Prometheus是什么
Prometheus是一套開源監控系統和告警為一體,由go語言(golang)開發,是監控+報警+時間序列數
據庫的組合,適合監控docker容器,因為kubernetes(k8s)的流行帶動其發展,
Prometheus的主要特點
- 多維度資料模型,由指標名稱和鍵/值對標識的時間序列資料,
- 作為一個時間序列資料庫,其采集的資料會以檔案的形式存盤在本地中,
- 靈活的查詢語言,PromQL(Prometheus Query Language)函式式查詢語言,
- 不依賴分布式存盤,單個服務器節點是自治的,
- 以HTTP方式,通過pull模型拉取時間序列資料,
- 也可以通過中間網關支持push模型,
- 通過服務發現或者靜態配置,來發現目標服務物件,
- 支持多種多樣的圖表和界面展示,
Prometheus原理架構圖
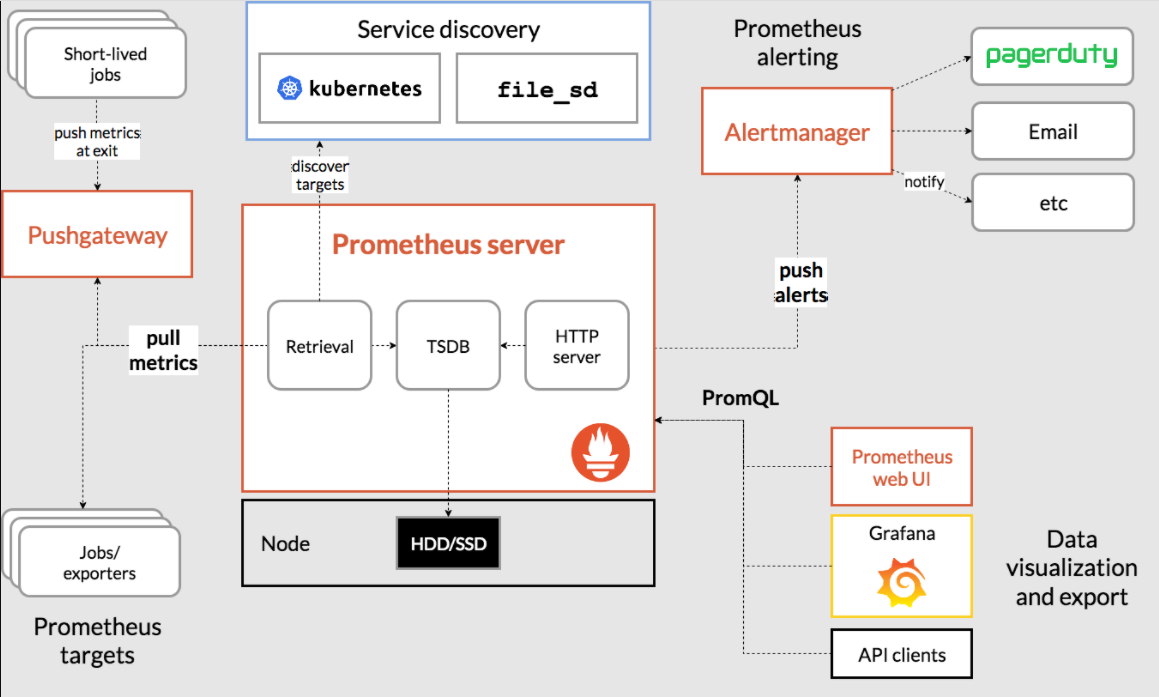
Prometheus基礎概念
什么是時間序列資料
時間序列資料(TimeSeries Data) : 按照時間順序記錄系統、設備狀態變化的資料被稱為時序資料,
應用的場景很多,如:
- 無人駕駛運行中記錄的經度,緯度,速度,方向,旁邊物體距離等,
- 某一個地區的各車輛的行駛軌跡資料,
- 傳統證券行業實時交易資料,
- 實時運維監控資料等,
時間序列資料特點:
- 性能好、存盤成本低
什么是targets(目標)
Prometheus 是一個監控平臺,它通過抓取監控目標(targets)上的指標 HTTP 端點來從這些目標收集指標,
安裝完Prometheus Server端之后,第一個targets就是它本身,
具體可以參考官方檔案
什么是metrics(指標)
Prometheus存在多種不同的監控指標(Metrics),在不同的場景下應該要選擇不同的Metrics,
Prometheus的merics型別有四種,分別為Counter、Gauge、Summary、Histogram,
- Counter:只增不減的計數器
- Gauge:可增可減的儀表盤
- Histogram:分析資料分布情況
- Summary:使用較少
簡單了解即可,暫不需要深入理解,
通過瀏覽器訪問http://被監控端IP:9100(被監控埠)/metrics
就可以查到node_exporter在被監控端收集的監控資訊
什么是PromQL(函式式查詢語言)
Prometheus內置了一個強大的資料查詢語言PromQL, 通過PromQL可以實作對監控資料的查詢、聚合,
同時PromQL也被應用于資料可視化(如Grafana)以及告警當中,
通過PromQL可以輕松回答以下問題:
- 在過去一段時間中95%應用延遲時間的分布范圍?
