Python資料結構與演算法(1.7)——演算法分析
- 0. 學習目標
- 1. 演算法的設計要求
- 1.1 演算法評價的標準
- 1.2 演算法選擇的原則
- 2. 演算法效率分析
- 2.1 大 O O O 表示法
- 2.2 常見演算法復雜度
- 2.3 復雜度對比
- 3. 演算法的存盤空間需求分析
- 4. Python內置資料結構性能分析
- 4.1 串列性能分析
- 4.2 字典性能分析
0. 學習目標
我們已經知道演算法是具有有限步驟的程序,其最終的目的是為了解決問題,而根據我們的經驗,同一個問題的解決方法通常并非唯一,這就產生一個有趣的問題:如何對比用于解決同一問題的不同演算法?為了以合理的方式提高程式效率,我們應該知道如何準確評估一個演算法的性能,
通過本節學習,應掌握以下內容:
- 了解演算法分析的重要性
- 能夠熟練使用大 O O O 表示法分析演算法的時間復雜度
- 掌握空間復雜度分析方法
- 了解 Python 串列和字典常見操作的時間復雜度
1. 演算法的設計要求
演算法分析的主要目標是從運行時間和記憶體空間消耗等方面比較演算法,
1.1 演算法評價的標準
一個好的演算法首先應該是“正確”的,其對于每個輸入實體均能終止并給出正確的結果,能夠正確解決給定的計算問題,此外,還需要考慮以下方面:
- 高效性:執行演算法所需要的時間;
- 低存盤量:執行演算法所耗費的存盤空間,其中主要考慮輔助存盤空間;
- 可讀性:演算法應易于理解,易于編碼,易于除錯等等,
1.2 演算法選擇的原則
一個演算法同時可以滿足存盤空間小、運行時間短、其它性能也好是很難做到的,很多情況下,我們不得不對性能進行取舍,在實際選擇演算法時,我們通常遵循以下原則:
- 若該程式使用次數較少,則力求演算法簡明易懂;
- 對于反復多次使用的程式,應盡可能選用快速的演算法;
- 若待解決的問題資料量極大,機器的存盤空間較小,則相應演算法主要考慮如何節省空間,
2. 演算法效率分析
演算法效率分析根據演算法執行所需的時間進行分析和比較,這也稱為演算法的執行時間或運行時間,要衡量演算法的執行時間,一個方法就是做基準分析,這是一種事后統計的方法,其使用絕對的時間單位來記錄程式計算出結果所消耗的實際時間,在 Python 中,可以使用 time 模塊的 time 函式記錄程式的開始時間和結束時間,然后計算差值,就可以得到以秒為單位的演算法執行時間,
以計算斐波那契數列第 n 項為例(斐波那契數列從第3項開始,每一項都等于前兩項之和),在計算斐波那契數列第 n 項前后呼叫 time 函式,計算執行時間:
import time
def fibo(n):
start = time.time()
a, b = 1, 1
if n > 2:
for i in range(n-2):
a, b = b, a + b
end = time.time()
running = end-start
return b, running
for i in range(5):
results = fibo(100000)
print('It takes {:.8f} seconds to calculate the 10000th item of Fibonacci sequence'.format(results[1]))
代碼執行結果如下:
It takes 0.08275080 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08277822 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08176851 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08178067 seconds to calculate the 10000th item of Fibonacci sequence
It takes 0.08081150 seconds to calculate the 10000th item of Fibonacci sequence
但是這種方法計算的是執行演算法的實際時間,有兩個明顯的缺陷:1) 必須先運行依據演算法編制的程式;2) 依賴于特定的計算機、編譯器與編程語言等軟硬件環境,容易掩蓋演算法本身的優劣,因此,我們希望找到一個獨立于程式或計算機的指標,以用來比較不同實作下的演算法,
2.1 大 O O O 表示法
為了擺脫與計算機硬體、軟體有關的因素,我們需要一種事前分析估算的方法,可以認為特定演算法的“運行作業量”大小取決于問題的規模,或者說,它是問題規模的函式,這時我們就需要量化演算法的操作或步驟,一個演算法是由控制結構和基本操作構成的,因此可以將演算法的執行時間描述成解決問題所需重復執行的基本運算元,需要注意的是,確定合適的基本操作取決于不同的演算法,例如在計算斐波那契數列第 n 項時,賦值陳述句就是一個基本操作,而在計算矩陣乘法時,乘法運算則是其基本操作,
在上一節的 fibo 函式中,整個演算法的執行時間與基本操作(賦值)重復執行的次數n 成正比,具體而言是 1 加上 n-2 個賦值陳述句,如果使用將其定義為函式可以表示為
T
(
n
)
=
n
?
