1 標準LRU的實作原理
LRU,最近最少使用(Least Recently Used,LRU),經典快取演算法,
LRU會使用一個鏈表維護快取中每個資料的訪問情況,并根據資料的實時訪問,調整資料在鏈表中的位置,然后通過資料在鏈表中的位置,表示資料是最近剛訪問的,還是已有段時間未訪問,
LRU會把鏈頭、尾分別設為MRU端和LRU端:
- MRU,Most Recently Used 縮寫,表示此處資料剛被訪問
- LRU端,此處資料最近最少被訪問的資料
LRU可分成如下情況:
- case1:當有新資料插入,LRU會把該資料插入到鏈首,同時把原來鏈表頭部的資料及其之后的資料,都向尾部移動一位
- case2:當有資料剛被訪問一次后,LRU會把該資料從它在鏈表中當前位置,移動到鏈首,把從鏈表頭部到它當前位置的其他資料,都向尾部移動一位
- case3:當鏈表長度無法再容納更多資料,再有新資料插入,LRU去除鏈表尾部的資料,這也相當于將資料從快取中淘汰掉
case2圖解:鏈表長度為5,從鏈表頭部到尾部保存的資料分別是5,33,9,10,8,假設資料9被訪問一次,則9就會被移動到鏈表頭部,同時,資料5和33都要向鏈表尾部移動一位,
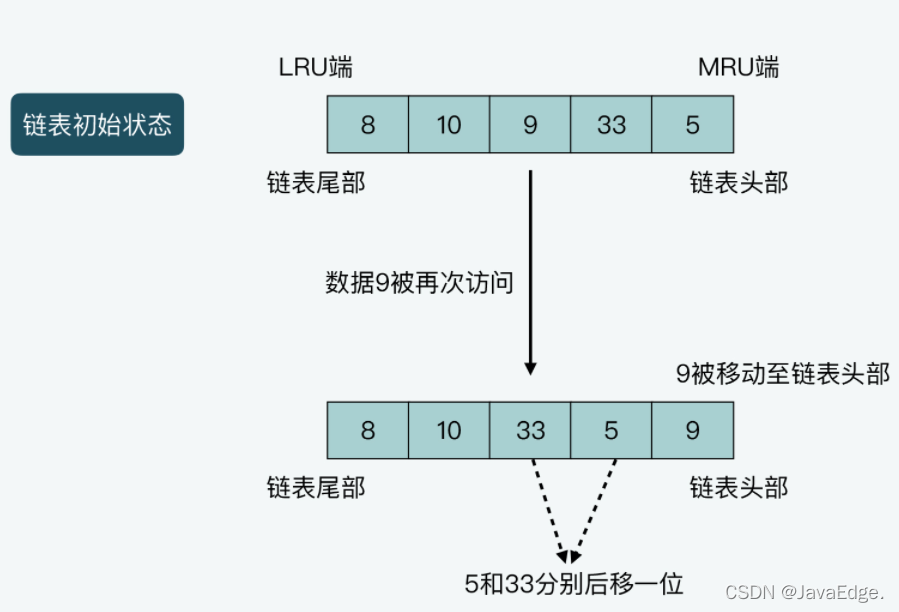
所以若嚴格按LRU實作,假設Redis保存的資料較多,還要在代碼中實作:
-
為Redis使用最大記憶體時,可容納的所有資料維護一個鏈表
需額外記憶體空間來保存鏈表
-
每當有新資料插入或現有資料被再次訪問,需執行多次鏈表操作
在訪問資料的程序中,讓Redis受到資料移動和鏈表操作的開銷影響
最終導致降低Redis訪問性能,
所以,無論是為節省記憶體 or 保持Redis高性能,Redis并未嚴格按LRU基本原理實作,而是提供了一個近似LRU演算法實作,
2 Redis的近似LRU演算法實作
Redis的記憶體淘汰機制是如何啟用近似LRU演算法的?redis.conf中的如下配置引數:
-
maxmemory,設定Redis server可使用的最大記憶體容量,一旦server使用實際記憶體量超出該閾值,server會根據maxmemory-policy配置策略,執行記憶體淘汰操作
-
maxmemory-policy,設定Redis server記憶體淘汰策略,包括近似LRU、LFU、按TTL值淘汰和隨機淘汰等

所以,一旦設定maxmemory選項,且將maxmemory-policy配為allkeys-lru或volatile-lru,近似LRU就被啟用,allkeys-lru和volatile-lru都會使用近似LRU淘汰資料,區別在于:
- allkeys-lru是在所有的KV對中篩選將被淘汰的資料
- volatile-lru在設定了TTL的KV對中篩選將被淘汰資料
Redis如何實作近似LRU演算法的呢?