- 預測在4小時后,磁盤空間占用大致會是什么情況?
- CPU占用率前5位的服務有哪些?(過濾)
具體查詢細節可以參考官方,
如何監控遠程Linux主機
安裝Prometheus組件其實很簡單,下載包--解壓--后臺啟動運行即可,不做具體演示,
在遠程linux主機(被監控端)上安裝node_exporter組件,可看下載地址
下載解壓后,里面就一個啟動命令node_exporter,直接啟動即可,
nohup /usr/local/node_exporter/node_exporter >/dev/null 2>&1 &
lsof -i:9100
nohup:如果直接啟動node_exporter的話,終端關閉行程也會隨之關閉,這個命令幫你解決問題,
Prometheus HTTP API
Prometheus 所有穩定的 HTTP API 都在 /api/v1 路徑下,當我們有資料查詢需求時,可以通過查詢 API 請求監控資料,提交資料可以使用 remote write 協議或者 Pushgateway 的方式,
支持的 API
| API | 說明 | 需要認證 | 方法 |
|---|---|---|---|
| /api/v1/query | 查詢介面 | 是 | GET/POST |
| /api/v1/query_range | 范圍查詢 | 是 | GET/POST |
| /api/v1/series | series 查詢 | 是 | GET/POST |
| /api/v1/labels | labels 查詢 | 是 | GET/POST |
| /api/v1/label/<label_name>/values | label value 查詢 | 是 | GET |
| /api/v1/prom/write | remote write 資料提交 | 是 | remote write |
| Pushgateway | pushgateway 資料提交 | 是 | SDK |
認證方法
默認開啟認證,因此所有的介面都需要認證,且所有的認證方式都支持 Bearer Token和 Basic Auth,
呼叫介面的時候,我們需要攜帶Basic Auth請求頭的認證,否則會出現401,
Bearer Token
Bearer Token 隨著實體產生而生成,可以通過控制臺進行查詢,了解 Bearer Token 更多資訊,請參見 Bearer Authentication,
Basic Auth
Basic Auth 兼容原生 Prometheus Query 的認證方式,用戶名為用戶的 APPID,密碼為 bearer token(實體產生時生成),可以通過控制臺進行查詢,了解 Basic Auth 更多資訊,請參見 Basic Authentication,
資料回傳格式
所有 API 的回應資料格式都為 JSON,每一次成功的請求會回傳 2xx 狀態碼,
無效的請求會回傳一個包含錯誤物件的 JSON 格式資料,同時也將包含一個如下表格的狀態碼:
| 狀態碼 | 含義 |
|---|---|
| 401 | 認證失敗 |
| 400 | 當引數缺失或錯誤時回傳無效的請求狀態碼 |
| 422 | 當一個無效的運算式無法被指定時 (RFC4918) |
| 503 | 當查詢不可用或者被取消時回傳服務不可用狀態碼 |
無效請求回應回傳模板如下:
{
"status": "success" | "error",
"data": <data>,
// 當 status 狀態為 error 時,下面的資料將被回傳
"errorType": "<string>",
"error": "<string>",
// 當執行請求時有警告資訊時,該欄位將被填充回傳
"warnings": ["<string>"]
}
資料寫入
運維程序不需要對資料進行寫入,所以暫時不深入理解,
有興趣的同學可以看看官方檔案
監控資料查詢
當我們有資料查詢需求時,可以通過查詢 API 請求監控資料,
- 查詢 API 介面
GET /api/v1/query
POST /api/v1/query
查詢引數:
? query=
? time= <rfc3339 | unix_timestamp>: 時間戳, 可選,
? timeout= -query.timeout 引數指定,
- 簡單的查詢
查詢當前狀態為up的監控主機:
curl -u "appid:token" 'http://IP:PORT/api/v1/query?query=up'
- 范圍查詢
GET /api/v1/query_range
POST /api/v1/query_range
根據時間范圍查詢需要的資料,這也是我們用得最多的場景,
這時我們需要用到 /api/v1/query_range 介面,示例如下:
$ curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
什么是Grafana
Grafana是一個開源的度量分析和可視化工具,可以通過將采集的資料分析、查詢,
然后進行可視化的展示,并能實作報警,
網址: https://grafana.com/
使用Grafana連接Prometheus
連接不再做具體演示,操作思路如下:
- 在Grafana服務器上安裝,下載地址:https://grafana.com/grafana/download
- 瀏覽器
http://grafana服務器IP:3000登錄,默認賬號密碼都是admin,就可以登陸了, - 把Prometheus服務器收集的資料做為一個資料源添加到Grafana,得到Prometheus資料,
- 然后為添加好的資料源做圖形顯示,最后在dashboard就可以查看到,
操作流程不難,就不講解重點,后面正式開始上查詢腳本,
作業使用場景
作業中需要通過CPU、記憶體生成資源利用率報表,可以通過Prometheus的API寫一個Python腳本,

可通過API獲取資料,然后再進行資料排序、過濾、運算、聚合,最后寫入Mysql資料庫,
CPU峰值計算
- 取最近一周CPU數值,再排序取最高的值,
def get_cpu_peak(self):
"""
CPU取最近一周所有數值,再排序取最高的值,TOP1
:return: {'IP' : value}
"""
# 拼接URL
pre_url = self.server_ip + '/api/v1/query_range?query='
expr = '100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) ' \