1
T(n)=n-1
T(n)=n?1,其中
n
n
n 為大于 2 的正整數,
n
n
n 常用于表示問題規模,我們可以使用問題規模
n
n
n 的某個函式
f
(
n
)
f(n)
f(n) 表示演算法中基本操作重復執行的次數,演算法的時間量度可以表示如下:
T
(
n
)
=
O
(
f
(
n
)
)
T(n)=O(f(n))
T(n)=O(f(n))
隨問題規模
n
n
n 的增大,
T
(
n
)
T(n)
T(n) 函式的某一部分會比其余部分增長得更快,演算法間進行比較時這一起部分起決定性作用,
T
(
n
)
T(n)
T(n) 增長最快的部分也稱為數量級函式,演算法執行時間的增長率和
f
(
n
)
f(n)
f(n) 的增長率相同,稱作演算法的漸近時間復雜度 (asymptotic time complexity),簡稱時間復雜度,數量級 (order of magnitude) 常被稱作大
O
O
O 記法或大
O
O
O 表示法,
通過以上分析,我們可以將演算法的漸近復雜度規則描述如下:
- 如果運行時間是一個多項式的和,那么僅保留增長速度最快的項,去掉其他各項;
- 如果剩下的項是個乘積,那么去掉所有常數,
假設某一演算法的基本步驟數為
T
(
n
)
=
3
n
2
+
50
n
+
2000
T(n)=3n^2+50n+2000
T(n)=3n2+50n+2000,當
n
n
n 很小時 2000 對于函式的影響最大,但是隨著
n
n
n 的增長
n
2
n^2
n2 將逐漸變得更重要,以至于可以忽略其他兩項以及
n
2
n^2
n2 的系數 3,因此可以說
T
(
n
)
T(n)
T(n) 的數量級是
n
2
n^2
n2 或寫為
O
(
n
2
)
O(n2)
O(n2),
演算法的性能有時不僅依賴問題的規模,還取決于演算法的輸入值,輸入令演算法運行最慢的情況稱為最壞情況,輸入令演算法運行最快的情況稱為最好情況,隨機輸入的情況下演算法的性能介于兩種極端情況之間,稱為平均情況,
2.2 常見演算法復雜度
下表列出了一些常見的大 O O O 表示法實體:
| 復雜度 | 解釋 | 示例 |
|---|---|---|
| O ( 1 ) O(1) O(1) | 常數復雜度 | 100, 500, 1, 30, … |
| O ( l o g n ) O(logn) O(logn) | 對數復雜度 | l o g 2 n log_2n log2?n, l o g 10 n log_{10}n log10?n, 2 l o g 2 n 2log_2n 2log2?n, … |
| O ( n ) O(n) O(n) | 線性復雜度 | 8 n + 10 8n+10 8n+10, n n n, 100 n 100n 100n, … |
| O ( n l o g n ) O(nlogn) O(nlogn) | 對數線性復雜度 | 10 n l o g n + 50 10nlogn+50 10nlogn+50, 5 n l o g n + 30 n 5nlogn+30n 5nlogn+30n, … |
| O ( n k ) O(n^k) O(nk) | 多項式復雜度,其中 k k k 為常數 | 4 n 2 ? 10 n 4n^2-10n 4n2?10n, 2 n 3 + 10 n 2 2n^3+10n^2 2n3+10n2, 4 n 2 + 5 n l o g n 4n^2+5nlogn 4n2+5nlogn, … |