-
全域LRU時鐘值的計算
如何計算全域LRU時鐘值的,以用來判斷資料訪問的時效性
-
鍵值對LRU時鐘值的初始化與更新
哪些函式中對每個鍵值對對應的LRU時鐘值,進行初始化與更新
-
近似LRU演算法的實際執行
如何執行近似LRU演算法,即何時觸發資料淘汰,以及實際淘汰的機制實作
2.1 全域LRU時鐘值的計算
近似LRU演算法仍需區分不同資料的訪問時效性,即Redis需知道資料的最近一次訪問時間,因此,有了LRU時鐘:記錄資料每次訪問的時間戳,
Redis對每個KV對中的V,會使用個redisObject結構體保存指向V的指標,那redisObject除記錄值的指標,還會使用24 bits保存LRU時鐘資訊,對應的是lru成員變數,這樣,每個KV對都會把它最近一次被訪問的時間戳,記錄在lru變數,
redisObject定義包含lru成員變數的定義:
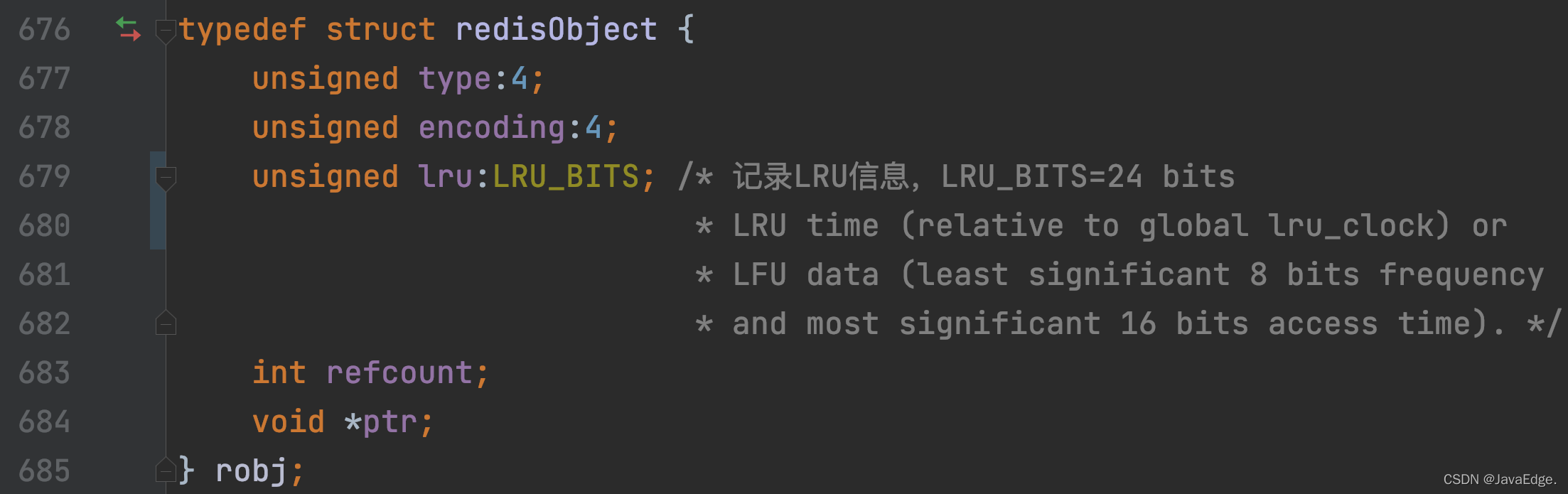
每個KV對的LRU時鐘值是如何計算的?Redis Server使用一個實體級別的全域LRU時鐘,每個KV對的LRU time會根據全域LRU時鐘進行設定,
這全域LRU時鐘保存在Redis全域變數server的成員變數lruclock

當Redis Server啟動后,呼叫initServerConfig初始化各項引數時,會呼叫getLRUClock設定lruclock的值:

于是,就得注意,**若一個資料前后兩次訪問的時間間隔<1s,那這兩次訪問的時間戳就是一樣的!**因為LRU時鐘精度就是1s,它無法區分間隔小于1秒的不同時間戳!
getLRUClock函式將獲得的UNIX時間戳,除以LRU_CLOCK_RESOLUTION后,就得到了以LRU時鐘精度來計算的UNIX時間戳,也就是當前的LRU時鐘值,
getLRUClock會把LRU時鐘值和宏定義LRU_CLOCK_MAX(LRU時鐘能表示的最大值)做與運算,

所以默認情況下,全域LRU時鐘值是以1s為精度計算得UNIX時間戳,且是在initServerConfig中進行的初始化,
那Redis Server運行程序中,全域LRU時鐘值是如何更新的?和Redis Server在事件驅動框架中,定期運行的時間事件所對應的serverCron有關,
serverCron作為時間事件的回呼函式,本身會周期性執行,其頻率值由redis.conf的hz配置項決定,默認值10,即serverCron函式會每100ms(1s/10 = 100ms)運行一次,serverCron中,全域LRU時鐘值就會按該函式執行頻率,定期呼叫getLRUClock進行更新:

這樣,每個KV對就能從全域LRU時鐘獲取最新訪問時間戳,
對于每個KV對,它對應的redisObject.lru在哪些函式進行初始化和更新的呢?