'&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
url = pre_url + expr
# print(url)
result = {}
# 請求URL后將Json資料轉為字典物件
res = json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
# print(data)
# 回圈取出字典里每個IP的values,排序取最高值,最后存入result字典
for da in res.get('data').get('result'):
values = da.get('values')
cpu_values = [float(v[1]) for v in values] # 取出數值并存入串列
# 取出IP并消除埠號
ip = da.get('metric').get('instance')
ip = ip[:ip.index(':')] if ':' in ip else ip
# if ip == '10.124.58.181':
# print (ip)
# cpu_peak = round(sorted(cpu_values, reverse=True)[0], 2)
cpu_peak = sorted(cpu_values, reverse=True)[0]
# 取出IP和最高值之后,寫入字典
result[ip] = cpu_peak
# print(result)
return result
CPU均值計算
- 取最近一周CPU每一天的TOP20除以20得到當時忙時平均值,
再將7天平均值的和除以n,得到時間范圍內忙時平均值,
def get_cpu_average(self):
"""
CPU忙時平均值:取最近一周CPU資料,每一天的TOP20除以20得到忙時平均值;
再將一周得到的忙時平均值相加,再除以7,得到時間范圍內一周的忙時平均值,
:return:
"""
cpu_average = {}
for t in range(len(self.time_list)):
if t + 1 < len(self.time_list):
start_time = self.time_list[t]
end_time = self.time_list[t + 1]
# print(start_time, end_time)
# 拼接URL
pre_url = server_ip + '/api/v1/query_range?query='
expr = '100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) ' \
'&start=%s&end=%s&step=300' % (start_time, end_time - 1)
url = pre_url + expr
# print(url)
# 請求介面資料
data = https://www.cnblogs.com/jiba/p/json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
for da in data.get('data').get('result'): # 回圈拿到result資料
values = da.get('values')
cpu_load = [float(v[1]) for v in values] # 回圈拿到values里面的所有值
ip = da.get('metric').get('instance') # 拿到instance里面的ip
ip = ip[:ip.index(':')] if ':' in ip else ip # 去除個別后面帶的埠號
# avg_cup_load = sum(sorted(cpu_load, reverse=True)[:20]) / 20
# 取top20% 再除以20%,得出top20%的平均值
# avg_cup_load = round(sum(sorted(cpu_load, reverse=True)[:round(len(cpu_load) * 0.2)]) / round(len(cpu_load) * 0.2), 2)
# 倒序后取前面20%除以個數,得到前20%的平均值
avg_cup_load = sum(sorted(cpu_load, reverse=True)[:round(len(cpu_load) * 0.2)]) / round(len(cpu_load) * 0.2)
# print(avg_cup_load)
# 將計算后的資料以ip為key寫入字典
if cpu_average.get(ip):
cpu_average[ip].append(avg_cup_load)
else:
cpu_average[ip] = [avg_cup_load]
# 每日top20的平均值累加,共7天的再除以7
for k, v in cpu_average.items():
# cpu_average[k] = round(sum(v) / 7, 2)
cpu_average[k] = sum(v)
# print(cpu_average)
return cpu_average
記憶體峰值計算
- 取7天記憶體數值,排序后取最高峰值TOP1
def get_mem_peak(self):
"""
記憶體單臺峰值:取7天記憶體最高峰值TOP1
:return: 7天記憶體使用率最高峰值
"""
pre_url = self.server_ip + '/api/v1/query_range?query='
# expr = '(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100&start=%s&end=%s&step=300' % (start_time, end_time)
# 字符太長會導致報錯,所以這里進行拆分欄位計算
expr_MenTotal = 'node_memory_MemTotal_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
expr_MemFree = 'node_memory_MemFree_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
expr_Buffers = 'node_memory_Buffers_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