| O ( c n ) O(c^n) O(cn) | 指數復雜度,其中 c c c 為常數 | 2 n + 5 n 2 2^n+5n^2 2n+5n2, 4 n + 10 n l o g n 4^n+10nlogn 4n+10nlogn, … |
2.2.1 常數復雜度
常數復雜度表示,演算法的漸進復雜度域輸入的規模無關,例如求串列的長度等都屬于常數復雜度,常數復雜度和代碼中是否包含回圈沒有必然關系,例如回圈列印 100 次 “Hello world”,這與輸入規模并沒有什么關系,因此其也是屬于常數復雜度,
2.2.2 對數復雜度
對數復雜度表示函式的增長速度至少是輸入規模的對數,當我們談論對數復雜度時,我們并不關系對數的底數,這是由于可以使用換底公式,將原來底數的對數乘以一個常數轉換為另一個底數:
l
o
g
a
n
=
l
o
g
a
b
?
l
o
g
b
n
log_an=log_ab*log_bn
loga?n=loga?b?logb?n
其中,
a
a
a 和
b
b
b 均為常數,例如以下代碼,將一個正整數轉換為字串:
def int_to_str(num):
digits = "0123456789"
result = ''
if num == 0:
result = '0'
else:
while num > 0:
result = digits[num % 10] + result
num = num // 10
return result
上述代碼中只包括一個回圈,且沒有呼叫其它函式,因此我們只需找出回圈迭代次數——在 num 為 0 之前所需的整數除法的次數 l o g 10 n log_{10}n log10?n,因此函式 int_to_str 的復雜度是 O ( l o g n ) O(logn) O(logn),
2.2.3 線性復雜度
線性復雜度在串列中等序列資料型別總十分常見,因為演算法通常需要遍歷處理序列中的每一個元素,例如將串列中的每個元素加上常數 10:
def add_constant(list_o):
for i in range(len(list_o)):
list_o[i] += 10
這個函式的復雜度就與串列的長度成線性關系,也就是 O ( n ) O(n) O(n),
2.2.4 線性對數復雜度
線性對數復雜度是兩項的乘積,每個項都依賴于輸入的規模,例如將串列中每一項正整數轉換為字串,很多實用演算法的復雜度都是對數線性的,
2.2.5 多項式復雜度
多項式復雜度的增長速度是輸入規模的 k k k 次冪,其中最常見的是平方復雜度,例如求串列 list_a 和 list_b 的交集:
def intersect(list_a, list_b):
# 第一部分
temp = []
for i in list_a:
for j in list_b:
if i == j:
temp.append(i)
break
# 第二部分
result = []
for i in temp:
if i not in result:
result.append(i)
return result
intersect 函式第一部分的復雜度顯然是
O
(
l
e
n
(
l
i
s
t
_
a
)
)
?
O
(
l
e
n
(
l
i
s
t
_
b
)
)
O(len(list\_a))*O(len(list\_b))
O(len(list_a))?O(len(list_b)),第二部分代碼用于去除第一部分得到結果串列中的重復元素,雖然其中僅包含一個回圈陳述句,但是測驗條件 if i not in result 需要檢查 result 中的每個元素,因此第二部分的復雜度為
O
(
l
e
n
(
t
e
m
p
)
)
?