2.2 鍵值對LRU時鐘值的初始化與更新
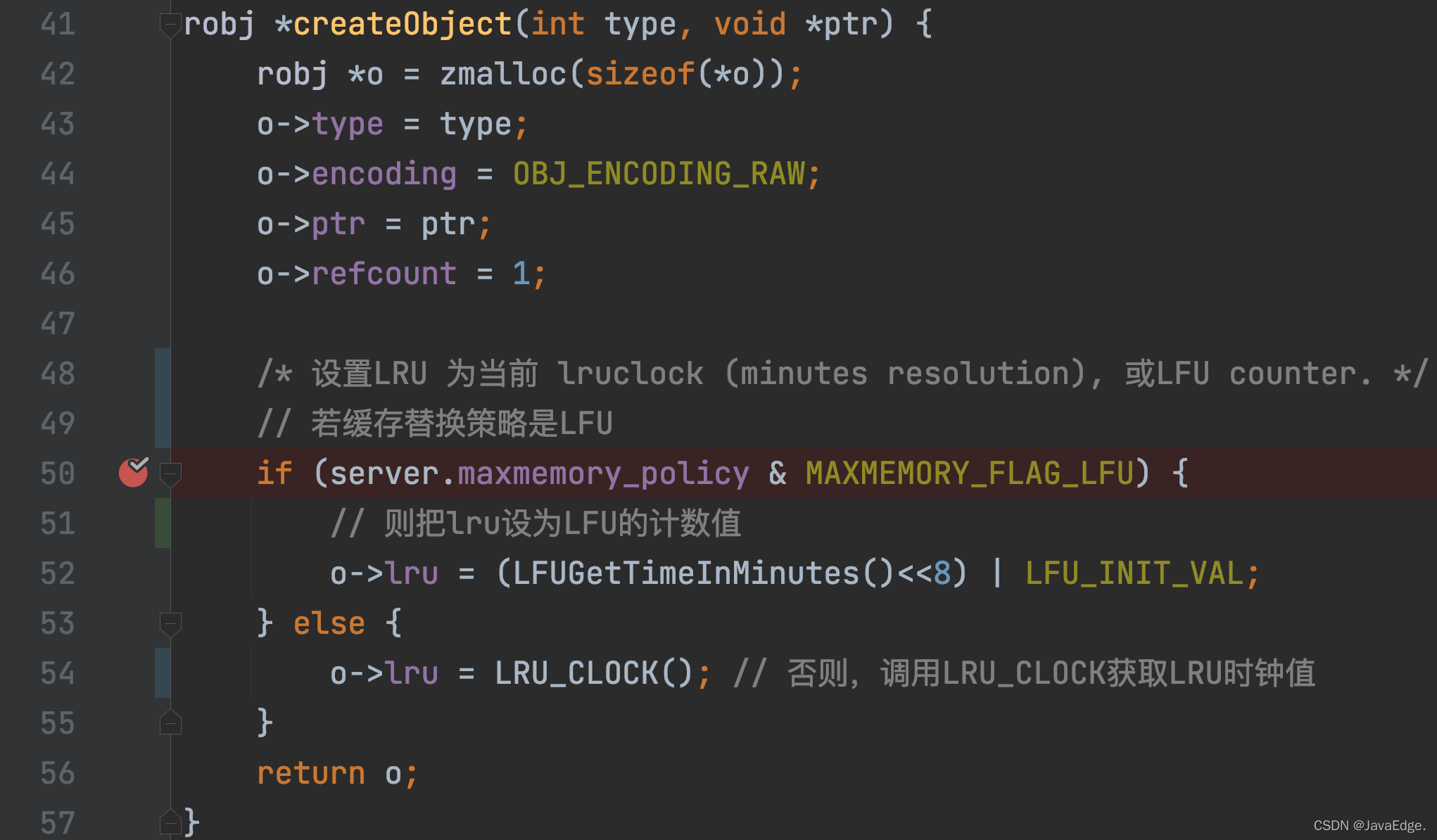
對于一個KV對,其LRU時鐘值最初是在這KV對被創建時,進行初始化設定的,這初始化操作在createObject函式中呼叫,當Redis要創建一個KV對,就會呼叫該函式,
createObject除了會給redisObject分配記憶體空間,還會根據maxmemory_policy配置,初始化設定redisObject.lru,
- 若maxmemory_policy=LFU,則lru變數值會被初始化設定為LFU演算法的計算值
- maxmemory_policy≠LFU,則createObject呼叫LRU_CLOCK設定lru值,即KV對對應的LRU時鐘值,
LRU_CLOCK回傳當前全域LRU時鐘值,因為一個KV對一旦被創建,就相當于有了次訪問,其對應LRU時鐘值就表示了它的訪問時間戳:
那一個KV對的LRU時鐘值又是何時再被更新?