expr_Cached = 'node_memory_Cached_bytes&start=%s&end=%s&step=300' % (self.time_list[0], self.time_list[-1] - 1)
result = {}
# 回圈分別取出總記憶體、可用記憶體、Buffer塊、快取塊四個欄位
for ur in expr_MenTotal, expr_MemFree, expr_Buffers, expr_Cached:
url = pre_url + ur
data = https://www.cnblogs.com/jiba/p/json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
ip_dict = {}
# 回圈單個欄位所有值
for da in data.get('data').get('result'):
ip = da.get('metric').get('instance')
ip = ip[:ip.index(':')] if ':' in ip else ip
# if ip != '10.124.53.12':
# continue
if ip_dict.get(ip): # 過濾重復的ip,重復ip會導致計算多次
# print("重復ip:%s" % (ip))
continue
values = da.get('values')
# 將串列里的值轉為字典方便計算
values_dict = {}
for v in values:
values_dict[str(v[0])] = v[1]
# 標記ip存在
ip_dict[ip] = True
# 建立串列追加字典
if result.get(ip):
result[ip].append(values_dict)
else:
result[ip] = [values_dict]
# print(result)
# 對取出的四個值進行計算,得出峰值
for ip, values in result.items():
values_list = []
for k, v in values[0].items():
try:
values_MenTotal = float(v)
values_MemFree = float(values[1].get(k, 0))
values_Buffers = float(values[2].get(k, 0)) if values[2] else 0
values_Cached = float(values[3].get(k, 0)) if values[3] else 0
# 如果是0,不參與計算
if values_MemFree==0.0 or values_Buffers==0.0 or values_Cached==0.0:
continue
# values_list.append(round((values_MenTotal - (values_MemFree + values_Buffers + values_Cached)) / values_MenTotal * 100, 2))
# 合并后計算,得出串列
values_list.append((values_MenTotal - (values_MemFree + values_Buffers + values_Cached)) / values_MenTotal * 100)
# 對得出結果進行排序
result[ip] = sorted(values_list, reverse=True)[0]
except Exception as e:
# print(values[0])
logging.exception(e)
# print(result)
return result
記憶體均值計算
- 先取出7天的日期,根據多條鏈接回圈取出每天資料,排序value取top20除以20,最終7天資料再除以7
def get_mem_average(self):
"""
記憶體忙時平均值:先取出7天的日期,根據多條鏈接回圈取出每天資料,排序value取top20除以20,最終7天資料再除以7
:return:
"""
avg_mem_util = {}
for t in range(len(self.time_list)):
if t + 1 < len(self.time_list):
start_time = self.time_list[t]
end_time = self.time_list[t + 1]
# 根據多條鏈接回圈取出每天資料
pre_url = self.server_ip + '/api/v1/query_range?query='
# expr = '(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100&start=%s&end=%s&step=300' % (start_time, end_time)
expr_MenTotal = 'node_memory_MemTotal_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
expr_MemFree = 'node_memory_MemFree_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
expr_Buffers = 'node_memory_Buffers_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
expr_Cached = 'node_memory_Cached_bytes&start=%s&end=%s&step=600' % (start_time, end_time - 1)
result = {}
# 回圈取出四個欄位
for ur in expr_MenTotal, expr_MemFree, expr_Buffers, expr_Cached:
url = pre_url + ur
data = https://www.cnblogs.com/jiba/p/json.loads(requests.post(url=url, headers=self.headers).content.decode('utf8', 'ignore'))
ip_dict = {}