O
(
l
e
n
(
r
e
s
u
l
t
)
)
O(len(temp))*O(len(result))
O(len(temp))?O(len(result)),tmp 和 result 的長度取決于 list_a 和 list_b 中長度較小的那個,根據漸進復雜度規則可以將其忽略,最終,intersect 函式的復雜度就是
O
(
n
2
)
O(n^2)
O(n2),
2.2.6 指數復雜度
指數復雜度演算法的解決時間隨輸入規模的指數增長,在以下示例中,由于 1 左移 num 位得到 end,因此 end 實際上等于 2 n u m 2^{num} 2num,因此回圈中計算了 2 n u m 2^{num} 2num 次加法,時間復雜度為 O ( 2 n ) O(2^{n}) O(2n),
def calculate(num):
result = 0
end = 1 << num
for i in range(end):
result += i
return result
2.3 復雜度對比
為了直觀的觀察到各種復雜度的增長情況,使用統計圖來對比各種復雜度演算法的運行時間增長速度,
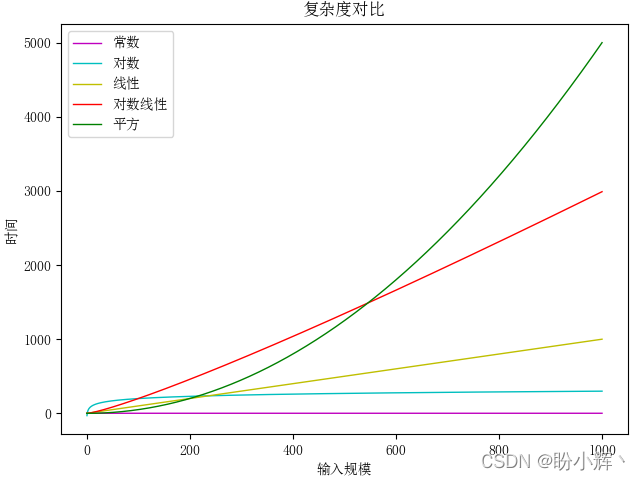
從上圖可以看出,對數復雜度隨問題規模的增長,運行時間的增長很小,幾乎和常數復雜度演算法一樣優秀,通常只有當輸入規模很大時才能直觀的看出兩者之間的差別,而線性復雜度和對數復雜度的區別在輸入規模很小時就非常明顯了,
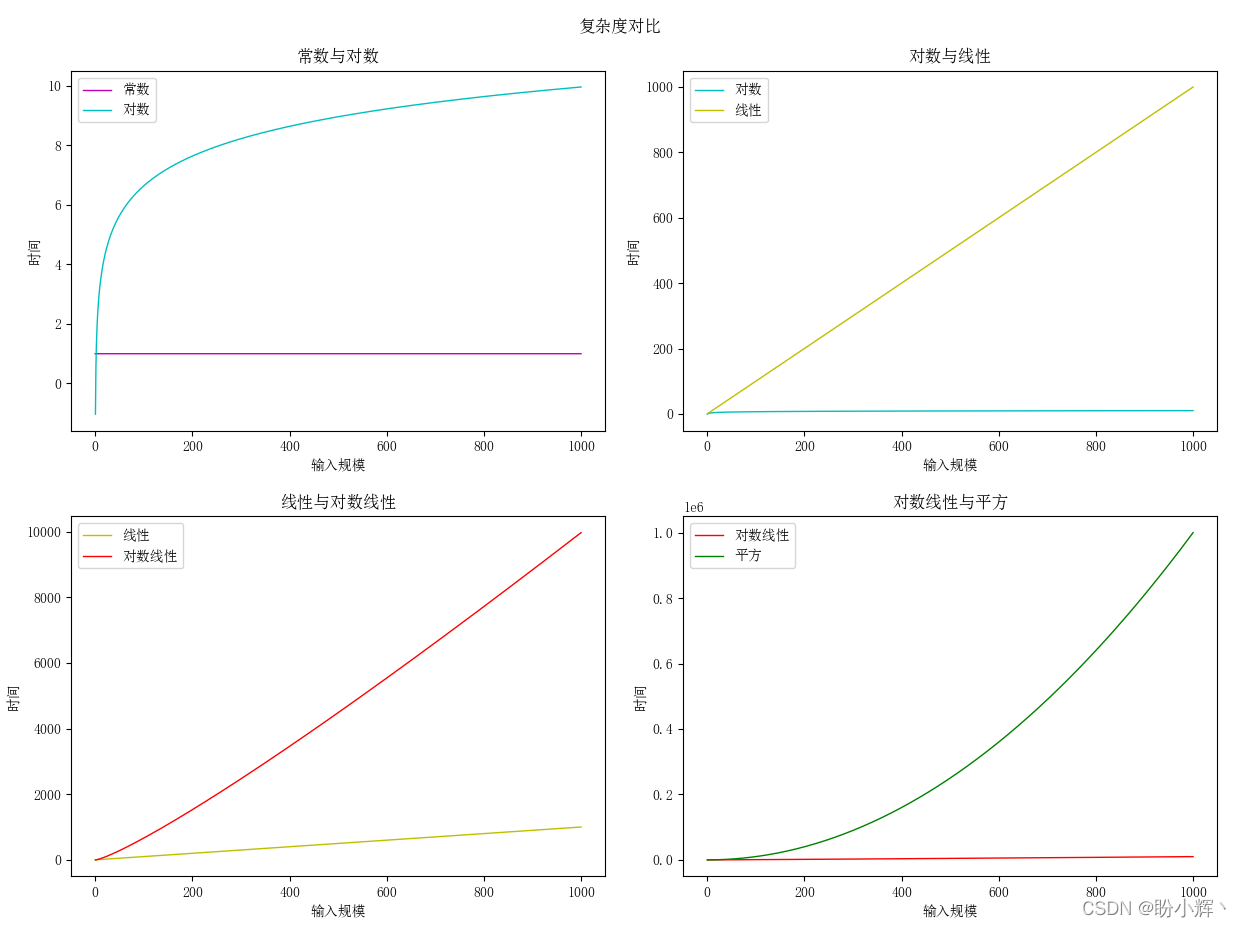
雖然
O
(
l
o
g
n
)
O(logn)
O(logn) 的增長速度很慢,但是在線性乘法因子的加持下,其增長速率高于線性復雜度,但與平方復雜度的增長速度相比,就不值一提了,因此在實際情況下,具有
O
(
n
l
o
g
n
)
O(nlogn)
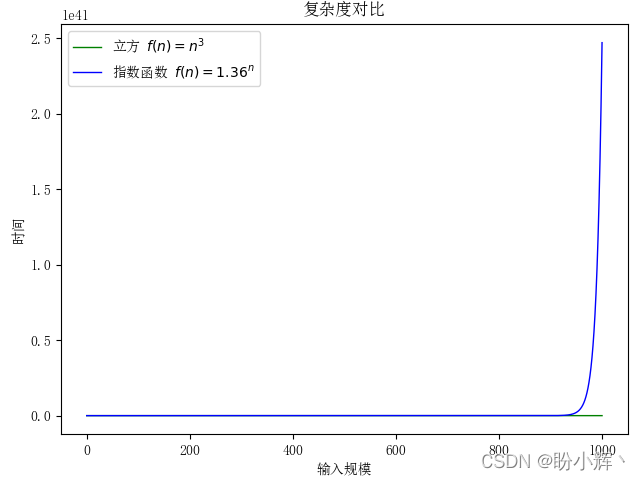
O(nlogn) 復雜度的演算法執行速度還是很快的,而指數復雜度除了對那些規模特別小的輸入,其運行時間都是不現實的,即使立方復雜度和其相比都相形見絀,
3. 演算法的存盤空間需求分析