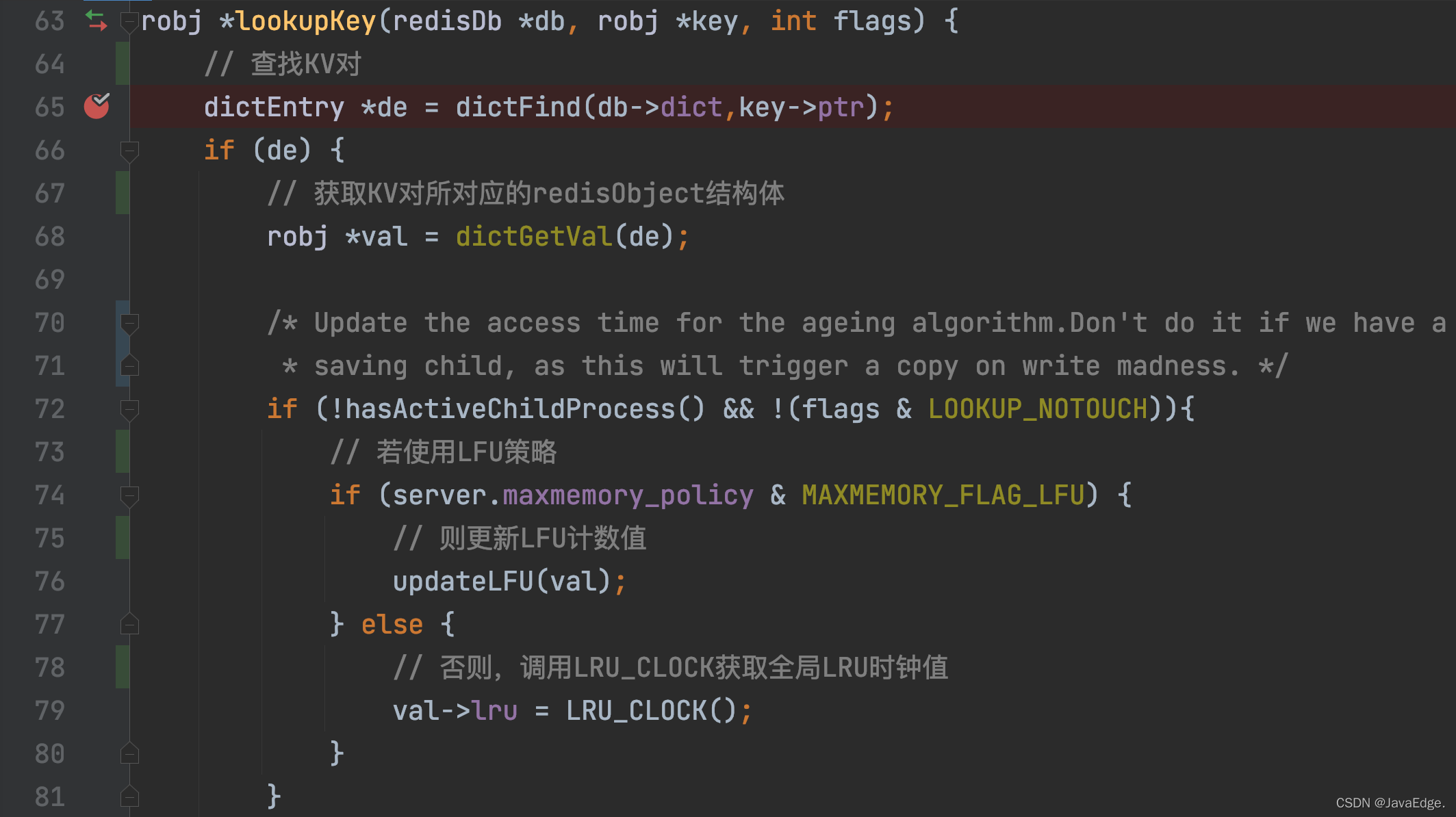
只要一個KV對被訪問,其LRU時鐘值就會被更新!而當一個KV對被訪問時,訪問操作最終都會呼叫lookupKey,
lookupKey會從全域哈希表中查找要訪問的KV對,若該KV對存在,則lookupKey會根據maxmemory_policy的配置值,來更新鍵值對的LRU時鐘值,也就是它的訪問時間戳,
而當maxmemory_policy沒有配置為LFU策略時,lookupKey函式就會呼叫LRU_CLOCK函式,來獲取當前的全域LRU時鐘值,并將其賦值給鍵值對的redisObject結構體中的lru變數
這樣,每個KV對一旦被訪問,就能獲得最新的訪問時間戳,但你可能好奇:這些訪問時間戳最終是如何被用于近似LRU演算法進行資料淘汰的?
2.3 近似LRU演算法的實際執行
Redis之所以實作近似LRU,是為減少記憶體資源和操作時間上的開銷,
2.3.1 何時觸發演算法執行?
