大家好,在之前文章中,我們介紹了很多 Python 用法,喜歡的朋友可以看一下歷史文章,今天我給大家講講lambda與pandas模塊配合使用方法,熟練掌握可以極大地提高資料分析與挖掘的效率 ,
注:文末提供技術交流群
資料推薦
- 年侄訓總:20份可視化大屏模板,直接套用真香(文末附原始碼)
- 終于盼到了,Python 資料科學速查表中文版來了
- 李航老師《統計學習方法(第二版)》課件 & 演算法代碼全公開了
匯入模塊與讀取資料
我們第一步需要匯入模塊以及資料集
import pandas as pd
df = pd.read_csv("IMDB-Movie-Data.csv")
df.head()
創建新的列
一般我們是通過在現有兩列的基礎上進行一些簡單的數學運算來創建新的一列,例如
df['AvgRating'] = (df['Rating'] + df['Metascore']/10)/2
但是如果要新創建的列是經過相當復雜的計算得來的,那么lambda方法就很多必要被運用到了,我們先來定義一個函式方法
def custom_rating(genre,rating):
if 'Thriller' in genre:
return min(10,rating+1)
elif 'Comedy' in genre:
return max(0,rating-1)
elif 'Drama' in genre:
return max(5, rating-1)
else:
return rating
我們對于不同類別的電影采用了不同方式的評分方法,例如對于“驚悚片”,評分的方法則是在“原來的評分+1”和10分當中取一個最小的,而對于“喜劇”類別的電影,則是在0分和“原來的評分-1”當中取一個最大的,然后我們通過apply方法和lambda方法將這個自定義的函式應用在這個DataFrame資料集當中
df["CustomRating"] = df.apply(lambda x: custom_rating(x['Genre'], x['Rating']), axis = 1)
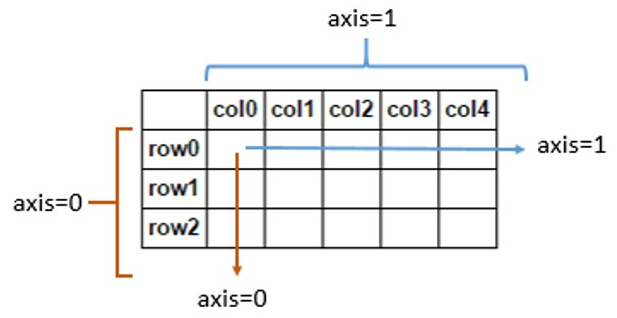
我們這里需要說明一下axis引數的作用,其中axis=1代表跨列而axis=0代表跨行,如下圖所示
篩選資料
在pandas當中篩選資料相對來說比較容易,可以用到& | ~這些運算子,代碼如下
# 單個條件,評分大于5分的
df_gt_5 = df[df['Rating']>5]
# 多個條件: AND - 同時滿足評分高于5分并且投票大于100000的
And_df = df[(df['Rating']>5) & (df['Votes']>100000)]
# 多個條件: OR - 滿足評分高于5分或者投票大于100000的
Or_df = df[(df['Rating']>5) | (df['Votes']>100000)]
# 多個條件:NOT - 將滿足評分高于5分或者投票大于100000的資料排除掉
Not_df = df[~((df['Rating']>5) | (df['Votes']>100000))]
這些都是非常簡單并且是常見的例子,但是要是我們想要篩選出電影的影名長度大于5的部分,要是也采用上面的方式就會報錯
df[len(df['Title'].split(" "))>=5]
output
AttributeError: 'Series' object has no attribute 'split'
這里我們還是采用apply和lambda相結合,來實作上面的功能
#創建一個新的列來存盤每一影片名的長度
df['num_words_title'] = df.apply(lambda x : len(x['Title'].split(" ")),axis=1)
#篩選出影片名長度大于5的部分
new_df = df[df['num_words_title']>=5]
當然要是大家覺得上面的方法有點繁瑣的話,也可以一步到位
new_df = df[df.apply(lambda x : len(x['Title'].split(" "))>=5,axis=1)]
例如我們想要篩選出那些影片的票房低于當年平均水平的資料,可以這么來做,
我們先要對每年票房的的平均值做一個歸總,代碼如下
year_revenue_dict = df.groupby(['Year']).agg({'Revenue(Millions)':np.mean}).to_dict()['Revenue(Millions)']
然后我們定義一個函式來判斷是否存在該影片的票房低于當年平均水平的情況,回傳的是布林值
def bool_provider(revenue, year):
return revenue<year_revenue_dict[year]
然后我們通過結合apply方法和lambda方法應用到資料集當中去
new_df = df[df.apply(lambda x : bool_provider(x['Revenue(Millions)'],x['Year']),axis=1)]
我們篩選資料的時候,主要是用.loc方法,它同時也可以和lambda方法聯用,例如我們想要篩選出評分在5-8分之間的電影以及它們的票房,代碼如下
df.loc[lambda x: (x["Rating"] > 5) & (x["Rating"] < 8)][["Title", "Revenue (Millions)"]]
轉變指定列的資料型別
通常我們轉變指定列的資料型別,都是呼叫astype方法來實作的,例如我們將“Price”這一列的資料型別轉變成整型的資料,代碼如下
df['Price'].astype('int')
會出現如下所示的報錯資訊
ValueError: invalid literal for int() with base 10: '12,000'
因此當出現類似“12,000”的資料的時候,呼叫astype方法實作資料型別轉換就會報錯,因此我們還需要將到apply和lambda結合進行資料的清洗,代碼如下
df['Price'] = df.apply(lambda x: int(x['Price'].replace(',', '')),axis=1)
方法呼叫程序的可視化
有時候我們在處理資料集比較大的時候,呼叫函式方法需要比較長的時間,這個時候就需要有一個要是有一個進度條,時時刻刻向我們展示資料處理的進度,就會直觀很多了,
這里用到的是tqdm模塊,我們將其匯入進來
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
然后將apply方法替換成progress_apply即可,代碼如下
df["CustomRating"] = df.progress_apply(lambda x: custom_rating(x['Genre'],x['Rating']),axis=1)
output

當lambda方法遇到if-else
當然我們也可以將if-else運用在lambda自定義函式當中,代碼如下
Bigger = lambda x, y : x if(x > y) else y
Bigger(2, 10)
output
10
當然很多時候我們可能有多組if-else,這樣寫起來就有點麻煩了,代碼如下
df['Rating'].apply(lambda x:"低分電影" if x < 3 else ("中等電影" if x>=3 and x < 5 else("高分電影" if x>=8 else "值得觀看")))
看上去稍微有點凌亂了,這個時候,小編這里到還是推薦大家自定義函式,然后通過apply和lambda方法搭配使用,
技術交流
歡迎轉載、收藏、有所識訓點贊支持一下!

目前開通了技術交流群,群友已超過2000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友
- 方式①、發送如下圖片至微信,長按識別,后臺回復:加群;
- 方式②、添加微信號:dkl88191,備注:來自CSDN
- 方式③、微信搜索公眾號:Python學習與資料挖掘,后臺回復:加群

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/393935.html
標籤:python
上一篇:對圓和橢圓進行邊緣檢測