在以上內容中討論的都是代碼的時間復雜度,這是由于,與時間復雜度相比,要想感覺到空間復雜度 (space complexity) 的影響比較困難,對于用戶來說,程式運行完成需要 1 分鐘還是 10 分鐘是明顯能夠感覺到的,但程式使用的記憶體是 1 兆位元組還是 10 兆位元組則無法直觀覺察,這也就是時間復雜度通常比空間復雜度更受關注的原因,通常只有當運行程式所需的存盤空間超過了計算機記憶體時,空間復雜度才會受到關注,
類似于演算法的時間復雜度,空間復雜度作為演算法所需存盤空間的量度,可以表示為:
S
(
n
)
=
O
(
f
(
n
)
)
S(n)=O(f(n))
S(n)=O(f(n))
一個程式的執行除了需要存盤空間來寄存本身所用指令、常數變數和輸入資料外,也需要一些輔助空間用于存盤資料處理的中間資料,若輸入資料所占空間只取決于問題本身,和演算法無關,則只需要分析除輸入和程式之外的額外空間,否則應同時考慮輸入本身所需空間,若額外空間相對于輸入資料量來說是常數,則稱此演算法為原地作業,
4. Python內置資料結構性能分析
由于在之后的學習中,我們需要經常使用串列和字典作為構建其他資料結構的基石,因此了解這些資料結構操作的時間復雜度是必要的,
4.1 串列性能分析
Python 串列常見操作的時間復雜度如下表所示:
| 操作 | 大 O O O 表示法 | 操作 | 大 O O O 表示法 |
|---|---|---|---|
| 索引及索引賦值 | O ( 1 ) O(1) O(1) | in 及 not in | O ( n ) O(n) O(n) |
| append() | O ( 1 ) O(1) O(1) | 切片 | O ( n ) O(n) O(n) |
| pop() | O ( 1 ) O(1) O(1) | 洗掉切片及切片賦值 | O ( n ) O(n) O(n) |
| pop(i) | O ( n ) O(n) O(n) | 反轉 | O ( n ) O(n) O(n) |
| insert(i, item) | O ( n ) O(n) O(n) | 連接 | O ( n ) O(n) O(n) |
| del | O ( n ) O(n) O(n) | sort() | O ( n l o g n ) O(nlogn) O(nlogn) |
| 遍歷 | O ( n ) O(n) O(n) | 乘法 | O ( n 2 ) O(n^2) O(n2) |