# 回圈單個欄位所有值
for da in data.get('data').get('result'):
ip = da.get('metric').get('instance')
ip = ip[:ip.index(':')] if ':' in ip else ip
if ip_dict.get(ip):
# print("重復ip:%s" % (ip))
continue
values = da.get('values')
# 將串列里的值轉為字典方便計算
values_dict = {}
for v in values:
values_dict[str(v[0])] = v[1]
# 標記ip存在
ip_dict[ip] = True
# 建立串列追加字典
if result.get(ip):
result[ip].append(values_dict)
else:
result[ip] = [values_dict]
# print(result)
for ip, values in result.items():
values_list = []
for k, v in values[0].items():
try:
values_MenTotal = float(v)
values_MemFree = float(values[1].get(k, 0)) if values[1] else 0
values_Buffers = float(values[2].get(k, 0)) if values[2] else 0
values_Cached = float(values[3].get(k, 0)) if values[3] else 0
if values_MemFree == 0.0 or values_Buffers == 0.0 or values_Cached == 0.0:
continue
value_calc = (values_MenTotal - (values_MemFree + values_Buffers + values_Cached)) / values_MenTotal * 100
if value_calc != float(0):
values_list.append(value_calc)
except Exception as e:
print(values[0])
# logging.exception(e)
continue
# 排序value取top20除以20
# avg_mem = round(sum(sorted(values_list, reverse=True)[:round(len(values_list) * 0.2)]) / round(len(values_list) * 0.2), 2)
try:
avg_mem = sum(sorted(values_list, reverse=True)[:round(len(values_list) * 0.2)]) / round(len(values_list) * 0.2)
except Exception as e:
avg_mem = 0
logging.exception(e)
if avg_mem_util.get(ip):
avg_mem_util[ip].append(avg_mem)
else:
avg_mem_util[ip] = [avg_mem]
# 最終7天資料再除以7
for k, v in avg_mem_util.items():
# avg_mem_util[k] = round(sum(v) / 7, 2)
avg_mem_util[k] = sum(v)
return avg_mem_util
匯出excel
- 將采集到的資料匯出excel
def export_excel(self, export):
"""
將采集到的資料匯出excel
:param export: 資料集合
:return:
"""
try:
# 將字典串列轉換為DataFrame
pf = pd.DataFrame(list(export))
# 指定欄位順序
order = ['ip', 'cpu_peak', 'cpu_average', 'mem_peak', 'mem_average', 'collector']
pf = pf[order]
# 將列名替換為中文
columns_map = {
'ip': 'ip',
'cpu_peak': 'CPU峰值利用率',
'cpu_average': 'CPU忙時平均峰值利用率',
'mem_peak': '記憶體峰值利用率',
'mem_average': '記憶體忙時平均峰值利用率',
'collector': '來源地址'
}
pf.rename(columns=columns_map, inplace=True)
# 指定生成的Excel表格名稱
writer_name = self.Host + '.xlsx'
writer_name.replace(':18600', '')
# print(writer_name)
file_path = pd.ExcelWriter(writer_name.replace(':18600', ''))
# 替換空單元格
pf.fillna(' ', inplace=True)
# 輸出
pf.to_excel(file_path, encoding='utf-8', index=False)
# 保存表格
file_path.save()
except Exception as e:
print(e)
logging.exception(e)
因為機房需要保留資料方便展示,后面改造成采集直接入庫mysql,
---- 鋼鐵知識庫 [email protected] 2021.12.29
寫在最后
以上簡單介紹了Prometheus架構、基礎概念、API使用,以及Python呼叫Prometheus的API部分示例,完整代碼也已經上傳,需要自取或聯系即可,
下載鏈接:
https://download.csdn.net/download/u011463397/72150839
參考鏈接:
Prometheus操作指南:https://github.com/yunlzheng/prometheus-book
官方查詢API:https://prometheus.io/docs/prometheus/latest/querying/api/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/397152.html
標籤:Python