歡迎訪問我的GitHub
https://github.com/zq2599/blog_demos
內容:所有原創文章分類匯總及配套原始碼,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概覽
- 欣宸是個Java程式員,最近正在學習Python,本文記錄了學習程序,以及一點自己的思考,主要用途是作為筆記來總結和溫習,另外如果您也是一位初學Python的Java程式員,希望本文能給您一些參考;
版本
作業系統:macOS Big Sur (11.6)
Anaconda3:2021.05
python:3.7.3
Jupyter Notebook:5.7.8
工具
- 編輯器用的是Jupyter Notebook,以下三個快捷鍵最常用到,尤其是第三個,執行當前行,并新增一行:

- 廢話不多說了,直接開始動手操作;
除法
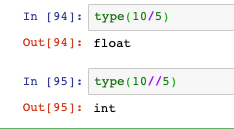
- 一個斜杠的除法,結果是浮點型,兩個斜杠的觸發,結果是整形:
字串
- 格式化的時候,可以不指定引數索引,此時按照出現順序處理:

- 也可以在花括號中添加數字:

-
還可以在花括號中添加冒號,在冒號之后添加特定的輸出格式
-
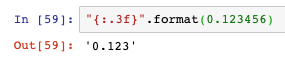
保留小數點后三位,f表示浮點數:
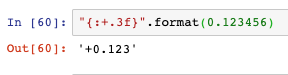
- 帶符號保留小數點后三位,f表示浮點數:
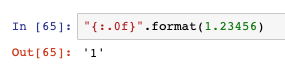
- 不顯示小數:
串列
- 逗號分隔,方括號包裹:
-
串列各個元素的型別無需相同(這一點和Java陣列是不同的)
-
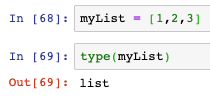
訪問串列中的元素,使用方括號+索引(從0開始):
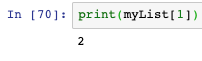
- 索引數值可以為負,負一表示倒數第一:
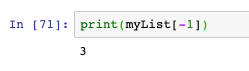
- 與字串的字符不同之處在于,串列的元素可以修改:

- 分片,下面代碼表示從0開始,一直取到2-1位置(左閉右開):

- 分片的時候,冒號左邊不填就表示從0開始,右邊不填表示直到最后一個元素:

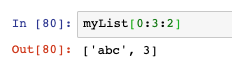
- 分片可以接受第三個引數:步長,下面的表示每遍歷兩個元素才取一個
- 當步長等于負一的時候,相當于反轉了:
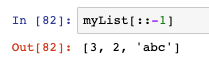
- 用加號實作兩個串列相連:

- 串列乘以數字N,表示生成一個新的串列,內容是原串列的N份復制:

- append:尾部追加元素

- insert:將元素插入在指定位置

- extend:將一個串列追加到另一個串列尾部
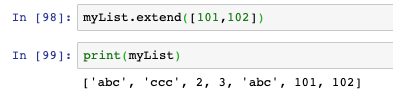
- 方法
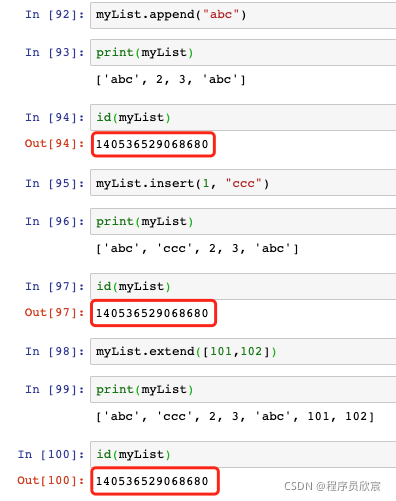
id可以查看物件的記憶體地址,如下圖,可見經歷了append、insert、extend等操作后,記憶體地址不變,也就是說這些都是原地操作(in place):
串列的洗掉操作
-
洗掉串列元素有三種方式:pop、remove、clear
-
pop()會彈出最后一個元素:

- 也可以將索引作為入參傳入,這樣就能洗掉指定元素:

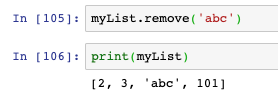
- remove方法的入參是串列中的值,也就是找到串列中與入參相同的元素,將其刪掉,下圖可見,myList中有兩個'abc',用remove會洗掉第一個:
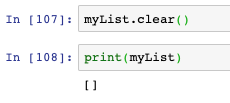
- clear方法會清空串列:
串列的記數和索引
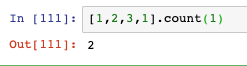
- count方法統計指定元素在串列中的數量,從下圖可見1在串列中出現了兩次:
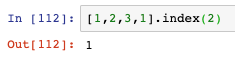
- index查找指定元素出現的位置:
串列排序
- sort方法用來排序,默認是比較元素大小:

- 默認是升序,添加reverse=True表示降序:

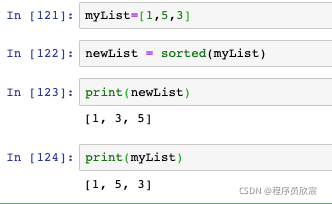
- sort操作的是串列物件本身,還可以用全域函式sorted來排序,該函式會生成一個新的副本,如下圖,newList是排序后的串列,而原有的myList保持不變:
與串列相關的常用全域函式
-
除了sorted,還有一些常用的全域函式和串列有關:
-
operator(取代原有的cmp),用于比較大小以及是否相等:
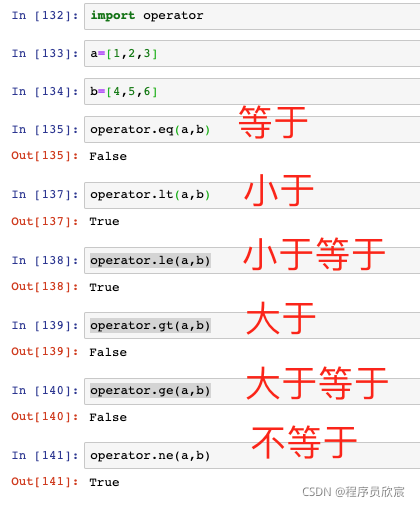
- len:計算個數
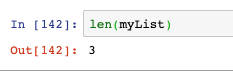
- max:回傳最大值
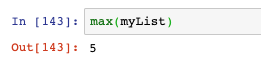
- min:回傳最小值
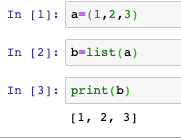
- list:元組轉為串列
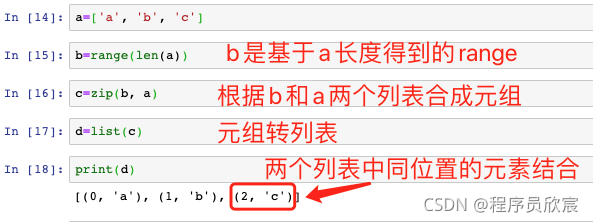
- zip:兩個串列中,同位置元素結合成一個元組,最終得到一個元組串列:
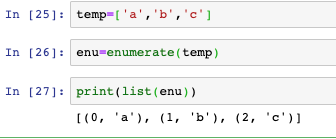
- enumerate:將指定串列的每個元素與其位置下表組成一個元組,最終得到一個元組串列(和上面的zip用法相似,不過簡單多了,range操作已經在enumerate內部實作),如下圖:
元組
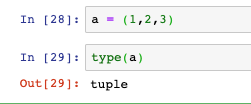
- 元組與串列相似,但是一旦創建就不能修改,創建使用的是圓括號(串列是方括號)
-
要注意的是,只有一個元素的元組也要帶逗號,例如(1,),這很好理解,畢竟(1)就是個整數而已
-
沒有括號,只有逗號,也是元組:
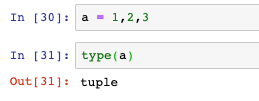
- 下標操作和串列相同:

- 串列轉元組用tuple函式:

- tuple函式還能將字串直接轉為元組:

- 修改元組會失敗:

- 修改元組的思路是創建新的元組,如下圖,用三個元組拼接的方式生成了一個新的元組,相比舊的,新元組的第三個元素已經從2變為'a',給人以修改過的感覺:

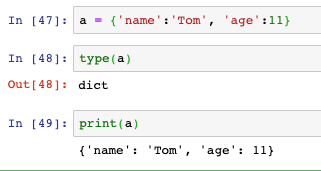
字典
- 字典和Java的map相似,由多個鍵值對構成,鍵和值之間用冒號分隔,多個鍵值之間用逗號分隔,外面用大括號包裹:
-
字典看起來很像json
-
items方法回傳所有元素,keys回傳所有鍵,values回傳所有值:

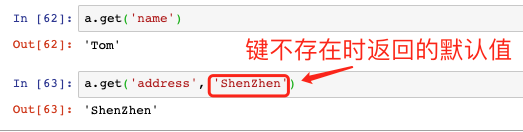
- 可以用鍵查找值,和Java的map一樣,不過語法是中括號:

- 也可以用get方法回傳鍵對應的值,還能指定鍵不存在時的默認值:
- 直接用方括號,可以修改,如果鍵不存在就是添加:

- update方法的入參是另一個字典,該方法可以將入參字典的內容合并進自身:

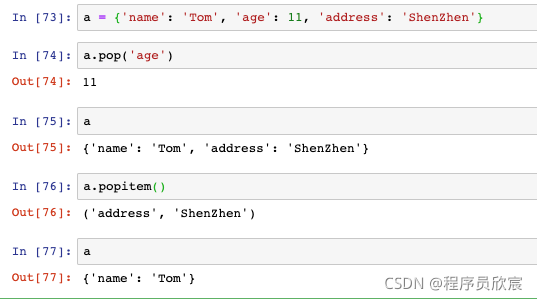
- pop方法洗掉指定元素,popitem方法洗掉最后一個元素:
集合(Set)
-
提到Set,Java程式員應該不陌生,就是咱們經常用來排重的那個Set,是個無序元素集
-
集合用逗號分隔,大括號包裹:

-
小結三種包裹方式:串列方括號,元組圓括號,字典和集合大括號(字典的元素是鍵值對,集合是單個元素),另外元組可以不包裹,有逗號就行
-
set方法可以將串列轉為集合:

-
集合的元素都是不可變型別的,如數值、字串、元組
-
可變型別不能作為集合的元素,如串列、字典、集合,至于其中原因,看看下圖紅框的錯誤資訊,如果您是個Java程式員,應該get到了:
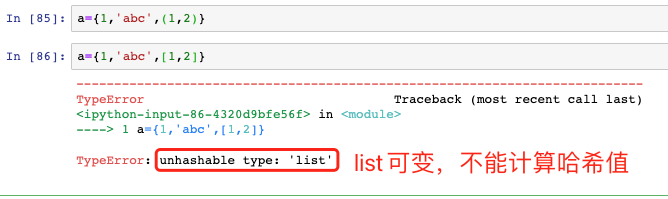
- 可以用減號或者difference方法求兩個集合的差集:

程式邏輯控制
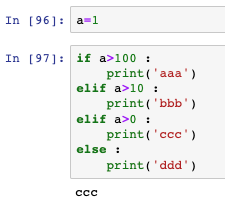
- if判斷,是用if、elif、else的組合,注意if、elif、else的行末尾都有冒號:
-
python不支持switch
-
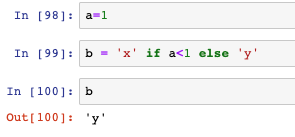
if判斷的三元運算子,賦值的時候可用if else組合:
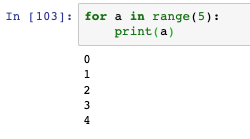
- 普通的for回圈:

- 內置函式range可以創建整數串列,也能在for回圈中遍歷:
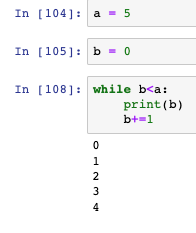
- while回圈的語法和java相似:
- 回圈中的break和continue與Java類似,就不贅述了
推導式:串列
- 格式如下:
[生成運算式 for 變數 in 序列或迭代物件]
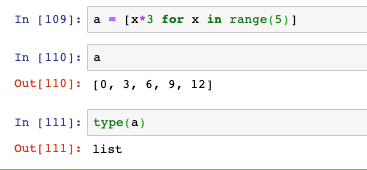
- 測驗如下,a就是串列推導式生成的串列:
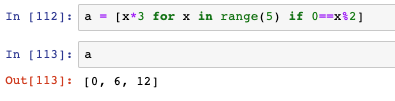
- 還可以通過if增加篩選條件,例如下面是只保留偶數:
- 如果串列的元素也是串列,我們可以用串列推導將其解開,平鋪為一層,下圖的例子中,a_element是a的元素,a_element自身也是串列,還可以用推導將其展開:

推導式:字典
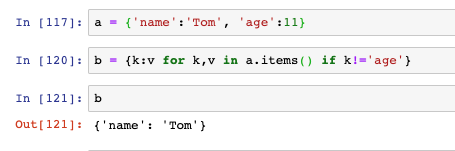
- 對字典用推導式,可以取得鍵和值的處理,下面是用推導式生成一個新的字典,剔除了鍵為age的鍵值對:
推導式:集合
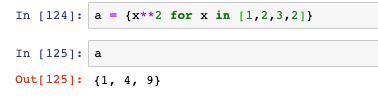
- 下面使用推導式,利用串列生成一個新集合,里面的值是原串列每個元素的平方,而且由于集合的不重復性,原串列中重復的元素已經被過濾為只剩一個:
匯入庫
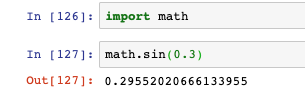
- 語法:
import 模塊名 [as 別名]
- 例如匯入math模塊來計算正弦值:
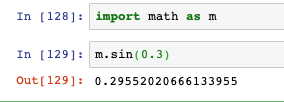
- 如果覺得每次在代碼中寫math太麻煩,還可以在匯入時設定別名:
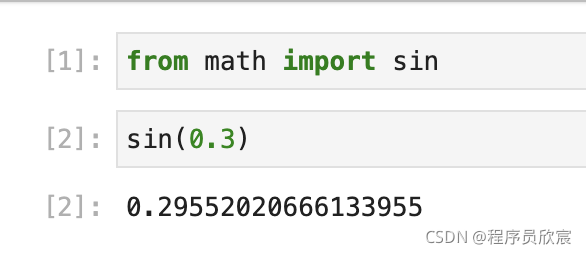
- 如果覺得別名也麻煩,能不能把m.也去掉,可以用以下語法:
from 模塊名 import 物件名
例如:
- 上述極簡的方式是不推薦使用的,因為缺少了namespace隔離,在API的正確性上就缺少了保障
關于自己的模塊
- 假設有一個python檔案hello.py,內容如下,定義了名為doHello的方法,再執行一下試試:
def doHello():
print("hello world!")
doHello()
- 現在另一個檔案test.py,里面會呼叫hello.py中的doHello的方法:
import hello
hello()
- 執行命令python test.py,結果如下,可見hello world!輸出了兩次:
will$ python test.py
hello world!
hello world!
-
上述結果顯然不是我們想要的,test.py只是想使用doHello方法,結果將hello.py中的doHello()也執行了,需要一種方式來避免test.py中的doHello()被執行
-
這時候內置變數name就派上用場了(注意前后都是兩個下劃線),將hello.py改成如下內容,如果執行python hello.py,內置變數name的值就是main,其他時候,例如hello.py被其他檔案import的時候,它的值就是模塊名(這里就是hello):
def doHello():
print("hello world!")
if __name__=='__main__':
doHello()
- 再試試python test.py,這次只有一次輸出了:
will$ python test.py
hello world!
- 我們再試試python hello.py,也能按照預期輸出:
will$ python hello.py
hello world!
包
-
對于Java程式員來說,包很好理解,在python中也很相似,接下來咱們嘗試一下,創建名為test的包,里面有兩個模塊:test1和test2
-
加入包名為test,咱們創建名為test的檔案夾
-
test檔案夾下,新增檔案init.py,這是個空檔案
-
創建檔案test1.py:
def doTest1():
print("hello test1!")
- 再創建檔案tes2.py:
def doTest2():
print("hello test2!")
- 現在回到test2.py檔案的上一層目錄,創建檔案hello.py,用來驗證如何使用包,可見訪問方式是包名.模塊名.方法名:
import test.test1 as test1
import test.test2 as test2
test1.doTest1()
test2.doTest2()
- 運行hello.py試試:
will$ python hello.py
hello test1!
hello test2!
內建模塊:collections
-
Java程式員對collections包不會陌生,這里面都是一些和容器相關的類,為咱們的開發提供了極大便利,接下來看看該模塊常用的幾個類
-
namedtuple:可以用名字訪問內容的元組子類,從下面的代碼可見,namedtuple可以方便的定義一個物件,很像java中的bean:
from collections import namedtuple
# 自定義元組物件
Student = namedtuple('Student', ['name', 'age'])
# 實體化Student
student = Student('Tom', 11)
# 看一下student的型別
print(type(student))
# 使用name欄位
print(student.name)
# 使用age欄位
print(student.age)
- 執行結果如下,可見student的name和age欄位都能方便的訪問到,而student實體的型別是class:
will$ python test.py
<class '__main__.Student'>
Tom
11
內建模塊:deque
- deque是雙向佇列,在增加和洗掉資料的時候比串列的性能更好(串列的讀性能更好),基本操作如下所示:
from collections import deque
# 實體化deque
dq = deque([1,2,3])
# 佇列右側增加元素
dq.append(4)
print('1. {}'.format(dq))
# 佇列左側增加元素
dq.appendleft(5)
print('2. {}'.format(dq))
# 指定位置增加元素
dq.insert(1, 6)
print('3. {}'.format(dq))
# 最右側元素彈出(洗掉)
dq.pop()
print('4. {}'.format(dq))
# 最左側元素彈出
dq.popleft()
print('5. {}'.format(dq))
# 洗掉元素,注意2是值,不是位置
dq.remove(2)
print('6. {}'.format(dq))
# 倒排
dq.reverse()
print('7. {}'.format(dq))
- 執行結果如下:
will$ python deque.py
1. deque([1, 2, 3, 4])
2. deque([5, 1, 2, 3, 4])
3. deque([5, 6, 1, 2, 3, 4])
4. deque([5, 6, 1, 2, 3])
5. deque([6, 1, 2, 3])
6. deque([6, 1, 3])
7. deque([3, 1, 6])
內建模塊:OrderedDict
- OrderedDict是有順序的字典,如果您了解LFU(Least frequently used)演算法,那么就很容易理解有序的字典了,OrderedDict中的順序是元素被添加的先后順序,普通用法如下:
from collections import OrderedDict
# 實體化
od = OrderedDict()
# 添加
od['a'] = 1
od['c'] = 2
od['b'] = 3
# 順序是添加的先后順序
print("1. {}".format(od))
# 列印所有的鍵
print(od.keys())
# 把一個字典合并進來
od.update({'e':'4'})
# 順序是添加的先后順序
print("2. {}".format(od))
# 根據鍵洗掉鍵值對
od.pop('a')
print("3. {}".format(od))
# 把指定鍵的鍵值對移到末尾
od.move_to_end('c')
print("4. {}".format(od))
- 輸出如下:
will$ python ordered.py
1. OrderedDict([('a', 1), ('c', 2), ('b', 3)])
odict_keys(['a', 'c', 'b'])
2. OrderedDict([('a', 1), ('c', 2), ('b', 3), ('e', '4')])
3. OrderedDict([('c', 2), ('b', 3), ('e', '4')])
4. OrderedDict([('b', 3), ('e', '4'), ('c', 2)])
內建模塊:defaultdict
- defaultdict容易理解:帶有默認值的字典,用法如下所示,要注意的是defaultdict實體化的入參是lambda運算式,至于這個lambda,相信java程式員并不陌生:
from collections import defaultdict
dd = defaultdict(lambda: 'ABC')
dd['a'] = 1
# 列印一個存在的鍵值
print(dd['a'])
# 列印一個不存在的鍵值
print(dd['b'])
- 輸出如下:
will$ python defaultdict.py
1
ABC
內建模塊:Counter
- Counter提供了計數器功能,下面的demo演示了用Counter將串列轉為了每個元素的統計結果,要注意的是most_common方法,相當于排序和串列的功能,該方法的回傳值是串列,里面的元素是元組:
from collections import Counter
# 一個普通串列
colors = ['aa', 'bb', 'cc', 'aa']
# 將串列傳給Counter進行統計
result = Counter(colors)
# 列印result型別
print(type(result))
# 列印result內容
print(result)
# 用內置函數dict將Counter實體轉為字典
print(dict(result))
# 取統計值最高的前兩個元素
most = result.most_common(2)
# 檢查most_common回傳值的型別
print("most_common's type {}".format(type(most)))
# 檢查most_common回傳值的型別
print("most_common's value : {}".format(most))
- 輸出結果如下:
will$ python Counter.py
<class 'collections.Counter'>
Counter({'aa': 2, 'bb': 1, 'cc': 1})
{'aa': 2, 'bb': 1, 'cc': 1}
most_common's type <class 'list'>
most_common's value : [('aa', 2), ('bb', 1)]
內建模塊:datetime
- 名為datetime的模塊中,有個名為datetime的類
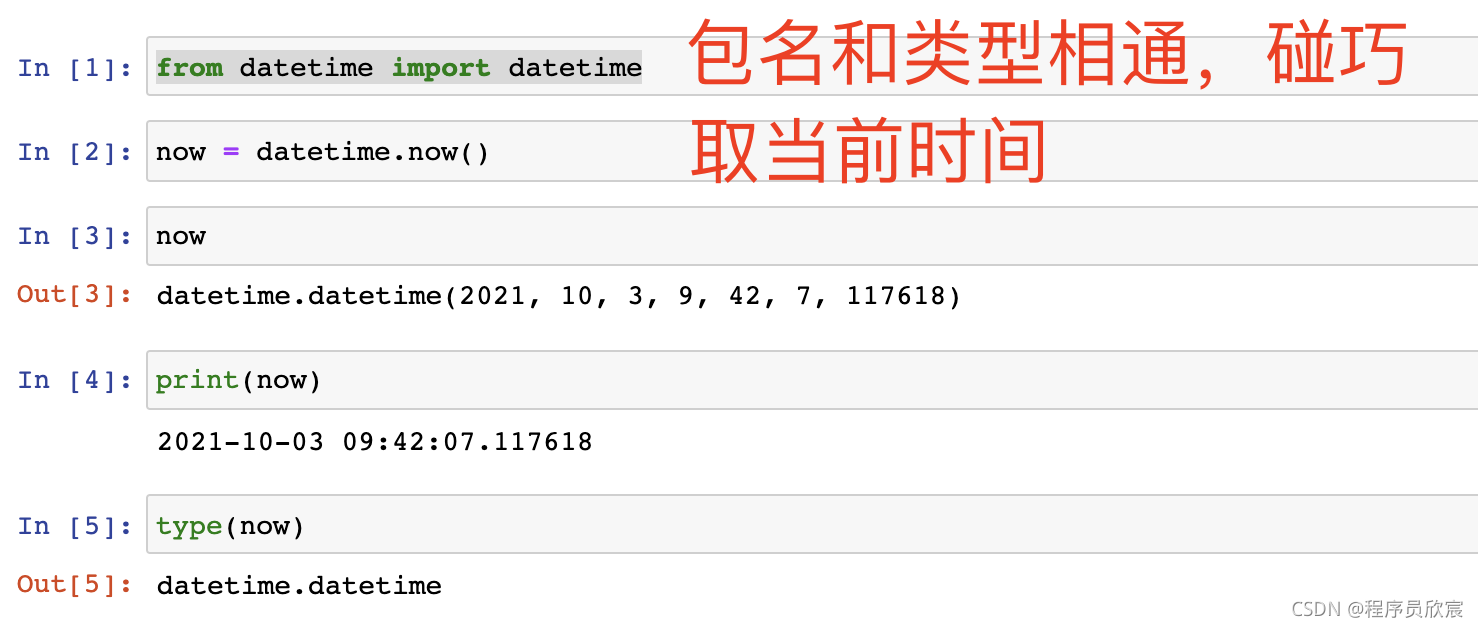
- 還可以實體化datetime物件:

- datetime物件的年月日時分秒等欄位:
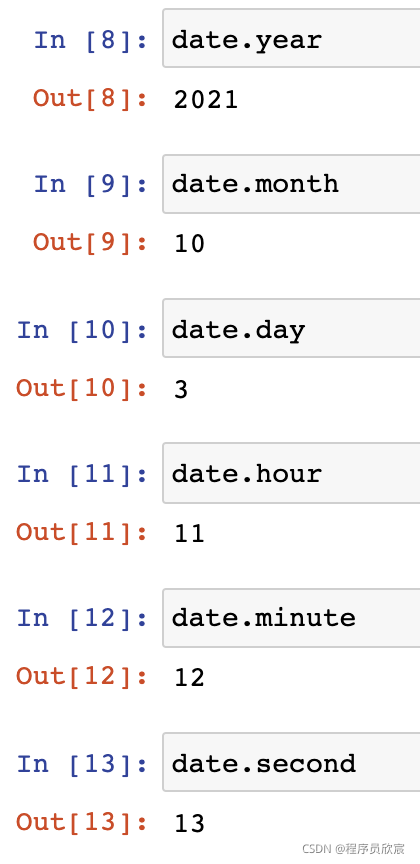
- 轉時間戳:
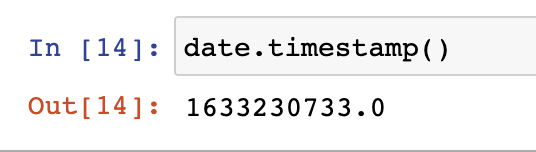
- 還可以通過strptime方法將指定格式的字串轉為datetime物件:

- datetime物件轉字串也是常見操作,用的是strftime方法:

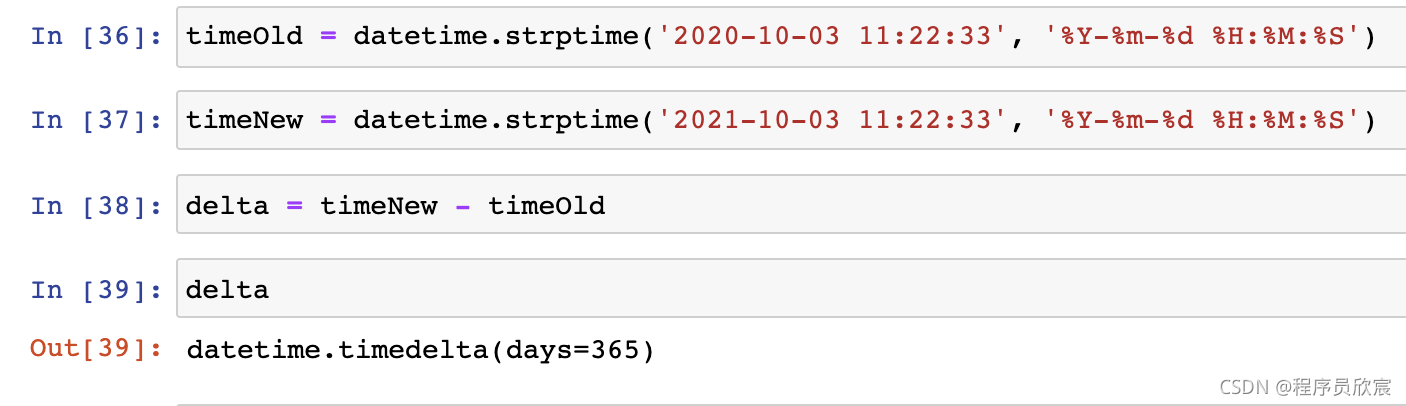
- 時間的計算,例如一天前,一小時后等操作,可以使用datetime包的timedelta類完成:

- datetime物件可以用減法結算時間差:

- 減法特性在計算日期間隔的時候很有用:
JSON處理
- 利用json進行物件和字串之間的序列化、反序列化轉換:
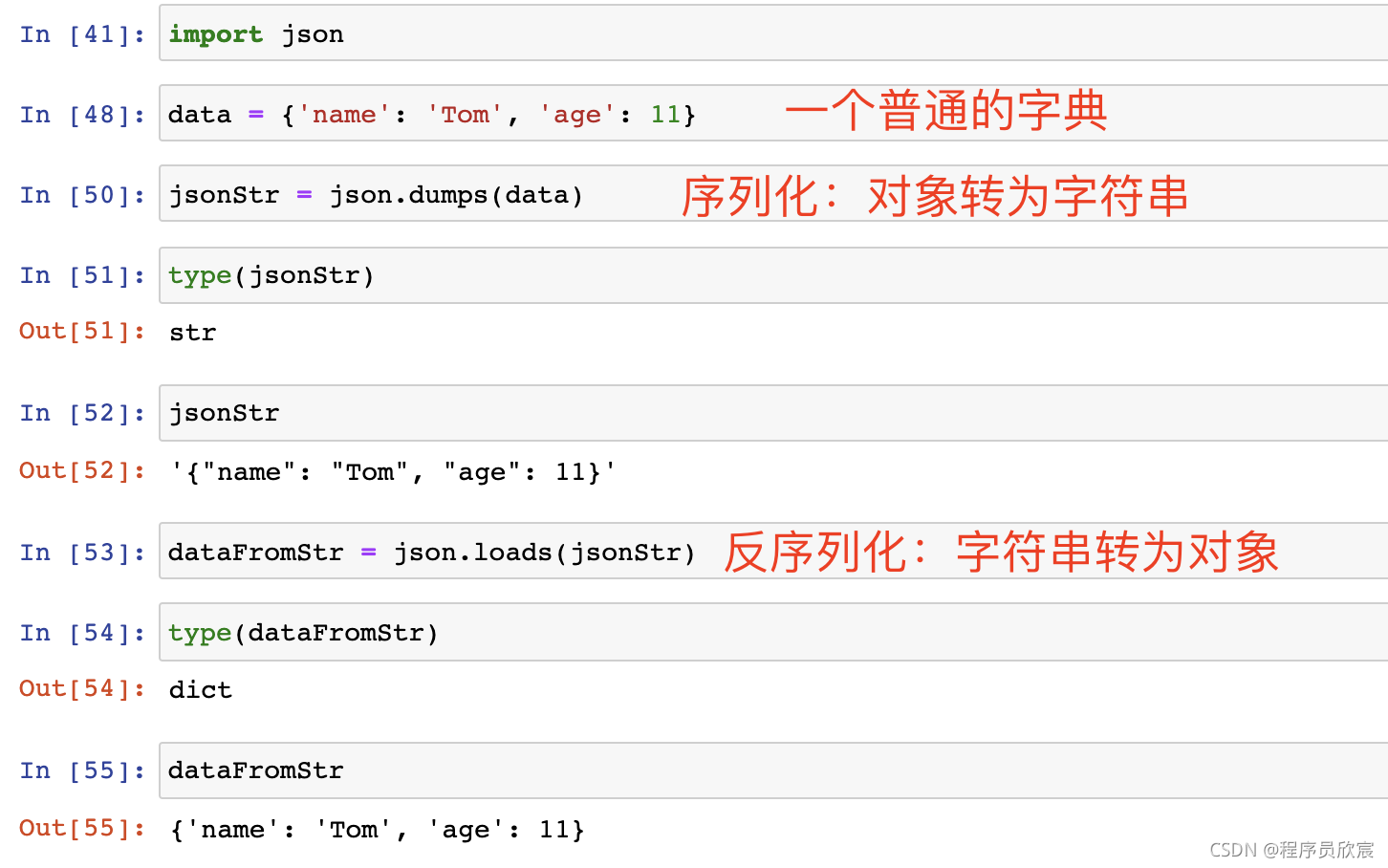
- 還可以用dump和load方法通過檔案進行序列化反序列化操作
內置模塊:random
- 生成亂數也是常見操作:
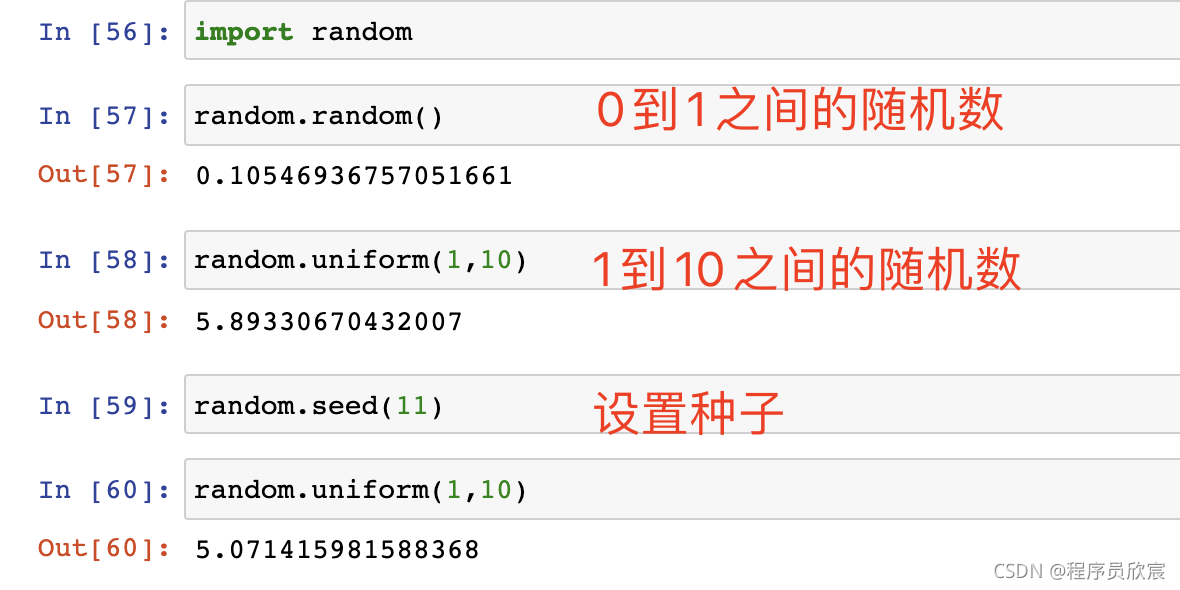
- 還可以產生整形亂數,設定內容范圍和遞增單位:
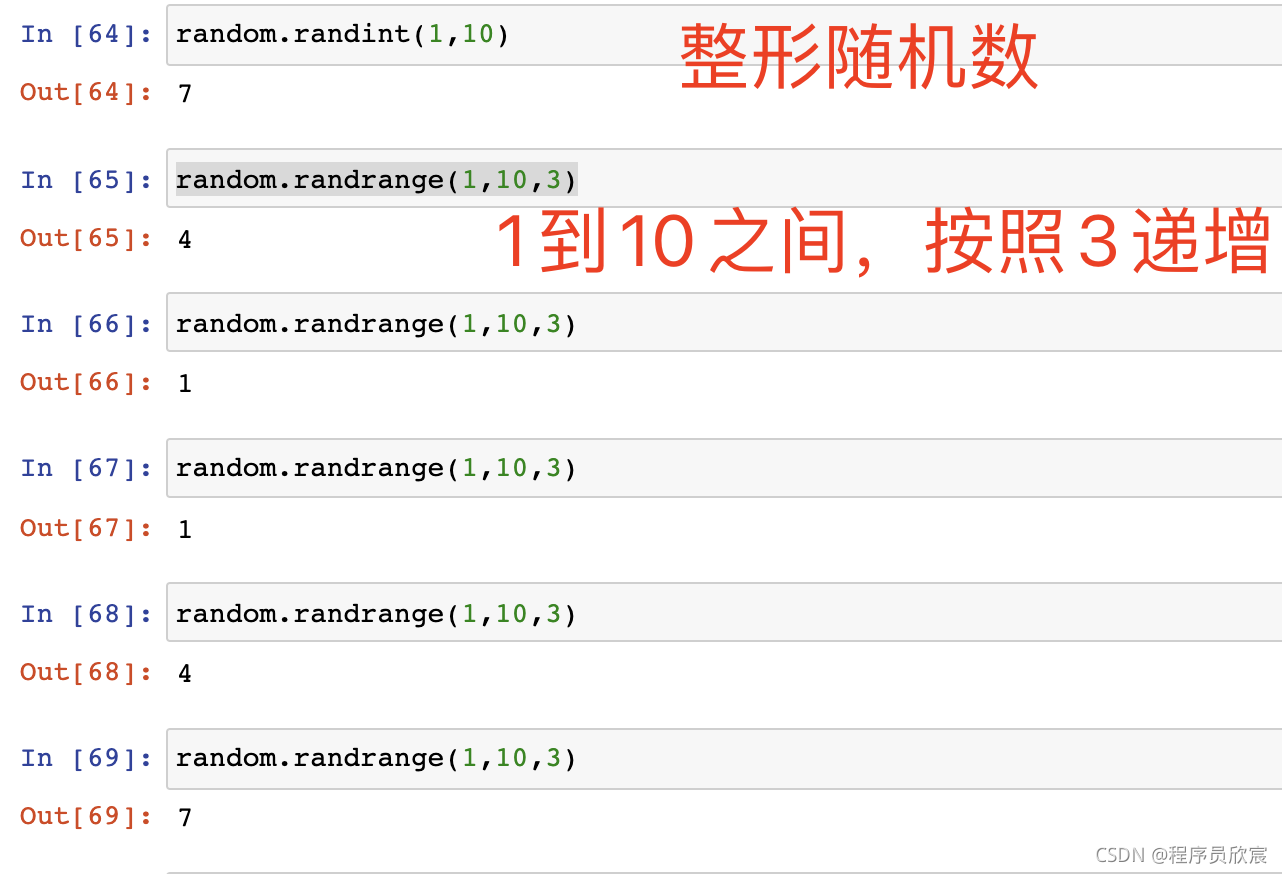
- 在一堆內容中做隨機選擇:

- 用choices方法(注意不是choice),可以隨機選擇指定數量的結果:
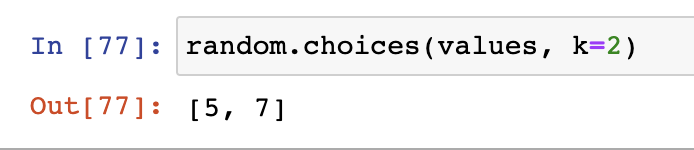
- choices得到的結果可能重復,如果想不重復可以用sample方法:
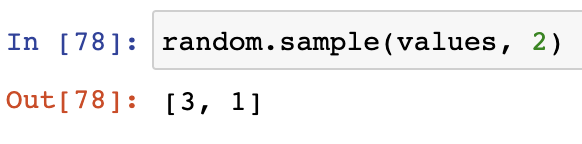
- 將原有集合資料的順序打亂,相當于洗牌的效果:

函式
- 基本函式語法:
def 函式名([引數串列]):
函式體
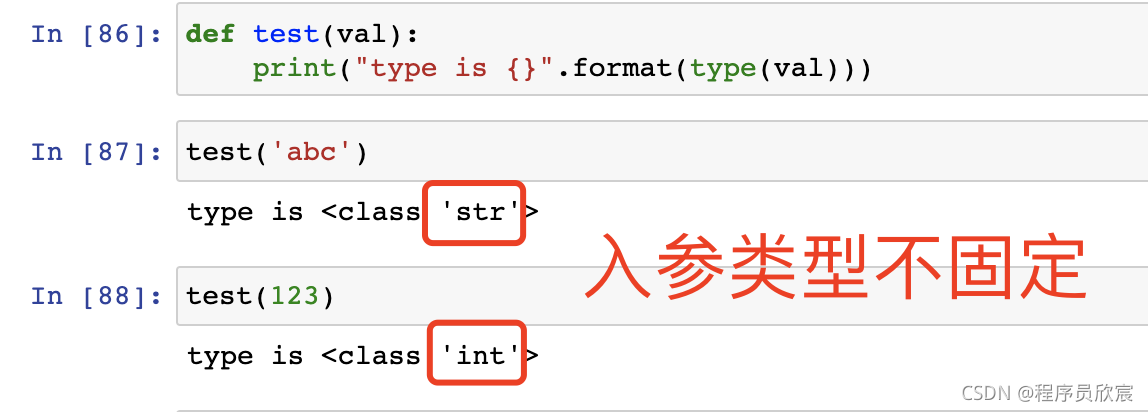
- 和Java不同的是,函式的入參型別并不固定:
- 使用關鍵字pass,可以定義一個空方法:
def test():
pass
- 一個函式可以回傳多個值(本質上是個元組),呼叫的時候用多個變數來接收即可:

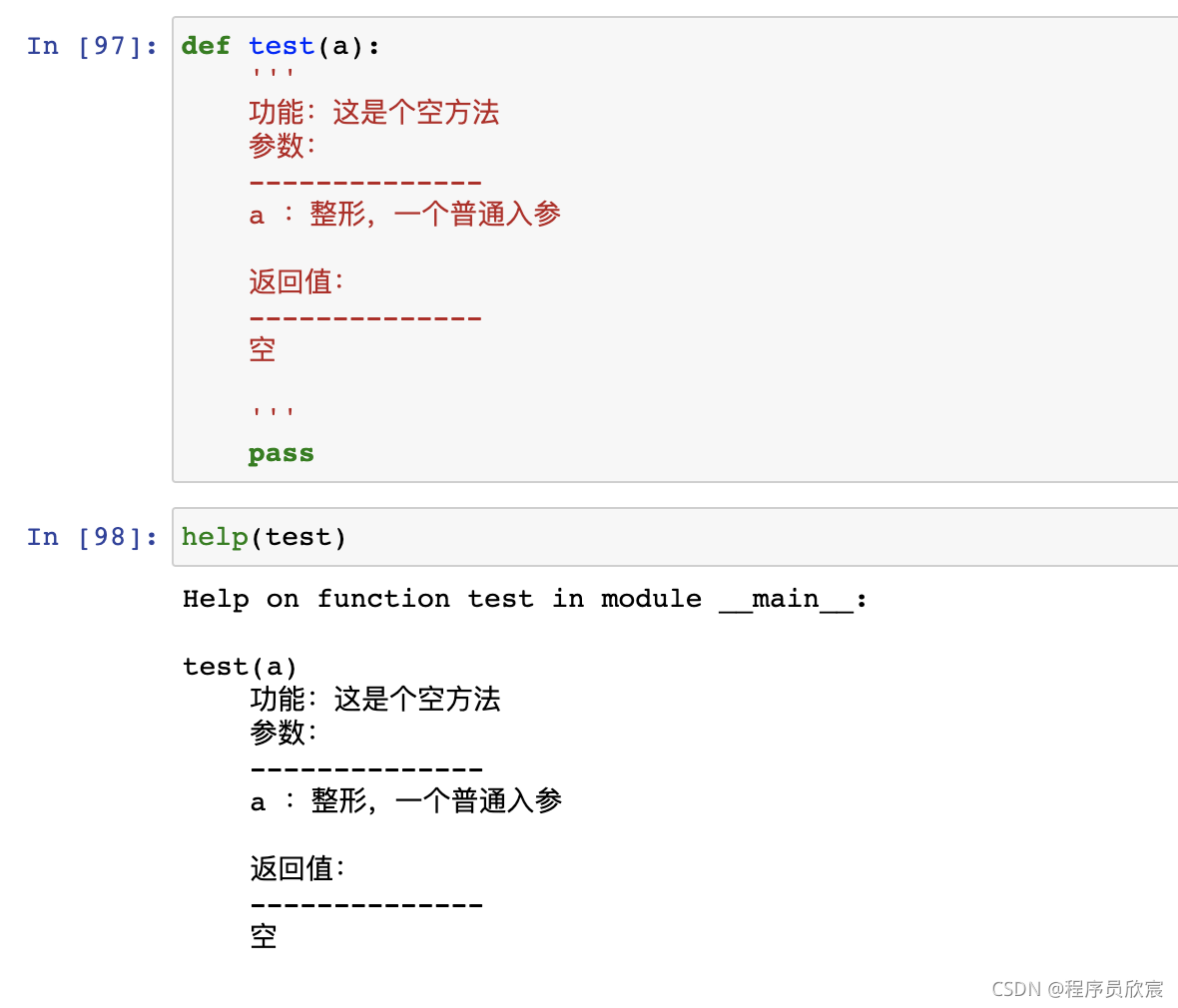
- 還可以給函式增加說明檔案,然后用help命令查看:
- 呼叫引數的時候可以用引數名=xxx的形式傳入引數,此時引數引數的先后順序可以隨意,無所有誰先誰后:

- 可變引數和Java的方法也相似,先看一個星號的可變引數,可以理解為元組:

- 再看兩個星號的可變引數,可以理解為字典:

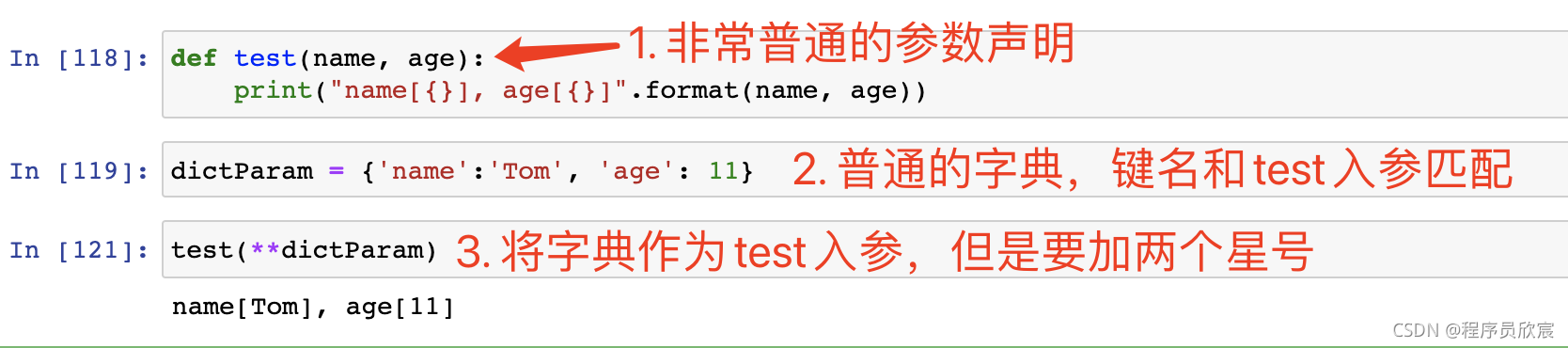
- 對于固定引數的函式,還可以直接將字典作為入參,不過要加兩個星號:
- 還可以設定默認引數:

lambda運算式
- java程式員對lambda運算式很熟悉,這里也差不多,來看看如何定義和使用:
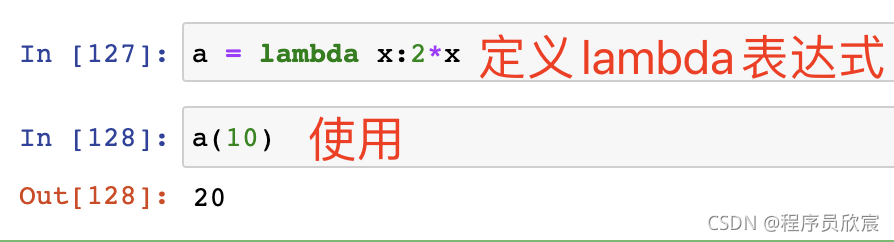
-
再來看看幾個支持lambda的內置函式,熟悉lambda的使用
-
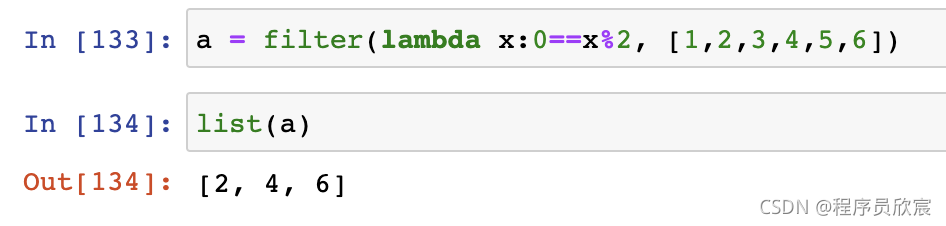
filter:過濾器,下面是個過濾奇偶數的例子,第一個引數是判斷是否過濾的邏輯,True保留,第二個引數是串列,最終奇數全部被剔除,只留下偶數:
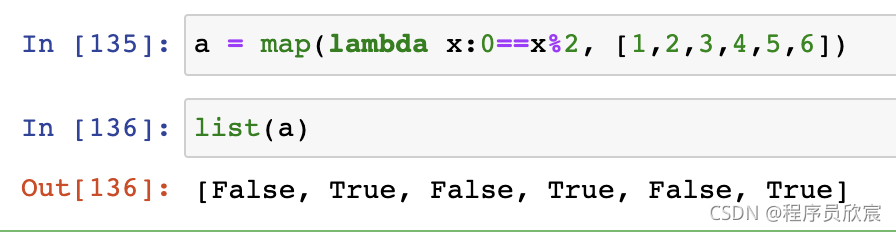
- map:逐一轉換,下面是將奇數轉為False,偶數轉為True的例子:
- reduce:大名鼎鼎的map reduce,您應該有所耳聞,reduce會將集合中的資料逐個取出來和前面一輪的結果做同樣的處理,最典型的當屬累加:

- sort:排序,先來看看最簡單的:

- sorted可以接受排序處理函式作為引數,例如按照絕對值進行排序,內置函式是abs,被作為引數傳給sorted:

- sorted方法會生成一個新的串列,如果想直接改變原串列就不適合用sorted方法了,此時用串列的sort方法即可,如下圖,還用了reverse引數試試倒排序的功能:

面向物件
- 身為Java程式員,天天和物件打交道,下面的代碼您應該很容易看懂:
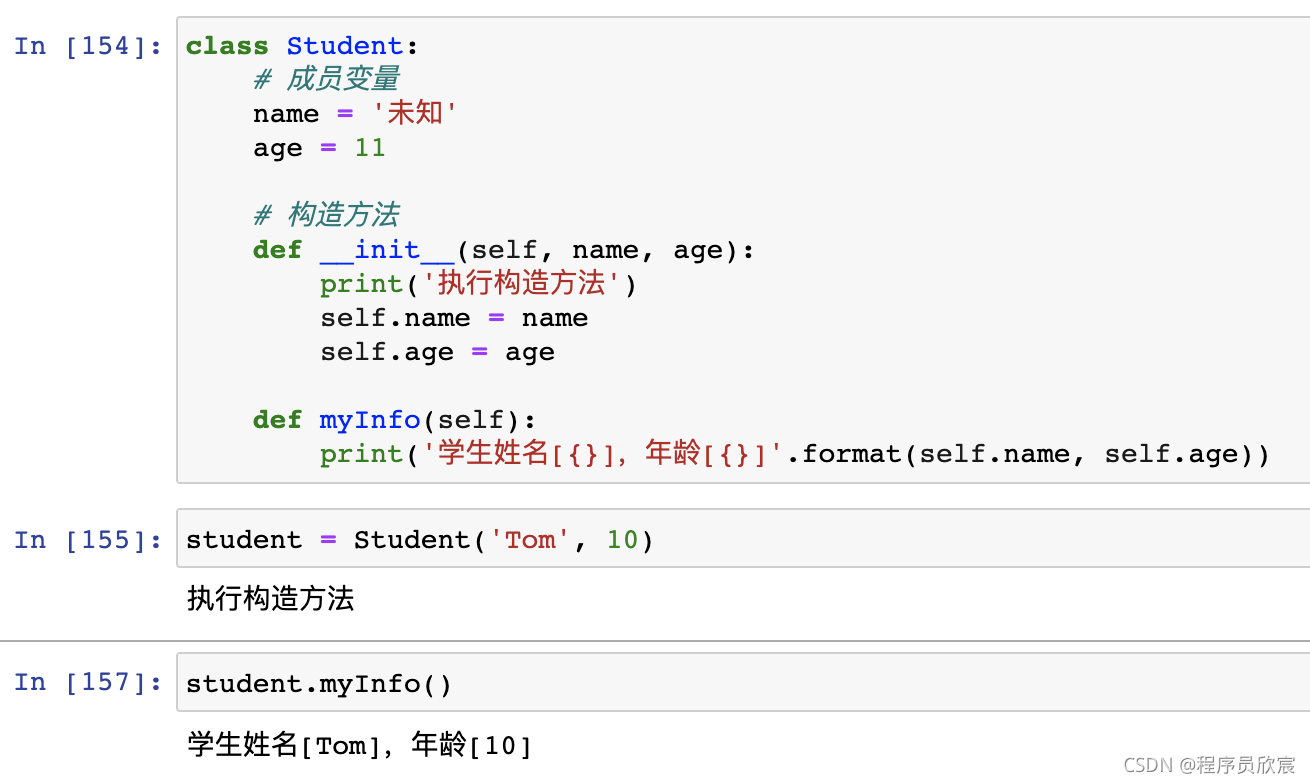
- 如果變數名是由兩個下劃線開始的,就表示改變數是私有成員變數,不能在外部訪問:
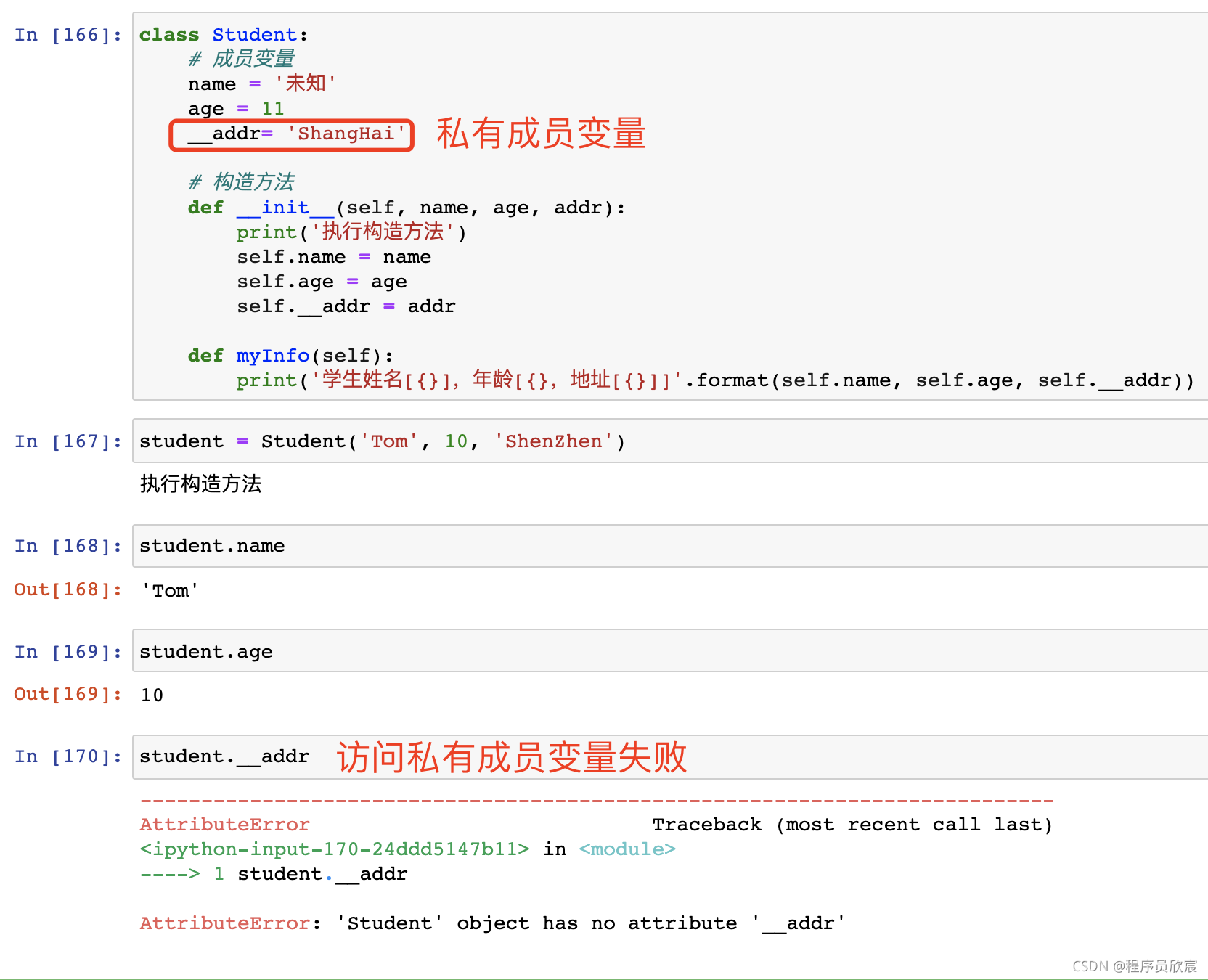
-
與Java不同的是,創建物件不需要關鍵字new
-
繼承:
class 派生類名 (父類名):
陳述句...
- 下面是個繼承的例子,Student是父類,Pupil是子類:
# 父類
class Student:
# 成員變數
name = '未知'
age = 11
__addr= 'ShangHai'
# 構造方法
def __init__(self, name, age, addr):
print('執行構造方法')
self.name = name
self.age = age
self.__addr = addr
def myInfo(self):
print('學生姓名[{}],年齡[{},地址[{}]]'.format(self.name, self.age, self.__addr))
class Pupil(Student):
#成員變數
grade = 1
# 構造方法
def __init__(self, name, age, addr, grade):
# 顯式呼叫父類構造方法
Student.__init__(self, name, age, grade)
print('執行構造方法(子類)')
self.grade = grade
# 子類自己的方法
def myGrade(self):
print('學生年級[{}]'.format(self.grade))
- 執行效果如下,符合預期:

生成器
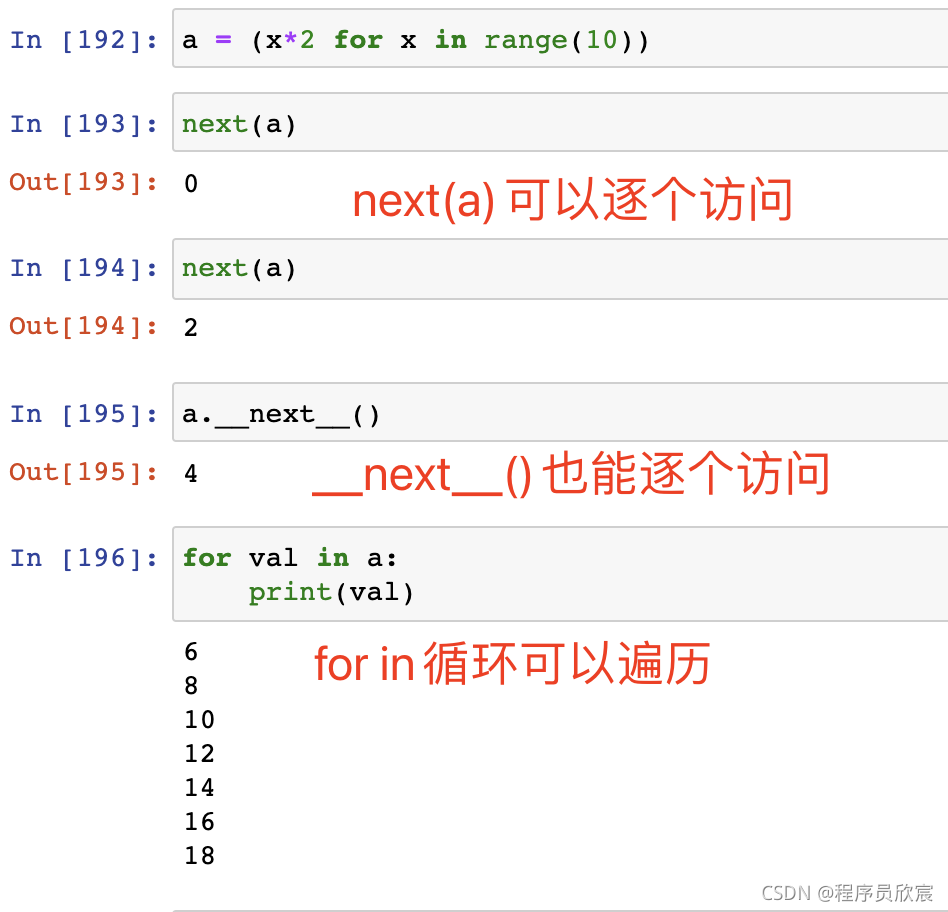
- 先回顧一下串列推導,下面的代碼會生成一個串列:
a = [x*2 for x in range(10)]
- 如果串列很大就會很占用記憶體空間,此時我們還有另一個選擇:生成器,簡單的說就是將上述代碼的方括號改成圓括號,這樣a就不是串列了,而是生成器,這是種特殊的迭代器:
例外處理
- 習慣了java的try-catch-finally,對python的例外處理就容易理解了,捕獲和處理如下:
try:
x = 1/0
print('不可能列印這一句')
except ZeroDivisionError as err:
print('發生例外', err)
finally:
print('執行finally')
- 輸出如下圖:

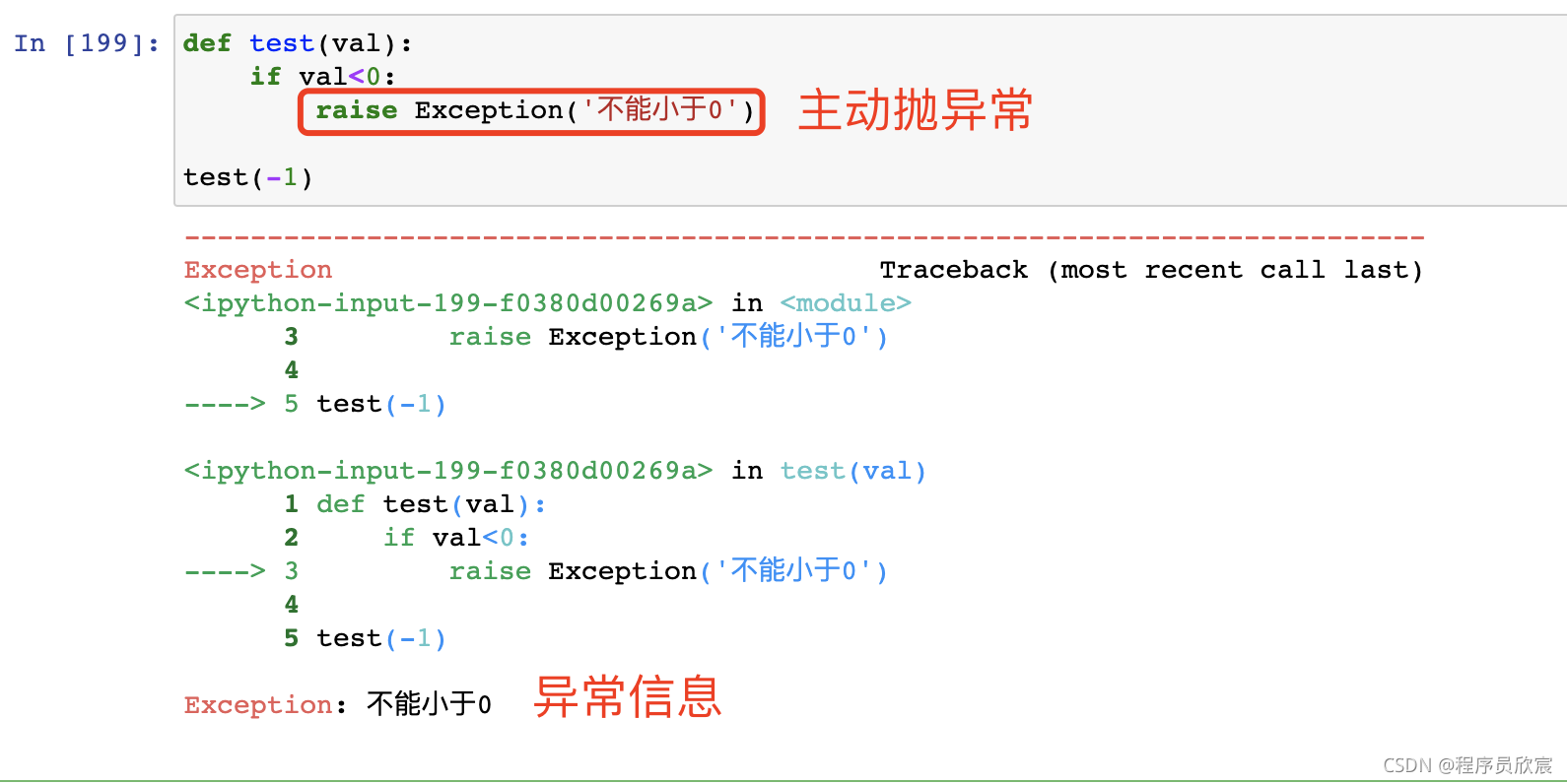
- 關鍵字raise可以主動拋出例外:
- 以上就是欣宸在自學Python程序中的簡化版筆記,希望能幫助您在初期抓住重點,快速入門;
你不孤單,欣宸原創一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 資料庫+中間件系列
- DevOps系列
歡迎關注公眾號:程式員欣宸
微信搜索「程式員欣宸」,我是欣宸,期待與您一同暢游Java世界...
https://github.com/zq2599/blog_demos
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/396024.html
標籤:Java
上一篇:房屋租賃系統(文字版)
下一篇:如何計算面向物件所需的旋轉