在串列中雖然 append() 操作和 insert() 操作都是向串列中添加一個元素,不同的是 append() 向串列末尾追加一個元素,而 insert() 在指定位置處插入元素,其后的元素都要向后移一位,因此它們的時間復雜度也不相同,
為了獲取執行時間,這里使用 timeit 模塊,該模塊能夠在一致的環境中執行函式,要使用 timeit 模塊,首先需要創建一個 Timer 物件,其接受兩個引數:第 1 個引數是要為之計時的 Python 陳述句;第 2 個引數是建立測驗的 Python 陳述句,timeit 模塊會統計多次執行陳述句要用多久,默認情況下,timeit 會執行 100 萬次陳述句,并在完成后回傳一個浮點數格式的秒數,可以給 timeit 傳入引數 number,以指定陳述句的執行次數,
import timeit
import random
append_timeit = timeit.Timer('x.append(1)', 'from __main__ import x')
insert_timeit = timeit.Timer('x.insert(0, 1)', 'from __main__ import x')
for i in range(10000, 2000000, 20000):
x = list(range(i))
# 測驗函式運行 1000 次所花的時間
append_time = append_timeit.timeit(number=1000)
x = list(range(i))
# 測驗函式運行 1000 次所花的時間
insert_time = insert_timeit.timeit(number=1000)
print("{}, {}, {}".format(i, append_time, insert_time))
在上例中,計時的陳述句是對 append 和 insert 操作的呼叫,建立測驗的陳述句是初始化代碼或構建環境匯入陳述句,是執行代碼的準備作業,示例中的 from __main__ import x 將 x 從 __main__ 命名空間匯入到 timeit 設定計時的命名空間,用于在測驗中使用串列物件 x,這么是為了在一個干凈的環境中運行計時測驗,以免某些變數以某種意外的方式干擾函式的性能,
