, upper_skin)
mask = cv2.dilate(mask, kernel, iterations=4)
mask = cv2.GaussianBlur(mask, (5, 5), 100)
# 找出輪廓
contours, h = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnt = max(contours, key=lambda x: cv2.contourArea(x))
epsilon = 0.0005 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
hull = cv2.convexHull(cnt)
areahull = cv2.contourArea(hull)
areacnt = cv2.contourArea(cnt)
arearatio = ((areahull - areacnt) / areacnt) * 100
# 求出凹凸點
hull = cv2.convexHull(approx, returnPoints=False)
defects = cv2.convexityDefects(approx, hull)
# 定義凹凸點個數初始值為0
l = 0
for i in range(defects.shape[0]):
s, e, f, d, = defects[i, 0]
start = tuple(approx[s][0])
end = tuple(approx[e][0])
far = tuple(approx[f][0])
pt = (100, 100)
a = math.sqrt((end[0] - start[0]) ** 2 + (end[1] - start[1]) ** 2)
b = math.sqrt((far[0] - start[0]) ** 2 + (far[1] - start[1]) ** 2)
c = math.sqrt((end[0] - far[0]) ** 2 + (end[1] - far[1]) ** 2)
s = (a + b + c) / 2
ar = math.sqrt(s * (s - a) * (s - b) * (s - c))
# 手指間角度求取
angle = math.acos((b ** 2 + c ** 2 - a ** 2) / (2 * b * c)) * 57
if angle <= 90 and d > 20:
l += 1
cv2.circle(roi, far, 3, [255, 0, 0], -1)
cv2.line(roi, start, end, [0, 255, 0], 2) # 畫出包絡線
l += 1
font = cv2.FONT_HERSHEY_SIMPLEX
# 條件判斷,知道手勢后想實作的功能
if l == 1:
if areacnt < 2000:
cv2.putText(frame, "put hand in the window", (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
else:
if arearatio < 12:
cv2.putText(frame, '0', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif arearatio < 17.5:
cv2.putText(frame, "1", (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
else:
cv2.putText(frame, '1', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 2:
cv2.putText(frame, '2', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 3:
if arearatio < 27:
cv2.putText(frame, '3', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
else:
cv2.putText(frame, '3', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 4:
cv2.putText(frame, '4', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 5:
cv2.putText(frame, '5', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
cv2.imshow('frame', frame)
cv2.imshow('mask', mask)
key = cv2.waitKey(25) & 0xFF
if key == ord('q'): # 鍵盤q鍵退出
break
cv2.destroyAllWindows()
cap.release()
此外的話還有一個版本的,這個是我在找資料的時候發現的,他這個是使用了 mediapipe 這個玩意來做的,結合opencv
mediapipe版本
參考這幾個人的博客:
https://blog.csdn.net/weixin_43654363/article/details/120809464
https://blog.csdn.net/qq_43550173/article/details/116273477
以及這個視頻(滿屏咖喱味)
https://www.bilibili.com/video/BV1V34y1Q7ka?from=search&seid=13134349602411946620&spm_id_from=333.337.0.0
這里的代碼是CV除錯之后的,原來的別人寫的代碼有點問題,我這邊除錯了,
兩個腳本
HandTrackingModule.py
import cv2
import mediapipe as mp
class HandDetector:
"""
使用mediapipe庫查找手,匯出地標像素格式,添加了額外的功能,
如查找方式,許多手指向上或兩個手指之間的距離,而且提供找到的手的邊界框資訊,
"""
def __init__(self, mode=False, maxHands=2,comPlexity=1, detectionCon=0.5, minTrackCon=0.5):
"""
:param mode: 在靜態模式下,對每個影像進行檢測
:param maxHands: 要檢測的最大手數
:param detectionCon: 最小檢測置信度
:param minTrackCon: 最小跟蹤置信度
"""
self.mode = mode
self.maxHands = maxHands
self.detectionCon = detectionCon
self.minTrackCon = minTrackCon
self.comPlexity = comPlexity
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxHands,self.comPlexity,
self.detectionCon, self.minTrackCon)
self.mpDraw = mp.solutions.drawing_utils
self.tipIds = [4, 8, 12, 16, 20]
self.fingers = []
self.lmList = []
def findHands(self, img, draw=True):
"""
從影像(BRG)中找到手部,
:param img: 用于查找手的影像,
:param draw: 在影像上繪制輸出的標志,
:return: 帶或不帶圖形的影像
"""
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 將傳入的影像由BGR模式轉標準的Opencv模式——RGB模式,