近似LRU主要邏輯在performEvictions,
performEvictions被evictionTimeProc呼叫,而evictionTimeProc函式又是被processCommand呼叫,
processCommand,Redis處理每個命令時都會呼叫:
 然后,isSafeToPerformEvictions還會再次根據如下條件判斷是否繼續執行performEvictions:
然后,isSafeToPerformEvictions還會再次根據如下條件判斷是否繼續執行performEvictions:


一旦performEvictions被呼叫,且maxmemory-policy被設定為allkeys-lru或volatile-lru,近似LRU就被觸發執行了,
2.3.2 近似LRU具體執行程序
執行可分成如下步驟:
2.3.2.1 判斷當前記憶體使用情況
呼叫getMaxmemoryState評估當前記憶體使用情況,判斷當前Redis Server使用記憶體容量是否超過maxmemory配置值,
若未超過maxmemory,則回傳C_OK,performEvictions也會直接回傳,

getMaxmemoryState評估當前記憶體使用情況的時候,若發現已用記憶體超出maxmemory,會計算需釋放的記憶體量,這個釋放記憶體大小=已使用記憶體量-maxmemory,
但已使用記憶體量并不包括用于主從復制的復制緩沖區大小,這是getMaxmemoryState通過呼叫freeMemoryGetNotCountedMemory計算的,
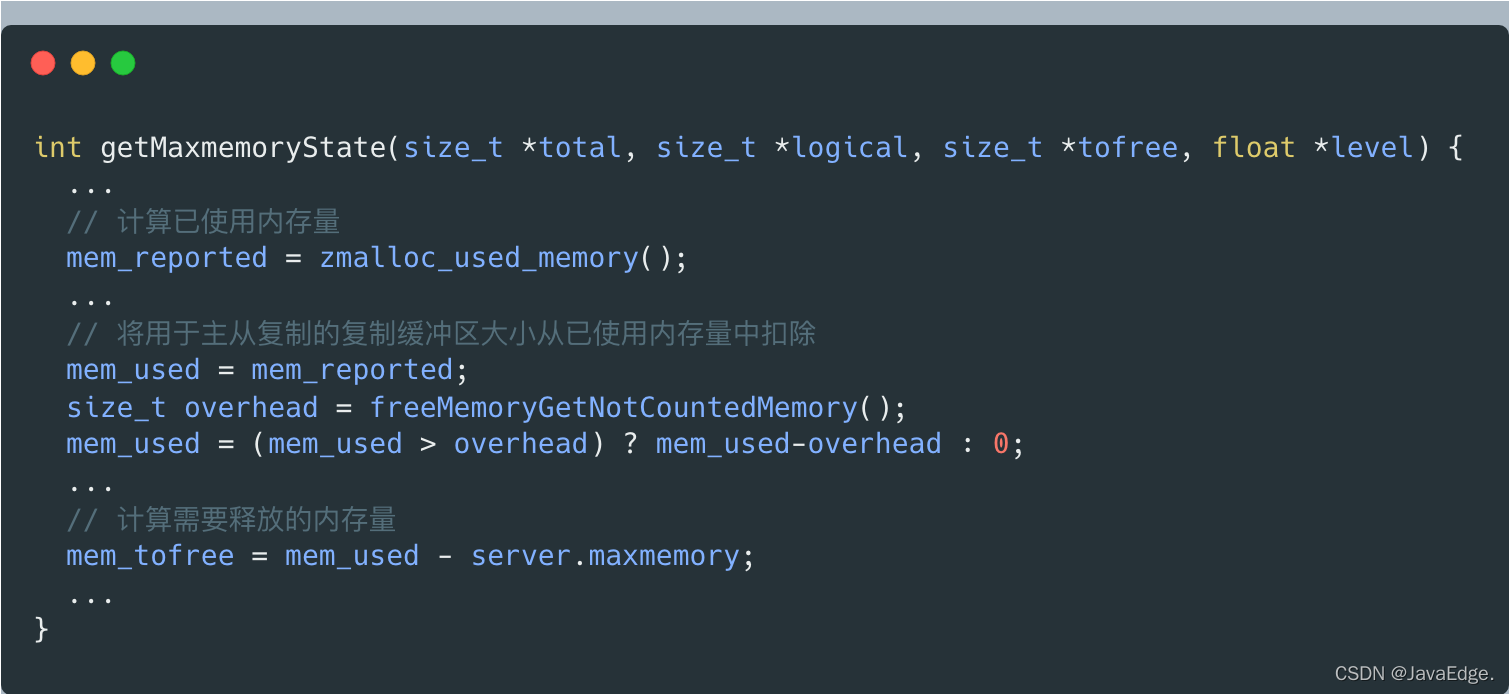