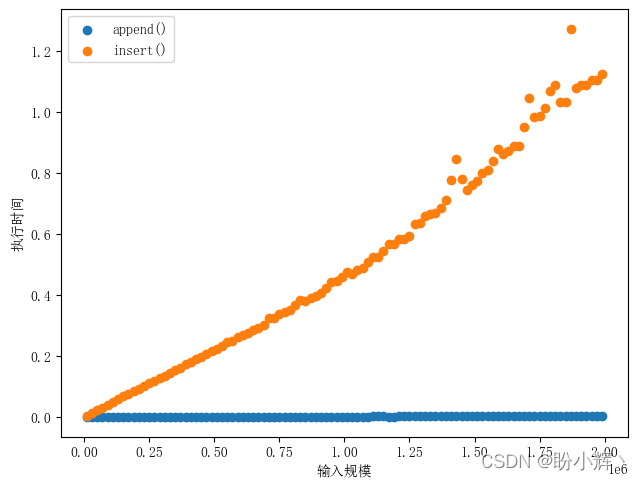
從上圖中可以看出,串列越長,insert 操作的耗時也隨之變長,而 append 操作的耗時很穩定,符合
O
(
n
)
O(n)
O(n) 和
O
(
1
)
O(1)
O(1) 的特征,
4.2 字典性能分析
Python 字典常見操作的時間復雜度如下表所示:
| 操作 | 大 O O O 表示法 | 操作 | 大 O O O 表示法 |
|---|---|---|---|
| 取值 | O ( 1 ) O(1) O(1) | 賦值 | O ( 1 ) O(1) O(1) |
| del | O ( 1 ) O(1) O(1) | in 及 not in | O ( n ) O(n) O(n) |
| 復制 | O ( n ) O(n) O(n) | 遍歷 | O ( n ) O(n) O(n) |
對比兩表可以發現,即使是同一操作使用不同資料結構其復雜度也是不同的,例如包含操作 in,為了驗證它們之間的不同,撰寫以下程式進行實驗:
import timeit
import random
for i in range(10000, 1000000, 20000):
t = timeit.Timer('random.randrange({}) in x'.format(i), 'from __main__ import random, x')
x = list(range(i))
list_time = t.timeit(number=1000)
x = {j: j for j in range(i)}
dict_time = t.timeit(number=1000)
print("{}, {}, {}".format(i, list_time, dict_time))
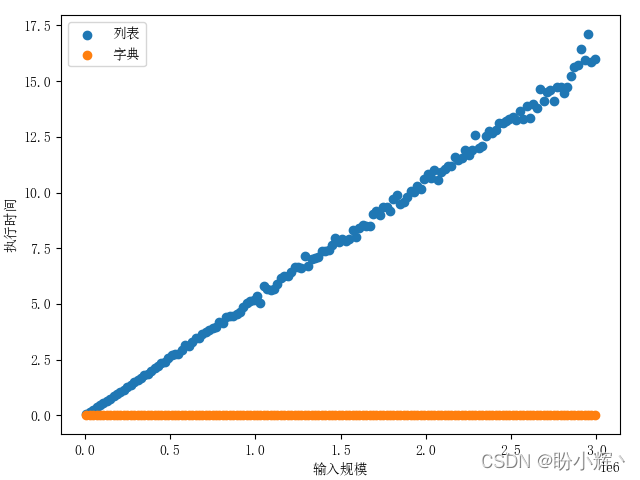
從上圖可以看出,隨著規模的增長,對于字典而言,包含操作的耗時始終是基本恒定的,而對于串列而言,其包含操作的耗時呈線性增長,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/393937.html
標籤:python