self.results = self.hands.process(imgRGB)
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms,
self.mpHands.HAND_CONNECTIONS)
return img
def findPosition(self, img, handNo=0, draw=True):
"""
查找單手的地標并將其放入串列中像素格式,還可以回傳手部周圍的邊界框,
:param img: 要查找的主影像
:param handNo: 如果檢測到多只手,則為手部id
:param draw: 在影像上繪制輸出的標志,(默認繪制矩形框)
:return: 像素格式的手部關節位置串列;手部邊界框
"""
xList = []
yList = []
bbox = []
bboxInfo =[]
self.lmList = []
if self.results.multi_hand_landmarks:
myHand = self.results.multi_hand_landmarks[handNo]
for id, lm in enumerate(myHand.landmark):
h, w, c = img.shape
px, py = int(lm.x * w), int(lm.y * h)
xList.append(px)
yList.append(py)
self.lmList.append([px, py])
if draw:
cv2.circle(img, (px, py), 5, (255, 0, 255), cv2.FILLED)
xmin, xmax = min(xList), max(xList)
ymin, ymax = min(yList), max(yList)
boxW, boxH = xmax - xmin, ymax - ymin
bbox = xmin, ymin, boxW, boxH
cx, cy = bbox[0] + (bbox[2] // 2), \
bbox[1] + (bbox[3] // 2)
bboxInfo = {"id": id, "bbox": bbox,"center": (cx, cy)}
if draw:
cv2.rectangle(img, (bbox[0] - 20, bbox[1] - 20),
(bbox[0] + bbox[2] + 20, bbox[1] + bbox[3] + 20),
(0, 255, 0), 2)
return self.lmList, bboxInfo
def fingersUp(self):
"""
查找串列中打開并回傳的手指數,會分別考慮左手和右手
:return:豎起手指的陣列(串列),陣列長度為5,
其中,由大拇指開始數,立起標為1,放下為0,
"""
if self.results.multi_hand_landmarks:
myHandType = self.handType()
fingers = []
# Thumb
if myHandType == "Right":
if self.lmList[self.tipIds[0]][0] > self.lmList[self.tipIds[0] - 1][0]:
fingers.append(1)
else:
fingers.append(0)
else:
if self.lmList[self.tipIds[0]][0] < self.lmList[self.tipIds[0] - 1][0]:
fingers.append(1)
else:
fingers.append(0)
# 4 Fingers
for id in range(1, 5):
if self.lmList[self.tipIds[id]][1] < self.lmList[self.tipIds[id] - 2][1]:
fingers.append(1)
else:
fingers.append(0)
return fingers
def handType(self):
"""
檢查傳入的手部是左還是右
:return: "Right" 或 "Left"
"""
if self.results.multi_hand_landmarks:
if self.lmList[17][0] < self.lmList[5][0]:
return "Right"
else:
return "Left"
Main.py
import cv2
from Head.HandTrackingModule import HandDetector
class Main:
def __init__(self):
self.camera = cv2.VideoCapture(0,cv2.CAP_DSHOW)
self.camera.set(3, 640)
self.camera.set(4, 480)
def Gesture_recognition(self):
while True:
self.detector = HandDetector()
frame, img = self.camera.read()
img = self.detector.findHands(img)
lmList, bbox = self.detector.findPosition(img)
if lmList:
x_1, y_1 = bbox["bbox"][0], bbox["bbox"][1]
x1, x2, x3, x4, x5 = self.detector.fingersUp()
if (x2 == 1 and x3 == 1) and (x4 == 0 and x5 == 0 and x1 == 0):
cv2.putText(img, "2", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif (x2 == 1 and x3 == 1 and x4 == 1) and (x1 == 0 and x5 == 0):
cv2.putText(img, "3", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif (x2 == 1 and x3 == 1 and x4 == 1 and x5 == 1) and (x1 == 0):
cv2.putText(img, "4", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif x1 == 1 and x2 == 1 and x3 == 1 and x4 == 1 and x5 == 1:
cv2.putText(img, "5", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif x2 == 1 and (x1 == 0, x3 == 0, x4 == 0, x5 == 0):
cv2.putText(img, "1", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif x1 and (x2 == 0, x3 == 0, x4 == 0, x5 == 0):
cv2.putText(img, "GOOD!", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
cv2.imshow("camera", img)
if cv2.getWindowProperty('camera', cv2.WND_PROP_VISIBLE) < 1:
break
if cv2.waitKey(1)==ord("q"):
break
if __name__ == '__main__':
Solution = Main()
Solution.Gesture_recognition()
效果
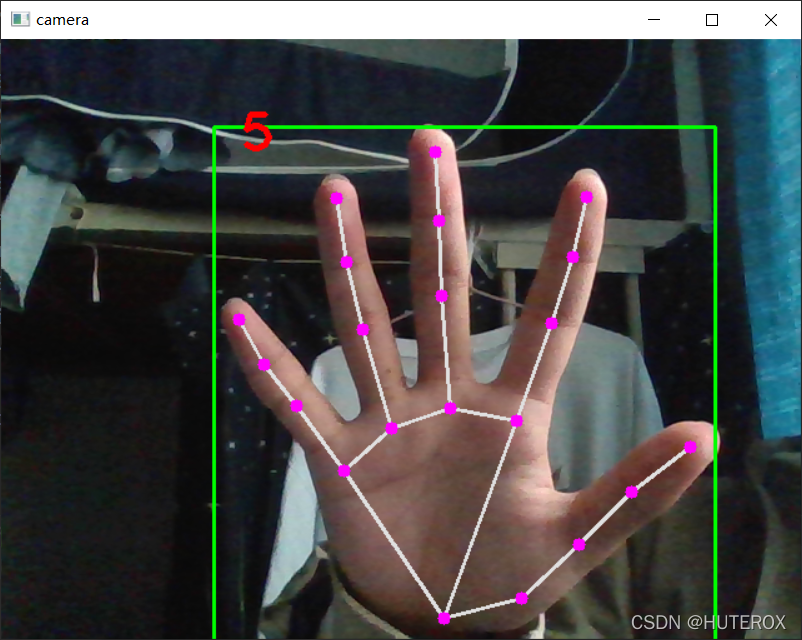
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/393151.html
標籤:python