而若當前Server使用的記憶體量超出maxmemory上限,則performEvictions會執行while回圈淘汰資料釋放記憶體,
為淘汰資料,Redis定義陣列EvictionPoolLRU,保存待淘汰的候選KV對,元素型別是evictionPoolEntry結構體,保存了待淘汰KV對的空閑時間idle、對應K等資訊:


這樣,Redis Server在執行initSever進行初始化時,會呼叫evictionPoolAlloc為EvictionPoolLRU陣列分配記憶體空間,該陣列大小由EVPOOL_SIZE決定,默認可保存16個待淘汰的候選KV對,
performEvictions在淘汰資料的回圈流程中,就會更新這個待淘汰的候選KV對集合,即EvictionPoolLRU陣列,
2.3.2.2 更新待淘汰的候選KV對集合
performEvictions呼叫evictionPoolPopulate,其會先呼叫dictGetSomeKeys,從待采樣哈希表隨機獲取一定數量K:
- dictGetSomeKeys采樣的哈希表,由maxmemory_policy配置項決定:
- 若maxmemory_policy=allkeys_lru,則待采樣哈希表是Redis Server的全域哈希表,即在所有KV對中采樣
- 否則,待采樣哈希表就是保存著設定了TTL的K的哈希表,
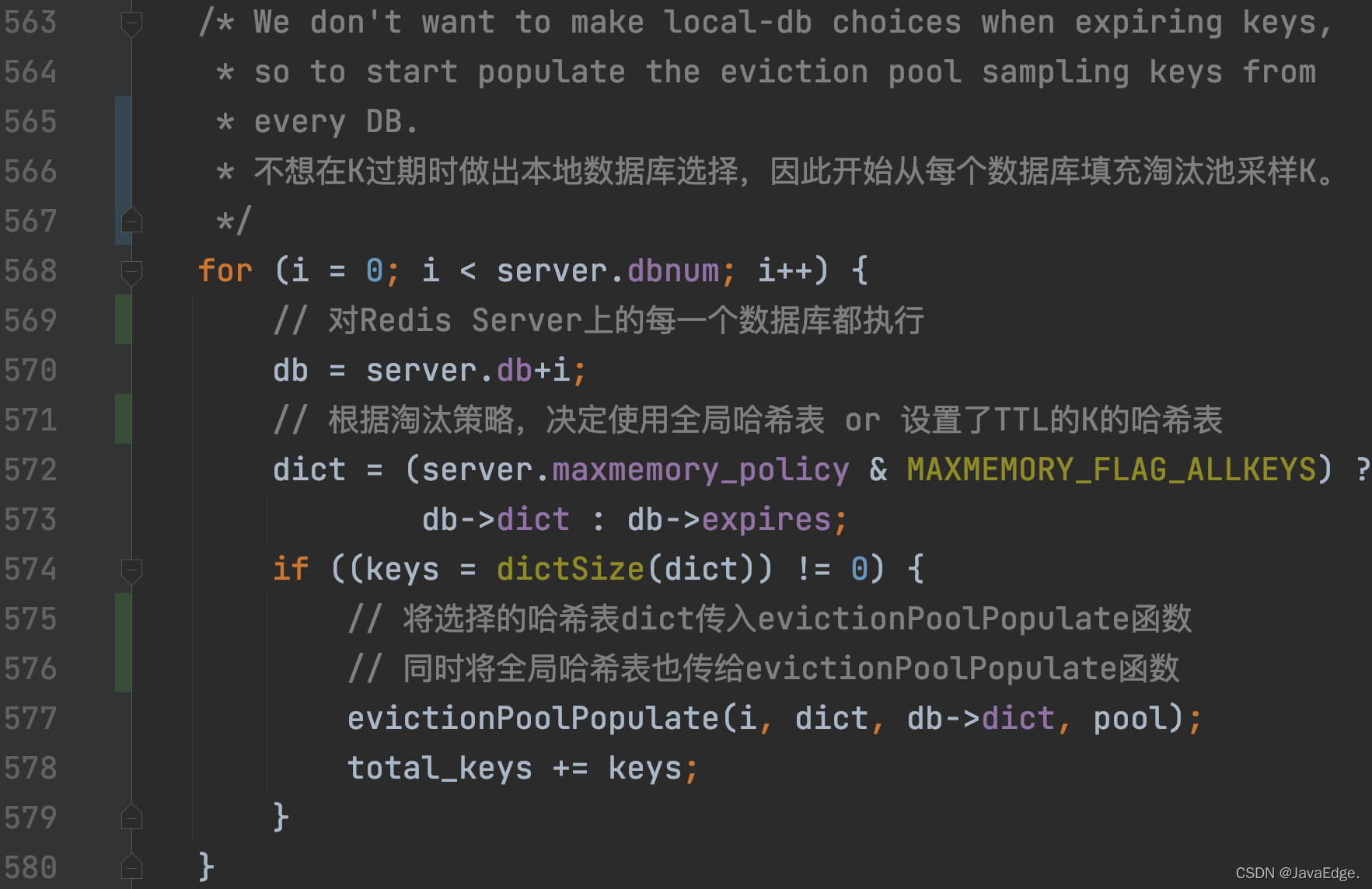
- dictGetSomeKeys采樣的K的數量由配置項maxmemory-samples決定,默認5:

于是,dictGetSomeKeys回傳采樣的KV對集合,evictionPoolPopulate根據實際采樣到的KV對數量count,執行回圈:呼叫estimateObjectIdleTime計算在采樣集合中的每一個KV對的空閑時間:
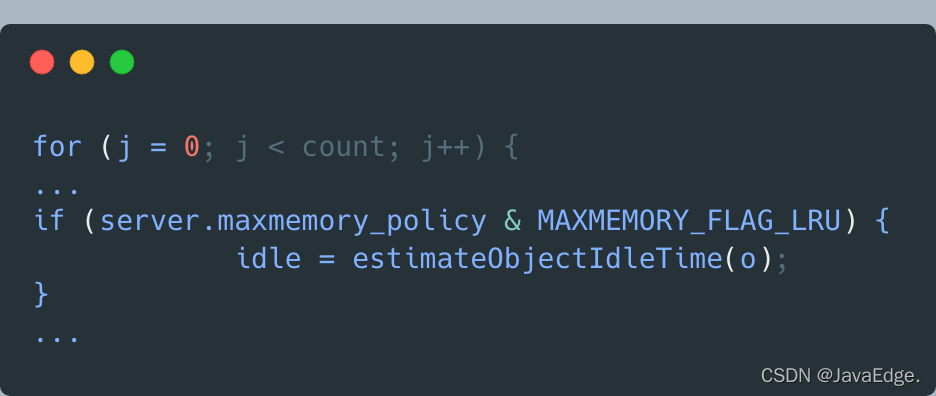
接著,evictionPoolPopulate遍歷待淘汰的候選KV對集合,即EvictionPoolLRU陣列,嘗試把采樣的每個KV對插入EvictionPoolLRU陣列,取決于如下條件之一:
- 能在陣列中找到一個尚未插入KV對的空位
- 能在陣列中找到一個KV對的空閑時間<采樣KV對的空閑時間
有一成立,evictionPoolPopulate就能把采樣KV對插入EvictionPoolLRU陣列,等所有采樣鍵值對都處理完后,evictionPoolPopulate函式就完成對待淘汰候選鍵值對集合的更新了,
接下來,performEvictions開始選擇最終被淘汰的KV對,
2.3.2.3 選擇被淘汰的KV對并洗掉
因evictionPoolPopulate已更新EvictionPoolLRU陣列,且該陣列里的K,是按空閑時間從小到大排好序了,所以,performEvictions遍歷一次EvictionPoolLRU陣列,從陣列的最后一個K開始選擇,若選到的K非空,就把它作為最終淘汰的K,
該程序執行邏輯:
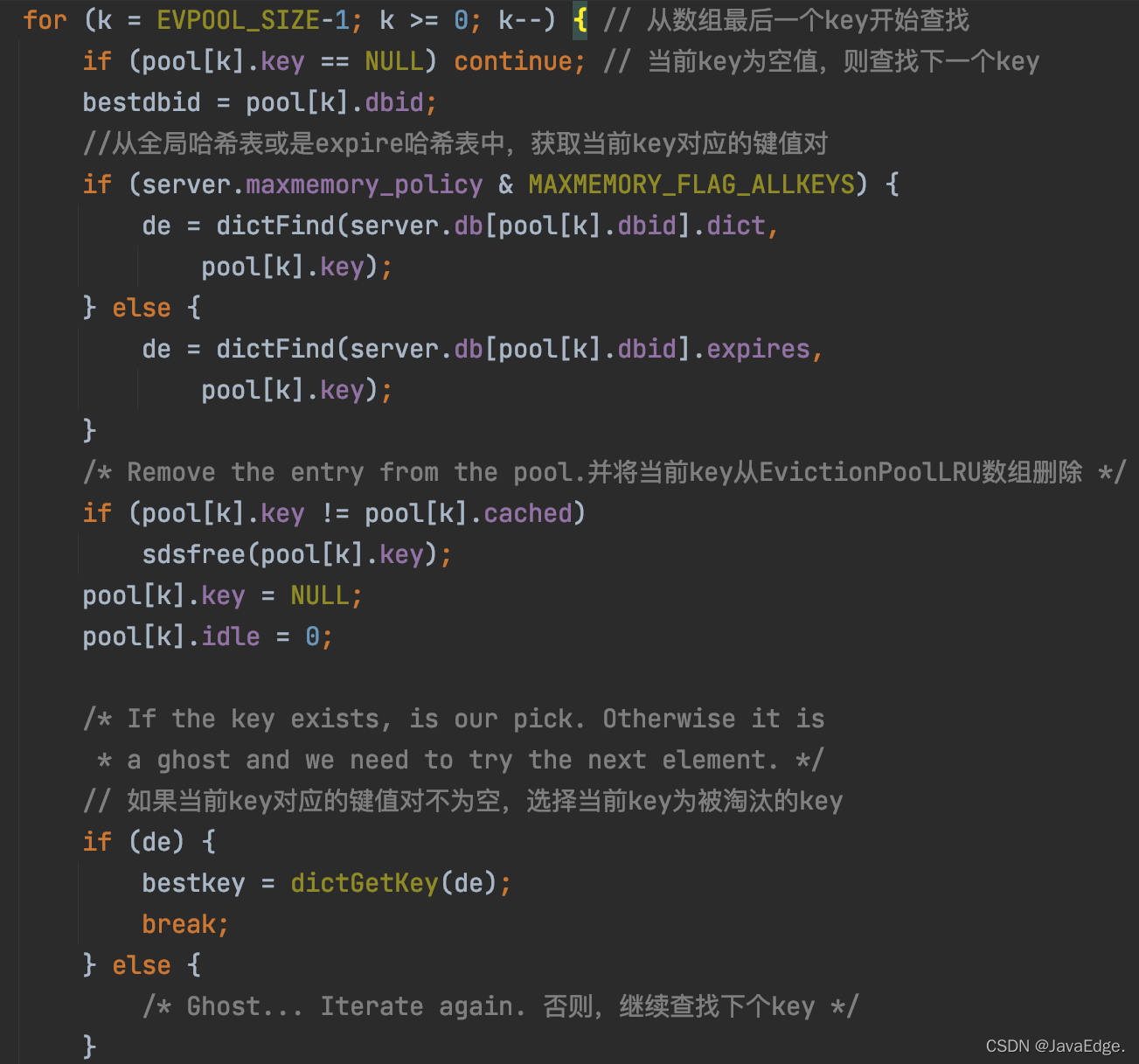
一旦選到被淘汰的K,performEvictions就會根據Redis server的惰性洗掉配置,執行同步洗掉或異步洗掉:
至此,performEvictions就淘汰了一個K,若此時釋放的記憶體空間還不夠,即沒有達到待釋放空間,則performEvictions還會重復執行前面所說的更新待淘汰候選KV對集合、選擇最終淘汰K的程序,直到滿足待釋放空間的大小要求,
performEvictions流程:
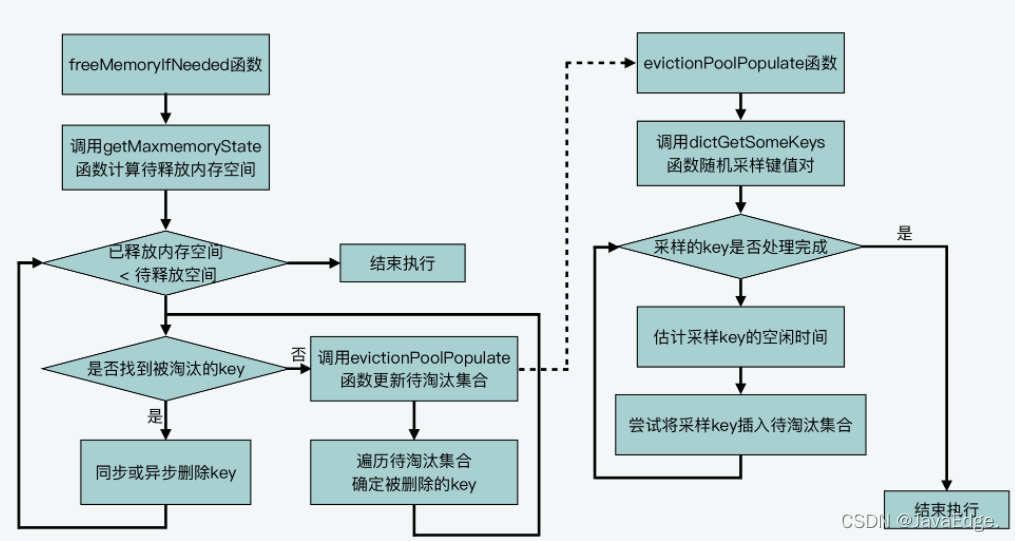
近似LRU演算法并未使用耗時且耗空間的鏈表,而使用固定大小的待淘汰資料集合,每次隨機選擇一些K加入待淘汰資料集合,
最后,按待淘汰集合中K的空閑時間長度,洗掉空閑時間最長的K,
總結
根據LRU演算法的基本原理,發現若嚴格按基本原理實作LRU演算法,則開發的系統就需要額外記憶體空間保存LRU鏈表,系統運行時也會受到LRU鏈表操作的開銷影響,
而Redis的記憶體資源和性能都很重要,所以Redis實作近似LRU演算法:
- 首先是設定了全域LRU時鐘,并在KV對創建時獲取全域LRU時鐘值作為訪問時間戳,及在每次訪問時獲取全域LRU時鐘值,更新訪問時間戳
- 然后,當Redis每處理一個命令,都呼叫performEvictions判斷是否需釋放記憶體,若已使用記憶體超出maxmemory,則隨機選擇一些KV對,組成待淘汰候選集合,并根據它們的訪問時間戳,選出最舊資料淘汰
一個演算法的基本原理和演算法的實際執行,在系統開發中會有一定折中,需綜合考慮所開發的系統,在資源和性能方面的要求,以避免嚴格按照演算法實作帶來的資源和性能開銷,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/395116.html
標籤:java